Apache SparkのORCとフィルタプッシュダウンのバグを発見してOSSに貢献した話
はじめに
クラウド事業本部サービス開発室の伊藤です。
私が所属するチームでは、弊社が提供するAWS総合支援サービス「クラスメソッドメンバーズ」の請求システムを開発・運用しています。
5,000社以上、35,000アカウントを超える導入実績がある本サービスで、すべてのお客様のご利用金額を毎日計算しています。
大量データの処理には、分散処理フレームワーク Apache Spark を採用しています。
今回、運用中にApache Sparkの挙動にバグを発見し、チームでコミュニティに貢献することができました。

本記事では、バグの内容・原因・修正プロセスを詳しく解説します。
Apache Sparkとは
こちらが公式ページです。
下記はAIによるApache Sparkの解説です。
Apache Spark(アパッチ・スパーク)は、ビッグデータの処理と分析に用いられるオープンソースの並列分散処理フレームワークです。
主な特徴は以下の通りです。
- 高速性: データをインメモリ(メモリ上)で処理する機能を持ち、従来のディスクベースの処理(例:Hadoop MapReduce)に比べて、多くの場合非常に高速に動作します。
- 多機能性: バッチ処理だけでなく、リアルタイムのストリーム処理、SQLクエリ、機械学習(MLlib)、グラフ処理(GraphX)など、複数のワークロードを単一の統合エンジンでサポートします。これにより、様々なデータ分析タスクを効率的に実行できます。
- 使いやすさ: Python (PySpark)、Java、Scala、Rといった複数のプログラミング言語に対応したAPIを提供しており、開発者が分散処理の複雑さを意識せずにアプリケーションを構築しやすくなっています。
簡単に言えば、Apache Sparkは「大量のデータを、速く、柔軟に処理・分析するための強力なツール」です。
GitHubのスター数は42K(2025年10月現在)で、並列分散処理フレームワークのデファクトスタンダードと言えると思います。
バグの内容
こちらが実際にバグとして報告した内容です。
以下のような内容となっています。
問題の概要
ORCファイルから作成したDataFrameに対して、eqNullSafe(<=>、null安全等価演算子)を用いたフィルタ処理を行うと、null値を含む行が本来残るべきにもかかわらず除外されてしまい正しく動作しません。
Parquetファイルでは同じ処理で期待通りの結果が得られます。また、ORCのフィルタプッシュダウンを無効化すると、ORCでも正しく動作します。
詳細な説明
再現手順
- 以下のようなデータを持つDataFrame(ORCファイルから作成)を用意します。
+---+----+-------------------+
| id|name| email|
+---+----+-------------------+
| 1|test| null|
| 2|null|example@example.com|
+---+----+-------------------+
- このDataFrame(df)に対し、次のフィルタ処理を実行します。
df.filter(!(col("name") <=> "dummy"))
- 期待される結果は以下の通り、全ての行が残ることです。
+---+----+-------------------+
| id|name| email|
+---+----+-------------------+
| 1|test| null|
| 2|null|example@example.com|
+---+----+-------------------+
- 実際の結果では、
nameがnullの行が除外されてしまいます。
+---+----+-------------------+
| id|name| email|
+---+----+-------------------+
| 1|test| null|
+---+----+-------------------+
追加情報
-
Parquetファイルから作成したDataFrameでは、同じフィルタ処理で期待通りの結果が得られます。
-
ORCのフィルタプッシュダウン(
spark.sql.orc.filterPushdown)を無効化すると、ORCでも正しい結果になります。 -
ORCとParquetでPhysical Plan(物理実行計画)は同じです。
どちらの形式でも、NOT (name <=> dummy)という条件がDataFiltersおよびPushedFiltersとしてプランに現れます。ORCのPhysical Plan
== Physical Plan == *(1) Filter NOT (name#36 <=> dummy) +- *(1) ColumnarToRow +- FileScan orc [id#35,name#36,email#37] Batched: true, DataFilters: [NOT (name#36 <=> dummy)], Format: ORC, Location: InMemoryFileIndex(1 paths)[file:/***/spark-null-safe/data/null_safe_..., PartitionFilters: [], PushedFilters: [Not(EqualNullSafe(name,dummy))], ReadSchema: struct<id:int,name:string,email:string>ParquetのPhysical Plan
== Physical Plan == *(1) Filter NOT (name#42 <=> dummy) +- *(1) ColumnarToRow +- FileScan parquet [id#41,name#42,email#43] Batched: true, DataFilters: [NOT (name#42 <=> dummy)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[file:/***/spark-null-safe/data/null_safe_..., PartitionFilters: [], PushedFilters: [Not(EqualNullSafe(name,dummy))], ReadSchema: struct<id:int,name:string,email:string>このように、物理的なクエリプランは同じにもかかわらず、ORCのみで誤ったフィルタ結果となります。
検証用コード
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.SparkSession
object NullSafeTest {
private val projectDir = new java.io.File(".").getCanonicalPath
private val dataPath = f"$projectDir/data/null_safe_test"
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("NullSafeTest")
.master("local[*]")
// .config("spark.sql.orc.filterPushdown", "false") // ORC works as expected without filter pushdown
.getOrCreate()
import spark.implicits._
val df = Seq(
(1, "test", null),
(2, null, "example@example.com")
).toDF("id", "name", "email")
df.show()
df.write.mode("overwrite").orc(s"$dataPath/orc")
df.write.mode("overwrite").parquet(s"$dataPath/parquet")
val orcDf = spark.read.orc(s"$dataPath/orc")
val parquetDf = spark.read.parquet(s"$dataPath/parquet")
val filteredOrcDf = orcDf.filter(!(col("name") <=> "dummy"))
filteredOrcDf.show()
filteredOrcDf.explain("extended")
val filteredParquetDf = parquetDf.filter(!(col("name") <=> "dummy"))
filteredParquetDf.show()
filteredParquetDf.explain("extended")
spark.stop()
}
}
まとめ
- ORCファイル+フィルタプッシュダウン有効時、
eqNullSafe(<=>)を使ったフィルタ処理で、null値を含む行が意図せず除外される問題です。 - Parquetや、ORCのフィルタプッシュダウン無効時は問題ありません。
- ORCのフィルタプッシュダウンによるnull値の扱いにバグがある可能性があります。
なかなかに致命的なバグかと思います。
報告先でも 優先度: Critical のラベルが付けられました。
原因
根本的な原因はSpark側ではなく、ORCフォーマットの方にあったようです。
ORCのGitHubリポジトリにissueが作成されました。
下記が本issueの修正PRです。
ORCの仕様
修正されたコードを確認する前に、まずORCの仕様について簡単に説明します。
一つのORCファイルは、効率的なデータアクセスを実現するために以下のような階層的な構造を持っています。
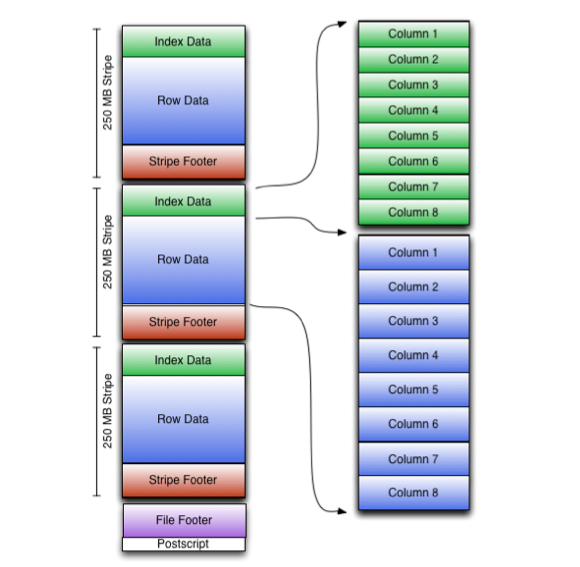
ORCファイル
├── Stripe(ストライプ)
│ ├── Index Data(インデックスデータ)
│ ├── Row Data(行データ)
│ └── Stripe Footer(ストライプフッター)
├── Stripe
│ ├── Index Data
│ ├── Row Data
│ └── Stripe Footer
├── ...
├── File Footer(ファイルフッター)
└── Postscript(ポストスクリプト)
また、ORCファイルは3段階のインデックス(統計情報)を持っています。
- ファイルレベル: ファイル全体における各列の値に関する統計情報
- ストライプレベル: 各ストライプにおける各列の値に関する統計情報
- 行レベル: ストライプ内の10,000行ごとのセットにおける各列の値に関する統計情報
各統計情報には次のようなデータが含まれます。
- 値の有無
- NULL値の有無
- 最小値と最大値 など
ファイルレベルとストライプレベルのインデックスはORCファイルのファイルフッターに含まれ、行レベルのインデックスはストライプ内のインデックスデータに含まれます。
さらに、ストライプ内のインデックスデータは、行データの情報を10,000行ごとのグループとして保持します。
ストライプ(例: 250MB、100万行)
│
├── Index Data ← ここに「複数の行グループの統計情報」が格納される
│ ├── 行グループ 0の統計(行 0 ~ 9,999)
│ ├── 行グループ 1の統計(行 10,000 ~ 19,999)
│ ├── 行グループ 2の統計(行 20,000 ~ 29,999)
│ └── ...(行グループ 99まで)
│
├── Row Data ← ここに「実際のデータ全体」が格納される
│ └── 100万行分のデータ
│
└── Stripe Footer
この構造により、以下のような読み取りフローで効率的にデータを読み込むことができます。
1. ポストスクリプトを読む(ファイルフッターの位置を確認)
↓
2. ファイルフッターを読む
└── ファイル全体の統計で不要なら終了
↓
3. 必要なストライプのストライプフッターを読む
└── ストライプの統計で不要ならスキップ
↓
4. インデックスデータを読む(行グループの統計)
└── 行グループの統計で不要ならスキップ
↓
5. 必要な行データのみ読む
└── 必要なカラムのみ読む
詳細は公式ドキュメントで説明されています。
PRでの修正内容
PRでの修正差分は下記のようになっています。
static TruthValue evaluatePredicateRange(PredicateLeaf predicate,
ValueRange range,
BloomFilter bloomFilter,
boolean useUTCTimestamp) {
// 省略
if (!range.hasValues()) {
if (predicate.getOperator() == PredicateLeaf.Operator.IS_NULL) {
return TruthValue.YES;
+ } else if (predicate.getOperator() == PredicateLeaf.Operator.NULL_SAFE_EQUALS) {
+ Object literal = predicate.getLiteral();
+ if (literal == null) {
+ return TruthValue.YES;
+ } else {
+ return TruthValue.NO;
+ }
} else {
return TruthValue.NULL;
}
} else if (!range.isComparable()) {
return range.hasNulls ? TruthValue.YES_NO_NULL : TruthValue.YES_NO;
}
// 省略
}
最初に if (!range.hasValues()) の判定がありますが、この ValueRange range 変数が 特定行グループの特定列の統計情報 を持っています。
わかりやすく抜き出すと ValueRange クラスは以下のようになっています。
これが range 変数が持っている行グループの統計情報です。
static class ValueRange<T extends Comparable> {
final Comparable lower; // 最小値
final Comparable upper; // 最大値
final boolean onlyLowerBound; // 下限のみが提供されているか
final boolean onlyUpperBound; // 上限のみが提供されているか
final boolean hasNulls; // NULL値が含まれているか
final boolean hasValue; // 値が存在するか
final boolean comparable; // 比較可能か
}
つまり、下記のようなORCの行グループがあった場合、name 列の値はすべて null のため range.hasValues() は false となります。
+---+----+-------------------+
| id|name| email|
+---+----+-------------------+
| 1|null|hoge001@example.com|
| 2|null|hoge002@example.com|
| 3|null|hoge003@example.com|
+---+----+-------------------+
よって if (!range.hasValues()) 内の処理に進みますが、修正前のコードでは NULL_SAFE_EQUALS オペレータの比較が漏れており、必ず TruthValue.NULL が返るようになっています(ここがバグでした)。
その結果、行グループの指定列が全て null の場合は <=> でフィルタしようとすると必ず結果が TruthValue.NULL となってしまいます。
TruthValue.NULL が返される場合は、Hive側の isNeeded() メソッドの実装で false が返されます。
フィルタプッシュダウンが有効な場合、下記の実装で行グループを読み込むか否か判定します。
関連する処理のみ抜き出すと下記のようになります。
isNeeded() メソッドで行グループの読み込みを判定しています。
/**
* 各行グループに対してフィルタ(述語)プッシュダウンを評価し、
* 読み込むべき行グループを判定する
*
* @param stripe ストライプ情報
* @param indexes 行グループごとの統計情報インデックス
* @param bloomFilterKinds ブルームフィルタの種類
* @param encodings カラムのエンコーディング情報
* @param bloomFilterIndices ブルームフィルタインデックス
* @param returnNone 全行グループがスキップされた場合にREAD_NO_RGSを返すか
* @return 各行グループを読み込むかどうかのboolean配列
*/
public boolean[] pickRowGroups(StripeInformation stripe,
OrcProto.RowIndex[] indexes,
OrcProto.Stream.Kind[] bloomFilterKinds,
List<OrcProto.ColumnEncoding> encodings,
OrcProto.BloomFilterIndex[] bloomFilterIndices,
boolean returnNone) throws IOException {
// 結果配列: true = 行グループを読み込む, false = スキップ
boolean[] result = new boolean[groupsInStripe];
// 各述語リーフの評価結果を格納する配列
TruthValue[] leafValues = new TruthValue[sargLeaves.size()];
// 各行グループに対して述語を評価
for (int rowGroup = 0; rowGroup < result.length; ++rowGroup) {
for (int pred = 0; pred < leafValues.length; ++pred) {
int columnIx = filterColumns[pred];
// 行グループの統計情報を取得
OrcProto.RowIndexEntry entry = indexes[columnIx].getEntry(rowGroup);
OrcProto.ColumnStatistics stats = entry.getStatistics();
PredicateLeaf predicate = sargLeaves.get(pred);
// ★統計情報に基づいて述語を評価★
// この中でevaluatePredicate()が呼ばれ、修正箇所(lines 766-772)が実行される
leafValues[pred] = evaluatePredicateProto(stats, predicate, ...);
}
// ★述語式全体を評価して行グループの読み込み可否を判定★
// sarg.evaluate()で述語式全体(AND/ORの組み合わせ)を評価
// isNeeded()で最終的な読み込み可否を判定
// - TruthValue.YES, YES_NO, YES_NULL, YES_NO_NULL → true (読み込む)
// - TruthValue.NO, NULL, NO_NULL → false (スキップ)
result[rowGroup] = sarg.evaluate(leafValues).isNeeded();
}
return result;
}
これによって、検証用コードの下記のような処理をしようとしても、<=> の比較では行グループ全体が不要と判断されて除外されてしまいます。
df.filter(!(col("name") <=> "dummy"))
つまり、今回のバグは行グループ内の特定列の値が全て null だった場合に発生します。
行グループ内に一つでも null ではない値があれば、修正前のコードでも TruthValue.YES_NO_NULL が返され、isNeeded() が true となり、フィルタプッシュダウンで除外されません。
フィルタプッシュダウンを無効にすると正常に動作するのは、行グループが全て読み込みまれ全ての列の値に対して !(col("name") <=> "dummy") を判定するためです。
今回の修正により NULL_SAFE_EQUALS オペレータで比較した際の判定が追加され、期待する結果が返るようになりました。
検証用コードでの動作
ここまで説明すると、なぜSparkに報告した検証用コードでバグが発生するのか疑問に思う方もいるかもしれません。
検証用コードで確認したDataFrameは下記です。
+---+----+-------------------+
| id|name| email|
+---+----+-------------------+
| 1|test| null|
| 2|null|example@example.com|
+---+----+-------------------+
ORCの行グループは10,000行単位なのに、なぜ2行のデータでこのバグが発生するのでしょうか?
今回のバグは、行グループ内の特定列が 全て null だった場合に発生 するはずでした。
結論としては、これはSparkの分散処理によるものです。
検証用コードではSparkをローカル実行していますが、PCのコア数で並列処理されるようになっています。
私の環境では10並列の処理になっていました。
% sysctl -n hw.physicalcpu_max
10
DataFrameは、特に指定がなければ各行が分割されて並列処理されます。
並列処理した結果は、それぞれ別のORCファイルとして出力されます。
今回は2行のDataFrameでしたが、並列処理の結果、出力されたORCファイルは2つに分かれていました。
2つのORCファイルの統計情報は下記のようになっています。
part-00000-xxx.orc (行1のデータ)
└── ストライプ 0: 1行
└── 行グループ 0: 1行
└── nameカラムの統計情報: hasValue: true, hasNulls: false, min: test, max: test
part-00001-xxx.orc (行2のデータ)
└── ストライプ 0: 1行
└── 行グループ 0: 1行
└── nameカラムの統計情報: hasValue: false, hasNulls: true
バグは行グループ単位で発生するので、フィルタプッシュダウンが有効だと行2のデータが hasValues: false のため読み込まれず除外されます。
実環境でバグを発見した際のデータでも、filterに指定していた列は20%程度が null のスパースなデータでした。
Sparkの「大量データの分散処理」という特性上、再現性は高いバグなのではないかと思います。
検証用のコードで、下記のようにして出力ファイルを1つにまとめた場合は、行グループは1つになり hasValues: true となります。
df.repartition(1).write.mode("overwrite").orc(s"$dataPath/orc") // repartition(1) を追加
想定通り、この場合はバグは発生しませんでした。
最後に
本バグの修正は Spark 4.1.0 4.0.1 3.5.7 バージョンに反映されます。
分散処理の代表的フレームワークである Apache Spark コミュニティに貢献できたことは、チームにとって大変嬉しい経験でした。
かなり専門的な内容となりましたが、過去に同様の問題に遭遇した方や、OSSコミュニティへの貢献に興味がある方の参考になれば幸いです。









