
AWS PCS に AWS 公式の AMI が登場し、自前ビルド不要で本番環境でも利用できるようになりました
はじめに
AWS Parallel Computing Service(AWS PCS)向けに、本番環境用でも利用可能な AWS 公式の AMI がやっと登場しました。 その名もPCS-ready Deep Learning AMI(DLAMI) です。
これまで AWS PCS が公式に提供する AMI は、本番利用は非推奨のサンプル AMI(Amazon Linux 2023 + Slurm のみ)だけでした。本番で GPU ワークロードを動かすには、PCS Agent、Slurm に加えて NVIDIA ドライバ、CUDA、EFA ドライバも要ります。これらを組み込んだカスタム AMI を自前でビルドする必要がありました。ようやく AWS 公式からサンプルではない AMI が提供され、自前の AMI ビルドから解放されたという大変めでたいアップデートです。
確認結果
最小構成(ログインノード×1 + GPU コンピュートノード×1)の PCS クラスターを起動し、ログインノードから srun で GPU コンピュートノードにジョブを投入できました。DLAMI にプリインストールされた NVIDIA ドライバ、CUDA、Slurm を最低限確認しました。
PCS-ready DLAMI とは
PCS-ready DLAMI は、AWS が提供する本番利用可能な AMI です。 Deep Learning Base GPU AMI(Ubuntu 24.04)をベースにしています。PCS で GPU ワークロードを動かすのに必要なコンポーネントを、プリインストール済みの状態で提供されています。
含まれる主なコンポーネントは次のとおりです。
| コンポーネント | バージョン(ami-0178c9707ea4aeb0d) |
|---|---|
| OS(Ubuntu 24.04) | 24.04 |
| NVIDIA GPU ドライバ | 595.71.05 |
| CUDA Toolkit | 13.2 |
| PCS Agent | 1.4.0-1 |
| Slurm for AWS PCS | 24.11 / 25.05 / 25.11 |
| EFS ユーティリティ | 2.4.2 |
Slurm は 3 バージョンがバンドルされ、クラスターの設定に合わせて起動時に自動で選ばれます。各バージョンは AMI の説明(Description)欄でも確認できます。
一方、PyTorch、TensorFlow、JAX などの学習フレームワークは含まれません。これら必要なアプリケーションは従来どおり別途追加することになります。
AWS PCS の歴史を語る
従来の AWS PCS には、本番で利用してよい公式 AMI がありませんでした。提供されていたのはサンプル AMI(Amazon Linux 2023 + Slurm のみ)で、公式ドキュメントでも本番利用は非推奨と明記されています。
Sample AMIs are for demonstration purposes and are not recommended for production workloads.
本番で動かすには、利用者が自分でカスタム AMI をビルドして検証する必要がありました。PCS-ready DLAMI はこの位置づけを変えるもので、公式ドキュメントは「カスタム AMI のビルドと検証の代わりに、数分でクラスターをデプロイできる」と説明しています。「なぜ、最初からそうしなかったのか」を説明して欲しいお気持ちです。
It provides a production-ready foundation so you can deploy clusters in minutes instead of building and validating custom AMIs.
追加費用はなく、EC2 インスタンスの料金のみで使えます。x86_64 と arm64 の両アーキテクチャに対応しています。
AMI ID の取得方法
AMI ID は SSM のパブリックパラメータから取得できます。
# x86_64(今回使用)
aws ssm get-parameter --region ap-northeast-1 \
--name /aws/service/pcs/ami/dlami-base-ubuntu2404/x86_64/latest/ami-id \
--query "Parameter.Value" --output text
ami-0178c9707ea4aeb0d
検証時点(2026 年 6 月)では ami-0178c9707ea4aeb0d が解決されました。DLAMI の更新で AMI ID は変わります。SSM パラメータパスは DLAMI が更新されても変わりません。
コンソールから作成する場合は、コンピュートノードグループ作成画面の AMI 選択で PCS-ready AMIs を選ぶと、DLAMI が候補に出てきます。
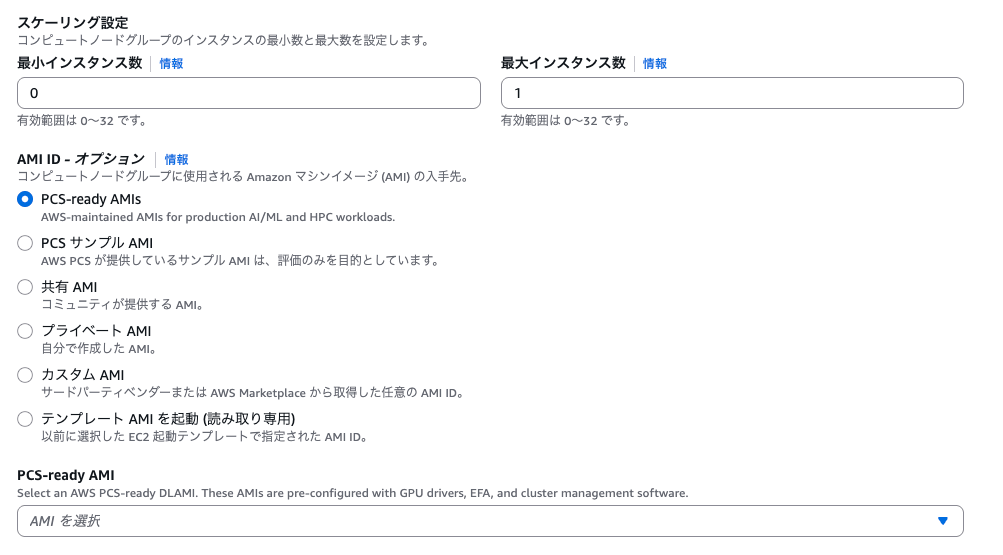
思いの外、候補が多かった。
今回の検証環境
最小構成として次のリソースを作ります。
| リソース | 設定 |
|---|---|
| PCS クラスター | Slurm 25.11、サイズ SMALL |
| ログインノードグループ | c6i.large、min=1/max=1(常時 1 台起動) |
| コンピュートノードグループ | g4dn.xlarge ×1、min=1/max=1(常時 1 台起動) |
PCS には専用のログインノード用リソースはありません。ログインノードもコンピュートノードグループとして作り、キューに関連付けないことでジョブ投入専用ノードにします。キューに関連付けると Slurm がそのノードにもジョブをスケジュールするため、キューへは GPU 用のコンピュートノードグループのみを関連付けます。
GPU コンピュートノードグループは 1a/1c/1d の 3 AZ のプライベートサブネットに配置しました。GPU インスタンスの確保が最近は難しく、特定 AZ のみ限定するより AZ を広げておくことで起動できる確率が上がります(後述)。
ログインノードと GPU コンピュートノードには同じ DLAMI を使います。DLAMI は GPU ドライバを含みますが、非 GPU インスタンス(c6i.large)でも問題なく起動します。
構築したクラスターを確認する
クラスター構築手順は割愛し、起動したクラスターを AWS CLI で確認していきます。
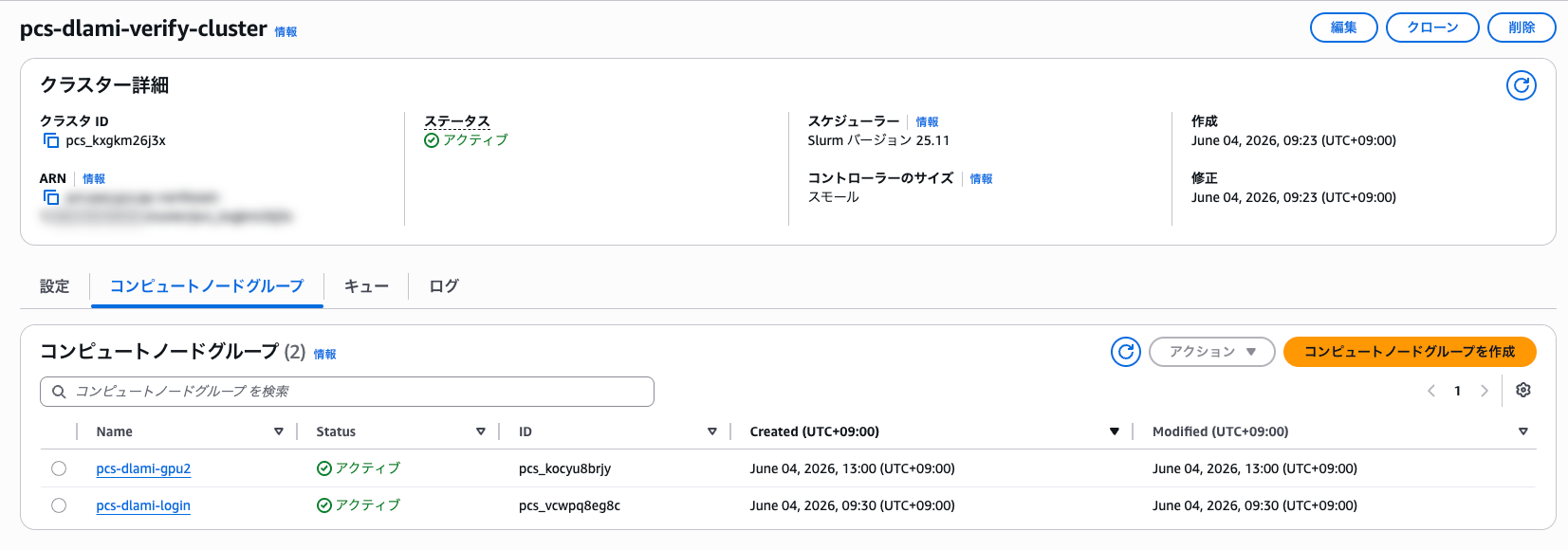
クラスターとノードグループの ID を確認する
以降のコマンドで使う ID を取得します。list-compute-node-groups の --cluster-identifier には、list-clusters で得たクラスター ID を渡します。ここでは pcs_kxgkm26j3x です。
aws pcs list-clusters \
--region ap-northeast-1 \
--query "clusters[].{name:name,id:id,status:status}" \
--output table
aws pcs list-compute-node-groups \
--region ap-northeast-1 \
--cluster-identifier pcs_kxgkm26j3x \
--query "computeNodeGroups[].{name:name,id:id,status:status}" \
--output table
----------------------------------------------------------------------
| ListClusters |
+----------------------------+------------------+--------------------+
| pcs-dlami-verify-cluster | pcs_kxgkm26j3x | ACTIVE |
+----------------------------+------------------+--------------------+
------------------------------------------------------------
| ListComputeNodeGroups |
+-------------------+------------------+-------------------+
| pcs-dlami-login | pcs_vcwpq8eg8c | ACTIVE |
| pcs-dlami-gpu | pcs_kocyu8brjy | ACTIVE |
+-------------------+------------------+-------------------+
EC2 インスタンスの起動を確認する
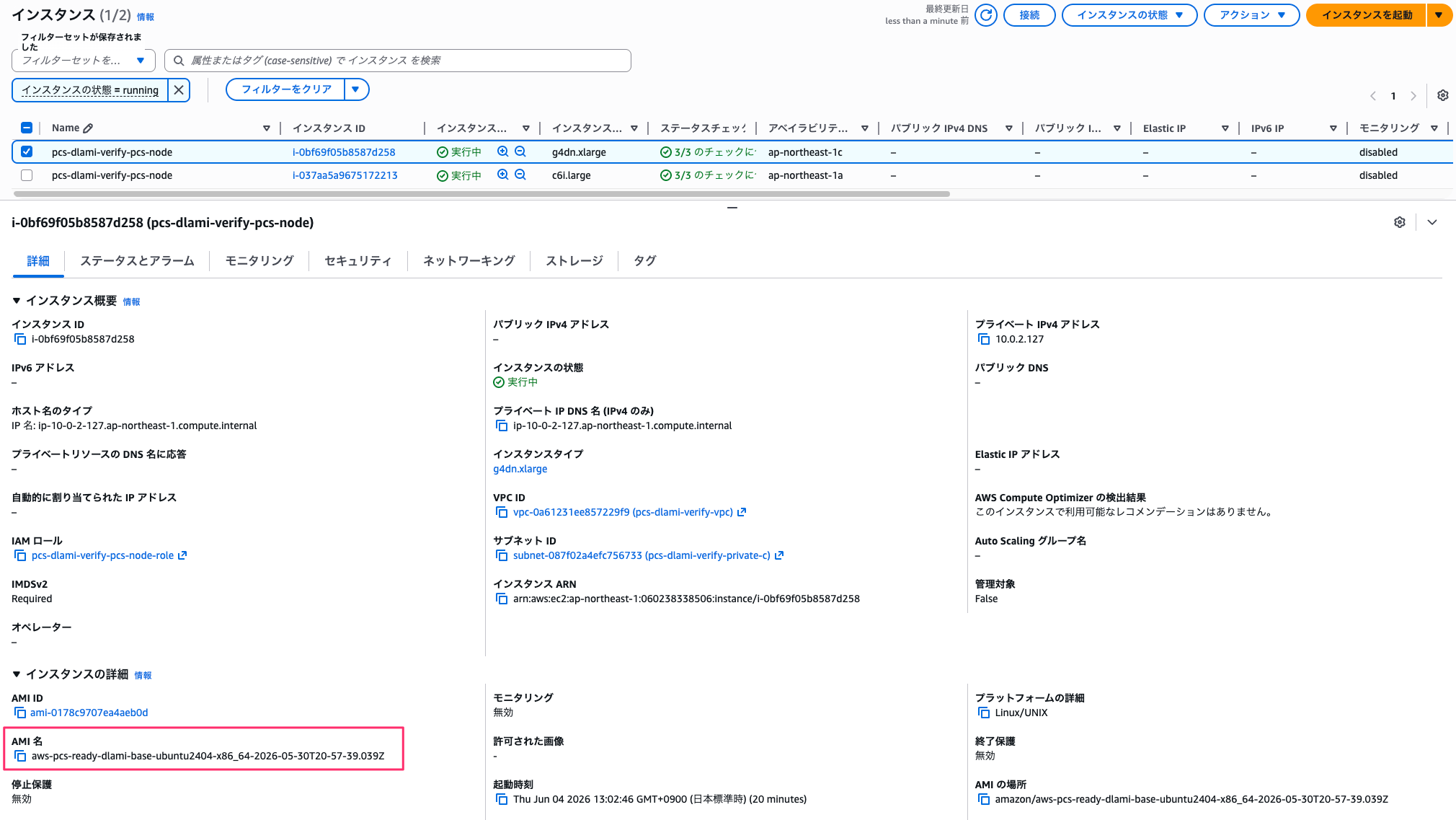
GPU ノードは 3 つのプライベートサブネットのうち、空きのあった ap-northeast-1c で起動しました。
aws ec2 describe-instances \
--region ap-northeast-1 \
--filters \
"Name=tag:aws:pcs:compute-node-group-id,Values=pcs_kocyu8brjy" \
"Name=instance-state-name,Values=running" \
--query "Reservations[].Instances[].[InstanceId,InstanceType,State.Name,Placement.AvailabilityZone]" \
--output table
---------------------------------------------------------------------------
| DescribeInstances |
+----------------------+--------------+----------+-------------------------+
| i-0bf69f05b8587d258 | g4dn.xlarge | running | ap-northeast-1c |
+----------------------+--------------+----------+-------------------------+
AMI も今回の DLAMI が使われています。
ログインノードに接続して Slurm の状態を確認する
SSM Session Manager で接続する
Session Manager でログインノードに接続します。
aws ssm start-session \
--region ap-northeast-1 \
--target i-037aa5a9675172213
接続後、DLAMI は Ubuntu 24.04 ベースのため、作業ユーザーは ubuntu です。
sudo su - ubuntu
Slurm のコマンド(sinfo など)は /opt/aws/pcs/scheduler/slurm-25.11/bin にあります。sudo su - ubuntu でログインシェルとして入ると、/etc/profile.d/slurm.sh によってこのパスが PATH に追加されます。
Slurm の状態を確認する
sinfo でパーティションとノードの状態を確認します。
sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
pcs-dlami-gpu-queue up infinite 1 idle pcs-dlami-gpu-1
パーティション pcs-dlami-gpu-queue が UP で、GPU ノード pcs-dlami-gpu-1 が表示されました。Slurm のバージョンも確認します。
sinfo --version
slurm 25.11.2
scontrol show node でノードの詳細を見ると、Gres=gpu:T4:1 から、Tesla T4 が 1 基の GPU リソースとして認識されていることがわかります。
scontrol show node pcs-dlami-gpu-1
NodeName=pcs-dlami-gpu-1 ...
AvailableFeatures=pcs-dlami-gpu,gpu
Gres=gpu:T4:1
State=IDLE+CLOUD
ジョブを実行して GPUインスタンス の中身を確認する
nvidia-smi をジョブとして実行する
ログインノードから、GPU コンピュートノード上で nvidia-smi を実行します。パーティション名はキュー名と同じ pcs-dlami-gpu-queue です。
srun --partition pcs-dlami-gpu-queue nvidia-smi
NVIDIA Tesla T4(g4dn.xlarge に搭載)が 1 基認識され、Driver 595.71.05 と CUDA 13.2 が表示されました。
Thu Jun 4 04:10:32 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 595.71.05 Driver Version: 595.71.05 CUDA Version: 13.2 |
+-----------------------------------------+------------------------+----------------------+
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 35C P0 33W / 70W | 3MiB / 15360MiB | 0% Default |
+-----------------------------------------+------------------------+----------------------+
GPU の一覧と CUDA コンパイラ(nvcc)のバージョンも確認します。
srun --partition pcs-dlami-gpu-queue nvidia-smi -L
srun --partition pcs-dlami-gpu-queue bash -lc "nvcc --version"
DLAMI にプリインストールされた NVIDIA ドライバと CUDA Toolkit が、追加の構成なしでそのまま使えることを確認できました。
GPU 0: Tesla T4 (UUID: GPU-cc7ca819-...)
nvcc: NVIDIA (R) Cuda compiler driver
Cuda compilation tools, release 13.2, V13.2.51
GPU インスタンスのキャパシティ確保問題について
今回 g4dn.xlarge を選んだ理由があります。当初は g5.xlarge(NVIDIA A10G)で進めていました。ですが、ap-northeast-1 では InsufficientInstanceCapacity が続き、GPU ノードを起動できませんでした。人気の GPU インスタンスは、AZ や時間帯によって空きが無いこともあります。対象のインスタンスタイプがどの AZ で提供されているかまず確認しておきましょう。
aws ec2 describe-instance-type-offerings \
--region ap-northeast-1 \
--location-type availability-zone \
--filters "Name=instance-type,Values=g5.xlarge,g4dn.xlarge" \
--query "sort_by(InstanceTypeOfferings, &InstanceType)[].[InstanceType,Location]" \
--output text
g4dn.xlarge ap-northeast-1a
g4dn.xlarge ap-northeast-1c
g4dn.xlarge ap-northeast-1d
g5.xlarge ap-northeast-1a
g5.xlarge ap-northeast-1c
ap-northeast-1 では g5.xlarge が 1a・1c のみで、g4dn.xlarge は 3 AZ すべてで提供されていました。提供 AZ があっても空きが少ないと起動できないため、とれる対策は次の 2 つです。
- コンピュートノードグループのサブネットを複数 AZ に広げ起動確率を上げる
- 容量を確保しやすそうな古めのインスタンスタイプ(今回は g4dn.xlarge)を選ぶ
今回は両方を採り、GPU ノードグループを 1a/1c/1d の 3 サブネットに広げたうえで g4dn.xlarge を使いました。結果として ap-northeast-1c で起動しています。
まとめ
今回試したのは、PCS-ready DLAMI を使った最小構成(ログインノード×1 + GPU コンピュートノード×1)の起動です。AMI ID に DLAMI を指定するだけで、NVIDIA ドライバ、CUDA、Slurm、PCS Agent 入りのノードが起動しました。自前でセットアップする手間がまるごと省けるので、ここが一番ありがたいところでした。
おわりに
AWS PCS リリースから、1 年 10 か月を経てやっと AWS 公式から本番環境で使ってよい AMI が提供されました。これで敷居はだいぶ下がったのではないでしょうか、よかったです。








