
Apache Iceberg の CoW と MoR 〜 データの読み取りと書き込みのパフォーマンスのバランスを取るための2つの戦略
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。今日は Apache Iceberg のデータの読み取りと書き込みのパフォーマンスのバランスを取るための2つの主要な戦略、MoR(Merge-on-Read)とCoW(Copy-on-Write)、Amazon AthenaとAWSの Glueのサポート状況について解説します。
Apache Iceberg と同様、OTF(Open Table Format)であるDelta LakeとApache HudiもMoR(Merge-on-Read)とCoW(Copy-on-Write)の両方をサポートしています。
CoW と MoR とは
Apache Icebergは、データの更新、削除、マージを処理するための2つの主要な戦略、MoR(Merge-on-Read)とCoW(Copy-on-Write)をサポートしています。これらの戦略は、データの読み取りと書き込みのパフォーマンスのバランスを取るために使用されます。
CoW(Copy-on-Write)
CoWは、Icebergのデフォルトの戦略です。
- データの更新や削除が発生すると、影響を受けるデータファイル全体が書き直されます。
- 読み取り性能が優れていますが、書き込み操作にはより多くの時間とコンピューティングリソースが必要です。
- 日次バッチロードなど、同じテーブルパーティション内で更新が集中する使用ケースに適しています。
MoR(Merge-on-Read)
MoRは、Iceberg v2で導入された戦略です。
- データの更新や削除時に、既存のファイルは変更せず、新しいファイルのみが追加されます。
- 書き込み増幅を回避し、更新操作が高速になります。
- 読み取り時にデータのマージが必要となるため、読み取り性能は若干低下する可能性があります。
- 頻繁な書き込みや更新が行われるテーブルに適しています。
CoW と MoR の選択のポイント
CoWとMoRの相違点
CoWとMoRの相違点を比較表にまとめました。CoWとMoRはそれぞれ読み取りと書き込みでトレードオフの関係にあることが分かります。
| 比較項目 | Copy-on-Write (CoW) | Merge-on-Read (MoR) |
|---|---|---|
| パフォーマンス | ・読み取りが高速 ・書き込みが遅い |
・書き込みが高速 ・読み取りが若干遅い |
| リソース消費 | 書き込み時により多くのコンピューティングリソースを使用 | 読み取り時により多くの処理が必要 |
| ファイル操作 | 更新時にファイル全体を書き直す | ・更新時に新しいファイルを追加 ・読み取り時にマージする |
CoW と MoR の選択基準
データのアクセスの要件に応じて、読み取り重視ならCoW、書き込み重視ならMoRを選択することをお勧めします。ユースケースに応じて最適なパフォーマンスを実現するためにテーブルごとにCoWとMoRを適切に組み合わせることができます。
MoR: 頻繁な更新が必要な場合
-
ストリーミングデータ処理
- IoTデバイスからのリアルタイムデータストリーム
- オンラインプラットフォームからの継続的なイベントデータ
-
頻繁な更新が必要なデータ
- ユーザープロファイル情報
- リアルタイムの分析ダッシボード
CoW: 読み取り性能が重要な場合
- 読み取り重視のワークロード
- データウェアハウスの分析クエリ
- ビジネスインテリジェンスレポート
- 履歴データの分析
- 大規模な一括更新
- 日次バッチジョブ
- 定期的なデータアーカイブ
- 履歴データの分析
CoW と MoR のサポート状況
Amazon Athena
Amazon Athena はIceberg v2テーブルですが、MoR(Merge-on-Read)方式のみをサポートです。AthenaはMoR(Merge-on-Read)方式を採用することで、Icebergテーブルに対して比較的低コストでの更新操作を実現しています。ただし、読み取り性能はCoW(Copy-on-Write)方式と比べて若干低下する可能性があることに注意が必要です。
AWS Glue
AWS Glue 4.0以降は、Iceberg のMerge-on-Read(MoR)とCoW(Copy-on-Write)の両方をサポートしています。
-
デフォルトの動作
Glue では、デフォルトでMerge-on-Read(MoR)方式が使用されます。
-
設定の柔軟性
テーブルプロパティを使用して、MoRとCoWを柔軟に設定できます。更新、削除、マージなどの操作ごとに異なる戦略を設定することが可能です。
-
設定方法
テーブル作成時またはALTER TABLE文を使用して、以下のプロパティを設定できます。
write.delete.modewrite.update.modewrite.merge.mode
-
自動コンパクション
AWS Glueは、MoRとCoW両方のテーブルに対して自動コンパクション機能を提供しています。小さなファイルの問題を軽減し、クエリパフォーマンスを向上させることができます。
-
Change Data Capture (CDC)クエリ
現時点では、CDCクエリ機能はCoWテーブルのみでサポートされています。MoRテーブルではまだサポートされていません。
AWS Glueにおける CoW と MoR の設定方法
Icebergでは、テーブルプロパティを使用してCoWとMoRを柔軟に設定できます。MoRは、特定の操作(更新、削除、マージ)ごとに異なる戦略を設定することも可能です。
この例では、削除操作にMoR、更新操作にCoW、マージ操作にMoRを使用するようにテーブルを設定しています。
CREATE TABLE my_table (
-- columns
) USING iceberg
TBLPROPERTIES (
'format-version' = '2',
'write.delete.mode'='merge-on-read',
'write.update.mode'='copy-on-write',
'write.merge.mode'='merge-on-read'
);
AWS Glueを用いて動作を確認する
MoRのテーブルの作成
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.conf import SparkConf
from awsglue.job import Job
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# sc = SparkContext()
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
def build_spark_session_s3i(catalog_name, warehouse_path):
spark = SparkSession.builder \
.config("spark.sql.warehouse.dir", warehouse_path) \
.config(f"spark.sql.catalog.{catalog_name}", "org.apache.iceberg.spark.SparkCatalog") \
.config(f"spark.sql.catalog.{catalog_name}.warehouse", warehouse_path) \
.config(f"spark.sql.catalog.{catalog_name}.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog") \
.config(f"spark.sql.catalog.{catalog_name}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.getOrCreate()
return(spark)
# Create Spark Session for Iceberg Tables on Glue
i_catalog_name = "glue_catalog"
i_bucket_name = "cm-datalaker-20241222"
i_bucket_prefix = "customer_mor"
i_database_name = "ssb_iceberg"
i_table_name = "customer_mor"
i_warehouse_path = f"s3://{i_bucket_name}/{i_bucket_prefix}"
spark_s3t = build_spark_session_s3i(i_catalog_name, i_warehouse_path)
# Dynamic Frame from catalog
customer = glueContext.create_dynamic_frame.from_catalog(
database="ssb",
table_name="customer",
transformation_ctx="customer",
)
df = customer.toDF()
spark_s3t.sql(f"""
DROP TABLE IF EXISTS {i_catalog_name}.{i_database_name}.{i_table_name} PURGE
""")
spark_s3t.sql(f"""
CREATE TABLE IF NOT EXISTS {i_catalog_name}.{i_database_name}.{i_table_name} (
c_custkey INT,
c_name VARCHAR(25),
c_address VARCHAR(25),
c_city VARCHAR(10),
c_nation VARCHAR(15),
c_region VARCHAR(12),
c_phone VARCHAR(15),
c_mktsegment VARCHAR(10)
) USING iceberg
TBLPROPERTIES (
'format-version' = '2',
'write.delete.mode'='merge-on-read',
'write.update.mode'='merge-on-read',
'write.merge.mode'='merge-on-read'
)
""")
# Insert records into Iceberg table
df.createOrReplaceTempView("tmp_customer")
spark_s3t.sql(f"""
INSERT INTO {i_catalog_name}.{i_database_name}.{i_table_name}
SELECT * FROM tmp_customer LIMIT 1
""")
# Insert records into Iceberg table
spark_s3t.sql(f"""
INSERT INTO {i_catalog_name}.{i_database_name}.{i_table_name}
(c_custkey, c_name, c_address, c_city, c_nation, c_region, c_phone, c_mktsegment)
VALUES(999999, 'ishikawa', 'cyuou-ku', 'sapporo', 'japan', 'hokkaido', '+81120-999-9999', 'consulting');
""")
df_out = spark_s3t.sql(f"""
SELECT * FROM {i_catalog_name}.{i_database_name}.{i_table_name}
""")
df_out.show()
上記のプログラムを実行すると、S3バケットに以下のオブジェクト作成されました。
$ aws s3 ls s3://cm-datalaker-20241222/customer_mor/ --recursive
2024-12-26 14:10:32 2472 customer_mor/ssb_iceberg.db/customer_mor/data/00000-45-e087bba9-4aff-414c-a5e0-4b214f4eb710-0-00001.parquet
2024-12-26 14:10:34 2296 customer_mor/ssb_iceberg.db/customer_mor/data/00000-46-34874481-1279-4d83-be75-e3067aa28c67-0-00001.parquet
2024-12-26 14:10:27 1804 customer_mor/ssb_iceberg.db/customer_mor/metadata/00000-251a720a-6a96-4a20-931e-caf3380420b3.metadata.json
2024-12-26 14:10:33 3140 customer_mor/ssb_iceberg.db/customer_mor/metadata/00001-58aa5e8d-68d3-451e-89a5-e22def4f4178.metadata.json
2024-12-26 14:10:34 4420 customer_mor/ssb_iceberg.db/customer_mor/metadata/00002-245e4253-b09e-466c-85a1-44eb11b9e203.metadata.json
2024-12-26 14:10:33 7167 customer_mor/ssb_iceberg.db/customer_mor/metadata/d1fa31dd-5c3c-427e-9e41-53b48617823e-m0.avro
2024-12-26 14:10:34 7156 customer_mor/ssb_iceberg.db/customer_mor/metadata/dac44df0-45e7-4533-80ed-d25dc01585d2-m0.avro
2024-12-26 14:10:33 4462 customer_mor/ssb_iceberg.db/customer_mor/metadata/snap-2540419391968118460-1-d1fa31dd-5c3c-427e-9e41-53b48617823e.avro
2024-12-26 14:10:34 4533 customer_mor/ssb_iceberg.db/customer_mor/metadata/snap-3169351705552154663-1-dac44df0-45e7-4533-80ed-d25dc01585d2.avro
CoWのテーブルを作成する
上記のソースの2箇所を書き換えます。
# Create Spark Session for Iceberg Tables on Glue
i_catalog_name = "glue_catalog"
i_bucket_name = "cm-datalaker-20241222"
i_bucket_prefix = "customer_cow"
i_database_name = "ssb_iceberg"
i_table_name = "customer_cow"
spark_s3t.sql(f"""
CREATE TABLE IF NOT EXISTS {i_catalog_name}.{i_database_name}.{i_table_name} (
c_custkey INT,
c_name VARCHAR(25),
c_address VARCHAR(25),
c_city VARCHAR(10),
c_nation VARCHAR(15),
c_region VARCHAR(12),
c_phone VARCHAR(15),
c_mktsegment VARCHAR(10)
) USING iceberg
TBLPROPERTIES (
'format-version' = '2'
)
""")
上記のプログラムを実行すると、S3バケットに以下のオブジェクト作成されました。
$ aws s3 ls s3://cm-datalaker-20241222/customer_cow/ --recursive
2024-12-26 14:13:40 2472 customer_cow/ssb_iceberg.db/customer_cow/data/00000-45-be4cc0e8-804c-4dd8-bffd-099f61e6d8d5-0-00001.parquet
2024-12-26 14:13:42 2296 customer_cow/ssb_iceberg.db/customer_cow/data/00000-46-56fcdf6c-a9f9-455c-95d0-1b5040f19bc0-0-00001.parquet
2024-12-26 14:13:34 1676 customer_cow/ssb_iceberg.db/customer_cow/metadata/00000-bd5c835e-3170-474e-b8a5-1dadf98b84d8.metadata.json
2024-12-26 14:13:41 3012 customer_cow/ssb_iceberg.db/customer_cow/metadata/00001-0d833e9c-5bcf-497d-8bcb-5726edffbca3.metadata.json
2024-12-26 14:13:42 4292 customer_cow/ssb_iceberg.db/customer_cow/metadata/00002-041db8e1-6d52-4319-9f1c-57ccffe18fac.metadata.json
2024-12-26 14:13:41 7168 customer_cow/ssb_iceberg.db/customer_cow/metadata/2212145e-eac0-4be3-952d-be5230594ce0-m0.avro
2024-12-26 14:13:42 7155 customer_cow/ssb_iceberg.db/customer_cow/metadata/b6c8a55e-9625-4f9d-aac8-6d8bc5f7590d-m0.avro
2024-12-26 14:13:42 4537 customer_cow/ssb_iceberg.db/customer_cow/metadata/snap-2450668046527973273-1-b6c8a55e-9625-4f9d-aac8-6d8bc5f7590d.avro
2024-12-26 14:13:41 4462 customer_cow/ssb_iceberg.db/customer_cow/metadata/snap-2977425690441395316-1-2212145e-eac0-4be3-952d-be5230594ce0.avro
MoRとCoWのメタ情報の比較
Icebergのメタ情報を確認します。MoRの方は、propertiesに以下の3つのプロパティを設定したため、それぞれMoRになります。
write.delete.mode- merge-on-read
write.update.mode- merge-on-read
write.merge.mode- merge-on-read
$ aws s3 cp s3://cm-datalaker-20241222/customer_mor/ssb_iceberg.db/customer_mor/metadata/00002-245e4253-b09e-466c-85a1-44eb11b9e203.metadata.json -
{
"format-version" : 2,
"table-uuid" : "1f7d4e5c-23ad-495e-b126-f5bbff60c89e",
"location" : "s3://cm-datalaker-20241222/customer_mor/ssb_iceberg.db/customer_mor",
"last-sequence-number" : 2,
"last-updated-ms" : 1735222233847,
"last-column-id" : 8,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "c_custkey",
"required" : false,
"type" : "int"
}, {
:
(中略)
:
"id" : 8,
"name" : "c_mktsegment",
"required" : false,
"type" : "string"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "hadoop",
"write.merge.mode" : "merge-on-read",
"write.update.mode" : "merge-on-read",
"write.delete.mode" : "merge-on-read",
"write.parquet.compression-codec" : "zstd"
},
:
(中略)
:
"metadata-file" : "s3://cm-datalaker-20241222/customer_mor/ssb_iceberg.db/customer_mor/metadata/00001-58aa5e8d-68d3-451e-89a5-e22def4f4178.metadata.json"
} ]
}
一方、CoWの方は、propertiesに指定していないので、デフォルトのCoWになります。
$ aws s3 cp s3://cm-datalaker-20241222/customer_cow/ssb_iceberg.db/customer_cow/metadata/00002-041db8e1-6d52-4319-9f1c-57ccffe18fac.metadata.json -
{
"format-version" : 2,
"table-uuid" : "744ac4b9-f05e-4bcf-8e0b-aa096d63afd9",
"location" : "s3://cm-datalaker-20241222/customer_cow/ssb_iceberg.db/customer_cow",
"last-sequence-number" : 2,
"last-updated-ms" : 1735222421663,
"last-column-id" : 8,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "c_custkey",
"required" : false,
"type" : "int"
}, {
:
(中略)
:
"id" : 8,
"name" : "c_mktsegment",
"required" : false,
"type" : "string"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "hadoop",
"write.parquet.compression-codec" : "zstd"
},
:
(中略)
:
"metadata-file" : "s3://cm-datalaker-20241222/customer_cow/ssb_iceberg.db/customer_cow/metadata/00001-0d833e9c-5bcf-497d-8bcb-5726edffbca3.metadata.json"
} ]
}[cloudshell-user@ip-10-132-45-104 ~]$
補足: S3 TablesもMoRに対応
上記の検証は、S3バケット上にIcebergテーブルを作成して、ファイルの中身を確認しました。S3 Tablesは、オブジェクトの中を確認することはできませんでしたが、同様の検証を行い、MoRでエラーにならないことを確認しました。
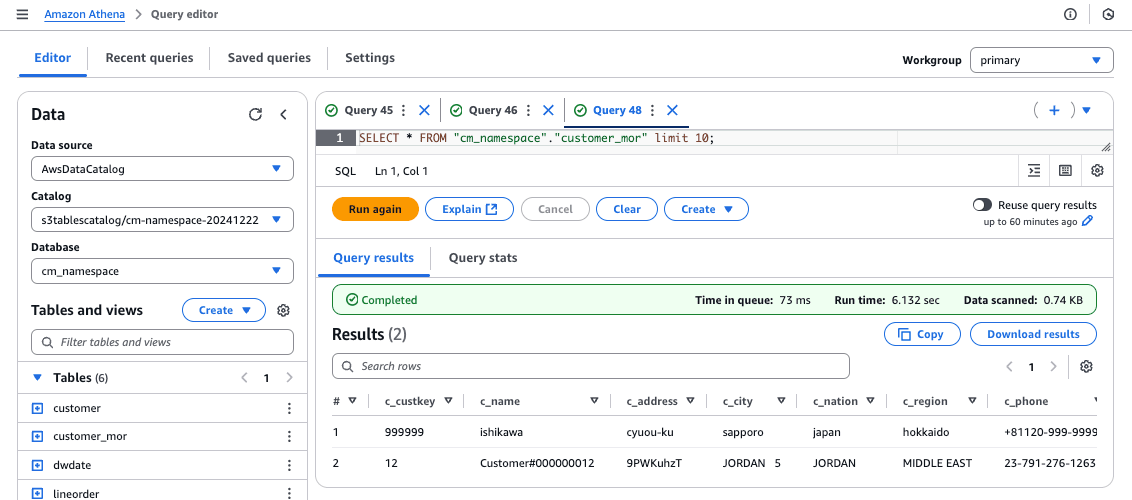
補足: Amazon AthenaからMoRのテーブルを参照可能
Amazon Athenaは、CoWのみのサポートになりますが、MoRのテーブルを参照することが可能でした。
最後に
Apache Icebergのデータ管理戦略であるMoR(Merge-on-Read)とCoW(Copy-on-Write)は、CoWは読み取り性能に優れ、MoRは書き込み性能に優れているため、ユースケースに応じて適切な戦略を選択することが重要です。
Amazon AthenaはMoRのみをサポートしていますが、AWS Glue 4.0以降は両方の戦略をサポートし、テーブルプロパティを通じて柔軟な設定が可能です。データアクセスのパターンや頻度、更新の性質を考慮し、CoWとMoRを適切に組み合わせることで、ビジネス要件に最適なパフォーマンスを実現できます。
さらに、AWS Glueの自動コンパクション機能を活用することで、小さなファイルの問題を軽減し、クエリパフォーマンスを向上させることができます。Apache Icebergの戦略を理解し、適切に活用することで、データレイクの効率的な管理と高性能なデータ処理が可能となります。
合わせて読みたい










