![[セッションレポート] オープンテーブルフォーマットで実現する、大規模データ分析基盤の構築と運用 #AWSSummit](https://images.ctfassets.net/ct0aopd36mqt/IpyxwdJt9befE2LRbgxQg/028ee4834e885c77086d6c53a87f1c10/eyecatch_awssummitjapan2025_sessionj_1200x630.jpg?w=3840&fm=webp)
[セッションレポート] オープンテーブルフォーマットで実現する、大規模データ分析基盤の構築と運用 #AWSSummit
こんにちは、まるとです。
先日、2025/6/25 - 26 に開催された、AWS Summit Japan 2025にてセッション「オープンテーブルフォーマットで実現する、大規模データ分析基盤の構築と運用」に参加しました。
世界的に生成 AI などの発展、活用に伴い大量のデータを保有する機会が多いのではないでしょうか。
個人的に大量のデータに対して、どのような形で運用するのが良いのか気になったため参加し、本記事でレポートします。
セッションについて
期間限定ですが、セッションは AWS Summit Japan のサイトよりオンデマンド配信を見ることができます。
概要
機械学習・生成AIの発展に対応するため、AWSの分析サービスとOTFを組み合わせて拡張性・堅牢性の高いデータ基盤を構築する方法を解説。
また、パフォーマンス向上、コスト最適化、運用効率化の実装方法や、ストリーミングデータのスキーマ進化課題への対処法など、データエンジニア向けの実践的なベストプラクティスを紹介するセッションです。
関連サービス・技術
- Amazon SageMaker Lakehouse
- オープンテーブルフォーマット
- Apache Iceberg
アジェンダ
- トランザクショナルデータレイク登場の背景
- トランザクショナルデータレイクのユースケース
- オープンテーブルフォーマット(OTF)の基礎知識
- Apache Iceberg によるトランザクショナルデータレイクの実現
- OTF のデータアクセスコントロール
- Amazon SageMaker Lakehouseで始めるトランザクショナルデータレイク
レポート
トランザクショナルデータレイク登場の背景について
はじめに、トランザクショナルデータレイクの背景から解説が始まりました。
データレイク自体が出現する前は、データ活用にあたりオンプレミスのデータウェアハウスに様々なデータを収集することから始まりました。
これにより企業はデータを一箇所に集約し、分析業務等を行なっていました。
一方で、オンプレミスデータウェアハウスにはいくつか課題も存在します。
- スケーラビリティの問題
- データ増加によるハードウェア拡張、大量のデータ処理のコストと時間の拡大
- 柔軟性の問題
- 構築したデータウェアハウスの中で表現可能なユースケースにしか対応できない
これらの課題を解決するためにデータレイクと呼ばれる概念が出現しました。
データレイク自体は Amazon S3 のようなストレージに様々なデータを集め、将来的にデータ活用できる基盤を構築する考え方です。
データの保存場所と活用の分離により、上記の課題を解決していました。
特にデータを一箇所に保存しながら、用途に応じて最適なツールを利用することで様々なユースケースに対し対応すると考え方とのことです。
AWS におけるデータレイクでは、多くのサービスが S3 と連携できるため、S3 にデータを貯めることでデータ分析、生成 AI などあらゆるニーズに対応しています。
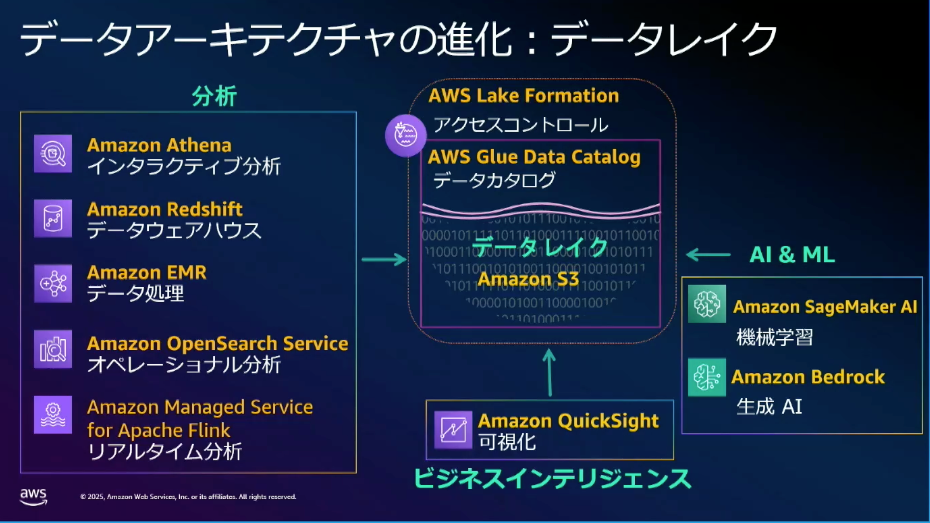
Amazon S3 はシンプルでありながら、可用性など強力な基盤を持っているため、AWS さんの調査で今日では100万を超えるデータレイクが運用されているとのことです。
一方で、データ活用のニーズ、要件が高度になっていきデータレイクでも課題が生じ始めています。
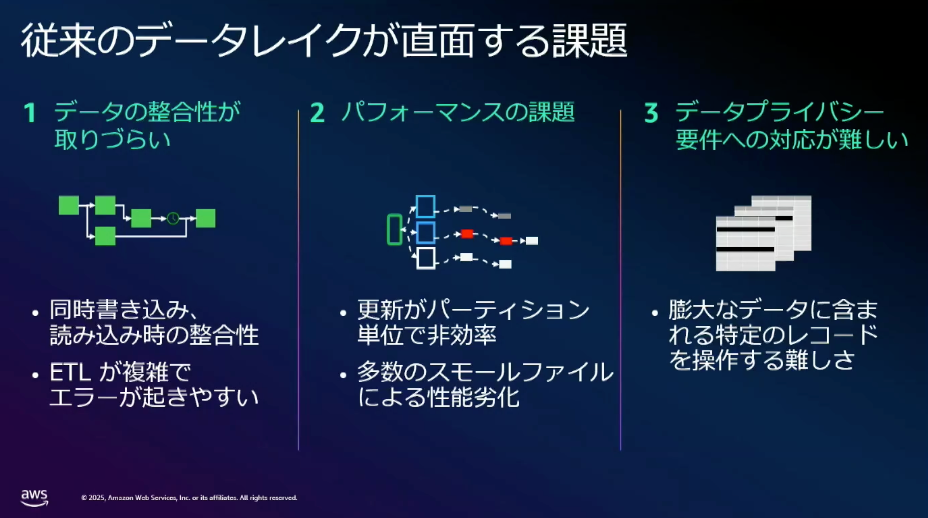
従来のデータレイクではトランザクションの概念がないことから、同時読み書き時の整合性が取れない、整合性を撮るために運用でカバーしようとすると読み出し順序などパイプライン構築・運用が複雑になるなどの問題があります。
また、パフォーマンスの観点でも、日付や月といったパーティション単位の更新となるため、行レベルでデータ更新を行おうとすると処理が非効率となる問題があります。
特定のデータを削除したい、マルチプロセスによる並列処理が基本となるなど、要件が高度化すると課題の根底として RDB では一般的なトランザクションの概念がないことによる課題が頻出してきました。
そこで登場したのがトランザクショナルデータレイクです。
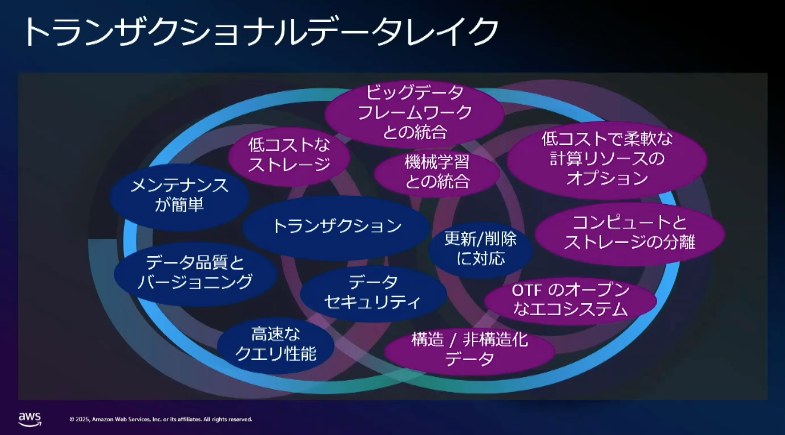
従来のデータレイクのメリットに加え、トランザクションを持つことにより、データの一貫性、同時読み書きのサポート等強力なデータ活用を可能にするとのことです。
それらを実現するために、中核の担うのがオープンテーブルフォーマット(以下、OTF)となり、代表的なものとして、Apache Hudi、Apache Iceberg、Delta Lakeがあります。
トランザクショナルデータレイクのユースケース
セッションでは大きく2つのユースケースが紹介されていました。
ストリームデータの取り込み
主に IoT 機器や Web サービスのストリーミングデータに対するケースの紹介です。
ストリーミングデータでは継続的にレコードの挿入・更新かつ小さなファイルが大量に作成される特徴を持っています。
これらの課題として、テーブルを更新中に他プロセスが読み出しを行うと、更新途中のデータが表示される、小さなファイルが大量にあるため読み取り時のオーバヘッドが大きくなるなど課題を持っています。
そのため、更新途中でも整合性のある読み出し、大量のファイルをまとめる処理(コンパクション)が必要となります。
データプライバシー要件への対応
もう一つのユースケースとして、データプライバシー要件への対応が挙げられていました。
サービスの特性や法律要件より、例えば特定ユーザの一部レコードを削除する場合、従来のデータレイクではパーティション単位の更新となるため、削除のために多くの計算コストが必要となっていました。
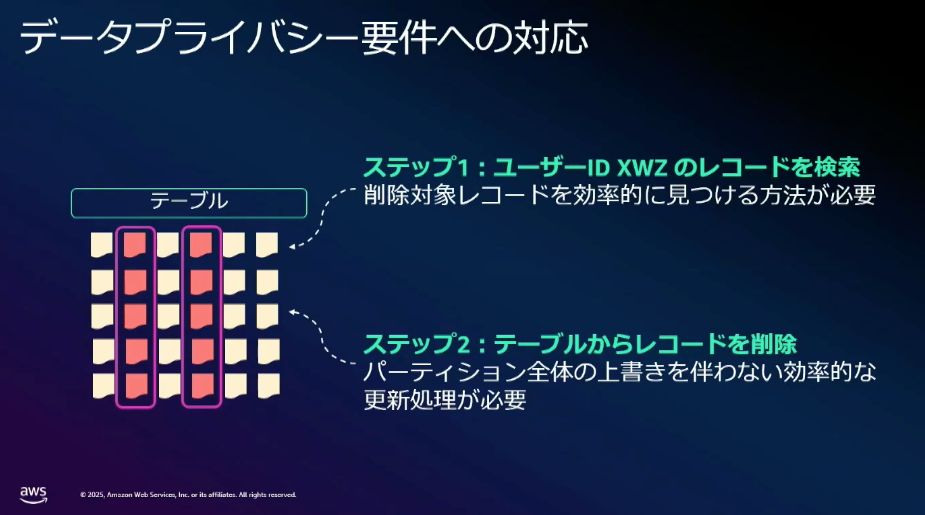
また、ファイルが複数に分割されている場合、TB や PB 級のデータ規模では、削除対象となるレコードが含まれるファイルを探す → パーティション全体を読み書きする必要があるなどと処理時間に大きな課題をもっていました。
これらのユースケースに対して、トランザクショナルデータレイクを使用することで、パーティション全体のスキャンを行わなくても、効率的にデータの操作が行えるとのことです。
実例
実際にトランザクショナルデータレイク活用後の効果についても説明がありました。
大量のアプリケーションログの効率的な取り込みや GDPR 対応のため、特定レコードを効率よく削除できるシステムに対し、本仕組みを利用することで、PR 規模のデータレイクから1,000件のレコード削除を3時間から2分未満に短縮、Amazon S3 によりコストを90%近く削減するなど、非常に大きな効果があるとのことです。
オープンテーブルフォーマット(OTF)入門
続いて OTF の概念に関する説明です。
データレイク以下の図で構成され、テーブルフォーマット自体はカタログとファイルフォーマットに間に位置します。

役割としてはストレージ上にある複数あるファイル群を、論理的に一つのテーブルであることを認識して構成します。
この仕組み自体は従来でも Hive テーブルフォーマットとして存在していましたが、より高度な課題の解決のために、Apache Hudi、Apache Iceberg、Delta Lakeが登場しました。
これらの共通点として、メタデータによってストレージ上にあるファイル群をテーブルとして管理しているとのことです。
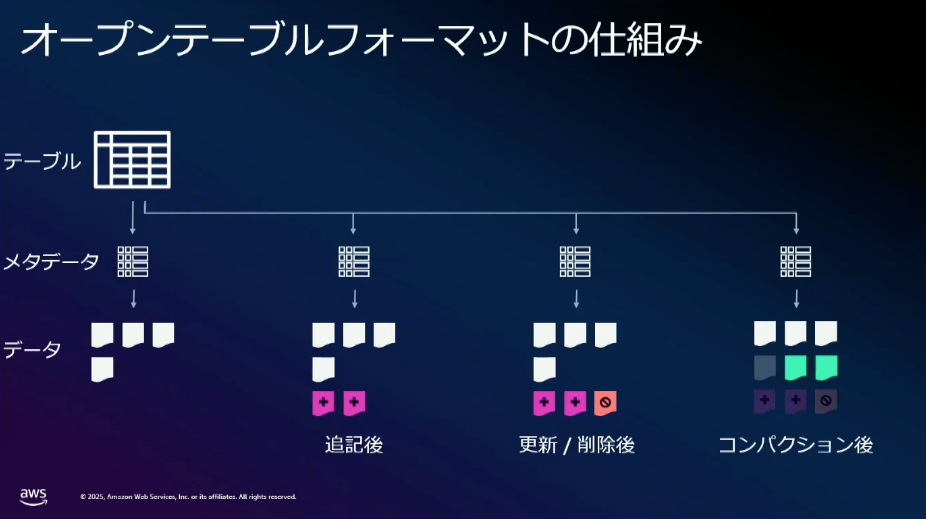
メタデータによる管理の特徴として、データが更新されると都度メタデータが作成されます。
また、ファイルを削除した場合、メタデータ上では論理的に削除されていますが、実際にはストレージ上に残ります。
これはタイムトラベルと呼ばれる機能があり、データベースでいう PITR のような仕組みがあります。
タイムトラベルを利用することで、現在と過去の2つの時点での比較分析を可能にしているとのことです。
ファイルを物理削除しないため、通常であれば保存コストが徐々に増えていくところですが、クリーンアップと呼ばれる機能により不要なファイルやメタデータを削除してストレージを最適化する仕組みもあります。
ここまではフォーマットの仕組みよりでしたが、AWS では AWS Glue Data Catalog にパフォーマンスやコストをマネージドに最適化する仕組みを整えています。
特にパートナー企業やユーザーからのフィードバック、OSS コミュニティなどの観点から Iceberg に注力しているとのことでした。
Apache Iceberg によるトランザクショナルデータレイクの実現
トランザクショナルデータレイクの実現にあたり、必要な構成に関する説明です。
主に効率的なデータの参照と更新、ファイル操作戦略、読み出しの特徴に関する説明がありました。
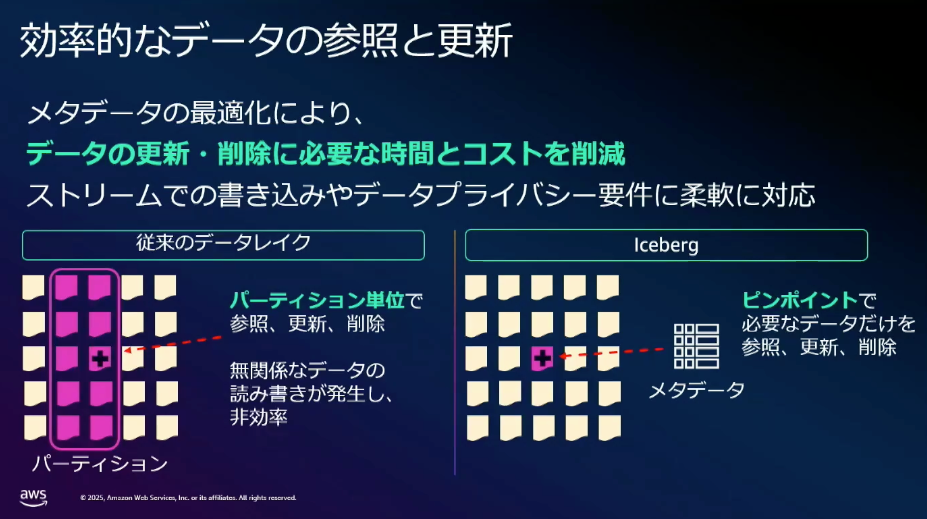
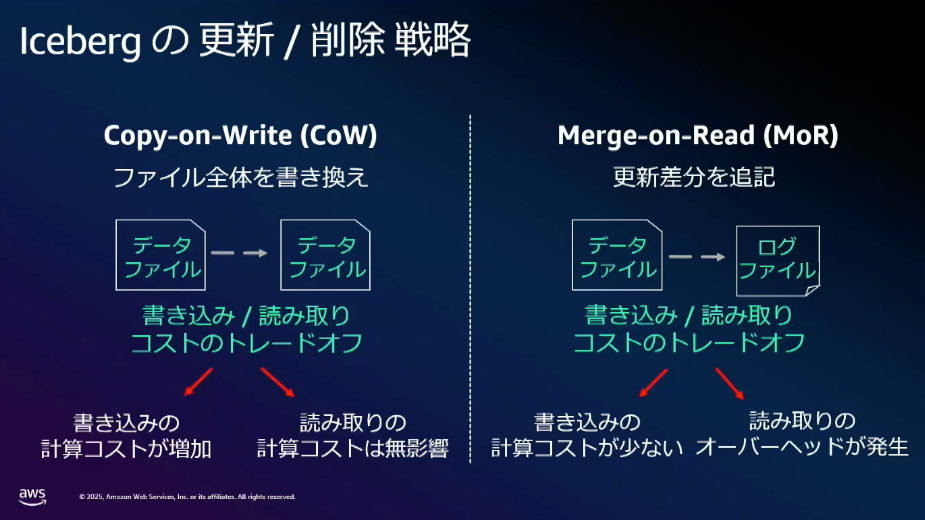

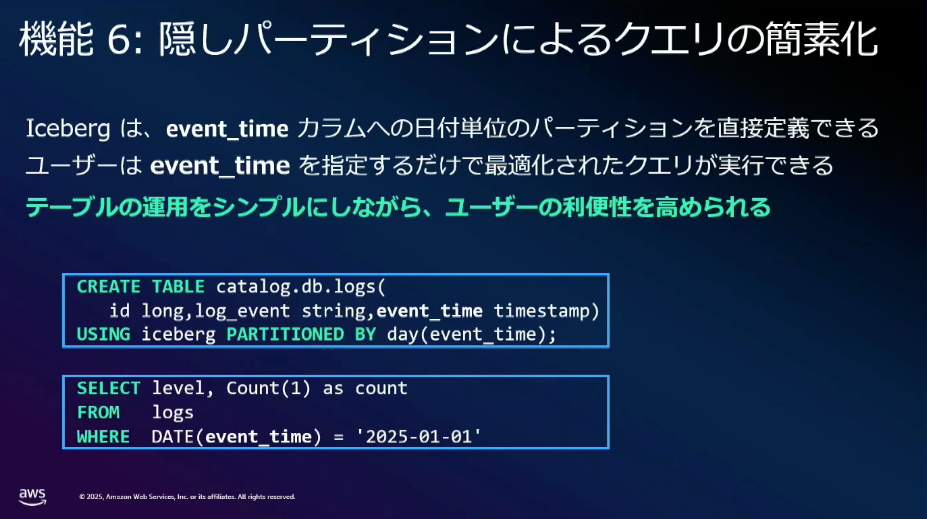
上記の資料以外にも
- SQLによるテーブル操作
- メタデータの最適化により効率的に更新が可能
- データファイルの書き換えなしでスキーマやパーティション構造の変更
- スナップショットにタグを付与し、目的のデータへの素早いアクセス
- ビジネス上必要なスナップショットのみを残す
- ファイルのコンパクション
- 単にファイルをまとめるだけでなく、コンパクション処理中でも一貫性と生合成を確保しながら実行可能
などが挙げられていました。
特に従来では初期段階でクエリパターンの予測などしてテーブルやパーティション設計を行う必要がありましたが、データファイルの書き換えなしでスキーマやパーティション構造の変更を行えるようになっているため、構築・運用負荷もかなり軽減されています。
OTF のデータアクセスコントロール
ビジネス上必要となる要素の一つとしてアクセス制御が出されていました。
これはデータ量の増加やデータ活用者の増加、ビジネスの加速などにより個人情報など機密データへのアクセス制御をはじめとして必要な要素の一つです。
OTF 自体はテーブルに対するアクセス制御を持たず、本来であれば別の仕組みで実装が必要となりますが、AWS では AWS Lake Formation を利用することでテーブル単位や行、列、セル単位でアクセス制御が可能となるため、一元で管理できるのが特徴です。
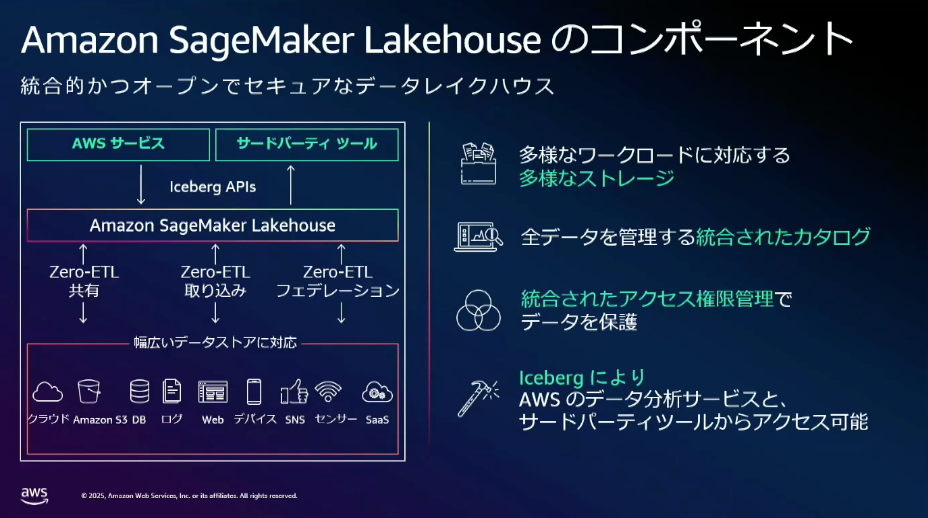
Amazon SageMaker Lakehouseで始めるトランザクショナルデータレイク
最後にトランザクショナルデータベースにアイデア基づき設計された、Amazon SageMaker Lakehouse に関する説明がありました。
様々なデータソースに対してデータ活用に求められるデータの収集/管理/活用までをワンストップでできることを特徴に挙げられていました。
- データを基盤に集めるにあたり、Zero ETL によってスクリプトの作り込み不要でデータ収集可能
- S3、S3 Tables、Redshift どこに置いてあったとしても一元的に管理可能
- Lake Formationの仕組みによりアクセス管理も含めて管理可能
- APIによりAWS ネイティブの分析サービス、Icebergに対応するサードパーティのサービスも利用可能
などデータ基盤の構築・運用にあたり、AWS 上でマネージドである程度行えるため、これから導入する企業向けでも非常に良いのではないかと感じました。
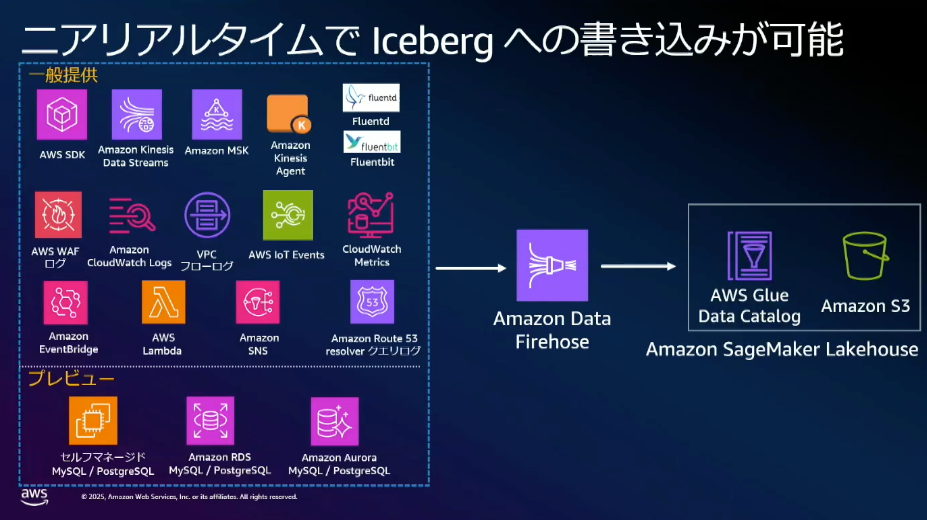
また、Amazon Data Firehose を利用することにより様々なAWS サービスから Iceberg への書き込みをニアリアルタイムで書き込み可能であるため、より迅速にデータの収集・活用が行える点も非常にポイントが高いです。
まとめと感想
まとめです。
本セッションでは。データ収集・活用の背景から課題に対する解決策まで幅広く取り上げられていました。
特に AWS を利用することでマネージドかつ収集・保存・活用・アクセス制御などがワンストップで行うことができ、管理を集中できるのは運用面でもかなり負荷を軽減できるのではないでしょうか。
ぜひ大規模データ分析基盤に関してクラウドに移行したい、というユースケースがあればぜひこちらを検討してみてください。
以上、まるとでした。









