
Amazon SageMaker AIのモデルとモデルパッケージの違いについて
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部の鈴木です。
Amazon SageMaker AIは開発した機械学習モデルの管理にモデルやモデルレジストリが用意されています。
SageMaker StudioのJupyterLabなどを使うユーザーは、boto3やSageMaker SDKからこれらのリソースを操作する機会も多いですが、各種SDKから使っていると登場するSageMakerの概念が混乱してしまうように思ったため、今回はモデルとモデルパッケージの違いについて簡単に整理しました。
実用性よりは区別に注目してまとめているので、そんな使い方しないだろといった感想はあるかもしれませんが、理解の助けになれば幸いです。
モデルとモデルパッケージ
SageMakerでは「モデル」を作成することができます。
このモデルは、推論エンドポイントなどにデプロイ可能なように、モデルアーティファクトの場所や実行用のイメージ、リソースへのアクセスに使用されるIAMロールなどの情報をまとめたオブジェクトです。
意外とモデルに関して説明したガイドが少ないように思うのですが、以下のページに記載があります。
このガイドではdeployable modelと表現されています。
モデルはSageMaker StudioおよびSageMaker AIコンソールから確認ができます。
SageMakerでは「モデルパッケージ」という概念もあります。
モデルパッケージはSageMakerモデルレジストリへの登録やAWS Marketplaceへの出品に使用する単位です。
SageMakerの枠組みでMLOpsをしたい場合はモデルパッケージを作成してモデルレジストリへ登録しておくと、バージョンや承認状況の管理ができて効果的です。
特にSageMakerモデルレジストリへバージョン付きで登録した際には「モデルバージョン」とも呼ばれています。
モデルパッケージはSageMaker Studioから確認できます。
モデルはCreateModel APIで作成できます。
モデルパッケージはCreateModelPackage APIで作成できます。
以下のようにモデルからモデルパッケージを作ることで、MLワークロードのコストの大きな割合を占める推論コストにアプローチできるように設計されています。
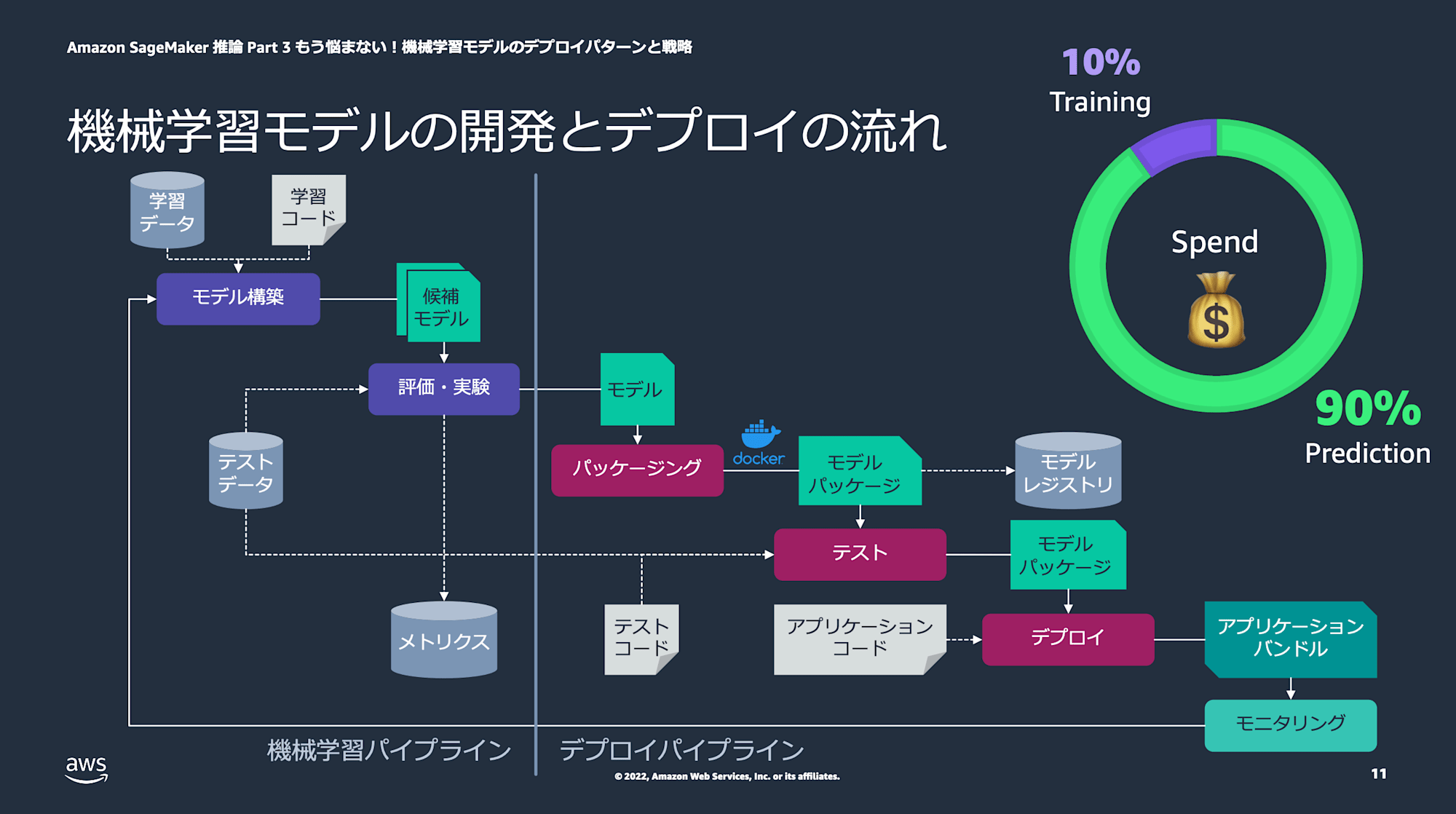
(引用元:ML Enablements Series【ML-Dark-05】)
SageMaker Studioから確認できるモデルとモデルパッケージ
Models画面から確認することができます。
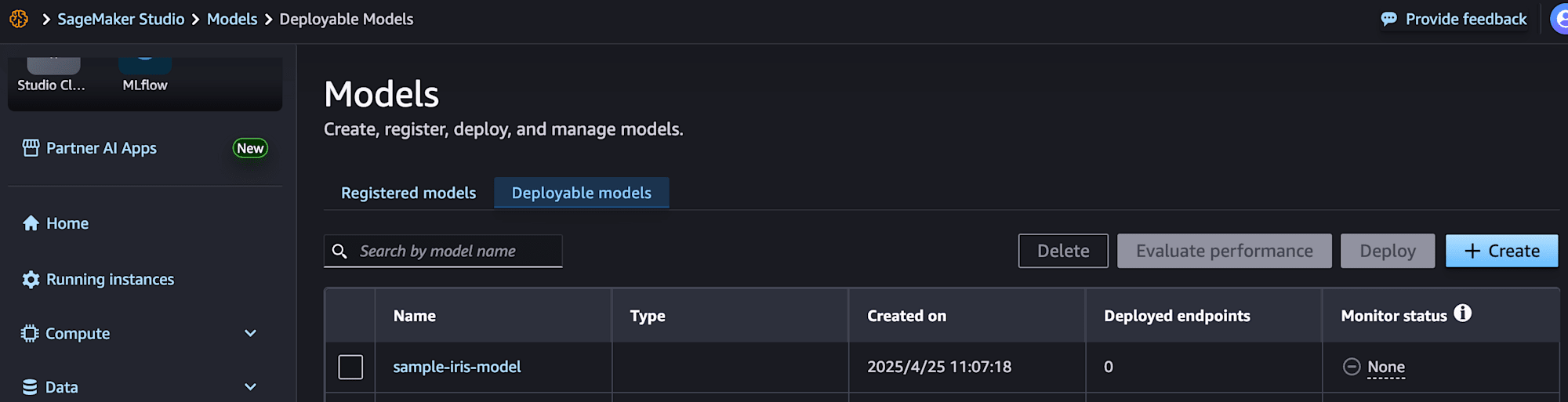
モデルはStudioのDeployable modelsから確認できます。こちらは先のガイドの名称が反映されています。
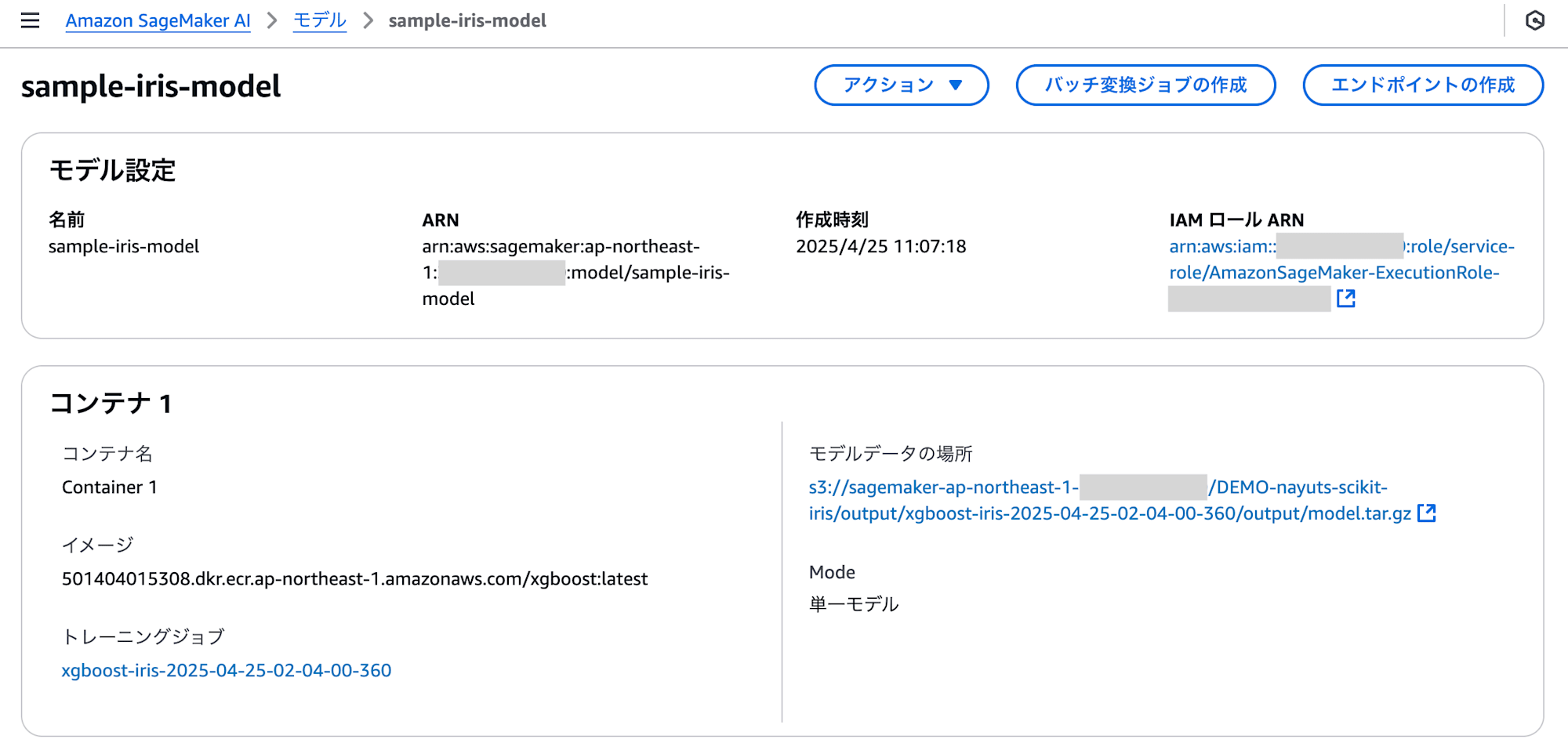
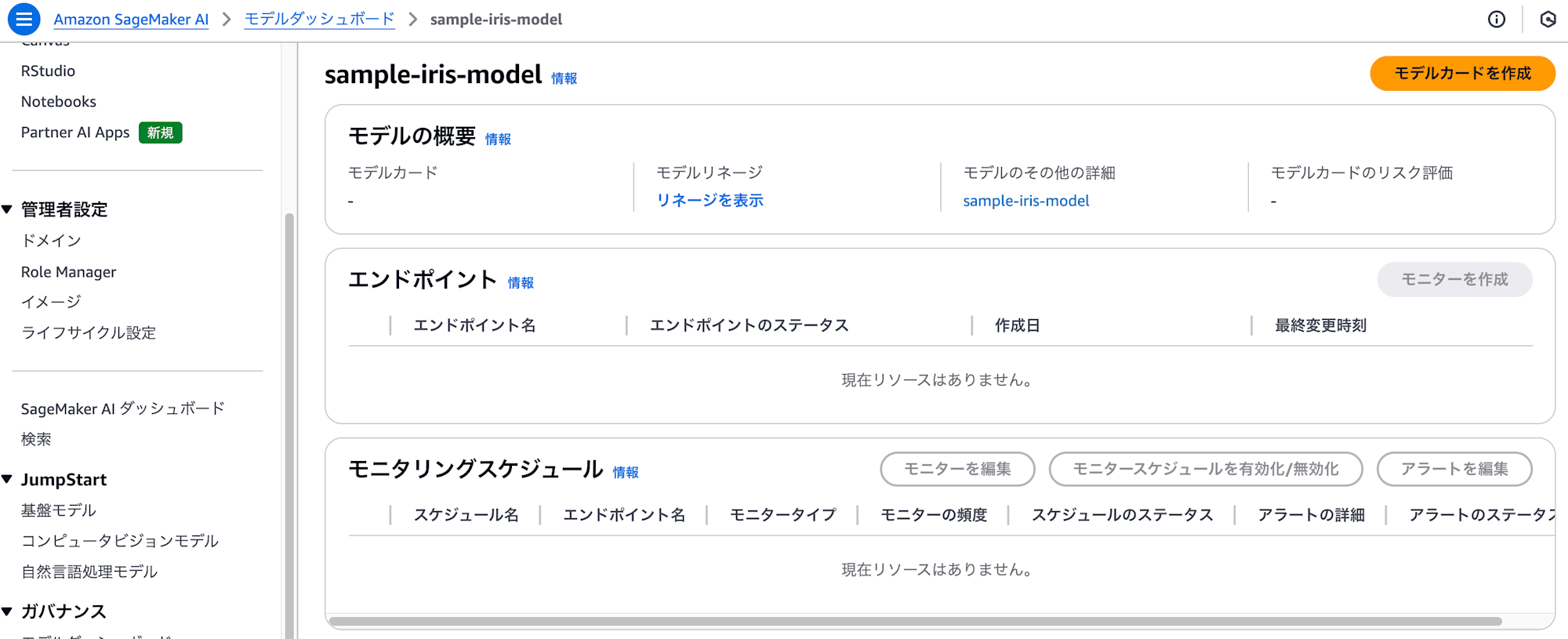
モデルはSageMaker AIコンソールからも確認できます。モデルやモデルダッシュボードに該当のモデルが作成されています。
一方、モデルレジストリに登録されたモデルパッケージはStudioのRegisterd modelsから確認できます。
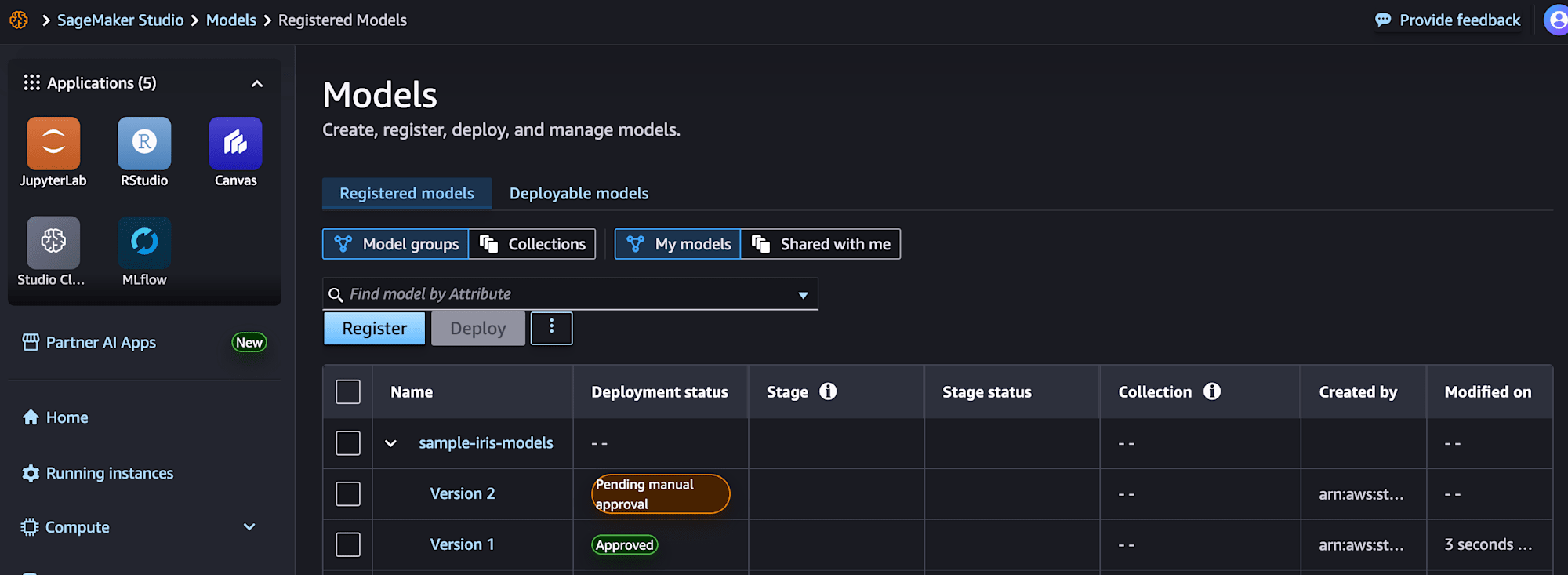
Registerd modelsはモデルグループやコレクションに登録したモデルを確認する、というイメージがよいと思います。
各種SDKからのモデル・モデルパッケージの利用
boto3およびSageMaker SDKからモデルを使った推論の実行についてです。
バッチ推論
モデル名を使い、boto3およびSageMaker SDKともに利用できます。
boto3ではcreate_transform_jobが利用できます。
# 以下の資料より2025/4/22に引用
# https://d1.awsstatic.com/webinars/jp/pdf/services/202208_AWS_Black_Belt_AWS_AIML_Dark_04_inference_part2.pdf
transform_job_name: Final[str] = f'{model_name}TransformJob-{uuid4()}'
print(transform_job_name)
response = sm_client.create_transform_job(
TransformJobName=transform_job_name,
ModelName=model_name,
TransformInput={
'DataSource': {
'S3DataSource': {
'S3DataType': 'S3Prefix',
'S3Uri': f's3://{bucket}/{input_prefix}'
}
},
'ContentType': 'text/csv',
},
TransformOutput={
'S3OutputPath': f's3://{bucket}/{output_prefix}',
'Accept': 'text/csv',
},
TransformResources={
'InstanceType': 'ml.m5.large',
'InstanceCount': 1,
}
)
SageMaker SDKではTransformerが利用できます。
# 以下のガイドより2025/4/22に引用
# https://sagemaker.readthedocs.io/en/v2.39.1/overview.html#sagemaker-batch-transform
transformer = Transformer(model_name='my-previously-trained-model',
instance_count=1,
instance_type='ml.m4.xlarge')
transformer.transform('s3://my-bucket/batch-transform-input')
推論エンドポイント
推論エンドポイントのデプロイはboto3が扱いやすいです。
SageMaker SDKは推論エンドポイントのデプロイにModelインスタンスのdeployメソッドを使うのが一般的と思いますが、モデルからModelインスタンスを作成する方法がなさそうでしたので、一度モデルパッケージを作ってから読み込む形になります。
# 以下のガイドより2025/4/22に引用
# https://sagemaker.readthedocs.io/en/stable/overview.html#consuming-sagemaker-model-packages
import sagemaker
model = sagemaker.ModelPackage(
role='SageMakerRole',
model_package_arn='arn:aws:sagemaker:us-west-2:123456:model-package/my-model-package')
model.deploy(1, 'ml.m4.xlarge', endpoint_name='my-endpoint')
# When you are done using your endpoint
model.sagemaker_session.delete_endpoint('my-endpoint')
推論エンドポイントのデプロイの仕方については以下のガイドにまとまっています。
最後に
Amazon SageMakerのモデルとモデルパッケージについて紹介しました。
参考になりましたら幸いです。








