
Amazon Bedrockを題材にした生成AIセキュリティワークショップに参加してきた #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
おのやんです。
現在re:Invent2024に現地参加しており、今回はAmazon Bedrockを題材にした生成AIセキュリティワークショップに参加することができたので、こちらの内容をまとめたいと思います。
ワークショップ概要
[SEC306] Securing your generative AI applications on AWS
In this workshop, discover how to secure generative AI applications using AWS services and features. Explore how to deploy a vulnerable sample generative AI application and then layer security controls to protect, detect, and respond to security issues.
[SEC306] AWSで生成AIアプリケーションを保護する
このワークショップでは、AWSのサービスと機能を使用して、生成AIアプリケーションを保護する方法を発見します。脆弱性のあるサンプルのジェネレーティブAIアプリケーションをデプロイし、セキュリティ問題を保護、検出、対応するためのセキュリティ制御をレイヤー化する方法を探ります。
会場の様子
今回はワークショップの予約はしていませんでした。普通だとWalk-upで入る時は人気セッションなんかはいっぱいで入れないケースもあるのですが、今回Venetian会場をうろついていたら掲示板で偶然こちらのワークショップを見つけ、「なんか面白そう!」ということでWalk-upにダメ元で並んでいたら参加できました。
今回も、席はど真ん中のど真ん前で受講しました。

ワークショップ内容まとめ
今回は、受付係と医師の2人だけが働いている小さな診療所で生成AIチャットbotを使っているというユースケースで進んでいきました。
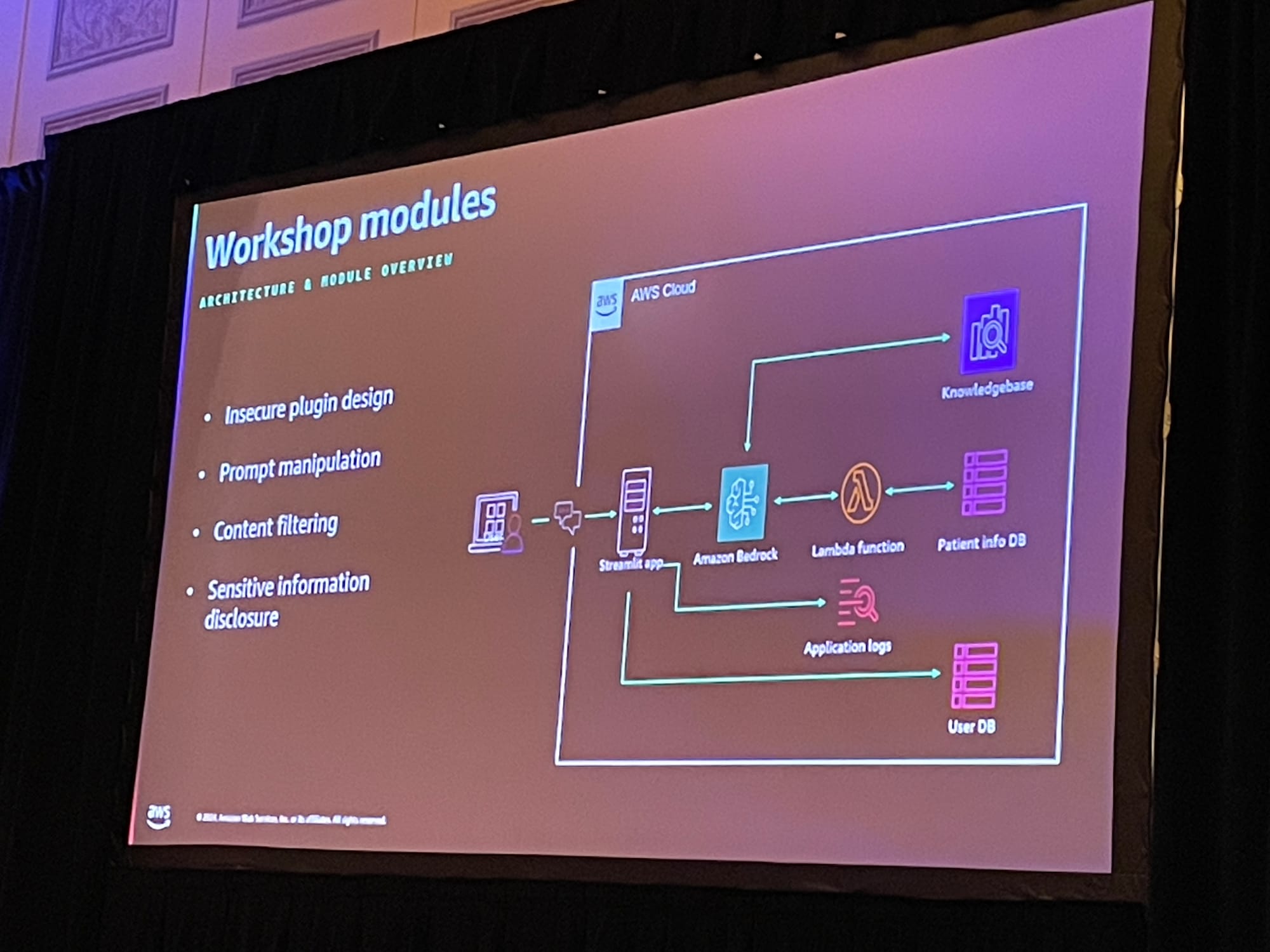
このチャットbotにはいくつか脆弱性があり、セキュリティ的に非常に危険な状態です。これらの脆弱性を、AWSサービスの設定というアプローチで解決していくワークショップでした。
なお、脆弱性を潰していく際は、NISTのCyberSecurity Frameworkをもとに、識別・防御・検出・対応の4つの観点からAWSサービスを設定していきました。その中で印象に残ったことも含めて、内容をざっくりダイジェストで紹介したいと思います。
危険なプラグインの修正
まず最初に、生成AIモデルによって呼び出されるプラグイン自体の脆弱性を修正していきました。ここでいうプラグインとは、ユーザーとのやり取り中に言語モデルによって自動的に呼び出される拡張機能のことを指します。
今回はプラグインはLambdaで作成されていたため、このLambdaに対して修正を加えたり、あとはBedrock自体に制限を賭けてセキュリティを高めると言った修正が多かったです。なお、今回のチャットbotのテストは、promptfooというツールで実行されていました。
具体的には、生成AIチャットbotに実装されているプラグイン(Lambdaで実装されている)に条件分岐分を追加して、特定のロールのユーザーが特定の情報を生成できないようにしたりしていました。
またBedrock側では、Bedrockガードレールを設定して、悪意ある攻撃(プロンプトインジェクション・)を予防していました・ここでいう「悪意ある攻撃」とは、
- 使用されているモデルの ID を抽出して、悪用される可能性のある既知の脆弱性がないか確認
- モデルに JSON 形式または表形式で情報を出力させて、システム プロンプトに組み込まれている保護を回避させる
などがあるそうです。Bedrockではこれらの設定を行っていました。
- ガードレールを作成してBedrockエージェントに適用
- アプリケーションログからガードレールのアクションを抽出するCloudWatchカスタムメトリクスを設定
- CLoudWatchを用いて、トリガーされたガードレールを監視してアラート発出
CloudWatchのメトリクスフィルターはこんな感じです。
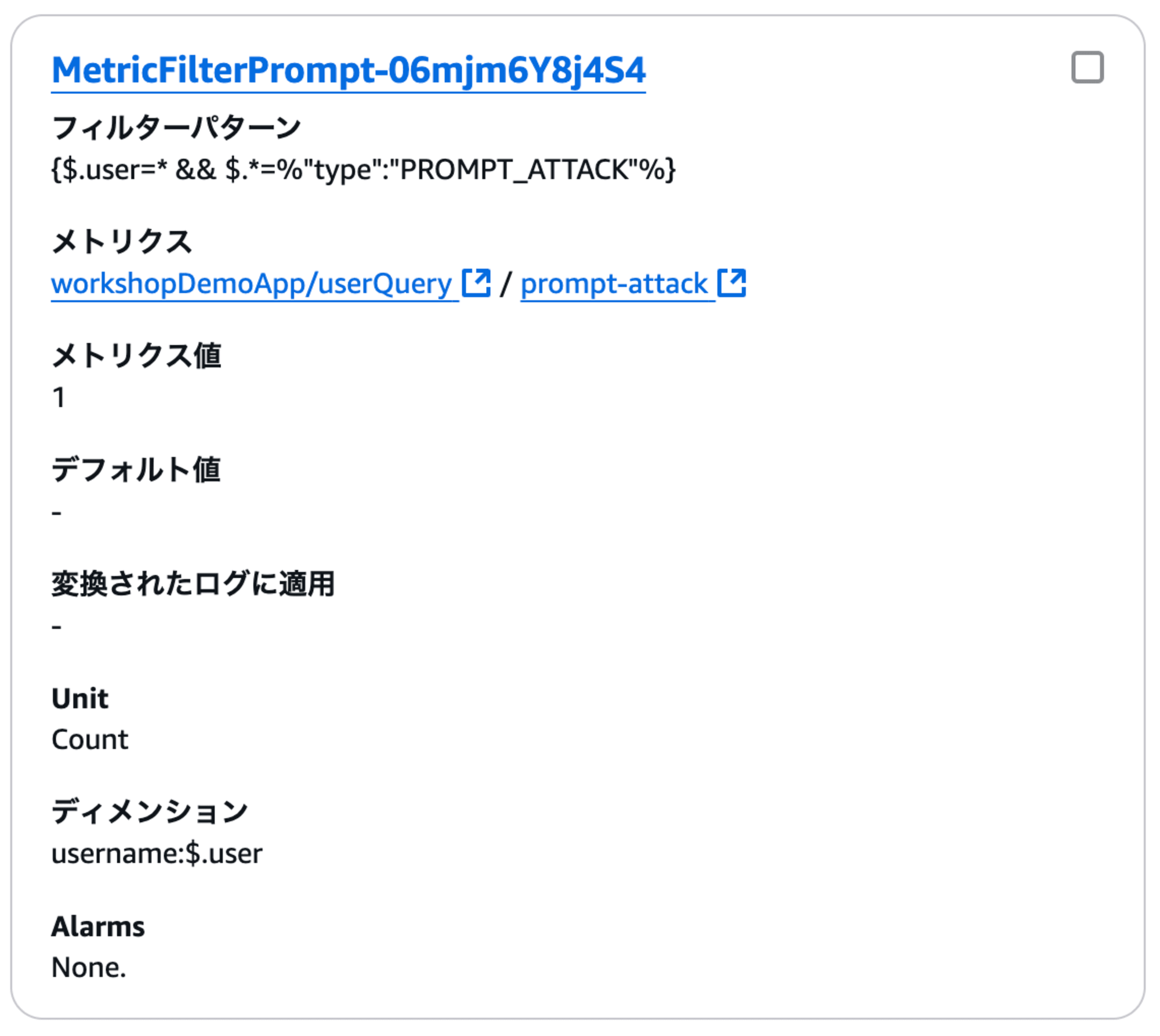
このCloudWatch メトリック アラームはわざと低いしきい値が設定されており、このしきい値に達するとLambda 関数が呼び出されてチャットボットが無効になるという仕組みです。
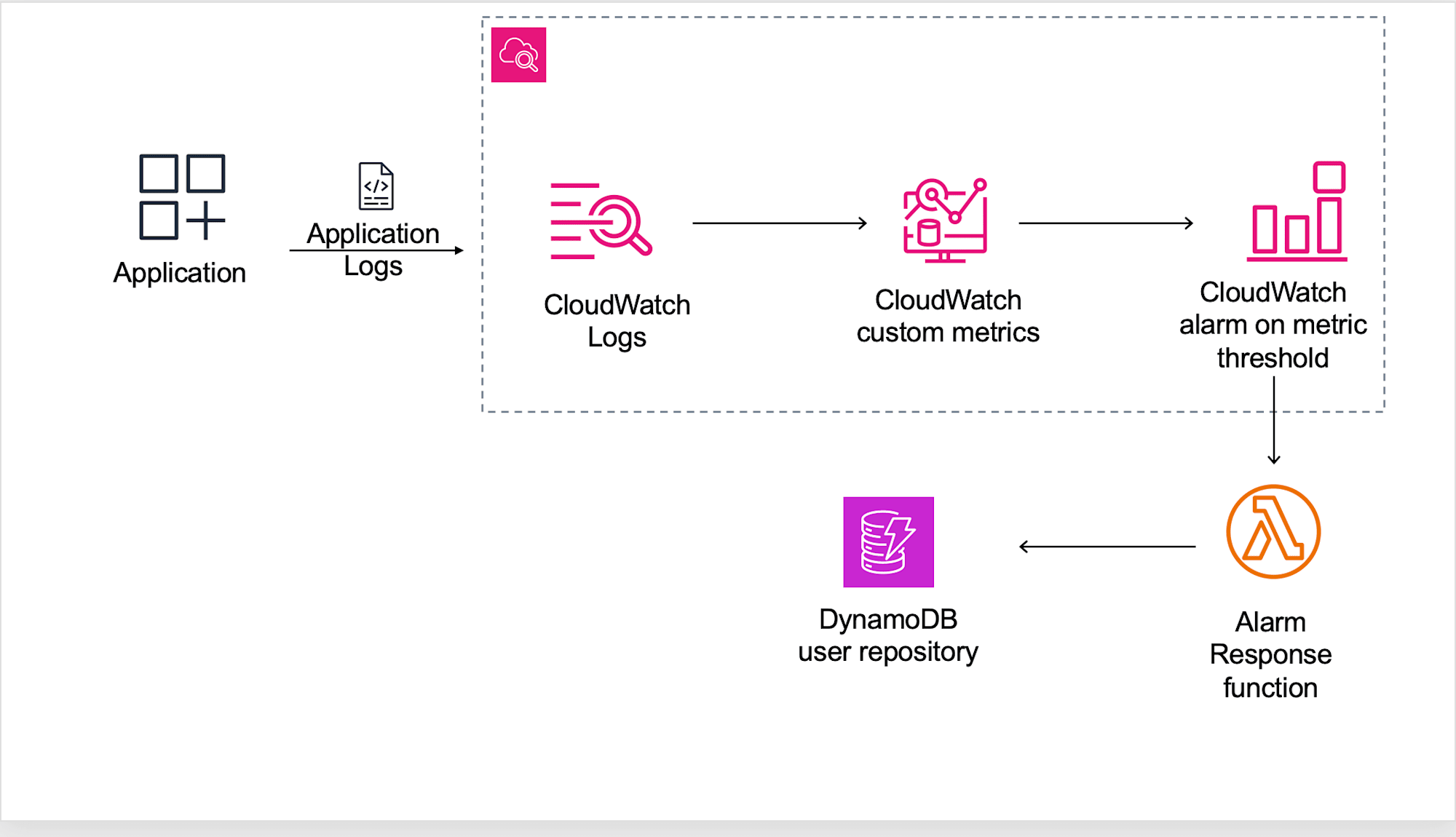
ちなみにチャットボットを無恋化する関数はこんな感じでした。
# Lambda function to handle CloudWatch alarms and update user status in DynamoDB
import boto3
import json
import logging
# Initialize logger
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# DynamoDB table name
DYNAMODB_TABLE_NAME = "UserTable"
# Initialize DynamoDB resource
dynamodb = boto3.resource('dynamodb', region_name='us-west-2')
table = dynamodb.Table(DYNAMODB_TABLE_NAME)
def update_user_status(username, status):
"""
Updates the user's status in DynamoDB.
"""
try:
response = table.update_item(
Key={'name': username},
UpdateExpression="SET #status = :status",
ExpressionAttributeNames={"#status": "status"},
ExpressionAttributeValues={":status": status},
ReturnValues="UPDATED_NEW"
)
logger.info(f"User {username} status updated to {status}: {response}")
except Exception as e:
logger.error(f"Failed to update user {username} status to {status}: {e}")
raise
def lambda_handler(event, context):
"""
Lambda function to process CloudWatch alarm events and update user status in DynamoDB.
"""
logger.info(f"Received event: {json.dumps(event)}")
try:
# Extract alarm details
alarm_data = event.get('alarmData', {})
if not alarm_data:
raise ValueError("Missing 'alarmData' in event.")
# Extract current alarm state and previous state
state = alarm_data.get('state', {}).get('value')
previous_state = alarm_data.get('previousState', {}).get('value')
if not state or not previous_state:
raise ValueError("Missing 'state' or 'previousState' in alarmData.")
# Extract metrics configuration
metrics = alarm_data.get('configuration', {}).get('metrics', [])
if not metrics:
raise ValueError("Missing 'metrics' in alarm configuration.")
# Find username from dimensions
for metric in metrics:
dimensions = metric.get('metricStat', {}).get('metric', {}).get('dimensions', {})
username = dimensions.get('username')
if username:
logger.info(f"Processing user: {username}")
# Handle state transitions
if previous_state == "OK" and state == "ALARM":
logger.info(f"Transition detected: OK -> ALARM for user {username}. Disabling user.")
update_user_status(username, "disabled")
return {"statusCode": 200, "body": f"User {username} disabled successfully."}
elif previous_state == "ALARM" and state == "OK":
logger.info(f"Transition detected: ALARM -> OK for user {username}. Re-enabling user.")
update_user_status(username, "enabled")
return {"statusCode": 200, "body": f"User {username} re-enabled successfully."}
else:
logger.info(f"No action required for transition {previous_state} -> {state}.")
return {"statusCode": 200, "body": f"No action required for {username}."}
raise ValueError("No username found in alarm dimensions.")
except Exception as e:
logger.error(f"Error processing CloudWatch alarm: {e}")
return {"statusCode": 500, "body": str(e)}
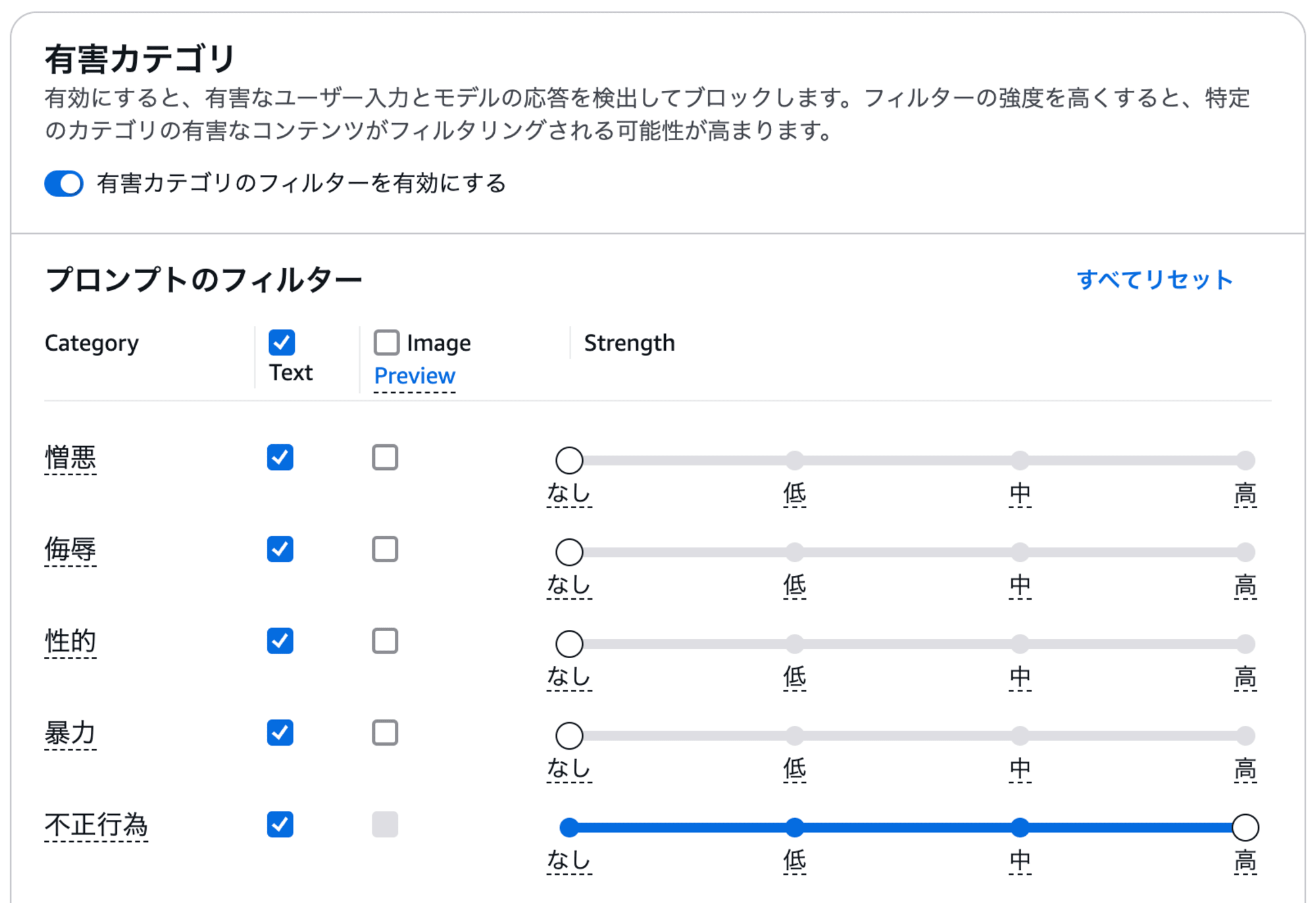
有害なコンテンツのフィルタリング
大規模な言語モデルで注意なのが、トレーニングされているコンテンツの量が多いため、間違っていたり、悪意のあるプロンプトが入力されることによって、有害なコンテンツが生成される可能性があります。こちらを防止する目的で、プロンプトと出力の両方を検査するためのガードレールを実装しました。
ちなみに余談ですが、ガードレールの有害カテゴリの画面がアップデートしていて、ちょっと操作に困りました。
またこちらにも同じように、CloudWatchログにメトリクスフィルターを設定しました。

情報漏洩の防止
RAGによっては、本来閲覧できるべきではないロールの職員にも情報が閲覧できてしまったりします。こちらを防ぐために、BedrockのナレッジベースでBedrock メタデータフィルタリングを設定しました。これにより、Bedrock ナレッジベースのソースデータをフィルタリングし、特定のロールのみが特定のデータにアクセスできるように修正しました。
また、今回のワークショップの資料を見ていて勉強になったのが、ソースデータによるBedrockサービスの向き不向きです。このセクションで使っているBedrock ナレッジベースは、ソースドキュメントが通常静的であり、リアルタイムで変更されません。更新ごとにデータ ストアを同期する必要があるため、ナレッジ ベースは動的データよりもまとまった静的コンテンツに最適とのことです。データベース内のユーザーデータなど、頻繁に変更される情報を処理する場合は、Bedrock エージェントやその他のリアルタイムデータ処理メカニズムが適切であるようです。
ワークショップを受けてみて
今回のワークショップで一番変わったのは、私のBedrockに対するイメージかもしれません。具体的には、以下のように変わりました・
いままで:BedrockはAWSで生成AIモデルがAPI経由でつける便利なサーバーレスサービス
これから:生成AIモデルの対して、必要な監視や通知・制限をかけて管理できる、総合AIモデルサービス
さまざまなAWSサービスに触ることができ、こちらも非常に面白かったです。Bedrock関係のサービスが増えていって追えていなかったのですが、これを気にもう少し勉強していきたいと思いました。
[最後に]後ろを通った外国人も、very nice workshopってはっきり言ってた。









