
Amazon S3 Vectors: AI-Ready Storage, Fast & Simple
Efficiently storing and querying vector embeddings at scale while keeping costs reasonable presents a significant challenge in AI/ML data management. Amazon S3 Vectors, an extension of Amazon Simple Storage Service (S3), offers a fully-managed vector storage solution specifically designed to overcome these scalability and cost barriers.
Architecture and Core Components
The S3 Vectors architecture builds upon the existing S3 foundation, introducing two key concepts:
- Vector Buckets: A specialized type of S3 bucket optimized for vector data. It inherits S3's core properties, such as 11 nines of durability and high availability, while offering dedicated API endpoints for vector operations.
- Vector Indexes: The organizational structure for vector data within a Vector Bucket. This primary data structure enables efficient similarity search operations.
When setting up an index, developers must specify these parameters:
- Vector dimensions: The dimensionality of the vectors.
- Distance metric: The algorithm for measuring distance. S3 Vectors currently supports Cosine Similarity and Euclidean Distance (L2).
Each Vector Bucket can hold up to 10,000 indexes, with each index capable of storing tens of millions of vectors, enabling large-scale data expansion.
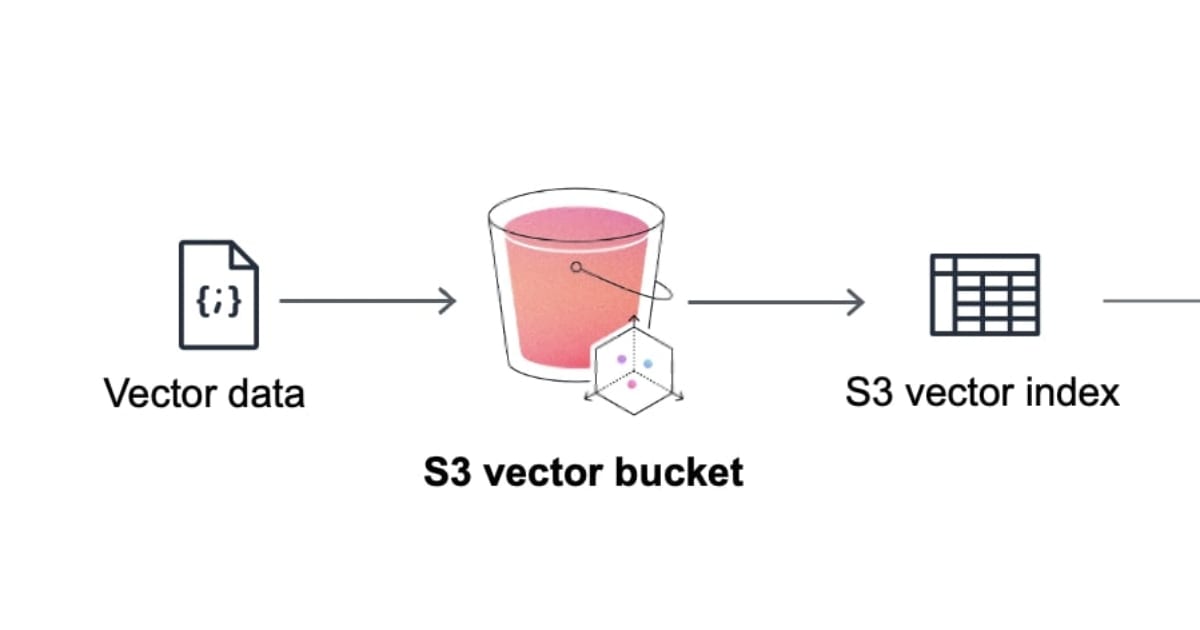
Operational Workflow
S3 Vectors operates through three main stages, each executed via API calls:
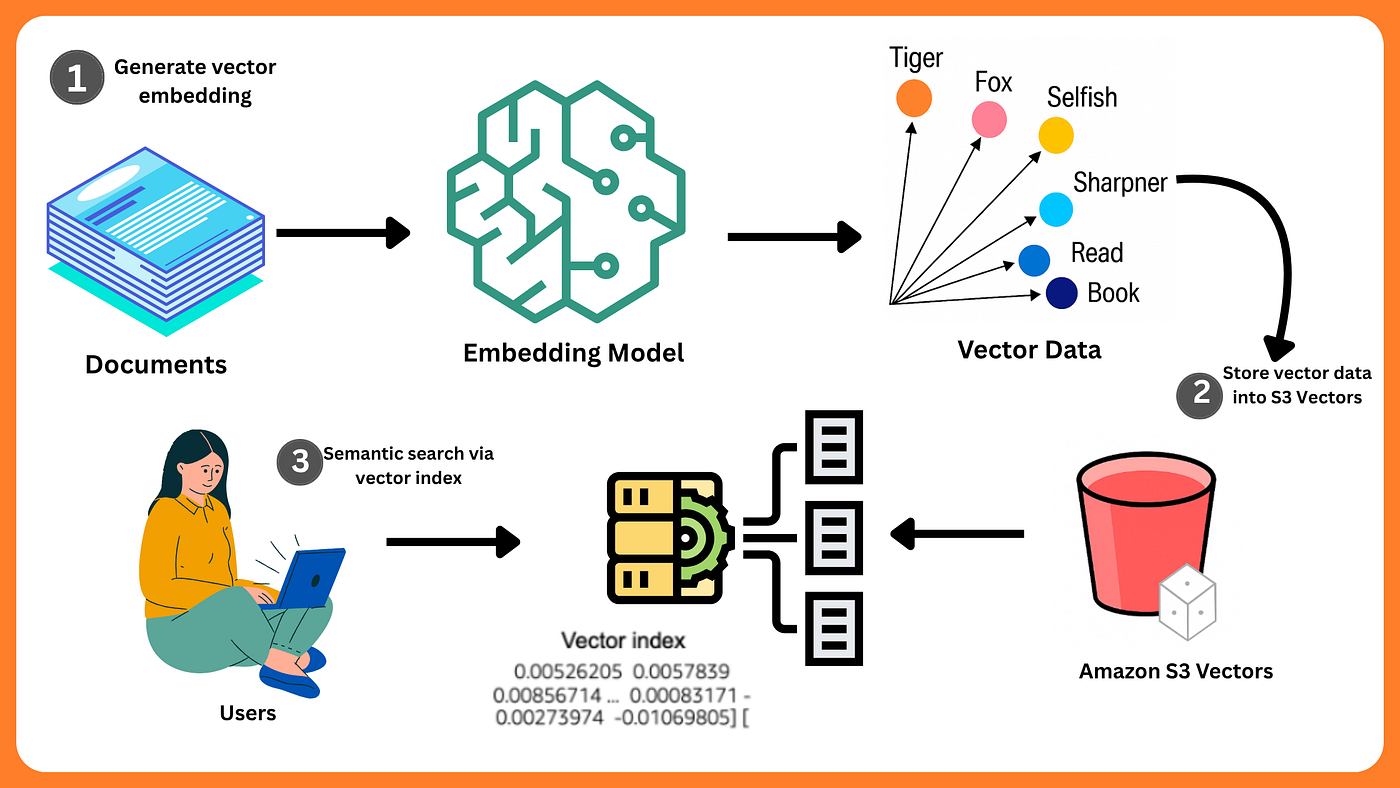
Data Ingestion
- Process: Vector embeddings generated from machine learning models (e.g., via Amazon Bedrock) are loaded into a predefined index.
- API: The
InsertVectorsAPI call handles batch ingestion of vectors. - Metadata Attachment: Each vector can include key-value metadata, essential for filtered queries later.
Data Querying
- API: Queries are executed through the
QueryVectorsAPI call. - Input: This call requires a query vector and a
topKparameter that specifies the number of similar results to return. - Metadata Filtering: The API supports filtering expressions on attached metadata, enabling hybrid searches that combine vector similarity with attribute filtering.
- Performance: AWS delivers sub-second latency for queries, making it suitable for applications that don't require real-time, ultra-low latency.
Integration Patterns
S3 Vectors delivers its greatest value when integrated into tiered data architectures and AI systems.
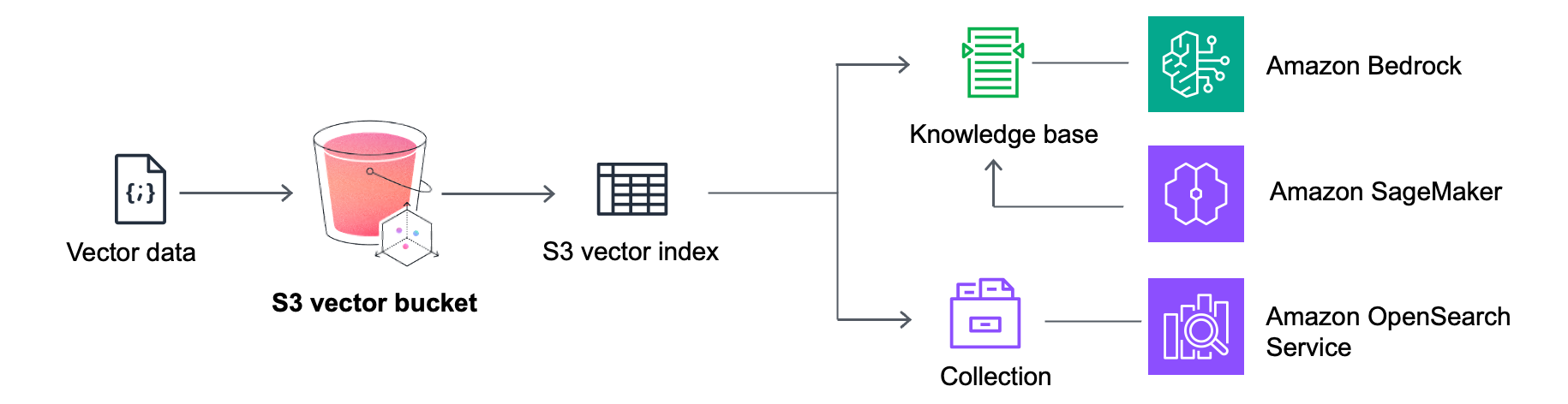
- Tiered Data Strategy with Amazon OpenSearch Service:
- S3 Vectors functions as "cold" or "warm" storage for less frequently accessed vectors, reducing long-term storage costs.
- Vectors requiring faster query performance can be synchronized to an Amazon OpenSearch Service collection, which acts as "hot storage" for high-throughput, low-latency queries.
- Retrieval-Augmented Generation (RAG):
- S3 Vectors serves as an ideal knowledge base for large-scale RAG systems.
- The workflow:
- Generate a vector from the user's query.
- Query S3 Vectors to retrieve relevant documents or text chunks.
- Supply these documents as context in the prompt sent to a Large Language Model (LLM) like Claude or Llama.
Quick Demo
Our Goal is turning documents into searchable knowledge — in under 10 minutes.
This hands-on walkthrough walks you through:
- Upload & convert documents to vectors
- Create a knowledge base & configure your data source
- Set up processing and sync data seamlessly
- Test search results — and clean up safely
No coding. No setup. Just a few clicks to see how Amazon S3 Vector powers intelligent, real-time search — all in the AWS Console.
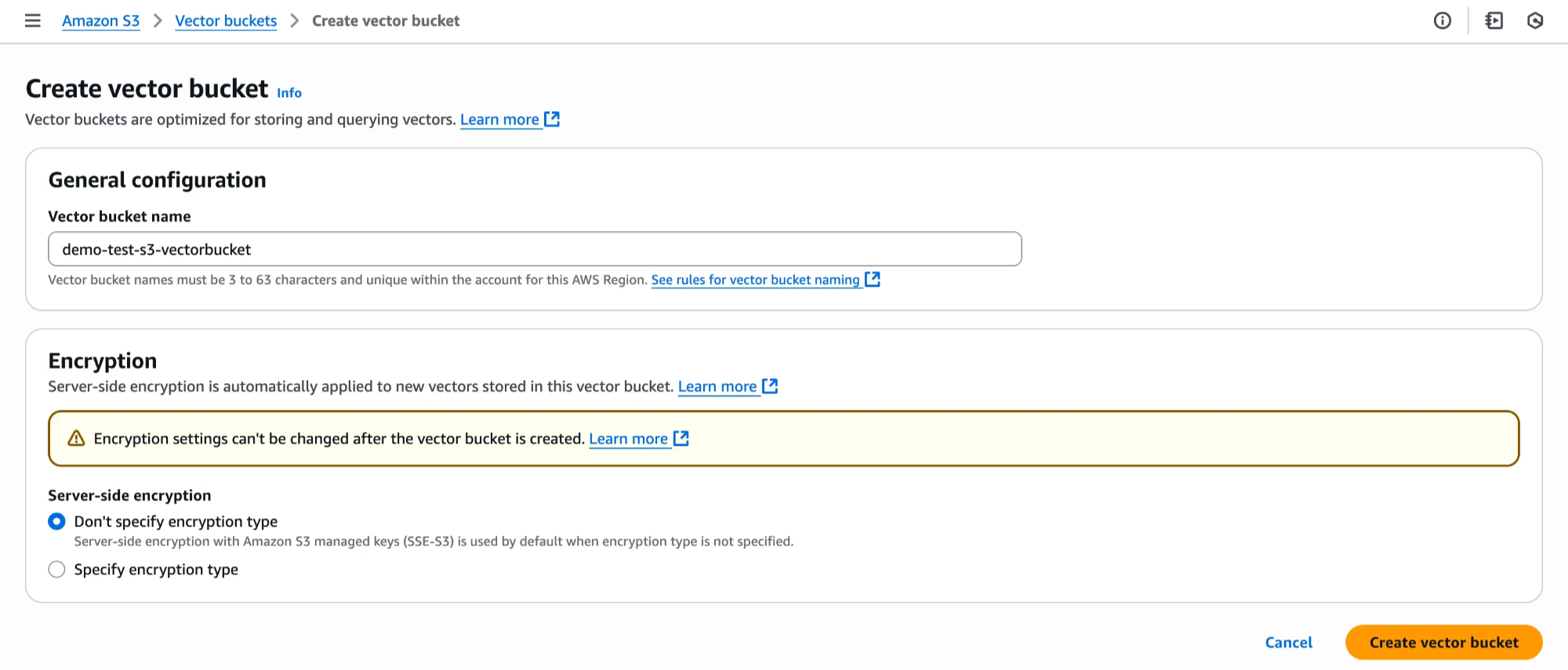
1. Create Amazon S3 Vectors
To create a vector bucket, navigate to the Amazon S3 console, select Vector buckets in the left navigation pane, and click Create vector bucket.
Enter a vector bucket name and select your preferred encryption type. If you don't specify one, Amazon S3 automatically applies server-side encryption with Amazon S3 managed keys (SSE-S3) as the default encryption for new vectors
Now, you can create a vector index to store and query your vector data within your created vector bucket.
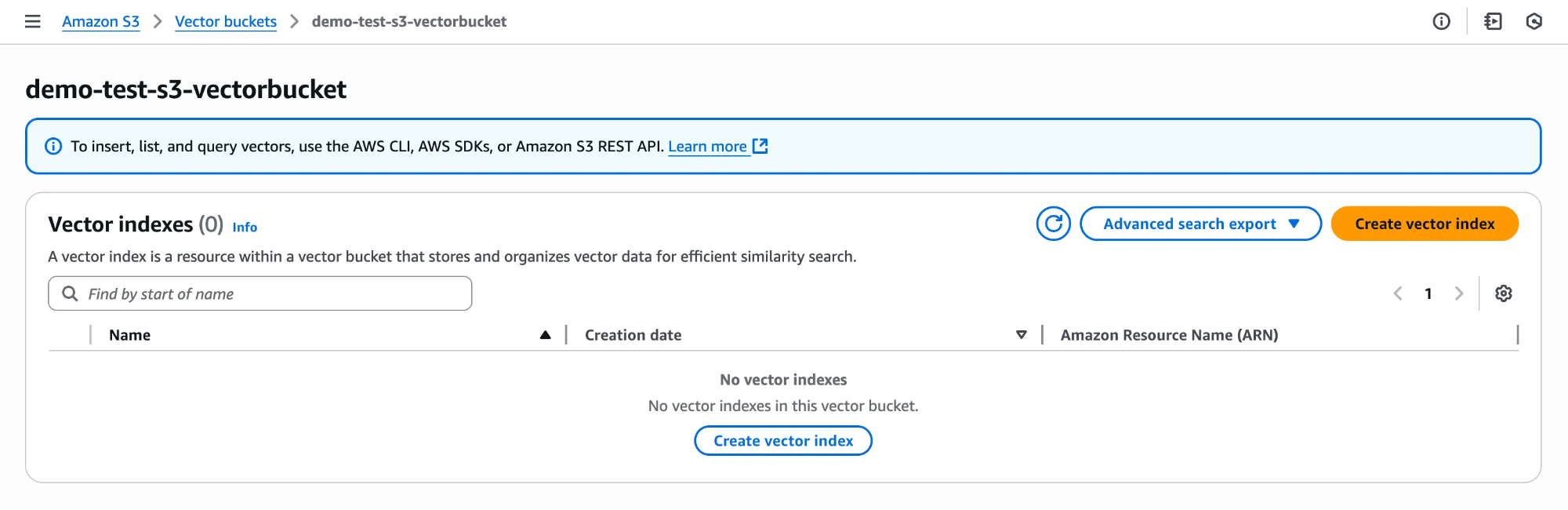
Enter a vector index name and specify the dimensionality of the vectors for this index. All vectors added must have exactly this same number of dimensions.
For Distance metric, choose either Cosine or Euclidean. For best results, select the distance metric recommended by your embedding model.
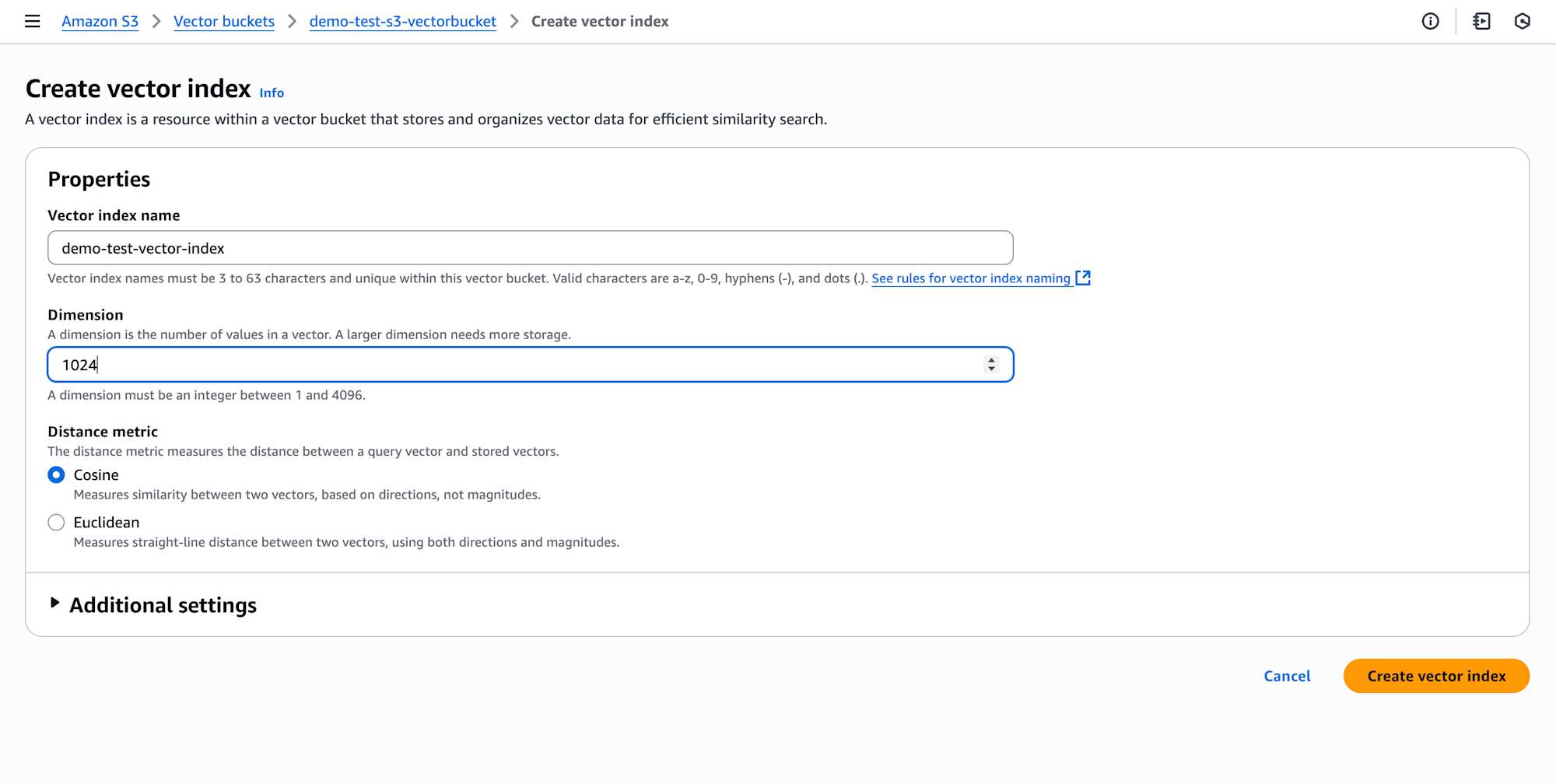
Choose Create vector index and then you can insert, list, and query vectors.
2. Create a new knowledge base
- On the Amazon Bedrock console in the left navigation pane, choose Knowledge Bases. To initiate the creation process, in the Create dropdown list, choose Knowledge Base with vector store.
- On the Provide Knowledge Base details page, enter a descriptive name for your knowledge base and an optional description to identify its purpose.
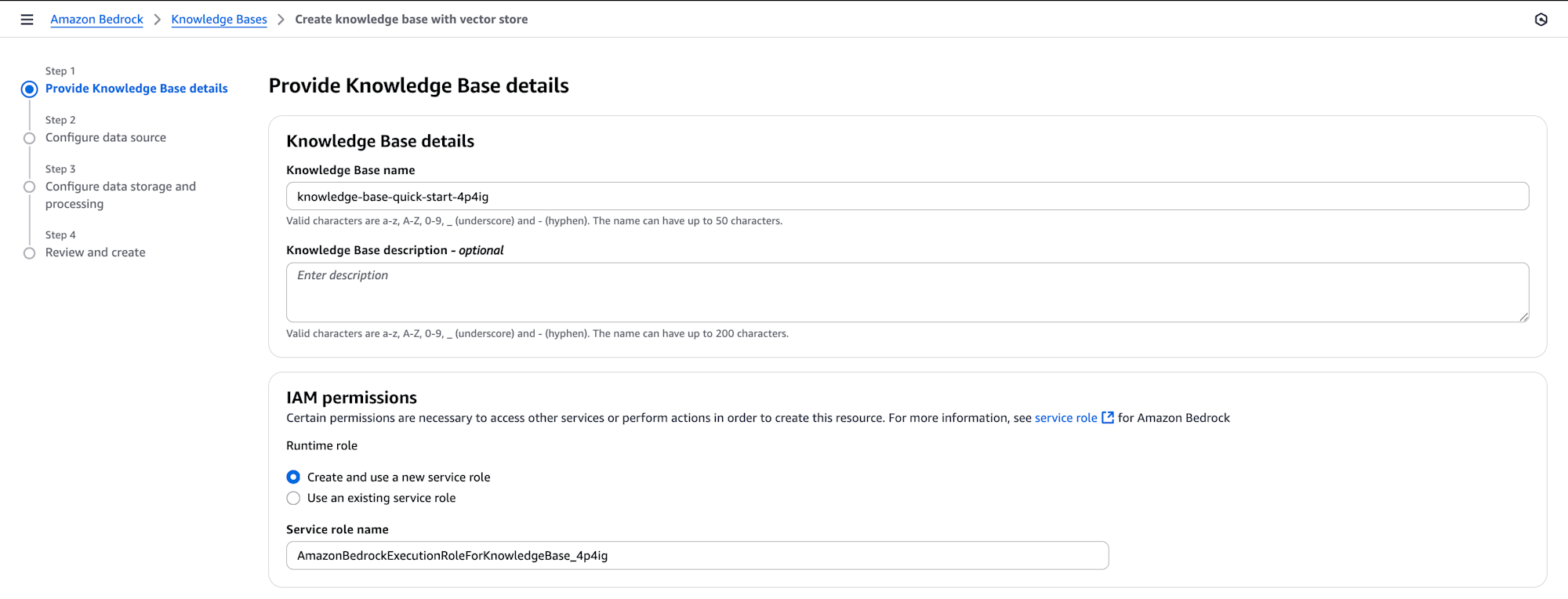
- Choose Next to proceed to the data source configuration.
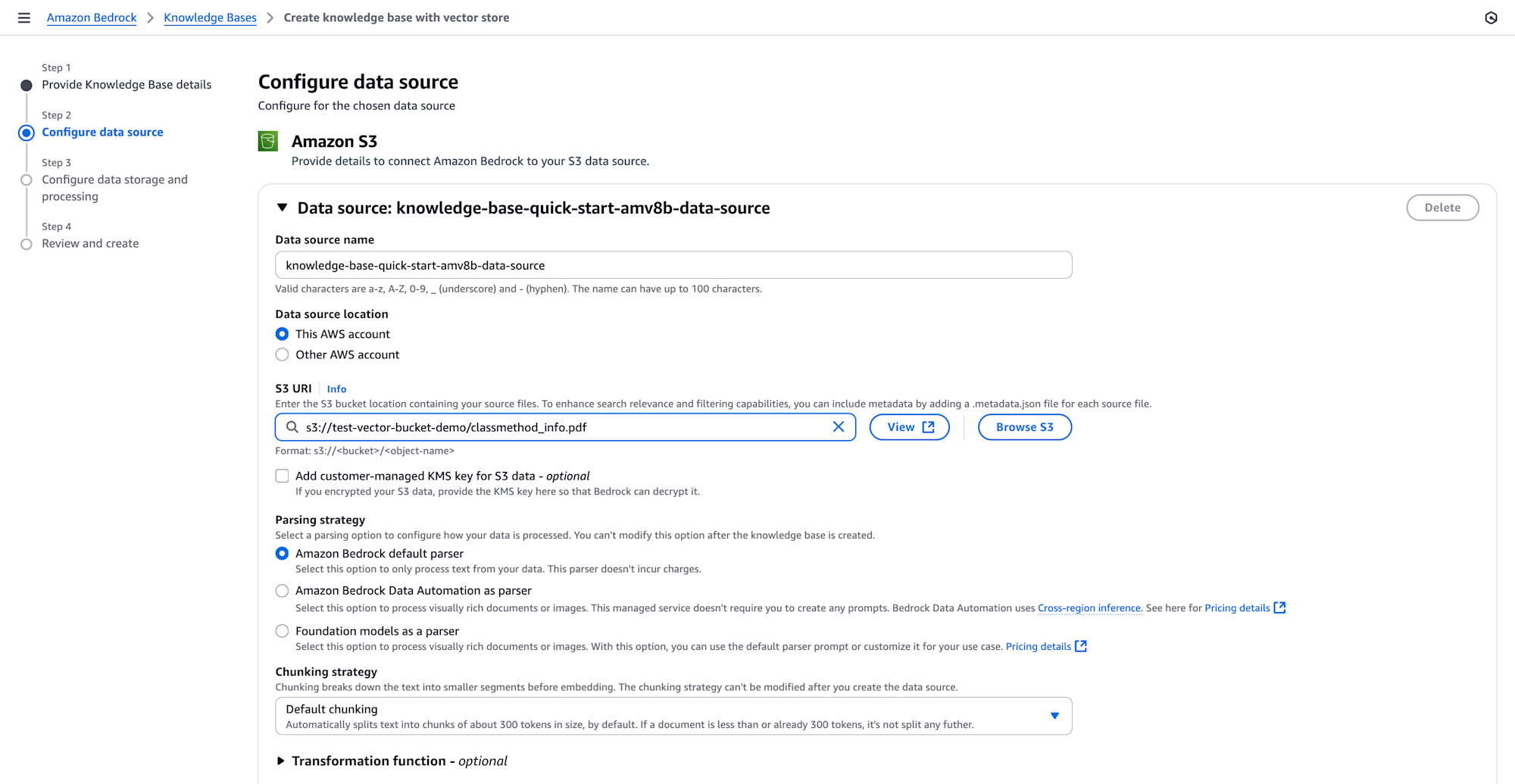
3. Configure the data source
- Assign a descriptive name to your knowledge base data.
- In Data source location, select whether the S3 bucket exists in your current AWS account or another account, then specify the location where your documents are stored.
- Select Amazon Bedrock default parser for text-only documents at no additional cost. Select Amazon Bedrock Data Automation as parser or Foundation models as a parser for processing complex documents with visual elements.
Configure data source and processing
- To configure data storage and processing, first select the embeddings model. The embeddings model will transform your text chunks into numerical vector representations for semantic search capabilities.
- After you have an S3 Vector bucket and index, you can connect it to your knowledge base. You’ll need to provide both the S3 Vector bucket Amazon Resource Name (ARN) and vector index ARN.
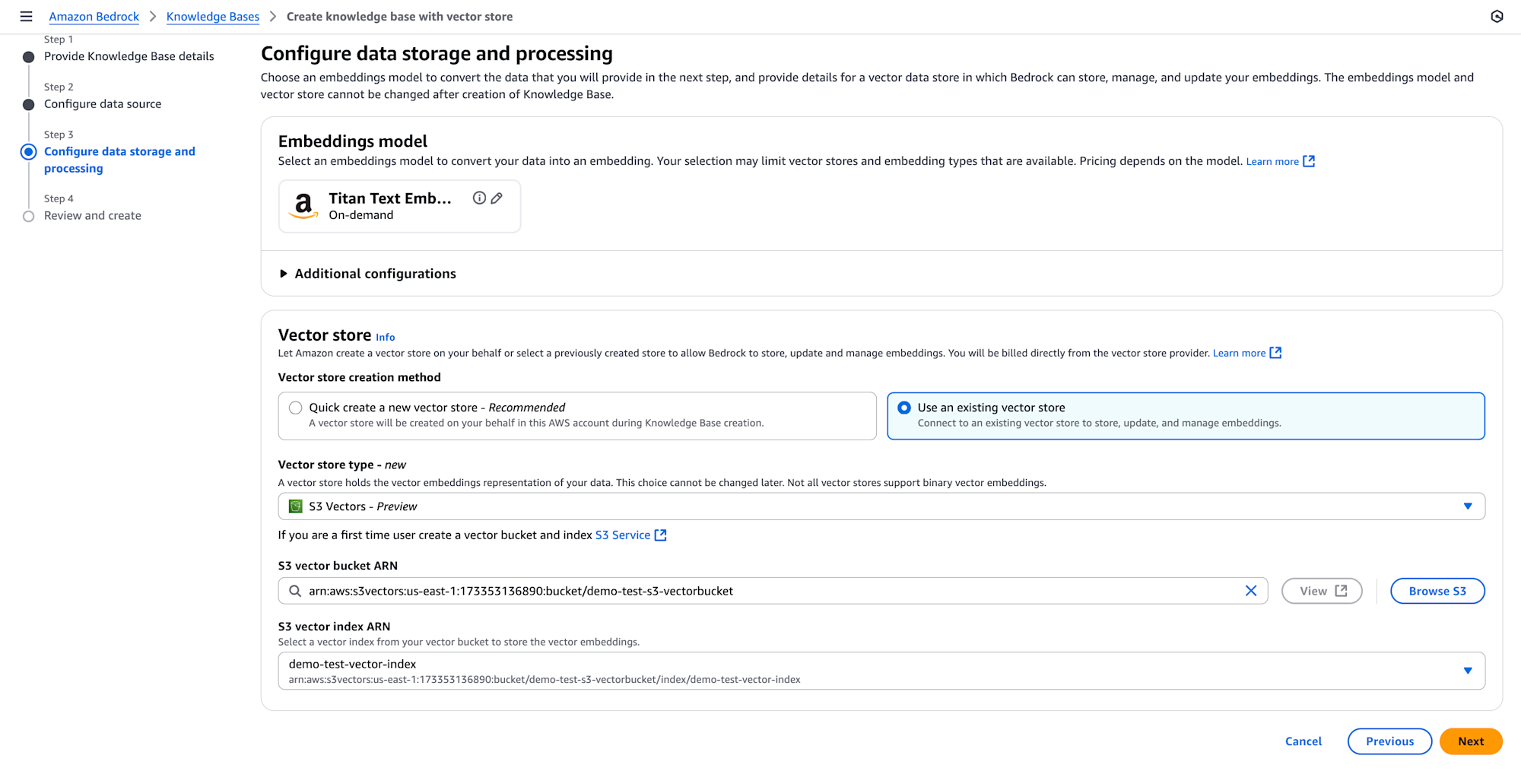
- Finally, preview and choose button Create Knowledge Base.
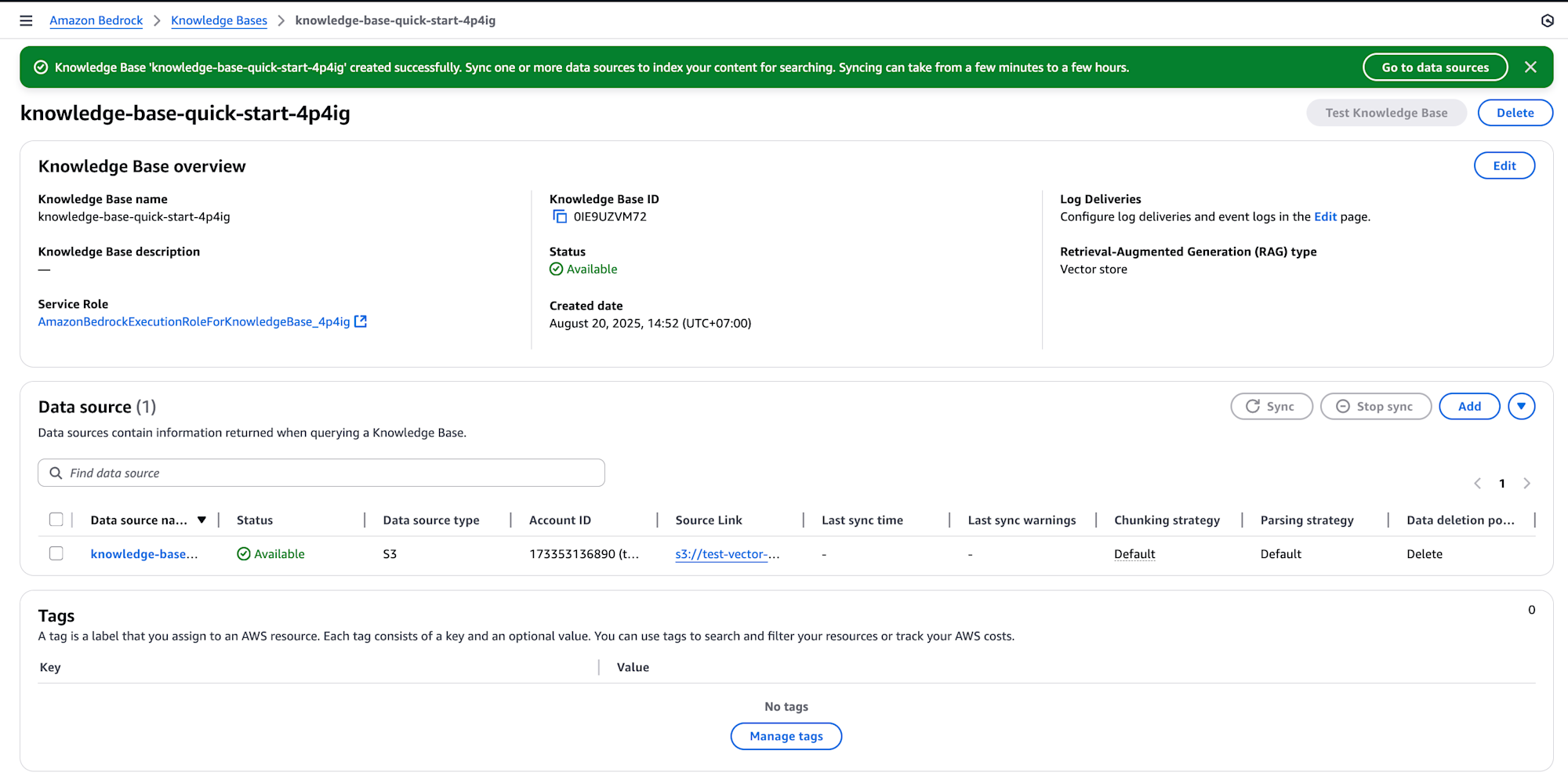
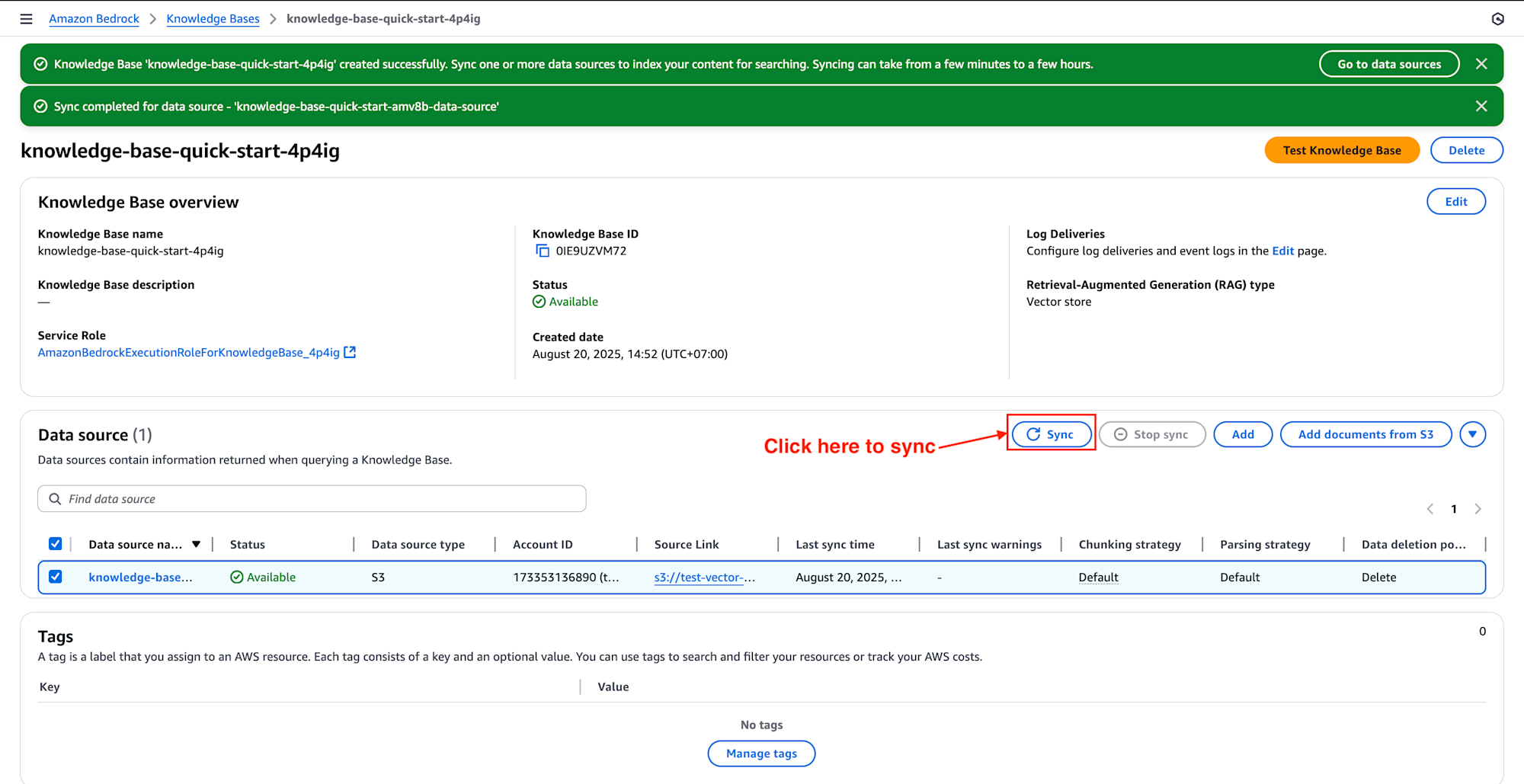
5. Sync the data source
After setting up your knowledge base with S3 Vectors, open it in Amazon Bedrock, select your data source, and click Sync. The system will process documents, generate embeddings with the chosen model, and store them in the S3 vector index.
6. Test the knowledge base
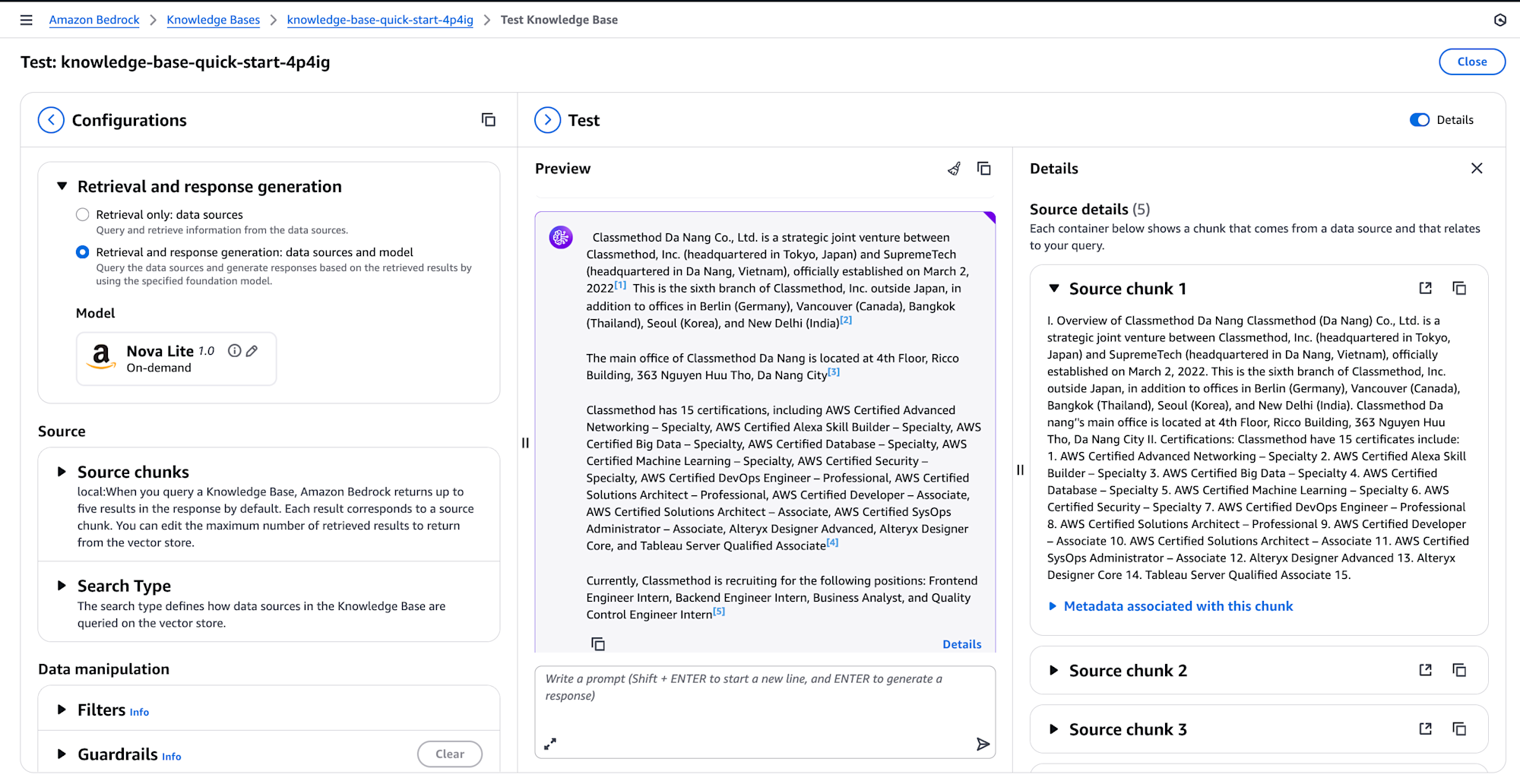
After successfully configuring your knowledge base with S3 Vectors, you can validate its functionality using the built-in testing interface.
The testing interface provides valuable insights into how your knowledge base processes queries, displaying source chunks, their relevance scores, and associated metadata.
7. Clean up resources:
- Delete resource Knowledge Bases
- Delete S3 Vector as a vector store using AWS CLI
aws s3vectors delete-index --vector-bucket-name YOUR_VECTOR_BUCKET_NAME --index-name YOUR_INDEX_NAME --region YOUR_REGION
aws s3vectors delete-vector-bucket --vector-bucket-name YOUR_VECTOR_BUCKET_NAME --region YOUR_REGION
- Delete S3 Bucket as you uploaded for this lab
The Position of S3 Vectors
To position S3 Vectors within the vector database ecosystem, it's essential to analyze its strengths and weaknesses compared to other solutions.
| Technical Characteristic | Amazon S3 Vectors | Dedicated Vector Databases(Pinecone, Weaviate) | Multi-model Databases (PostgreSQL + pgvector) |
|---|---|---|---|
| Cost Model | Based on S3 storage and API calls. Low cost for long-term storage. | Based on compute resources (nodes, pods) running continuously. Higher cost. | Based on database instance compute resources. |
| Scalability | Virtually infinite storage scalability. | Scales with cluster configuration and node count. | Scales with database instance capability. |
| Query Latency | Sub-second latency. Not optimized for real-time workloads. | Ultra-low latency (milliseconds). Optimized for high QPS. | Typically higher than dedicated DBs, depends on indexing. |
| Features | Focuses on core vector storage and search. Supports metadata filtering. | Richer feature set: advanced indexing, clustering, support for more algorithms. | Supports vector queries combined with relational and JSON data. |
| Operational Overhead | Fully-managed. No infrastructure to manage. | Fully-managed (for cloud services) or High operational overhead (for open-source). | Requires management of the database instance. |
Conclusion
Amazon S3 Vectors is not a complete replacement for dedicated vector databases but rather a strategic complementary solution. It fills a gap by providing a cost-effective and scalable vector storage option for workloads that do not require high QPS. Its unique position lies in offering an efficient vector storage platform for large-scale RAG architectures and enabling flexible, tiered data models that balance cost and performance.
With its cost efficiency and scalability, S3 Vectors presents an ideal solution for applications requiring long-term storage and effective querying capabilities, particularly when low-latency and high-query-frequency processing aren't essential.








