
Athena Partition Projection の enum 型で複数 ALB のアクセスログを横断検索する
札幌オフィスの中川です。
複数のリソースを横断して Athena でクエリを投げたいことがあります。
例えば以下のように、複数の ALB のアクセスログが、同じバケットの中で ALB 名ごとの prefix で並んでいる構成です。
s3://<log-bucket>/
└── <共通 prefix>/
├── <alb-name-1>/ ← ALB 名でフォルダが分かれる
│ └── AWSLogs/<account>/elasticloadbalancing/<region>/yyyy/mm/dd/*.log.gz
├── <alb-name-2>/
│ └── AWSLogs/<account>/elasticloadbalancing/<region>/yyyy/mm/dd/*.log.gz
└── <alb-name-N>/
└── AWSLogs/<account>/elasticloadbalancing/<region>/yyyy/mm/dd/*.log.gz
こういう環境で「先週 5xx を返したリクエストを ALB 横断で見たい」のような調査が入ったとき、Athena テーブルが ALB 1 つにつき 1 つあると、横断クエリは UNION ALL で繋ぐことになります。ALB が増えるたびにテーブルも UNION も増えていきます。
公式ドキュメントには ALB アクセスログを Partition Projection で扱う DDL が紹介されていますが、こちらは日付パーティションだけが対象となります。
本記事では Athena Partition Projection の enum 型を使って、リソース名(ここでは ALB 名)もパーティション列として射影することで、複数リソースを 1 テーブルで扱う方法を紹介します。
なぜ enum なのか — injected との使い分け
複数 ALB を 1 テーブルで扱うには、ALB 名を Partition Projection のパーティション列として追加します。
Partition Projection には 4 つの型(enum / integer / date / injected)があり、このうち ALB 名のような文字列の集合に使えるのは enum か injected の 2 つになります。
enum— 値をカンマ区切りで列挙する。値の数が数十までに収まる前提injected— 列挙しない。クエリの WHERE 句で常に値を指定する前提
今回のようなケースでは enum を選びます。
injected 型は、クエリのたびに WHERE 句でそのパーティション列の値を必ず指定する必要があります。つまり「特定の ALB に絞らずにクエリを投げる」ということができません。
injected はカーディナリティが数百〜数千を超えて enum の制約に収まらないケースで利用します。
Queries on injected columns fail if a filter expression is not provided for each injected column.
出典: https://docs.aws.amazon.com/athena/latest/ug/partition-projection-supported-types.html
enum 側の注意として以下の 2 点が挙げられます。
- 公式が推奨するのは「数十まで」。テーブル全体のメタデータが Glue の制限(gzip 圧縮後で約 1 MB)に収まる必要があるため(出典: Supported types for partition projection)
projection.alb_name.valuesは自動追従しない。ALB が増えたらALTER TABLE ... SET TBLPROPERTIESで values を手動更新する必要がある
ALB 数が数十以内に収まる環境なら enum で十分シンプルです。それを超えるなら、「ALB を見るときは必ず WHERE で名前を指定する」という運用ルールとセットで injected を選ぶ形になります。
やってみた
複数 ALB のアクセスログに対して、alb_name を enum 型で射影した Athena テーブルを作り、横断クエリが通ることを確認します。
ALB アクセスログの S3 パス
ALB アクセスログの S3 パスは公式に決まっています。
{bucket}[/{prefix}]/AWSLogs/{aws-account-id}/elasticloadbalancing/{region}/{yyyy}/{mm}/{dd}/{aws-account-id}_elasticloadbalancing_{region}_app.{load-balancer-id}_{end-time}_{ip-address}_{random-string}.log.gz
出典: https://docs.aws.amazon.com/elasticloadbalancing/latest/application/load-balancer-access-logs.html
bucket と prefix は ALB 側で指定するパラメータで、AWSLogs/... 以降は ALB が自動付与する固定階層です。bucket と prefix を ALB 単位で指定できるので、ALB ごとに prefix の末尾を変えれば、1 つのバケットに集約しつつ ALB 名でフォルダを分離できます。たとえば prefix を logs/alb/web-alb-a, logs/alb/web-alb-b, logs/alb/api-alb のように設定すると、最終的な S3 パスはこうなります。
s3://alb-logs-demo/
└── logs/alb/ ← 共通 prefix
├── web-alb-a/ ← ALB 名でフォルダが分かれる
│ └── AWSLogs/111122223333/elasticloadbalancing/ap-northeast-1/yyyy/mm/dd/*.log.gz
├── web-alb-b/
│ └── AWSLogs/111122223333/elasticloadbalancing/ap-northeast-1/yyyy/mm/dd/*.log.gz
└── api-alb/
└── AWSLogs/111122223333/elasticloadbalancing/ap-northeast-1/yyyy/mm/dd/*.log.gz
公式の Partition Projection DDL は日付パーティションのみ
AWS 公式ドキュメントには、ALB アクセスログを Partition Projection で扱う DDL が載っており、ベースとして利用します。
出典:https://docs.aws.amazon.com/athena/latest/ug/create-alb-access-logs-table-partition-projection.html
PARTITIONED BY (day STRING)
LOCATION 's3://amzn-s3-demo-bucket/AWSLogs/<ACCOUNT-NUMBER>/elasticloadbalancing/<REGION>/'
TBLPROPERTIES (
"projection.enabled" = "true",
"projection.day.type" = "date",
"projection.day.range" = "2022/01/01,NOW",
"projection.day.format" = "yyyy/MM/dd",
...
"storage.location.template" = "s3://amzn-s3-demo-bucket/AWSLogs/<ACCOUNT-NUMBER>/elasticloadbalancing/<REGION>/${day}"
)
ただ、このままだと LOCATION と storage.location.template が「単一の ALB」を前提にした形になっていて、ALB が複数あると ALB ごとにこの DDL を作るしかありません。
複数 ALB に拡張する(enum を追加)
alb_name を enum 型の射影パーティションとして加えると、1 テーブルで全 ALB を扱えます。
公式 DDL から以下の3箇所を更新します。
PARTITIONED BYにalb_nameを追加projection.alb_name.type = 'enum'とprojection.alb_name.values = '<ALB 名カンマ区切り>'を追加storage.location.templateに${alb_name}を埋め込む
最終的な DDL がこちらです。
CREATE EXTERNAL TABLE IF NOT EXISTS alb_access_logs (
type string, time string, elb string,
client_ip string, client_port int,
target_ip string, target_port int,
request_processing_time double, target_processing_time double, response_processing_time double,
elb_status_code string, target_status_code string,
received_bytes bigint, sent_bytes bigint,
request_verb string, request_url string, request_proto string,
user_agent string, ssl_cipher string, ssl_protocol string,
target_group_arn string, trace_id string,
domain_name string, chosen_cert_arn string,
matched_rule_priority string, request_creation_time string,
actions_executed string, redirect_url string, lambda_error_reason string,
target_port_list string, target_status_code_list string,
classification string, classification_reason string, conn_trace_id string
)
PARTITIONED BY (
alb_name string,
`date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\\s]+?)\" \"([^\\s]+)\" \"([^ ]*)\" \"([^ ]*)\" ?([^ ]*)? ?( .*)?'
)
LOCATION 's3://alb-logs-demo/logs/alb'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.alb_name.type' = 'enum',
'projection.alb_name.values' = 'web-alb-a,web-alb-b,api-alb',
'projection.date.type' = 'date',
'projection.date.format' = 'yyyy/MM/dd',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'DAYS',
'projection.date.range' = 'NOW-5YEARS,NOW',
'storage.location.template' = 's3://alb-logs-demo/logs/alb/${alb_name}/AWSLogs/111122223333/elasticloadbalancing/ap-northeast-1/${date}'
)
これで Athena は WHERE alb_name = '<ALB 名>' AND date = '<日付>' のような条件を S3 パスにマッピングし、該当 prefix だけをスキャンします。
クエリを投げてみる
まず、特定の ALB に絞って 5xx を抽出してみます。
SELECT alb_name, date, time, client_ip, elb_status_code, request_url
FROM alb_access_logs
WHERE alb_name = 'api-alb'
AND date BETWEEN '2026/05/20' AND '2026/05/27'
AND elb_status_code LIKE '5%'
ORDER BY time DESC
LIMIT 50;
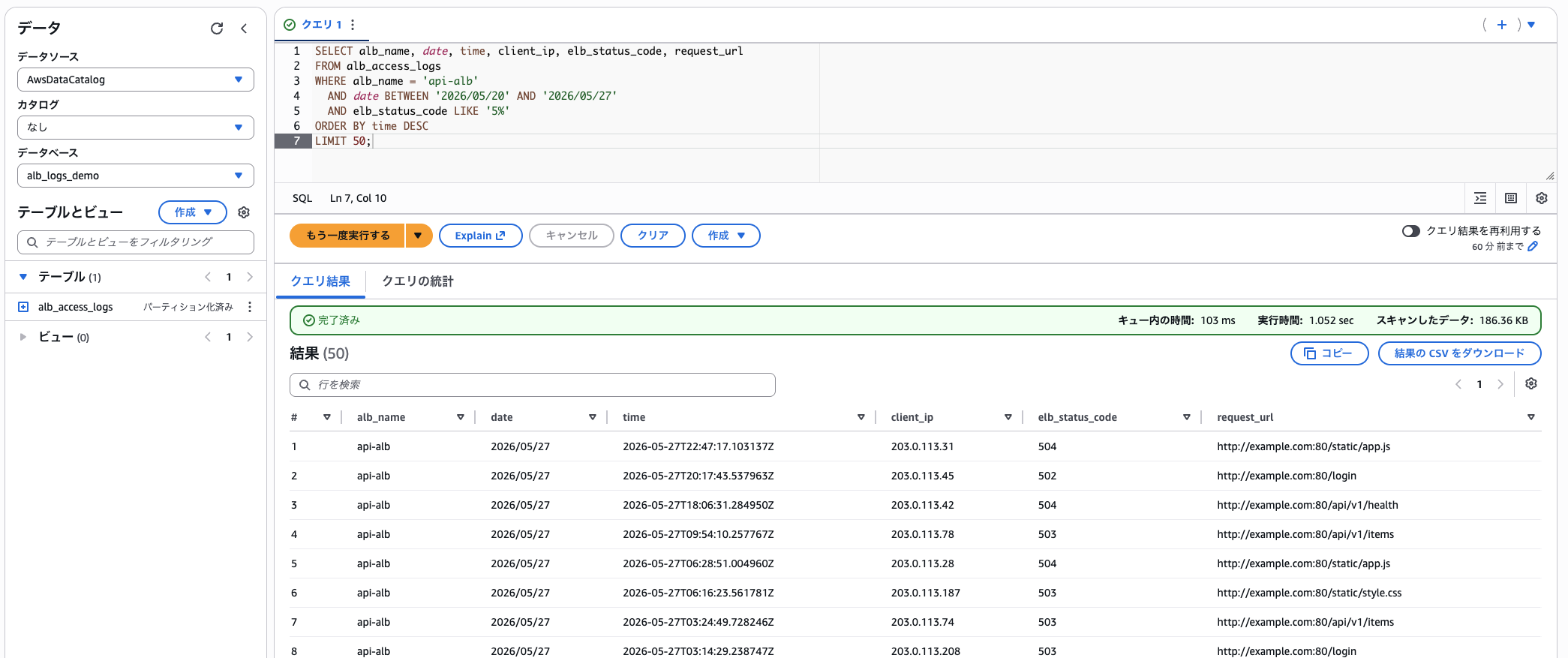
api-alb のログだけが返ります。スキャン量は約 186 KB。storage.location.template の ${alb_name} が api-alb に展開され、その prefix だけがスキャン対象になっていることが分かります。
次に、ALB を絞らずに同じ条件で 5xx を横断抽出してみます。
SELECT alb_name, date, time, client_ip, elb_status_code, request_url
FROM alb_access_logs
WHERE date BETWEEN '2026/05/20' AND '2026/05/27'
AND elb_status_code LIKE '5%'
ORDER BY time DESC
LIMIT 50;
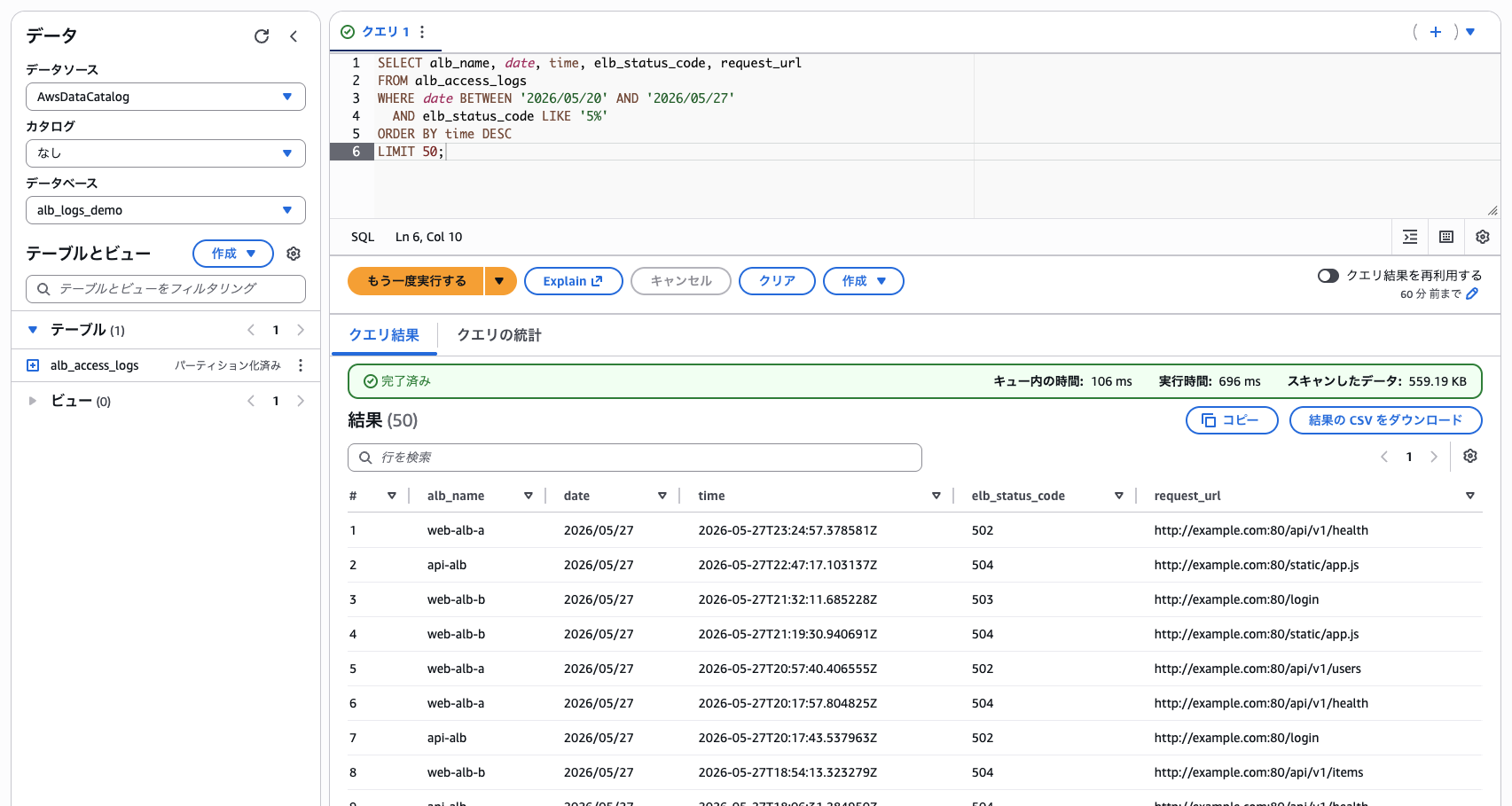
alb_name 列を見ると、web-alb-a、web-alb-b、api-alb の 3 つから結果が混ざって返ってきます。スキャン量は約 559 KB。単一 ALB の約 3 倍で、3 ALB ぶんがスキャンされていることになります。射影によって、ALB を絞ったぶんだけスキャン対象 S3 prefix が縮む、という挙動が確認できました。
ALB 別の集計も書けます。
SELECT
alb_name,
COUNT(*) AS total_requests,
SUM(CASE WHEN elb_status_code LIKE '5%' THEN 1 ELSE 0 END) AS error_5xx,
SUM(CASE WHEN elb_status_code LIKE '4%' THEN 1 ELSE 0 END) AS error_4xx
FROM alb_access_logs
WHERE date BETWEEN '2026/05/20' AND '2026/05/27'
GROUP BY alb_name
ORDER BY error_5xx DESC;
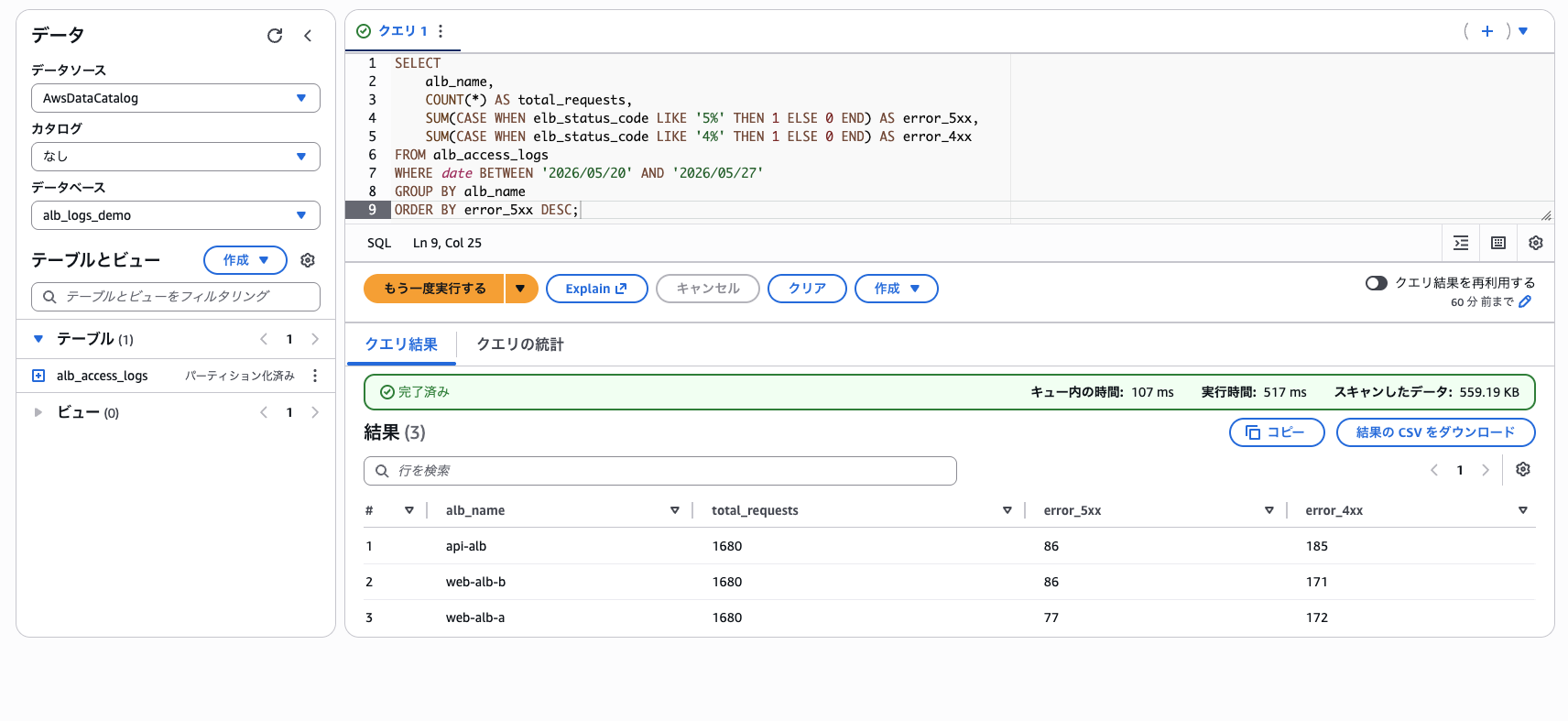
3 ALB それぞれの統計が算出されます。
enum を使ったクエリの動作を確認できました。
さいごに
複数 ALB のアクセスログを 1 テーブルで横断検索する方法を、Athena Partition Projection の enum 型を使って紹介しました。storage.location.template に ${alb_name} を埋め込むだけで、ALB ごとに分かれた S3 prefix を 1 つのテーブルにまとめられます。ALB が増えても projection.alb_name.values を更新するだけで対応できるので、ログ調査のたびに UNION ALL を書く運用から解放されます。
ただ、enum で取る値は数十程度までが公式の推奨な点と、自動追従はしないので ALB を追加するたびに ALTER TABLE ... SET TBLPROPERTIES での DDL 更新が必要な点にご注意ください。
同じパターンは CloudFront のディストリビューションや VPC フローログなど、リソース名ごとの prefix で S3 に溜まる他の AWS サービスログにも応用できます。横断調査が必要な環境であれば、試してみてください。










