
【セッションレポート】 生成 AI アプリケーションを最適化するインメモリセマンティックキャッシュ (AWS-45) #AWSSummit
2025 年 6 月 26 日 (木) 13:50 - 14:30
登壇者:堤 勇人 氏
シニアNoSQLスペシャリストソリューションアーキテクト
アマゾン ウェブ サービス ジャパン合同会社
はじめに
生成AIの急速な普及に伴い、基盤モデル(LLM)の推論処理にかかるコストとレイテンシーの最適化が喫緊の課題となっています。本セッションでは、Amazon MemoryDB を用いた「耐久性セマンティックキャッシュ」のアプローチによって、コスト削減・応答速度向上・スケーラビリティ確保をどのように実現するかが紹介されました。

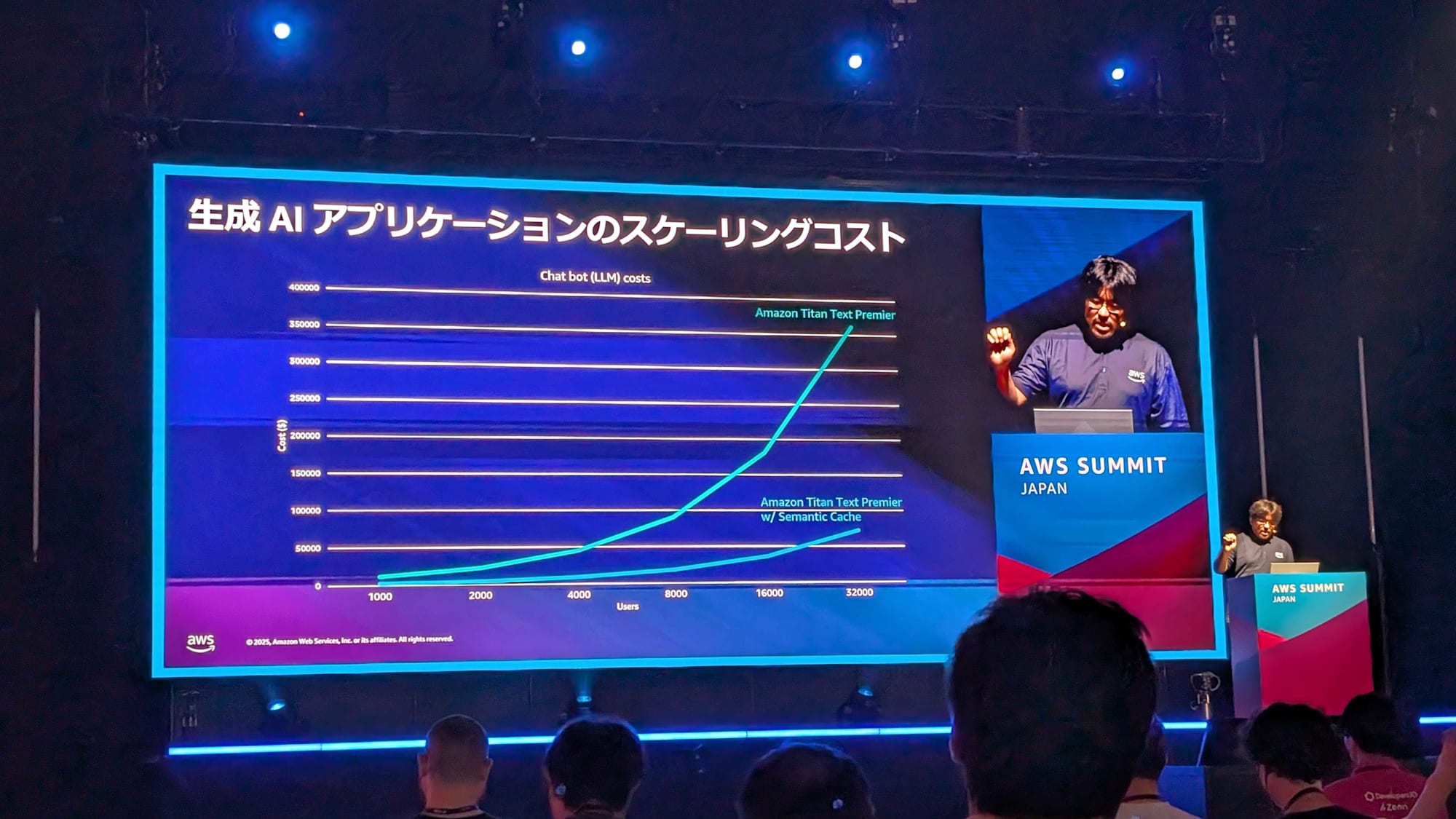
生成 AI におけるスケーリングの課題
- 基盤モデル(FM)は高コストかつ数秒の応答時間が発生
- ユーザー数が増えるほど推論コストがリニアに増加
- 自然言語ベースのクエリでは意味的に同じような質問に対しても毎回キャッシュミスが発生
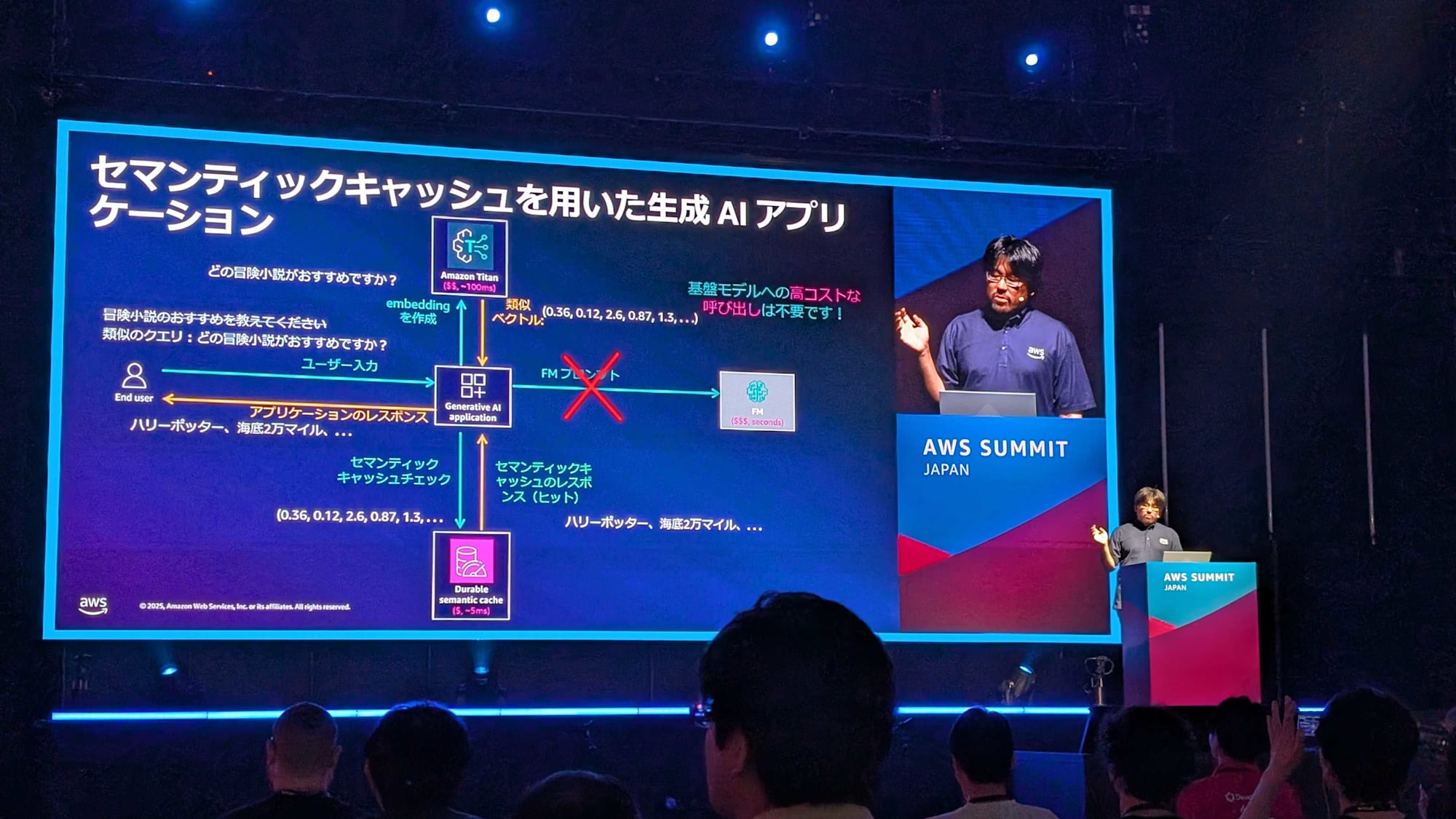
セマンティックキャッシュとは?
従来のキャッシュでは、完全一致のキーに対してしかヒットせず、意味的に近くてもキャッシュミスが起こる問題があります。これを解決するアプローチとしてセマンティックキャッシュがあります。セマンティックキャッシュには次のような特徴があります。
- クエリをベクトルに変換(Amazon Titan などで embedding)
- クエリベクトルとキャッシュ内ベクトルの「距離」を計算
- 意味的に近いものを再利用し、キャッシュヒットにする
これにより、同義的な表現(例:「おすすめの冒険小説を教えて」と「どの冒険小説がおすすめ?」)でもキャッシュが活用可能となります。
構成要素の要件
セマンティックキャッシュを実現するには、以下の3点が必要です。
| 要件 | 説明 |
|---|---|
| 耐久性 | キャッシュ損失がシステムに与える影響を抑える |
| セマンティック性 | 高度なベクトル類似度検索(VSS)と距離計算方法のカスタマイズ |
| キャッシュ性 | ミリ秒単位の高速アクセス、スループット単価の低さ |
技術詳細
Amazon MemoryDB を使用する例が紹介されました。
- Redis OSS / Valkey 互換
- マルチ AZ 構成で高可用性(SLA 99.99%)
- 毎秒数百万リクエスト対応の超低レイテンシー性能
- セマンティックキャッシュ用途にも対応(VSS 機能)
MemoryDB では、インデックス作成方式として HNSW(Hierarchical Navigable Small World) が選択できます。
- 構築・検索パラメータ(m, efConstruction, efRuntime)が調整可能
- ユークリッド距離・コサイン類似度など複数の距離指標に対応

クエリ例
FT.SEARCH index "@field:[VECTOR_RANGE radius $vector]=>{$YIELD_DISTANCE_AS: dist_field}"
PARAMS 2 vector BLOB "..."
SORTBY dist_field
このような形式で、ベクトルとの距離が一定以下のデータを高速に検索できます。
実運用例
月間およそ 57,000 リクエストのチャットボットでの適用例が紹介されました。80% のクエリが意味的に重複しており、セマンティックキャッシュを導入した結果下記の効果が得られました。
- 70%のコスト削減
- キャッシュヒット時ミリ秒単位の応答
まとめ
セマンティックキャッシュを導入する利点は以下です。
- コスト削減
LLM API の呼び出しを極力回避 - スケーラビリティ
ユーザー増に比例しないコスト構造 - 速度向上
ミリ秒で応答し、UX を大幅に改善
感想
従来の完全一致キャッシュの限界を乗り越える「意味的キャッシュ」の提案は、生成 AI の現実的な運用コスト問題を極めて実践的に解決するものだと思いました。特に、MemoryDB とベクトル検索の組み合わせというアーキテクチャの具体性と、実運用での効果(70% コスト削減)が印象的でした。生成 AI アプリケーションにおいて「LLM の呼び出し回数を減らすことが最適化の鍵」であるという観点を、あらためて実感できたセッションでした。









