![[新機能] AWS Glue 生成AIを用いたトラブルシューティング機能を発表しました(preview)](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-545ba5dfbc8fa4c7760dd9872ef835f9/665944e579f487b4434cb289305767b3/aws-glue?w=3840&fm=webp)
[新機能] AWS Glue 生成AIを用いたトラブルシューティング機能を発表しました(preview)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。AWS Glueは、生成AIを用いたトラブルシューティング機能機能をプレビューとして発表しました。この新機能により、Sparkジョブのトラブルに対して自動的に原因を分析、特定された問題を修正するための実用的な推奨事項を提供します。まだ、プレビュー版ですので変更される可能性がありますが新機能を試してみます。
AWS Glue 生成AIを用いたトラブルシューティング機能とは
現在でも、AWS Glue と Amazon Q Developersの統合によって、トラブルシューティングの支援する機能があります。これはトラブルに関する自然言語の質問に対して、自然言語の回答を返すものです。回答の専門性や精度は高いのですが、適切に質問をしなければ良い回答が得られませんでした。
今回の新機能は、Sparkジョブのトラブルシューティングする新しいジェネレーティブ AI 機能です。Amazon Bedrock を搭載したこの機能は、コードはもちろん、ジョブメタデータ、メトリクス、ログから障害が発生した Spark アプリケーションのトラブルに対して、自動的に原因を分析し、特定された問題を修正するための実用的な推奨事項を提供します。まだ、プレビュー版ですので変更される可能性がありますが新機能を試してみます。
トラブルシューティングシナリオ
Sparkジョブのトラブルシューティング機能はジョブのメタデータ、メトリクス、およびジョブのエラーに関連するログを分析し、包括的な根本原因分析を生成します。AWS Glue コンソール上からトラブルシューティングと最適化プロセスを開始できます。この機能は、Sparkアプリケーションのデバッグや日々の運用で発生する以下のようなトラブルに対応します。
リソース設定またはアクセスエラー
- S3バケット、データベース、パーティション、カラムなどの設定ミスを特定
- IAMロールやKMSキーの権限問題を解析
Spark のメモリ不足エラー
- DriverまたはExecutorでのメモリ不足問題を診断
- メモリ使用パターンを分析し、メモリ集中型操作を特定
Spark のディスク容量不足エラー
- Executorでのディスク容量不足を検出
- データシャッフル操作や広範な変換の最適化を提案
AWS Glue for Spark ジョブのトラブルシューティングを試す
では早速、生成AIを用いて、Glue version 2.0のGlue ETLジョブのトラブルシューティングしてみます。このGlue ETLジョブは、出力先に存在しないS3バケットを指定して、エラーが出るようにコードを書き換えています。
AWS Glue ETLジョブを実行すると案の定エラーになります。
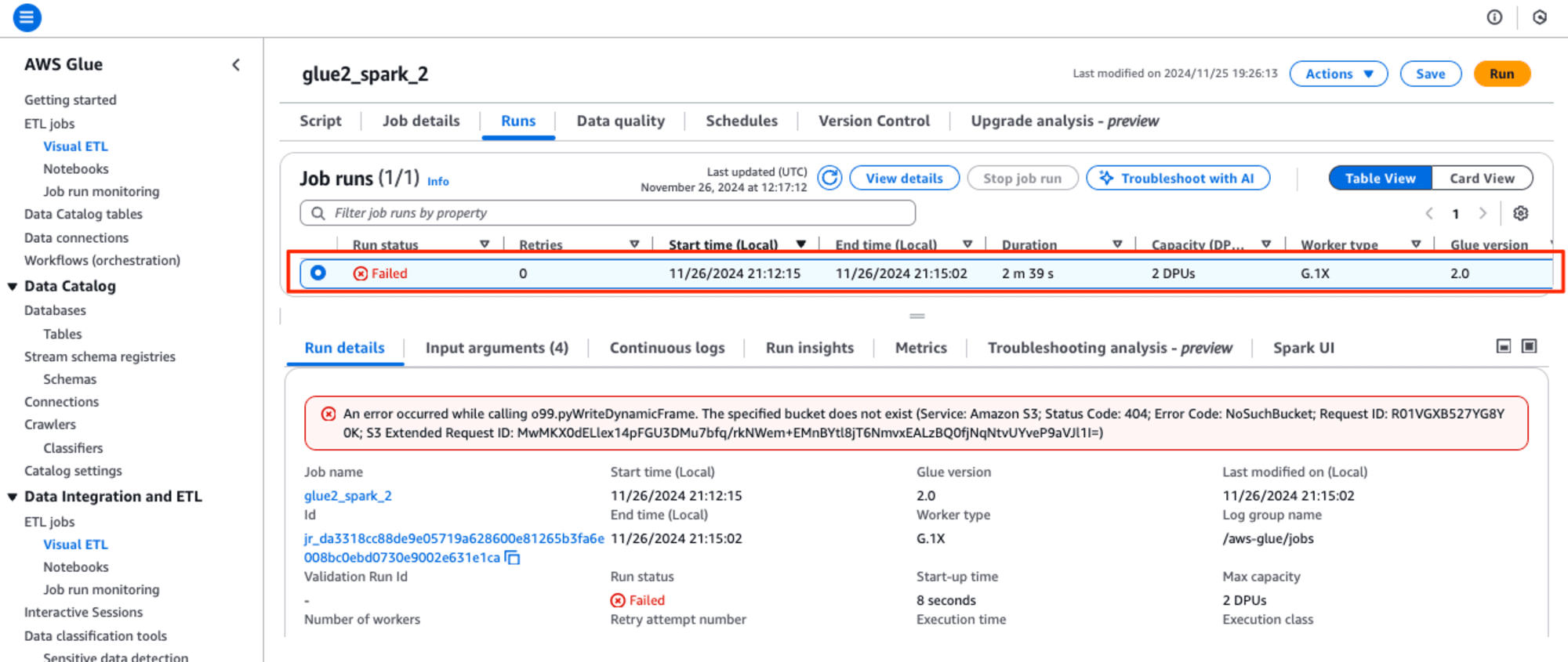
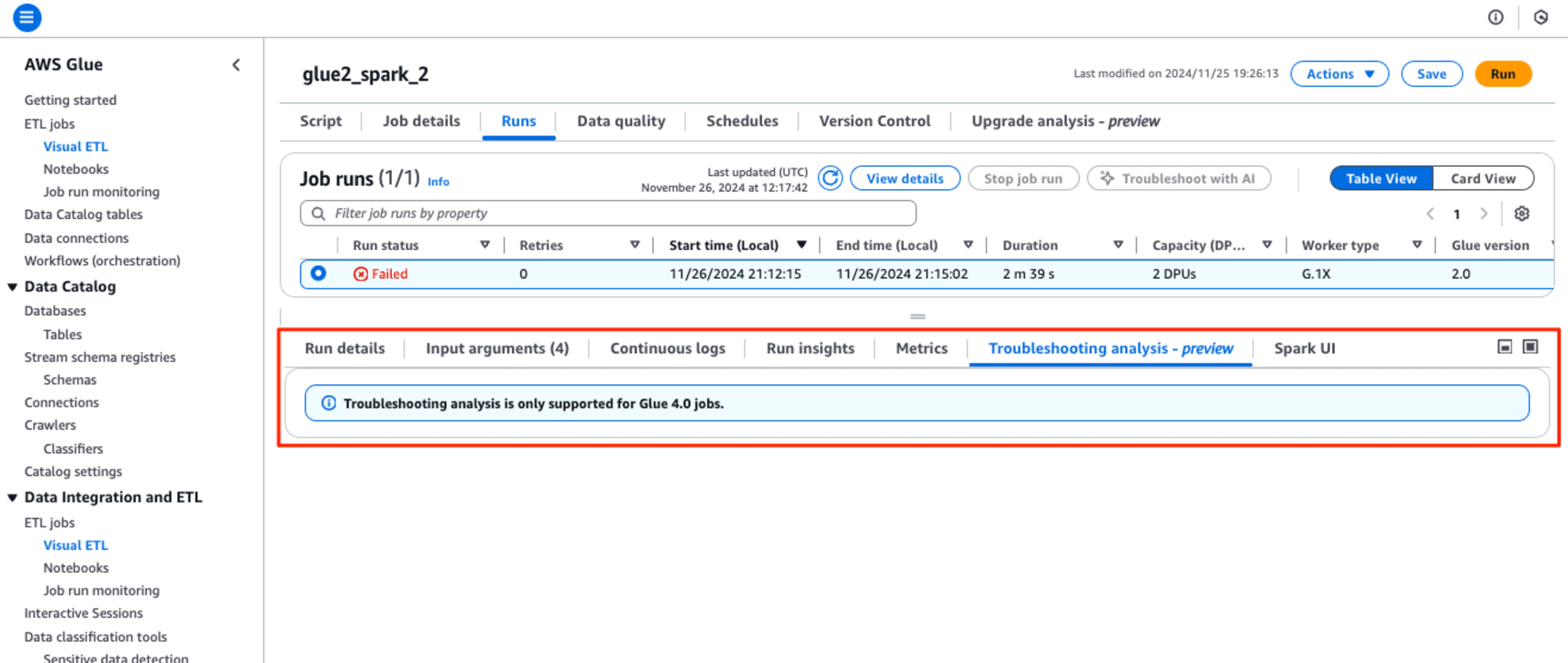
画面下の[Troubleshooting analysis - preview] タブを選択して、確認すると、"Troubleshooting analysis is only supported for Glue 4.0 jobs."とあり、Glue version 2.0はサポートしていませんでした。
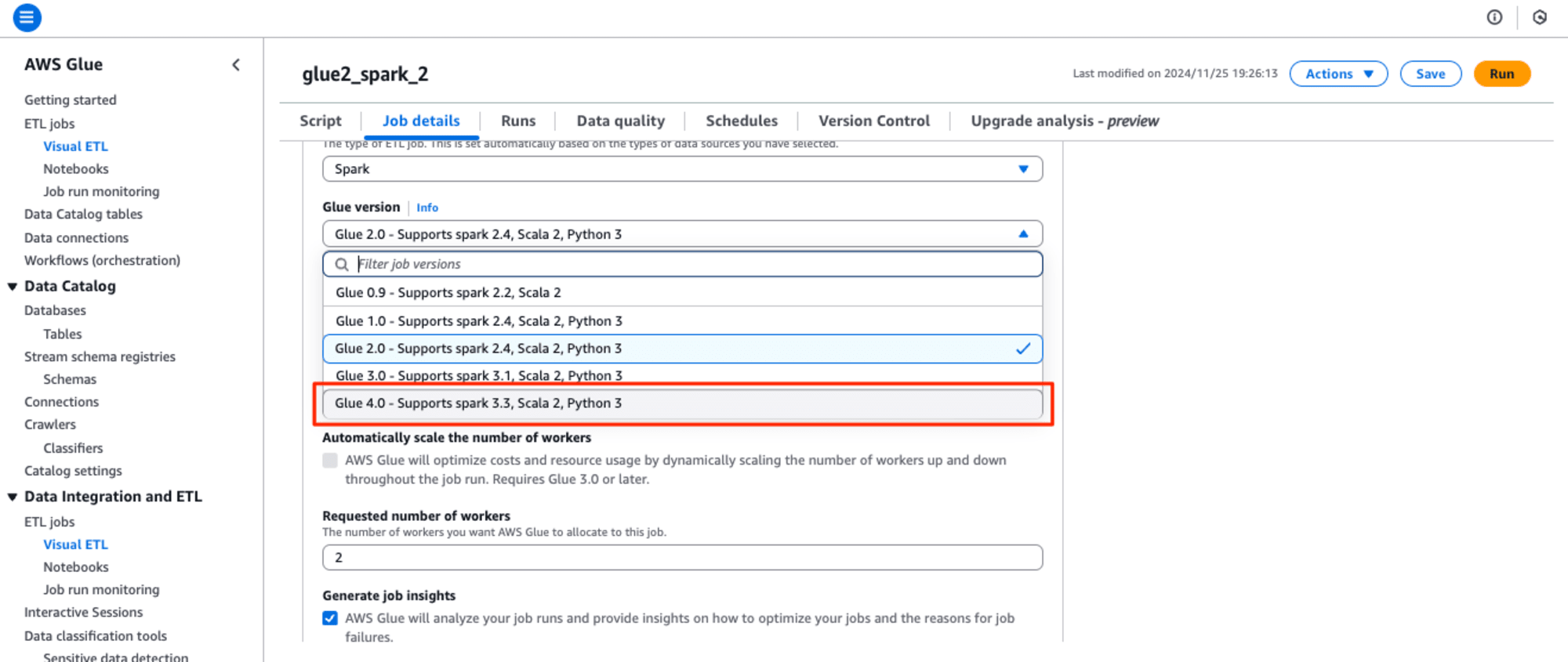
そのため、Glue version 4.0に変更してリトライします。
再び実行すると実行すると案の定エラーになります。
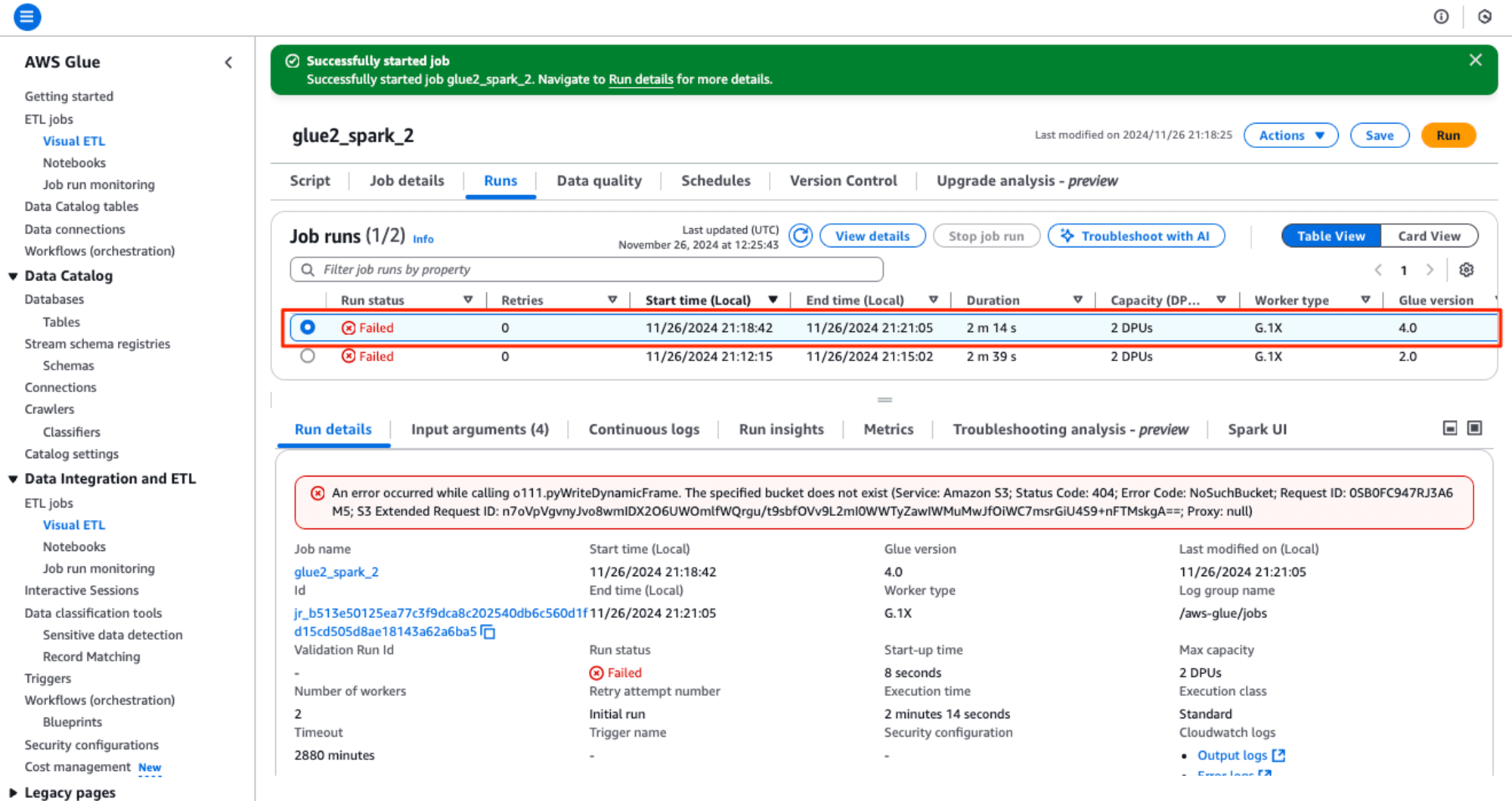
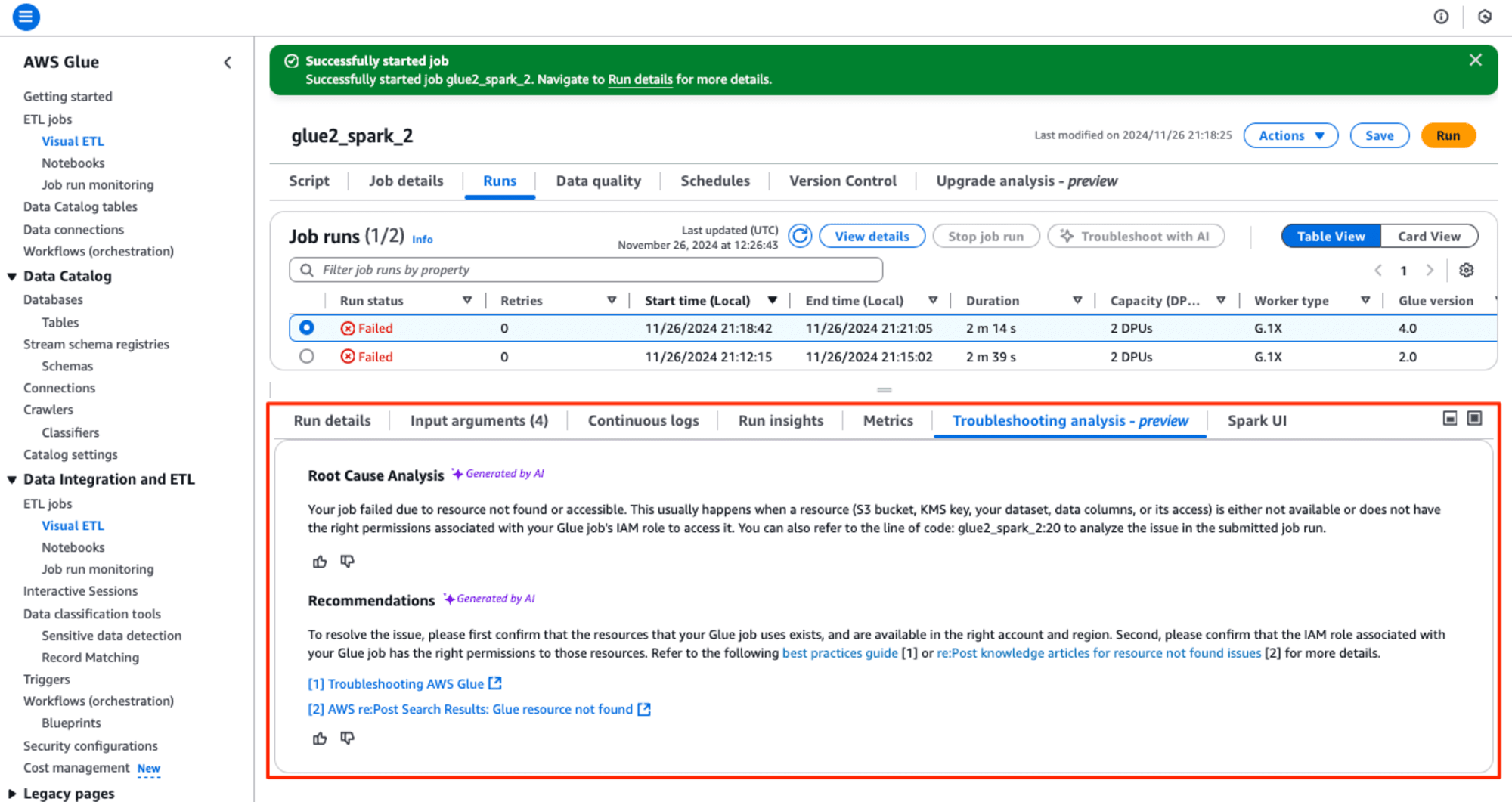
画面下の[Troubleshooting analysis - preview] タブを選択して、確認すると1分ほど待たされ、生成AIによるRoot Cause Analysis(根本原因分析)とRecommendations(推奨事項)が表示されました。
Root Cause Analysis
Your job failed due to resource not found or accessible. This usually happens when a resource (S3 bucket, KMS key, your dataset, data columns, or its access) is either not available or does not have the right permissions associated with your Glue job's IAM role to access it. You can also refer to the line of code: glue2_spark_2:20 to analyze the issue in the submitted job run.
リソースが見つからないかアクセスできないため、ジョブが失敗しました。これは通常、リソース (S3 バケット、KMS キー、データセット、データ列、またはそのアクセス) が利用できないか、Glue ジョブの IAM ロールに関連付けられた適切なアクセス権限がない場合に発生します。送信されたジョブ実行の問題を分析するには、コード行 glue2_spark_2:20 を参照することもできます。
Recommendations
To resolve the issue, please first confirm that the resources that your Glue job uses exists, and are available in the right account and region. Second, please confirm that the IAM role associated with your Glue job has the right permissions to those resources. Refer to the following best practices guide [1] or re:Post knowledge articles for resource not found issues (2] for more details.
この問題を解決するには、まず、Glue ジョブが使用するリソースが存在し、適切なアカウントとリージョンで利用できることを確認してください。次に、Glue ジョブに関連付けられた IAM ロールに、それらのリソースに対する適切な権限があることを確認してください。詳細については、次のベスト プラクティス ガイド [1] または、リソースが見つからない問題に関する re:Post ナレッジ記事 (2) を参照してください。
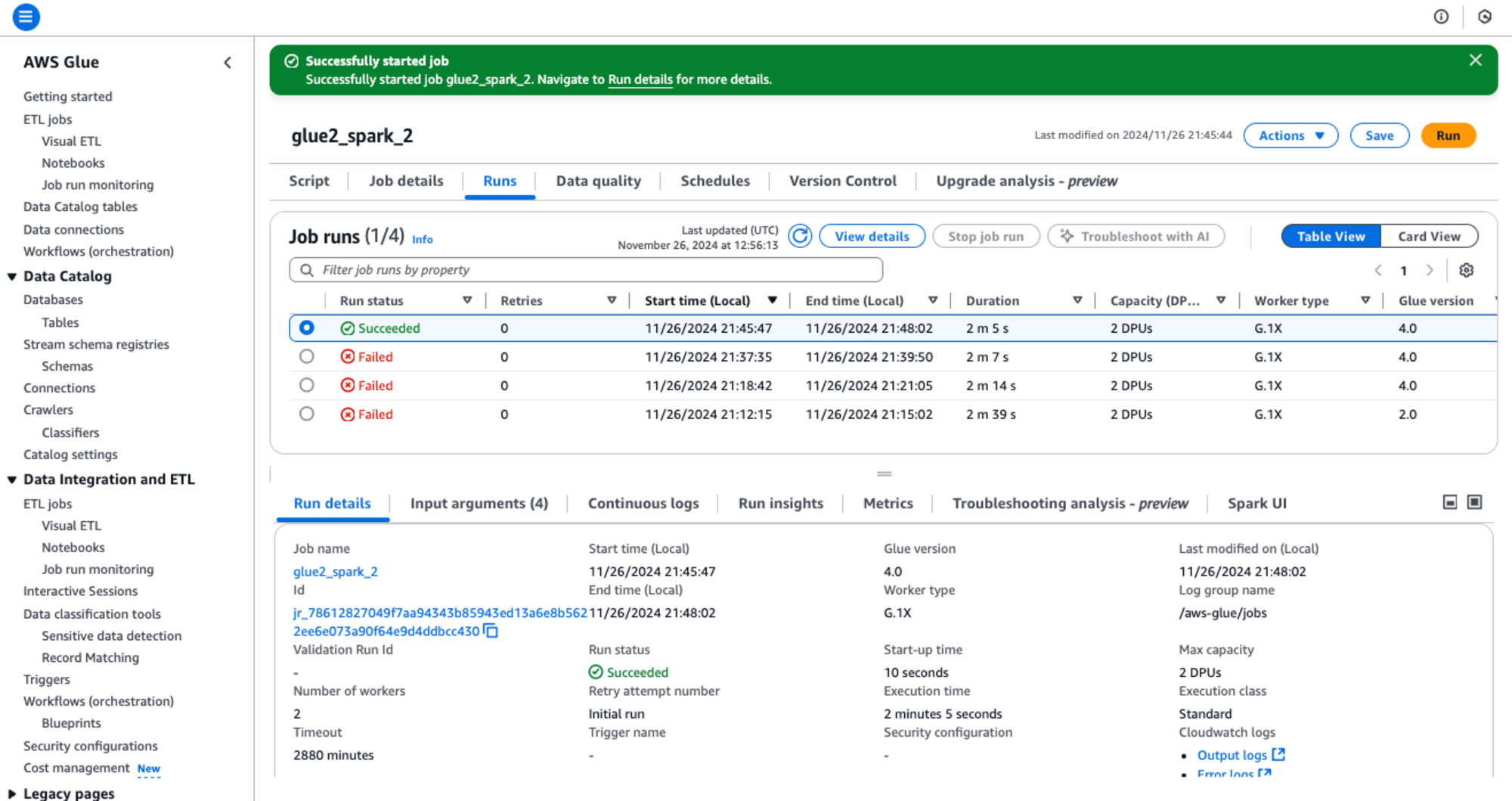
生成AIによるRoot Cause Analysis(根本原因分析)のとおり、出力先のS3バケット名を変更してトラブルシューティングできました。
最後に
この機能は、Sparkジョブのトラブルに対して自動的に原因を分析し、問題を修正するための実用的な推奨事項を提供します。この新機能は、リソース設定やアクセスエラー、Sparkのメモリ不足エラー、ディスク容量不足エラーなど、様々なトラブルに対応できます。また、ジョブのメタデータ、メトリクス、ログを分析し、包括的な根本原因分析を生成します。
私の経験として、特にSparkのメモリ不足エラーのトラブルシューティングは心強い機能と感じます。数十TBのデータを変換するため、一度に数万円にかかる Glue ETL ジョブが最終段階でSparkのメモリ不足エラーが発生、何度も実行して発生原因の特定や対策を繰り返したとき、生きた心地がしませんでした。この機能があったらどんなに心強かっただろうと思います。
この新機能は、Sparkアプリケーションのデバッグや日々の運用で発生するトラブルに対して、効率的な解決策を提供し、問題解決までの時間を大幅に短縮することが期待されます。データエンジニアにとって、この機能は作業効率の向上とコスト最適化に貢献するでしょう。










