Building a Serverless AI Training Platform on AWS: Pay-as-you-Grow Architecture with Bedrock, SQS, and WebSockets
I built AWS Mission Architect, a web platform that uses Amazon Bedrock to generate dynamic, hands-on AWS architecture challenges. The system runs entirely on serverless primitives so it costs near-zero at rest, but scales horizontally under load without manual intervention.
This article walks through the architectural decisions — why I chose each service, what I'd do differently, and the non-obvious gotchas around Bedrock streaming, WebSocket auth, and SQS-buffered LLM workloads.
1. Why this architecture?
The product brief had three hard constraints:
- Idle-cost ≈ $0 — no always-on EC2 / Fargate / RDS.
- Elastic — sudden traffic spikes must not require ops intervention.
- LLM-resilient — Bedrock has per-account TPM (tokens per minute) limits; the UI must never hang when we're throttled.
Those three constraints map almost 1:1 onto an AWS serverless stack:
| Constraint | Service choice |
|---|---|
| Idle-cost ≈ 0 | Lambda + DynamoDB on-demand + API Gateway |
| Elastic scaling | Lambda concurrency + API Gateway built-in throttling |
| LLM resilience | SQS buffer + DLQ + async WebSocket delivery |
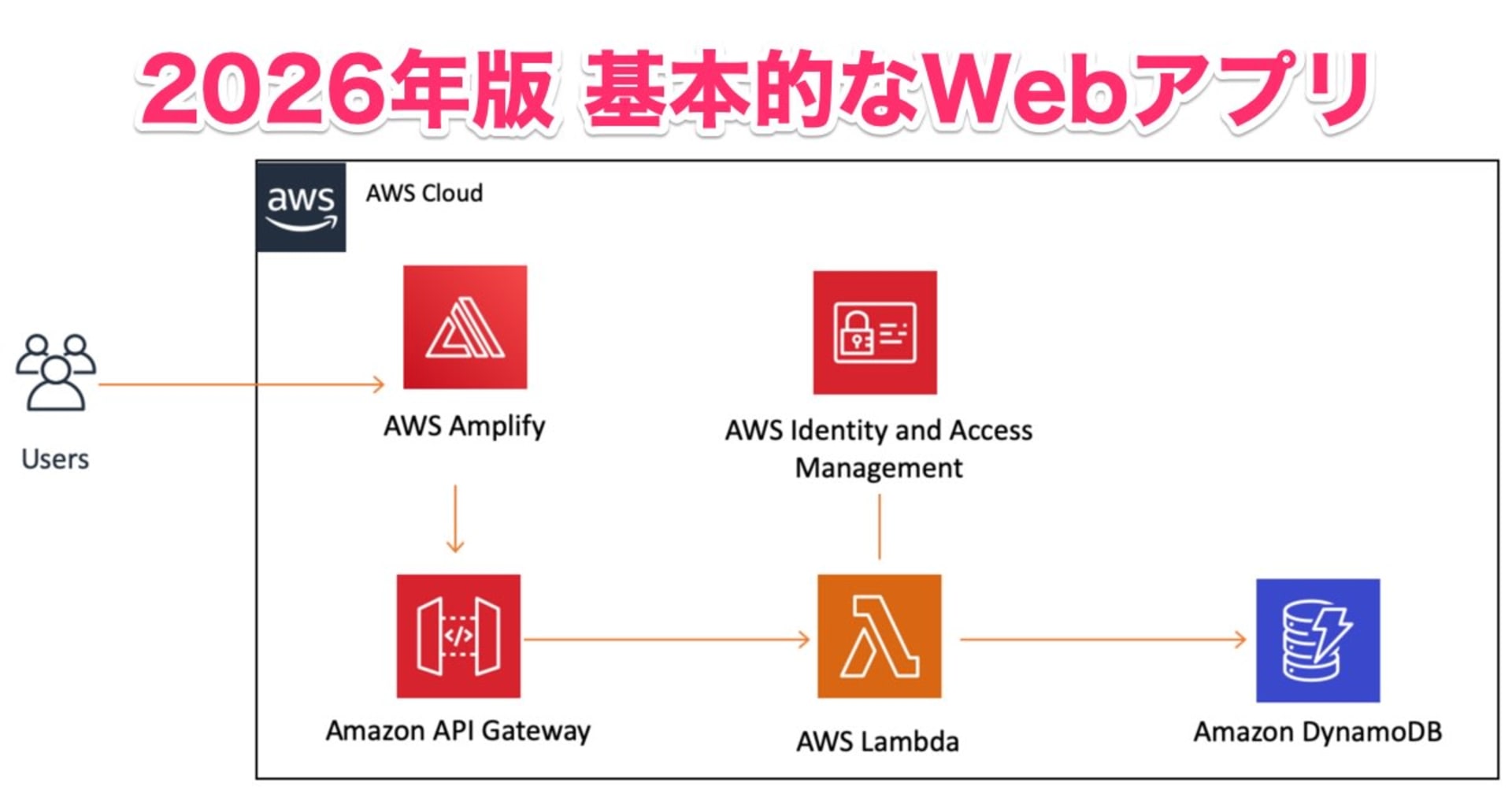
2. High-level architecture
[Browser — Vite + React SPA]
↓ CloudFront + S3 (static hosting)
[Edge: Cognito · API Gateway REST · API Gateway WebSocket]
↓ JWT-validated
[Compute: Lambda functions (Node.js 22 / TypeScript)]
├── Mission Generator → SQS → AI Worker → Bedrock (non-streaming)
├── Chat Hints → Bedrock (streaming)
├── History & Profile → DynamoDB CRUD
├── Auto-Grader → template parse + criteria check
└── WS Connection Manager → ws_connections table
↓
[Data: DynamoDB — users · missions · conversations · ws_connections]
Two API surfaces sit at the edge:
- REST API — synchronous CRUD: list missions, fetch a mission, submit a template for grading.
- WebSocket API — async push: streaming chat tokens and "mission ready" notifications.
The split matters: it lets us hand long-running Bedrock calls off to background workers without forcing the frontend to poll.
3. The mission-generation pipeline
This is the part I spent the most time on, because it's where every constraint collides.
The naive approach (and why it fails)
[Client] → API Gateway → Lambda → Bedrock.invokeModel → Lambda response → Client
This works until Bedrock throttles. Then:
- Lambda hits a 5-second invocation that returns
ThrottlingException. - The user sees a generic 500.
- API Gateway has a 29s hard timeout; long generations risk hitting it anyway.
- No retry strategy.
The actual pipeline
- Client → API Gateway → Lambda → Bedrock → Client
+ Client → API Gateway → MissionGenerator(Lambda) → SQS
+ ↓
+ AIWorker(Lambda) → Bedrock
+ ↓
+ DynamoDB.update + WS.push("mission ready")
+ ↓
+ Client (via WebSocket)
Steps:
MissionGeneratorwrites astatus: "generating"row to DynamoDB and enqueues an SQS message. Returns202 Acceptedwith the mission ID in ~50ms.AIWorkeris the SQS consumer. It calls Bedrock, parses the structured output, and updates the mission row tostatus: "ready".- The worker pushes a message over the user's WebSocket connection, so the SPA updates instantly without polling.
Throttling resilience for free
Because the worker reads from SQS:
- If Bedrock throttles, the worker
throws — the message returns to the queue (visibility timeout) and retries. - After N retries it lands in the DLQ. A CloudWatch alarm fires on
ApproximateNumberOfMessagesVisible > 0. - The frontend shows a "generating…" spinner the whole time. No 500s, no spinning forever.
export const handler = async (event: SQSEvent) => {
for (const record of event.Records) {
const { missionId, userId, prompt } = JSON.parse(record.body);
try {
const result = await invokeBedrock(prompt);
await updateMission(missionId, { status: "ready", result });
await pushToUser(userId, { type: "mission_ready", missionId });
} catch (err) {
if (isThrottling(err)) throw err; // back to SQS
await updateMission(missionId, { status: "failed", error: String(err) });
}
}
};
4. WebSocket auth: the part that surprised me
API Gateway WebSocket APIs only run the authorizer at $connect. That sounds fine until you realise: browsers can't set custom headers on new WebSocket(). The standard workaround is ?token=... in the query string, which puts a long-lived JWT in URL logs and browser history.
The fix I ended up with — a one-time ticket flow:
- Frontend calls a REST endpoint
POST /ws-ticket(authed via Cognito ID token inAuthorization: Bearer). - The endpoint mints a single-use, short-lived ticket (60s TTL) and stores it in a DynamoDB table with a TTL attribute.
- Frontend opens the WS with
?ticket=<value>. - The
$connectauthorizer looks up the ticket, deletes it atomically (single use), and binds the connection ID → user ID.
const ticket = event.queryStringParameters?.ticket;
const row = await ddb.send(new DeleteItemCommand({
TableName: TICKETS_TABLE,
Key: { ticket: { S: ticket } },
ReturnValues: "ALL_OLD", // atomic consume
}));
if (!row.Attributes) return deny();
return allow(row.Attributes.userId.S);
5. Bedrock: streaming vs non-streaming
I use Bedrock in two different modes for two different UX needs:
| Use case | Mode | Why |
|---|---|---|
| Mission generation | InvokeModel (non-stream) |
Output is parsed as structured JSON; need the whole response to validate schema |
| Chat hints | InvokeModelWithResponseStream |
Token-by-token UX over WS feels 10× more responsive |
Cross-region inference profile
In ap-southeast-1 (Singapore), Claude Sonnet 4.x is only available through a cross-region inference profile:
const MODEL_ID = "global.anthropic.claude-sonnet-4-6";
// NOT "anthropic.claude-sonnet-4-6-20250101-v1:0"
If you use the raw model ID, you get ValidationException: invocation of model ID anthropic.claude-... isn't supported. The global. prefix is the inference profile, which routes the call to whichever region has capacity.
IAM policy for cross-region Bedrock
The Lambda execution role needs bedrock:InvokeModel on both the inference profile ARN and the foundation model ARN — the SDK calls the profile, but the profile calls the underlying model on your behalf.
{
"Effect": "Allow",
"Action": ["bedrock:InvokeModel", "bedrock:InvokeModelWithResponseStream"],
"Resource": [
"arn:aws:bedrock:*::foundation-model/anthropic.claude-sonnet-4-6-*",
"arn:aws:bedrock:*:*:inference-profile/global.anthropic.claude-sonnet-4-6"
]
}
6. DynamoDB schema
Four tables, all on-demand billing:
| Table | PK | SK | Purpose |
|---|---|---|---|
users |
userId |
— | Profile, stats |
missions |
userId |
missionId |
One row per generated mission |
conversations |
missionId |
timestamp |
Chat history per mission |
ws_connections |
connectionId |
— | Live WS sessions (TTL = 2h) |
Two non-obvious choices:
userIdas PK for missions,missionIdas SK — this gives a free "list my missions, newest first" query by sorting onmissionId(ULID, lexicographically time-sorted).- TTL on
ws_connections— DynamoDB sweeps stale connection rows automatically. Even if my disconnect handler fails, dead rows expire within 48h. Free garbage collection.
7. Auto-grader
Does it call Bedrock? No.
The grader is pure, deterministic computation over the parsed template. Zero LLM calls, zero Bedrock cost, runs in <50ms.
The "intelligence" happened earlier — when Bedrock generated the mission, it emitted structured successCriteria alongside the human-readable scenario. The grader is just a small interpreter for that format.
A criterion looks like this:
{
"resourceType": "AWS::Lambda::Function",
"property": "Runtime",
"expected": "nodejs22.x",
"label": "Lambda uses Node.js 22 runtime"
}
The flow
[Client uploads template.yaml/.json]
↓
[POST /missions/{id}/grade] → AutoGrader Lambda
↓
1. Auth check (Cognito JWT) — verify user owns this mission
2. Load mission from DynamoDB → get successCriteria[]
3. Parse template body:
• try JSON.parse first
• fall back to js-yaml with custom !Ref/!GetAtt/!Sub tags
4. For each criterion: walk template.Resources, check property path
5. score = passed / total
6. Persist {gradeStatus, gradeResult} back to mission row
7. Return JSON
Three primitives do all the work
// 1. JSON-or-YAML parser, with custom tags so !Ref etc. don't crash
const CFN_TAG_NAMES = ['Ref', 'GetAtt', 'Sub', 'Select', 'If', /* ... */];
const cfnTypes = CFN_TAG_NAMES.flatMap(tag =>
(['scalar', 'sequence', 'mapping'] as const).map(kind =>
new Type(`!${tag}`, { kind, construct: (d: unknown) => d })));
const CFN_SCHEMA = DEFAULT_SCHEMA.extend(cfnTypes);
// 2. Walks dotted paths like "LambdaConfigurations[0].Event"
function getNestedValue(obj: Record<string, unknown>, path: string): unknown {
return path.split('.').reduce<unknown>((acc, key) => {
if (acc == null || typeof acc !== 'object') return undefined;
const arrMatch = key.match(/^(.+?)\[(\d+)\]$/);
if (arrMatch) {
const arr = (acc as Record<string, unknown>)[arrMatch[1]];
return Array.isArray(arr) ? arr[Number(arrMatch[2])] : undefined;
}
return (acc as Record<string, unknown>)[key];
}, obj);
}
// 3. Exact match, escalates to regex if expected has wildcards
function matchesValue(val: unknown, expected: string): boolean {
const str = String(val);
if (!expected.includes('*') && !expected.includes('?')) return str === expected;
const pattern = expected
.replace(/[.+^${}()|[\]\\]/g, '\\$&')
.replace(/\*/g, '.*').replace(/\?/g, '.');
return new RegExp(`^${pattern}$`).test(str);
}
Three things made this harder than expected:
- YAML intrinsic functions —
!Ref,!GetAtt,!Sub, etc. crash a vanilla YAML parser. Each one needs a customTyperegistered against the schema in all three kinds (scalar, sequence, mapping). - Array index paths —
LambdaConfigurations[0].Eventneeds a walker that handles both.keyand[n]. A naive.split('.')doesn't work. - Glob matching for ARNs —
arn:aws:iam::*:role/*should match a real ARN. Plain string equality fails; I convert*/?to regex.*/.after escaping all other special chars.
Why this design
| LLM-graded | Rule-graded (this one) | |
|---|---|---|
| Cost per grade | ~$0.01–0.05 | $0 |
| Latency | 5–15 s | <50 ms |
| Determinism | Same input → maybe different output | Same input → same output |
| Required IAM | bedrock:InvokeModel |
None beyond DynamoDB |
| Expressiveness | Anything you can describe | Anything fitting {resourceType, property, expected} |
The trade-off is rigidity. If a mission needs "the template must include a Lambda that subscribes to an SNS topic that fans out to SQS", the current schema can't express that multi-hop relationship — you'd either pre-bake the check into the criteria emitter, or fall back to Bedrock for grading.
8. Costs at rest vs under load
Rough numbers for ap-southeast-1, sustained 1000 missions/day:
| Service | At rest | 1000 missions/day |
|---|---|---|
| Lambda | $0 | ~$0.20 |
| API Gateway (REST + WS) | $0 | ~$3.50 |
| DynamoDB (on-demand) | $0 | ~$0.40 |
| SQS | $0 | ~$0.01 |
| Bedrock (Claude Sonnet 4.6) | $0 | ~$45 |
| CloudFront + S3 | ~$0.10 | ~$0.30 |
| Total | ~$0.10/mo | ~$49/mo |
Bedrock dominates the bill — every other service is rounding error. So the optimisation target is prompt size and output tokens, not infrastructure.
9. Provisioning it all with CDK
The whole stack is defined in TypeScript CDK, split into four stacks: DatabaseStack, AuthStack, StorageStack, BackendStack. Below are the bits that actually carried weight.
9.1 DynamoDB tables — schema-as-code
this.missionsTable = new dynamodb.Table(this, 'Missions', {
partitionKey: { name: 'missionId', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST, // on-demand → zero idle cost
removalPolicy: cdk.RemovalPolicy.RETAIN, // never auto-delete user data
});
this.missionsTable.addGlobalSecondaryIndex({
indexName: 'userId-createdAt-index',
partitionKey: { name: 'userId', type: dynamodb.AttributeType.STRING },
sortKey: { name: 'createdAt', type: dynamodb.AttributeType.STRING },
});
this.wsConnectionsTable = new dynamodb.Table(this, 'WsConnections', {
partitionKey: { name: 'connectionId', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
timeToLiveAttribute: 'ttl', // DDB sweeps stale connections
removalPolicy: cdk.RemovalPolicy.DESTROY, // ephemeral state, safe to drop
});
this.wsTicketsTable = new dynamodb.Table(this, 'WsTickets', {
partitionKey: { name: 'ticket', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
timeToLiveAttribute: 'ttl', // 60s TTL — defence in depth
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
9.2 SQS queue with DLQ + alarm in one place
const dlq = new sqs.Queue(this, 'Dlq', {
retentionPeriod: cdk.Duration.days(14),
});
new cloudwatch.Alarm(this, 'DlqDepthAlarm', {
metric: dlq.metricApproximateNumberOfMessagesVisible(),
threshold: 1,
evaluationPeriods: 1,
comparisonOperator: cloudwatch.ComparisonOperator.GREATER_THAN_OR_EQUAL_TO_THRESHOLD,
alarmDescription: 'Mission generation DLQ has messages — check for stuck missions',
treatMissingData: cloudwatch.TreatMissingData.NOT_BREACHING,
});
const missionQueue = new sqs.Queue(this, 'MissionQueue', {
visibilityTimeout: cdk.Duration.seconds(1800), // 6× Lambda timeout
deadLetterQueue: { queue: dlq, maxReceiveCount: 3 },
});
The visibilityTimeout must be ≥ Lambda function timeout × 6 — otherwise Lambda will start re-processing a message while the previous invocation is still running. CDK won't warn you; the docs hint at it.
9.3 A mkFn helper to keep Lambda definitions DRY
Seven Lambda functions share 90% of their config. A tiny factory beats copy-paste:
const sharedEnv = {
USERS_TABLE: props.usersTable.tableName,
MISSIONS_TABLE: props.missionsTable.tableName,
WS_ENDPOINT: wsStage.callbackUrl,
MISSION_QUEUE_URL: missionQueue.queueUrl,
BEDROCK_MODEL_ID: 'global.anthropic.claude-sonnet-4-6',
// ...
};
const mkFn = (id: string, handler: string, extra?: Partial<lambda.FunctionProps>) =>
new lambda.Function(this, id, {
runtime: lambda.Runtime.NODEJS_22_X,
handler,
code: lambda.Code.fromAsset('../backend/dist'),
timeout: cdk.Duration.minutes(5),
environment: sharedEnv,
logGroup: new logs.LogGroup(this, `${id}Logs`, {
retention: logs.RetentionDays.ONE_MONTH,
removalPolicy: cdk.RemovalPolicy.DESTROY,
}),
...extra,
});
const missionGeneratorFn = mkFn('MissionGenerator', 'handlers/mission-generator.handler');
const aiWorkerFn = mkFn('AiWorker', 'handlers/ai-worker.handler', {
reservedConcurrentExecutions: 10, // cap Bedrock fan-out
});
The reservedConcurrentExecutions: 10 on the AI worker is the second half of throttle protection: even if SQS has 10k messages waiting, we'll never have more than 10 concurrent Bedrock calls. The rest sit in SQS, free.
9.4 SQS → Lambda event source + least-privilege IAM
// Wire the AI worker to consume from SQS
missionQueue.grantSendMessages(missionGeneratorFn);
missionQueue.grantConsumeMessages(aiWorkerFn);
aiWorkerFn.addEventSource(new lambdaEventSources.SqsEventSource(missionQueue, {
batchSize: 1, // one mission per invocation
}));
// Per-function, per-table DynamoDB grants
props.missionsTable.grantWriteData(missionGeneratorFn);
props.missionsTable.grantReadWriteData(aiWorkerFn);
props.missionsTable.grantReadData(chatHintsFn);
// Bedrock + WebSocket management policies for the AI-touching functions
const bedrockPolicy = new iam.PolicyStatement({
actions: ['bedrock:InvokeModel', 'bedrock:InvokeModelWithResponseStream'],
resources: ['*'],
});
const wsManagePolicy = new iam.PolicyStatement({
actions: ['execute-api:ManageConnections'],
resources: [`arn:aws:execute-api:${this.region}:${this.account}:${wsApi.apiId}/*`],
});
[aiWorkerFn, chatHintsFn].forEach(f => {
f.addToRolePolicy(bedrockPolicy);
f.addToRolePolicy(wsManagePolicy);
});
grant*Data is the right primitive to lean on. It writes the minimal policy for you, and if you forget a permission you get a deploy-time CDK warning instead of a runtime AccessDenied.
9.5 Two API surfaces, one stack
// WebSocket API (must exist before Lambdas, so callbackUrl can be injected as env)
const wsApi = new apigwv2.WebSocketApi(this, 'WsApi');
const wsStage = new apigwv2.WebSocketStage(this, 'WsStage', {
webSocketApi: wsApi, stageName: 'prod', autoDeploy: true,
});
const wsi = (fn: lambda.Function, id: string) =>
new integrations.WebSocketLambdaIntegration(id, fn);
wsApi.addRoute('$connect', { integration: wsi(wsConnectionFn, 'Connect') });
wsApi.addRoute('$disconnect', { integration: wsi(wsConnectionFn, 'Disconnect') });
wsApi.addRoute('sendHint', { integration: wsi(chatHintsFn, 'SendHint') });
// REST API with Cognito authorizer
const rest = new apigw.RestApi(this, 'RestApi', {
deployOptions: { stageName: 'prod' },
defaultCorsPreflightOptions: {
allowOrigins: apigw.Cors.ALL_ORIGINS,
allowHeaders: apigw.Cors.DEFAULT_HEADERS,
allowMethods: apigw.Cors.ALL_METHODS,
},
});
const cogAuth = new apigw.CognitoUserPoolsAuthorizer(this, 'CogAuth', {
cognitoUserPools: [props.userPool],
});
const opts = { authorizer: cogAuth, authorizationType: apigw.AuthorizationType.COGNITO };
const missionsRes = rest.root.addResource('missions');
missionsRes.addMethod('POST', new apigw.LambdaIntegration(missionGeneratorFn), opts);
missionsRes.addResource('{id}').addResource('grade')
.addMethod('POST', new apigw.LambdaIntegration(autoGraderFn), opts);
9.6 Stack composition
const app = new cdk.App();
const env = { region: 'ap-southeast-1' };
const db = new DatabaseStack(app, 'AwsMissionDatabase', { env });
const auth = new AuthStack(app, 'AwsMissionAuth', { env });
const store = new StorageStack(app, 'AwsMissionStorage', { env });
new BackendStack(app, 'AwsMissionBackend', {
env,
...db, ...auth, // pass tables + user pool as props
});
Splitting by lifecycle (data vs compute vs auth vs static hosting) means I can redeploy the compute stack 50× a day without ever touching the database stack. CDK's cross-stack references handle the wiring.
10. What I'd do differently
- Pre-warm Lambda for the AI worker. Cold starts on Node.js Lambda + AWS SDK v3 are ~400ms. Provisioned concurrency = 1 would cut that, but at the cost of breaking the idle-zero promise. Trade-off, not a bug.
- Skip API Gateway REST, use Lambda Function URLs + CloudFront. Cheaper, but you lose request validation, usage plans, and the WebSocket API anyway. Worth it for higher-traffic projects.
- Consider Bedrock Agents for the chat-hints flow. The streaming + tool-use plumbing I wrote by hand is what Bedrock Agents gives you for free.
11. Closing
The serverless tax used to be vendor lock-in and cold starts. In 2026, with on-demand DynamoDB, Lambda response streaming, and Bedrock inference profiles, the math has shifted: for a side-project that needs to scale to thousands of users but cost nothing when no one's there, this stack is hard to beat.
If you're building something similar, the three things I'd lean on hardest:
- Queue your LLM calls. SQS in front of Bedrock turns rate-limit pain into a non-event.
- Use WebSockets for async UX. Polling works, but a live spinner that updates the second the worker finishes is a 10× better experience.
- Don't put JWTs in WebSocket URLs. The one-time-ticket pattern is 30 lines of code and removes a real security hole.