
คู่มือสำหรับ Practitioner: เตรียม Data ให้พร้อมสำหรับ Agentic AI บน AWS
บทนำ (Introduction)
ในเซสชัน "A practitioner's guide to data for agentic AI" (ANT301 — Level 300) จากงาน AWS Summit Bangkok โดยคุณ Nutchanon Leelapornudom (Senior Solutions Architect) และคุณ Tanisorn Jansamret (Solutions Architect) จาก AWS ได้พาผู้ฟังไปเจาะลึกคำถามที่หลายองค์กรกำลังเผชิญ นั่นคือ ถ้าเราอยากนำ Agentic AI เข้ามาทำงานร่วมกับข้อมูล (Data) ที่มีอยู่ในองค์กร หน้าตาของระบบจะเปลี่ยนไปอย่างไร และเราต้องเตรียมตัวอะไรบ้าง
ประเด็นสำคัญที่ผู้พูดเน้นย้ำคือ ทุกวันนี้ "Data" ไม่ได้จำกัดอยู่แค่เรื่อง Data Platform อีกต่อไป แต่ข้อมูลทุกอย่างในองค์กรควรเป็นสิ่งที่ทั้ง "คน" และ "AI" สามารถเข้าถึงได้เพื่อช่วยให้ทำงานได้มีประสิทธิภาพมากขึ้น เซสชันนี้จึงแบ่งเนื้อหาออกเป็นสองส่วนหลัก คือ (1) พื้นฐานว่า Agentic AI คืออะไรและทำงานอย่างไร และ (2) เมื่อจะนำ Agentic AI ไปเชื่อมกับข้อมูลจริงในองค์กร สถาปัตยกรรมควรมีหน้าตาแบบไหน
เนื้อหาหลัก (Main Content)
Agentic AI คืออะไร: Reason, Act และ Memory
Agentic AI เปรียบเสมือนระบบ (System) ที่อาจประกอบด้วย Agent ตัวเดียวหรือหลายตัวก็ได้ โดยมีเป้าหมายคือช่วยมนุษย์ทำงานให้บรรลุผล โดยที่เราไม่จำเป็นต้องบอกทุกขั้นตอนล่วงหน้าว่าต้องเดินจาก A ไป B ไป C ตัว Agent ควร "คิดเอง" และหาทางไปสู่เป้าหมายที่เรากำหนดได้ คุณสมบัติสำคัญของ AI Agent มีอย่างน้อย 3 ข้อ ได้แก่
- Reasoning (การคิดวิเคราะห์): เมื่อได้รับคำขอจากผู้ใช้ โมเดลต้องวิเคราะห์ก่อนว่างานคืออะไร เป้าหมายของผู้ใช้คืออะไร และต้องวางแผนอย่างไรเพื่อทำงานต่อไป
- Acting (การลงมือทำ): Agent ลงมือทำแทนผู้ใช้ ไม่ว่าจะเป็นการเข้าถึงข้อมูลในองค์กรผ่าน Tools, การเรียกใช้แอปพลิเคชัน หรือการเรียกใช้ Agent อื่นเพื่อบรรลุวัตถุประสงค์
- Memory (ความทรงจำ): เราไม่อยากให้ Agent ลืมสิ่งที่เคยคุยกันทุกครั้ง Agent ที่ดีควรจดจำบทสนทนาและความต้องการของผู้ใช้ และเรียนรู้จากสิ่งเหล่านั้นเพื่อต่อยอดไปสู่เป้าหมายได้
📎 Amazon Bedrock AgentCore — Overview
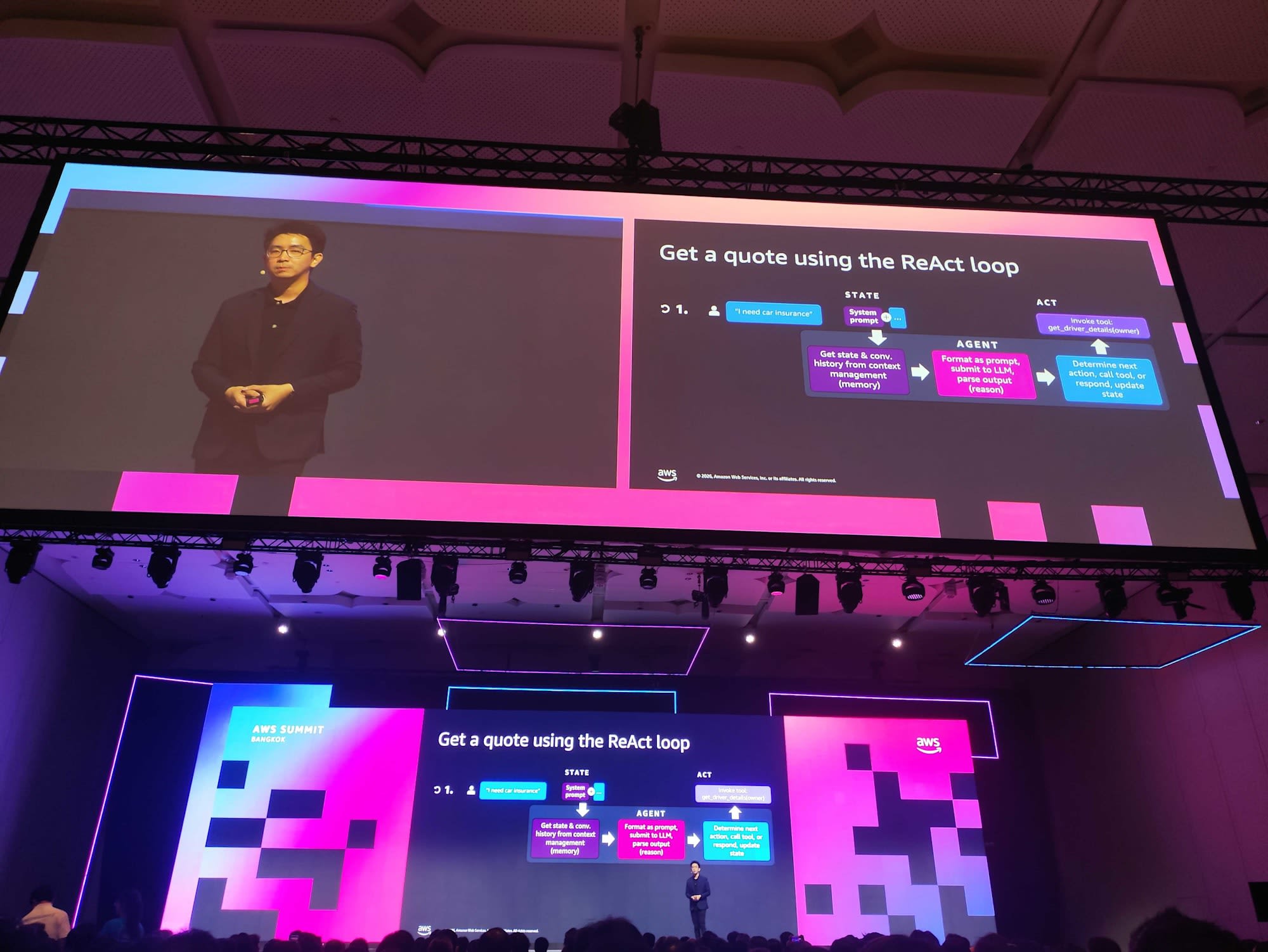
ตัวอย่างจริง: ออกใบเสนอราคาประกันรถยนต์ด้วย ReAct Loop
ผู้พูดยกตัวอย่าง use case การทำประกันรถยนต์ของบริษัทสมมติ AnyCompany Insurance สมมติว่าลูกค้าชื่อ "Terry" บอกว่าต้องการทำประกันรถยนต์ ถ้าเราจำลองตัวเองเป็น Agent เราจะต้องทำอะไรบ้าง? คำตอบคือเราต้องทำงานเป็นรอบ ๆ ผ่านสิ่งที่เรียกว่า ReAct loop (Reason + Act) โดยในแต่ละรอบ Agent จะดึง State และประวัติการสนทนาจาก Memory มา จากนั้น Format เป็น prompt ส่งให้ LLM เพื่อ Reason แล้วตัดสินใจว่าจะ Act อย่างไรต่อ
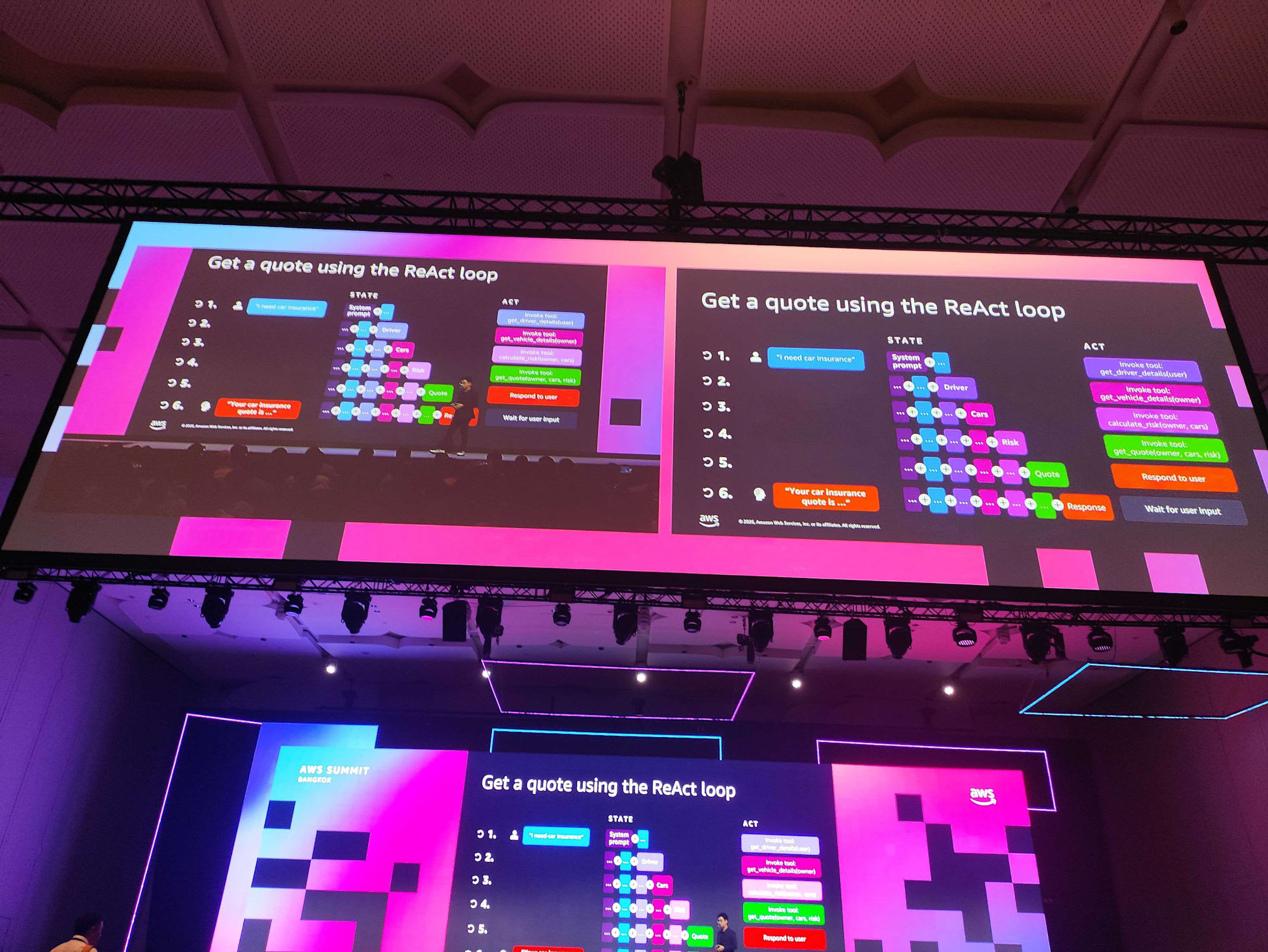
ลำดับการทำงานที่เกิดขึ้นจริงเป็นดังนี้
- รู้จัก Terry หรือยัง? เรียก Tool
get_driver_details(user)เพื่อดึงข้อมูลผู้ขับขี่ - มีข้อมูลรถหรือยัง? เรียก Tool
get_vehicle_details(owner)เพื่อดึงข้อมูลรถยนต์ - ประเมินความเสี่ยง (underwriting) ผ่าน
calculate_risk(owner, cars) - สร้างใบเสนอราคาผ่าน
get_quote(owner, cars, risk)แทนที่จะให้ AI เดาราคาเอง - Respond to user — ตอบกลับใบเสนอราคาให้ลูกค้า

จุดสำคัญคือ Agentic AI ไม่ได้จบแค่ทำงานครั้งเดียว เมื่อ Terry ขอแก้ไขเงื่อนไข เช่น "Change the deductible to $1,000" ระบบต้องอาศัย Memory ของบทสนทนาก่อนหน้าเพื่อทำงานต่อ และเมื่อ context window เริ่มเต็ม ระบบที่ดีควรทำสิ่งที่เรียกว่า Compaction หรือการบีบอัดบทสนทนาให้กระชับ เพื่อให้การทำงานมีประสิทธิภาพและยังเก็บเข้า Memory ได้ต่อ
องค์ประกอบของ Memory: Short-term และ Long-term

ผู้พูดอธิบายว่า Memory ของ Agent แบ่งเป็นสองฝั่ง
- Short-term memory (ความทรงจำระยะสั้น): ใช้กับ task หรือ session ปัจจุบัน เช่น Agent state (action plan, scratchpad ที่แชร์ระหว่าง loop) และ Messages (ประวัติบทสนทนา) ส่วนนี้มักขึ้นกับ Agentic framework และเก็บใน backend data store เช่น Amazon DynamoDB
- Long-term memory (ความทรงจำระยะยาว): ใช้กับผู้ใช้หรือทั้งแอป เพื่อให้ Agent มอบประสบการณ์ที่ต่อเนื่อง ผู้ใช้ไม่ต้องให้ข้อมูลซ้ำ ประกอบด้วย Semantic (บริบทที่เกี่ยวข้องกับงาน), Profiles (ข้อมูลโปรไฟล์ผู้ใช้), Episodic (ประวัติการโต้ตอบและผลลัพธ์) และ Prompts (system prompt, instructions) โดยมักถูก retrieve ผ่าน Tools จาก vector data store เช่น Amazon OpenSearch Service และเน้นเรื่อง Data accessibility และ Data quality
📎 Amazon Bedrock AgentCore Memory — short-term & long-term memory · 📎 Amazon OpenSearch Service
Tools และ Model Context Protocol (MCP)

นอกจาก Memory แล้ว อีกหัวใจของ Agent คือ Tools เพราะเมื่อ Agent ต้องเข้าถึงข้อมูล ไม่ว่าจะเป็น Relational/NoSQL database หรือระบบอย่าง CRM เราต้องมีมาตรฐานกลางในการเชื่อมต่อ ผู้พูดเปรียบเทียบให้เห็นภาพง่าย ๆ ว่า ถ้า Agent คือแล็ปท็อป Tools รอบตัว (เมาส์ คีย์บอร์ด จอ) ก็ต้องมีมาตรฐานกลางอย่าง USB-C ในการเชื่อมต่อ — และมาตรฐานกลางสำหรับ Agent ก็คือ Model Context Protocol (MCP)
MCP เปรียบเสมือนสะพานเชื่อมที่ทำให้ Agent เข้าถึงข้อมูลหลากหลาย เรียกใช้ Agent อื่น หรือเรียกแอปพลิเคชันได้อย่างเป็นมาตรฐาน ในตัวอย่าง MCP Server มี DB Driver และเปิด tools อย่าง get_owner_vehicles(ssn), get_vehicle_by_vin(vin) และ get_vehicle_telemetry(vin) ให้ Agent เรียกใช้
📎 What is MCP? — AWS Prescriptive Guidance · 📎 Unlocking the power of Model Context Protocol (MCP) on AWS
เลือก Tool ให้เหมาะกับงาน

แม้เราจะไม่ใช่ผู้พัฒนา Agentic AI โดยตรง แต่ในฐานะ Data Provider หรือ Data Consumer สิ่งที่ต้องสนใจคือ "Tools" ที่เปิดให้ Agent เข้าถึงข้อมูล ผู้พูดจัดหมวด Tools ออกเป็น 4 ประเภทตามสองแกน คือ Data Retrieval vs Data Mutation และ General Purpose vs Specialized
- General Purpose + Data Retrieval: เหมาะกับ Data analyst/Data engineer ที่ดึงข้อมูลทั่วไป เช่น ส่ง SQL query มาทำ report หรือ dashboard
- General Purpose + Data Mutation: เหมาะกับ Developer/DevOps เมื่อ Agent ต้องเปลี่ยนแปลงข้อมูลหรือทำ transaction (ต้องเริ่มจำกัดสิทธิ์ให้ชัดเจน)
- Specialized: เหมาะกับ End user/Consumer ที่ต้องการ Tool เฉพาะทาง โดยต้องไม่ลืมเรื่องความปลอดภัยและ Access control ที่เหมาะกับแต่ละ Agent
มุมมอง Data Consumer: Nikki (Investigator)
ผู้พูดยกตัวอย่างผู้ใช้ภายในชื่อ Nikki ที่เป็น Investigator มีหน้าที่ตรวจสอบเคลม เดิมต้องเขียน query เองเพื่อดึงข้อมูลมาทำ report แต่ในโลก Agentic AI เธอเพียงพิมพ์ว่า "Show me high value collision claims in Nevada" แล้ว Agent จะทำงานเป็นลำดับ task คือ
- Find data products — เรียก Tool ไปที่ Amazon SageMaker (business catalog) และ AWS Glue (technical catalog) เพื่อดูว่ามี data product อะไรอยู่บ้าง แล้วเก็บเป็น Context/Memory
- Retrieve data — เรียก Tool ไปที่ Amazon Athena (query engine) เพื่อ query ข้อมูลที่อยู่บน Amazon S3
- Create report — สร้าง report จาก Context ที่ได้
จุดที่ย้ำคือ ในทุก Tool call จะมี Role "INVESTIGATOR" แปะอยู่เสมอ หมายความว่าข้อมูลที่ Nikki เข้าถึงได้จะถูกจำกัดด้วย Role โดยมี AWS Lake Formation เป็นตัวควบคุมสิทธิ์ ทั้ง row filter (state = NV), column filter (injuries) และ audit ทุก query ย้อนหลัง 7 ปี สิ่งที่ Data Consumer ต้องโฟกัสจึงได้แก่ คุณภาพและที่มาของข้อมูล (lineage), การ search ข้อมูลผ่าน catalog, การจำกัดสิทธิ์การเข้าถึง และการลบข้อมูลที่ละเอียดอ่อนออก
📎 AWS Lake Formation — Data filtering & cell-level security · 📎 Amazon Athena
มุมมอง Data Producer: Jane (Data Engineer)

อีกมุมหนึ่งคือ Jane ที่เป็น Data Engineer เดิมการสร้าง data pipeline อาจใช้เวลาเป็นวัน แต่ด้วย Agentic AI เธอเพียงบอกว่า "Create IaC deployment code for a data set of speeding incidents from telematics..." แล้ว Agent จะทำงานเป็น task คือ
- Configure streaming ingest (topic) — รับข้อมูลพฤติกรรมการขับขี่จาก Vehicle telematics ผ่าน Amazon MSK (data streaming)
- Set up topic consumer pipeline — ใช้ AWS Glue (Spark jobs) ประมวลผล พร้อมคุม Data Quality ด้วย AWS Glue Data Quality (DQDL) แล้วเก็บลง Amazon S3
- Publish data product to marketplace — เผยแพร่ผ่าน Amazon SageMaker (business catalog) โดยมี AWS Lake Formation (governance) คุมสิทธิ์
โดยทุก Tool call ก็จะมี Role "DATA ENGINEER" แปะอยู่เช่นกัน สิ่งที่ Data Producer ต้องโฟกัสคือ ความเร็วของข้อมูล, การคุมคุณภาพข้อมูล (ยังต้องมีคน validate ขั้นสุดท้าย), การใส่ metadata ใน business catalog ให้ AI เข้าใจบริบท และการ audit การเข้าถึงข้อมูล
📎 Amazon Managed Streaming for Apache Kafka (Amazon MSK) · 📎 AWS Glue Data Quality
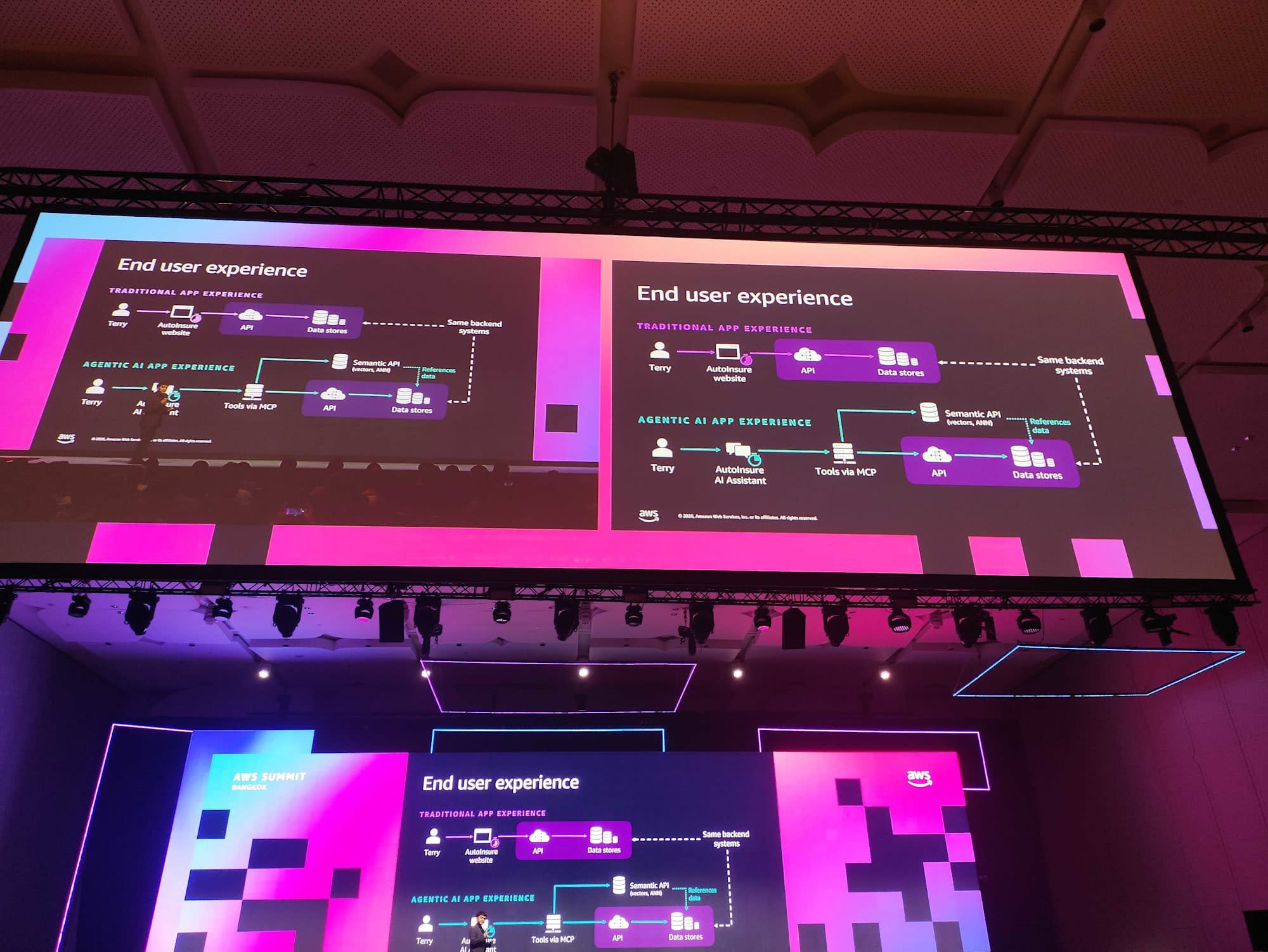
มุมมอง End User: จาก Traditional App สู่ Agentic AI App

สำหรับ End User อย่าง Terry เดิมต้องเข้าเว็บไซต์ AutoInsure แล้วกรอกข้อมูลและทำตามขั้นตอนเองทั้งหมด แต่ในรูปแบบ Agentic AI เขาเพียงพิมพ์ความต้องการเป็นภาษาธรรมชาติให้ AI Assistant ซึ่งทำหน้าที่เป็นผู้ช่วยส่วนตัวจัดการระบบหลังบ้านให้
ข่าวดีคือ เราใช้ระบบเดิมได้ทันที ทั้ง backend และ data stores ยังเป็นชุดเดียวกัน เพียงเพิ่มเข้ามาคือ Tools via MCP และ Semantic API (vectors, ANN) เพื่อให้ Agent เข้าใจ content ของข้อมูล โดยอ้างอิงกลับไปยัง data stores เดิม
ภาพรวมสถาปัตยกรรมด้วย Amazon Bedrock AgentCore

เมื่อรวมทุกอย่างเข้าด้วยกัน ทั้ง Internal และ External user จะเข้ามาผ่าน Amazon Bedrock AgentCore ซึ่งดูแล Memory, Runtime, Gateway และ Identity ช่วยเรื่อง scale ทั้งวันนี้และอนาคต ส่วน Agent logic เขียนด้วย framework อย่าง Strands Agents หรือ LangGraph ได้
- ใช้ Amazon Bedrock เป็น LLM เลือก/สลับโมเดลได้อิสระแม้มีโมเดลใหม่ออกมา
- ใช้ Amazon Bedrock Knowledge Bases ทำ RAG ดึงความรู้มาเสริม
- ใช้ MCP Servers เชื่อมไปยังข้อมูลหลังบ้าน ทั้ง Database engines (Aurora PostgreSQL, DynamoDB, ElastiCache) และ Analytics engines (Redshift, Athena) รวมถึง External service APIs
ฝั่งซ้ายคือภาพของ AI Agent ส่วนฝั่งขวาคือภาพของ Data ที่ Agent จะเข้าไปเชื่อมต่อ ทำให้ AI Agent ทำงานร่วมกับ data estate เดิมขององค์กรได้อย่างแข็งแกร่งและปลอดภัย
📎 Amazon Bedrock AgentCore · 📎 Amazon Bedrock Knowledge Bases
สรุป (Conclusion)
สำหรับองค์กรที่อยากเริ่มนำ Agentic AI มาใช้ ผู้พูดฝากแนวทางง่าย ๆ ไว้ดังนี้
- จัดระเบียบข้อมูลที่มีอยู่ ให้ใช้งานในรูปแบบ API ก่อน
- นำ MCP มาเชื่อมกับ API เพื่อให้ Agent ติดต่อระบบหลังบ้านได้ผ่านมาตรฐานกลาง
- วาง Governance ตั้งแต่วันแรก เรื่องสิทธิ์การเข้าถึงและการ audit ไม่ควรเป็นเรื่องที่ทำทีหลัง
- มองหา Managed service ที่ช่วยจัดการ infrastructure ที่ซ้ำซ้อน เพื่อให้ทีมเอาเวลาไปโฟกัสที่ use case จริง
ประเด็นที่ทิ้งท้ายคือ ไม่ว่าคุณจะเป็น Data Consumer, Data Producer หรือ End User การเตรียม "ข้อมูล" ให้พร้อม ทั้งในแง่การเข้าถึง คุณภาพ และการกำกับดูแล คือรากฐานสำคัญที่จะทำให้ Agentic AI ทำงานได้อย่างถูกต้อง แม่นยำ และปลอดภัยในระดับองค์กร
อ้างอิง (References)
- Amazon Bedrock AgentCore — Overview
- Amazon Bedrock AgentCore (Product page)
- Host agent or tools with Amazon Bedrock AgentCore Runtime
- What is MCP? — AWS Prescriptive Guidance
- Unlocking the power of Model Context Protocol (MCP) on AWS
- Amazon Bedrock Knowledge Bases
- Retrieve data and generate AI responses with Amazon Bedrock Knowledge Bases
- AWS Lake Formation — Data filtering and cell-level security
- Methods for fine-grained access control — AWS Lake Formation
- Amazon Athena
- Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- AWS Glue Data Quality
- Amazon OpenSearch Service













