
AWS AI-DLC Unicorn Gymに参加してきました!
リテールアプリ共創部の市川です。
2026年1月22日・23日の2日間、アマゾンウェブサービスジャパン合同会社(以下、AWSJと表記します)主催の AI-DLC Unicorn Gym に参加してきました。
本記事では、イベントの大まかな流れと、実際に参加して感じたことをご紹介します。
概要
AIを活用し、2日間でプロダクト開発を行うワークショップに参加しました。
全体では11社が参加しており、それぞれが個別のテーマを設定して取り組みました。
AI-DLCとは
AI駆動開発ライフサイクルを略してAI-DLCと呼びます。
AI-DLCは、AIを開発プロセスの中心的な協力者・チームメイトとして位置づけ、ソフトウェア開発ライフサイクル全体でその能力を活用する手法です。
なぜAI-DLCに取り組むのか
これまでのAI活用は、コード補完やチャットによる質問対応といった「支援型(Assistive)」が主流で、開発の一部を効率化する手段として使われてきました。
AWSが提唱するAI-DLCは、AIを単なるツールとして扱うのではなく、開発ライフサイクル全体に関与する「チームメイト」として位置づける「主体型(Agentic)」のアプローチが特徴です。
これにより、人間の役割はコードを書くことから、AIの成果物を評価し、方向性を示す「監督・レビュー(Supervising)」へとシフトします。
AIと人間が役割分担して協働する開発プロセスを確立することで、組織として責任を持ち、判断可能で持続可能な開発を実現できると考え、AI-DLCに取り組む必要があると感じました。
この「ソフトウェアエンジニアリングの再構築」とも言えるパラダイムシフトをいち早く体験し、AIと人間が真に協働する未来の開発プロセスを身をもって検証するために、今回のワークショップに参加しました。
チーム構成
今回はクラスメソッドとして単独で参加するのではなく、お客様のチームに加えていただく形での参加でした。
お客様、パートナー企業様、クラスメソッドの3社による混成チームで参加しました。
ロールは、ビジネスサイド2名、PM3名、エンジニア3名の合計8名です。
私自身はPMのロールで参加しました。

会場の写真
ワークショップの流れ
AI-DLCのワークショップは、以下の3つの工程で進行します。
- 工程1:Inception
ユーザーストーリーの作成 - 工程2:Construction
開発・テストの実施 - 工程3:Operation
IaCを用いた本番環境へのデプロイ
各工程ごとにサンプルプロンプトが用意されており、それをベースに、各チームのテーマに沿った内容を補完しながら進めていきます。
ワークショップでの主な注意点
冒頭の説明では、以下の注意点が共有されました。
- 人間はコードを一切書かない
- AIが生成した成果物は必ず人間がレビューする
- AIの成果物に違和感があれば、無理に修正せず破棄して作り直してよい
Kiroについて
本ワークショップでは、AWSが提供する Kiro というAgentic IDEを使用しました。
Kiroは、複数のAIエージェントが協調して動作する統合開発環境です。
従来のIDE(統合開発環境)とは異なり、開発者がプロンプトで指示を出すと、AIエージェントが自律的にコードの実装、テスト、ドキュメント作成などを行います。
体験記 1日目
初日はガイダンスを受けた後、早速テーマ決めからスタートしました。
今回はユーザー向けのWeb画面ではなく、管理者向け画面を作成する方針で進めることになりました。
ユーザーストーリー作成
主な作業はユーザーストーリーの作成です。
ここからは Kiro を使用し、AIと対話しながら、サンプルプロンプトに沿ってユーザーストーリーを具体化していきます。
作業期間は2日間と限られているため、着手する機能はある程度絞る必要があります。
AWSJの方からは「この時点でユーザーストーリーは10〜15程度に絞っておくと良い」とアドバイスをいただきました。
また、ここからはプロンプト内にある質問に答えていく必要があります。
回答の際、グループワークではなく個人作業になりがちです。
しかしビジネスサイドとエンジニアサイドで目線合わせをするためにも、メンバー内で意見を交わすことが重要だと感じました。
こちらはユーザーストーリーを作成した際のKiroの画面です。画像右側で対象ユーザーが洗い出されていることがわかります。
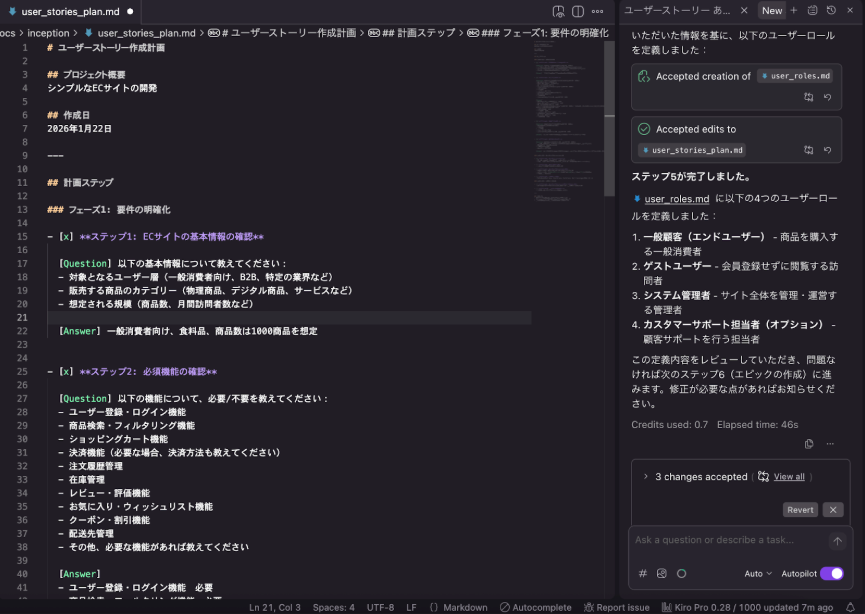
ユーザーストーリーを作成したKiroの画面
ユニット分割作業
次の工程に向けて、チームをユニットに分ける準備を行います。
私たちのチームでは、フロントエンド(以下FE)チームとバックエンド(以下BE)チームに分かれる形を選択しました。
サンプルプロンプトを活用し、作成済みのユーザーストーリーを各ユニットに振り分けていきます。
コンテキストマップ・API設計書の作成
ユーザーストーリーをもとに、コンテキストマップとAPI設計書を作成します。
コンテキストマップはドメイン駆動設計(DDD)に沿った形で作成し、ユニット間の関係性を図式化するための内容を出力しました。
ここでは図で表されたユニット間の紐付けが正しい状態・関係性になっているかレビューを実施しました。
API設計書は、私たちのチームはOpenAPI形式で作成しました。
ここでは各APIのyamlファイルが出力され、API間の依存関係などもREADMEファイルとして出力されました。
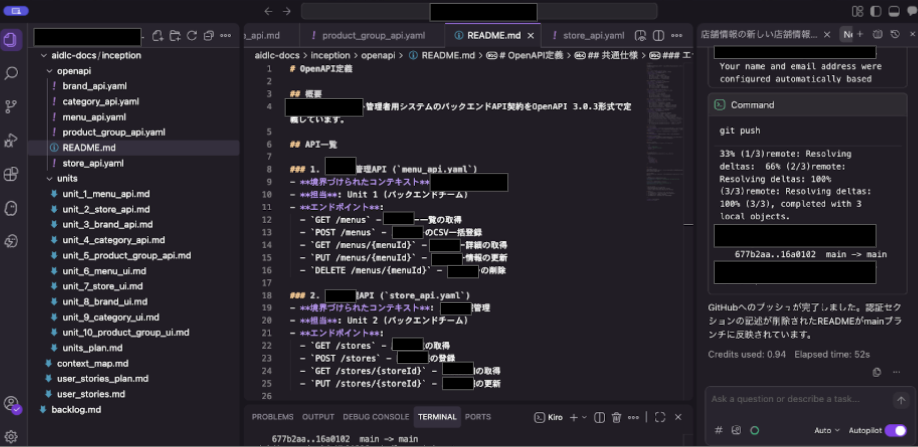
API設計を作成した際のREADMEファイル
体験記 2日目
FE・BEの実装
2日目からは、いよいよ実装フェーズに入ります。
私はBEチームとして参加しました。
ユニットごとに割り当てられたユーザーストーリーとAPI設計書をもとに、実装を進めていきます。
同時に、テストコードやドキュメントも生成されるため、レビュー対象の成果物は一気に増加します。
基本的な作業の流れは下記の通りです。
- ドメイン設計
- 論理設計作成
- コード実装
それぞれのチームに分かれる前にフレームワーク・言語・ディレクトリ構成などの共通ルールを設定しました。
後にマージした際のエラーを防ぐためです。
また、AWSJの方のアドバイスで、実装のフェーズではKiroを使用する際はオートモードではなく用途に合わせて適切なモデルを手動で切り替えて選択することを推奨されていました。
仕様とソースコードの理解が求められる工程のため、非エンジニアである私にとっては難易度の高いフェーズでした。
AIエージェントAの成果物をAIエージェントBでレビューさせることはできますが、いずれにせよ人間が成果物の品質の担保をしなければならないため、最終的な判断は必ず人間が行う必要があります。
そのため、AI主体の開発とはいえ、ソースコードを理解できるメンバーがチームの半数以上いる状態が望ましいと感じました。
反省点として、このあたりからレビュー量が急増し、「たぶんこれでOK」 「とりあえず問題なさそう」といった、やや曖昧な確認が増えてしまった点があります。
レビューする成果物を不必要に増やさないためにも「YAGNIの原則」を意識して作業した方が良いとアドバイスをいただきました。
YAGNIとは(You Aren't Gonna Need It)の略称で、「今必要なものだけを実装する」という意味です。
実際の作業を通しても、AIの特性上どうしても共通機能をたくさん作ってしまうため、人間の手で必要なものだけをピックアップしなければなりません。
「何を作らないか」を決めるPMの意思決定が、従来の開発以上に重要だと感じました。
また、ユニットごとの作業で注意すべき点として、最終的に成果物をマージする必要があることが挙げられます。
私たちのチームはFEとBEに分かれていたため、結合テスト時にエラーが発生してしまいました。
エラーの原因は、結合テストの段階でFEとBEの項目名が一致していなかったことです。そのため、正しく項目の値を更新することができませんでした。
最終的にはKiroに項目名を修正させて再度テストを実施し、無事に動作するところまで確認することができました。
最終的な成果物はこちらです。
FEからBEのREST APIを呼び出して基本的なマスタメンテナンス操作が可能になりました。
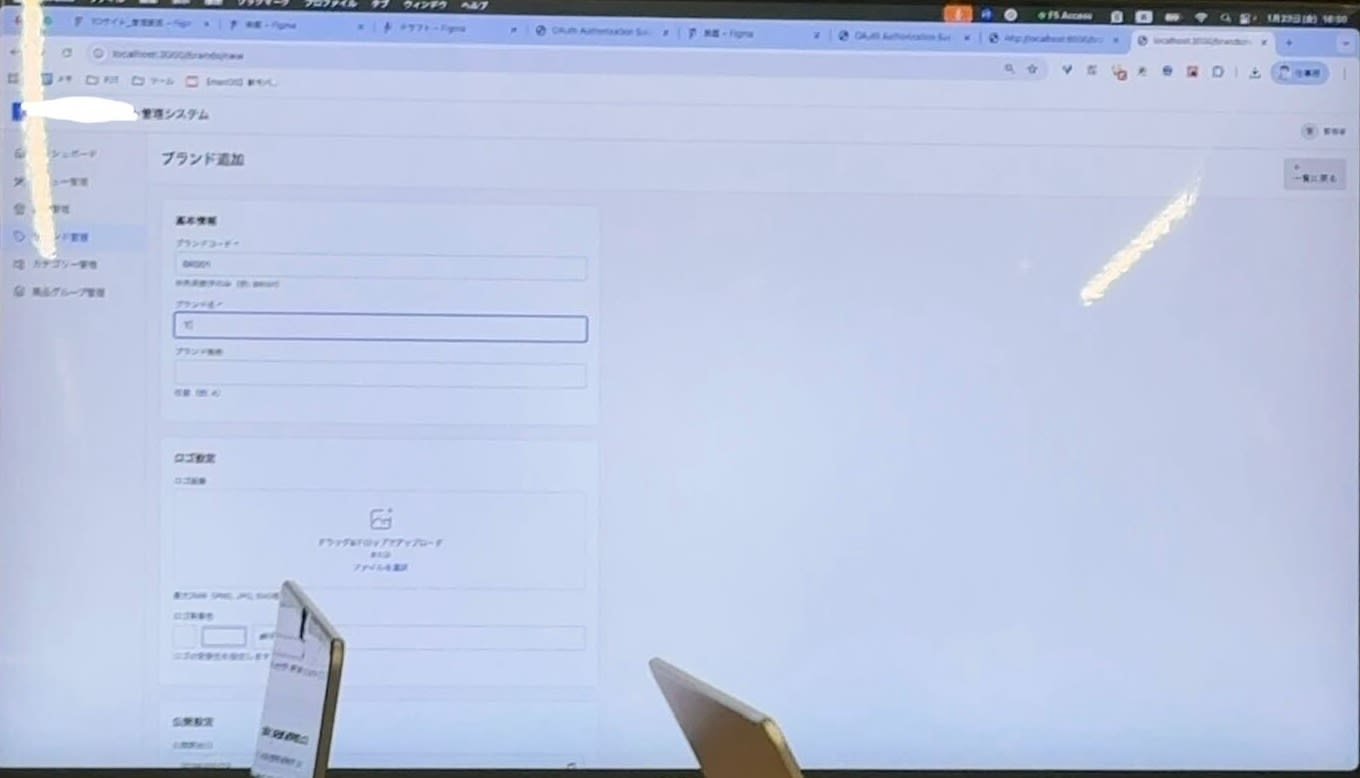
最終的に完成した管理画面
全体を通して
2日間を通して、AI活用の可能性と難しさの両方を実感しました。
今後に活かせそうな点
- まっさらな状態から要件を整理する際に、AIは非常に有効
- ドキュメントをコンテキストとして与えることで、仕様変更時に複数資料を同時に修正できる点は非常に便利
難しいと感じた点
- 企業独自の用語や仕様をAIに正確に理解させるのは難しい
- 複雑で多岐にわたるシステムを短期間で作り上げるには相応の時間が必要
今回のワークショップを通して、要件定義から結合テストまでをAI主体で進めるという、非常に貴重な経験を得ることができました。









