
AWS Glue for SparkからDatabricksのテーブルにアクセスしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部のueharaです。
今回は、AWS Glue for SparkからDatabricksのテーブルにアクセスしてみたいと思います。
※なお、今回DatabricksはServerless SQL Warehouseを利用します。
はじめに
AWS GlueからDatabricksに接続したいことってありますよね。
Glueを使えば、例えばですがS3へのファイルPutイベントを検知し、Sparkを用いてファイルの読み込み・データ変換を行いDatabricksへのデータの書き込みを行う、といったことが容易にできます。
本記事では、Glue (Spark)からDatabricksへの接続を試してみたいと思います。
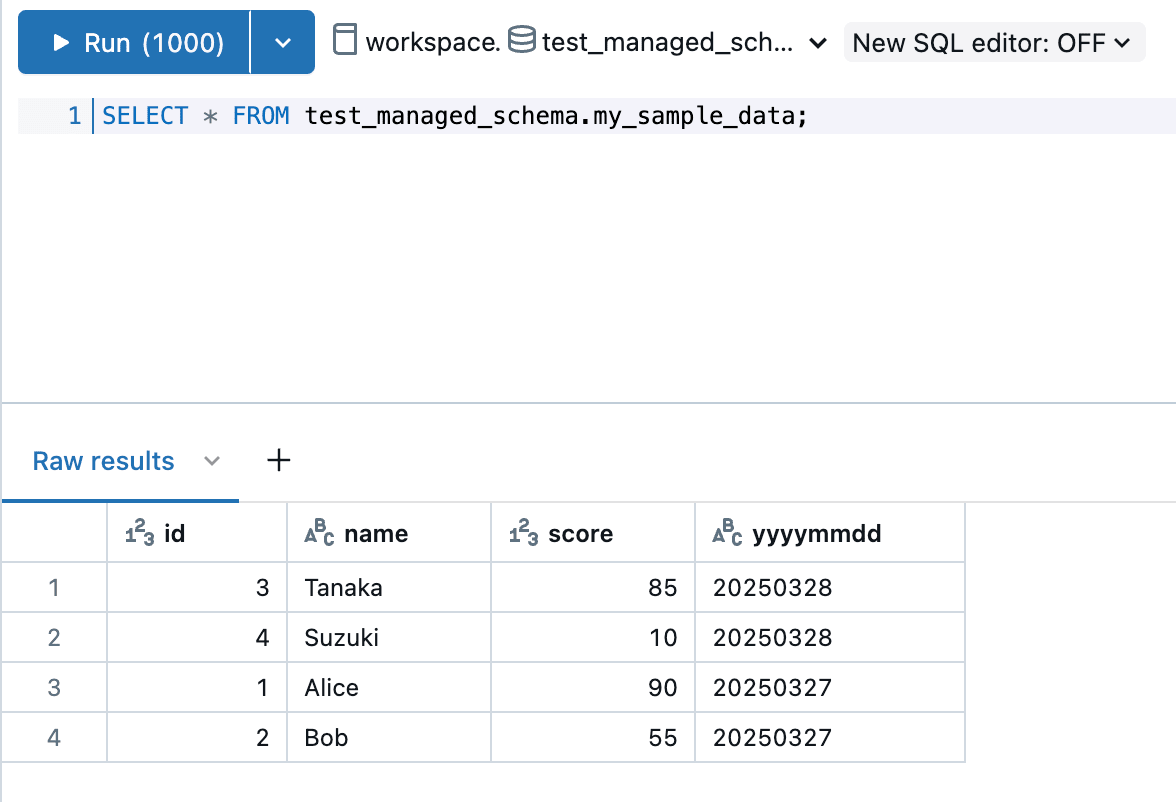
ちなみに、私の手元のDatabricks環境では以下のような test_managed_schema.my_sample_data というテーブルを用意しているので、こちらのテーブルにアクセスしようと思います。
Databricks側の準備
アクセストークンの払い出し
今回、Databricksへの接続はアクセストークンを利用して実施しますので、まずアクセストークンの払い出しを行います。
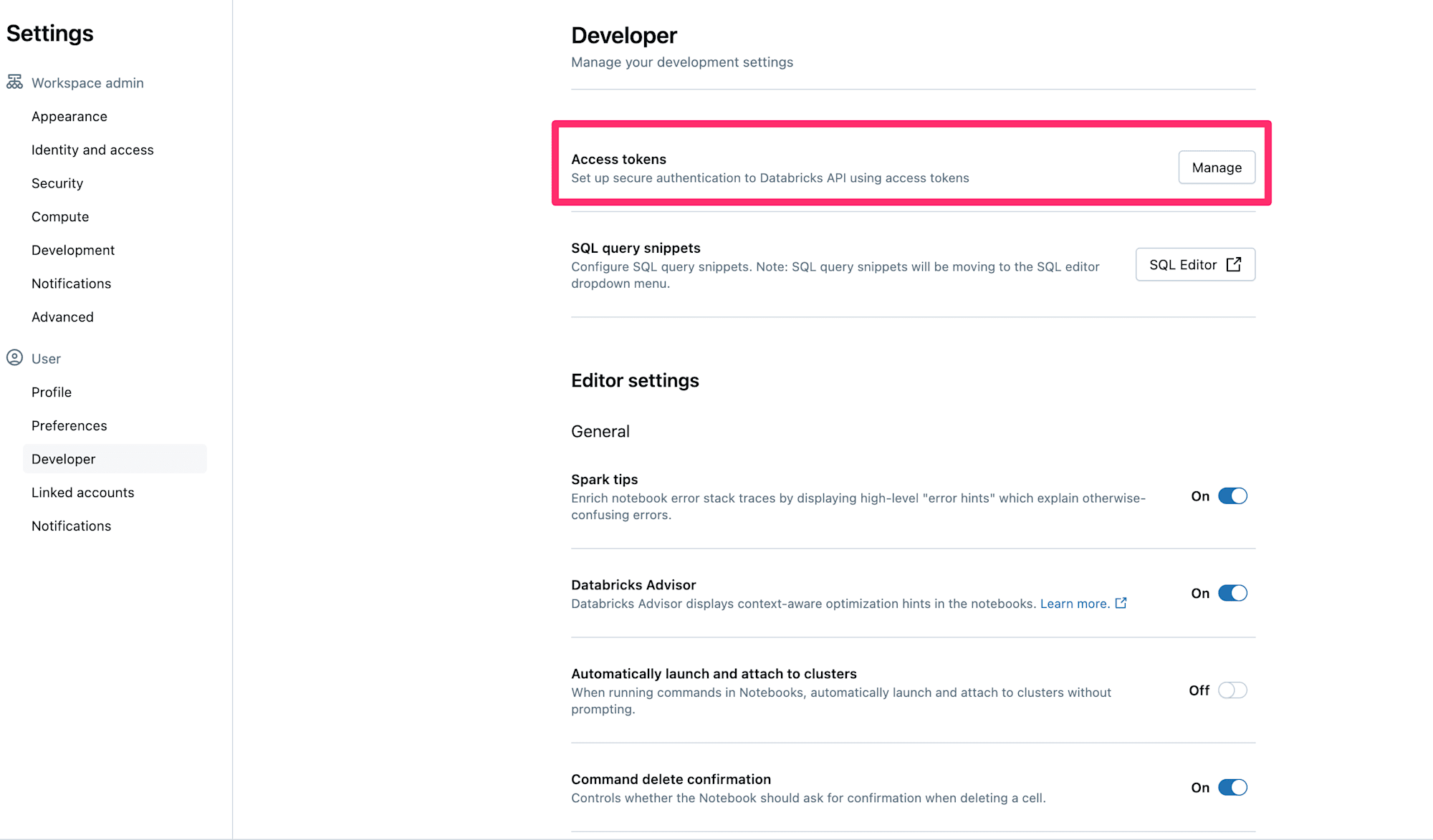
ユーザのプロフィールアイコンから『Settings』画面にアクセスし、『Developer』を開きます。
すると『Access tokens』という部分があるので、『Manage』ボタンを押します。
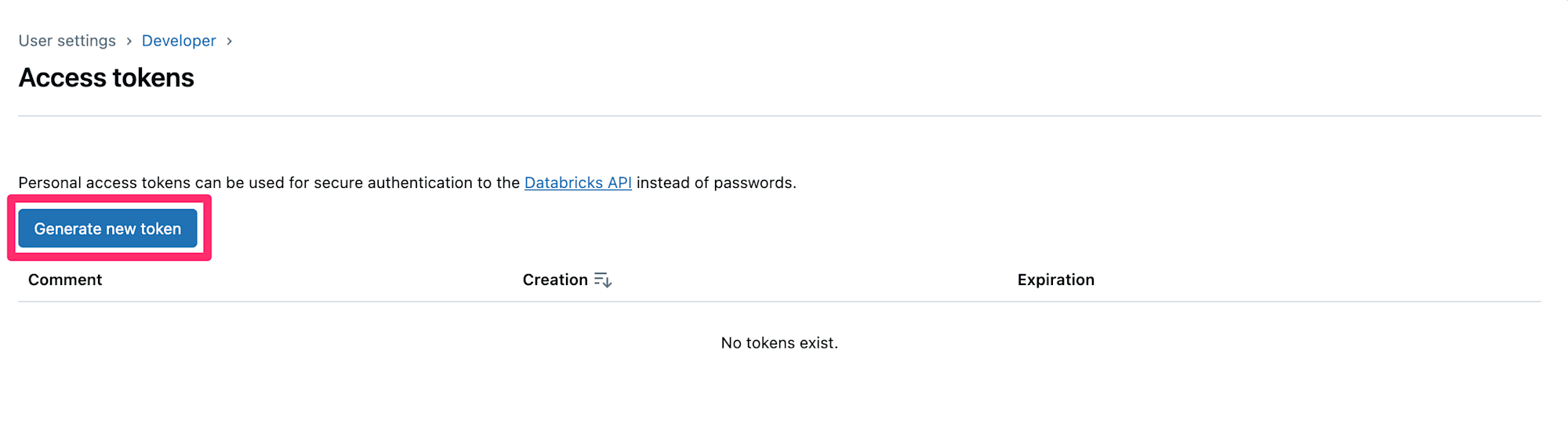
すると以下のような画面になりますので、『Generate new token』を選択します。
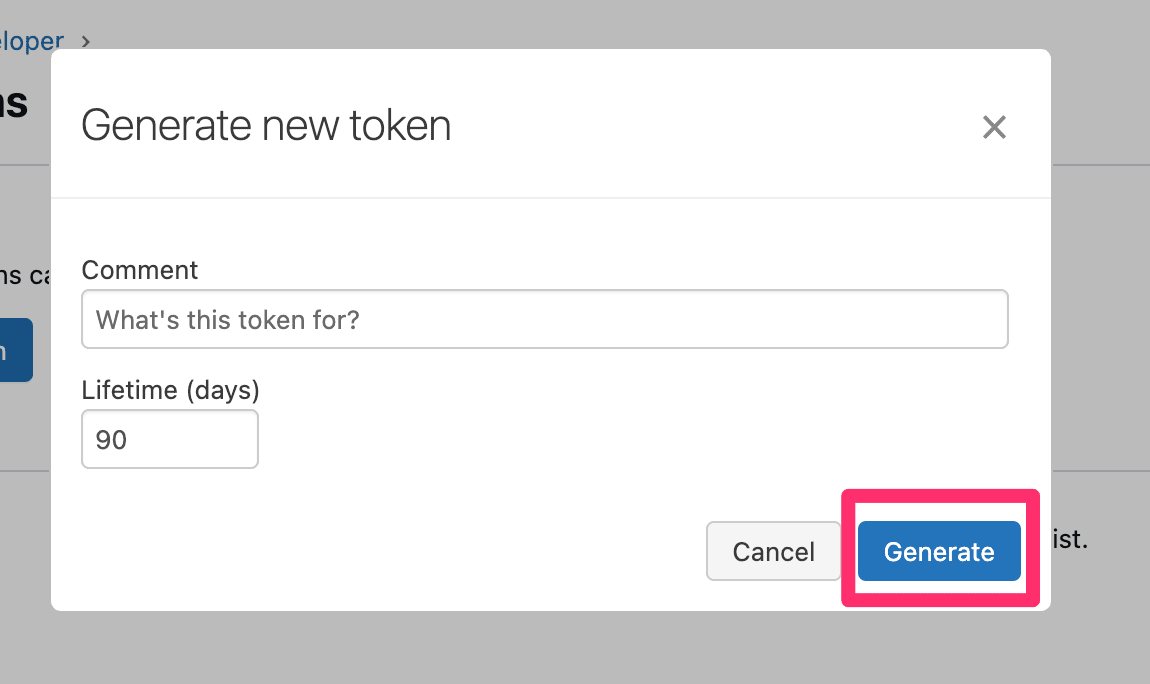
コメントや有効期限(日)などを入力して『Generate』ボタンを押します。
作成が完了するとトークンが払い出されるので、どこかにメモしておきます。
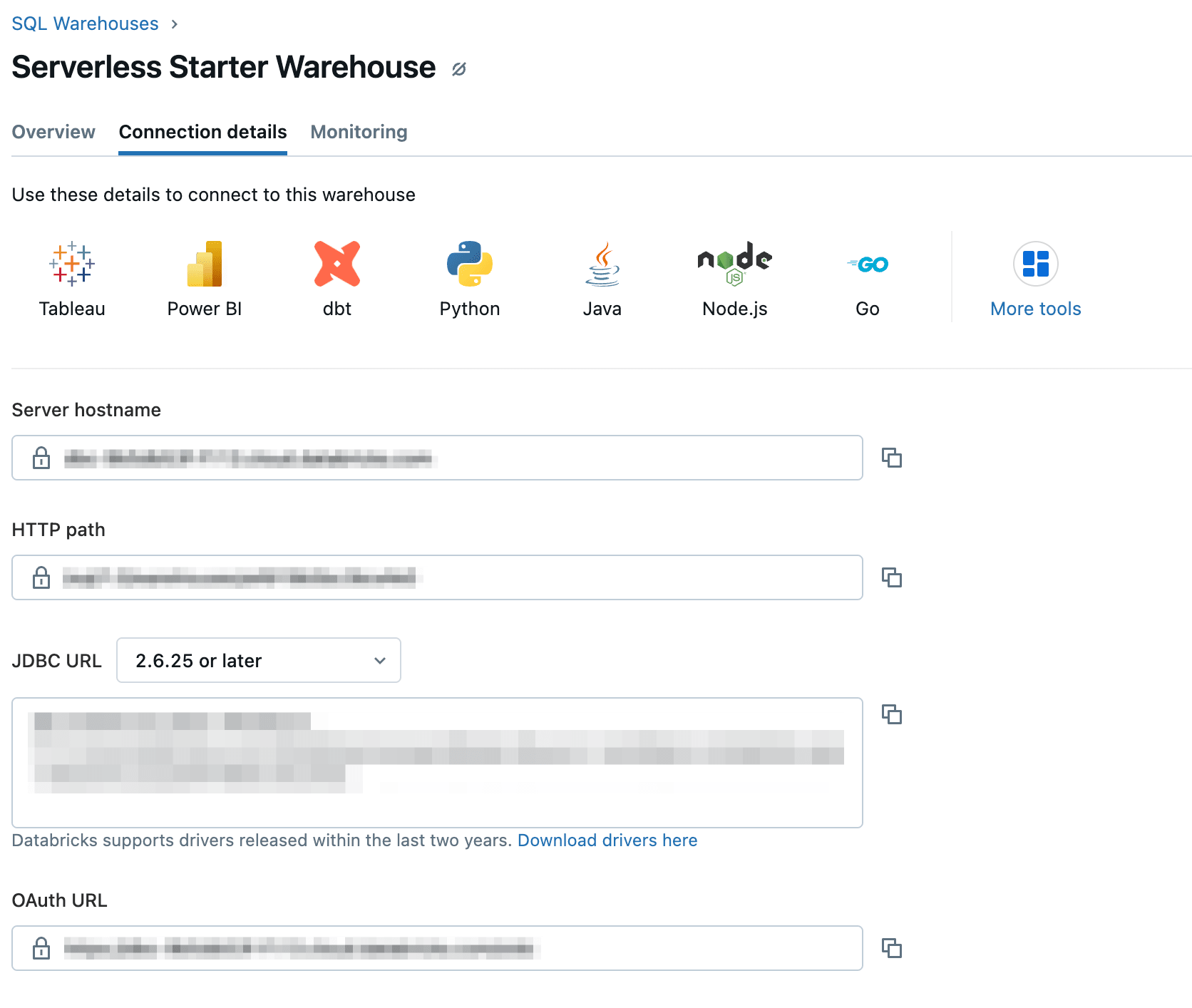
Server hostnameとHTTP pathの確認
Databricksトップ画面の左側にあるタブから『Compute』ページにアクセスし、接続したいSQL Warehouseの情報を確認します。
以下のような画面が出るかと思うので、Server hostnameとHTTP pathをメモしておきます。
AWS側の準備
ファイル作成
今回用意するファイルは以下の通りです。
.
├── CFn_resource.yml
└── glue_scripts
└── sample.py
以下に、それぞれのファイルの内容を記載します。
CFn_resouce.yml
AWSにリソースを展開するためのCloudFormationテンプレートである CFn_resource.yml は以下の通りです。
AWSTemplateFormatVersion: '2010-09-09'
Description: CFn Template for Glue Spark Job with Databricks Connection
Parameters:
# Glue用パラメーター
GlueScriptS3Bucket:
Type: String
Description: S3 bucket containing the Glue job script
# Databricks接続用パラメータ
DatabricksHost:
Type: String
Description: 'Databricks host (e.g. dbc-123abc45-6def.cloud.databricks.com)'
HttpPath:
Type: String
Description: 'HTTP Path for the SQL Warehouse (e.g. sql/1.0/warehouses/abcd1234)'
DatabricksToken:
Type: String
Description: 'Databricks personal access token'
NoEcho: true
Metadata:
AWS::CloudFormation::Interface:
ParameterGroups:
- Label:
default: Parameter for Glue
Parameters:
- GlueScriptS3Bucket
- Label:
default: Parameter for Databricks connection
Parameters:
- DatabricksHost
- HttpPath
- DatabricksToken
Resources:
# Databricks接続情報を保存するためのシークレット
DatabricksSecret:
Type: AWS::SecretsManager::Secret
Properties:
Name: !Sub 'databricks/connection'
Description: 'Databricks connection information for Glue Job'
SecretString: !Sub |
{
"host": "${DatabricksHost}",
"httpPath": "${HttpPath}",
"token": "${DatabricksToken}"
}
# Glueジョブ用のIAMロール
GlueJobRole:
Type: AWS::IAM::Role
Properties:
RoleName: uehara-test-glue-job-for-databricks-role
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: glue.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
Policies:
- PolicyName: uehara-test-glue-job-for-databricks-policy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
- s3:ListBucket
Resource:
- !Sub 'arn:aws:s3:::${GlueScriptS3Bucket}'
- !Sub 'arn:aws:s3:::${GlueScriptS3Bucket}/*'
- Effect: Allow
Action:
- secretsmanager:GetSecretValue
Resource: !Ref DatabricksSecret
# Glue Sparkジョブ
GlueJob:
Type: AWS::Glue::Job
Properties:
Name: uehara-test-glue-job-for-databricks
Role: !GetAtt GlueJobRole.Arn
Command:
Name: glueetl
ScriptLocation: !Sub 's3://${GlueScriptS3Bucket}/sample.py' # スクリプトファイルの格納先
PythonVersion: 3
DefaultArguments:
'--job-language': 'python'
'--enable-metrics': 'true'
'--enable-continuous-cloudwatch-log': 'true'
'--enable-spark-ui': 'true'
'--spark-event-logs-path': !Sub 's3://${GlueScriptS3Bucket}/sparkHistoryLogs/'
'--secret_id': !Ref DatabricksSecret
'--extra-jars': !Sub 's3://${GlueScriptS3Bucket}/DatabricksJDBC42.jar' # JARファイルの格納先
GlueVersion: 5.0
WorkerType: G.1X # 1 DPU
NumberOfWorkers: 2
MaxRetries: 0
Timeout: 60 # minutes
ここでは以下のAWSリソースを作成しています。
- Glue Sparkジョブ
- Glueの実行IAMロール
- シークレットマネージャー
Databricksに接続するための情報である Server hostname, HTTP Path, Access Token はパラメータとして入力できるようにし、シークレットマネージャーで管理をするようにしています。
Glue Sparkジョブの --extra-jars にDatabricksのJDBCドライバのファイルパスを記載していますが、こちらは後段の作業で用意します。
sample.py
sample.py はGlueで動かすPythonスクリプトファイルになります。
今回は以下のようにしてみました。
import json
import sys
import boto3
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
# ジョブパラメータを取得
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'secret_id'])
# Spark/Glueコンテキストの初期化
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Secrets Managerから接続情報を取得
def get_secret(secret_id):
client = boto3.client('secretsmanager')
response = client.get_secret_value(SecretId=secret_id)
secret = response['SecretString']
return json.loads(secret)
# 接続情報を取得
secret_id = args['secret_id']
connection_info = get_secret(secret_id)
# 接続パラメータを設定
databricks_host = connection_info['host']
http_path = connection_info['httpPath']
token = connection_info['token']
print(f"Connecting to Databricks host: {databricks_host}")
print(f"Using HTTP path: {http_path}")
# Databricksからデータを読み込む
try:
# JDBC URLを構築
jdbc_url = f"jdbc:databricks://{databricks_host}:443;httpPath={http_path};AuthMech=3;UID=token;PWD={token};UseNativeQuery=0"
# JDBCを使用してDatabricksに接続
df = spark.read \
.format("jdbc") \
.option("driver", "com.databricks.client.jdbc.Driver") \
.option("url", jdbc_url) \
.option("dbtable", "workspace.test_managed_schema.my_sample_data") \
.load()
print(f"Successfully read {df.count()} rows from Databricks")
# 取得したデータの表示
df.show(10)
except Exception as e:
print(f"Error connecting to Databricks: {str(e)}")
raise
job.commit()
S3へのファイルの格納
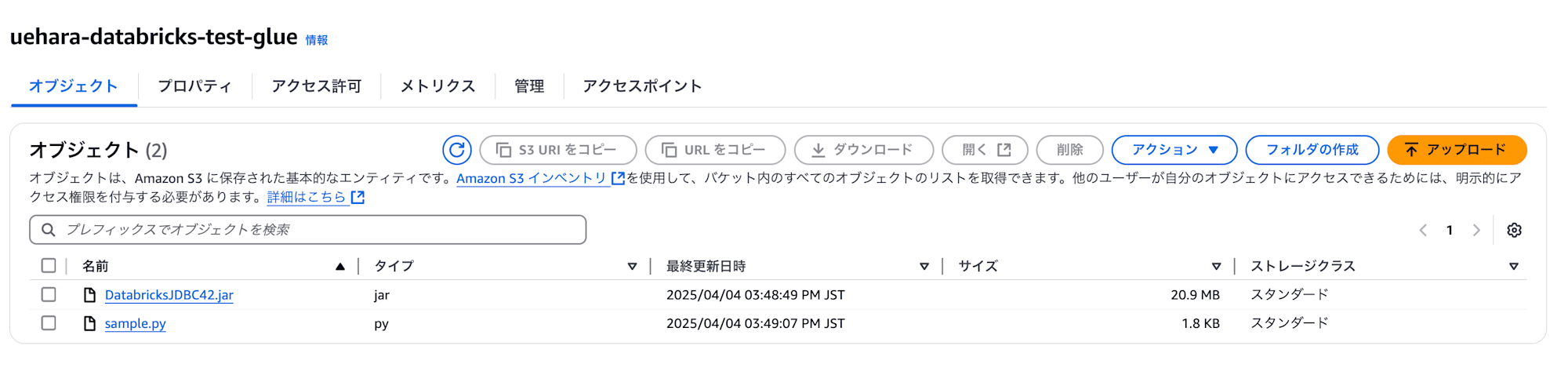
デプロイするためのファイル準備ができたので、スクリプトファイルとDatabricksのJDBCドライバファイルをS3に格納します。
JDBCドライバは以下のページからDownloadできます。
私は uehara-databricks-test-glue というような適当なバケットを作り、以下のようにスクリプトファイルとドライバファイルを配置しました。
CloudFormationでスタックの作成
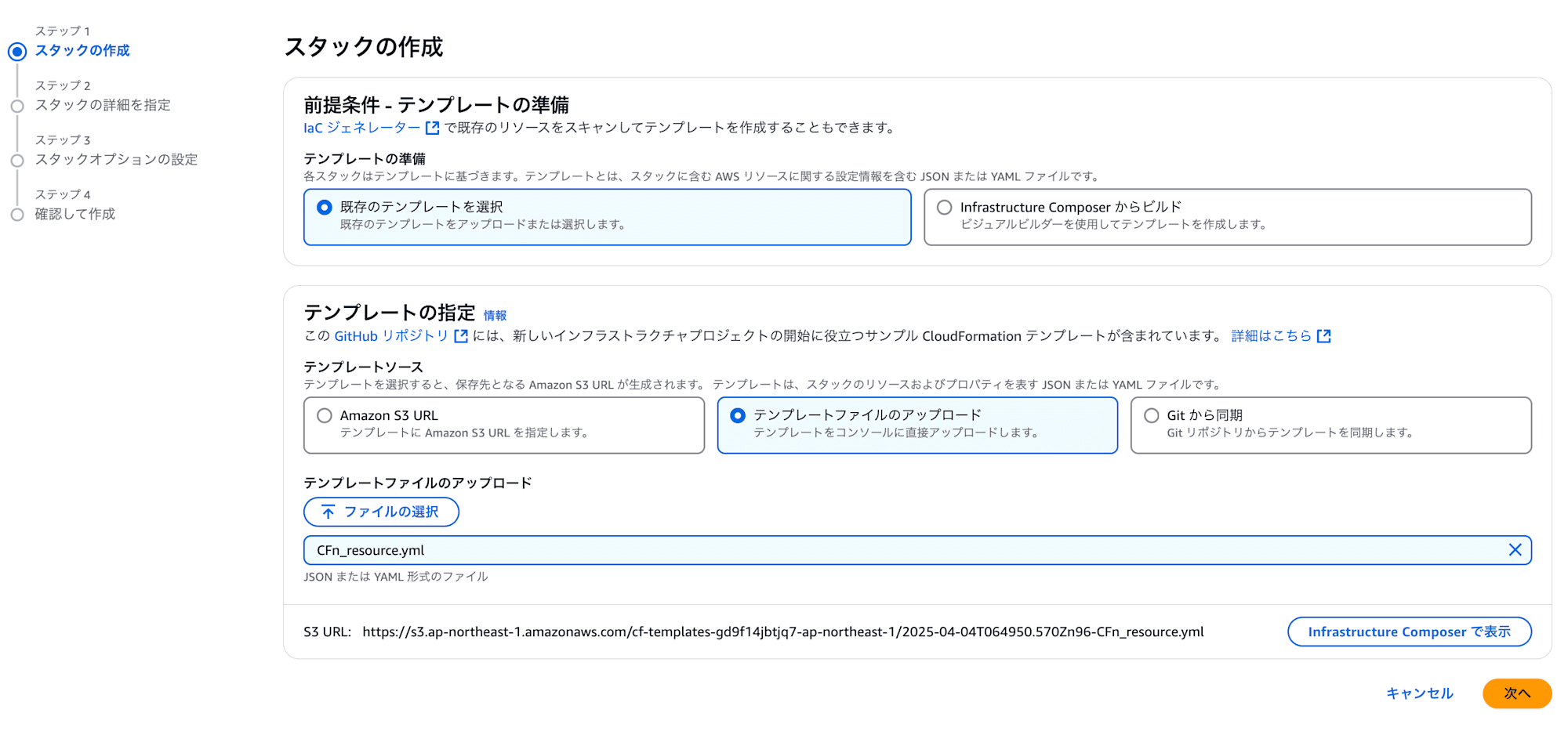
それでは、CloudFormationからスタックの作成を行います。
『テンプレートファイルのアップロード』から、先に作成したテンプレートファイル CFn_resource.yml を選択します。
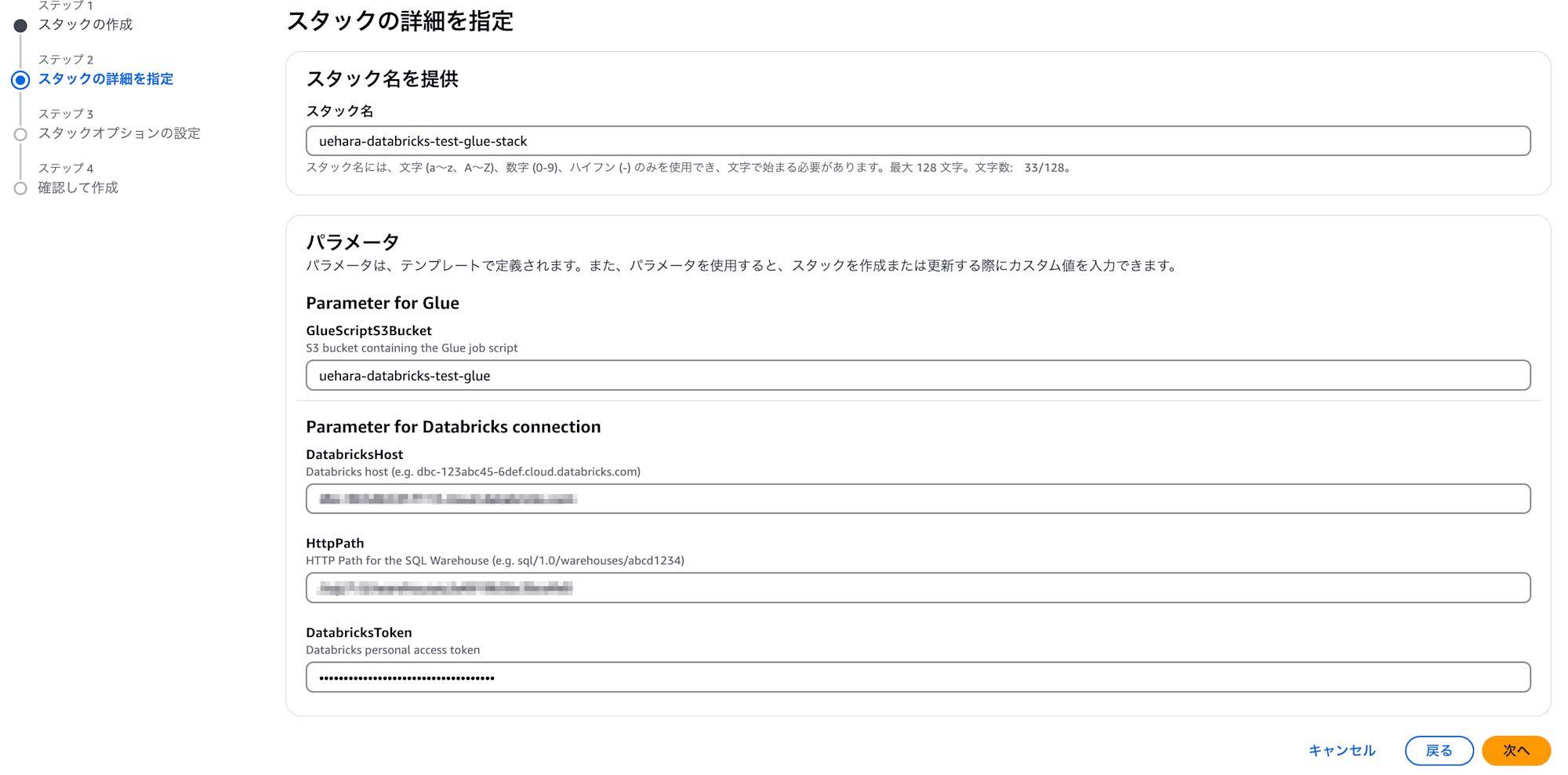
すると以下のようにパラメータを入力する画面が出てきますので、ご自身の環境に合わせてスクリプトファイルを配置したS3バケットや、メモしておいたDatabricksの接続情報を入力して下さい。
あとはそのまま作成まで進めていくと、以下のようにリソースが作成されるかと思います。

実行してみた
準備が完了したので、いよいよGlueを動かしてみます。
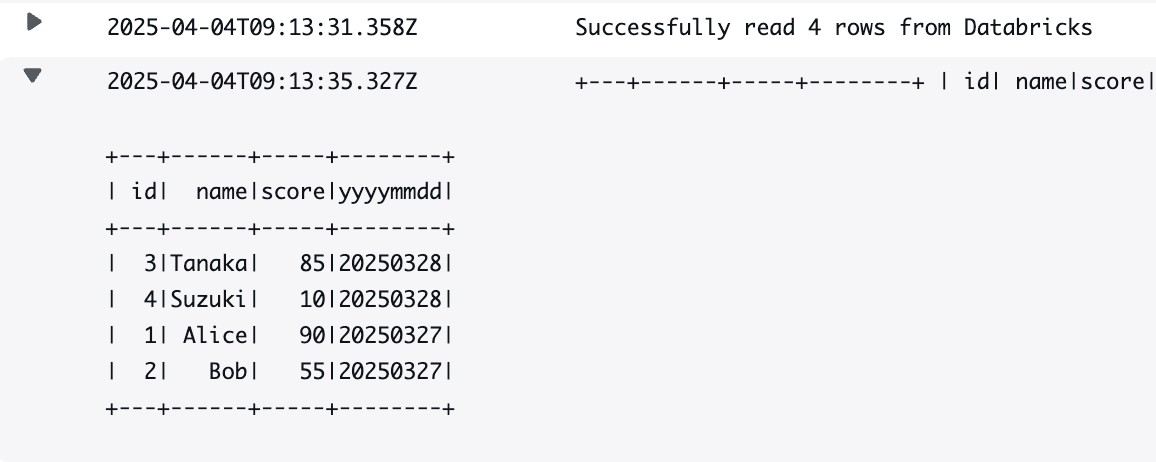
ジョブが正常終了したのでCloudWatch Logsを確認すると、以下の通りテーブルからデータが取得できたことが確認できました。
ハマりポイント
当初JDBCのURLを公式ドキュメントのまま
jdbc:databricks://{databricks_host}:443;httpPath={http_path};AuthMech=3;UID=token;PWD={token}
というようにしていたところ、以下の通り型変換でエラーがでました。
An error occurred while calling o146.showString. [Databricks][JDBC](10140) Error converting value to int.
以下の通り UseNativeQuery=0 を入れることで事象が解決したので、この場で共有しておきます。
jdbc:databricks://{databricks_host}:443;httpPath={http_path};AuthMech=3;UID=token;PWD={token};UseNativeQuery=0
最後に
今回は、AWS Glue for SparkからDatabricksのテーブルにアクセスしてみました。
参考になりましたら幸いです。







