![[新機能] AWS Glue 生成AIを用いた古いバージョンのSparkジョブのアップグレード機能を発表しました (Preview)](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-545ba5dfbc8fa4c7760dd9872ef835f9/665944e579f487b4434cb289305767b3/aws-glue?w=3840&fm=webp)
[新機能] AWS Glue 生成AIを用いた古いバージョンのSparkジョブのアップグレード機能を発表しました (Preview)
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。AWS Glueは、生成AIを用いた古いバージョンのSparkジョブのアップグレード機能をプレビューとして発表しました。この新機能により、既存のSparkジョブを迅速にアップグレードおよび最新化することが可能になります。まだ、プレビュー版ですので変更される可能性がありますが新機能を試してみます。
AWS Glue の Apache Spark 向け生成 AI アップグレードとは
現在でも、AWS Glue と Amazon Q Developersの統合によって、自然言語でETLジョブのコードの雛形を生成したり、トラブルシューティングする機能があります。
今回の新機能は、既存の Spark ジョブを迅速にアップグレードして最新化できるようにする新しいジェネレーティブ AI 機能です。Amazon Bedrock を搭載したこの機能は、Spark スクリプトと設定の分析と更新を自動化し、Spark のアップグレードに必要な時間と労力を短縮します。
アップグレードの流れ
-
分析
- Python ベースのSparkジョブを分析します。
-
アップグレードプラン生成
- コード変更と設定修正の詳細を含むアップグレードプランを生成します。
-
反復的な改善
- 生成AIを活用して、アップグレードされたコードを反復的に改善し、Glueジョブとしてテスト実行を行います。
-
検証
- 検証が成功すると、すべての変更の詳細な要約が提供されます。
-
レビューと展開
- ユーザーは変更をレビューし、自信を持ってアップグレードされたSparkジョブを展開できます。
特長
-
複雑さの軽減
- Sparkアップグレードの複雑さを軽減します。
-
信頼性の維持
- データパイプラインの信頼性を維持しながら、アップグレードプロセスを自動化します。
-
効率化
- データ統合、分析、機械学習、アプリケーション開発のためのデータの発見、準備、結合が容易になります。
Glue ETLジョブをGlue version 2.0から4.0にアップデートしてみる
では早速、生成AIを用いて、Glue version 2.0のGlue ETLジョブをGlue version 4.0にアップデートしてみます。
以下のように、「glue2_spark_1」というGlue ETLジョブ(Glue version 2.0)を選択して、[Actions]プルダウンから、[Run upgrade analysis with AI - preview]を選択します。
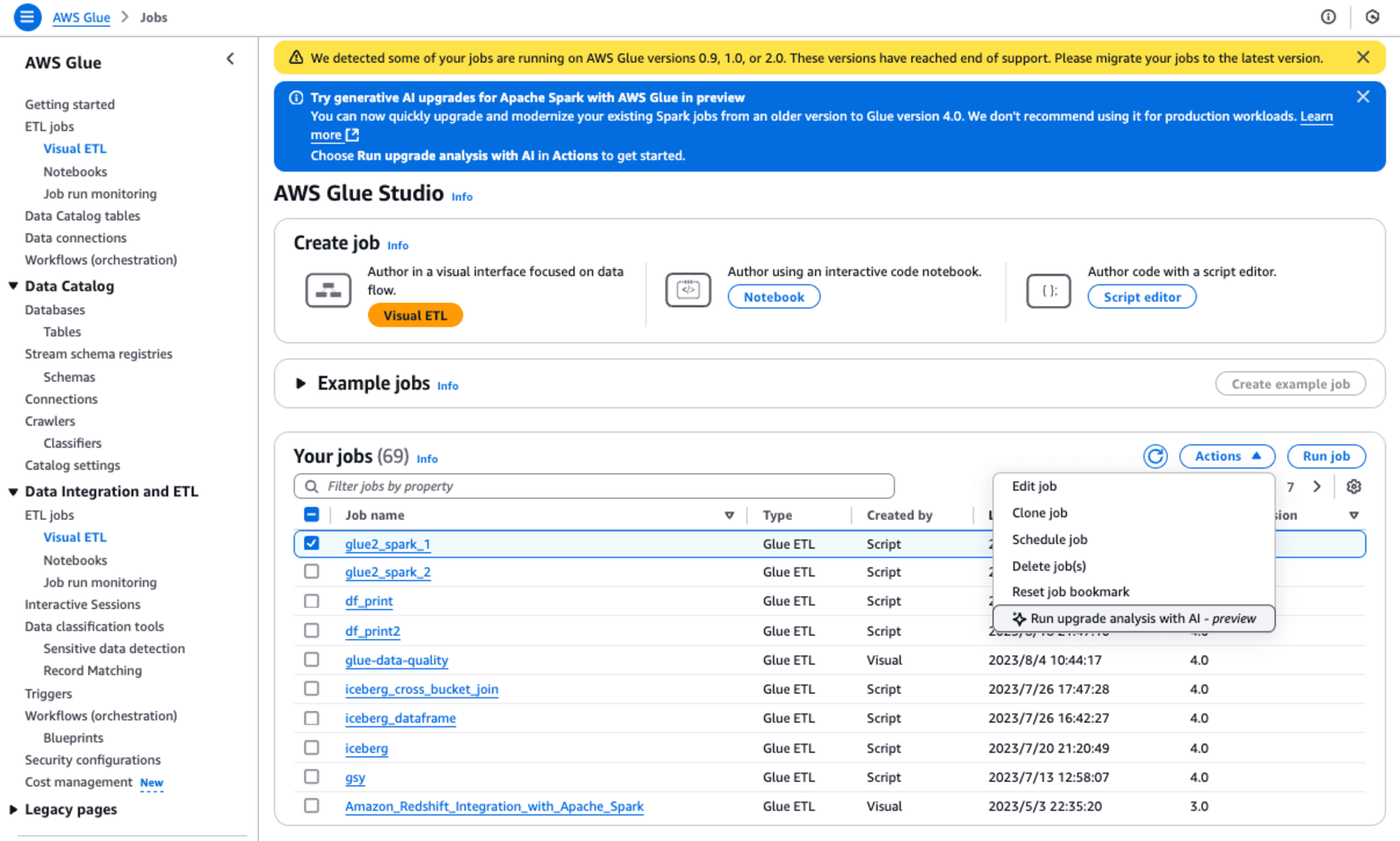
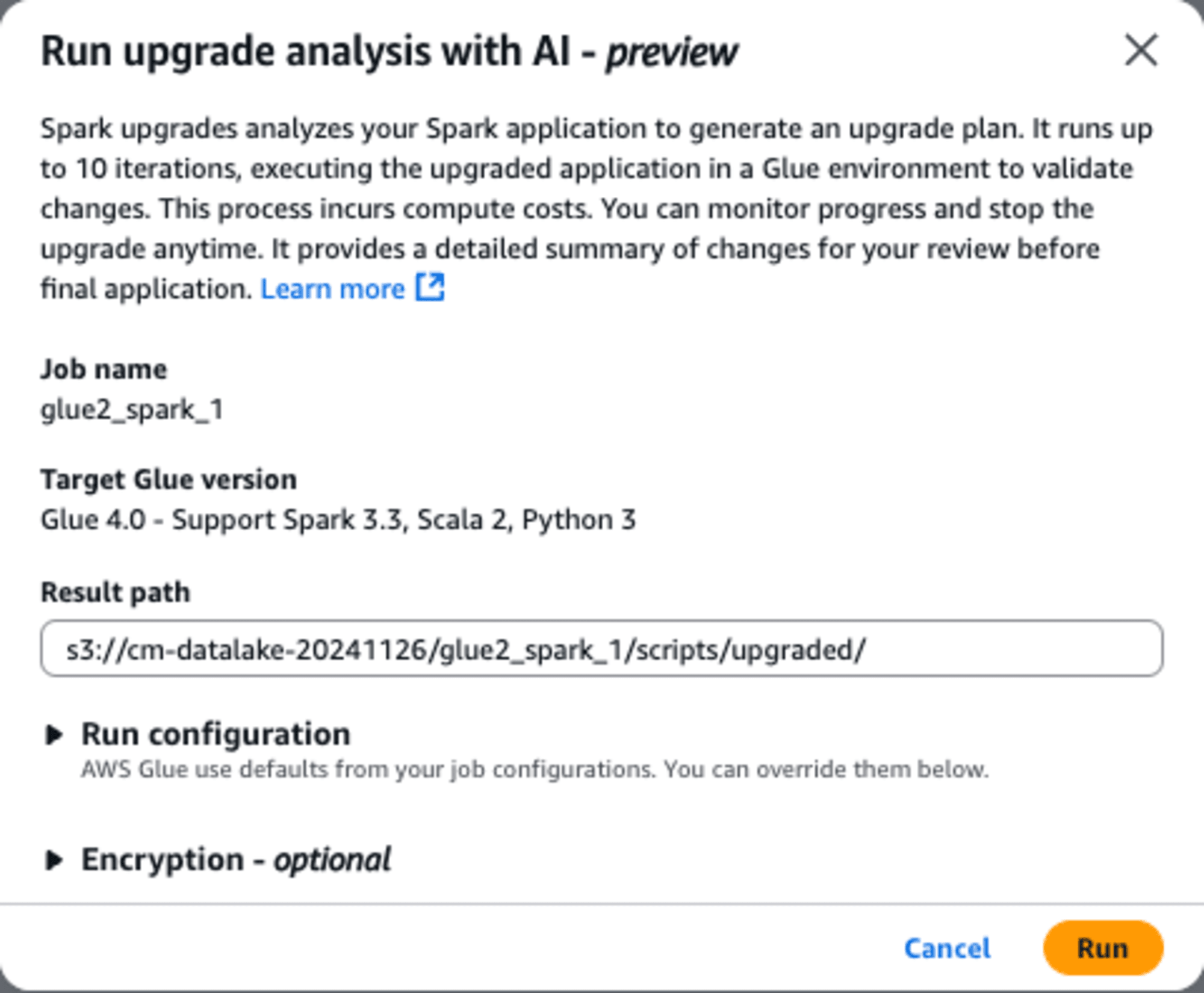
すると、下記のダイアログが表示されますので、「Result path」にアップデートしたスクリプトとそのレポート(summary.txt)の出力先となるS3のパスを指定して、[Run]ボタンを実行します。
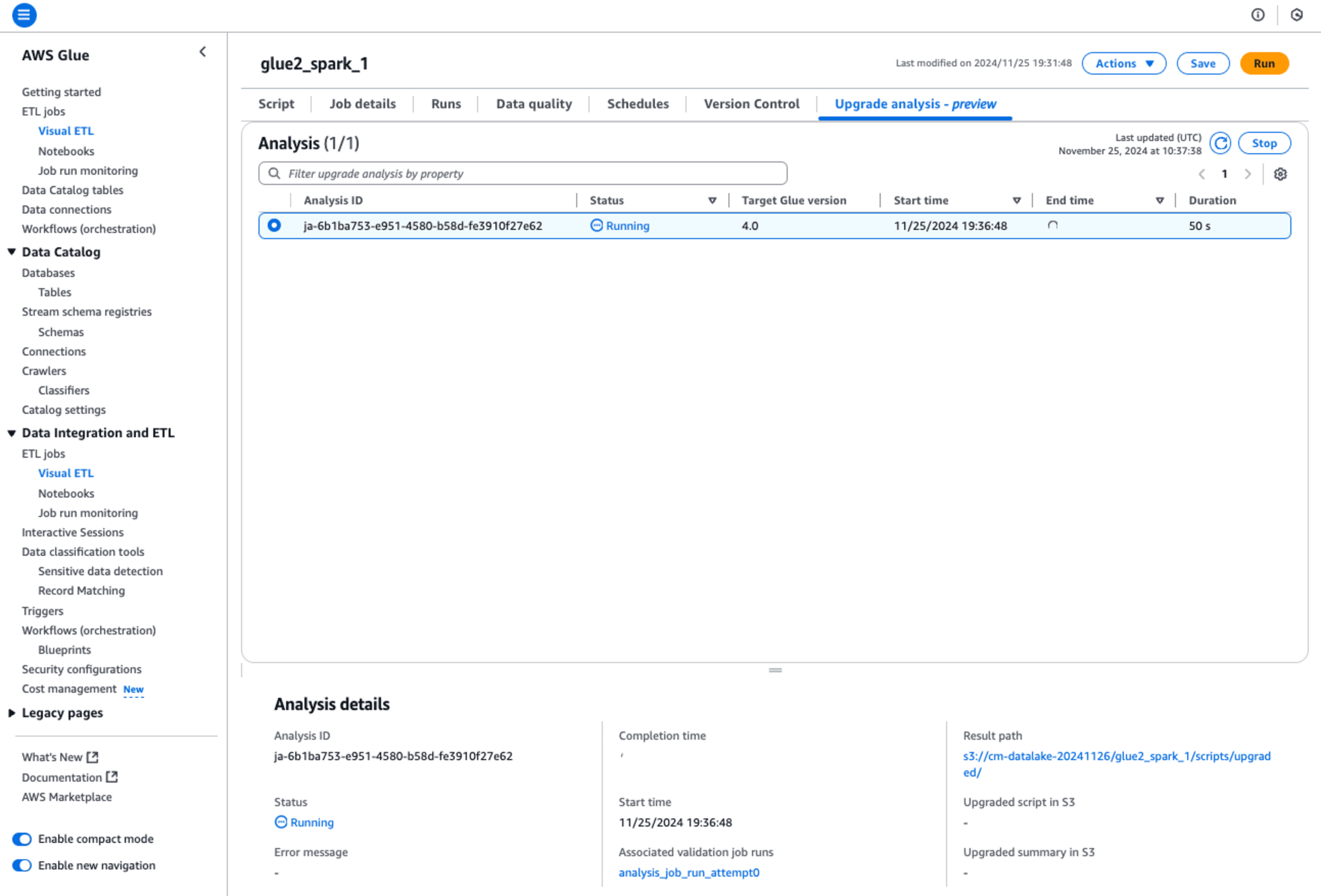
「glue2_spark_1」というGlue ETLジョブの分析が始まります。
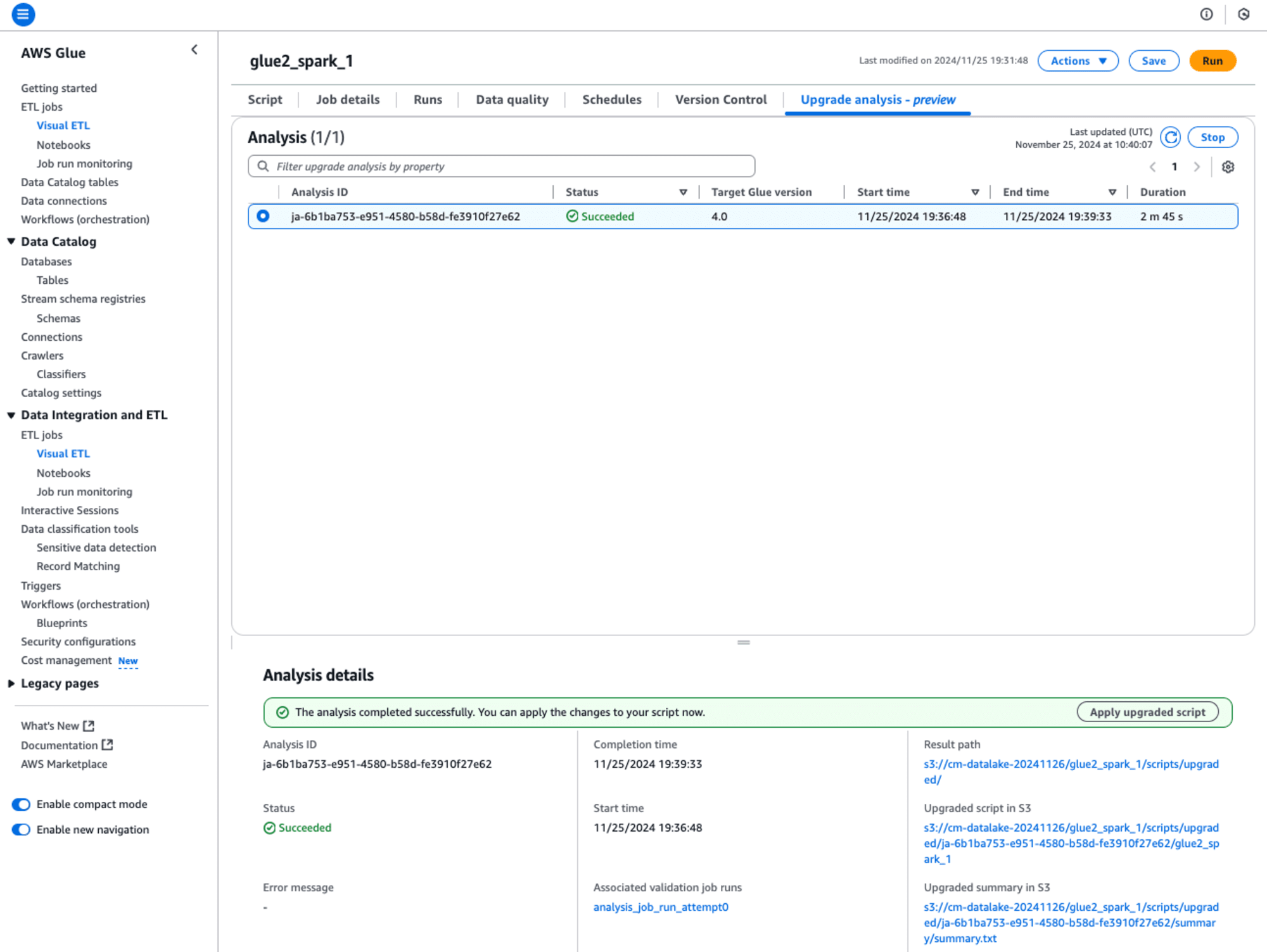
アップデートの分析が終わると、画面の下にAnalysis detailsが表示されます。
- Result path
- アップデートの分析のダイアログで指定したResult pathが表示されます。
- Upgraded script in S3
- アップグレードされたpysparkのスクリプトのパスが表示されます。
- Upgraded summary in S3
- アップグレードされたETLジョブのレポートのパスが表示されます。
Glue ETLジョブのアップグレードが成功しました。アップグレードを適用するには、[Apply upgrade script]ボタンを押します。
ダイアログに「アップグレードされたコードを使用する前に必ず確認してください。」とあります。
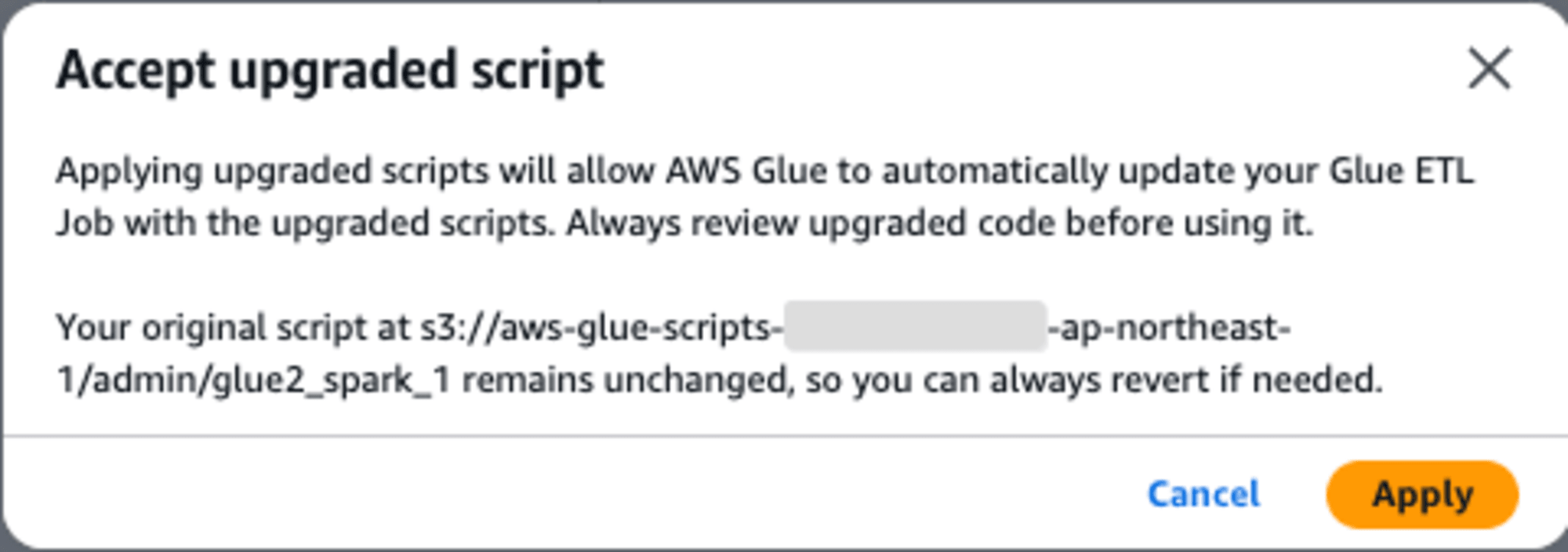
コードを確認しましたが、変更されていません。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "ssbgzdb_tsv", table_name = "customer", transformation_ctx = "datasource0")
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("c_custkey", "int", "c_custkey", "int"), ("c_name", "string", "c_name", "string"), ("c_address", "string", "c_address", "string"), ("c_city", "string", "c_city", "string"), ("c_nation", "string", "c_nation", "string"), ("c_region", "string", "c_region", "string"), ("c_phone", "string", "c_phone", "string"), ("c_mktsegment", "string", "c_mktsegment", "string")], transformation_ctx = "applymapping1")
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://cm-datalake-20241126/glue2_spark_1/customer1", "compression": "gzip"}, format = "json", transformation_ctx = "datasink2")
job.commit()
レポートの結果を確認すると、スクリプトは既に互換性があると分析されました。コードについては変更不要ということです。
Script is already compatible with target Glue version 4.0. No changes required.
では、[Apply]を押し、変更を適用します。
変更を適用して、Job detailsを確認するとGlue versionが、4.0になったことが確認できます。
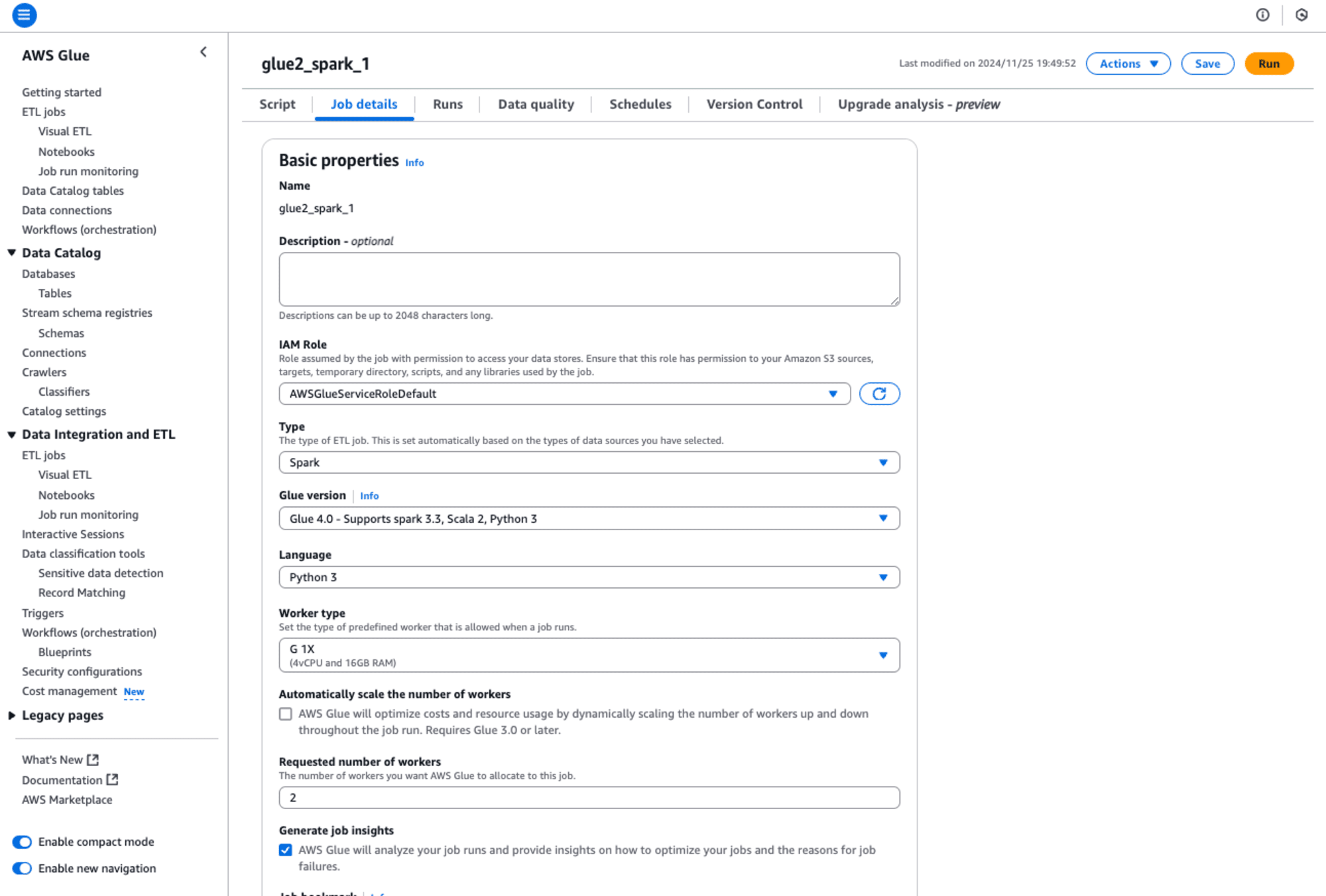
pysparkのコードに変更がなかったとはいえ、互換があるとお墨付きをもらえると安心してGlue versionを最新にできます。
最後に
今回のAWS Glueの新機能は、生成AIを活用して古いバージョンのSparkジョブを効率的にアップグレードするという、データエンジニアにとって非常に有用なツールです。ちょっと先の未来には非エンジニアがVisual Editorで作成したSparkジョブのアップグレードなどにも役立ちそうです。
Amazon Bedrockを基盤としたこの機能は、Sparkスクリプトと設定の分析と更新を自動化することで、アップグレードにかかる時間と労力を削減します。このプロセスは、分析からアップグレードプランの生成、反復的な改善、検証、そして最終的なレビューと展開までを含みます。これにより、複雑なアップグレード作業が簡素化されるだけでなく、データパイプラインの信頼性も維持されます。
実際の操作では、Glue ETLジョブを選択し、AIによるアップグレード分析を実行することで、自動的にスクリプトが最新バージョンに適合しているかどうかが判断されます。今回の例では、「glue2_spark_1」というジョブが分析され、既存のコードがGlue version 4.0と互換性があることが確認されました。このように、生成AIによる事前検証のおかげで、ユーザーは安心して最新バージョンへの移行を進めることができるでしょう。









