
【新機能】Amazon Aurora DSQL の変更データをリアルタイムにストリーミングできる Change Data Capture がプレビューになりました
ウィスキー、シガー、パイプをこよなく愛する大栗です。
Amazon Aurora DSQL に Change Data Capture(CDC)ストリーム機能がプレビューとして追加されました。コミットされたデータベースの変更をほぼリアルタイムで Amazon Kinesis Data Streams に配信できるようになります。
- Amazon Aurora DSQL now supports Change Data Capture (Preview)
- Getting started with change data capture in Amazon Aurora DSQL
- Change data capture streams (Preview)
Change Data Capture(CDC)とは
Change Data Capture(CDC)は、データベースに加えられた変更(INSERT・UPDATE・DELETE)をリアルタイムにキャプチャし、下流のシステムに配信する仕組みです。バッチ処理を使わず変更をイベントとして扱えるため、検索インデックスの同期やイベント駆動アーキテクチャの構築などに活用できます。
Aurora DSQL の CDC ストリームは、クラスター内のすべてのユーザーテーブルの行レベル変更を自動的にキャプチャし、構造化された JSON レコードとして Amazon Kinesis Data Streams に配信します。主なユースケースは以下の通りです。
| ユースケース | 概要 |
|---|---|
| 下流システムとの同期 | バッチなしで検索インデックス・キャッシュ・データウェアハウスに即時反映 |
| イベント駆動アーキテクチャ | DB の変更をトリガーにワークフロー・通知・マイクロサービスを起動 |
| 監査証跡の維持 | コンプライアンスや障害調査のためにすべてのコミット済み変更を記録 |
| プロデューサーとコンシュマーの分離 | DB はトランザクションに集中し、下流システムは自分のペースで変更を処理 |
Aurora DSQL の CDC の仕組み
Aurora DSQL の CDC は BYOT(Bring Your Own Target)モデル を採用しています。Kinesis Data Stream はユーザー側で作成・管理し、Aurora DSQL が IAM ロールを引き受けて書き込みを行います。CDC のインフラ管理・ストリームヘルスの監視はすべて AWS が担当し、GetStream API と CloudWatch メトリクスでステータスが確認できます。
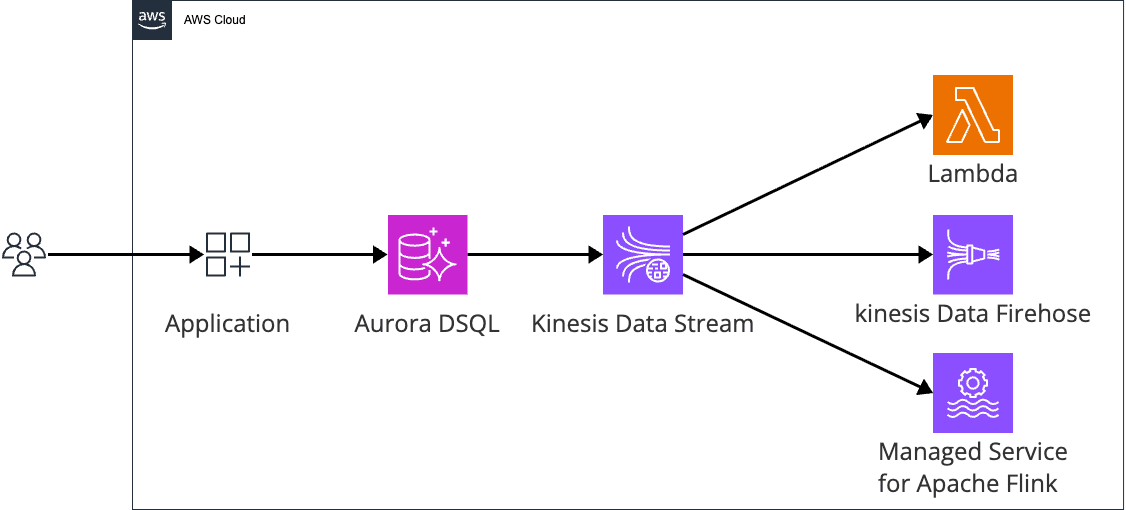
マルチリージョンクラスターの場合、任意の 1 リージョンに作成した単一ストリームで全リージョンの変更をキャプチャできます。全リージョンに CDC レコードを届けたい場合は各リージョンに個別にストリームを作成します。なお、Aurora DSQL クラスター・Kinesis データストリーム・IAM サービスロール・呼び出し元プリンシパルはすべて同一 AWS アカウント・同一リージョンに存在する必要があります。
配信保証と順序付け
| 特性 | 内容 |
|---|---|
| 配信保証 | 少なくとも 1 回(at-least-once) — 同じレコードが複数回届くことがある |
| 順序付け | UNORDERED — コミット順に近い順で届くが、厳密な順序保証はない |
| 重複排除 | source.ts_ns(ナノ秒タイムスタンプ)と主キーの組み合わせで識別可能 |
重複が発生した場合は source.ts_ns と主キーの値が一致するかどうかで判別できます。異なるトランザクションのレコードは任意の順序で届くことがあるため、アプリケーション側での対処が必要です。
CDC レコードの形式
Aurora DSQL CDC は各変更を次のような JSON 形式で配信します。
INSERT の例
{
"type": "full",
"op": "c",
"before": null,
"after": {"order_id": 1001, "item_id": 42, "quantity": 5, "price": "29.99"},
"source": {
"version": "1.0",
"ts_ms": 1705318200000,
"ts_ns": 1705318200000000000,
"txId": "ffthunp5stx6ffs2vyfqoatmfu",
"schema": "public",
"table": "order_items",
"db": "postgres",
"cluster": "kmabugltfmjdaj2siqr2qbxgju"
},
"ts_ms": 1705318200125,
"ts_ns": 1705318200125483291
}
DELETE の例
DELETE の場合、before フィールドに削除された行の主キーの値が含まれます。
{
"type": "full",
"op": "d",
"before": {"order_id": 1001, "item_id": 42},
"after": null,
"source": {
"version": "1.0",
"ts_ms": 1705318400000,
"ts_ns": 1705318400000000000,
"txId": "xyzabc123def456ghi789jklmno",
"schema": "public",
"table": "order_items",
"db": "postgres",
"cluster": "kmabugltfmjdaj2siqr2qbxgju"
},
"ts_ms": 1705318400125,
"ts_ns": 1705318400125483291
}
主なフィールドの説明
| フィールド | 説明 |
|---|---|
type |
レコード種別。full(完全なレコード)/chunked(サイズ超過のメインレコード)/fragment(分割フラグメント) |
op |
操作種別。c = INSERT(現在は UPDATE も含む)、u = UPDATE(GA 後に追加予定)、d = DELETE |
before |
DELETE かつ主キーあり の場合に主キーの値を格納。それ以外は null |
after |
変更後の完全な行の状態。DELETE の場合は null |
source.ts_ns |
トランザクションのコミットタイムスタンプ(ナノ秒・UTC)。順序の確立に使用 |
source.txId |
トランザクション識別子(base32 エンコード)。同一トランザクションのレコードは同じ値を持つ |
source.schema / source.table |
PostgreSQL のスキーマ名・テーブル名。ダウンストリームでのフィルタリングに使用 |
ts_ms |
CDC システムがレコードを処理した時刻(ミリ秒)。source.ts_ms との差が複製遅延の目安 |
プレビュー期間中の注意点として、現在は INSERT と UPDATE の両方に op: "c" が使用されています。GA 前に UPDATE は op: "u" として区別されるようになる予定です。未知の op 値は after の内容を適用するアップサートとして処理するよう実装しておくことをお勧めします。
ダウンストリームの処理パターン
Kinesis に届いた CDC レコードはさまざまな方法で処理できます。
| パターン | 処理方法 |
|---|---|
| 直接消費 | Amazon Kinesis Client Library(KCL)または AWS SDK でシャードを直接読み取る |
| AWS Lambda | Lambda をイベントソースとして設定し、バッチ単位で CDC レコードを処理 |
| Amazon Data Firehose | S3・Redshift・OpenSearch Service 等への配信と長期保管 |
| セルフマネージド | Apache Kafka Connect(Kinesis ソースコネクタ)や Apache Flink との統合 |
各レコードには source.schema・source.table・op が含まれるため、テーブルや操作種別でフィルタリングできます。テーブルレベルのフィルタリングは Aurora DSQL 側ではサポートされていないため、ダウンストリーム側で実施します。
注意点
| 項目 | 詳細 |
|---|---|
| プレビュー段階 | GA 前に op: "u"(UPDATE)が追加予定。未知の op 値は after を適用するアップサートとして処理するよう実装してください |
| 主キーの必須化 | CDC に参加するテーブルには主キーを定義してください。主キーがないと重複排除や DELETE 時の行特定ができません |
| 全シャードの消費 | ランダムなパーティションキーで均等分散されるため、すべての変更を受け取るにはすべてのシャードを消費する必要があります |
| 大きすぎるレコード | 9 MiB を超える CDC レコードは chunked・fragment に分割されます。本番実装ではフラグメントの再組み立て処理が必要です |
| ストリーム数の上限 | 1 クラスターあたりの CDC ストリーム数には 5 個の上限があります |
やってみる
Aurora DSQL クラスターから Kinesis Data Streams に CDC ストリームを設定するまでの手順を説明します。
前提条件
- Aurora DSQL クラスターがアクティブステータスで存在すること
- Kinesis データストリームと Aurora DSQL クラスターが同一 AWS アカウント・同一リージョンに存在すること
- IAM Role / Kinesis Data Stream を作成できる AWS CLI の認証情報があること
Step 1: Kinesis データストリームを作成する
CDC レコードは JSON 形式でカラム名・メタデータのオーバーヘッドが加わるため、元の行サイズより大きくなります。作成時に以下のパラメーターを設定します。
| パラメーター | 推奨値 | 理由 |
|---|---|---|
StreamMode |
ON_DEMAND |
突発的な書き込み増加に自動対応 |
MaxRecordSizeInKiB |
10240(10 MiB) |
デフォルト 1 MiB では CDC レコードが超過する場合があるため |
$ aws kinesis create-stream \
--stream-name my-cdc-stream \
--stream-mode-details StreamMode=ON_DEMAND \
--max-record-size-in-ki-b 10240 \
--region ap-northeast-1
アクティブになるまで待ちます。
$ aws kinesis wait stream-exists \
--stream-name my-cdc-stream
MaxRecordSizeInKiB を 10240 に設定しない場合、レコードサイズ超過で CDC ストリームが KINESIS_OVERSIZE_RECORD エラーになることがあります。Aurora DSQL はサイズ超過のレコードを最大 10 MiB のフラグメントに分割するため、Kinesis 側でも同サイズを受け入れられる設定が必要です。
Step 2: IAM ロールを作成する
Aurora DSQL が Kinesis データストリームに書き込むための IAM ロールを作成します。信頼ポリシーには Confused Deputy 攻撃 を防ぐため aws:SourceAccount と aws:SourceArn を必ず設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DSQLAccess",
"Effect": "Allow",
"Principal": { "Service": "dsql.amazonaws.com" },
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "123456789012"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:dsql:ap-northeast-1:123456789012:cluster/CLUSTER_ID/stream/*"
}
}
}
]
}
$ aws iam create-role \
--role-name dsql-cdc-role \
--assume-role-policy-document file://trust-policy.json
{
"Role": {
"Path": "/",
"RoleName": "dsql-cdc-role",
"RoleId": "ABCDEFGHIJKLMNOPQRSTU",
"Arn": "arn:aws:iam::942414336389:role/dsql-cdc-role",
"CreateDate": "2026-05-15T01:08:59+00:00",
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DSQLAccess",
"Effect": "Allow",
"Principal": {
"Service": "dsql.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "123456789012"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:dsql:ap-northeast-1:123456789012:cluster/CLUSTER_ID/stream/*"
}
}
}
]
}
}
}
permissions-policy.json
KMS 暗号化を使用していない場合も KMSAccess ステートメントを含めておくと、後から KMS を追加した際に影響しません。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "KinesisAccess",
"Effect": "Allow",
"Action": [
"kinesis:PutRecord",
"kinesis:PutRecords",
"kinesis:DescribeStreamSummary",
"kinesis:ListShards"
],
"Resource": "arn:aws:kinesis:ap-northeast-1:123456789012:stream/my-cdc-stream"
},
{
"Sid": "KMSAccess",
"Effect": "Allow",
"Action": ["kms:GenerateDataKey"],
"Resource": "arn:aws:kms:*:*:key/*",
"Condition": {
"StringEquals": {
"kms:ViaService": "kinesis.ap-northeast-1.amazonaws.com",
"kms:EncryptionContext:aws:kinesis:arn": "arn:aws:kinesis:ap-northeast-1:123456789012:stream/my-cdc-stream",
"aws:ResourceAccount": "${aws:PrincipalAccount}"
}
}
}
]
}
$ aws iam put-role-policy \
--role-name dsql-cdc-role \
--policy-name dsql-cdc-kinesis-access \
--policy-document file://permissions-policy.json
Step 3: CDC ストリームを作成する
Step 1 の Kinesis Stream ARN と Step 2 の IAM Role ARN を指定して CDC ストリームを作成します。
$ aws dsql create-stream \
--cluster-identifier CLUSTER_ID \
--target-definition '{"kinesis":{"streamArn":"arn:aws:kinesis:ap-northeast-1:123456789012:stream/my-cdc-stream","roleArn":"arn:aws:iam::123456789012:role/dsql-cdc-role"}}' \
--ordering UNORDERED \
--format JSON \
--region ap-northeast-1
{
"clusterIdentifier": "CLUSTER_ID",
"streamIdentifier": "STREAM_ID",
"arn": "arn:aws:dsql:ap-northeast-1:123456789012:cluster/CLUSTER_ID/stream/STREAM_ID",
"status": "CREATING",
"creationTime": "2026-05-15T01:23:18.006000+00:00",
"ordering": "UNORDERED",
"format": "JSON"
}
ストリームの作成には通常 1〜3 分かかります。アクティブになるまで待ちます。
$ aws dsql wait stream-active \
--cluster-identifier CLUSTER_ID \
--stream-identifier STREAM_ID
アクティブになると Aurora DSQL はコミット済みの変更を Kinesis に配信し始めます。
Step 4: 動作を確認する
Aurora DSQL クエリエディタを開き 管理者として接続 します。
Aurora DSQL クラスターにテストデータを挿入します。
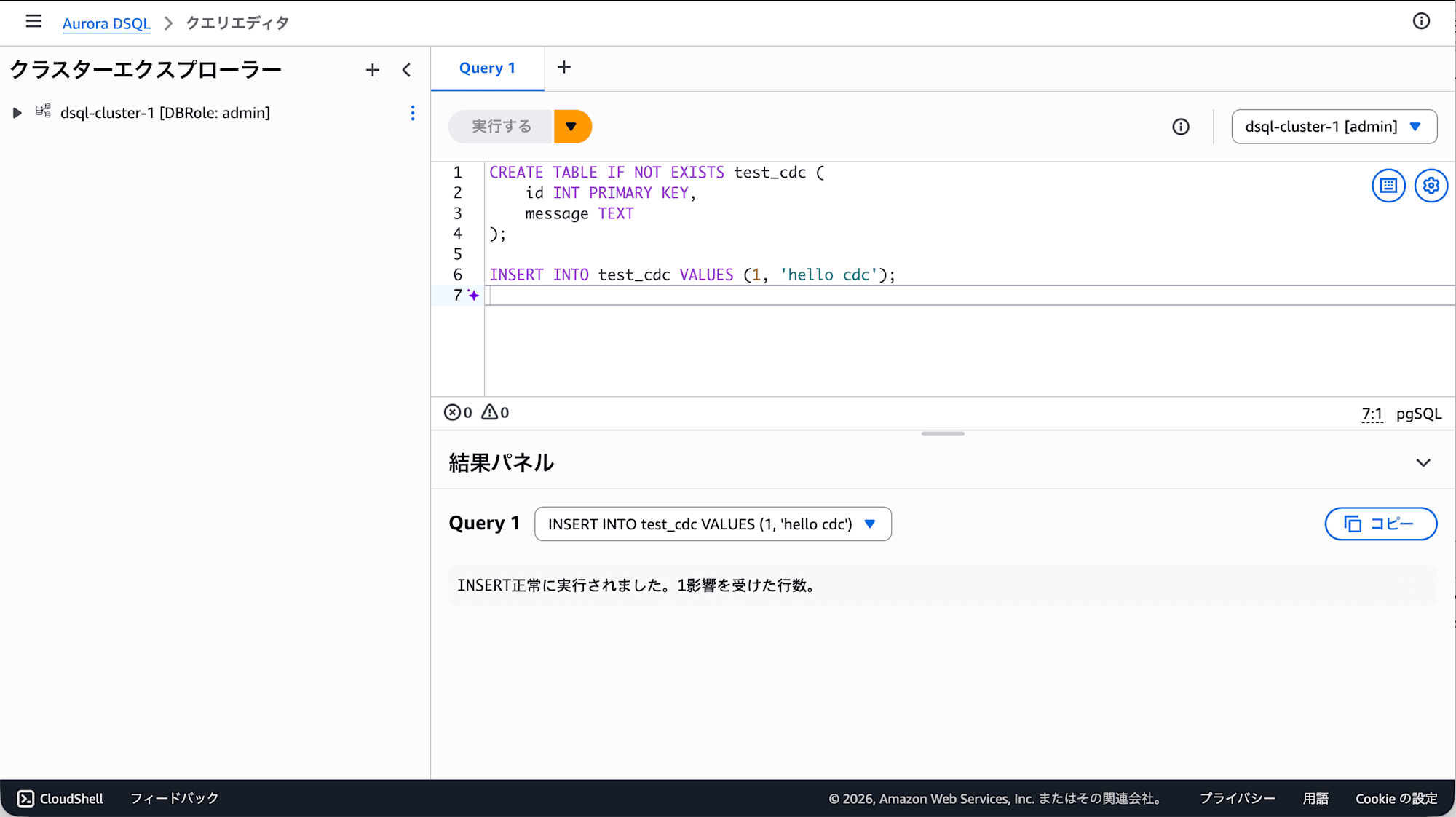
以下のクエリをエディタに記述して すべて実行 を行います。
CREATE TABLE IF NOT EXISTS test_cdc (
id INT PRIMARY KEY,
message TEXT
);
INSERT INTO test_cdc VALUES (1, 'hello cdc');
Kinesis からレコードを読み取って CDC レコードが届いているか確認します。
まずはシャードを確認します。
$ aws kinesis list-shards --stream-name my-cdc-stream \
--region ap-northeast-1
{
"Shards": [
{
"ShardId": "shardId-000000000000",
"HashKeyRange": {
"StartingHashKey": "0",
"EndingHashKey": "85070591730234615865843651857942052863"
},
"SequenceNumberRange": {
"StartingSequenceNumber": "49674557149064894605784231929960583713125036683033575426"
}
},
{
"ShardId": "shardId-000000000001",
"HashKeyRange": {
"StartingHashKey": "85070591730234615865843651857942052864",
"EndingHashKey": "170141183460469231731687303715884105727"
},
"SequenceNumberRange": {
"StartingSequenceNumber": "49674557149087195350982762553102119431397685044539555858"
}
},
{
"ShardId": "shardId-000000000002",
"HashKeyRange": {
"StartingHashKey": "170141183460469231731687303715884105728",
"EndingHashKey": "255211775190703847597530955573826158591"
},
"SequenceNumberRange": {
"StartingSequenceNumber": "49674557149109496096181293176243655149670333406045536290"
}
},
{
"ShardId": "shardId-000000000003",
"HashKeyRange": {
"StartingHashKey": "255211775190703847597530955573826158592",
"EndingHashKey": "340282366920938463463374607431768211455"
},
"SequenceNumberRange": {
"StartingSequenceNumber": "49674557149131796841379823799385190867942981767551516722"
}
}
]
}
シャードは shardId-000000000000 から shardId-000000000003 まで 4 個あります。各シャードの状況を見てみます。
$ SHARD_ITERATOR_0=$(aws kinesis get-shard-iterator \
--stream-name my-cdc-stream \
--shard-id shardId-000000000000 \
--shard-iterator-type TRIM_HORIZON \
--region ap-northeast-1 \
--query 'ShardIterator' --output text)
$ SHARD_ITERATOR_1=$(aws kinesis get-shard-iterator \
--stream-name my-cdc-stream \
--shard-id shardId-000000000001 \
--shard-iterator-type TRIM_HORIZON \
--region ap-northeast-1 \
--query 'ShardIterator' --output text)
$ SHARD_ITERATOR_2=$(aws kinesis get-shard-iterator \
--stream-name my-cdc-stream \
--shard-id shardId-000000000002 \
--shard-iterator-type TRIM_HORIZON \
--region ap-northeast-1 \
--query 'ShardIterator' --output text)
$ SHARD_ITERATOR_3=$(aws kinesis get-shard-iterator \
--stream-name my-cdc-stream \
--shard-id shardId-000000000003 \
--shard-iterator-type TRIM_HORIZON \
--region ap-northeast-1 \
--query 'ShardIterator' --output text)
各々のシャードのデータを確認します。
$ aws kinesis get-records \
--shard-iterator "$SHARD_ITERATOR_0" \
--region ap-northeast-1
{
"Records": [],
"NextShardIterator": "AAAAAAAAAAFipTQ5lRXgleplbp6KW+fbgeYxSTRhyzPVE/FdDkTvFho2FjMHzXmYzubvR3OpQAaWcg5E8Z7wSodOnMnKerhZ909P96VFKXF37sQnD4PENNt5TRzR1sQQlnBCWnNwEvTnnKJmbL53T3gFW2Lyt72yHX8PNUDC/s9nyJd0s6nlrdB0Xx/ap9pZje+P7qQFILWuC4hosrsss6QncxFOsBc6Pl+Pb/kH2mp0lvtlzVNA1A==",
"MillisBehindLatest": 795000
}
$ aws kinesis get-records \
--shard-iterator "$SHARD_ITERATOR_1" \
--region ap-northeast-1
{
"Records": [
{
"SequenceNumber": "49674557416339325810186146276413288323013745776472883218",
"ApproximateArrivalTimestamp": "2026-05-15T01:38:09.316000+00:00",
"Data": "eyJ0eXBlIjoiZnVsbCIsIm9wIjoiYyIsImJlZm9yZSI6bnVsbCwiYWZ0ZXIiOnsiaWQiOjEsIm1lc3NhZ2UiOiJoZWxsbyBjZGMifSwic291cmNlIjp7InZlcnNpb24iOiIxLjAiLCJ0c19tcyI6MTc3ODgwOTA4OTIxMSwidHNfbnMiOjE3Nzg4MDkwODkyMTEzMjI3OTQsInR4SWQiOiJ6YnR5dXVybGV0YXBxYnRodWxmY3k0b3cyNCIsInNjaGVtYSI6InB1YmxpYyIsInRhYmxlIjoidGVzdF9jZGMiLCJkYiI6InBvc3RncmVzIiwiY2x1c3RlciI6ImhmdHlzY3FmYmlvYmR4NG52empjMjdhZ295In0sInRzX21zIjoxNzc4ODA5MDg5MjA5LCJ0c19ucyI6MTc3ODgwOTA4OTIwOTQ2OTg1OX0=",
"PartitionKey": "-"
}
],
"NextShardIterator": "AAAAAAAAAAGT46RJ2sulk00yj1atdNeUJ5Yx64oABIJNxJkLgrohlxnj9Iz3lCYZpVmw9Wkg+pvKuDCKbgYE1LlIXi0aMITsq0y+qpUSyhbKeNE0oNqgJHkZILxB6QWZI1G/eohwZIo/rkincWHnM7RjcXY96Y6p9TekCzTB3L9rNyAIa4sxpYpbOlLCX4cJHnl/5Ws6uBccLTRHhqY3RcmWtbwvTgsGdPl/u2DZrMi9iqsvS1wZpQ==",
"MillisBehindLatest": 262000
}
$ aws kinesis get-records \
--shard-iterator "$SHARD_ITERATOR_2" \
--region ap-northeast-1
{
"Records": [],
"NextShardIterator": "AAAAAAAAAAGit/Cu8v5y70LNx8KGCDyIHD09r0jZO4t751thyljDBhtxA/LdgMmbVierv9NQfEzVOdDsF/qPE5FjIf1L5yjq+VytbaRYBJuxxCMG1e0Cmes58XZ3msuc5fjGF9X5awCgQlbtBlW9gZMP1m9YTyCaN9JGcqLuuvtgagVUhCJSPkSm1Ie+cqDPSjZigv44Eay5m+zx3P/AIS+qW66r8Lvn0SNLj9UMlvFjPN1VC7kJGA==",
"MillisBehindLatest": 1994000
}
$ aws kinesis get-records \
--shard-iterator "$SHARD_ITERATOR_3" \
--region ap-northeast-1
{
"Records": [],
"NextShardIterator": "AAAAAAAAAAE4QvQRF961gheOmrvCHntbyiCfXSeYtyAU3PXsWNTt2LDCyY7Noc4d9F6p5Exv1yM6PtnMSZguFzghxJFuLK8zfH4sZucFLADZKz4qgTN7oFBmh7Oik9n5/CCzdvAAWpv0AQh2/FsfXKfePtVJTtPZXMFpLfY0ZZVS4pfESqMi6HOETwRVzgfZFNfCDSEdxNeJwvf+YErLTnwKFT+koVUYTdyX6bPLydM9lM+WIZ3Ntg==",
"MillisBehindLatest": 2006000
}
shardId-000000000001 のレコードには Records フィールドの中身があるので内容を確認します。Data フィールドは Base64 エンコードされています。デコードすると以下のような JSON レコードが確認できます。
echo "eyJ0eXBlIjoiZnVsbCIsIm9wIjoiYyIsImJlZm9yZSI6bnVsbCwiYWZ0ZXIiOnsiaWQiOjEsIm1lc3NhZ2UiOiJoZWxsbyBjZGMifSwic291cmNlIjp7InZlcnNpb24iOiIxLjAiLCJ0c19tcyI6MTc3ODgwOTA4OTIxMSwidHNfbnMiOjE3Nzg4MDkwODkyMTEzMjI3OTQsInR4SWQiOiJ6YnR5dXVybGV0YXBxYnRodWxmY3k0b3cyNCIsInNjaGVtYSI6InB1YmxpYyIsInRhYmxlIjoidGVzdF9jZGMiLCJkYiI6InBvc3RncmVzIiwiY2x1c3RlciI6ImhmdHlzY3FmYmlvYmR4NG52empjMjdhZ295In0sInRzX21zIjoxNzc4ODA5MDg5MjA5LCJ0c19ucyI6MTc3ODgwOTA4OTIwOTQ2OTg1OX0=" \
| base64 -d | jq .
{
"type": "full",
"op": "c",
"before": null,
"after": {"id": 1, "message": "hello cdc"},
"source": {
"version": "1.0",
"ts_ms": 1705318200000,
"ts_ns": 1705318200000000000,
"txId": "ffthunp5stx6ffs2vyfqoatmfu",
"schema": "public",
"table": "test_cdc",
"db": "postgres",
"cluster": "CLUSTER_ID"
},
"ts_ms": 1705318200125,
"ts_ns": 1705318200125483291
}
INSERT が "op": "c" として届いていることが確認できます。
今度は Aurora DSQL クエリエディタでレコードを更新と削除を行います。
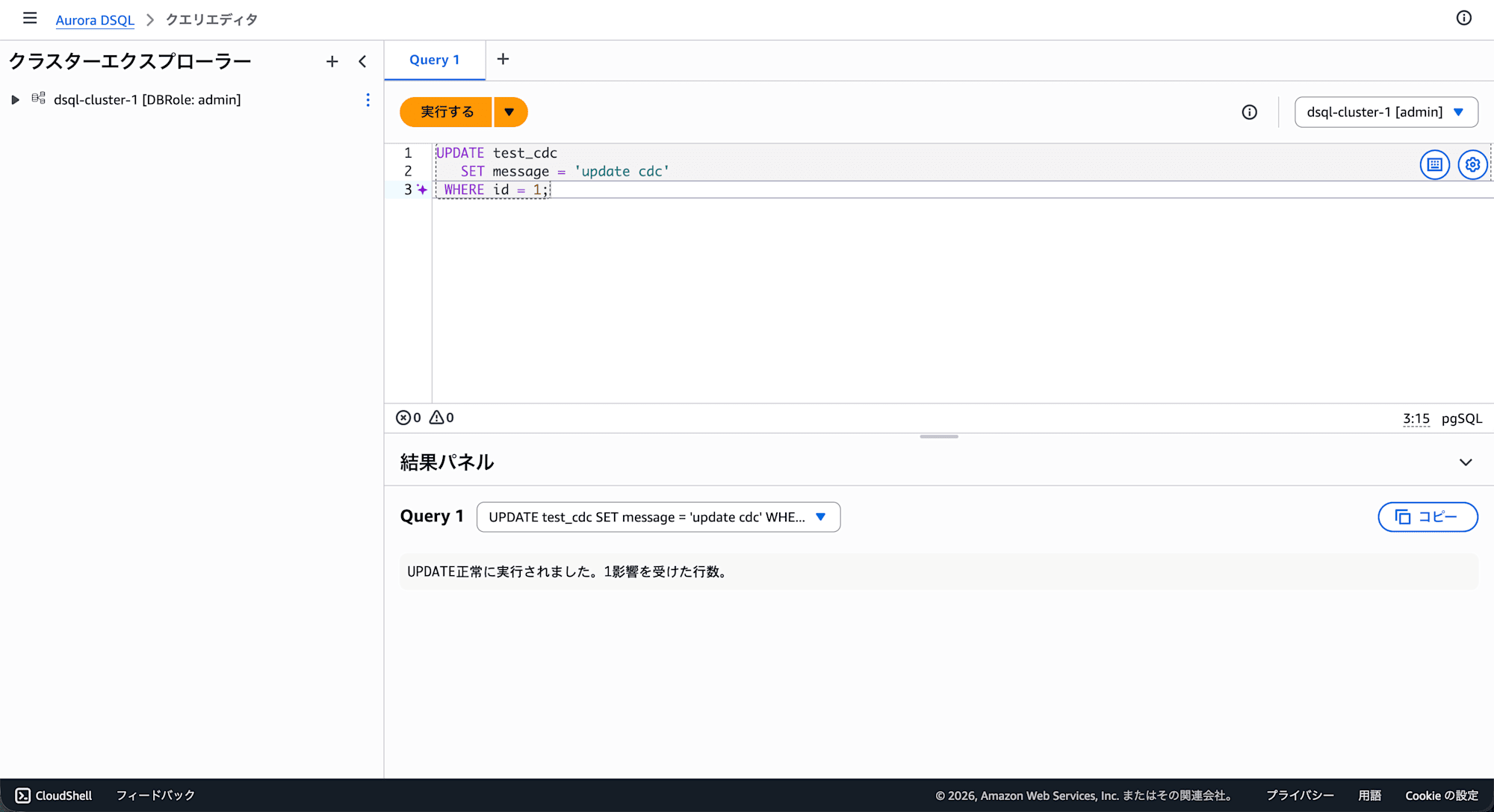
以下のクエリをエディタに記述して 実行する をクリックします。
UPDATE test_cdc
SET message = 'update cdc'
WHERE id = 1;
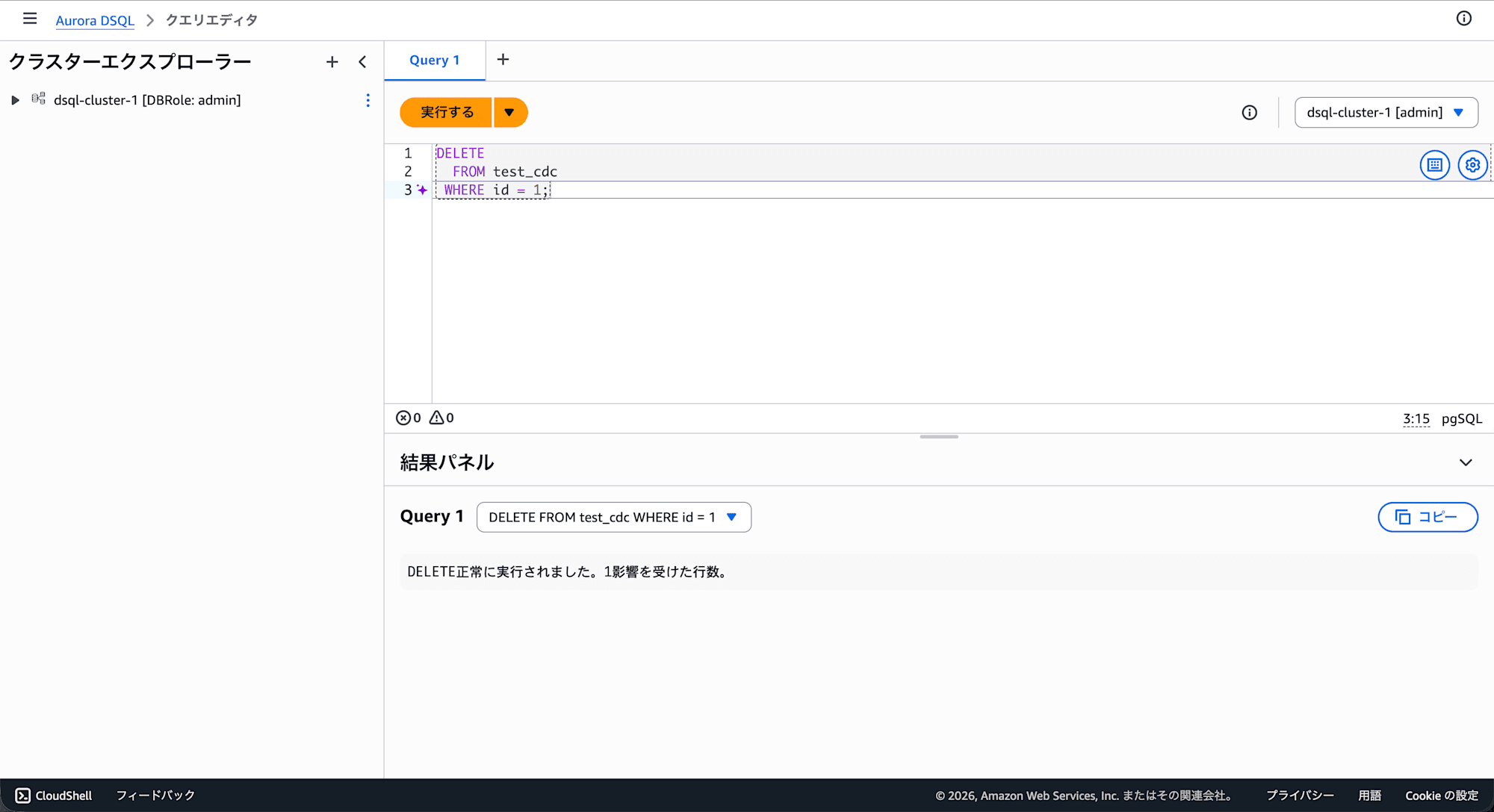
以下のクエリをエディタに記述して 実行する をクリックします。
DELETE
FROM test_cdc
WHERE id = 1;
各々のシャードのデータを確認して、レコードの中身を確認します。
以下のレコードを取得しました。
{
"Records": [
{
"SequenceNumber": "49674557418101084680870066793622645563028019768027250690",
"ApproximateArrivalTimestamp": "2026-05-15T02:17:58.746000+00:00",
"Data": "eyJ0eXBlIjoiZnVsbCIsIm9wIjoiYyIsImJlZm9yZSI6bnVsbCwiYWZ0ZXIiOnsiaWQiOjEsIm1lc3NhZ2UiOiJ1cGRhdGUgY2RjIn0sInNvdXJjZSI6eyJ2ZXJzaW9uIjoiMS4wIiwidHNfbXMiOjE3Nzg4MTE0Nzg3NjYsInRzX25zIjoxNzc4ODExNDc4NzY2ODQ4NDY3LCJ0eElkIjoic2Z0eXV3MmlzZ2hvbHc1M3Fqbm9qNnpjeXUiLCJzY2hlbWEiOiJwdWJsaWMiLCJ0YWJsZSI6InRlc3RfY2RjIiwiZGIiOiJwb3N0Z3JlcyIsImNsdXN0ZXIiOiJoZnR5c2NxZmJpb2JkeDRudnpqYzI3YWdveSJ9LCJ0c19tcyI6MTc3ODgxMTQ3ODcxOCwidHNfbnMiOjE3Nzg4MTE0Nzg3MTgwMzgxNDN9",
"PartitionKey": "-"
}
],
"NextShardIterator": "AAAAAAAAAAFfjcFU1mO7rjY4P7HnIMVwqS4p91JYLQEW4nPULjX43ZRKgwQSLNyl/6b5NRv0qO5ep+CB7mrHZLxH0z6iLhY5b0jH/13C6liTsXsH2uKzapPqs69f/LtRsET5ggIqrykLSeoTJBfEdPrExo6ndRDI6zmppZ12IWYr3dgN+dMTa0AkJsaH7GQ3RpG9ceGGH4FSpN3m3jq9IpHux8f4Oj/NubuAtS0bLq5H5aqS6JqChw==",
"MillisBehindLatest": 0
}
{
"Records": [
{
"SequenceNumber": "49674557416339325810186146276413288323013745776472883218",
"ApproximateArrivalTimestamp": "2026-05-15T01:38:09.316000+00:00",
"Data": "eyJ0eXBlIjoiZnVsbCIsIm9wIjoiYyIsImJlZm9yZSI6bnVsbCwiYWZ0ZXIiOnsiaWQiOjEsIm1lc3NhZ2UiOiJoZWxsbyBjZGMifSwic291cmNlIjp7InZlcnNpb24iOiIxLjAiLCJ0c19tcyI6MTc3ODgwOTA4OTIxMSwidHNfbnMiOjE3Nzg4MDkwODkyMTEzMjI3OTQsInR4SWQiOiJ6YnR5dXVybGV0YXBxYnRodWxmY3k0b3cyNCIsInNjaGVtYSI6InB1YmxpYyIsInRhYmxlIjoidGVzdF9jZGMiLCJkYiI6InBvc3RncmVzIiwiY2x1c3RlciI6ImhmdHlzY3FmYmlvYmR4NG52empjMjdhZ295In0sInRzX21zIjoxNzc4ODA5MDg5MjA5LCJ0c19ucyI6MTc3ODgwOTA4OTIwOTQ2OTg1OX0=",
"PartitionKey": "-"
}
],
"NextShardIterator": "AAAAAAAAAAHsBvhlZYaCsR6HQgvHb3u5fMb6r6Cnj/KrJlifd4cazsT5/n2qFyfSDX2D1hs+nGrVTBhEsWWMTpEg0bbqHaG9y3GRI6zCvFagiuAFOV71sihgThnz+uL3V8/V6KNi7q3TJzG/xQeq9saeGJxt7GoatUbStI6k0mcg4f7da8r4dT4BrbIjDYMjsWiC9I8f42nbkNOSovD4uiWXaphex1cXDspEZVsLYL9kg0I4EImRsvqyjQOFc9HIxTblP08AF3gvWYjb3gf0Asfxgt51UnQAIYJ+I33phEYutWC/dtOzgg==",
"MillisBehindLatest": 2589000
}
{
"Records": [
{
"SequenceNumber": "49674557419929745787149577901458504746964178724831887394",
"ApproximateArrivalTimestamp": "2026-05-15T02:18:16.636000+00:00",
"Data": "eyJ0eXBlIjoiZnVsbCIsIm9wIjoiZCIsImJlZm9yZSI6eyJpZCI6MX0sImFmdGVyIjpudWxsLCJzb3VyY2UiOnsidmVyc2lvbiI6IjEuMCIsInRzX21zIjoxNzc4ODExNDk2NjA3LCJ0c19ucyI6MTc3ODgxMTQ5NjYwNzQ3MzUwNywidHhJZCI6IjZydHl1dzIyZXFhZHkyZXlnamlreG5xYzRpIiwic2NoZW1hIjoicHVibGljIiwidGFibGUiOiJ0ZXN0X2NkYyIsImRiIjoicG9zdGdyZXMiLCJjbHVzdGVyIjoiaGZ0eXNjcWZiaW9iZHg0bnZ6amMyN2Fnb3kifSwidHNfbXMiOjE3Nzg4MTE0OTY2MDIsInRzX25zIjoxNzc4ODExNDk2NjAyMDAwNjMyfQ==",
"PartitionKey": "-"
}
],
"NextShardIterator": "AAAAAAAAAAFQlBzxuHwO9P8UoLKF3yfV2Ra6DOa4Ytqef8qr/JRLf/OYv5Bz2M2VcvVCvCTlGuG1ntszZSB7iKTs+0a1VKIgdTgdsve1r2LlznzJq9PkMw0lcuEumXAJxXGkMn7DKDHbb2A3qQAYRg9Rw9r5N5DcaZ+eYuNn/L7uTDmWzZnoEMctG/fZCOCCnK4bIT06A1bFInaNEUBZwNlUUgAq7khngCF2LaBkXY5Ui26sXrLFtA==",
"MillisBehindLatest": 0
}
{
"Records": [],
"NextShardIterator": "AAAAAAAAAAG4pR285dX3Oy8pVQtr+4biea1dVGbv4gsVRRAwFDBt/rsxBqVzS+th9t7UiU90TtfmXwirCuWU2H83udJ6z3qQZ7yVmznwpJimdHs/aUkMiJvmgotDGISh18T5R3HluB35P774JseC2+fOEPdUQ4FOHA2Pr8mUXDIOWk+yEKBt+xF2cdyBSmZI0ZIzhuvkAD+A8h0zv8/WY+K6VZq8cU792tlcgUTgZH3PPdEjdXutOA==",
"MillisBehindLatest": 3124000
}
shardId-000000000001 のレコードは先程の挿入のレコードなので、shardId-000000000000 と shardId-000000000002 のデータをデコードします。
{
"type": "full",
"op": "c",
"before": null,
"after": {
"id": 1,
"message": "update cdc"
},
"source": {
"version": "1.0",
"ts_ms": 1778811478766,
"ts_ns": 1778811478766848467,
"txId": "sftyuw2isgholw53qjnoj6zcyu",
"schema": "public",
"table": "test_cdc",
"db": "postgres",
"cluster": "hftyscqfbiobdx4nvzjc27agoy"
},
"ts_ms": 1778811478718,
"ts_ns": 1778811478718038143
}
{
"type": "full",
"op": "d",
"before": {
"id": 1
},
"after": null,
"source": {
"version": "1.0",
"ts_ms": 1778811496607,
"ts_ns": 1778811496607473507,
"txId": "6rtyuw22eqady2eygjikxnqc4i",
"schema": "public",
"table": "test_cdc",
"db": "postgres",
"cluster": "hftyscqfbiobdx4nvzjc27agoy"
},
"ts_ms": 1778811496602,
"ts_ns": 1778811496602000632
}
UPDATE が "op": "c" として届いており、"before": null と新規にレコード挿入しているような表現となってしまっていることが分かります。"op": "u" として処理されるようなアップデートは GA までに行われるということですので、対応を待ちたいと思います。DELETE は "op": "d" として届いていることが分かります。
さいごに
Aurora DSQL に CDC ストリームが追加されたことで、分散サーバーレスデータベースをイベント駆動アーキテクチャの起点として活用できるようになりました。フルマネージドでマルチリージョンクラスターの変更をキャプチャできる点は非常に強力だと思います。
現時点では INSERT と UPDATE が区別されないことや、厳密な順序保証がないといった制約はありますが、GA 時には INSERT と UPDATE が区別される予定です。ダウンストリームでの重複排除と source.ts_ns による順序付けを意識した設計をしておけば、プレビュー期間中でも十分に活用できると思います。








