![[アップデート] AWS Batch でジョブ完了後のインスタンス終了タイミングを制御できるようになりました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-1e1fd76bc503bd5a3c4d1de9b90b16fd/c9ff0ee1442ae0fa3c4563c1f6aca764/aws-batch?w=3840&fm=webp)
[アップデート] AWS Batch でジョブ完了後のインスタンス終了タイミングを制御できるようになりました
はじめに
AWS Batch の EC2 コンピュート環境で、ジョブ完了後のインスタンスの終了タイミングを制御できるようになりました。2026 年 3 月 2 日にリリースされた minScaleDownDelayMinutes パラメーターを使うと、ジョブ完了後もインスタンスを一定時間維持できます。
間欠的なバッチジョブを実行する環境では、ジョブのたびに EC2 インスタンスの起動待ちが発生していました。今回のアップデートにより、次のジョブ投入までインスタンスを待機させておくことでコールドスタートを回避できます。
コンソールでスケールダウン遅延を設定し、従来動作との違いを確認します。
確認結果
minScaleDownDelayMinutes を設定すると、ジョブ完了後もインスタンスが指定時間だけ維持されます。実際に検証したところ、遅延未設定ではジョブ完了後約 42 秒でインスタンスが終了しましたが、20 分に設定した場合は約 22 分間維持されました。
有効な設定範囲は 20〜10,080 分(1 週間)です。0 を指定すると遅延が無効化され、従来どおりの動作になります。遅延中に新しいジョブが実行された場合は、そのジョブ完了時から再度カウントが開始されます。
設定の更新は「スケーリング更新」として高速に反映されます。インスタンスタイプなど他の設定と同時に変更すると「インフラストラクチャ更新」となるため、単独での変更を推奨します。
検証環境
| 項目 | 値 |
|---|---|
| サービス | AWS Batch(EC2 コンピュート環境) |
| リージョン | ap-northeast-1(東京) |
| Allowed instance types | optimal |
| コンテナイメージ | public.ecr.aws/amazonlinux/amazonlinux:2023 |
コンピュート環境の作成
まず、スケールダウン遅延を設定しない状態でコンピュート環境を作成しました。従来動作の確認が目的です。
AWS Batch コンソールから環境を開きました。
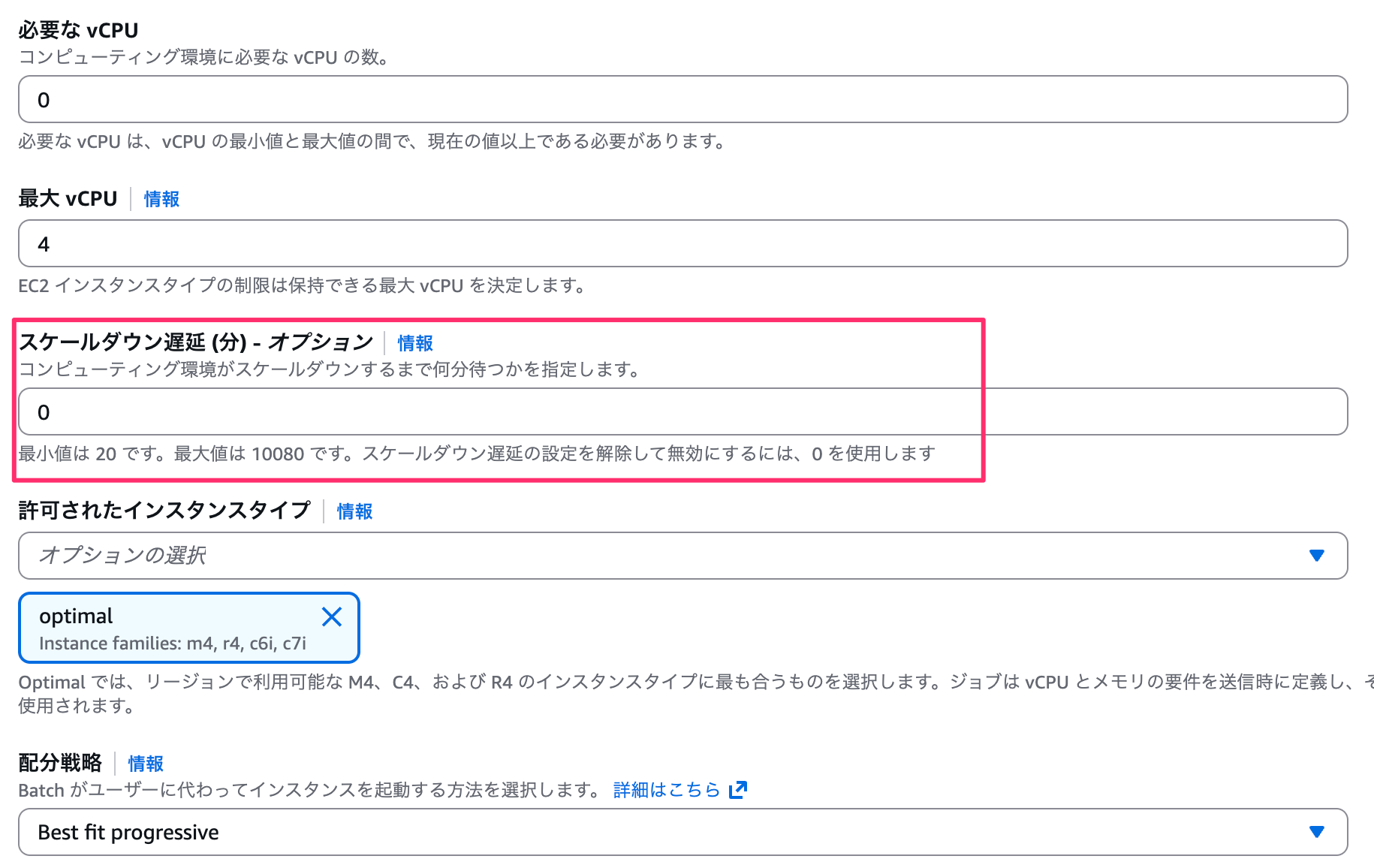
スケールダウン遅延を 0 のままにすることで、従来どおりジョブ完了後にインスタンスが終了される動作になります。
ジョブキューの作成
作成したコンピュート環境を紐づけたジョブキューを作成しました。
ジョブ定義の作成
動作確認用に 30 秒間スリープするだけのジョブ定義を作成します。
| 項目 | 値 |
|---|---|
| Image | public.ecr.aws/amazonlinux/amazonlinux:2023 |
| Command | sleep,30 |
| vCPUs | 1 |
| Memory | 512 MiB |
ジョブ定義の JSON
{
"jobDefinitionName": "sleep-job",
"jobDefinitionArn": "arn:aws:batch:ap-northeast-1:xxxxxxxxxxxx:job-definition/sleep-job:1",
"revision": 1,
"type": "container",
"status": "ACTIVE",
"parameters": {},
"containerProperties": {
"image": "public.ecr.aws/amazonlinux/amazonlinux:2023",
"command": [
"sleep",
"30"
],
"volumes": [],
"environment": [],
"mountPoints": [],
"ulimits": [],
"resourceRequirements": [
{
"value": "1",
"type": "VCPU"
},
{
"value": "512",
"type": "MEMORY"
}
],
"secrets": []
},
"propagateTags": false,
"platformCapabilities": [
"EC2"
],
"containerOrchestrationType": "ECS"
}
スケールダウン動作の比較
従来動作の確認
スケールダウン遅延を設定していない状態でジョブを投入し、従来動作を確認します。
ジョブの実行状況と EC2 の起動確認に Desired vCPUs の推移を確認します。10 秒ごとにポーリングし、今回の検証では以下のタイムラインになりました。
| イベント | 時刻 |
|---|---|
| ジョブ投入 | 10:19:38 |
| RUNNABLE | 10:19:49 |
| Desired vCPUs: 0 → 2 | 10:21:11 |
| STARTING | 10:21:53 |
| RUNNING | 10:22:03 |
| SUCCEEDED | 10:22:34 |
| Desired vCPUs: 2 → 0 | 10:23:16 |
ジョブ完了(10:22:34)から約 42 秒後(10:23:16)にインスタンスが終了しました。従来動作では、ジョブ完了後に速やかにスケールダウンされることがわかります。
スケールダウン遅延の設定
ここからが今回の本題です。コンピュート環境にスケールダウン遅延を設定します。スケールダウン遅延を 20 分に変更しました。
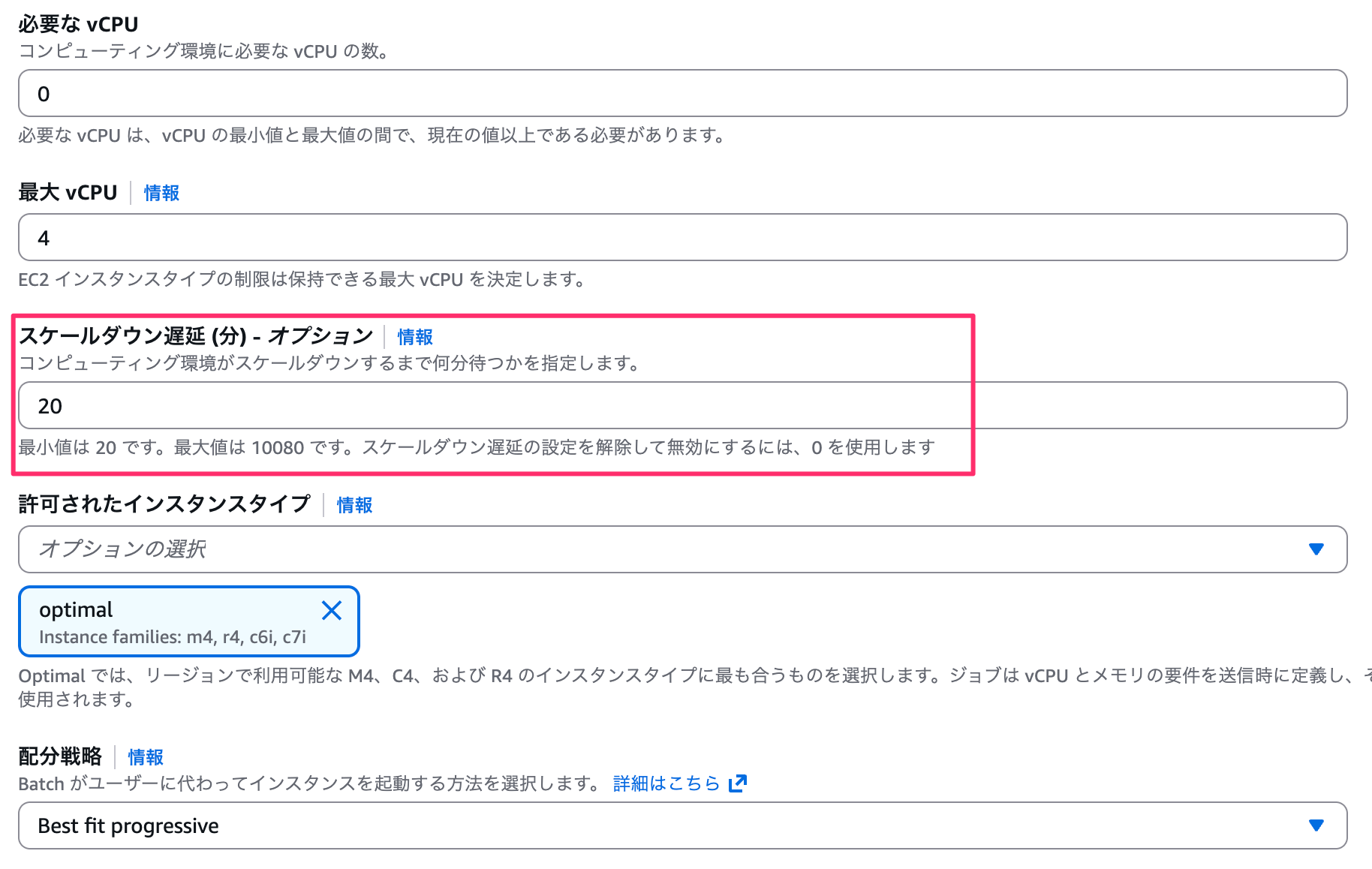
遅延設定後の動作確認
スケールダウン遅延を設定した状態で再度ジョブを投入し、動作の違いを確認します。以下のタイムラインになりました。
| イベント | 時刻 |
|---|---|
| ジョブ投入 | 12:51:24 |
| RUNNABLE | 12:51:35 |
| Desired vCPUs: 0 → 2 | 12:53:28 |
| STARTING | 12:54:10 |
| RUNNING | 12:54:30 |
| SUCCEEDED | 12:54:51 |
| Desired vCPUs: 2 → 0 | 13:16:48 |
従来動作とは異なり、ジョブ完了後もインスタンスが長時間維持されていることがわかります。
ジョブ完了(12:54:51)から約 22 分後(13:16:48)にインスタンスが終了しました。設定値の 20 分に対して約 2 分の上振れがありますが、スケールダウン処理自体のオーバーヘッドと考えられます。
動作確認結果まとめ
| 区間 | 遅延なし | 遅延 20 分 |
|---|---|---|
| 投入 → ジョブ開始 | 約 143 秒 | 約 176 秒 |
| ジョブ実行時間 | 約 30 秒 | 約 30 秒 |
| ジョブ完了 → EC2 終了 | 約 42 秒 | 約 22 分 |
投入からジョブ開始までの差(約 33 秒)は EC2 インスタンス起動タイミングのばらつきです。スケールダウン遅延の影響ではありません。また、コンテナイメージはデフォルトの Amazon Linux2023 を使用しています。巨大なコンテナイメージを利用する場合は、起動時間が長くなります。
スケールダウン遅延の効果が現れるのはジョブ完了から EC2 終了までの区間です。遅延未設定では約 42 秒でインスタンスが終了したのに対し、20 分設定では約 22 分間維持されました。
スケールダウン遅延が適用されないケース
AWS Batch API Reference によると、以下のケースではスケールダウン遅延が適用されません。
- インフラストラクチャ更新中に置換されるインスタンス
- まだジョブを実行していない新規起動インスタンス
- スポットインスタンスの中断
ComputeScalingPolicy - AWS Batch
コスト面の考慮
遅延時間を長く設定するほど、アイドル状態のインスタンスが維持されコストが増加します。ジョブ間の典型的なアイドル時間よりやや長い値を設定するのが目安です。
- アイドル時間が短い場合: 5〜15 分間隔のジョブなら最小値の 20 分で十分(20 分未満は設定不可)
- アイドル時間が長い場合: 数時間おきのジョブに数時間の遅延を設定するとアイドルコストが高くつく
コールドスタートの待ち時間削減とアイドルコストのバランスを見て設定値を決めてください。
まとめ
AWS Batch の minScaleDownDelayMinutes を使い、ジョブ完了後のインスタンス終了タイミングを制御しました。
設定のポイントは以下のとおりです。
- 有効な設定範囲は 20〜10,080 分(1 週間)で、
0で無効化 - EC2 コンピュート環境のみ対応(Fargate は非対応)
minScaleDownDelayMinutesのみの変更はスケーリング更新として高速に反映- 遅延中に新しいジョブが配置されると、そのジョブ完了時から再度カウント開始
間欠的なバッチジョブや大きなコンテナイメージを使うワークロードで、コールドスタートの待ち時間を削減したい場合に有効なアップデートでした。
おわりに
AWS Batch はマネージドサービスなので細かいところは気にしてはいなかったのですが、かゆいところに手が届く良いアップデートでした。AWS PCS や、HyperPod は、インスタンスの終了待ち時間の設定どうなっているのか気になったのでちょっと調べてみようと思います。








