
I tried to run auto identification of languages in audio file and converted it from speech to text while also redacting PII using Amazon Transcribe
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Your audio files may contain several languages if you operate in a country with numerous official languages or across multiple regions. Participants may communicate in completely different languages or alternate between them. Consider a customer service call to report a problem in a community with a large multi-lingual population. Although the communication may begin in one language, the client may switch to another to communicate the problem, based on comfort level or user preferences with other languages.
Introduction to Amazon Transcribe
Amazon Transcribe is an automatic speech recognition (ASR) service that makes it simple to add speech-to-text functionality to your applications. You may now enable Amazon Transcribe to automatically mask or delete particular phrases from output transcripts based on a vocabulary that you select while transcribing audio. For example, a vocabulary filter may be used to automatically exclude obscene terms from transcription results for content control. You no longer have to remove inappropriate stuff from each transcript. Once you've created a vocabulary filter, you may apply it to all of your transcribing tasks.
Amazon Transcribe can automatically detect and effectively create transcripts in the languages spoken in the audio with as little as 3 seconds of audio, eliminating the need for humans to define the languages.
This blog explains how to use Amazon Transcribe to transcribe a multi-language audio recording, and also how to mask profane words and redact PII.
Technical Overview
Amazon Simple Storage Service (Amazon S3) is also used in the solution, which is an object storage service designed to store and retrieve any quantity of data from anywhere. When you store data in Amazon S3, you use buckets and objects as resources. A bucket is a container that stores objects.
Prerequisites
- I have already created an S3 bucket
- Uploaded the audio file to the bucket
Create the Transcription Job
With the audio file uploaded, we now create a transcription job.
- On the Amazon Transcribe console, choose Transcription jobs in the navigation pane.
- Select Create job.

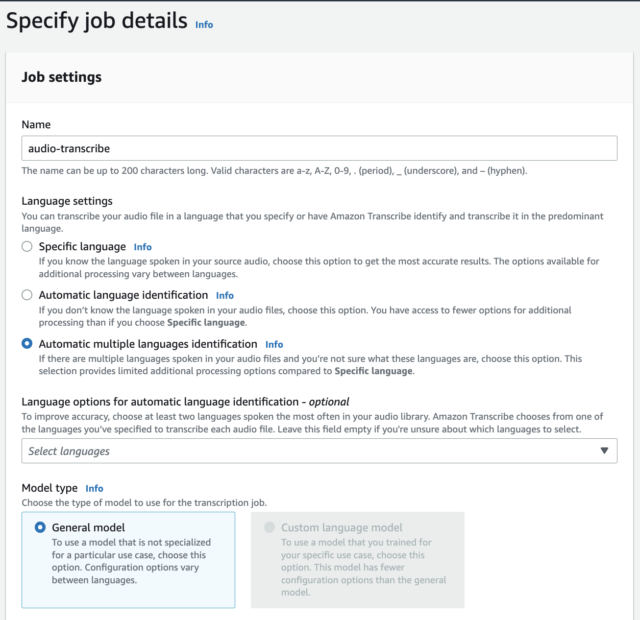
3. For Name enter a unique name for the job.
This will also be the name of the output transcript file.
4. For Language settings, select Automatic language identification. This feature enables Amazon Transcribe to automatically identify and transcribe all languages spoken in the audio file.
5. For Language options for automatic language identification, leave it unselected. Amazon Transcribe automatically identifies and transcribes all languages spoken in the audio.
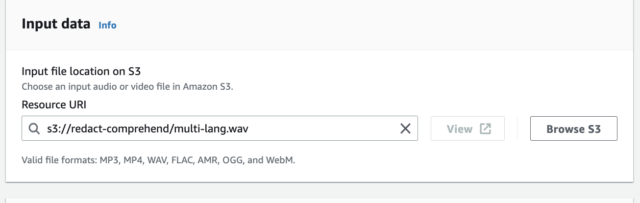
6. For Input data, choose Browse S3.
7. Choose Next.
8. Under Content removal, click on PII redaction
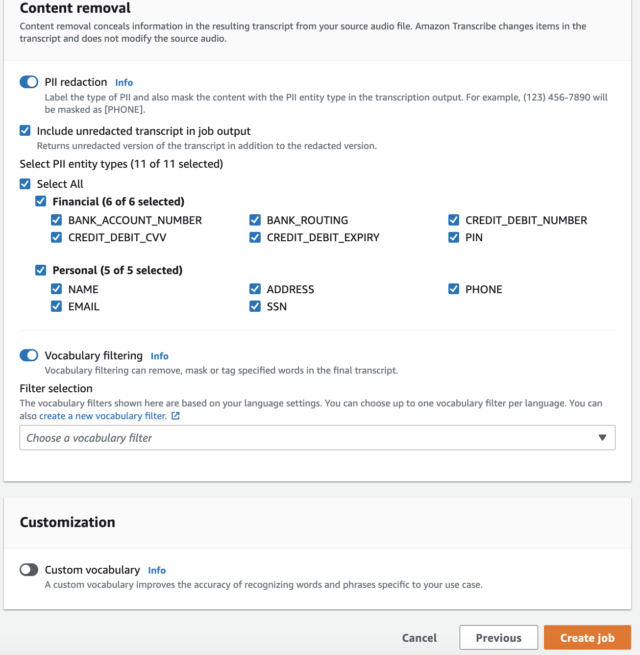
9. Select Create job
Output Review
When the transcription job is complete, open the transcription job.


The name which is a PII entity was redacted and replaced with [NAME], also the number 987654321 is not redacted because it does not recognize it as a PII entity.

You can optionally download a copy of the transcript as a JSON file, which you could use for further post-call analytics.








