
【セッションレポート】AI アプリケーションのためのデータエンジニアリング戦略 - Amazon Bedrock で実現する構造化データ活用(AWS-46) #AWSSummit
はじめに
こんにちは、コンサルティング部の神野です。
AWS Summit Japan 2025 の2日目で行われた、「AI アプリケーションのためのデータエンジニアリング戦略 - Amazon Bedrock で実現する構造化データ活用(AWS-46)」に参加してきました。
AI アプリケーションでのデータエンジニアリングってどういうことが必要なんだろう?とタイトルを見て気になったので本セッションに参加してみました。本記事ではそのレポートをお届けします。
セッション概要
タイトル :
AI アプリケーションのためのデータエンジニアリング戦略 - Amazon Bedrock で実現する構造化データ活用
概要:
生成 AI や機械学習を用いたアプリケーションがもたらすビジネス価値は、取り扱うデータの多様性や品質、整合性に大きく依存します。ゆえに取り組みを成功させるには、高品質なデータの可用性や利用可能性を実現するためのデータ戦略が重要です。加えて、生成 AI の急速な進化によってデータ活用の幅は広がり、企業が有する非構造化データや構造化データなど様々なデータを、自然言語での直感的な問い合わせで活用することが可能になり始めました。このセッションでは、生成 AI 時代において重要となるデータエンジニアリングやデータ活用の考え方をお話し、セッション後半では生成 AI のユースケースとして自然言語での構造化データ活用を取り上げます。自然言語から SQL への変換における課題と Amazon Bedrock Knowledge Bases の構造化データ取得機能に焦点を当て、デモを交えてご紹介します。
スピーカー :
森下 裕介(アマゾン ウェブ サービス ジャパン合同会社 技術統括本部 エンタープライズ技術本部 ソーシャルソリューション&サービスグループ ソリューションアーキテクト)
セッションレベル :
Level 300
セッション内容
生成AI時代におけるデータの重要性
森下さんは冒頭で、「生成AIのセッションなのになぜデータの話?」と思われるかもしれないと前置きした上で、Amazonにおける長年のAI/ML活用から得た最も重要な学びは「データが差別化に繋がる」ということだと強調されました。
今やAIエンジニアでなくても誰でもプロンプトを書ける時代になり、APIを通じて簡単に利用できる基盤モデルも多く存在しています。そんな状況で差別化を実現するのは、自社にしかないデータをAIアプリケーションに組み込むことだということです。
確かに汎用的なLLMは当たり前に使う時代になってきているので、より自社に特化した回答が業務では必要とされてくるのはイメージがつきます。
セゾンテクノロジー様の事例

具体例として、ファイル転送ツール「HULFT」を開発・販売するセゾンテクノロジー様の事例が紹介されました。長年蓄積されてきたマニュアルやFAQという膨大な自社情報への素早いアクセスが課題となっていたところ、Amazon Bedrockを用いたRAGシステムを構築することで下記を実現していました。
- サポートエンジニアの回答作成時間を最大30%削減
- 社内全部門展開後、80%のユーザー満足度と24%の業務効率向上を実現
この成果は汎用的な基盤モデルだけでは達成できず、自社製品に関するデータと生成AIを組み合わせることで初めて実現できた「データによる差別化」の素晴らしい事例だと説明されました。
非構造化データと構造化データ
生成AIが意味表現を柔軟に理解できるようになったことで、ドキュメントや画像などの非構造化データとの相性が良いことは知られています。企業内でのデータ基盤、データパイプラインの重要性は生成AI時代でも変わらず、むしろより重要になっているとのことでした。
しかし、企業には非構造化データだけでなく、以下のような構造化データも多く存在します。
- 小売業:商品の注文や売上データ
- 製造業:工場の稼働データ
- 各種業務システムのデータ
データによる差別化を実現するには、全ての種類のデータを柔軟に活用していく必要があります。
今回はとりわけ構造化データの活用に注目して話が進んでいきます。
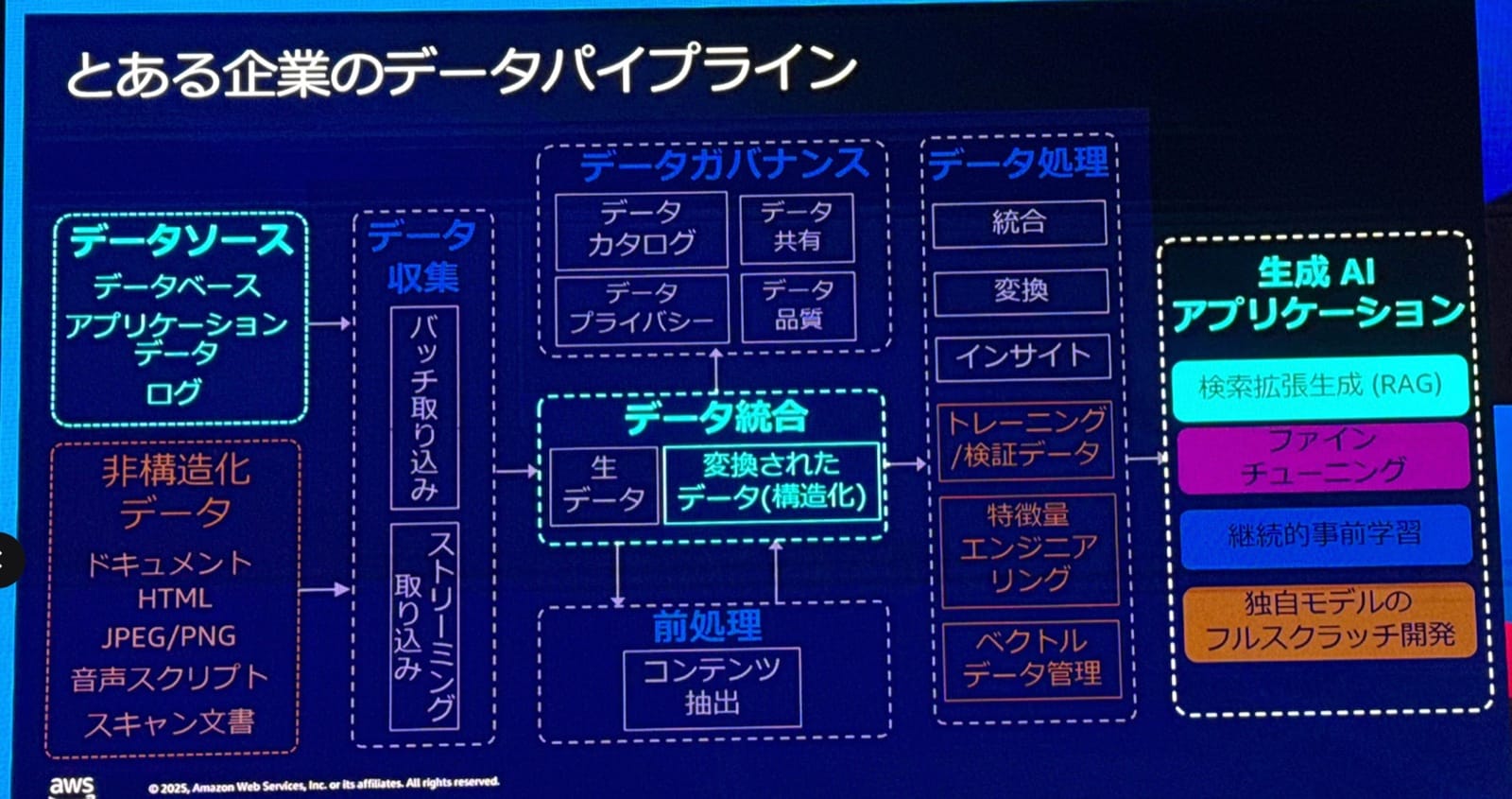
構造化データ活用の課題:NL2SQL
セッションでは架空の企業「Dカンパニー」を例に、構造化データ活用の課題が説明されました。Dカンパニーはオンラインショッピングサイトを運営しており、従業員が注文や売上データなどを自然言語でチャットから問い合わせできるようにしたいという要望があります。
例えば「2025年5月に最も売れた商品は?」という質問に答えるには下記のようにテーブル間の結合を考慮する必要があります。
- 注文テーブル
- 商品テーブル
- 注文-商品の紐付けテーブル
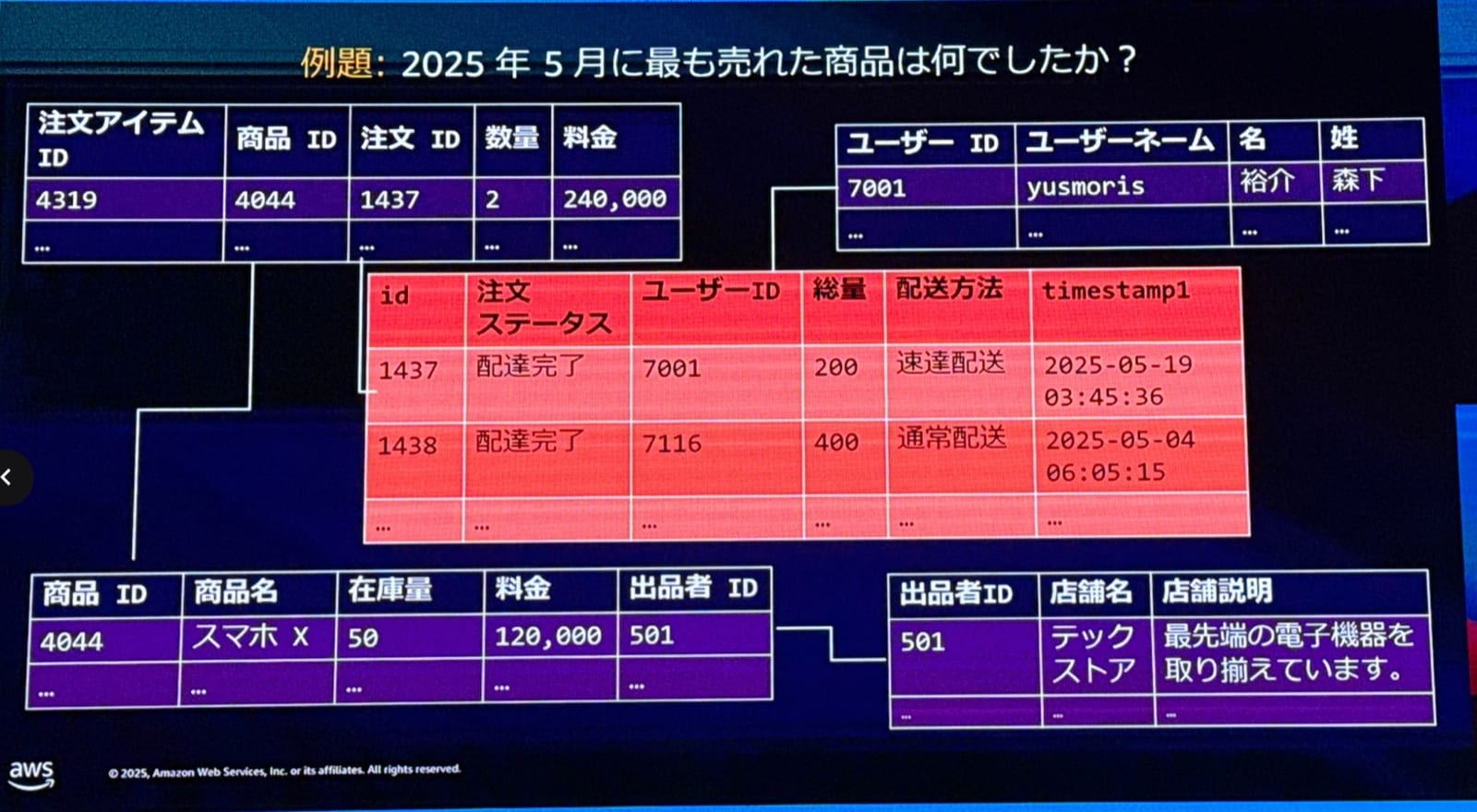

結合も配慮して自然言語からSQL変換するにはスキーマや色々な情報必要になる印象がありますね。
この後、課題について言及されます。
NL2SQL(自然言語からSQLへの変換)の難しさ
森下さんは3つの具体例を使って、NL2SQLがなぜ難しいのかを説明されました。
-
スキーマ構造の理解が必要
-
テーブル名やカラム名が実際のデータベースと一致していないとエラーになる
-
テーブル間の結合関係を正確に把握する必要がある
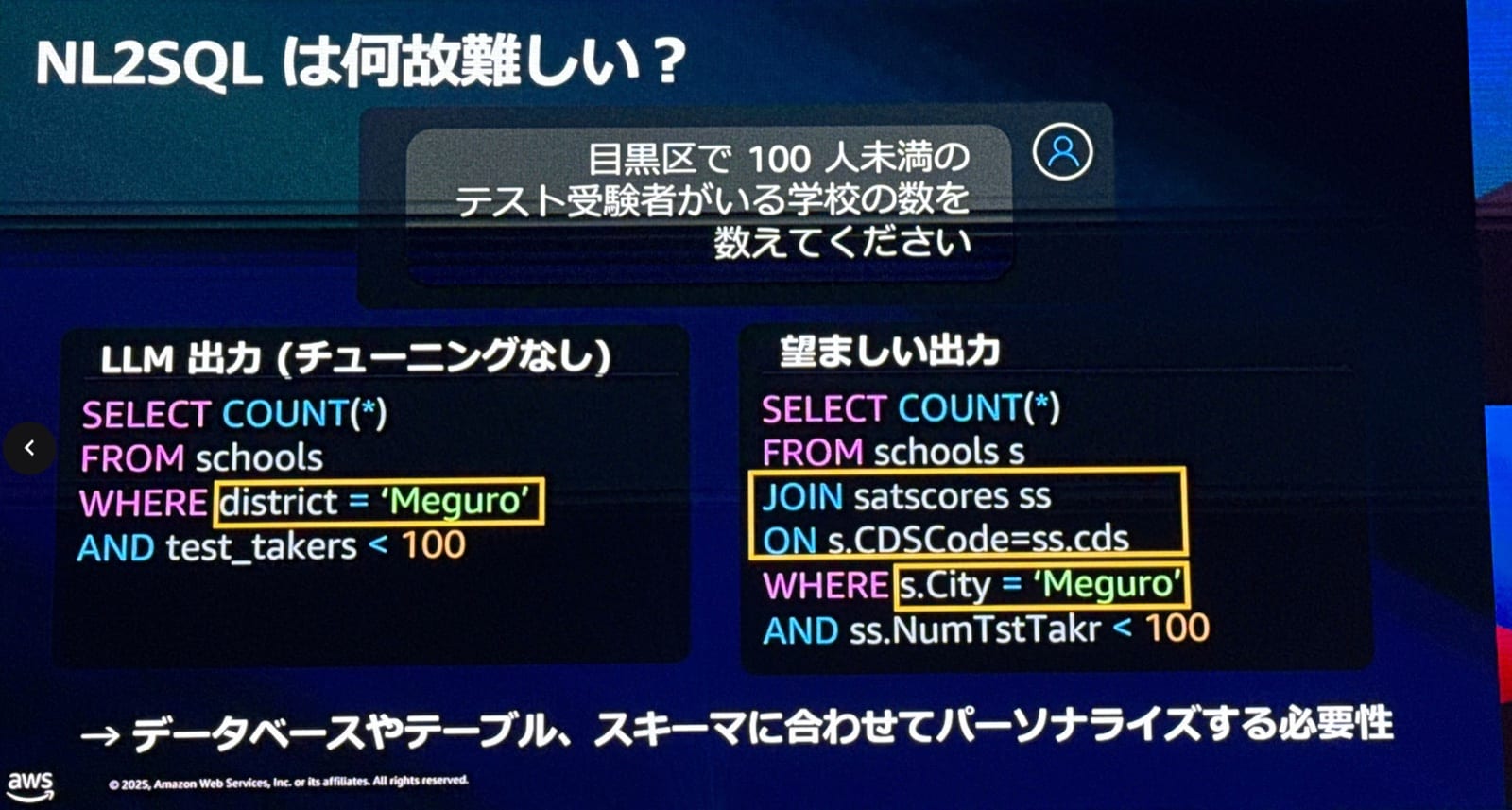
-
-
データの中身の理解が必要
- 例:国名が「Japan」ではなく「JPN」という3文字コードで格納されている
- スキーマ構造だけでなく、実際のデータ形式を理解する必要がある

-
SQLの文法・方言の理解が必要
-
複数テーブルを結合する際は、カラム名の前にテーブル名を明示する必要がある
-
使用するデータベースエンジンの方言に合わせた記述が必要
-
これらの課題に対処するには、自前で実装したり試行錯誤したりする手間やコスト、時間が必要となってきます。
Amazon Bedrock Knowledge Basesの構造化データ取得機能
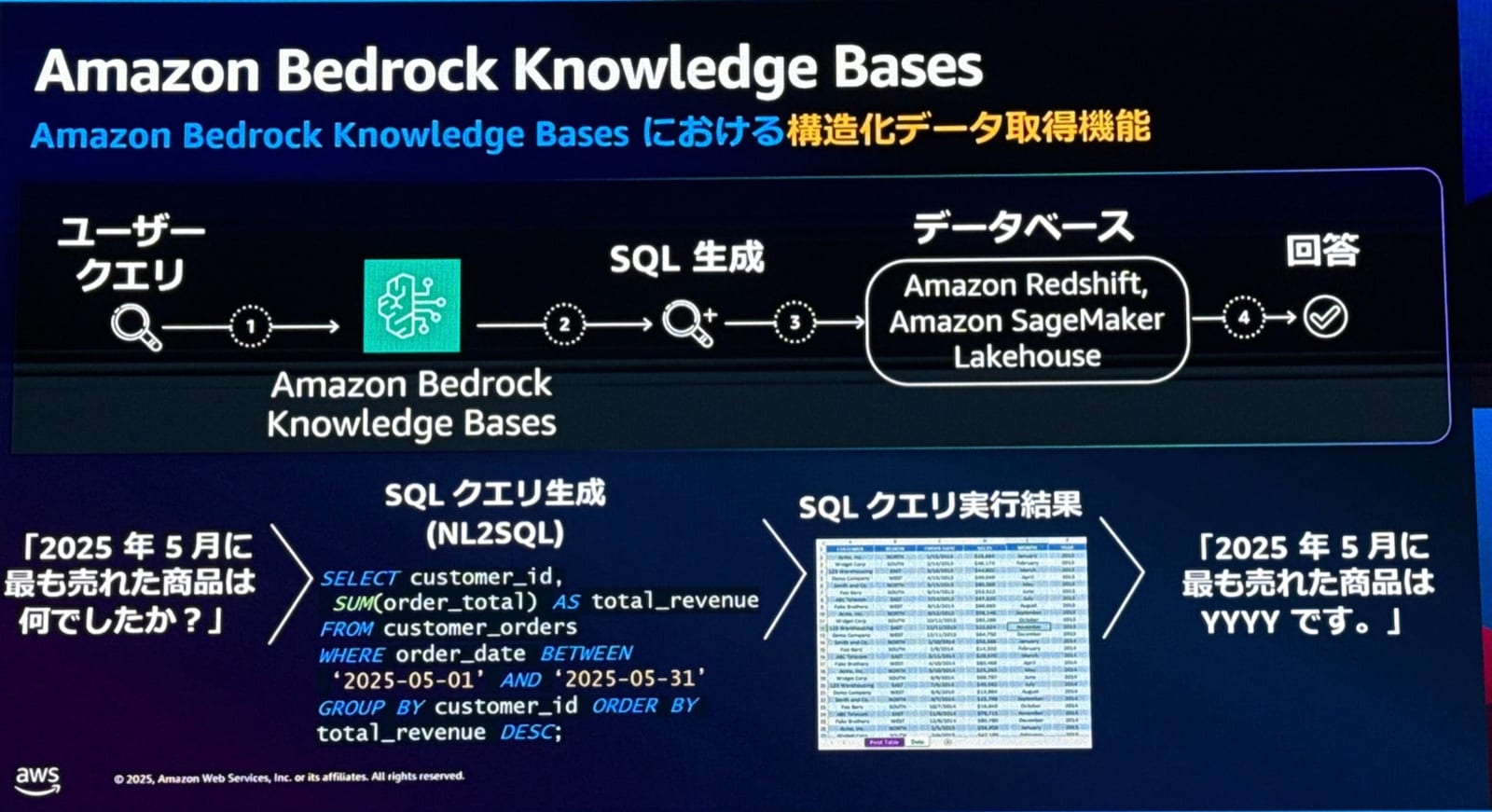
そこで登場したのが、Amazon Bedrock Knowledge Basesの構造化データ取得機能です。Knowledge Basesは元々非構造化データのみを対象としたフルマネージド型のRAGサービスでしたが、構造化データにも対応しています。
この機能の特徴は下記となります。
- 独自のNL2SQLエンジンを搭載
- データベースのメタデータに自動的にアクセスし、スキーマを理解
- 過去のクエリログを分析し、SQLの方言を深く理解
- 自動的にパーソナライズされたSQLクエリを生成
さらに、生成されるSQLに満足できない場合は、設定オプションでカスタマイズも可能です。
- テーブルやカラムに明示的な説明を追加
- よくある質問に対応するSQLクエリを事前登録
- 会話のセッション管理機能も搭載
今までの説明を聞いて大変そうな実装がKnowledge Basesとして実装することで回避できるのは魅力的ですね!
デモ1:構造化データへの自然言語問い合わせ
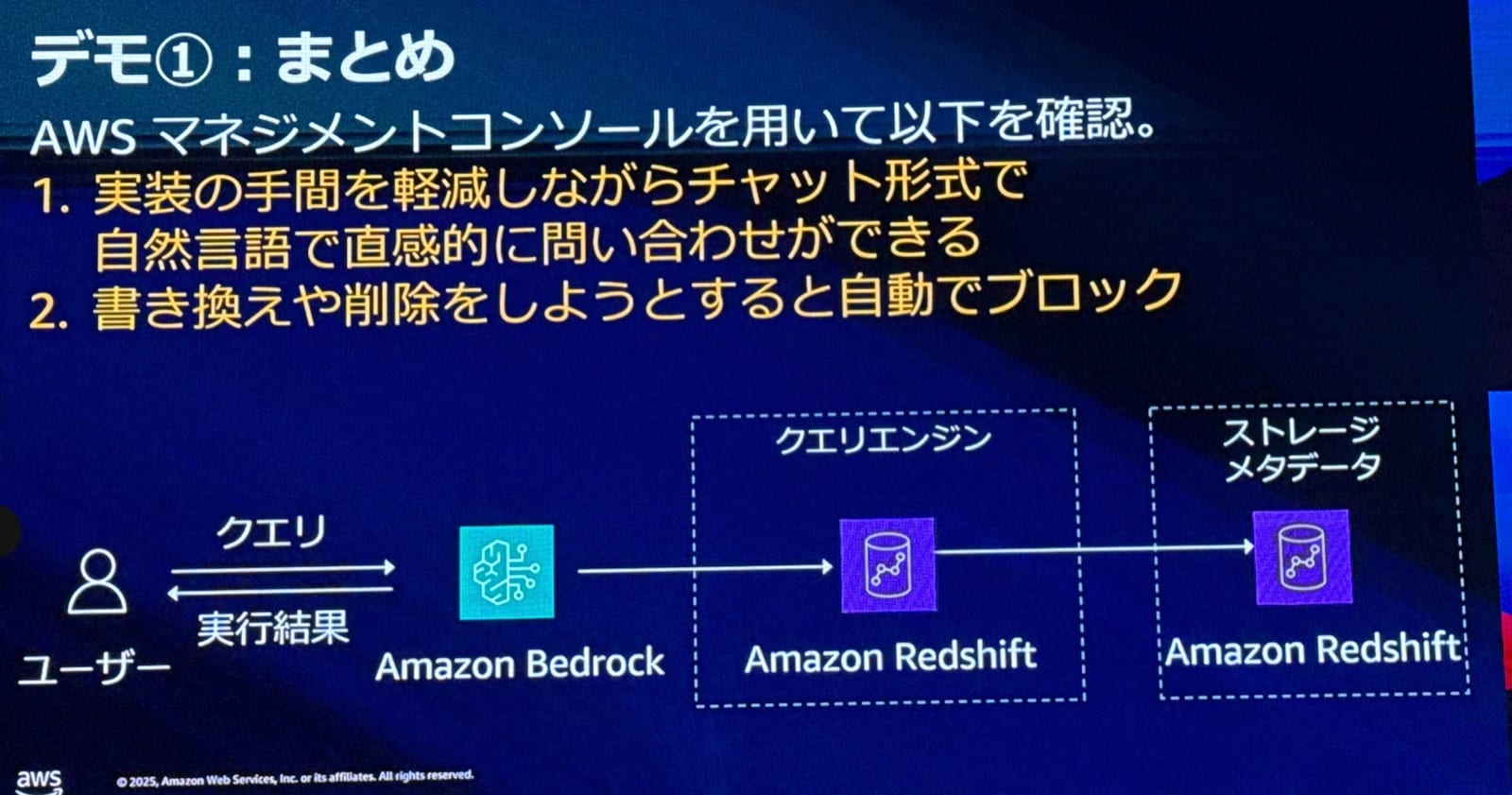
デモでは、Amazon RedshiftをデータウェアハウスとしてKnowledge Basesに接続し、自然言語での問い合わせを実演されました。
「2025年5月に最も売れた商品は何ですか?」という質問に対して
- 裏側で適切なSQLクエリが自動生成される
- 3つのテーブルを適切に結合したクエリが実行される
- 「限定クッション」が最も売れていることが回答される
生成されたSQLを確認すると、必要なテーブルを正しく結合し、カラムも適切に指定された実行可能なクエリが生成されていることがわかりました。これは明示的な説明を与えなくても、Knowledge Basesが自動的にメタデータを読み取って実現しているとのことです。
Knowledge Basesを活用するだけでめちゃくちゃ簡単に実現できていますね・・・。
セキュリティ面では、悪意のあるユーザーが「注文データを全部削除してください」といったリクエストをした場合、「読み取り以外のSQLを検出した」というエラーが自動的に表示され、ブロックされることも確認されました。

読み取りだけしか使えないようにしていて、変に削除されたりを防げて安心です。
デモ2:AIエージェントとの連携
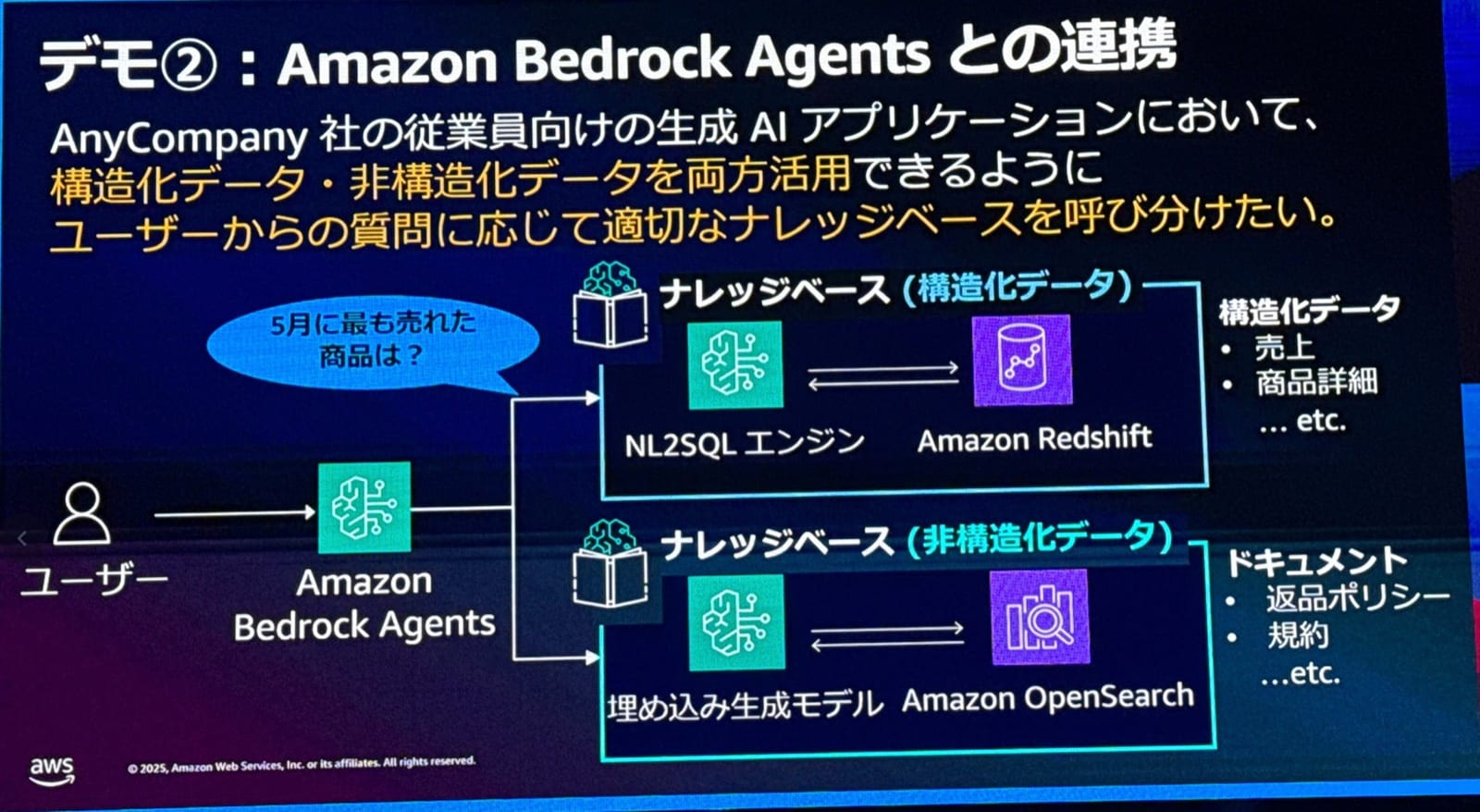
Dカンパニー社は構造化データだけでなく、非構造化データも活用したいと考えました。そこで、Amazon Bedrock Agentsを使用して、2つのKnowledge Basesを連携させるデモが行われました。下記2つのKnowledge Basesを用意します。
- 構造化データ用Knowledge Bases(データウェアハウス)
- 非構造化データ用Knowledge Bases(社内文書)
エージェントは、ユーザーからの質問に応じて適切なKnowledge Basesを自律的に選択します。
- 「2025年5月に最も売れた商品は?」→ 構造化データKnowledge Basesへ
- 「我が社の返品ポリシーは?」→ 非構造化データKnowledge Basesへ
このように、Amazon Bedrock AgentsとKnowledge Basesを連携することで、多様なデータソースを柔軟に活用できることが紹介されていました。

上記のような設定で、簡単に切り替えできるならユースケースに応じてナレッジベースを分岐するような実装してみたいなと思いました。参考になりますね。
まとめ
今回のセッションで特に印象に残ったのは、「データが差別化に繋がる」という冒頭のメッセージです。誰でも基盤モデルを使える時代だからこそ、自社独自のデータをいかに活用するかが競争力の源泉になるということを改めて認識しました。
また、Amazon Bedrock Knowledge Basesの構造化データ取得機能によって、これまで実装負担が大きかったNL2SQLが手軽に実現できるのは良いポイントかと思います。特に以下の点が実務で活用できそうです。
- データベースのメタデータを自動的に理解し、パーソナライズされたSQLを生成
- 会話のコンテキストを理解した自然な対話が可能
- 読み取り以外のクエリを自動的にブロックするセキュリティ機能
- AIエージェントとの連携による柔軟なデータ活用
構造化データと非構造化データの両方を活用したRAGシステムの構築を検討している方にとって、Amazon Bedrockの機能群は非常に有力な選択肢になると感じました。
私はあまりAmazon Bedrock KnowledgeBaseとRDSなどの構造化データを連携させたことがあまりなかったので、手軽に実装できる感じがしたので、自分でも試して効果を見てみたいと思いました!
以上、本レポートが参考になりましたら幸いです!
ご覧いただきありがとうございましたー!!








