
Amazon Timestreamでユーザー定義のパーティションを試してみた
ユーザー定義のパーティションを試してみました。
2025.05.23
Amazon Timestreamではユーザー定義のパーティションが設定できます。
本記事では、CloudFormationでAmazon Timestreamのユーザー定義パーティションを設定し、大量データを用いたクエリを試してみました。なお、ユーザー定義パーティションは、テーブル作成時のみ設定可能です。
おすすめの方
- タイトルについて知りたい方
- Amazon Timestreamにboto3でデータを書き込みたい方
- Amazon Timestreamのクエリサンプルを知りたい方
Amazon TimestreamをCloudFormationで作成する
テンプレートファイル
パーティションは、Schema部分で定義します。本記事では、次のDimensionを指定します。
- deviceId
cfn.yml
AWSTemplateFormatVersion: "2010-09-09"
Description: Amazon Timestream Many Data Sample use Partition Key
Resources:
TimestreamDatabase:
Type: AWS::Timestream::Database
Properties:
DatabaseName: ManyDataSampleUsePartitionKeyDatabase
TimestreamTable:
Type: AWS::Timestream::Table
Properties:
DatabaseName: !Ref TimestreamDatabase
TableName: many-data-sample-use-partition-key-table
Schema:
CompositePartitionKey:
- Name: deviceId
Type: DIMENSION
EnforcementInRecord: REQUIRED
RetentionProperties:
MemoryStoreRetentionPeriodInHours: 168 # 7 days
MagneticStoreRetentionPeriodInDays: 1825 # 5 year
MagneticStoreWriteProperties:
EnableMagneticStoreWrites: true # マグネティックストアへの書き込みを有効にする
デプロイ
aws cloudformation deploy \
--template-file cfn.yaml \
--stack-name Amazon-Timestream-Many-Data-Sample-use-Partition-Key-Stack
Amazon Timestreamに約473万件のデータを書き込む
本記事のお試しデータ
3つのデバイスがあり、それぞれに6つのセンサーが存在する構成とします。各センサーは、温度と湿度を計測できます。
- デバイス1
- センサー1
- センサー2
- センサー3
- センサー4
- センサー5
- センサー6
- デバイス2
- センサー1
- センサー2
- センサー3
- センサー4
- センサー5
- センサー6
- デバイス3
- センサー1
- センサー2
- センサー3
- センサー4
- センサー5
- センサー6
それぞれのセンサーから、10分毎に5年間、データを受信した想定です。つまり、データ件数は4730400です。
- 3 x 6 x 6 x 24 x 365 x 5 = 4730400
データのサンプル
{
"Dimensions": [
{
"Name": "deviceId",
"Value": "device0001",
"DimensionValueType": "VARCHAR"
},
{
"Name": "sensorId",
"Value": "sensor0001",
"DimensionValueType": "VARCHAR"
}
],
"MeasureValueType": "MULTI",
"MeasureName": "sensorData",
"Time": "1745798400000",
"TimeUnit": "MILLISECONDS",
"MeasureValues": [
{
"Name": "temperature",
"Value": "25.8",
"Type": "DOUBLE"
},
{
"Name": "humidity",
"Value": "14.1",
"Type": "DOUBLE"
}
]
}
スクリプト
それぞれのセンサーごとに5年分のデータを作成し、Amazon Timestreamに書き込みます。
import boto3
import random
import json
from datetime import datetime, timedelta, timezone
from botocore.exceptions import ClientError
TIMESTREAM_DATABASE_NAME = "ManyDataSampleUsePartitionKeyDatabase"
TIMESTREAM_TABLE_NAME = "many-data-sample-use-partition-key-table"
client = boto3.client("timestream-write")
def main():
JST = timezone(timedelta(hours=9), "JST")
base_datatime = datetime(2025, 5, 23, 9, 0, 0, tzinfo=JST)
base_unixtime = int(base_datatime.timestamp() * 1000)
records = []
# デバイス1〜3
for device_number in range(1, 4):
# センサー1〜6
for sensor_number in range(1, 7):
# 5年分のデータ(10分毎)
for count in range(6 * 24 * 365 * 5):
records.append(
make_record(
base_unixtime - count * 10 * 60 * 1000, # 10分毎にする
f"device{device_number:04d}",
f"sensor{sensor_number:04d}",
round(random.uniform(0, 40), 1), # 温度の乱数
round(random.uniform(0, 100), 1), # 湿度の乱数
)
)
# Timestreamに書き込む(書き込み制限が最大100件のため、分割している)
for i in range(0, len(records), 100):
write_records(
TIMESTREAM_DATABASE_NAME,
TIMESTREAM_TABLE_NAME,
records[i : i + 100],
)
def make_record(unixtime, device_id, sensor_id, temperature, humidity):
return {
"Dimensions": [
{"Name": "deviceId", "Value": device_id, "DimensionValueType": "VARCHAR"},
{"Name": "sensorId", "Value": sensor_id, "DimensionValueType": "VARCHAR"},
],
"MeasureValueType": "MULTI", # マルチメジャーレコード
"MeasureName": "sensorData",
"Time": str(unixtime),
"TimeUnit": "MILLISECONDS",
"MeasureValues": [
{
"Name": "temperature",
"Value": str(temperature),
"Type": "DOUBLE",
},
{
"Name": "humidity",
"Value": str(humidity),
"Type": "DOUBLE",
},
],
}
def write_records(database_name, table_name, records):
try:
resp = client.write_records(
DatabaseName=database_name,
TableName=table_name,
Records=records,
)
except ClientError as e:
if e.response["Error"]["Code"] == "RejectedRecordsException":
print(e.response["Error"]["Message"])
print(json.dumps(e.response["RejectedRecords"], indent=2))
else:
print(f"error: {e}")
raise e
# print(resp)
if __name__ == "__main__":
main()
スクリプトを実行する
約1時間12分ほど掛かりました。IAMロールの最大セッション時間が1時間の場合は、変更しておきましょう。元の値に戻すのも忘れずに。
$ time python app.py
python app.py 752.37s user 96.52s system 19% cpu 1:12:37.91 total
Amazon Timestreamで検索する
参考までに3回実施して持続時間とスキャンされたバイト数も記載します。あくまでも参考です。
すべてのデータ件数を取得する
SELECT COUNT(*) AS total_records
FROM "ManyDataSampleUsePartitionKeyDatabase"."many-data-sample-use-partition-key-table"
- 持続時間
- 6.021 秒
- 3.445 秒
- 2.485 秒
- スキャンされたバイト数
- 198.50 MB
期待通りの件数でした。

クエリインサイトの結果は下記です。

デバイス1のデータ件数を取得する
SELECT COUNT(*) AS total_records
FROM "ManyDataSampleUsePartitionKeyDatabase"."many-data-sample-use-partition-key-table"
WHERE deviceId='device0001'
- 持続時間
- 2.224 秒
- 2.026 秒
- 1.122 秒
- スキャンされたバイト数
- 66.17 MB
期待通りの件数(全件の1/3)です。

クエリインサイトの結果は下記です。

デバイス1のセンサーごとに最新データの値を取得する
SELECT deviceId, sensorId,
MAX_BY(time, time) AS latest_timestamp,
MAX_BY(temperature, time) AS latest_temperature,
MAX_BY(humidity, time) AS latest_humidity
FROM "ManyDataSampleUsePartitionKeyDatabase"."many-data-sample-use-partition-key-table"
WHERE deviceId='device0001'
GROUP BY deviceId, sensorId
ORDER BY latest_timestamp DESC, deviceId ASC, sensorId ASC
- 持続時間
- 4.016 秒
- 3.992 秒
- 3.089 秒
- スキャンされたバイト数
- 66.17 MB
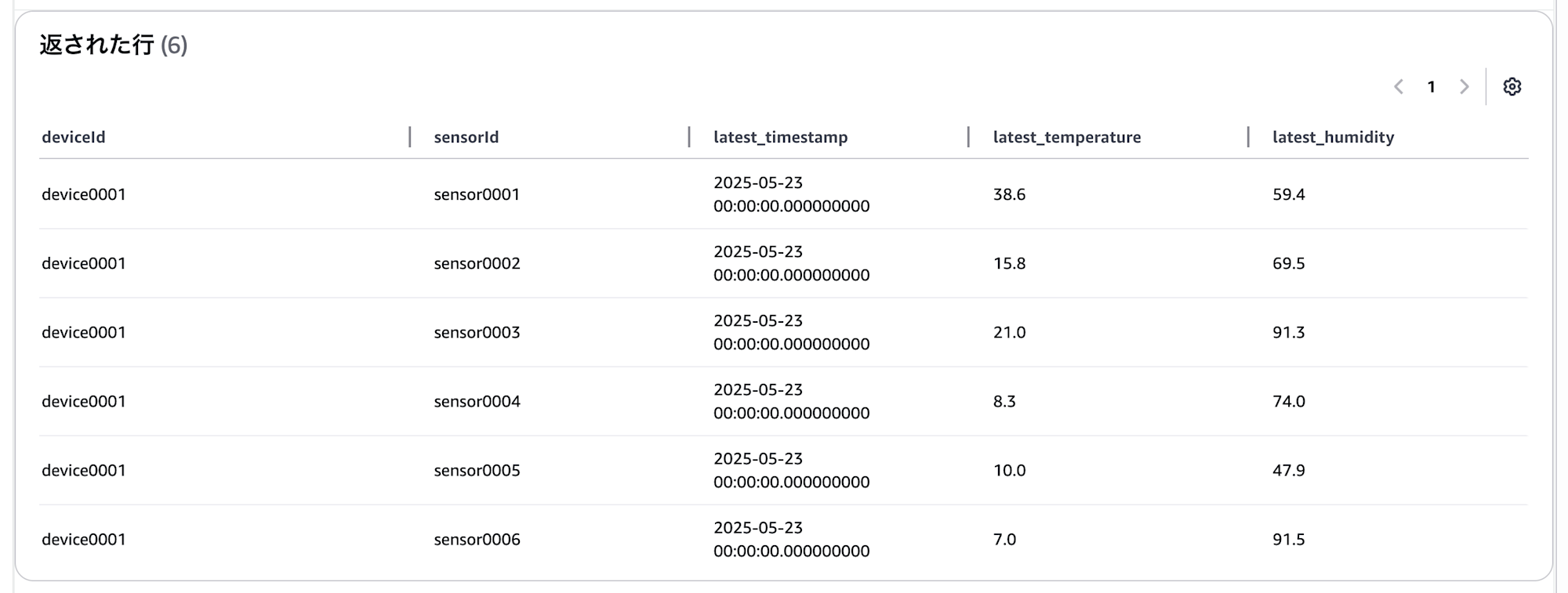
クエリインサイトの結果は下記です。

デバイス1のセンサーごとに、過去30日間における最大値・最小値・平均値を取得する
SELECT deviceId, sensorId,
MAX(temperature) AS temperature_max,
MIN(temperature) AS temperature_min,
ROUND(AVG(temperature), 1) AS temperature_avg,
MAX(humidity) AS humidity_max,
MIN(humidity) AS humidity_min,
ROUND(AVG(humidity), 1) AS humidity_avg
FROM "ManyDataSampleUsePartitionKeyDatabase"."many-data-sample-use-partition-key-table"
WHERE deviceId='device0001' AND time >= ago(30day)
GROUP BY deviceId, sensorId
ORDER BY deviceId ASC, sensorId ASC
- 持続時間
- 1.348 秒
- 1.475 秒
- 0.3430 秒
- スキャンされたバイト数
- 1.07 MB
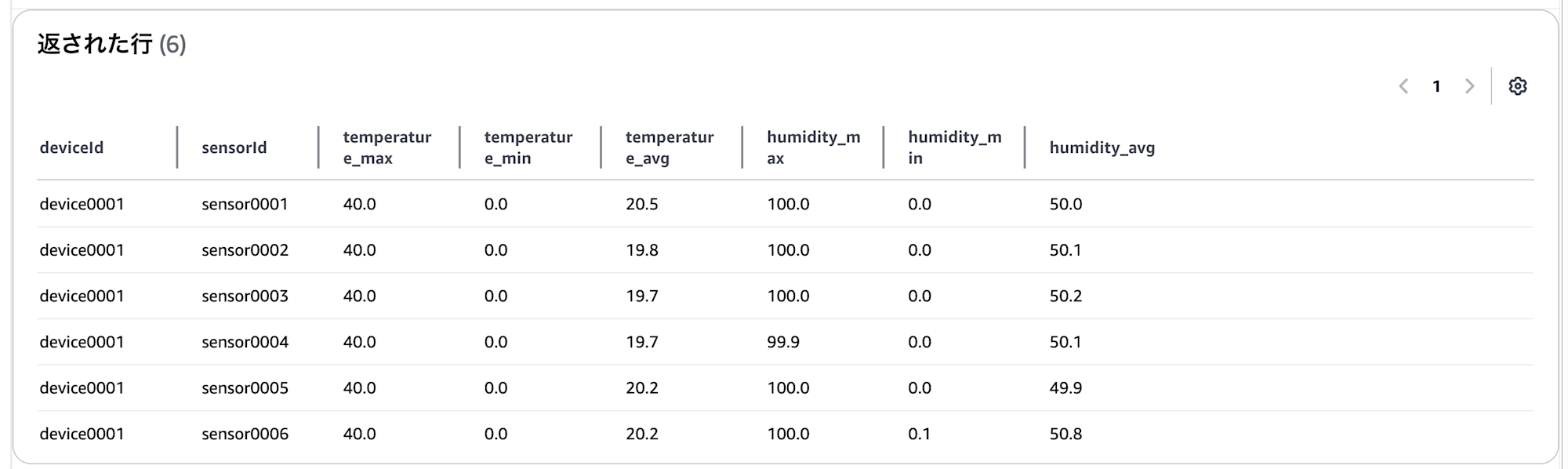
クエリインサイトの結果は下記です。

さいごに
「デバイス1の〜」とした場合、以前と比べると、スキャンされたバイト数が1/3になっていました。これがユーザー定義パーティションの効果ですね。
ただし、デフォルトの「measure_name」に対するパーティションはなくなります。measure_nameを利用するかユーザー定義パーティションを利用するかは、事前にしっかりと検討・設計したいです。
参考
- クエリパフォーマンスの最適化につながる Amazon Timestream の顧客定義パーティションキー機能 | Amazon Web Services ブログ
- AWS::Timestream::Table - AWS CloudFormation
- AWS::Timestream::Table Schema - AWS CloudFormation
- AWS::Timestream::Table PartitionKey - AWS CloudFormation
- Amazon Timestream でのデータアクセスの最適化 - Amazon Timestream
- Amazon Timestreamとは何者か、そして速度が出なくて悩んでいる人へ #AWSreInvent | DevelopersIO
- ユーザー定義のパーティションキーの制限 - Amazon Timestream
- Amazon Timestreamに約473万件のデータを書き込んだり、検索をしてみた | DevelopersIO







