
Amazon Timestream for InfluxDB のリードレプリカクラスターを試す
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
先日、Amazon Timestream for InfluxDB が リードレプリカをサポートするアナウンスがありました。
これによりマネージドサービスで「マルチ AZ なリードレプリカクラスター」を簡単に作れるようになりました。具体的には次のような構成を作ることができます。
本記事では、リードレプリカクラスターを実際に作りながら詳細を確認していきたいと思います。

リードレプリカの提供形態と料金体系
Timestream for InfluxDB のリードレプリカを利用するには、InfluxDB の開発・提供を行っている InfluxData 社が AWS Marketplace で提供している「レプリカアドオン」をサブスクライブする必要があります。
(Timestream のコンソール画面からサブスクライブすることもできます)
- Marketplace のページ
- 該当ドキュメント
そのため、リードレプリカを利用する場合は次の 2 種類の料金が発生します。
- Marketplace を介したアドオンライセンスの利用料金
- Timestream のレプリカインスタンスの利用料金
Marketplace を介したライセンスアドオンの利用料金
上記に記載した Marketplace のページにライセンスアドオンの料金が掲載されています。
こちらの表を見ると 「レプリカインスタンスで利用している vCPU の時間(1時間単位)」 でアドオン料金が発生するようです。

ライセンス費用が発生する条件
アドオンライセンスの費用が発生するのは次の条件が満たされる場合です。
- アドオンライセンスをサブスクライブしてアクティブな状態になっている
- アクティブなリードレプリカクラスターが存在すること
ライセンスがアクティブであっても、アクティブなリードレプリカクラスターが存在しない場合は料金は発生しません。
(レプリカインスタンスだけ残る場合はインスタンスに対する料金が発生します)
料金について確認できたので、次からは実際にクラスターを作成してみたいと思います。
試してみた
それでは、Timestream のマネージドコンソールよりリードレプリカクラスターを作成してみます。
アドオンをサブスクライブしていない場合は Not subscribed と表示されるので、最初に View subscription option をクリックします。

サブスクリプションの料金詳細が表示されるので、内容を確認して Subscribe をクリックします。

ちなみに、サブスクライブは Marketplace の画面からも実行できます。画面右上にある 「View purchase options」 をクリックします。

料金の詳細が表示されるので、確認して問題なければ 「サブスクライブ」 をクリックします。

サブスクライブが完了するまで数分かかります。

下記のように 「Subscribed」 という表示になれば完了です。

次にデータベースの構成を設定していきます。クラスター名、ユーザー名、組織名、バケット名を設定します。

インスタンスの種類、ストレージを設定します。
今回は検証なので一番小さいものをそれぞれ指定しています。

次に接続設定です。ここではネットワークの設定を行います。
今回は簡単に検証したかったので、既存の VPC にあるパブリックサブネットを指定しています。
また、ここでは2つのサブネットを指定していますが、アベイラビリティゾーンが異なれば3つのサブネットを指定することも可能です。サブネットが複数あっても同じアベイラビリティゾーンのものは指定できません。
サブネットを3つ指定しても、作成されるインスタンスは「プライマリ」「レプリカ」がそれぞれ1台ずつの合計2インスタンスまでです。1つのクラスターに対してレプリカインスタンスを2つ以上作成することはできません。(後から追加もできません)
また、検証のために自分の端末から直接アクセスしたかったので「パブリックアクセス」の項目は 「パブリックアクセス可能」 としています。
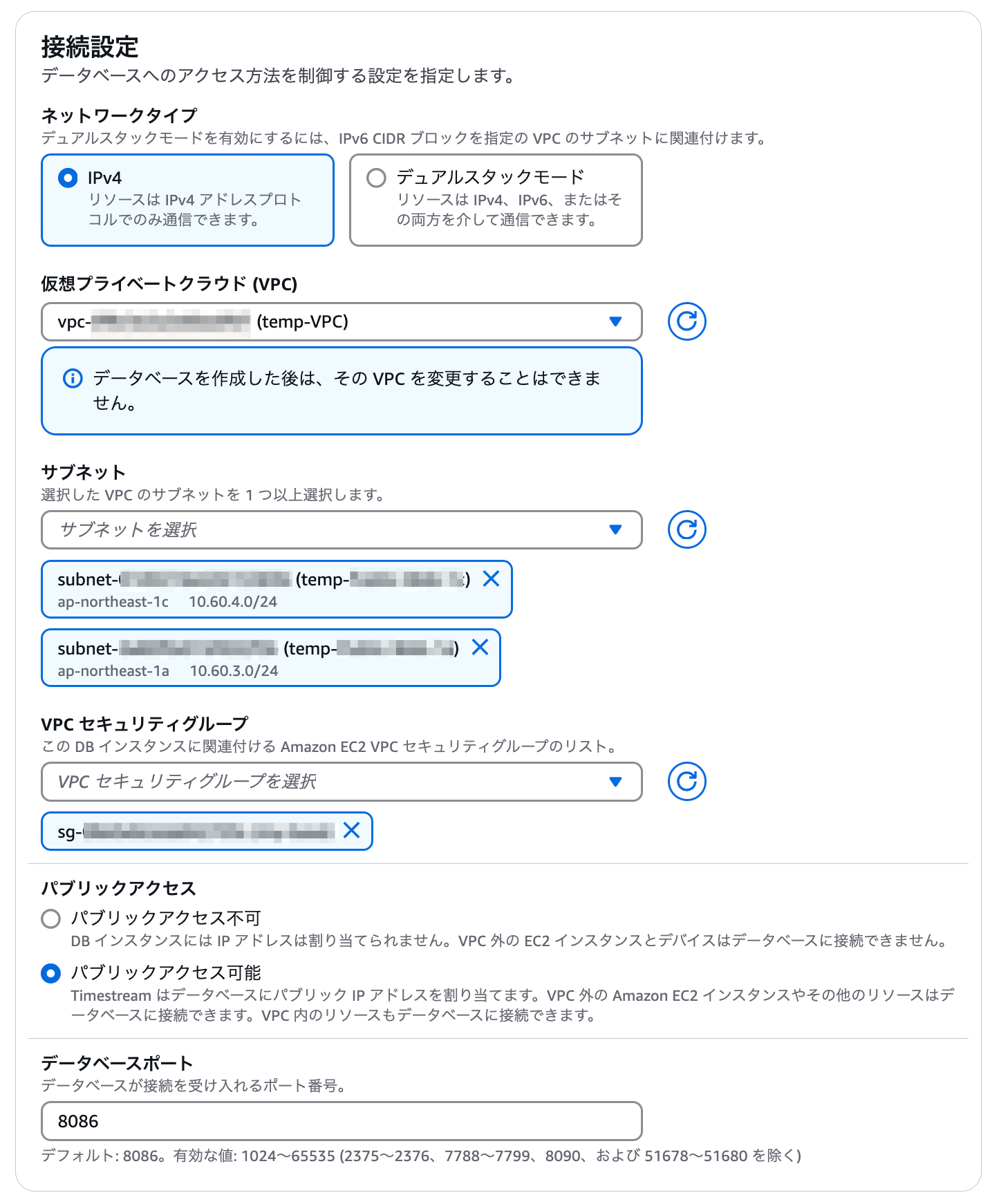
フェイルオーバーの指定は 「Automatic」 を選択しています。

「Automatic」と「NO_FAILOVER」の違い は下記のとおりです。
| フェイルオーバー設定 | 内容 |
|---|---|
| Automatic | プライマリインスタンスに障害が発生した場合、システムは自動的に読み取りレプリカを昇格させて新しいプライマリインスタンスにします。 |
| NO_FAILOVER | プライマリインスタンスに障害が発生した場合、システムは読み取りレプリカを 昇格せずに プライマリインスタンスの復元を試みます。プライマリインスタンスが復元されるまで、クラスターは使用できなくなります。 |
その他はデフォルトのままでデータベースを作成します。

作成できると、画面のようにプライマリーインスタンスとレプリカインスタンスが1つずつ作成されました。

詳細画面を開くと各エンドポイントを確認できます。

エンドポイントの種類
リードレプリカクラスターには、3つのエンドポイントが利用できます。
- クラスターエンドポイント
- リードオンリーエンドポイント
- インスタンスエンドポイント
先ほどのコンソール画面だと、次のような配置になっています。

クラスターエンドポイント
書き込みと読み込みができるエンドポイントです。InfluxDB 固有の管理コマンド(組織、ユーザー、バケット、タスクなどの作成、変更、削除など)を受け付けることができます。
書き込みが可能なインスタンス、つまりプライマリーインスタンスに接続します。
プライマリーインスタンスに障害が発生すると、フェイルオーバーによりリードレプリカがプライマリーに昇格します。書き込むエンドポイントの URL 自体は変わりません。
ただし、プライマリーに昇格した「旧レプリカインスタンスのエンドポイント」は新しいレプリカがデプロイされるまで利用できません。
アクセスする際の URL は次のようなものになります。
(ドキュメントには xxxxx.us-west-2.timestream-influxdb.amazonaws.com という例がありましたがドメインなど大きく異なるようです。)
4fc0xxxxxx-xxxxxxxxxxxxxx.timestream-influxdb.ap-northeast-1.on.aws
リードオンリーエンドポイント
読み取り操作のみをサポートするエンドポイントです。クラスター内の いずれかのレプリカインスタンスに接続 します。
クラスターエンドポイントのホスト名に -ro が付いた URL になります。
4fc0xxxxxx-xxxxxxxxxxxxxx-ro.timestream-influxdb.ap-northeast-1.on.aws
インスタンスエンドポイント
クラスター内の各インスタンス毎に用意されるエンドポイントです。
多くのケースでは参照系リクエストはリードオンリーエンドポイントを指定することになると思われます。
しかし、複雑な負荷分散が必要なワークロードのケースでは、クライアント側で個々のリードレプリカのエンドポイントを直接指定することが考えられます。そのようなケースで活用できるものになります。
c19vxxxxxx-xxxxxxxxxxxxxx.timestream-influxdb.ap-northeast-1.on.aws (プライマリーインスタンス)
uwqexxxxxx-xxxxxxxxxxxxxx.timestream-influxdb.ap-northeast-1.on.aws (レプリカインスタンス)
エンドポイントの名前解決を確認してみる
せっかくなので、名前解決がどうなるかも確認してみました。
| エンドポイント | 名前解決の結果 (パブリックアクセス) |
名前解決の結果 (パブリックアクセス不可) |
|---|---|---|
| クラスターエンドポイント | 35.79.xxx.xxx | 10.60.3.214 |
| リードオンリーエンドポイント | 13.115.xxx.xxx | 10.60.4.220 |
| インスタンスエンドポイント(プライマリーインスタンス) | 35.79.xxx.xxx | 10.60.3.214 |
| インスタンスエンドポイント(レプリカインスタンス) | 13.115.xxx.xxx | 10.60.4.220 |
パブリックアクセス不可の設定で作成すると、指定した VPC サブネットの IP が返ってきます。
この結果から、クラスターエンドポイントがプライマリーインスタンスを指していて、リードオンリーエンドポイントはレプリカインスタンスを指していることが分かります。
ちなみにパブリックアクセス不可のクラスターでは、インターネット経由の名前解決でプライベート IP が返ってきました。
また、パブリック IP アドレスの詳細を確認すると EC2 の情報が返ってきました。
{
"ip": "13.115.xxx.xxx",
"hostname": "ec2-13-115-xxx-xxx.ap-northeast-1.compute.amazonaws.com",
"city": "Tokyo",
"region": "Tokyo",
"country": "JP",
"loc": "35.6895,139.6917",
"org": "AS16509 Amazon.com, Inc.",
"postal": "101-8656",
"timezone": "Asia/Tokyo",
"readme": "https://ipinfo.io/missingauth"
}
これまでの作業で各エンドポイントについて理解できました。あらためてここで全体図を確認すると具体的な利用方法がイメージできるようになるかと思います。
書き込み、読み込みを試してみる
次に各エンドポイントに対してデータの書き込みを試してみます。
influx コマンドの構成情報(コンフィグ)を作成する
今回は influx コマンドで書き込むので、各エンドポイントに対して influx コマンドが参照する構成情報を事前に作成します。
--config-name オプションに各エンドポイントを識別できるコンフィグ名を指定して作成します。
influx config create --config-name [YOUR_CONFIG_NAME] \
--host-url "https://[YOUR_ENDPOINT]:8086" \
--org [YOUR_ORG_NAME] \
--username-password [YOUR_USER_NAME] \
--active
例えば、クラスターエンドポイントの構成情報なら次のような形になります。
influx config create --config-name cluster-endpoint \
--host-url "https://4fc0xxxxxx-xxxxxxxxxxxxxx.timestream-influxdb.ap-northeast-1.on.aws:8086" \
--org cm-org \
--username-password cm-user \
--active
今回はそれぞれ次のようなコンフィグ名にして作成しました。
| エンドポイント種別 | コンフィグ名 |
|---|---|
| クラスターエンドポイント | cluster-endpoint |
| リードオンリーエンドポイント | read-only-endpoint |
| プライマリーインスタンスのエンドポイント | primary-endpoint |
| レプリカインスタンスのエンドポイント | replica-endpoint |
作成したコンフィグは influx config list コマンドで確認できます。* が付いているコンフィグがアクティブなものになります。
$ influx config list
Active Name URL Org
* cluster-endpoint https://4fc0xxxxxx.timestream-influxdb.ap-northeast-1.on.aws:8086 cm-org
read-only-endpoint https://4fc0xxxxxx-ro.timestream-influxdb.ap-northeast-1.on.aws:8086 cm-org
replica-endpoint https://uwqexxxxxx.timestream-influxdb.ap-northeast-1.on.aws:8086 cm-org
primary-endpoint https://c19vxxxxxx.timestream-influxdb.ap-northeast-1.on.aws:8086 cm-org
アクティブなコンフィグの切り替えは influx config [CONFIG_NAME] で行います。
クラスターエンドポイントに書き込む
準備ができたのでデータを書き込みます。最初は「クラスターエンドポイント」です。
influx config cluster-endpoint
influx write \
--bucket cm-test-bucket \
--precision s "
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1743495600
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1743495600
"
特にエラーなく書き込みできました。
リードオンリーエンドポイントに書き込む
次はリードオンリーエンドポイントに書き込みます。
influx config read-only-endpoint
influx write \
--bucket cm-test-bucket \
--precision s "
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1743495700
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1743495700
"
Error: failed to write data: 403 Forbidden: failure writing points: cannot write to org id: 886f87d15db2b7d5, bucket id: 0dd6c3fabf15cd07 because of: read-only
リードオンリーなので書き込みできないというエラーになりました。
各インスタンスエンドポイントに書き込む
先にプライマリーのインスタンスエンドポイントに書き込みます。
influx config primary-endpoint
influx write \
--bucket cm-test-bucket \
--precision s "
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1743495760
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1743495760
"
書き込みできました。
次にレプリカのインスタンスエンドポイントに書き込みます。
influx config replica-endpoint
influx write \
--bucket cm-test-bucket \
--precision s "
home,room=Living\ Room temp=21.1,hum=35.9,co=0i 1743495800
home,room=Kitchen temp=21.0,hum=35.9,co=0i 1743495800
"
Error: failed to write data: 403 Forbidden: failure writing points: cannot write to org id: 886f87d15db2b7d5, bucket id: 0dd6c3fabf15cd07 because of: read-only
リードオンリーエンドポイントと同様に書き込み不可のエラーとなりました。
いずれも予想通りの結果になりました。
参照クエリを実行する
いずれのエンドポイントもデータの参照は可能です。そのため、全てのエンドポイントに次のようなクエリを投げてデータを取得できます。
influx query 'from(bucket:"cm-test-bucket")
|> range(start: 1743494500, stop: 1743495800)
|> filter(fn: (r) => r._measurement == "home")
|> filter(fn: (r) => r.room == "Kitchen")
|> filter(fn: (r) => r._field == "temp" or r._field == "hum")
|> keep(columns: ["_time", "_value", "_field", "_measurement", "room"])'
出力結果の抜粋です。
Result: _result
Table: keys: [_field, _measurement, room]
_field:string _measurement:string room:string _time:time _value:float
---------------------- ---------------------- ---------------------- ------------------------------ ----------------------------
hum home Kitchen 2025-04-01T08:01:42.000000000Z 36.4338
hum home Kitchen 2025-04-01T08:01:47.000000000Z 36.011
hum home Kitchen 2025-04-01T08:01:52.000000000Z 37.5992
Table: keys: [_field, _measurement, room]
_field:string _measurement:string room:string _time:time _value:float
---------------------- ---------------------- ---------------------- ------------------------------ ----------------------------
temp home Kitchen 2025-04-01T08:01:42.000000000Z 22.1952
temp home Kitchen 2025-04-01T08:01:47.000000000Z 22.0049
temp home Kitchen 2025-04-01T08:01:52.000000000Z 22.7197
マルチ AZ 構成との比較
Timestream for InfluxDB は従来から「マルチ AZ」構成で作成できましたが、リードレプリカクラスターとの違いは何でしょうか。確認できたポイントを表にまとめました。
| 確認事項 | マルチ AZ 構成 | リードレプリカクラスター |
|---|---|---|
| 各インスタンスの利用 | スタンバイインスタンスは読み書き不可 | インスタンス種別に読み書き可能 |
| 利用料金 | 2インスタンス分の料金 | 2インスタンス分の料金 + サブスクリプション料金 |
| 構成変更 | マルチ AZ、シングル AZ の双方の構成に変更可能 インスタンスタイプの変更可能 |
インスタンス構成は変更不可 インスタンスタイプの変更可能 |
| 書き込み同期性(※) | 同期書き込み | 非同期書き込み |
どちらもメリット・デメリットがあるので、コストや利用するワークロードをよく考慮して選定する必要がありそうです。
※) セカンダリインスタンスへの書き込みの同期性については下記のドキュメントを参考にしています。
サブスクリプションの解約
サブスクリプションを解除する場合は、Marketplace のページにある 「サブスクリプションの管理」 から行います。
管理ページにはサブスクライブした全てのリソースを確認できるので、対象のリソースに対して 「管理」 をクリックします。

アクションから 「サブスクリプションをキャンセル」 をクリックします。
(クラスター自体を削除しておけばサブスクリプションはそのままでもアドオンライセンス自体の料金は発生しません)

クラスターの削除
クラスターを削除する時は、対象を選択して 「削除」 を実行します。
なお、クラスターから単一のノードだけを削除することはできません。削除時はクラスター全体が削除されることに注意してください。

最後に
今回のアップデートで InfluxDB のリードレプリカを気軽に構成できるようになりました。
しかし、リードレプリカのインスタンスは1つしか作成できないので、読み取りのスケーリングが必要なケースでは慎重にアーキテクチャを設計する必要がありそうです。
IoT 導入支援 / 相談会の紹介
クラスメソッドでは、AWS を中心とした IoT 導入においてエッジからクラウドまでトータルでサポートしています。
次のようなお困りごとがあれば、お気軽にお問い合わせください。
- ローカルでデータ収集と可視化はできたが、クラウドで可視化する適切な構成が分からない
- 集めたデータを使って故障予知などに使いたい
- 工場設備からデータ収集してクラウドに送る方法が分からない
- スマートファクトリー化を検討しているが何から着手していいか分からない
- デバイスで動くアプリケーションの開発を AWS で効率化したい
- エッジデバイスのセキュリティが心配だ
- カメラ映像をクラウドにストリーミングして活用したい
- その他、お困り事があれば何でもご相談ください









