![[アップデート] AWS Resilience Hub v2 がリリースされ、生成AIベースの障害モード分析や依存関係の自動検出が可能になりました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e90f2d5df93382d762eade0c5c825299/23a404c74b6ff29c464743064259e87a/amazon-resilience-hub?w=3840&fm=webp)
[アップデート] AWS Resilience Hub v2 がリリースされ、生成AIベースの障害モード分析や依存関係の自動検出が可能になりました
いわさです。
AWS Resilience Hub は、AWS 上のアプリケーションのレジリエンス(耐障害性)を評価・改善するためのサービスです。
RTO(目標復旧時間)や RPO(目標復旧時点)を定義し、アプリケーションがそれらの目標を満たしているかを評価する機能を提供しています。
従来の Resilience Hub では、アプリケーション単位で1つの RTO/RPO ポリシーを設定し、静的なルールベースのチェックで評価を行う仕組みでした。
先日、AWS Resilience Hub の次世代版(Next generation)が一般提供開始されました。
コンソールの URL が /resiliencehub/v2/home になっているので、この記事では v2 と呼ぶことにします。
v2 では、アプリケーションモデルの刷新、生成AIベースの障害モード分析、依存関係の自動検出、モジュラーなレジリエンスポリシー、AWS Organizations 統合による組織全体のレポーティングなど、大幅な機能強化が行われています。
以前に Resilience Hub については何度か記事を書いています。[1] [2]
今回こちらを確認してみたので紹介します。
コンソールを確認してみる
まずはコンソールの変化を確認してみます。
本日時点では v1 と v2 のコンソールが両方とも利用可能な状態でした。
URL が異なっており、v1 は /resiliencehub/home、v2 は /resiliencehub/v2/home です。
v2 のコンソールはこんな感じです。
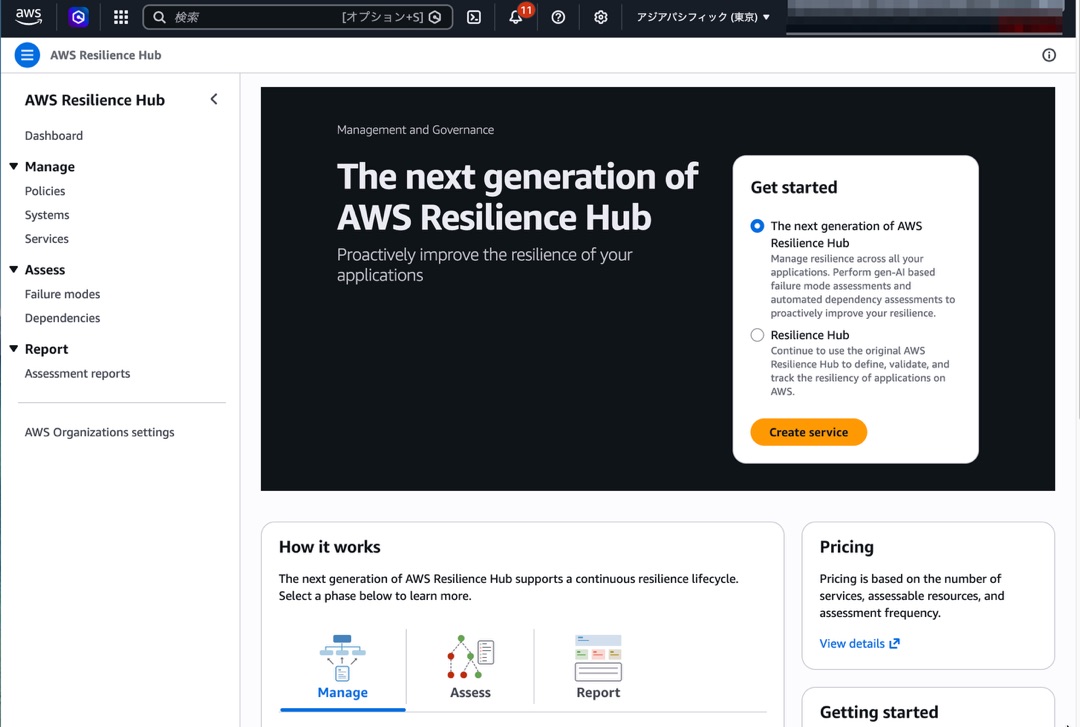
左メニューの構成が大きく変わっています。
- Manage: Policies / Systems / Services
- Assess: Failure modes / Dependencies
- Report: Assessment reports
- AWS Organizations settings
「Get started」パネルでは「The next generation of AWS Resilience Hub」と「Resilience Hub」(v1)を選択できるラジオボタンがあり、本日時点ではここから v1 に切り替えることもできるようです。
Dashboard を開くと「Resilience dashboard」が表示されます。
Organization summary として Services monitored / Services assessed / Total failure mode results / Total dependencies が一覧で確認でき、Account / Policy / System / User journey / Time range でフィルタリングできるようになっています。
また「Service assessment results」ではレジリエンスポリシーのコンポーネントごとにフィルタリングした評価結果のサマリーが表示されるようです。
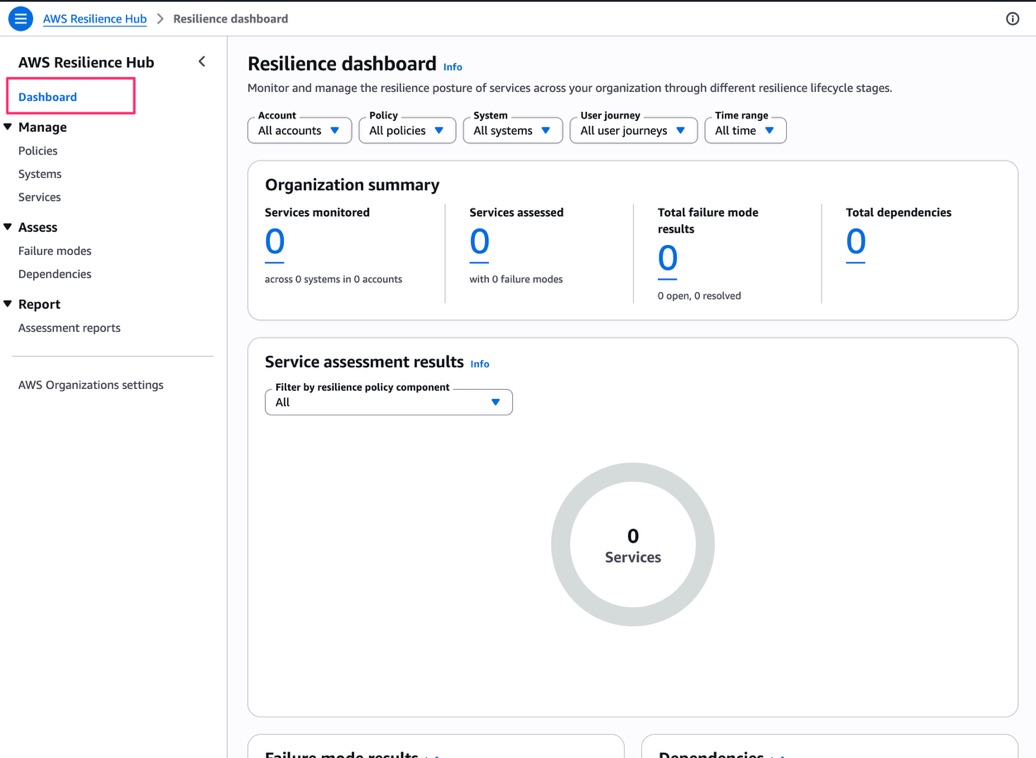
他のメニューを開くと各リソースのー一覧が表示されます。
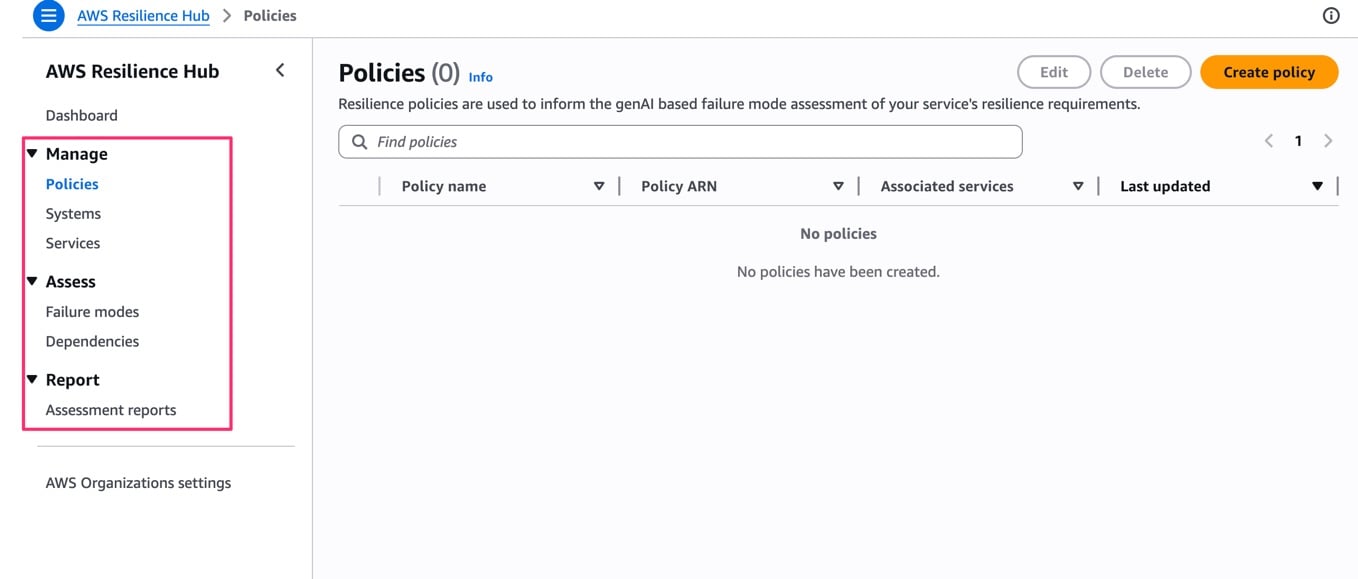
v1 のコンソールはこちら。
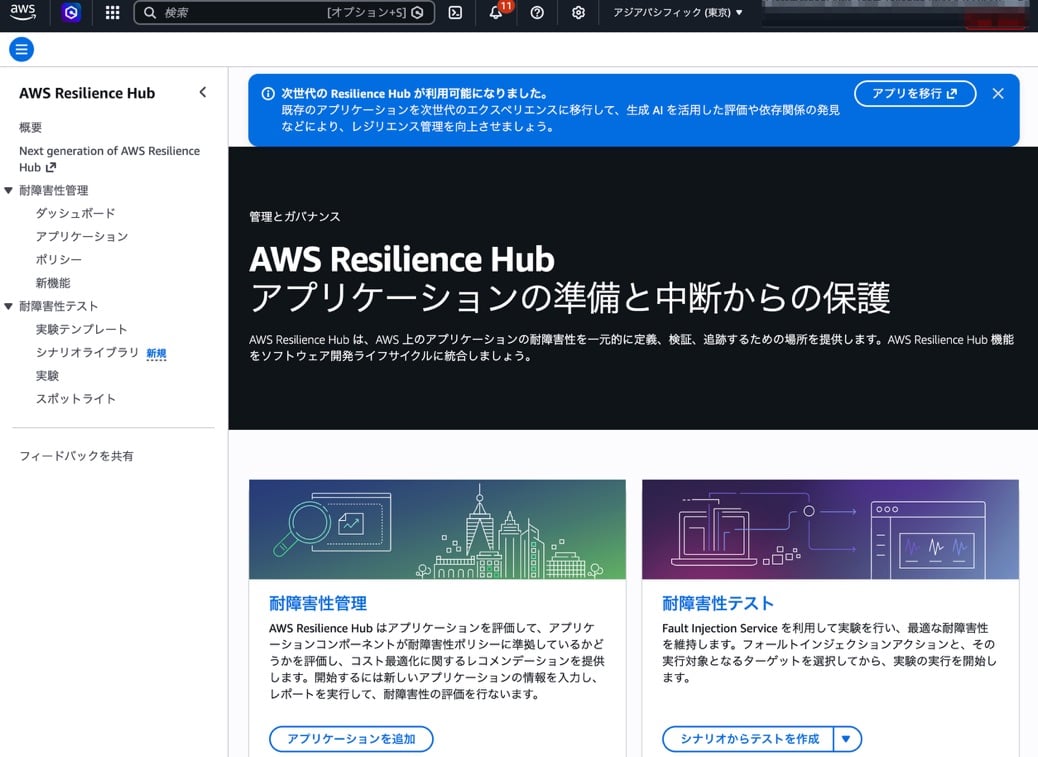
上部に「次世代の Resilience Hub が利用可能になりました」という青いバナーが表示されており、「アプリを移行」ボタンから v2 への移行が案内されています。
メニュー構成を見比べると、v2 では v1 にあった「耐障害性テスト」(FIS 連携の実験機能)のメニューがなくなっていて、代わりに「Failure modes」「Dependencies」という評価系の機能に置き換わっています。
また、v1 の「アプリケーション」が v2 では「Systems」と「Services」に分かれているのも大きな変更点ですね。
v1 の廃止予定は?
気になるのは v1 がいつまで使えるのかという点です。
公式ドキュメントのマイグレーションガイドを確認してみましたが、本日時点では v1 の明確な廃止日(End of Support)のアナウンスは見つけられませんでした。
公式ドキュメントのマイグレーションガイドには「transition period」という表現があり、この移行期間中は v1 の API や評価結果に引き続きアクセスできるとのことです。
v1 assessment results are not automatically migrated to the next generation of Resilience Hub format. v1 results remain accessible through v1 APIs during the transition period.
ただしこの移行期間がいつまでなのかは明記されていないようです。
v1 コンソールに移行バナーが出ている状態なので、いずれは v1 が廃止される方向だとは思いますが、急いで移行しなければならないという状況ではなさそうですね。
Resilience Hub v2 をドキュメントベースで紐解く
v2 で何が変わったのか、公式ドキュメントのマイグレーションガイドに新旧比較表が掲載されているので整理してみます。
| 領域 | v1 | v2 |
|---|---|---|
| コアの単位 | Application | System + Services |
| 評価エンジン | 静的ルールベースのチェック | 生成AIベースの障害モード分析 |
| 依存関係の可視化 | なし | 依存関係の自動検出 |
| マルチアカウント | 限定的 | AWS Organizations 完全統合 |
| ポリシー | アプリケーションごとに1つの RTO/RPO ポリシー | 複数の要件を組み合わせ可能なポリシー(DR + 可用性 + データ復旧) |
| API バージョン | /v1 | /v2 |
主な変更点を見ていきます。
アプリケーションモデルの刷新
従来は「Application」が唯一の単位でしたが、v2 では以下の階層構造に変わっています。
- System: ビジネスアプリケーション全体を表す
- User Journey: 重要なビジネスパス(エンドユーザーの操作フロー)を表す
- Service: デプロイ可能な単位(マイクロサービスなど)。AWS リソース、コード、オブザーバビリティを含む
公式ドキュメントによると、v1 の「Application」は v2 の「Service」に相当するとのことです。
The v1 concept of an "application" maps to a "service" as the primary unit of assessment. Services are grouped within systems, and user journeys describe the paths through them.
v1 ではアプリケーション単位でしか評価できませんでしたが、v2 では System の中に複数の Service をまとめることで、ビジネスアプリケーション全体のレジリエンスを俯瞰しつつ、個々のマイクロサービス単位で評価・管理できるようになっています。
また User Journey でエンドユーザーの操作フローを定義し、そのフローに関わる Service 群に対してポリシーを適用できるので、「このビジネスフローは 99.99% を維持したい」のような要件の表現がしやすくなっているみたいです。
生成AIベースの障害モード分析
v1 では静的なルールベースのチェックで「RTO/RPO を満たせるか」を判定していましたが、v2 では生成AIがアーキテクチャ全体を分析して障害モード(どのような障害が起きうるか)を特定し、対処方法まで提案してくれるようになっています。
分析のベースとなっているのは Well-Architected ベストプラクティスと AWS Resilience Analysis Framework です。
Resilience Analysis Framework は AWS が公開しているレジリエンス分析の方法論で、以前に記事を書いたことがあります。
つまり、v1 では「設定した RTO/RPO を満たせるかどうか」の合否判定だけだったのが、v2 では「そもそもどんな障害が起きうるのか」を洗い出して「どう対処すべきか」まで提案してくれるようになった、ということですね。
依存関係の自動検出
VPC の DNS クエリログを分析して、AWS サービス・内部エンドポイント・サードパーティエンドポイントへの依存関係を自動的に検出する機能が追加されています。
例えば、あるサービスが意図せず別リージョンのエンドポイントを呼び出していたり、把握していないサードパーティ API に依存していたりするケースを発見できるみたいです。
障害時に「実はこの外部サービスが落ちたのが原因だった」みたいな事態を事前に把握しておけるのは嬉しいですね。
ポリシーの柔軟な構成
従来は1つのアプリケーションに対して RTO/RPO を1つ設定するだけでしたが、v2 では以下の要件を組み合わせてポリシーを構成できます。
- SLO(サービスレベル目標): 可用性の目標値(例: 99.95%)
- Multi-AZ / Multi-Region の DR 要件: RTO、RPO、DR 戦略
- データ復旧要件: バックアップからの復旧時間目標
AWS Organizations 統合
委任管理者アカウントから組織全体のレジリエンス状況を一元管理できるようになっています。
個別のアカウントにログインせずに、組織横断でレジリエンスの評価・レポーティングが可能とのこと。
マイグレーション時の制約
なお、公式ドキュメントによると、v1 から v2 への移行にはいくつかの制約があるみたいです。
| 制約 | 説明 |
|---|---|
| 評価履歴 | v1 の評価結果は v2 のフォーマットに自動移行されない |
| カスタムレジリエンスチェック | v1 のカスタムチェックは移行されない |
| AppRegistry 入力ソース | v2 では AppRegistry が入力ソースとして未サポート |
気になる料金
v2 の料金体系も確認してみます。
旧版の料金については以前記事を書いたことがあります。
公式ドキュメントに新旧の料金比較表が掲載されています。
| 項目 | v1 | v2 |
|---|---|---|
| 基本料金 | $15/アプリケーション/月 | $15/サービス/月 |
| 評価回数 | 無制限 | 月2回まで含む |
| リソース超過 | なし | 1評価あたり150リソース超で $0.10/リソース |
| 依存関係検出 | なし | $10/サービス/月(オプション) |
基本料金の $15 は据え置きですが、課金単位が「アプリケーション」から「サービス」に変わっています。
公式ドキュメントによると、150リソース以下で月2回以下の評価であれば、ほとんどの場合は同額になるとのこと。
The $15 entry price is preserved. Most customers (services with 150 or fewer resources using 2 or fewer assessments per month) pay the same amount.
依存関係検出はオプションで $10/サービス/月が追加されます。
また、v1 では評価回数が無制限だったのに対し、v2 では月2回までが基本料金に含まれる形になっている点は注意が必要ですね。
機能検証
では実際に v2 の機能を検証してみます。
今回は既存の API Gateway + Lambda のサーバーレスアプリケーション(CloudFormation スタック)を対象に、ポリシー作成 → システム/サービス作成 → 障害モード評価の一連の流れを試してみました。
レジリエンスポリシーの作成
まずはポリシーを作成してみます。
v2 のコンソールで左メニューの「Policies」から「Create policy」を選択します。
ポリシー作成画面では、Policy name と Description を入力した後、「Resilience requirements」セクションで以下の3つの要件を任意に組み合わせて選択できます。
- Availability Service Level Objective (SLO)
- Disaster recovery requirements
- Data recovery requirements
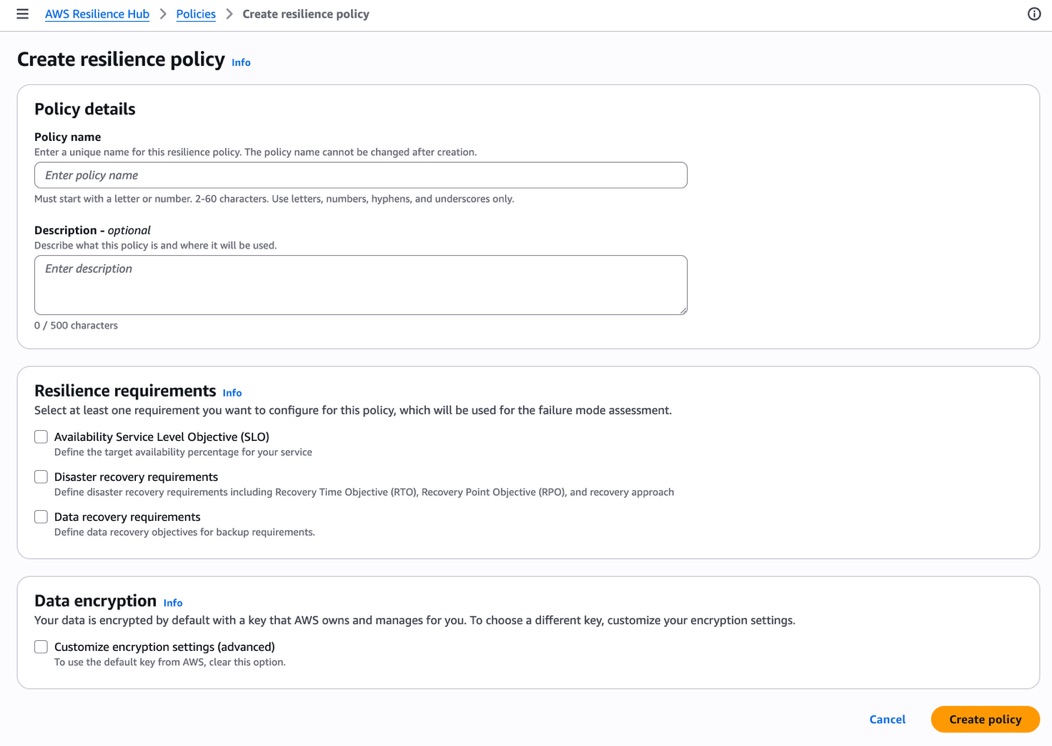
従来はアプリケーションに対して単一の RTO/RPO を設定するだけでしたが、v2 ではこれらを組み合わせて柔軟にポリシーを構成できるようになっています。
また、Data encryption セクションで KMS キーのカスタマイズも可能です。
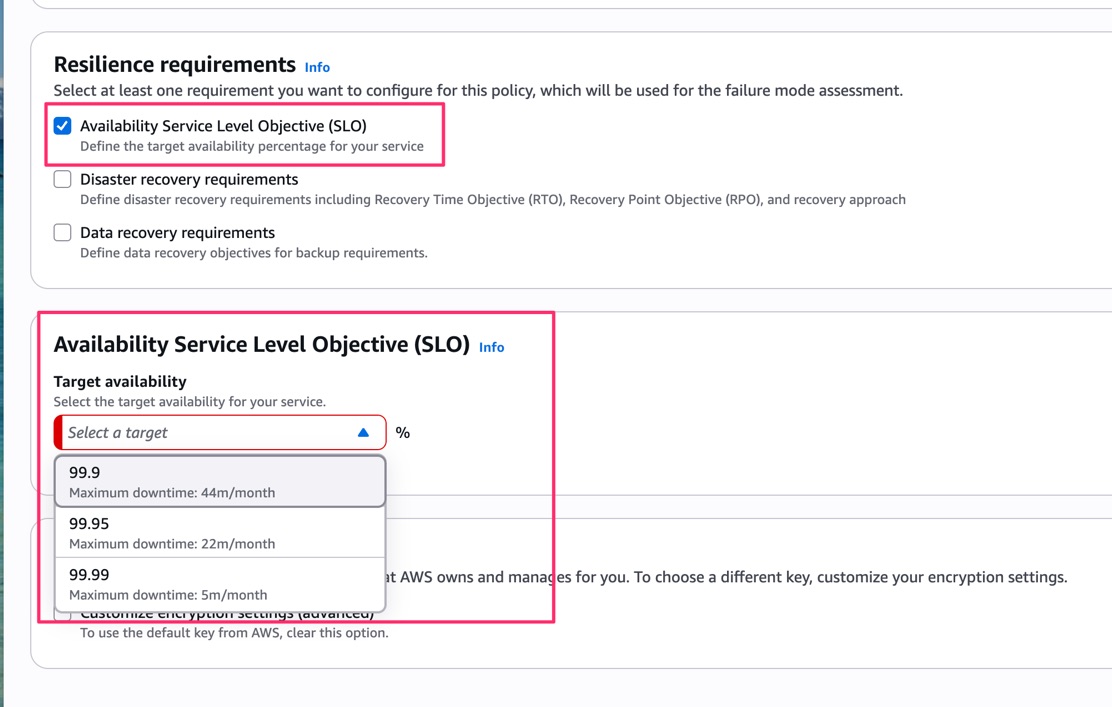
Availability Service Level Objective (SLO)
SLO を選択すると、ターゲットの可用性をドロップダウンから選択できます。
選択肢は 99.9%(Maximum downtime: 44m/month)、99.95%(22m/month)、99.99%(5m/month)が用意されていました。
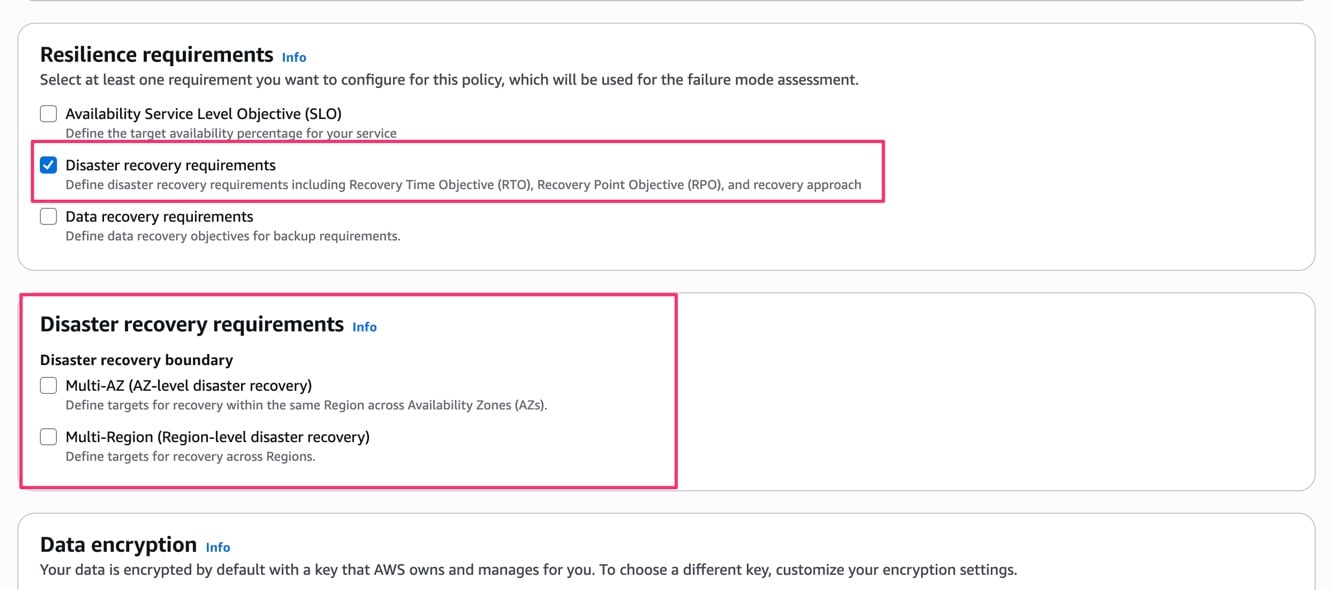
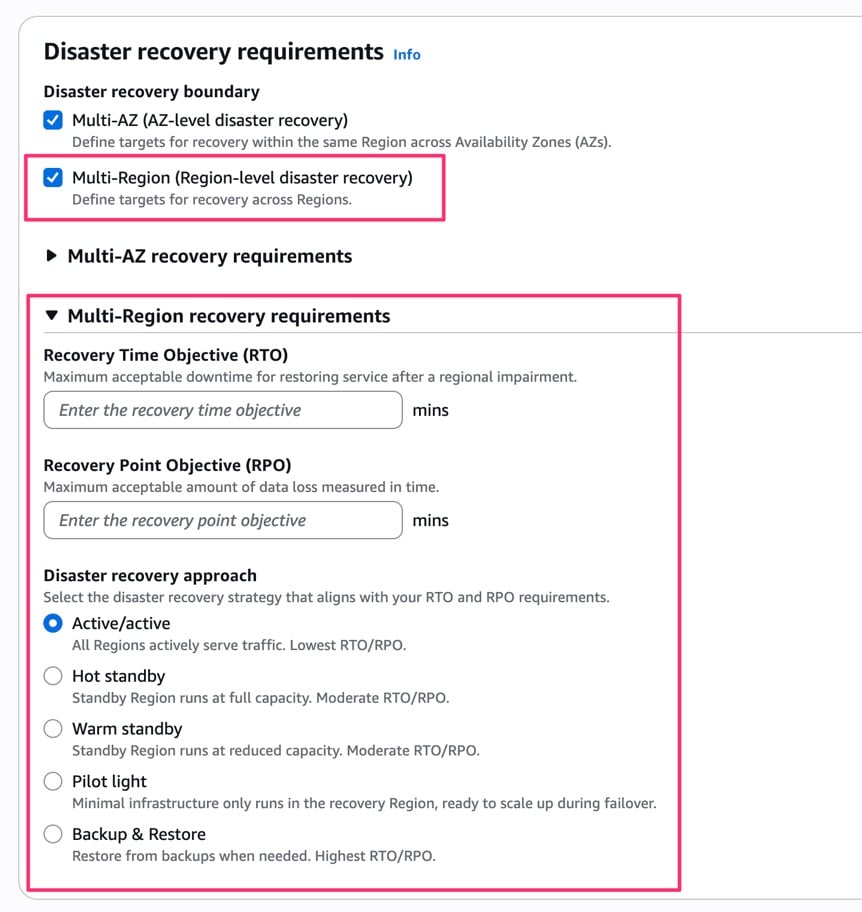
Disaster recovery requirements
DR 要件を選択すると、DR の境界として Multi-AZ(AZ レベルの DR)と Multi-Region(リージョンレベルの DR)を選択できます。
両方同時に選択することも可能です。
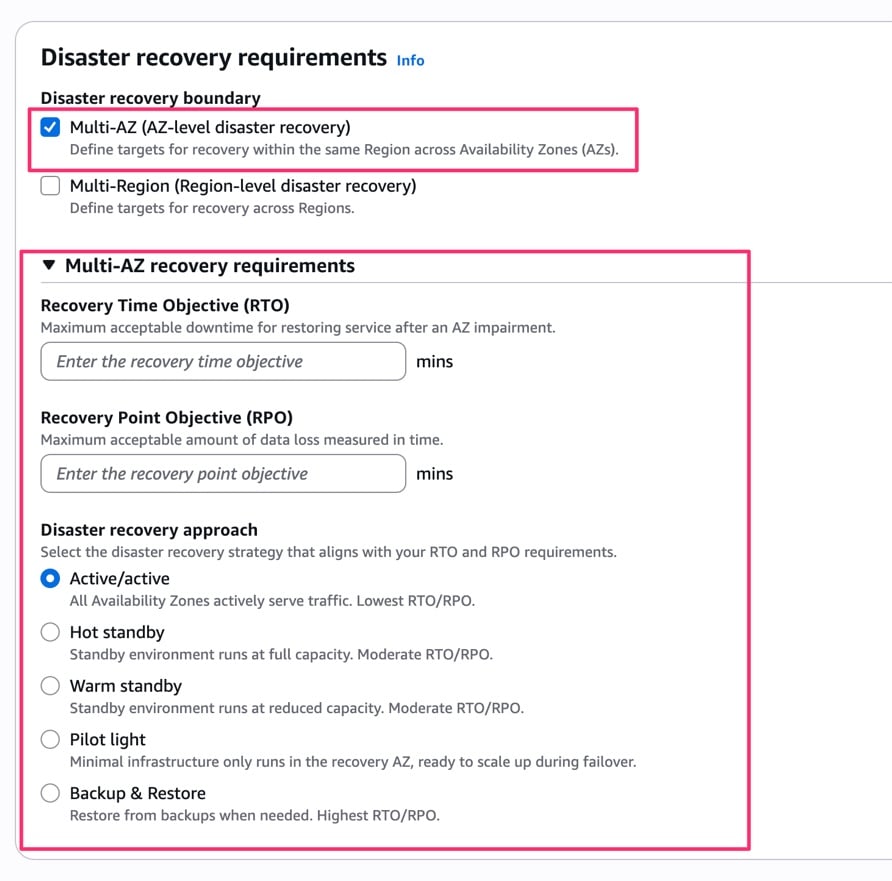
Multi-AZ を選択した場合は、RTO(分単位)、RPO(分単位)、DR 戦略を設定します。
DR 戦略は以下の5つから選択できます。よく言われてるやつですね。
- アクティブ/アクティブ: すべての AZ がアクティブにトラフィックを処理。最も低い RTO/RPO
- ホットスタンバイ: スタンバイ環境がフルキャパシティで稼働。中程度の RTO/RPO
- ウォームスタンバイ: スタンバイ環境が縮小キャパシティで稼働。中程度の RTO/RPO
- パイロットライト: 最小限のインフラのみ復旧 AZ で稼働。フェイルオーバー時にスケールアップ
- バックアップ&リストア: バックアップから復元。最も高い RTO/RPO
Multi-Region を選択した場合も同様の構成で、RTO/RPO と DR 戦略を設定します。
こちらはリージョンレベルの説明になっています。
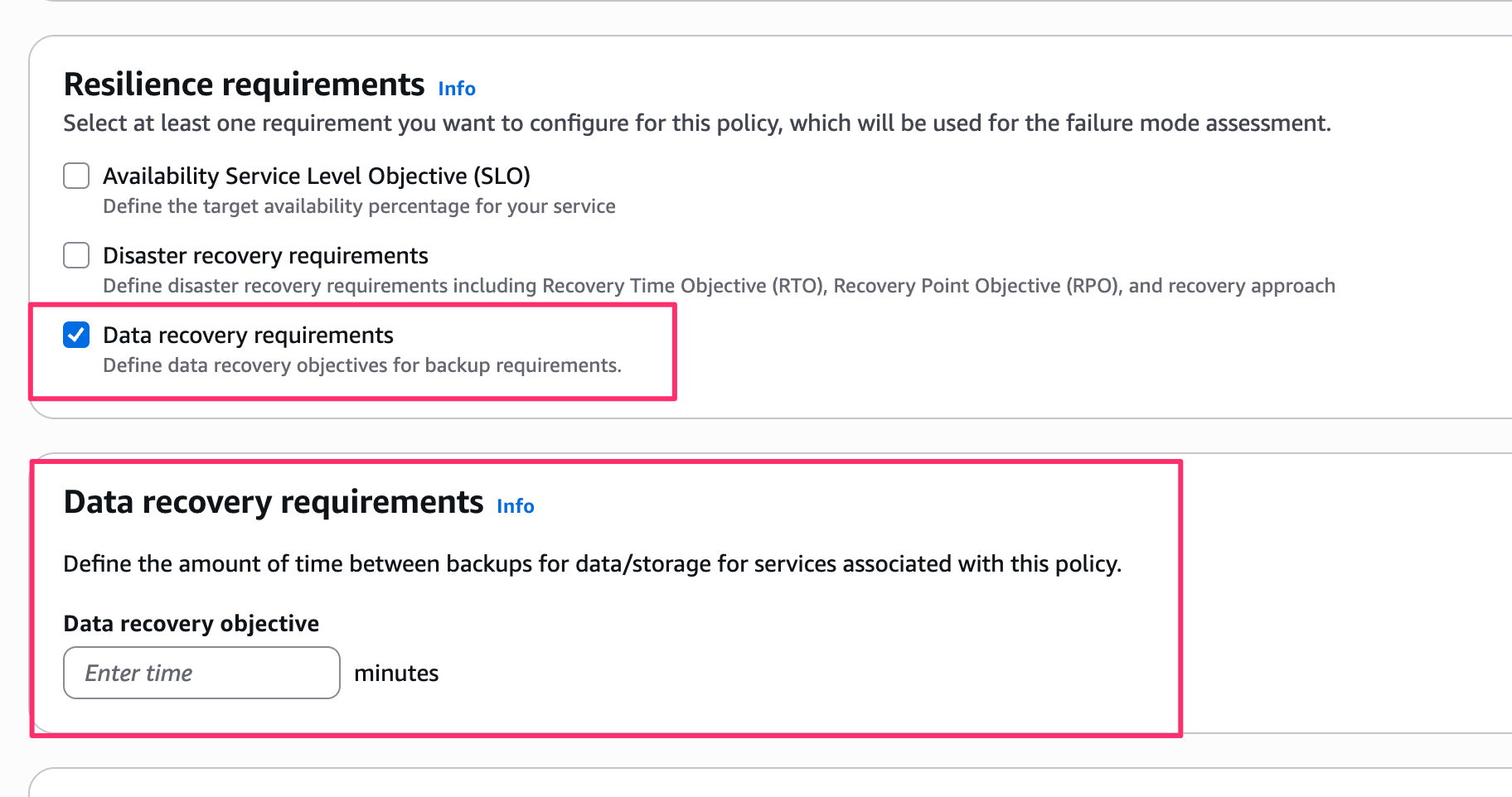
Data recovery requirements
Data recovery requirements を選択すると、Data recovery objective(分単位)を設定します。
サービスに関連するデータやストレージのバックアップ間隔の目標を定義するもので、ポリシーに含めておくことで障害モード評価時にバックアップ戦略の妥当性も合わせてチェックしてくれるようです。
ポリシー作成完了
今回は全ての要件を選択して、以下の設定でポリシーを作成してみました。
- SLO: 99.99%(Maximum downtime: 5m/month)
- Multi-AZ: RTO 60分 / RPO 60分 / Active/active
- Data recovery objective: 60分
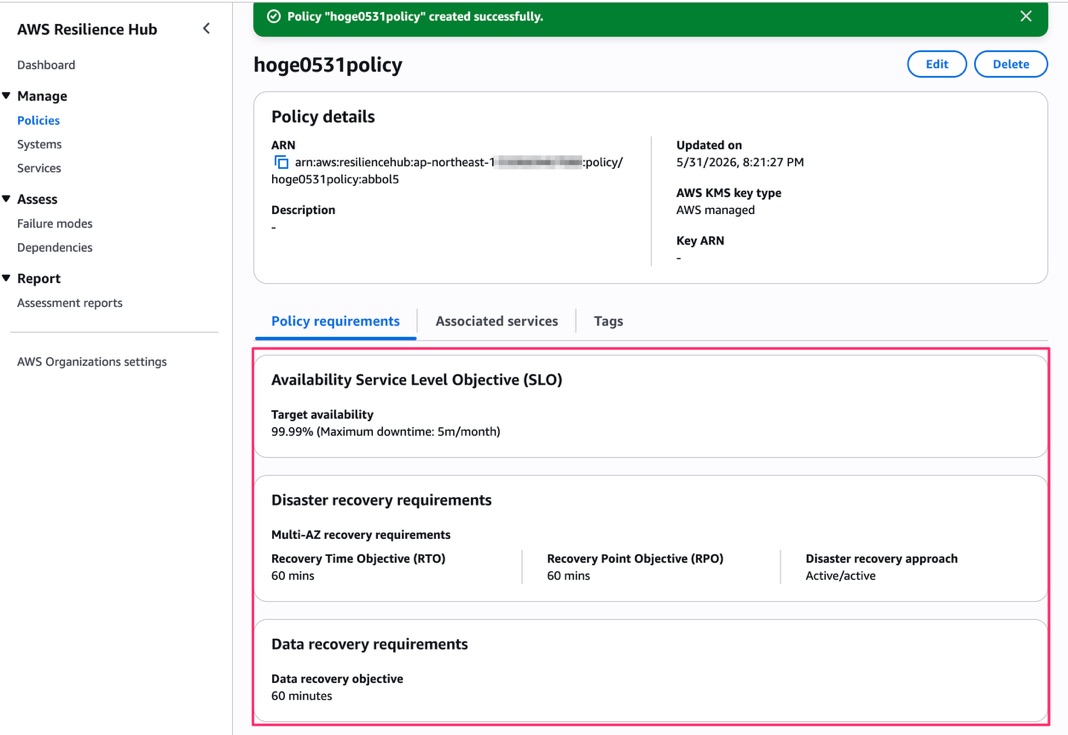
ポリシーの詳細画面では「Policy requirements」「Associated services」「Tags」のタブが表示されます。
設定した要件が一覧で確認できますね。
システムの作成
次にシステムを作成します。
左メニューの「Systems」から「Create system」を選択します。
システム作成画面では System name、Description、AWS Organizations access(Enable access)、Data encryption を設定します。
Organizations access を有効にすると、組織内のアカウントからこのシステムに関連するリソースやポリシーにアクセスできるようになるみたいです。
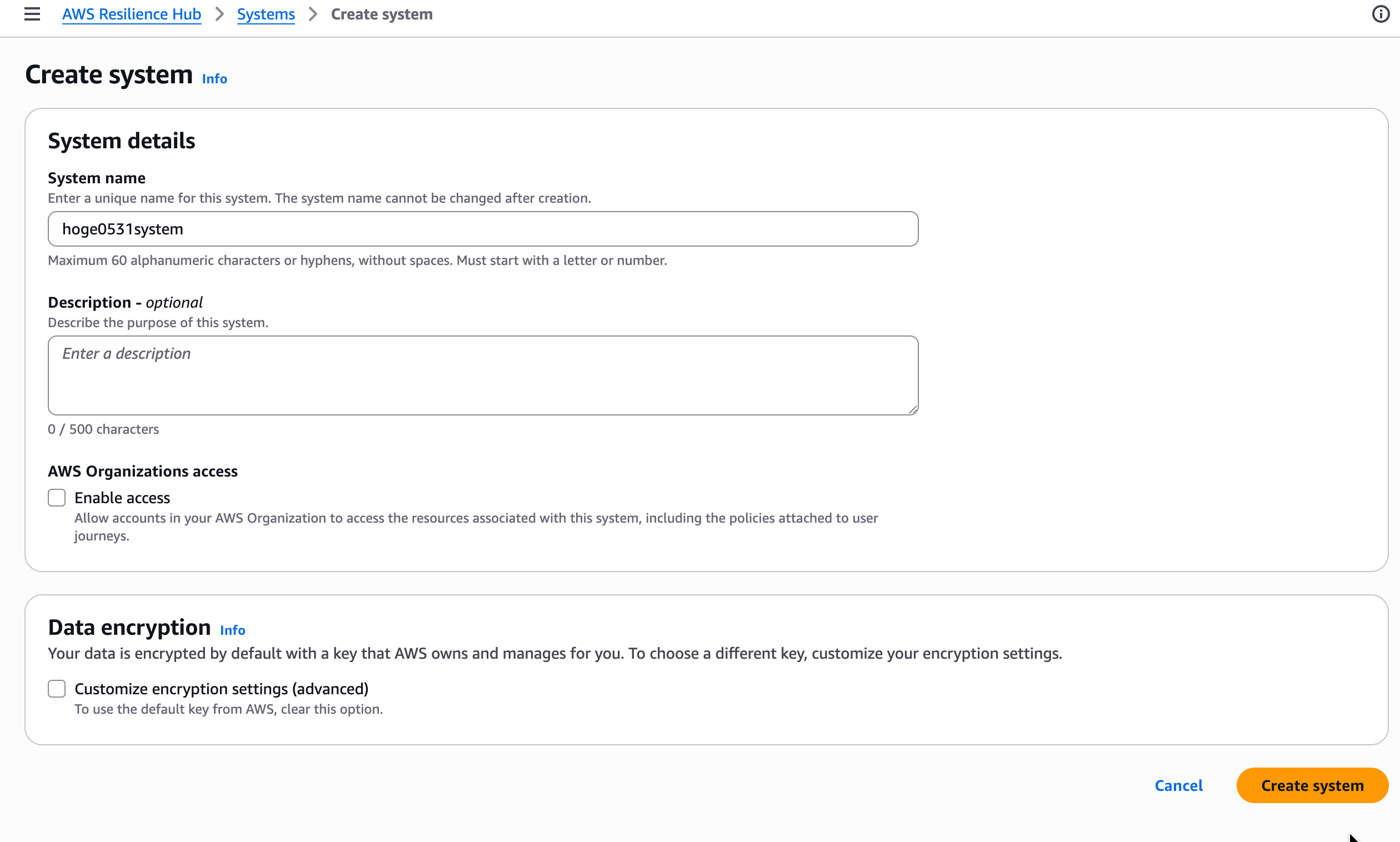
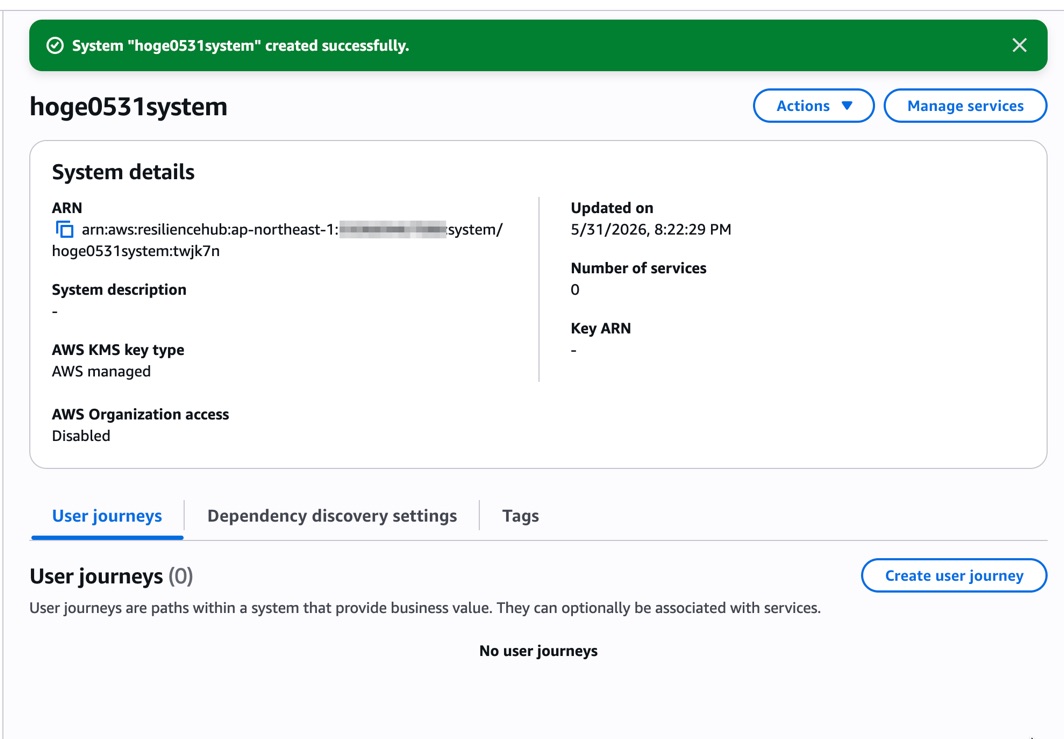
システムが作成されると、詳細画面に「User journeys」「Dependency discovery settings」「Tags」のタブが表示されます。
「Manage services」ボタンからサービスを関連付けることもできます。
User Journey の作成
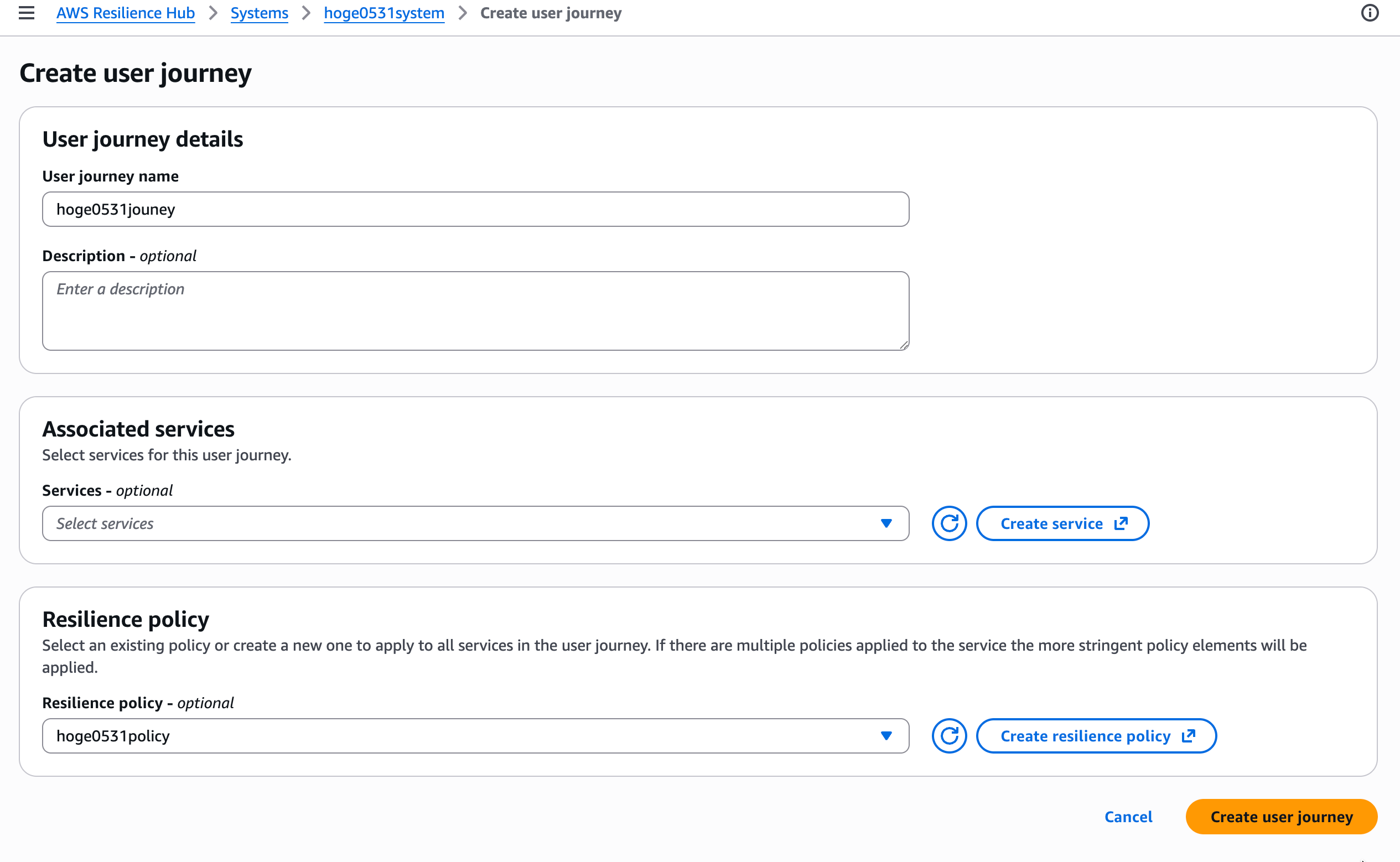
システムの中に User Journey を作成することもできます。
User Journey はビジネス価値を提供するパス(エンドユーザーの操作フロー)を表すもので、サービスとポリシーを関連付けることができます。
なお、複数のポリシーがサービスに適用される場合は、より厳格なポリシー要素が適用されるとのこと。
サービスの作成
次にサービスを作成します。
左メニューの「Services」から「Create service」を選択します。
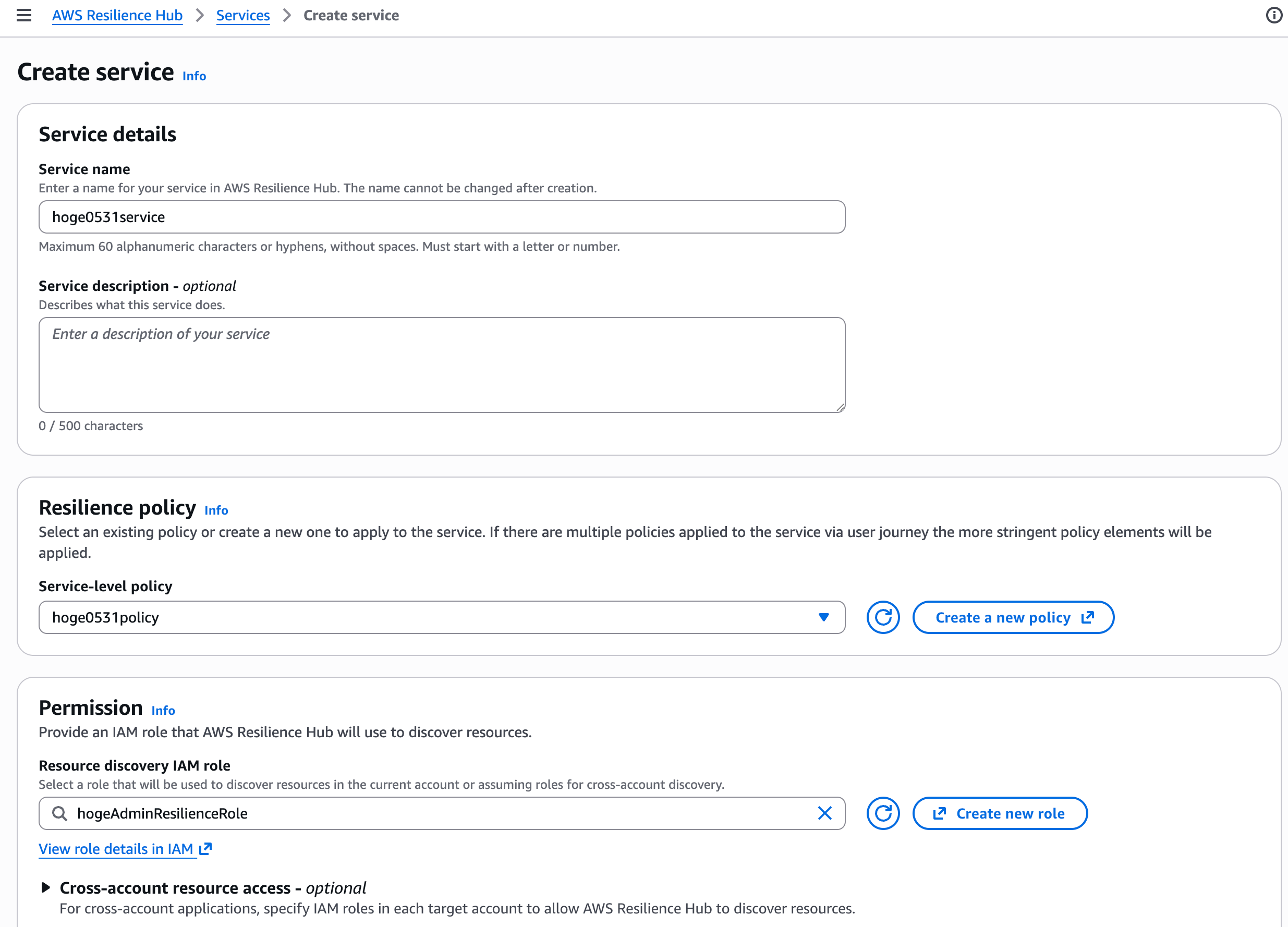
サービス作成画面では以下を設定します。
- Service name / Description
- Resilience policy: 先ほど作成したポリシーを選択(Service-level policy)
- Permission: Resource discovery IAM role(リソース検出に使う IAM ロール)
- Cross-account resource access(オプション)
続いて、Service architecture セクションで Service Regions を選択し、Service resource discovery でリソースの検出方法を選択します。
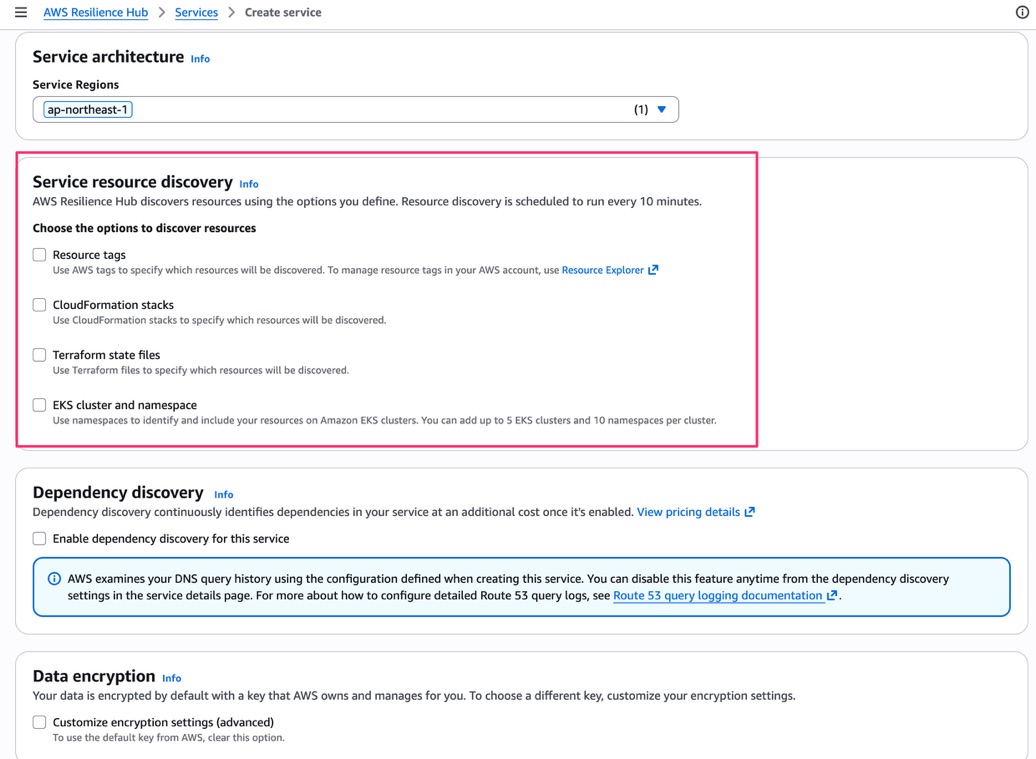
リソース検出は10分ごとにスケジュール実行されるとのこと。
選択肢は以下の4つです。
- Resource tags
- CloudFormation stacks
- Terraform state files
- EKS cluster and namespace(最大5クラスター、クラスターあたり10ネームスペース)
また、Dependency discovery セクションで依存関係検出を有効にすることもできます。
有効にすると追加料金が発生する旨と、Route 53 のクエリログを使って DNS クエリ履歴を分析する旨が記載されています。
今回は CloudFormation スタック(API Gateway + Lambda のサーバーレスアプリケーション)を入力ソースとして指定しました。
サービス作成完了と Service resilience lifecycle
サービスが作成されると、詳細画面に「Service resilience lifecycle」が表示されます。
ライフサイクルは3つのフェーズで構成されています。
- Define: サービスの定義。ポリシーの関連付けとリソース検出
- Assess: 障害モード評価。AWS Resilience Analysis Framework と生成AIを活用
- Test: サービスの応答テスト。「Coming soon...」と表示されており、まだ利用できないようです
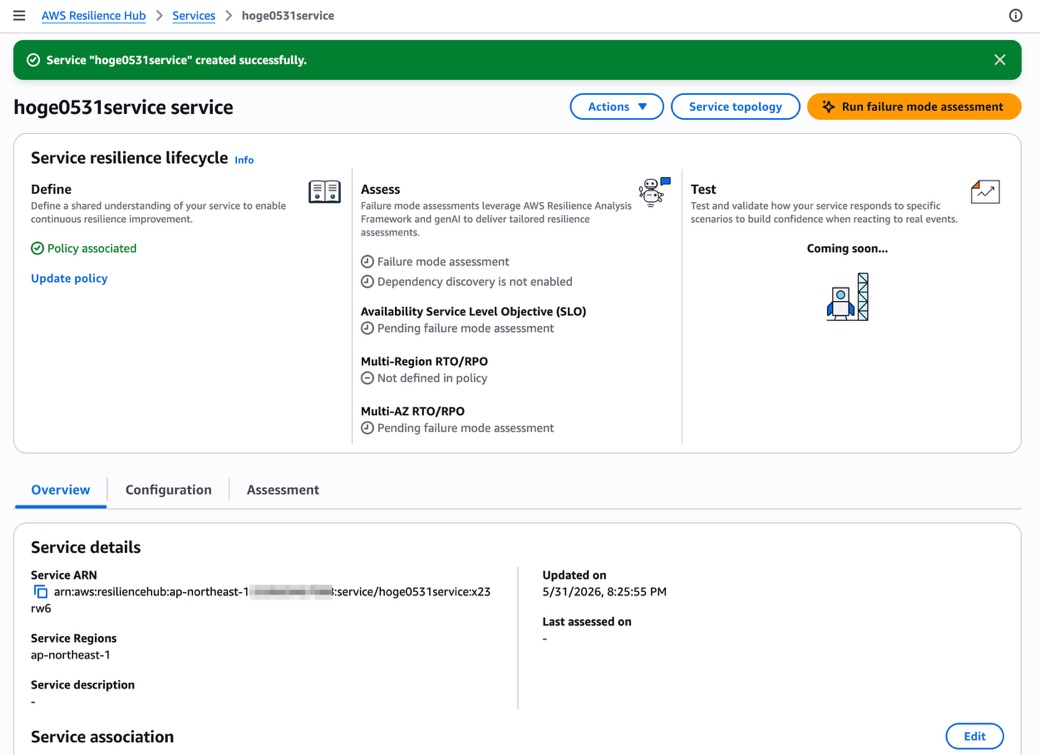
「Define」フェーズでは「Policy associated」と「Resource discovery succeeded」が緑のチェックマークで表示されています。
「Assess」フェーズでは各ポリシーコンポーネントの評価状態が表示されており、この時点では「Pending failure mode assessment」となっています。
Multi-Region RTO/RPO はポリシーに定義していないので「Not defined in policy」と表示されていますね。
なお、「Test」フェーズが Coming soon になっているのが気になります。
v1 では FIS 連携の実験機能がありましたが、v2 のこのテストフェーズが同じものなのか、あるいは別の仕組みなのかは現時点ではわかりません。
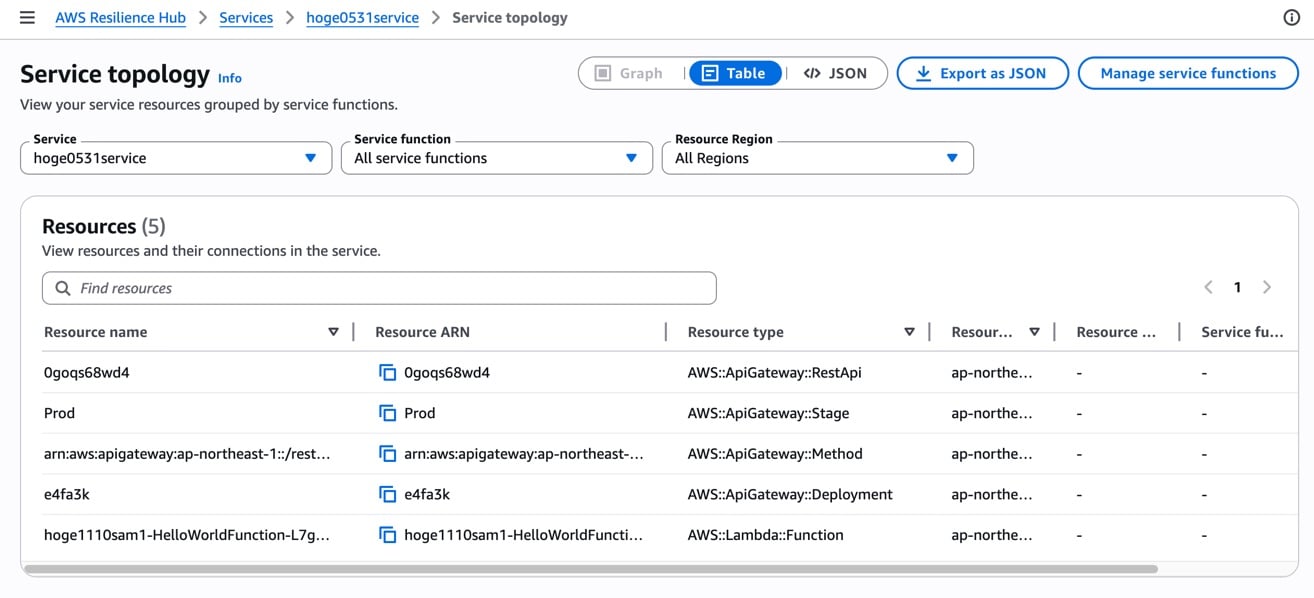
サービストポロジー
「Service topology」ボタンからリソースのトポロジーを確認できます。
Graph / Table / JSON の3つの表示形式が用意されています。
今回は Table 表示で確認してみました。
CloudFormation スタックから検出された5つのリソース(API Gateway の RestApi / Stage / Method / Deployment と Lambda Function)が表示されています。
障害モード評価の実行
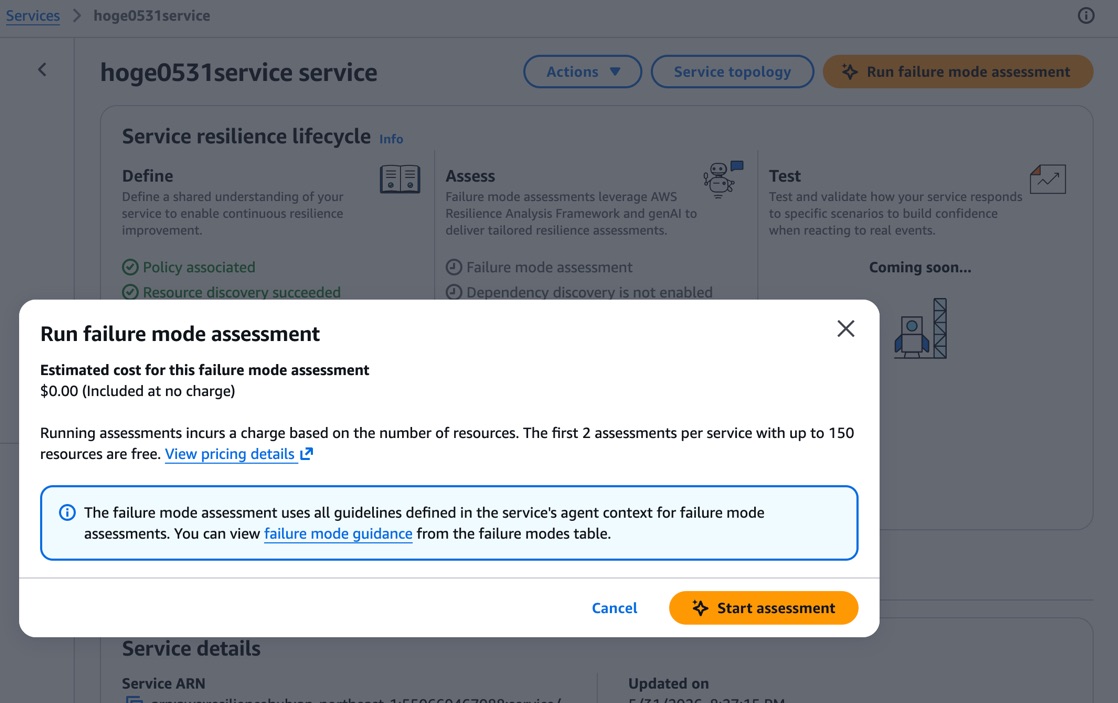
いよいよ障害モード評価を実行してみます。
「Run failure mode assessment」ボタンをクリックすると、確認ダイアログが表示されます。
ダイアログには「Estimated cost for this failure mode assessment: $0.00 (Included at no charge)」と表示されており、月2回までの評価は無料で含まれていることがわかります。
また「The failure mode assessment uses all guidelines defined in the service's agent context for failure mode assessments.」という説明もあり、Failure mode guidance で定義したガイドラインが評価に使われるとのこと。
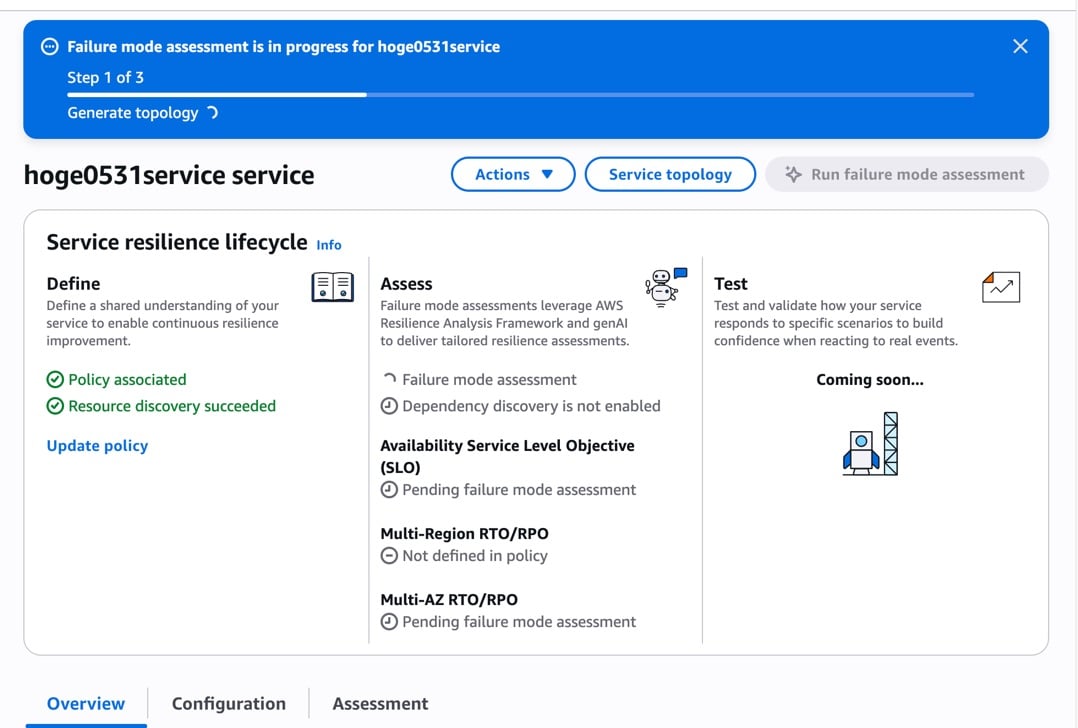
「Start assessment」をクリックすると評価が開始されます。
上部に「Failure mode assessment is in progress for hoge0531service」というバナーが表示され、「Step 1 of 3: Generate topology」と進捗が表示されます。
評価結果の確認
評価が完了すると「Assessment completed successfully.」のバナーが表示されます。
Service resilience lifecycle の「Assess」フェーズに結果が反映されています。
- Availability Service Level Objective (SLO): Not achievable(赤)
- Multi-Region RTO/RPO: Not defined in policy
- Multi-AZ RTO/RPO: Achievable(緑)
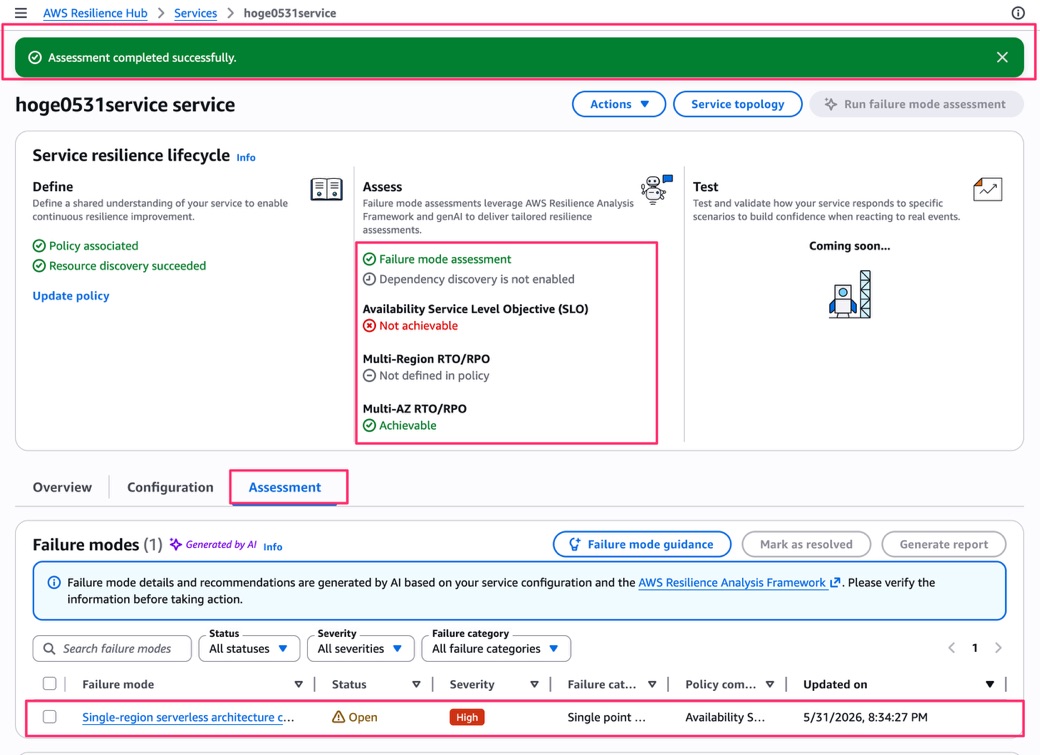
「Assessment」タブを開くと「Failure modes (1)」として検出された障害モードが一覧表示されます。
「Generated by AI」のラベルが付いており、生成AIによる分析結果であることが明示されています。
検出された障害モードは以下でした。
- Failure mode: Single-region serverless architecture c... / Status: Open / Severity: High / Failure category: Single point of failure / Policy component: Availability SLO
障害モードの詳細
検出された障害モードの詳細を開いてみます。
タイトルは「Single-region serverless architecture cannot achieve 99.99% availability SLO」で、Severity は High、Failure category は「Single point of failure」です。
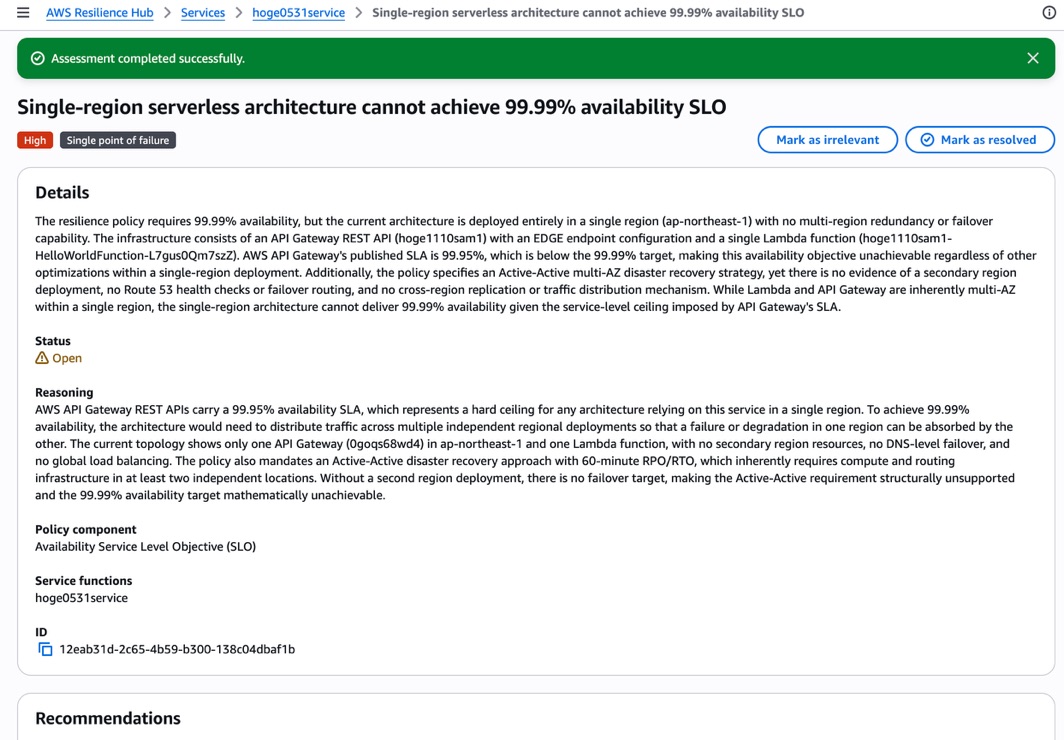
Details セクションには、現在のアーキテクチャが単一リージョンにデプロイされており、マルチリージョンの冗長性やフェイルオーバー機能がないこと、API Gateway の公開 SLA が 99.95% であるため単一リージョンでは 99.99% の可用性目標を達成できないことが説明されています。
Reasoning セクションでは、より詳細な分析が記載されています。
API Gateway REST API の SLA が 99.95% であること、99.99% を達成するには複数の独立したリージョンにトラフィックを分散する必要があること、現在のトポロジーには1つの API Gateway と1つの Lambda 関数しかなく、セカンダリリージョンのリソースや DNS レベルのフェイルオーバー、グローバルロードバランシングがないことなどが具体的に指摘されています。
なるほど、ポリシーで設定した SLO(99.99%)に対して、API Gateway の SLA 上限(99.95%)を根拠に「達成不可能」と判定しているわけですね。
レコメンデーション
障害モードの詳細画面の下部に「Recommendations」セクションがあり、「Mitigations」「Observability」「Testing」の3つのタブが用意されています。
Mitigations タブの「Implementation option 1」には以下の推奨事項が記載されていました。
- 2つ目の AWS リージョン(例: us-east-1)に API Gateway REST API と Lambda 関数スタックの複製をデプロイし、Active/Active マルチリージョンアーキテクチャを構築する
- Amazon Route 53 のヘルスチェックとレイテンシーベースまたはフェイルオーバールーティングを設定し、両リージョンのエンドポイントにトラフィックを分散する
- Global Accelerator または CloudFront ディストリビューションを実装し、自動リージョンフェイルオーバーを備えた単一エントリポイントを提供する
- あるいは、可用性 SLO を 99.99% から 99.95% に引き下げ、単一リージョンの API Gateway デプロイメントで達成可能な上限に合わせる
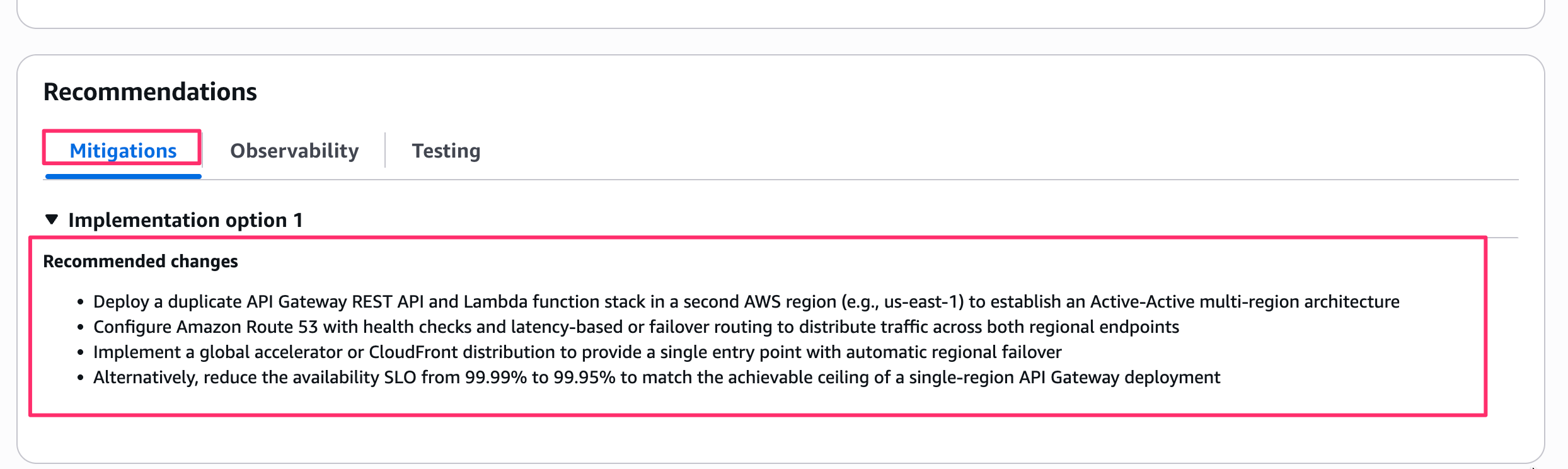
最後の選択肢として「SLO を下げる」という提案も含まれています。
「Mark as irrelevant」「Mark as resolved」ボタンで、各 Finding の対応状況を管理できるようになっています。
さいごに
本日は AWS Resilience Hub v2 がリリースされたので確認してみました。
従来の静的ルールベースのチェックから生成AIベースの障害モード分析に進化し、アプリケーションモデルも「System + Service」の階層構造に刷新されています。
サービスごととかユーザーフローごとに目標値設定できたりとか、どんな障害が考えられるのかまで考察してくれたりとかなんかかなり良さそうです。進化してますね。
実際に API Gateway + Lambda のシンプルなサーバーレスアプリケーションで試してみたところ、API Gateway の SLA(99.95%)を根拠に「99.99% の SLO は単一リージョンでは達成不可能」と論理的に判定してくれました。
単純なルールチェックではなく、サービスの SLA を考慮した上で論理的に判断しているのは従来の静的チェックとは明らかに異なるレベルの分析だなと感じました。
ただ今回はシンプルな構成だったので「構造的に SLO を満たせない」という指摘にとどまっていました。
マルチ AZ でデータベースやキャッシュを含むような複雑な構成であれば、もっと具体的な障害シナリオ(「ここが単一障害点になっている」等)が出てくるのかもしれません。別途試してみたい。
一方で「Test」フェーズが Coming soon になっている点は気になります。
どんなテスト機能が使えるようになるのだろう。楽しみです。FIS へのリンクが配置されるとかだけだったら笑っちゃう。
料金面では基本料金 $15 は据え置きですが、評価回数が月2回までになった点と、依存関係検出がオプション $10 追加になる点は把握しておきたいところですね。
v1 の廃止時期は明確にアナウンスされていないので、既存ユーザーは慌てず移行計画を立てられそうです。
正直なところ、v1 の Resilience Hub の普及具合はいまいちだなぁと感じていました。私は好きだったんですけどね。
以前コンソールに「使えてますか?」的なアンケートが出ていたこともあり、このままサービス廃止もあり得るのかな...と心配もしてました。
今回これだけ大幅に刷新されたということは、AWS としてもこのサービスに力を入れていく方向なのかな、Resilience Hub 先生の次回作に期待したいです。











