![【セッションレポート】AWS DevOps Agent による自律的インシデント対応 -その能力を引き出す設計のベストプラクティス- [CNS319]](https://images.ctfassets.net/ct0aopd36mqt/7cN8mkB4Ni5uqeEvJpsSW1/b629d0b5a4a192e6547eaa743065e1bd/aws-summit-japan2026_session.png?w=3840&fm=webp)
【セッションレポート】AWS DevOps Agent による自律的インシデント対応 -その能力を引き出す設計のベストプラクティス- [CNS319]
はじめに
かつまたです。
本記事は「AWS DevOps Agent による自律的インシデント対応 -その能力を引き出す設計のベストプラクティス-」の聴講レポートです。
セッション概要
タイトル : AWS DevOps Agent による自律的インシデント対応 -その能力を引き出す設計のベストプラクティス-
セッションスピーカー: 加藤 正樹氏
所属: ソリューションアーキテクト, AWS
AWS DevOps Agent は、生成 AI による自律的なインシデント調査・根本原因分析・緩和策提案を行うフロンティアエージェントです。汎用 AI エージェントを運用に組み込むには、安全に自走させる仕組みの整備等、考慮すべき点が多々あります。DevOps Agent はこれらの課題に応える AI エージェントです。本セッションでは DevOps Agent の仕組みを理解した上で、 スコープ設計やナレッジの整備といった、 その能力を引き出す設計のベストプラクティスをお話しします。
本セッションのまとめ
- AWS DevOps Agent は「調査は AI、判断は人」をコンセプトとした、障害対応と運用改善に特化した AI エージェント
- 能力を引き出す設計のベストプラクティスは 3 つ: 調査スコープ設計(Agent Space)、テレメトリの充実、ナレッジの共有(Skills / Agent Instructions)
- MCP サーバーによる外部ツール連携で、既存の監視ツールやチケットシステムとの統合も可能
アジェンダ
- 運用に AI を組み込むには
- デモ
- 能力を引き出す設計のベストプラクティス
- 応用編 〜さらなる拡張〜
- まとめ
セッション内容
運用に AI を組み込むには
障害タイムラインと課題
障害発生から復旧までのタイムラインにおいて、Time to Resolve 短縮の鍵は初動と調査・切り分けにあるとの説明がありました。
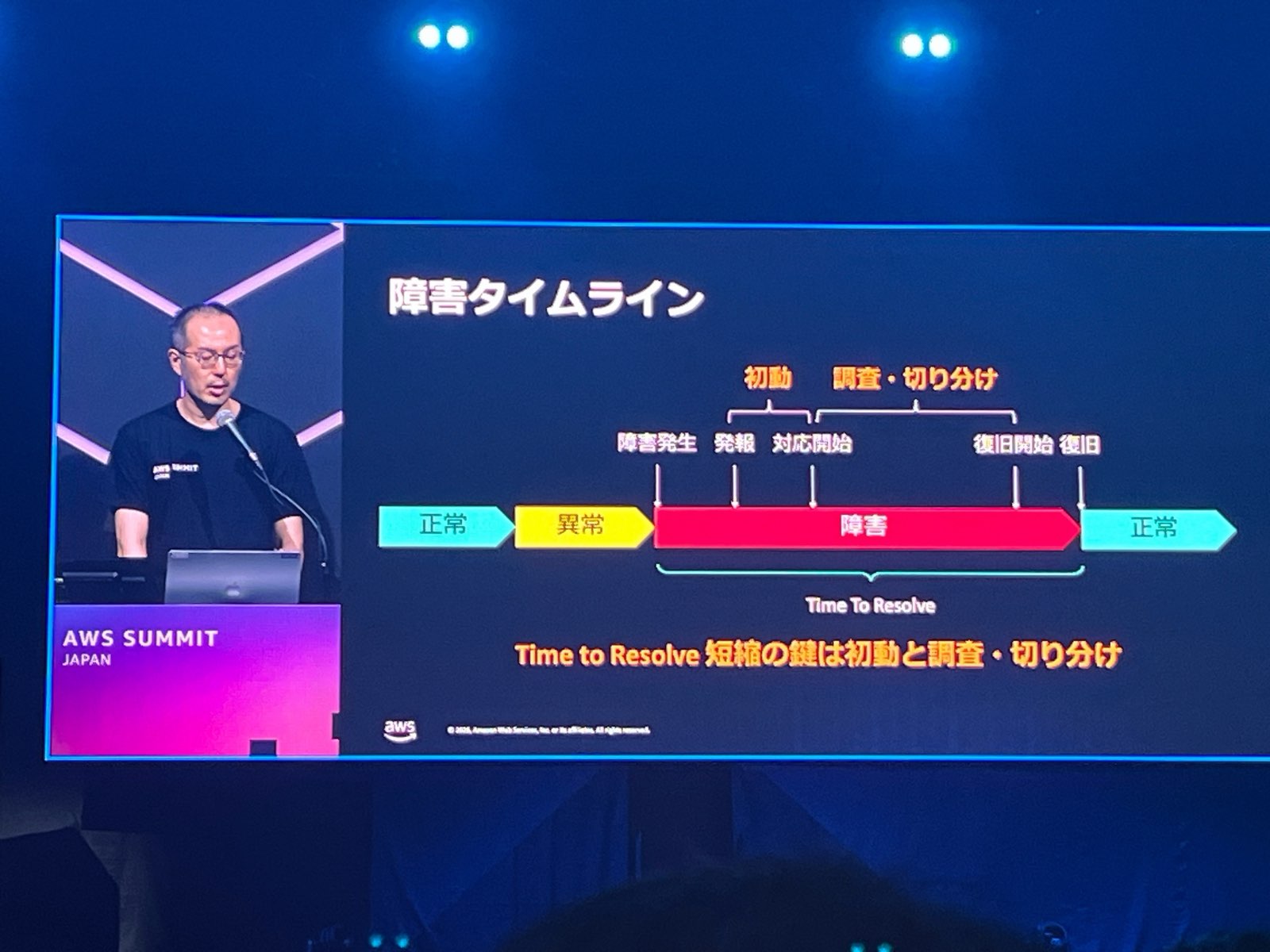
しかし、現実の障害調査は長期化しがちです。その原因として以下が挙げられました。
- アプリの複雑化で問題箇所の絞り込みが難航
- ツールを跨いだテレメトリ調査
- ナレッジが属人化し、特定の人しか対応できない

AI 利用の課題
汎用 AI を障害対応に組み込む際、大きく 3 つの課題があります。
挙動の課題 : AI に判断保留で人を待たせると「止まる」、自走させると勝手に判断・実行して「暴走する」。自走しつつ、危険な行動はしない仕組みが必要です。

調査ロジックの課題 : テレメトリ、システム構成、パイプライン、コードリポジトリ、変更履歴など多様なデータソースを横断する調査ロジックが必要です。

コンテキスト整備の課題 : 整備直後は全員のセットアップが揃いコンテキストも共有されていますが、運用するうちにメンバー間の差が広がります。チーム全員で同じコンテキストを維持する仕組みが必要です。

デモ
CloudWatch アラームをトリガーに DevOps Agent が自律的に調査を開始するデモが行われました。複数の調査結果をタイムライン形式で統合分析し根本原因を特定した上で、準備→事前検証→適用→事後検証→ロールバックまでカバーした緩和計画を提示していました。

能力を引き出す設計のベストプラクティス
セッションの中核となるパートです。3 つのベストプラクティスが紹介されました。
- 調査スコープを決めて精度を引き出す
- テレメトリを充実させて正確性を上げる
- ナレッジを共有して時間を短縮する

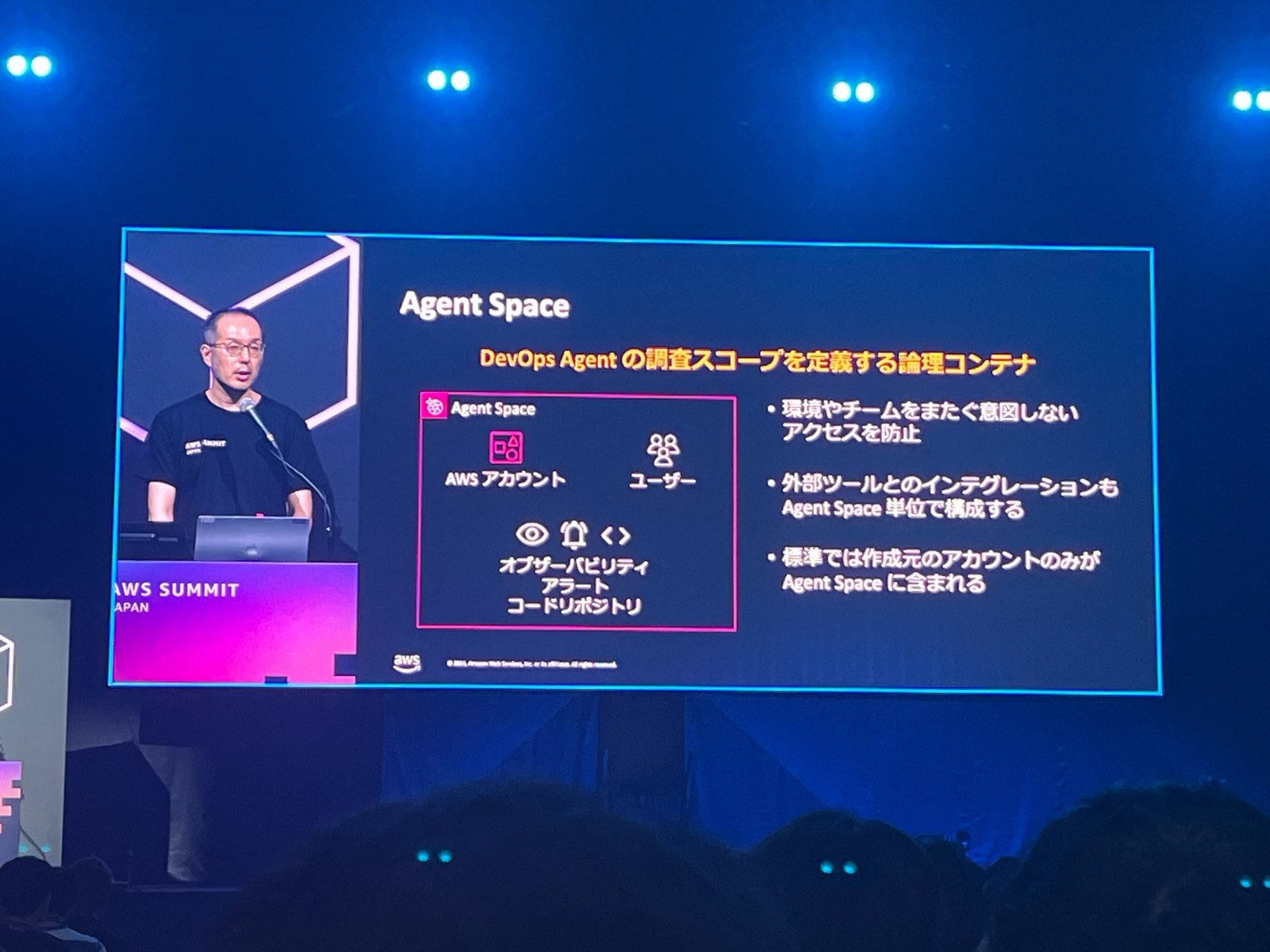
1. 調査スコープを決めて精度を引き出す — Agent Space
Agent Space は、DevOps Agent の調査スコープを定義するコンテナです。AWS アカウント、ユーザー、オブザーバビリティ、アラート、コードリポジトリを束ねます。
- 環境やチームをまたぐ意図しないアクセスを防止
- 外部ツールとのインテグレーションも Agent Space 単位で構成
- 標準では作成元のアカウントのみが Agent Space に含まれる
同一システムが複数アカウントにまたがる場合、標準の Agent Space ではアカウント単位で調査が限定され根本原因にたどり着けないことがあります。解決策として、Agent Space はシステム単位でまとめることで横断調査が可能になります。

また、1 アカウント内でタグ・リージョン等により複数 Agent Space に分けたり、共通基盤を複数チームの Agent Space に含めることも可能です。
2. テレメトリを充実させて正確性を上げる
テレメトリが充実すれば調査は深まります。デモでは、アプリケーションログがインシデント時間帯に存在しないために調査が浅くなる「調査ギャップ」が示されました。
テレメトリ拡充の方法として、インフラ面では Insights ファミリー(Container Insights / Database Insights / Lambda Insights)でマネージドサービスの内部状態まで観測すること、アプリケーション面ではメトリクス・ログ・トレースの 3 本柱を整備することが紹介されました。OpenTelemetry(OTel)の活用も推奨されていました。

3. ナレッジを共有して時間を短縮する
ナレッジの有無で調査時間が大きく変わります。デモでは、同じ障害に対してナレッジ整備前は根本原因到達まで 6 分 32 秒、整備後は 3 分 38 秒に短縮されました。

Skills で調査順序(例: DB 接続→Pod ステータス→リソース利用率)を教えることで、調査の優先順位を制御できます。
Skillsは DevOps Agent と対話しながら作成でき、Markdown のほか PDF や画像からの取り込みにも対応しています。
ナレッジ共有の進め方として、個別の手順は Skills、共通の前提は Agent Instructions で教える、というアプローチが紹介されました。

応用編 〜さらなる拡張〜
MCP サーバーによる外部連携
既存の監視ツール(Zabbix 等)、チケットシステム、社内ナレッジとの連携は MCP サーバーを介しての実現が紹介されました。

まとめ
セッション全体を通じた DevOps Agent のコンセプトは「調査は AI、判断は人」でした。

おわりに
本セッションを聴講し、ベストプラクティスとして挙げられたテレメトリの充実やナレッジの整備は、DevOps Agent に限った話ではなく運用の成熟度そのものに直結するなと感じました。
DevOps Agent を導入して終わりではなく、運用基盤の棚卸し・最適化など運用プロセス全体を見直すきっかけとして捉えることが重要だと感じました。










