![[アップデート] Amazon Quick にデータセット Q&A が追加され、トピックなしでデータセットに自然言語で直接質問できるようになりました](https://images.ctfassets.net/ct0aopd36mqt/2x7muHjvW69fxuVNSKWZHp/b37e05a972fc8125e9214abd764928fa/amazon-quick.png?w=3840&fm=webp)
[アップデート] Amazon Quick にデータセット Q&A が追加され、トピックなしでデータセットに自然言語で直接質問できるようになりました
いわさです。
Amazon Quick(旧 Amazon QuickSight)には Amazon Q を活用した自然言語による Q&A 機能が搭載されています。
従来はダッシュボード Q&A とトピック Q&A の 2 つのモードが提供されていましたが、いずれもダッシュボードやトピックの事前構成が必要でした。
以下の記事では、トピックなしでどこまで Q&A 機能が使えるのかを検証されています。
データセットに対して直接自然言語で質問するにはトピックの作成が必要という状態でした。
今回のアップデートで、データセット Q&A が追加されました。
トピックの事前設定なしに、データセットに対して直接自然言語で質問すると、テキストから SQL が生成・実行され、数秒で回答が返ってくる機能です。
今回こちらを確認してみたので紹介します。
実際に確認してみる
では早速 Amazon Quick のチャット画面からデータセット Q&A を試してみましょう。
今回は東京リージョンで検証しています。
チャットからデータセットを選択する
データセット Q&A を使うには、チャット画面のナレッジピッカーからデータセットを選択します。
以前のチャット画面でアセットの追加ダイアログを開くと、「データセット」タブは存在せず、スペース・トピック・ダッシュボード・ナレッジベース・アクションのみが選択可能でした。
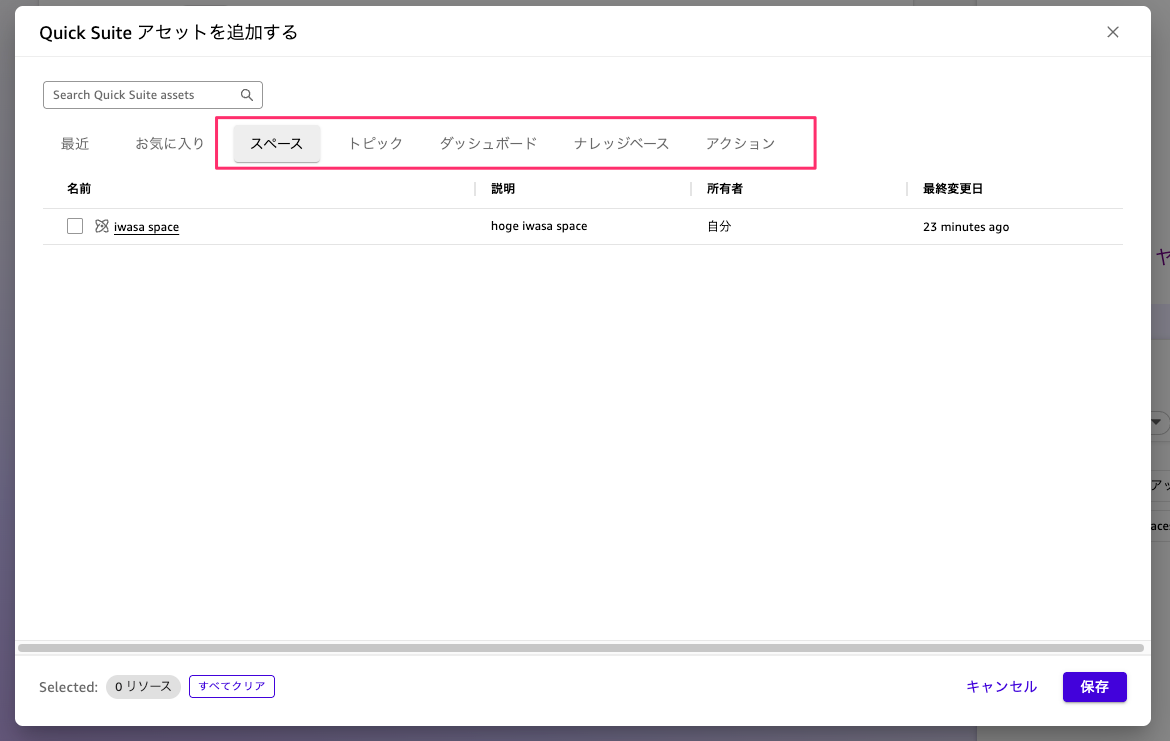
今回のアップデート後は、アセット追加ダイアログに「データセット」タブが追加されています。
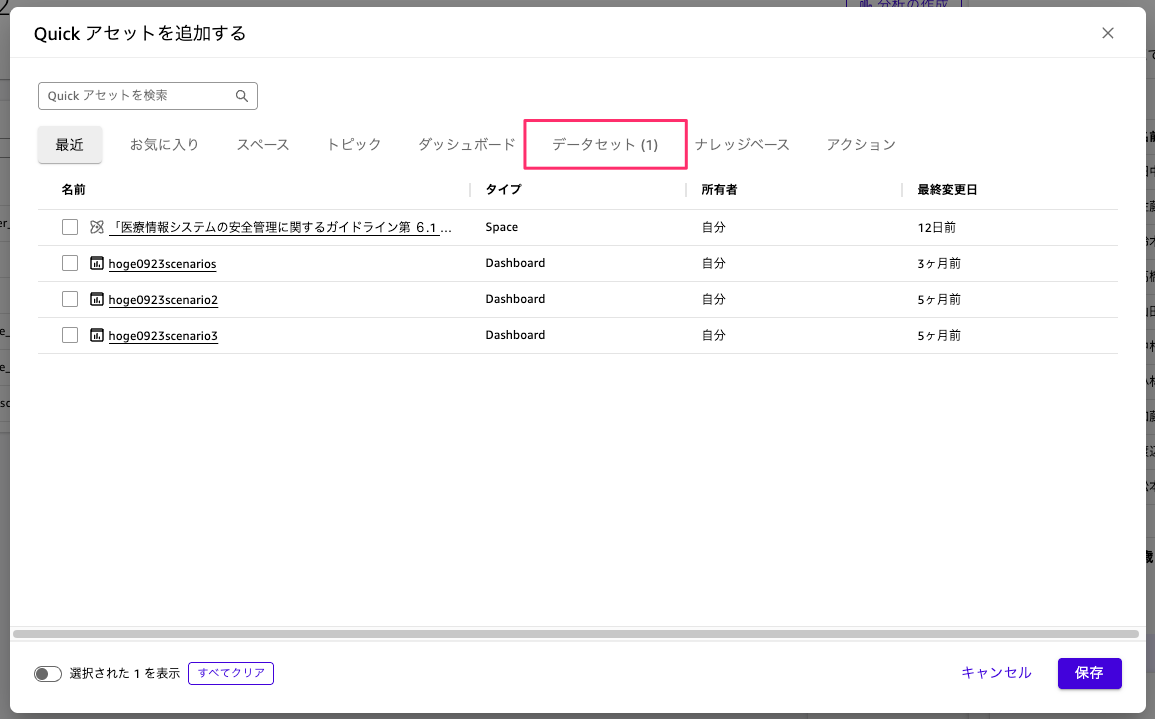
今回は Athena 経由のダイレクトクエリデータセットを用意しました。
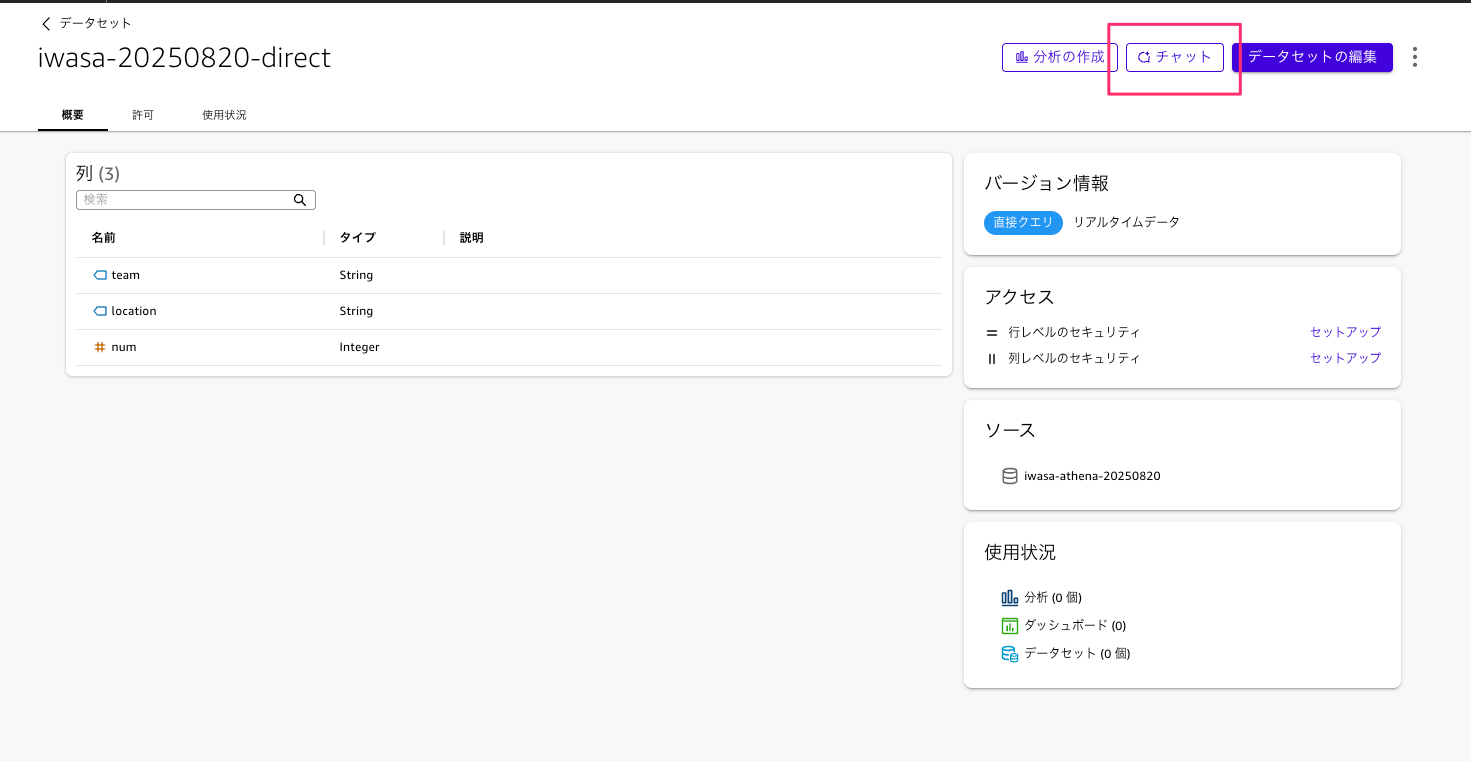
データセットの詳細画面の「チャット」ボタンから開くと、対象のデータセットが選択された状態でチャットが開きます。
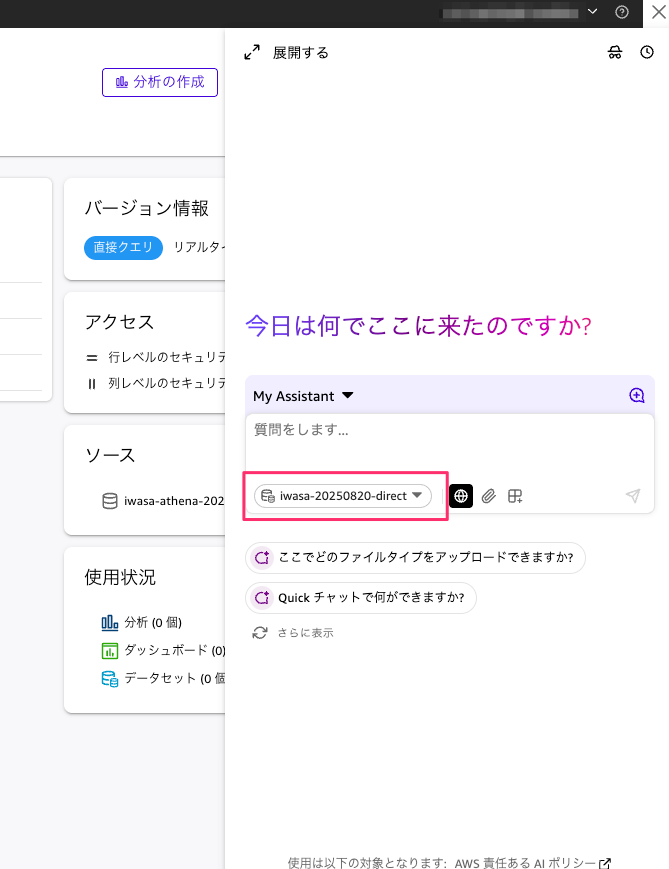
基本的な集計を質問してみる
データセットを選択した状態で、まずはシンプルな集計を質問してみます。
「チームごとのnumの合計は?」と入力してみました。
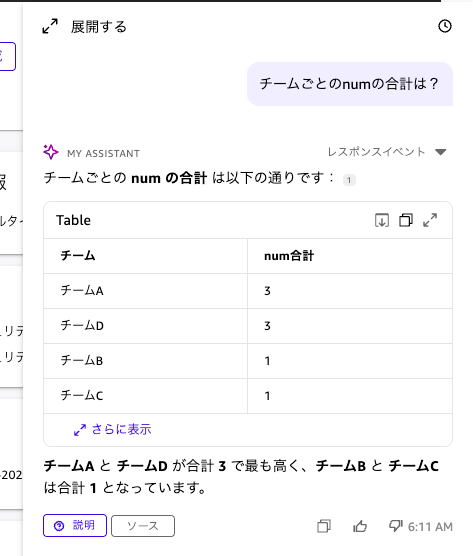
チームごとの num の合計がテーブルで返ってきました。
チームA とチームD が合計 3 で最も高く、チームB とチームC は合計 1 という結果です。
回答にはテーブルだけでなく、結果の要約テキストも付いていますね。
ランタイム計算を試してみる
次に、データセットに存在しないメトリクスの算出を試してみます。
データセット Q&A の特徴のひとつとして、ランタイムでのカスタム計算が可能な点が挙げられています。
「拠点ごとのnumの平均と、全体平均との差を教えて」と質問してみました。
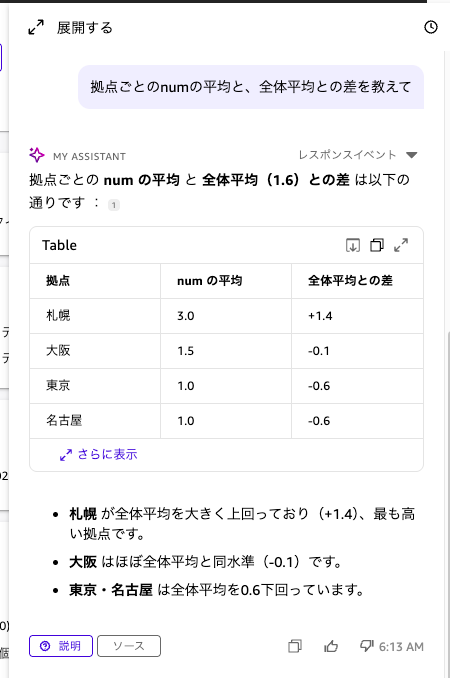
全体平均(1.6)を自動で算出した上で、各拠点の平均との差を計算してくれました。
札幌が +1.4 で全体平均を大きく上回っており、東京・名古屋は -0.6 で下回っているという結果です。
データセットには「全体平均との差」というフィールドは存在しないので、ランタイムで計算されていることがわかります。
Explain 機能で推論過程を確認する
回答の下部に「説明」ボタンが表示されています。
クリックすると Explanation 画面が開き、回答に至るまでの推論過程を確認出来ます。
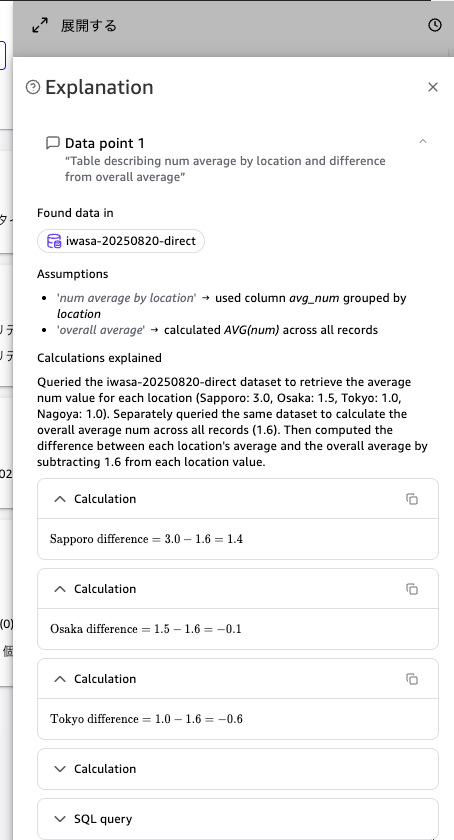
Assumptions(前提)として、num average by location → avg_num カラムを location でグループ化、overall average → 全レコードの AVG(num) を計算、という解釈が示されています。
Calculations explained では、各拠点の差分計算(例:Sapporo difference = 3.0 - 1.6 = 1.4)がステップごとに表示されており、回答の根拠を確認出来ますね。
さらに下部には SQL query のセクションもあり、実際に生成された SQL を確認することも出来るようです。
複数データセットの横断分析
ナレッジピッカーで複数のデータセットを選択すると、質問の内容に応じて適切なデータセットに自動ルーティングされるようです。
公式ブログによると、「すべてのデータとアプリ」を選択すると、どのデータセットがあるかを知らなくても、質問に関連するデータセットを自動で発見してくれるとのこと。
You don't even need to know which datasets are available. In Quick Chat, the knowledge picker provides an option to select All data and apps.
今回は複数のデータセットを選択した状態で質問してみました。
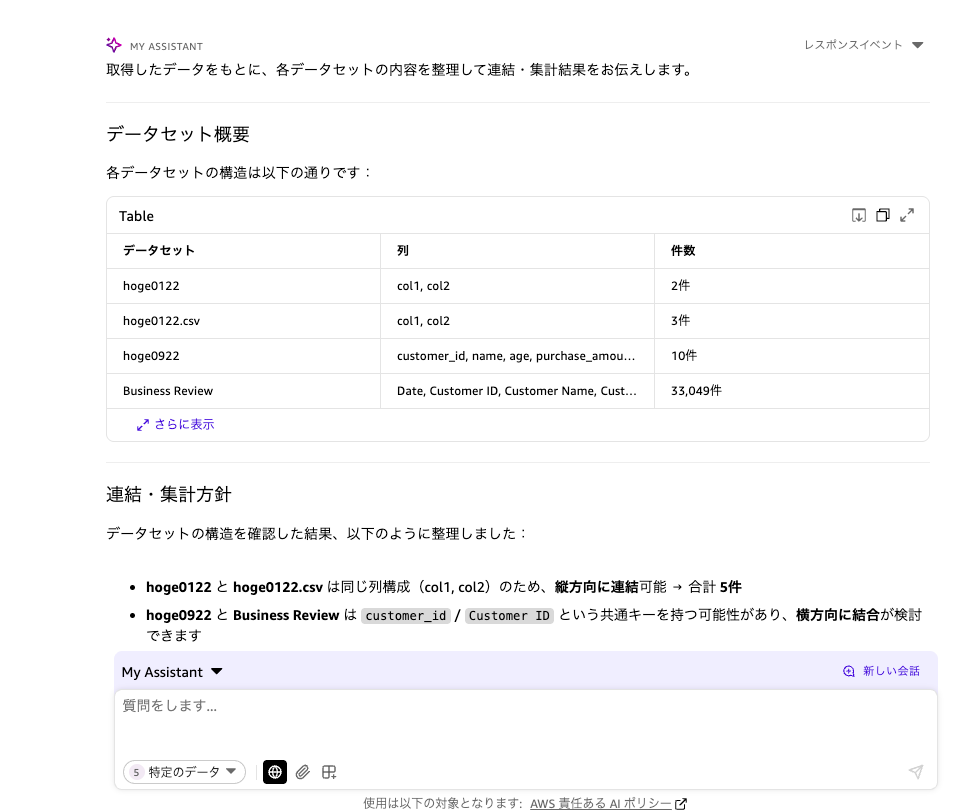
各データセットの構造を横断的に分析し、連結・集計の方針まで提案してくれています。
なるほど、これはおもしろいですね。
3 つの Q&A モードの使い分け
公式ブログでは、データセット Q&A と従来の Q&A モードとの使い分けについて整理されていました。
Dataset Q&A opens up one-time exploration beyond pre-configured boundaries. It provides access to any field with custom runtime calculations in natural language, plus full SQL transparency for technical validation.
Dashboard Q&A works well when exploring insights within the boundaries of what dashboard authors have configured, including specific visuals, fields, filters, and curated business logic with calculations.
Topic Q&A shines when authors have created and maintained topic configurations with curated field definitions, synonyms, and custom instructions.
| モード | 用途 |
|---|---|
| ダッシュボード Q&A | ダッシュボード著者が構成したビジュアル・フィールド・フィルター・計算ロジックの範囲内で質問する場合 |
| トピック Q&A | 著者がフィールド定義・シノニム・カスタム指示を設定したトピックに対して質問する場合 |
| データセット Q&A | トピックやダッシュボードの事前構成なしに、データセットのあらゆるフィールドに対してアドホックに質問する場合 |
トピック Q&A は事前にフィールド定義やシノニムを設定しておくことで精度の高い回答が得られる一方、データセット Q&A は事前設定なしにすぐ使い始められるのが特徴ですね。
ランタイムでのカスタム計算(データセットに存在しないメトリクスの算出)や、生成された SQL の確認が出来る点もデータセット Q&A ならではです。
なお、公式ブログによると現時点での制約事項として以下が挙げられています。
Composite datasets are not supported when the parent datasets use SPICE and the child dataset is in direct query mode.
Custom SQL datasets with parameters are currently not supported.
SPICE の親データセットとダイレクトクエリの子データセットを組み合わせた複合データセットは非対応とのこと。
また、パラメータ付きのカスタム SQL データセットも現時点では非対応のようです。
利用条件について
公式ブログによると利用には Enterprise Edition が必要で、プロロール(Enterprise ユーザーまたは Professional ユーザー)が必要とのことです。
Amazon Quick Enterprise Edition enabled in your account with at least one Enterprise user and Professional user.
ただし、今回の検証ではプロロールの存在しない Enterprise Edition 環境でもデータセット Q&A を利用出来ました。
過去記事でもトピックの作成にはプロロールが必要だが自然言語での問い合わせ自体はプロでなくても可能と検証されていたので、データセット Q&A はトピック不要な分、プロロールなしでも使えるのかもしれないですね。
ただし、プロロールなしでの利用によって Q&A のインフラ料金(250 USD/月)が発生するかどうかは未確認です。こちらは後日確認して追記予定です。
対応データソースについては、公式ブログによると SPICE データセットとダイレクトクエリデータセットの両方に対応しているようです。
ファイルアップロードで作成したデータセット(SPICE に取り込まれるもの)でも利用出来ることを確認しました。
ダイレクトクエリモードの場合は Amazon Athena、Amazon Redshift、Amazon Aurora PostgreSQL、Amazon S3 Tables が対応データソースとして挙げられています。
Dataset Q&A capabilities can be invoked for both SPICE and direct query datasets including Amazon Redshift, Amazon Athena, Amazon Aurora PostgreSQL and Amazon Simple Storage Service (S3) Tables.
なお、ダイレクトクエリデータセットの場合は行数制限なくデータセット全体に対して集計が行われ、SPICE の場合は SPICE キャパシティの範囲内での集計になるようです。
Dataset Q&A has no row limits for direct query datasets, so aggregations reflect the complete dataset. For SPICE datasets, the aggregations are subject to SPICE capacity.
さいごに
本日は Amazon Quick にデータセット Q&A が追加され、データセットに対して自然言語で直接質問できるようになったので確認してみました。
従来のダッシュボード Q&A やトピック Q&A ではダッシュボードやトピックの事前構成が必要でしたが、データセット Q&A ではデータセットさえあればすぐに自然言語で質問を始められるのは手軽で良いですね。
特に Explain 機能で推論過程や生成された SQL を確認できるのは、回答の正確性を検証したい場面で重宝しそうです。
また、今回は検証しませんでしたが、データセットエンリッチメントという機能も同時に導入されています。
This launch also introduces Dataset Enrichment, a streamlined way for authors to ground the system in business context for a single dataset with no topic configuration required.
公式ブログによると、データセットのフィールドに対してビジネス上の説明やカスタム指示を付与することで、Q&A の回答精度を向上させる仕組みのようです。
例えば num というカラム名だけでは「人数」なのか「売上」なのか判断しづらいですが、フィールドの説明を付与しておくことでエージェントが正しく解釈出来るようになるイメージですね。
YAML や JSON 形式のファイルをアップロードする方法でも設定出来るとのことで、データカタログやチーム Wiki に既にある定義を流用出来るのは便利そうです。
こちらも別途試してみたいと思います。










