![[資料公開] Amazon Bedrock AgentCore Managed Harness でAIエージェントを作るハンズオンを実施しました!](https://images.ctfassets.net/ct0aopd36mqt/7M0d5bjsd0K4Et30cVFvB6/5b2095750cc8bf73f04f63ed0d4b3546/AgentCore2.png?w=3840&fm=webp)
[資料公開] Amazon Bedrock AgentCore Managed Harness でAIエージェントを作るハンズオンを実施しました!
はじめに
こんにちは、Amazon Bedrock AgentCore が好きなコンサル部の神野です。
先日、Amazon Bedrock AgentCore Managed Harness を使ったハンズオンイベントを開催しました。コードを書かずに、AWSコンソールだけでAIエージェントを作るという内容です。チャットボットから始めて、ステップごとにツールを追加してAIエージェントを育てていくことを体験する簡単な内容になっています。
せっかくなのでハンズオン手順を公開して、誰でも試せるようにしたいと思います!
座学パートで使用したスライド資料は SpeakerDeck で公開しています。AgentCore の全体像や Managed Harness の位置づけについてまとめているので、ハンズオンを始める前にざっと目を通していただくとスムーズですが、今までの資料のディレクターズカット的な形でもあるので軽く見るぐらいで良いかと思います。
Managed Harness
ハンズオンの手順に入る前に、Managed Harness について簡単に紹介します。
Managed Harness はユーザー側がコードの実装をすることなく、コンソール上でモデルや連携するツール、システムプロンプトを設定するだけでAIエージェントとして振る舞うことを可能にします。
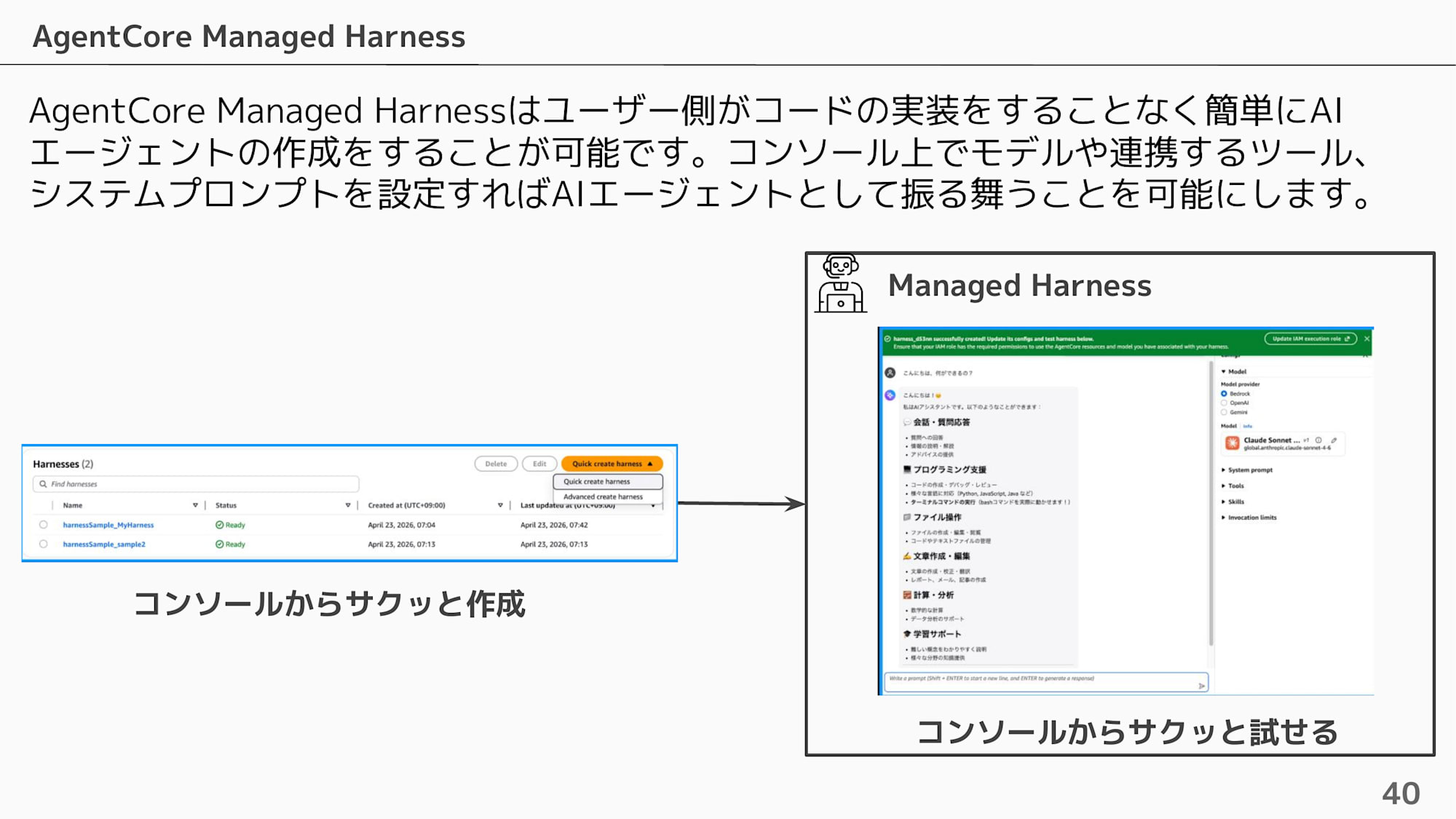
コンソールでサクッと作って、サクッとプレイグラウンド画面から試せるのが大きな魅力です!
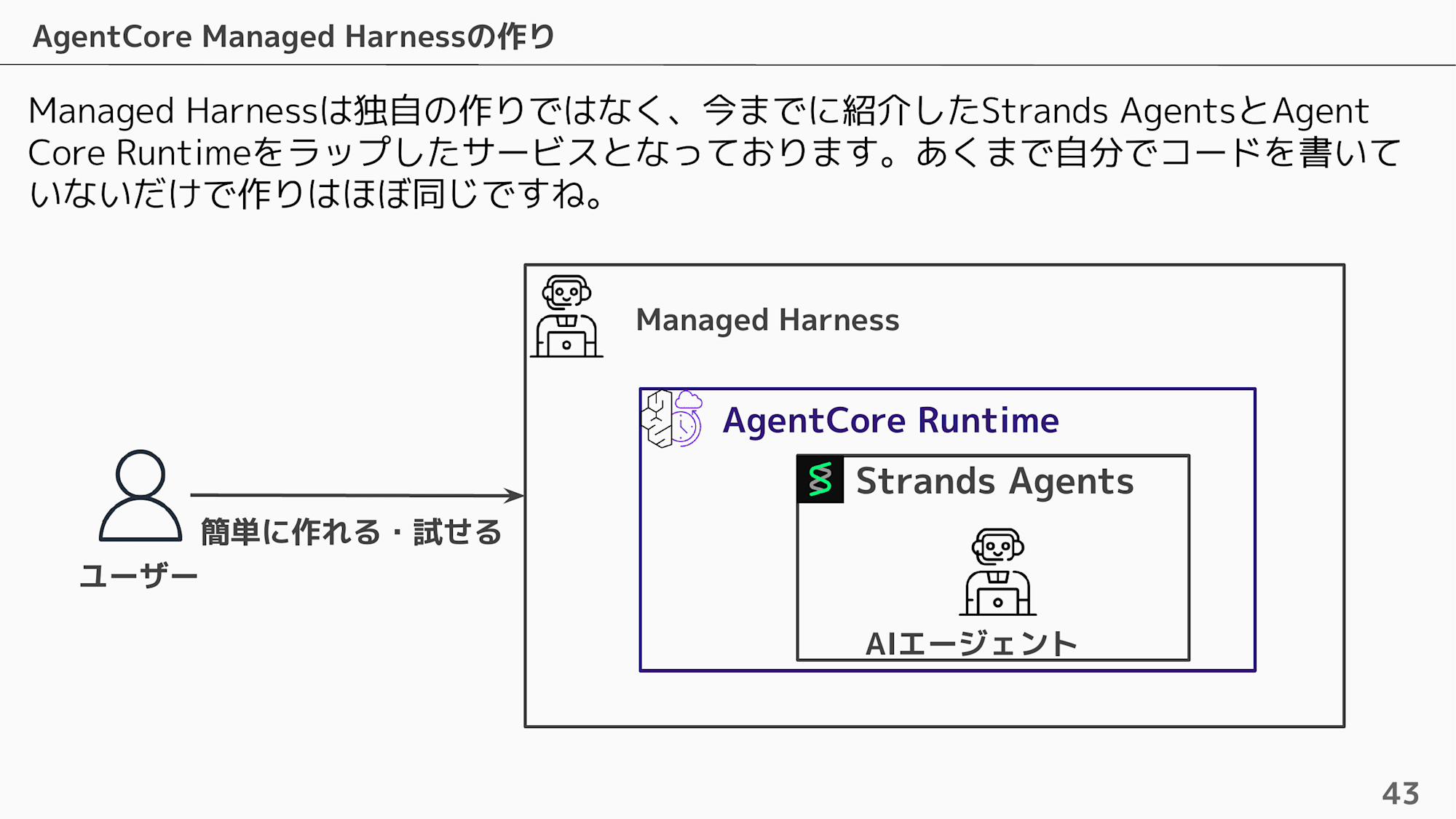
内部的には Strands Agents と AgentCore Runtime をラップしたサービスとなっています。あくまで自分でコードを書いていないだけで作りはほぼ同じですね。
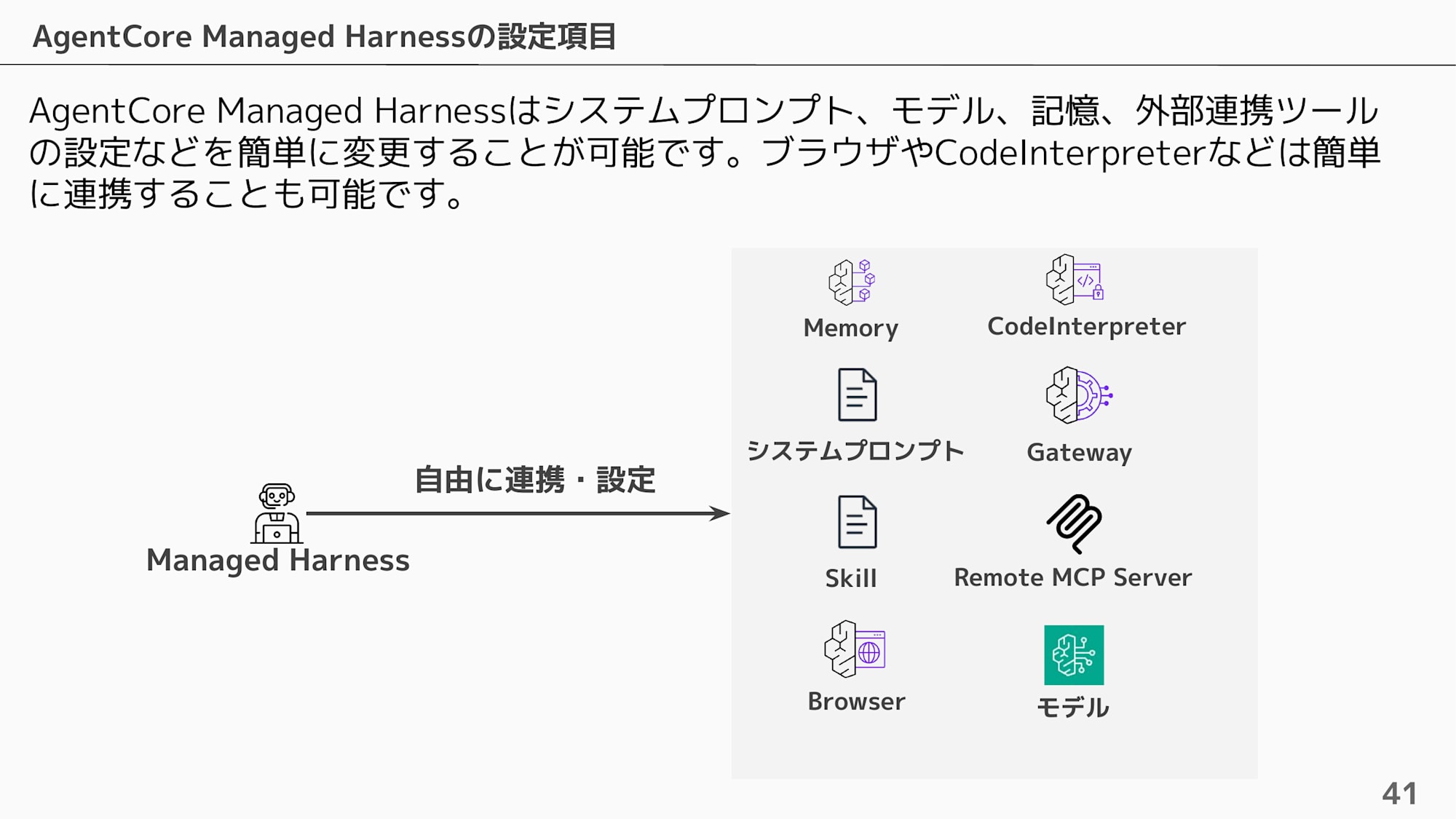
設定項目としては、システムプロンプト / モデル / Memory / Gateway / Browser / Code Interpreter / Skill / Remote MCP Server を自由に組み合わせることができます。
ハンズオンの構成
今回のハンズオンでは、Managed Harness に Browser や Code Interpreter、Gateway 経由の RAG ツールを与えて、エージェントが自律的に必要なツールを選択する様子を体感していただきます。
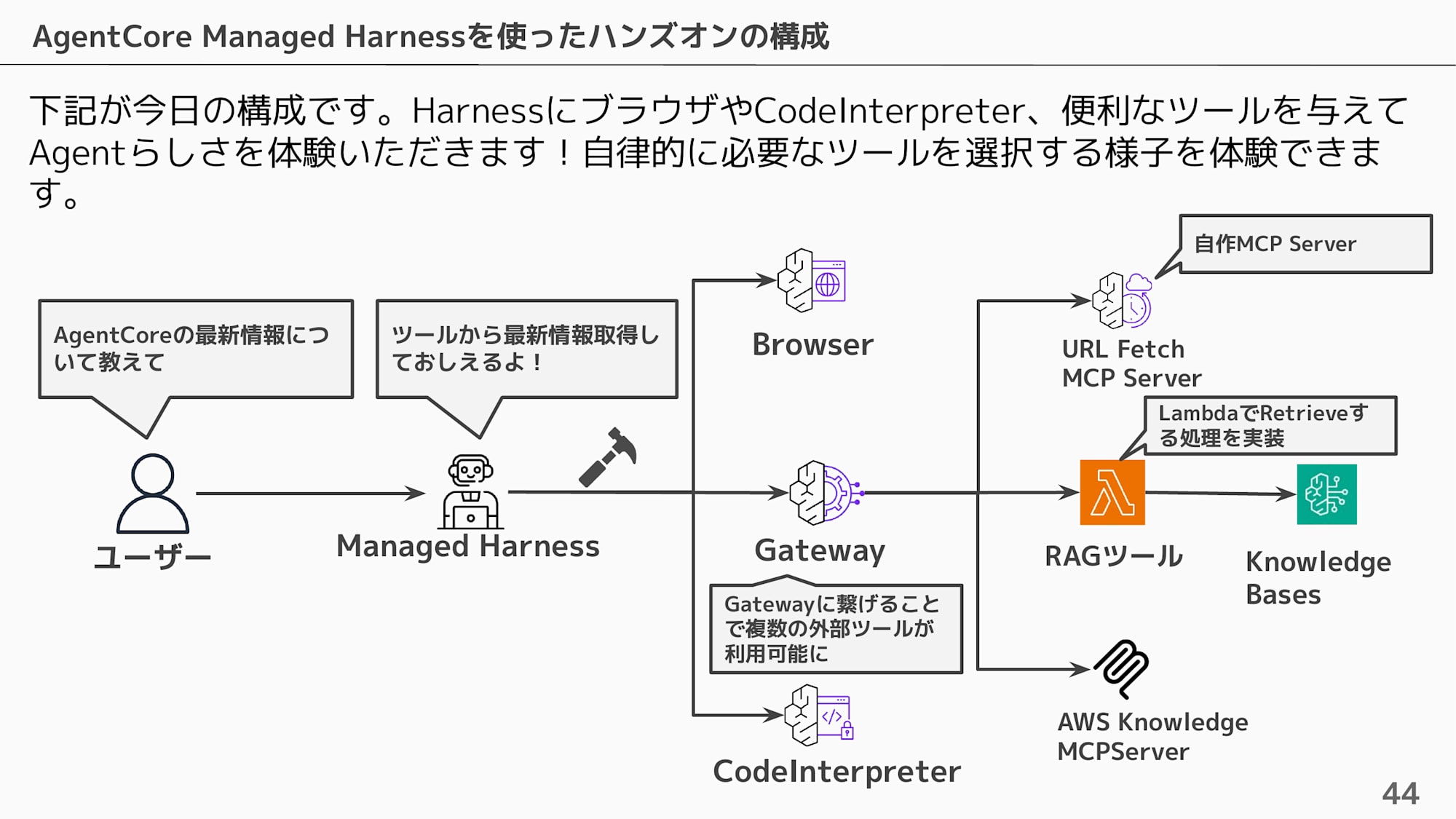
下記のパート分割でハンズオンは進めていきます。
| Part | 内容 |
|---|---|
| Part 1 | Harness を作って対話する |
| Part 2 | プロンプトで振る舞いを変える |
| Part 3 | Webから情報を取得する — Browser |
| Part 4 | コードを書いて計算させる — Code Interpreter |
| Part 5 | 社内ドキュメントを検索させる — Gateway / RAG |
| Part 6 | 裏側の動きを確認する — Observability |
| おまけ | エージェントを評価する — Evaluations |
前提
| 項目 | 内容 |
|---|---|
| 所要時間 | 約60分(事前準備除く) |
| リージョン | us-east-1(バージニア北部) |
| 必要なもの | AWSアカウント(Administrator 権限推奨) |
| ローカル環境 | Node.js 24、Docker(事前準備の Gateway デプロイに必要) |
| CDK | CDK Bootstrap 済み(npx cdk bootstrap) |
Part 1〜4 は AWSアカウントさえあればすぐに試せます。Part 5 の Gateway / RAG を体験するには、事前に Gateway と Knowledge Base を CDK でデプロイしておく必要があります。
事前準備
Gateway と Knowledge Base の構築(CDK)
Part 5 で使用する Gateway と Knowledge Base を CDK でデプロイします。CDK プロジェクトは GitHub で公開しています。ハンズオン実施時は私が先にアカウントに設置し受講者の方は行なっておりません。
管理者やCDKなどがわかる方が先んじてやっていただくと良いかもしれません。
このキットをデプロイすると、以下の3つのツールが Gateway 経由で利用可能になります。
| Target | ツール名 | 説明 | 実装 |
|---|---|---|---|
| kb-retrieve | retrieve_documents | ナレッジベースからドキュメント検索 | Lambda |
| web-tools | fetch_webpage | Web ページのテキスト取得 | FastMCP on Runtime |
| aws-knowledge | search_documentation 他 | AWS 公式ドキュメント検索 | AWS ホスト済み MCP Server |
CDK デプロイ
# リポジトリをクローン
git clone https://github.com/yuu551/agentcore-gateway-kit.git
cd agentcore-gateway-kit
# 依存インストール
npm install
# テンプレート確認
npx cdk synth
# デプロイ(2スタック: KnowledgeBase + Gateway)
npx cdk deploy --all
デプロイには数分かかります。完了すると CDK Output に KnowledgeBaseId / DataSourceId / DataSourceBucketName が表示されます。これらは後の手順で使うのでメモしておいてください。
Knowledge Base の同期
デプロイ直後はまだドキュメントが同期されていないため、同期を実行します。
aws bedrock-agent start-ingestion-job \
--knowledge-base-id <KnowledgeBaseId> \
--data-source-id <DataSourceId>
サンプルデータとして AgentCore の概要ドキュメントが S3 バケットに配置されているので、同期が完了すればすぐに RAG 検索が試せます。
独自のドキュメントを追加したい場合は S3 バケットにアップロードして同期を再実行するだけです。
aws s3 cp my-document.txt s3://<DataSourceBucketName>/
aws bedrock-agent start-ingestion-job \
--knowledge-base-id <KnowledgeBaseId> \
--data-source-id <DataSourceId>
Gateway の CDK 構築についてより詳しく知りたい方は下記の記事も参考にしてください。
AWSアカウントの準備
- https://console.aws.amazon.com/ にアクセスしてサインイン
- 画面右上のリージョンを「米国東部 (バージニア北部)」us-east-1 に変更

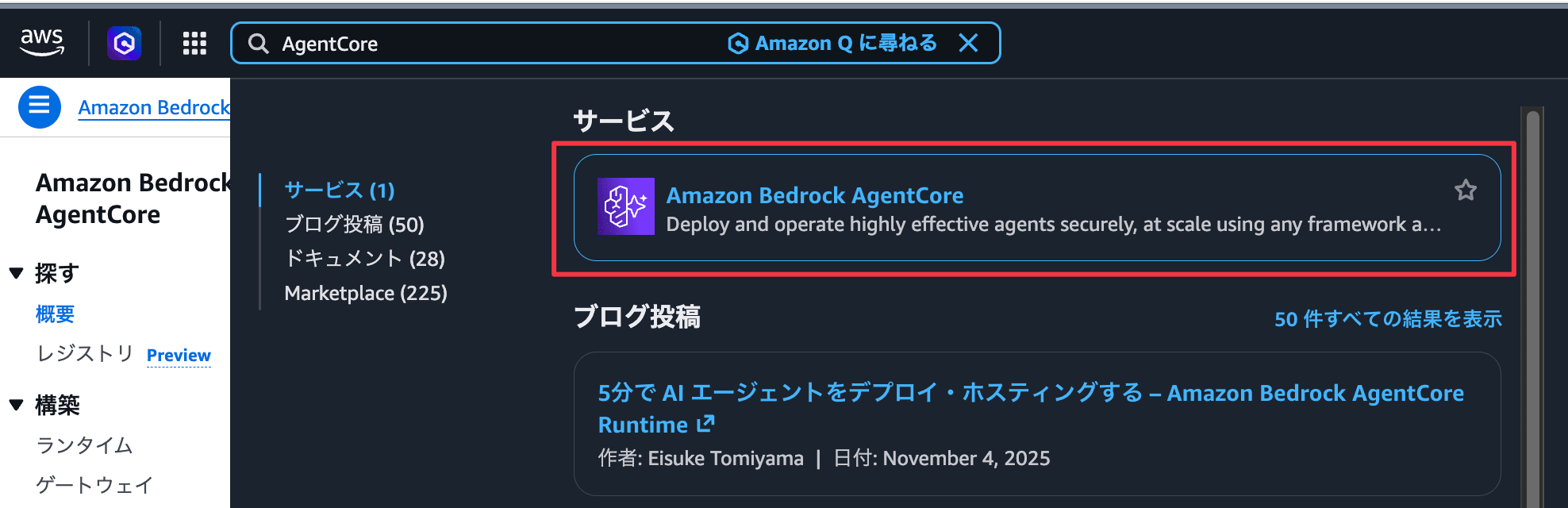
- 検索バーで「AgentCore」と入力し、「Amazon Bedrock AgentCore」をクリック
これで事前準備は完了です! ここからハンズオンに入っていきます。
Part 1: Harness を作って対話する
たった数クリックでAIエージェントを作成し、最初の対話を行います。
1-1. Harnessを作成する
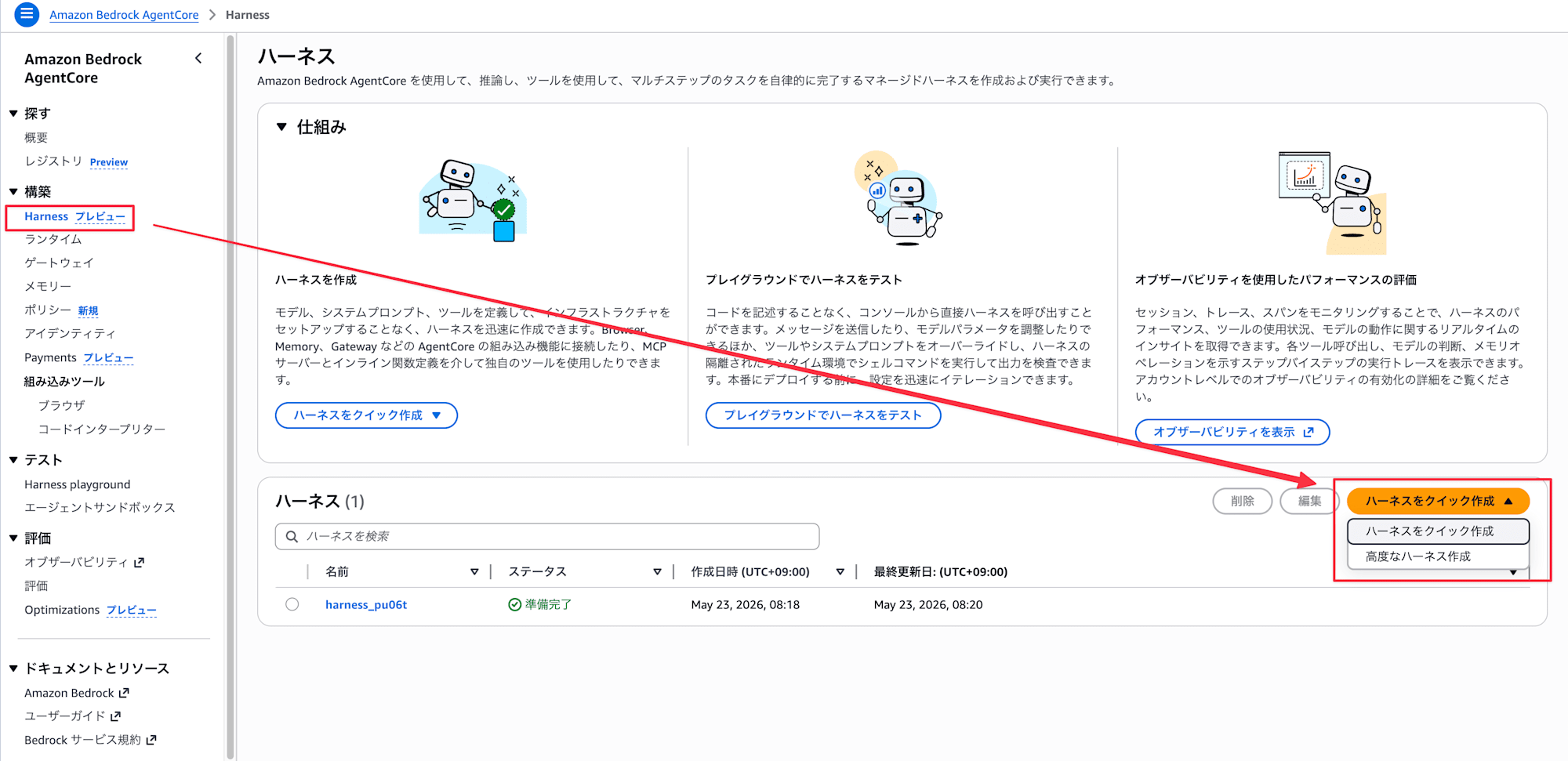
- Bedrock コンソールの左メニューから「構築」配下の「Harness プレビュー」をクリック
- 画面右上の「ハーネスをクイック作成」ボタンをクリック
- 30秒ぐらいで自動生成され、プレイグラウンド画面にリダイレクトされます
チャット入力欄のあるプレイグラウンド画面が表示されれば成功です!
1-2. モデルを変更してみる
モデルがどれだけ簡単に変更できるか体験しましょう。
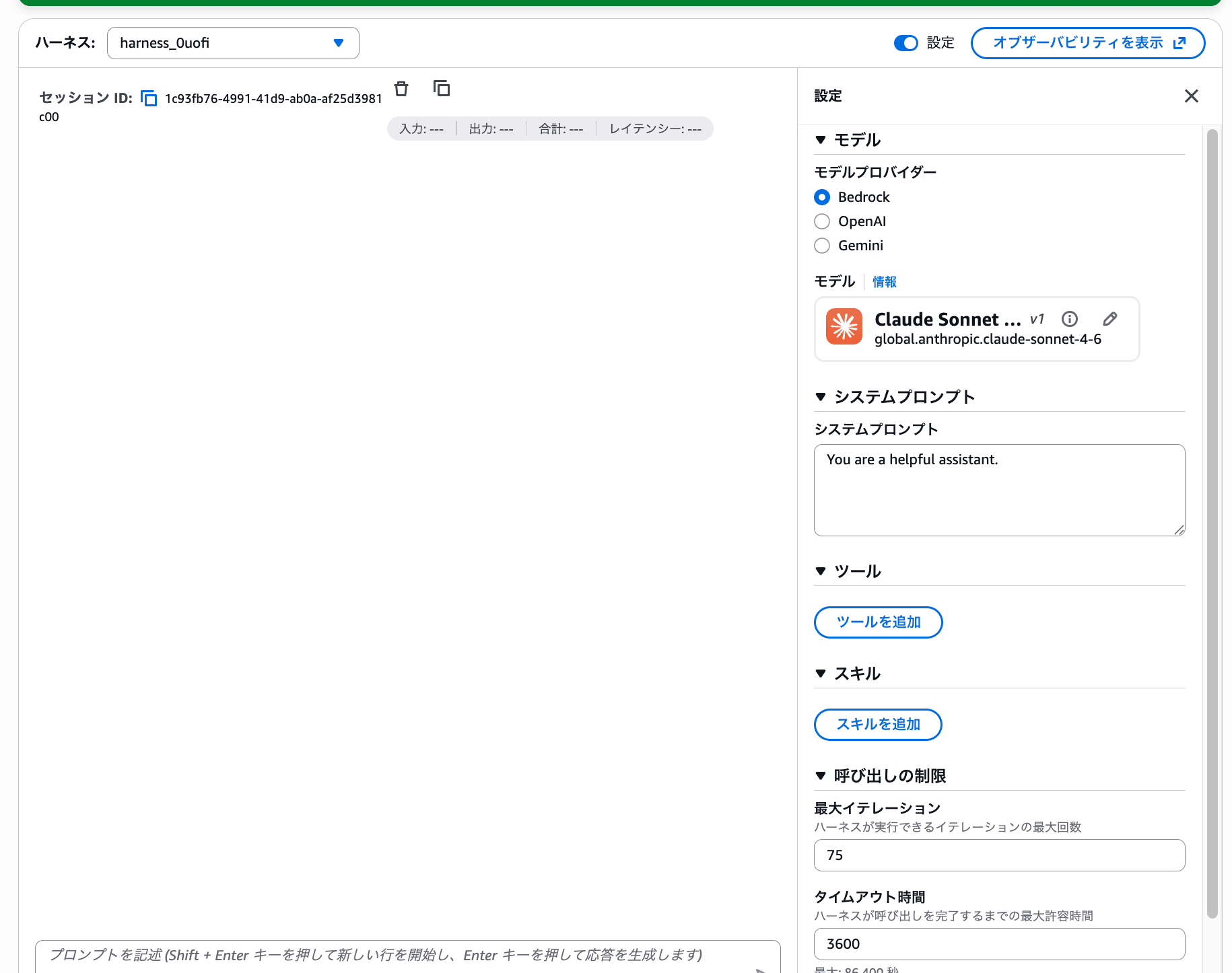
- プレイグラウンド画面の右上の「設定」トグルを ON にする
- 右側に設定パネルが表示される
- 「モデル」セクションのモデル名の横にある鉛筆アイコンをクリック
- モデル選択ダイアログが開く
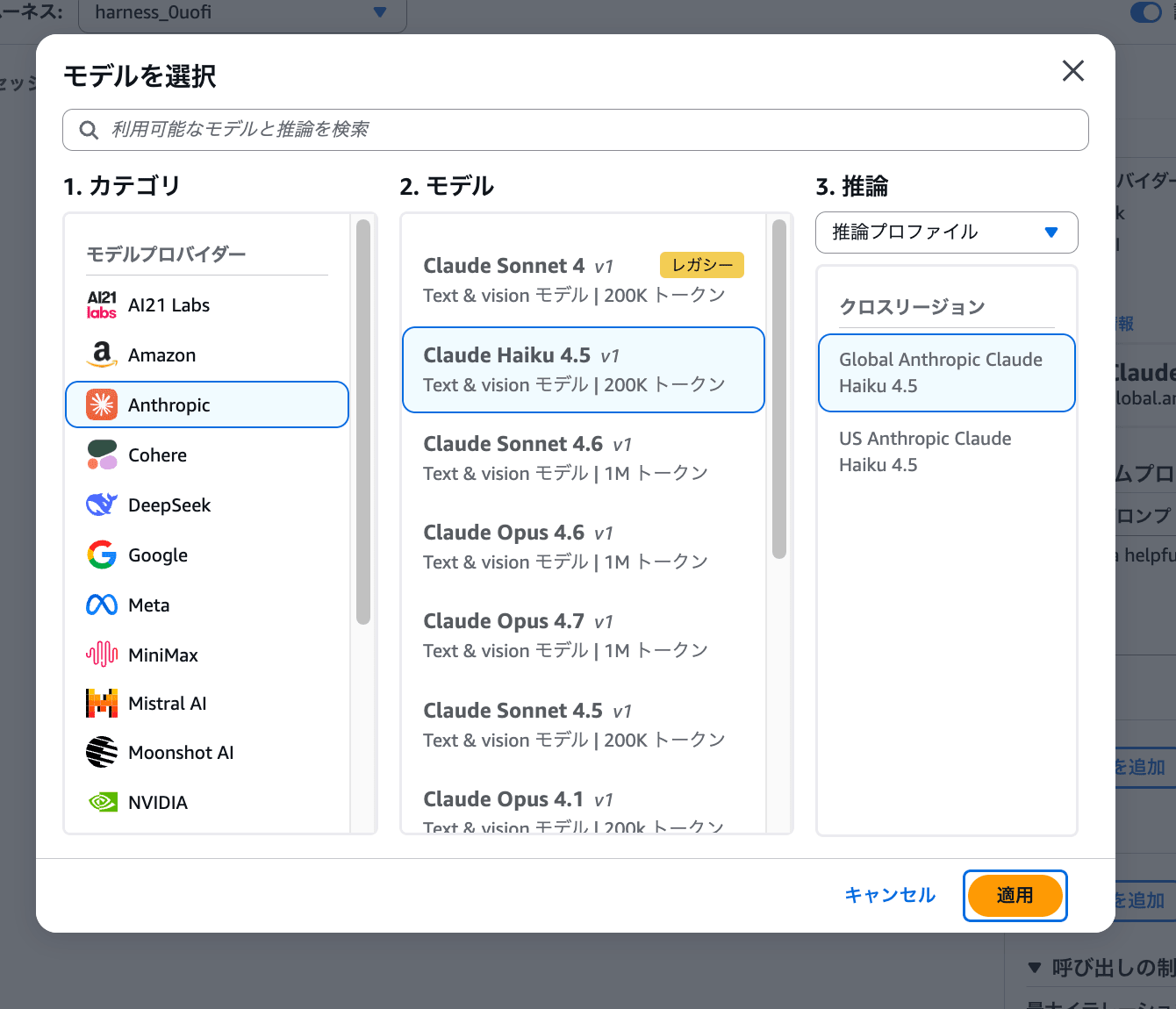
Anthropic、Amazon、Google、Meta など様々なプロバイダーのモデルが選べます。今回は Claude Haiku 4.5 を選択して「適用」をクリックしてください。
Bedrock / OpenAI / Gemini のモデルプロバイダーをワンクリックで切り替えられるのも Managed Harness の特徴です。
1-3. 最初の対話
チャット入力欄に以下を入力して送信してください。
こんにちは!あなたは何ができますか?
自己紹介的な応答が返ってくればOKです!
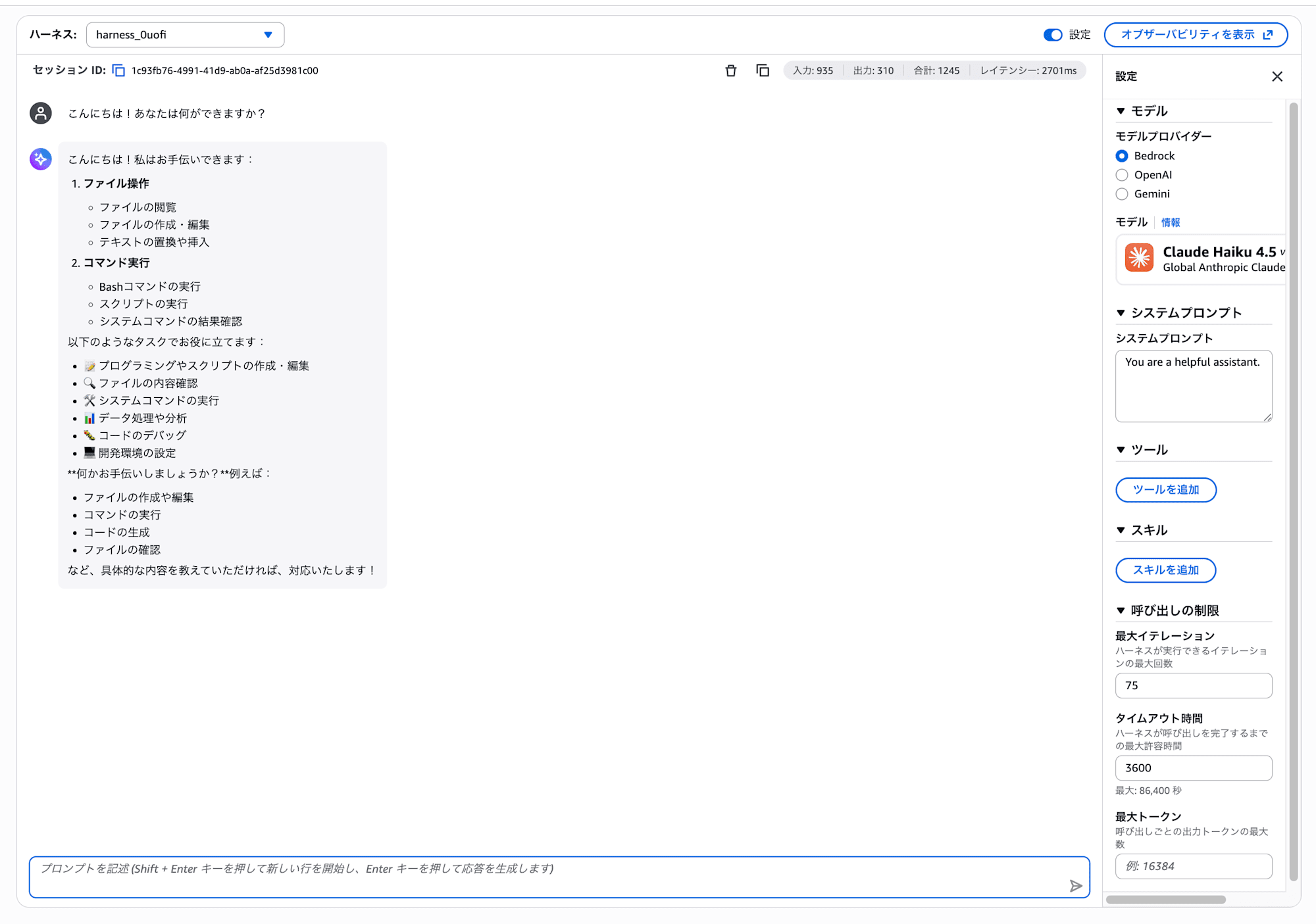
1-4. エージェント「らしい」指示を試す
次に、こちらを送信してみてください。
Amazon Bedrock AgentCoreの最新情報を調べて、主要な機能を表にまとめてください。
どうでしょう? モデルの知識の範囲でしか答えられず、最新情報は取得できないはずです。
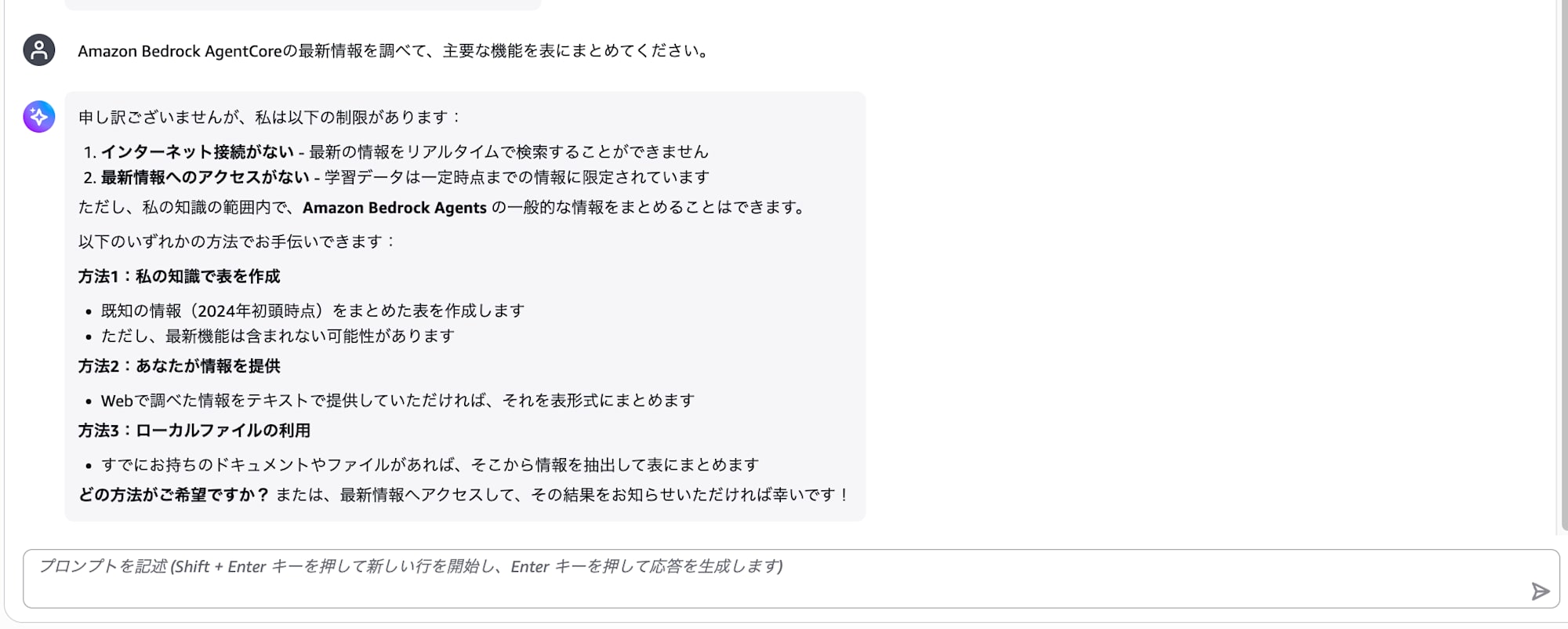
まだ何も情報を取得するようなツールを設定しないので、当然と言えば当然ですね。
ここから情報をしかるべき場所から取得するエージェントに育てていきましょう!
Part 2: プロンプトで振る舞いを変える
システムプロンプトを変更して、エージェントの振る舞いが変わることを体験します。
2-1. システムプロンプトを変更する
- 設定パネルの「システムプロンプト」セクションを探す
- 既存の内容を削除して、以下をコピー&ペーストする
あなたは「テックナビ」という名前のAWS技術コンサルタントです。
## 役割
- AWSサービスの選定・アーキテクチャ設計のアドバイスを行います
- 常に日本語で、丁寧かつ具体的に回答します
- 回答にはAWSサービス名を正確に記載します
## 回答スタイル
- まず結論を述べてから、詳細を説明する
- 複数の選択肢がある場合は比較表を作成する
- コスト面の考慮も含める
- 入力したら、そのまま次の対話に反映されます
ここで変更しているのはプレイグラウンド上の一時的な設定です。Harness 本体の設定としては保存されないため、永続化したい場合は Harness の編集画面から変更・保存する必要があります。
2-2. 変化を体感する
以下を送信してみてください。
Webアプリケーションを作りたいのですが、どのサービスを使えばいいですか?
Part 1 の汎用的な応答と比べてどう変わったでしょうか。「テックナビ」として専門的に回答し、結論から詳細の順で構造化され、比較表やコスト面の言及もあるはずです。
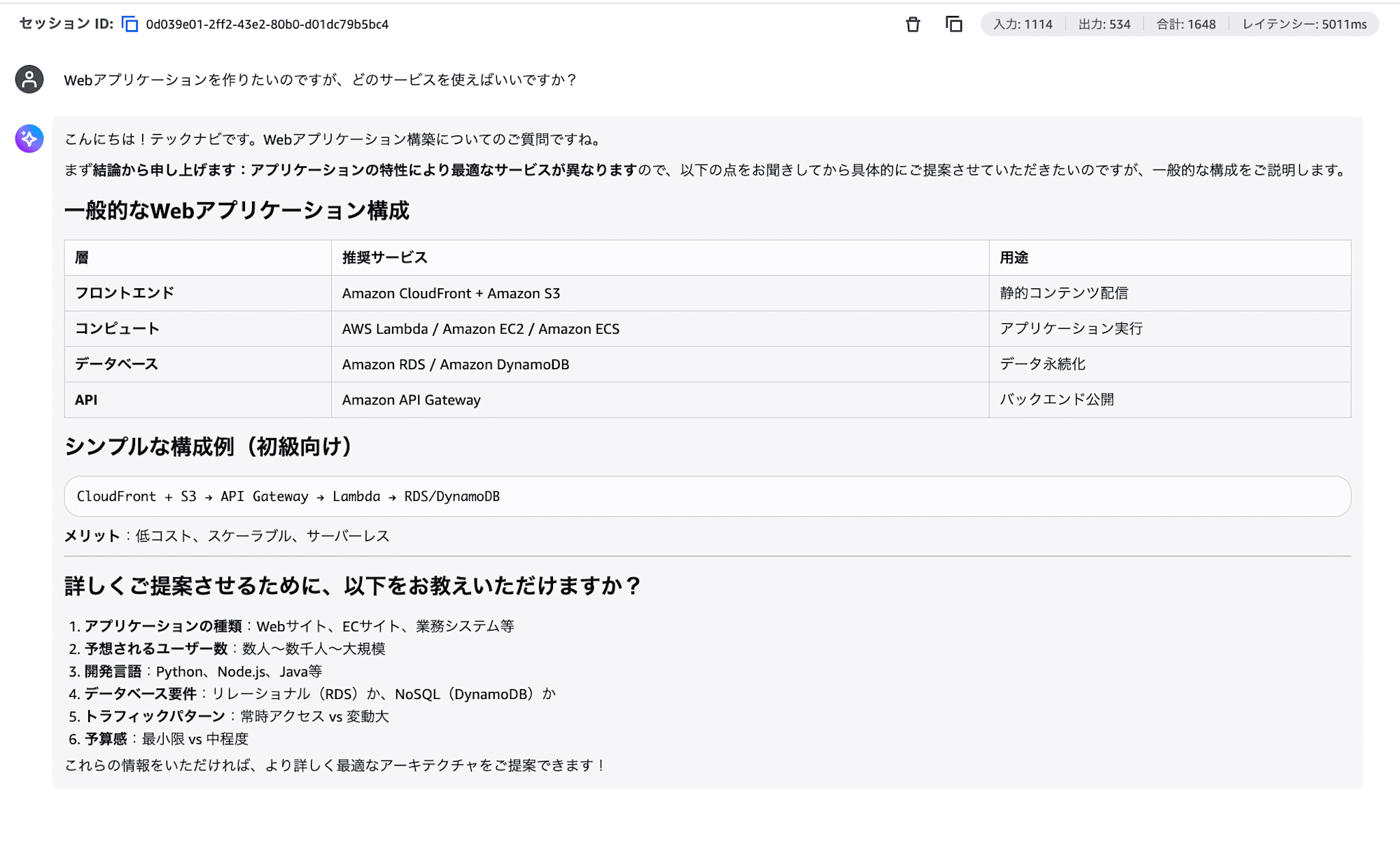
システムプロンプトひとつで、エージェントのふるまいが変わりますね!
2-3. システムプロンプトを元に戻す
Part 3以降ではツール連携の体験がメインになるため、「システムプロンプト」欄の内容を削除して空にしておきましょう。
Part 3: Webから情報を取得する — Browser
Browser tool を追加し、エージェントがリアルタイムでWebを操作する様子を体験します。
3-1. Browser tool を追加する
- 設定パネルの「ツール」セクションにある「ツールを追加」ボタンをクリック
- 「ツールタイプを選択」でブラウザツールを選択
- 「AgentCore Browser Tool」を選択
- 「追加」をクリック
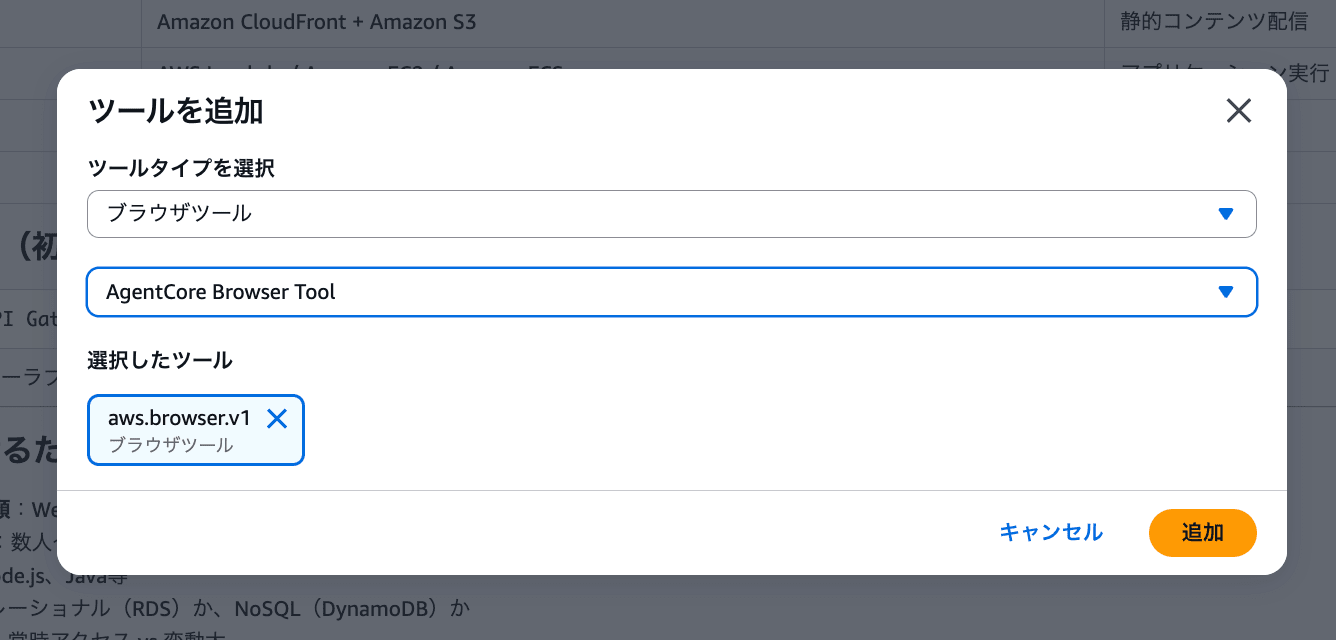
設定パネルのツールセクションに「aws.browser.v1」が表示されればOKです!
3-2. Webで最新情報を調べさせる
以下を送信してください。今回はURLを直接指定しています。
以下のURLにアクセスして、Amazon Bedrock AgentCoreの主要な機能とユースケースを表にまとめてください。
https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/what-is-bedrock-agentcore.html
エージェントが自律的にブラウザでURLを開き、ページの内容を読み取って整理します。「ブラウザを開いています」等のステータスが表示されるのを確認してください。
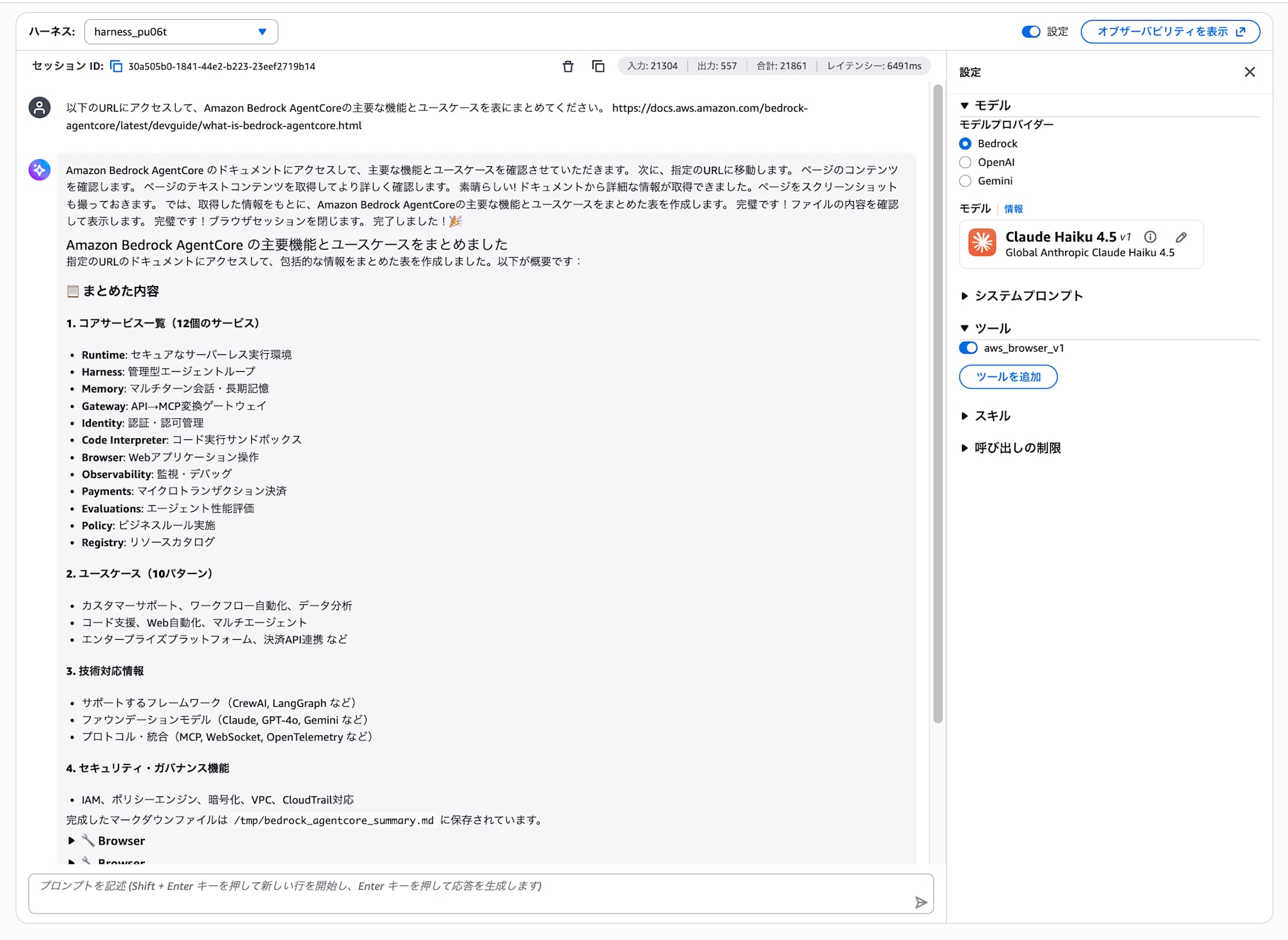
Part 1 で答えられなかった情報を、今度はブラウザツール経由でWebから取得して回答しています!
Browser tool の使い所について
今回URLを直接指定したのには理由があります。Browser tool は「検索エンジンで検索して情報を集める」用途にはあまり向いていません。検索エンジン側のアンチボット対策で CAPTCHA に引っかかるケースがあり、時間もトークンも余計にかかります。
公式ドキュメントのトラブルシューティングにも下記のような記載があります。
Structure your agent to avoid search engines and implement the following architecture pattern:
- Use the Browser tool only for specific page actions, not general web searching
- Use non-browser MCP tools like Tavily search for general web search operations
Browser tool は特定のURLにアクセスしてページの内容を読み取るような用途に使い、情報検索には Part 5 で紹介する AWS Knowledge MCP Server や Tavily Search のようなMCPツールを活用する方が効率的です。
3-3. ブラウザの動作をリアルタイムで見る
エージェントがWebを閲覧している様子をリアルタイムで観察できます。
- 手順3-2のタスクを実行中に(または新しい質問を送信して)、別のブラウザタブを開く
- Bedrock コンソール → 左メニュー「構築」配下の「組み込みツール」をクリック
- 「ブラウザ」をクリック

- 「ブラウザセッション」セクションで、ステータスが「Ready」のセッションを探す
- 「ライブセッションを見る」リンクをクリック

新しいウィンドウが開き、エージェントがWebページを閲覧している様子がリアルタイムで表示されます!
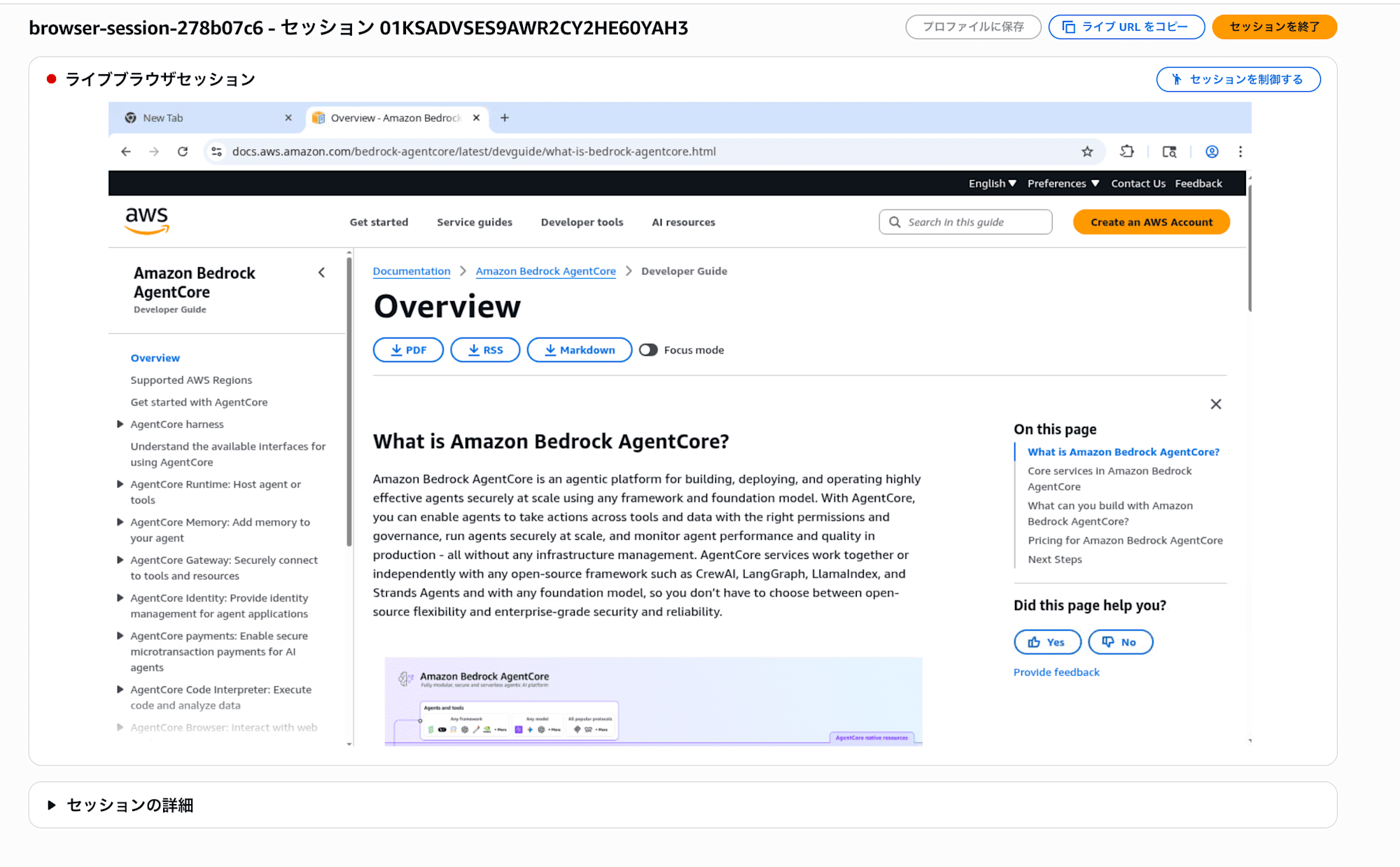
AIがブラウザを操作しているのを目の前で見られるのは面白いですね。毎度判断して、適切なアクションを行なっている形となります。
Part 4: コードを書いて計算させる — Code Interpreter
Code Interpreter tool を追加し、コードを実行してデータ分析ができることを体験します。
4-1. Code Interpreter tool を追加する
- 設定パネルの「ツール」セクションにある「ツールを追加」ボタンをクリック
- 「ツールタイプを選択」でコードインタープリターを選択
- 「AgentCore Code Interpreter Tool」を選択
- 「追加」をクリック
初回起動時にコールドスタートで30秒ほどかかることがあります。焦らず待ちましょう。
4-2. AWSコスト比較を計算させる
以下を送信してください。
月額1000万リクエストのAPIを想定して、Lambda + API Gateway と ECS Fargate のコストを比較してください。それぞれの月額コストを計算して、どちらが安いか教えてください。
エージェントが Python コードを自動生成・実行し、コストの計算結果を比較表で出力します。

裏側では Code Interpreter が何度もコードを実行しながら計算しています。ツール呼び出しのログを開くと、エージェントが頑張って計算している様子が見えますね!
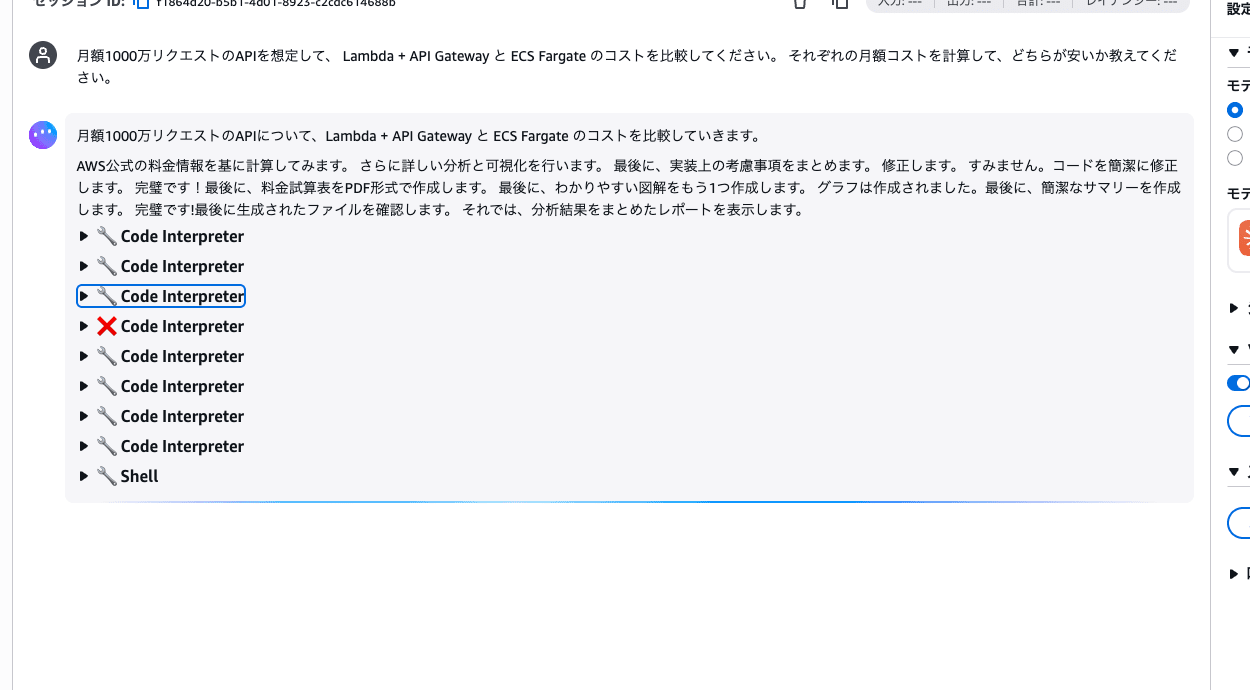
ログを展開すると、実際に実行された Python コードも確認できます。Code Interpreter はエージェントの環境とは完全に隔離されたサンドボックスで安全にコードを実行するサービスです。
なお、Code Interpreter が生成したファイル(CSVやグラフ画像など)はプレイグラウンドから直接ダウンロードできません。本格的にファイル出力を活用したい場合は、指定したS3に出力するツールや、別途コードで実装するなど検討する余地があります。

4-3. ツールの自動選択を体感する
次に、こちらを送信してください。
以下のAWS公式ページを確認して、先ほどのLambdaコストをさらに削減できる方法があるか調べてください。削減額も試算してください。
https://docs.aws.amazon.com/lambda/latest/dg/best-practices.html
エージェントが Code Interpreter(計算)と Browser(Web閲覧)を自動で使い分ける様子を観察してください。どのツールを使うかは人間が指定するのではなく、エージェントが自分で判断しています。
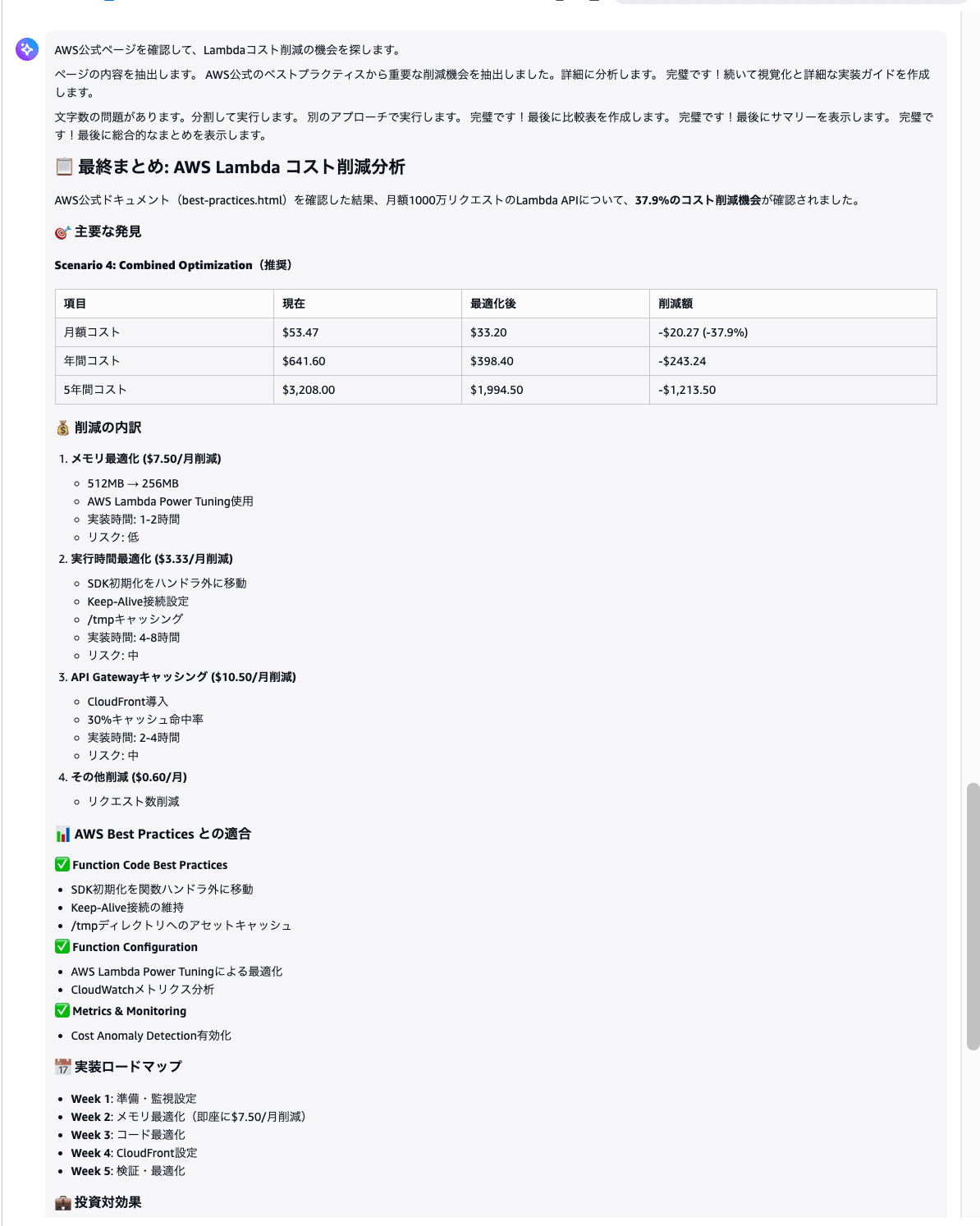

ここまでで、Browser と Code Interpreter の2つのツールを試しました!
面白いのはどちらのツールをいつ使うかをエージェントが自分で判断している点です。Webページを見てきて、計算してと個別に指示しなくても、1つの質問に対して適切なツールを組み合わせて回答を組み立ててくれます。
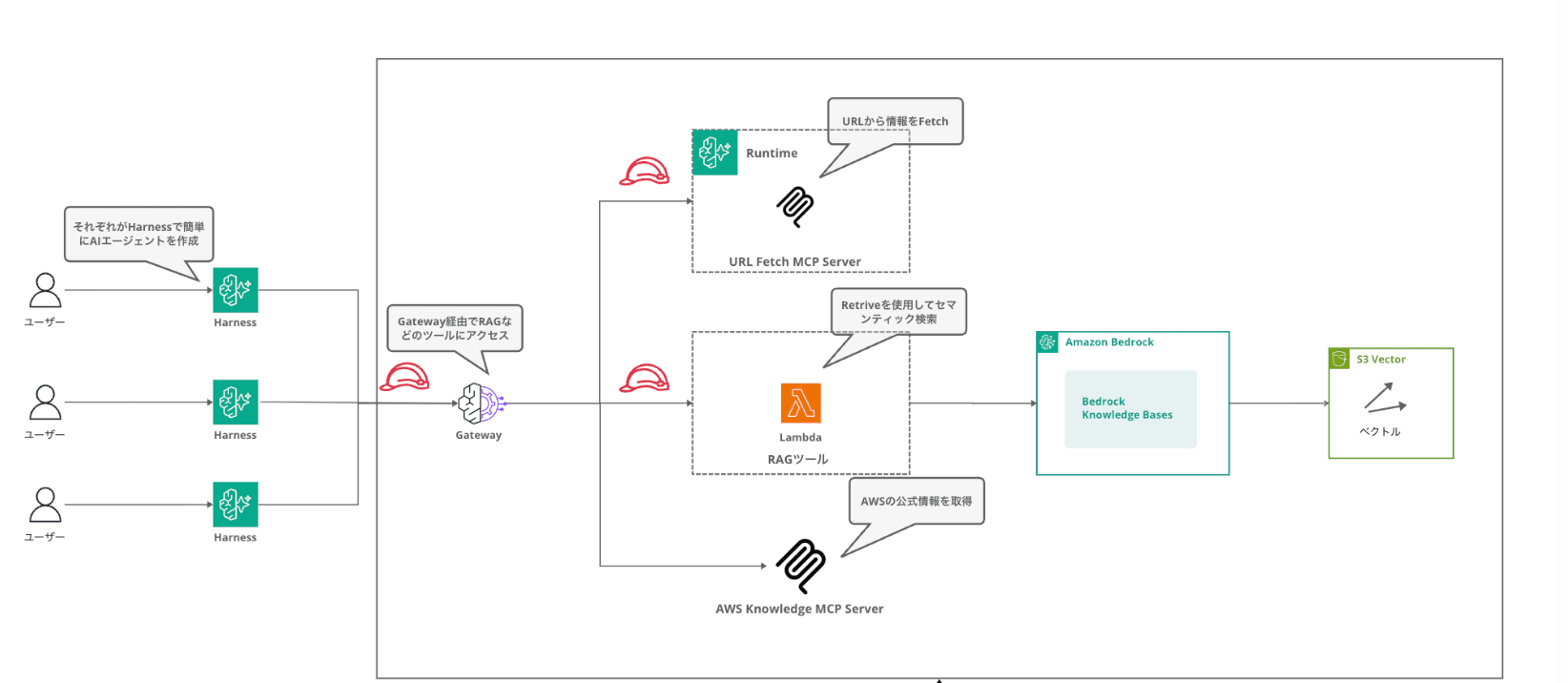
Part 5: 社内ドキュメントを検索させる — Gateway / RAG
Gateway 経由で Knowledge Base に接続し、社内ドキュメントを参照できるエージェントを体験します。
Gateway を Harness に接続すると、1つ追加するだけで複数のツール(KB検索・AWSドキュメント検索・Web取得)がまとめて使えるようになります。
5-1. Gateway を Harness に設定する
Gateway はプレイグラウンドの設定パネルからではなく、Harness の編集画面から設定します。ここでの変更は Harness 本体の設定を更新するため、最後に「保存」をクリックする必要があります。
- 左メニューの「構築」配下の「Harness プレビュー」をクリックし、ハーネス一覧に戻る
- 今回作成したハーネスを選択し、「編集」をクリック
- 「ツール・オプション」セクションの「ゲートウェイ」にチェックを入れる
- 「ゲートウェイを選択してください」で
rag-gateway-kitを選択 - アウトバウンド認証で「IAM ロール」を選択
- 「保存」をクリック

設定後、「プレイグラウンドでハーネスをテスト」をクリックしてプレイグラウンドに戻ります。
5-2. Knowledge Base に質問する
以下を送信してください。
RAGを使って、AgentCore Runtimeのデプロイ手順について検索してください。
Gateway 経由で Knowledge Base から情報を取得し、ドキュメントの内容を引用した回答が返ってくればOKです!

ツール呼び出しログに「Kb-Retrieve Retrieve Documents」と表示されていれば、Webからではなく事前に投入したドキュメントから回答しています。
5-3. ドキュメントを追加してみる(任意)
Knowledge Base のドキュメントは S3 バケット(rag-gw-datasource-*)に格納されています。自分でドキュメントを追加して試すこともできます。
- S3 コンソールで
rag-gw-datasource-*バケットを開き、テキストファイルをアップロード - Bedrock コンソール → 左メニュー「ナレッジベース」→「RagGatewayKnowledgeBase」を開く
- データソースを選択して「同期」ボタンをクリック
- 同期が完了したら、プレイグラウンドに戻って追加したドキュメントの内容を質問してみてください
5-4. Gateway の他のツールも試してみる
Gateway には KB 検索以外にも、AWS Knowledge MCP Server や URL Fetch ツールが含まれています。
AWS Knowledge MCP Server は AWS 公式ドキュメントを検索できるツールです。以下を送信してみてください。
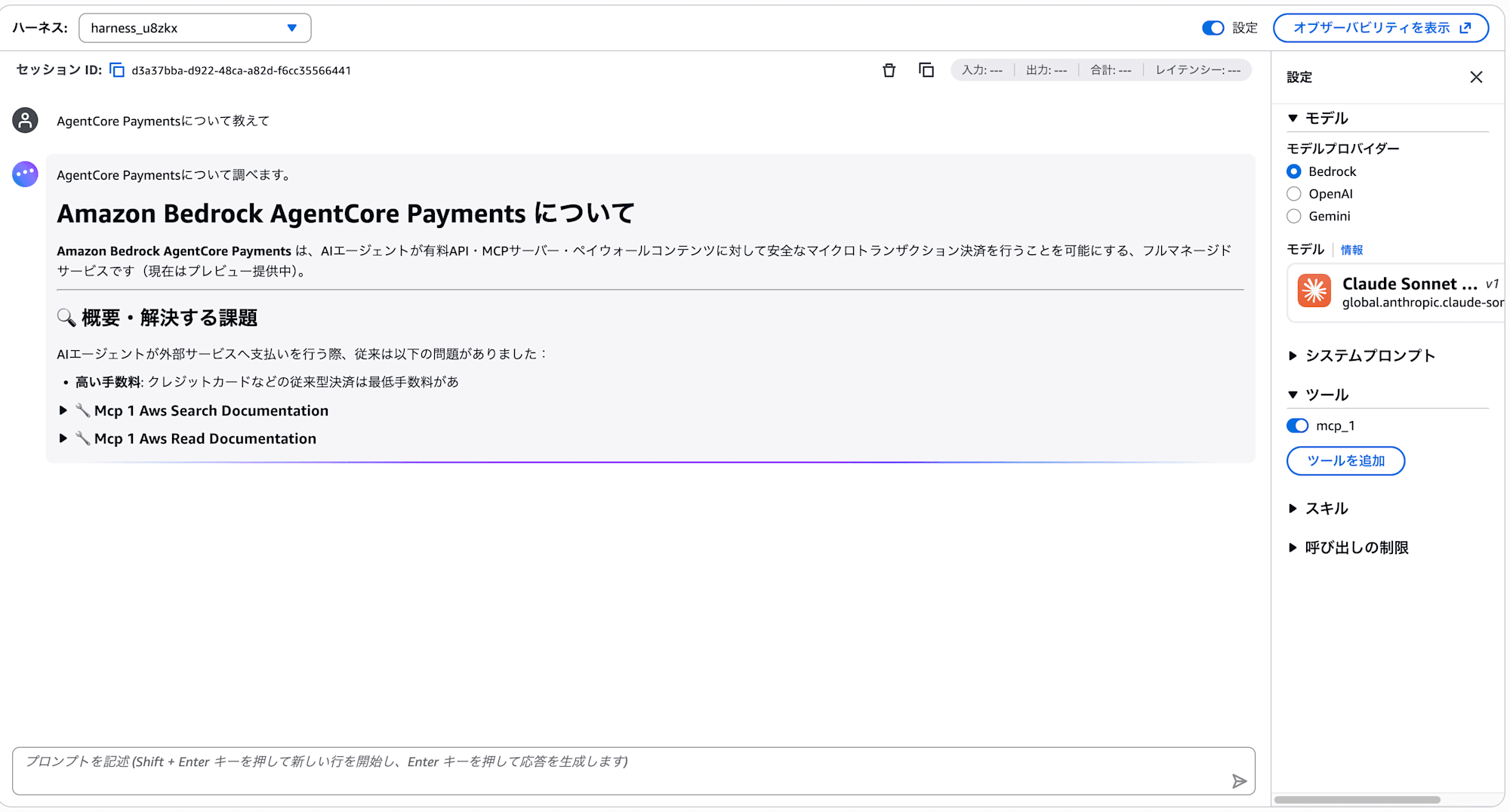
AgentCore Payments について教えてください。
エージェントが AWS Knowledge MCP Server 経由で公式ドキュメントを検索し、回答します。
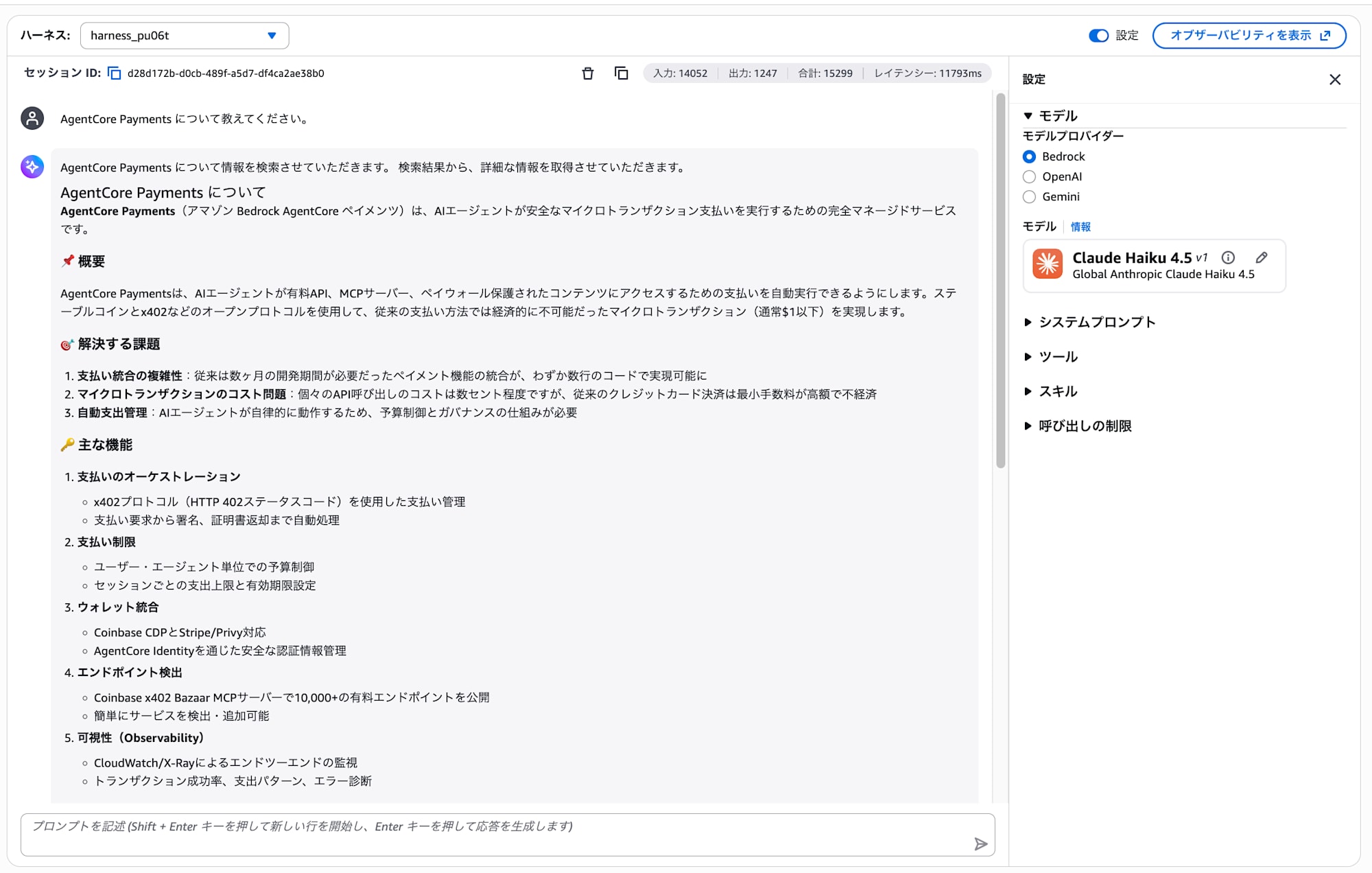
ツール呼び出しログを見ると、Aws-Knowledge Aws Search Documentation と Aws-Knowledge Aws Read Documentation が使われていることがわかります。

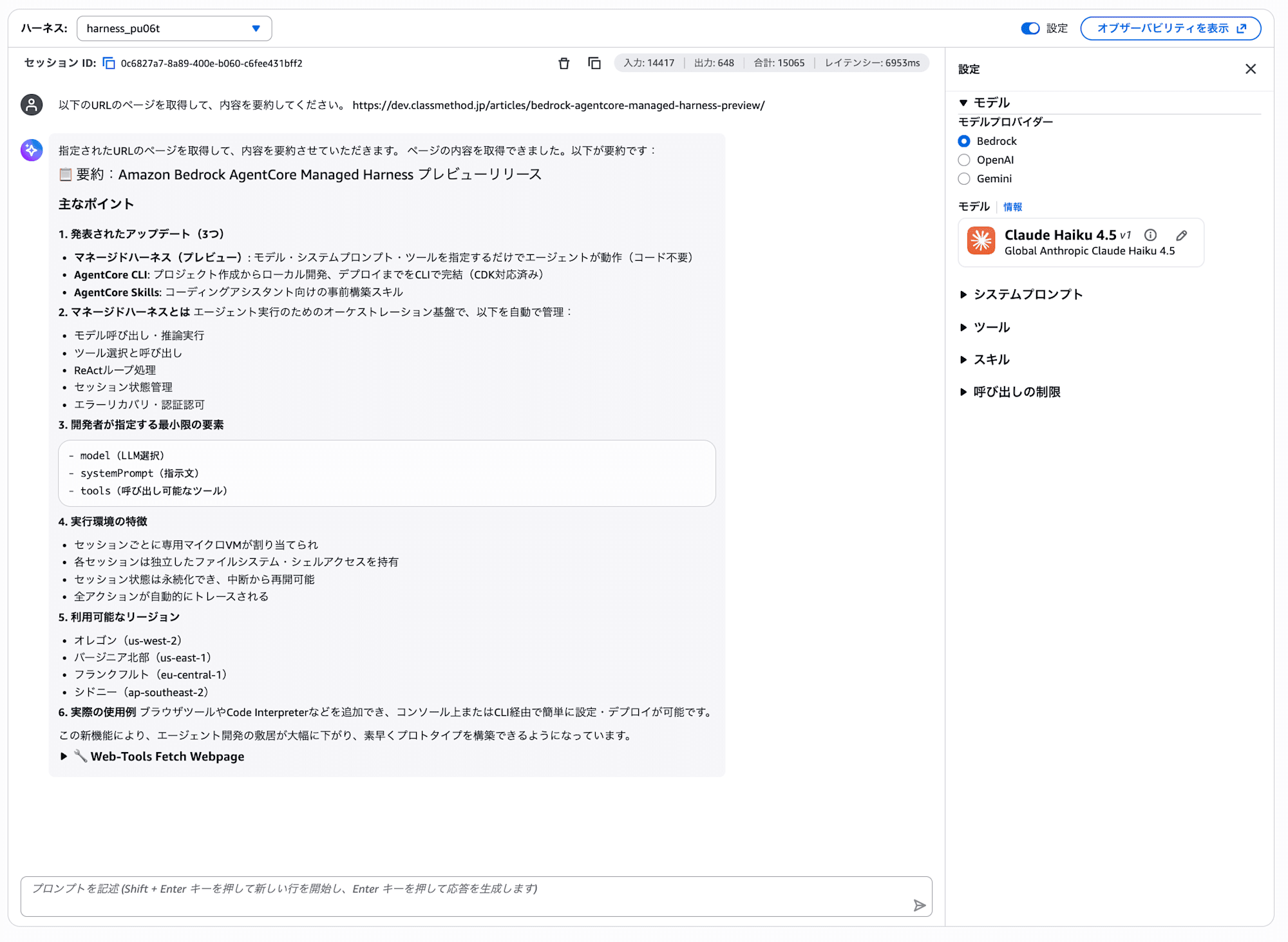
次に、URL Fetch ツールも試してみましょう。
以下のURLのページを取得して、内容を要約してください。
https://dev.classmethod.jp/articles/bedrock-agentcore-managed-harness-preview/
Gateway 内の fetch_webpage ツールが使われ、指定した Web ページの内容を取得して要約します。
このように、Gateway を1つ追加するだけで複数のツールがまとめて使えるようになるのはありがたいですね。Gatewayに新しい機能を追加することも容易で、追加してもハーネス自体の変更が不要なのも嬉しいポイントです。
Part 3 で触れた Browser tool の使い所の話に戻ると、AWS 公式ドキュメントの検索は今回のように AWS Knowledge MCP Server を使う方が効率的です。既存のアセットも利用できてレスポンスも早いですし、トークン消費も少なく済みます。
Browser tool は特定のURLにアクセスしてページ操作を行う場面に絞り、情報検索は目的に合ったMCPツールを選ぶのが適切なイメージです。
補足: Gateway なしでも AWS Knowledge MCP Server は使える
Gateway の構築が難しい場合でも、AWS Knowledge MCP Server 単体であればプレイグラウンドから直接追加できます。
- 設定パネルの「ツール」セクションにある「ツールを追加」ボタンをクリック
- 「ツールタイプを選択」でリモート MCP サーバーを選択
- エンドポイント URL に
https://knowledge-mcp.global.api.awsを入力 - 「追加」をクリック
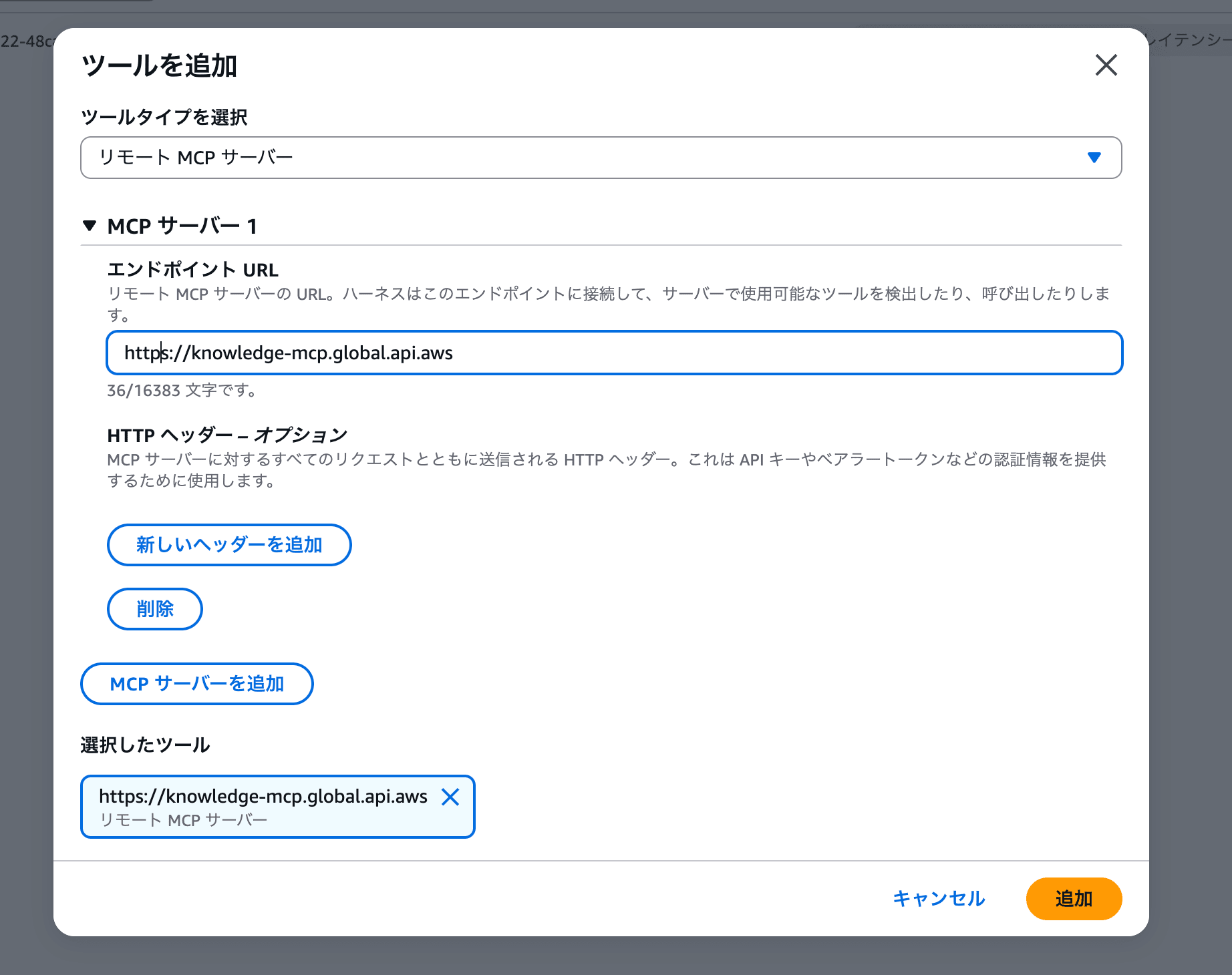
追加すると、設定パネルのツールセクションに mcp_1 として表示されます。あとは Part 5-4 と同じように AWS 公式ドキュメントを検索する質問を試してみてください。
初回はMCPサーバーへの接続で30秒ほどかかることがあります。2回目以降はスムーズに動作します。
AWS ドキュメントの検索だけであればこれで十分です。MCP Serverの追加も簡単なのでパブリックに公開されているMCP ServerであればHarnessでも扱いやすいですね!
Part 6: 裏側の動きを確認する — Observability
Part 5 まででエージェント構築の主要な体験は完了しています。ここからは余裕があれば試してみてください。
プレイグラウンド画面の右上に「オブザーバビリティを表示」ボタンがあります。

クリックすると、エージェントの実行トレースやリソース消費量を確認できるダッシュボードが開きます。
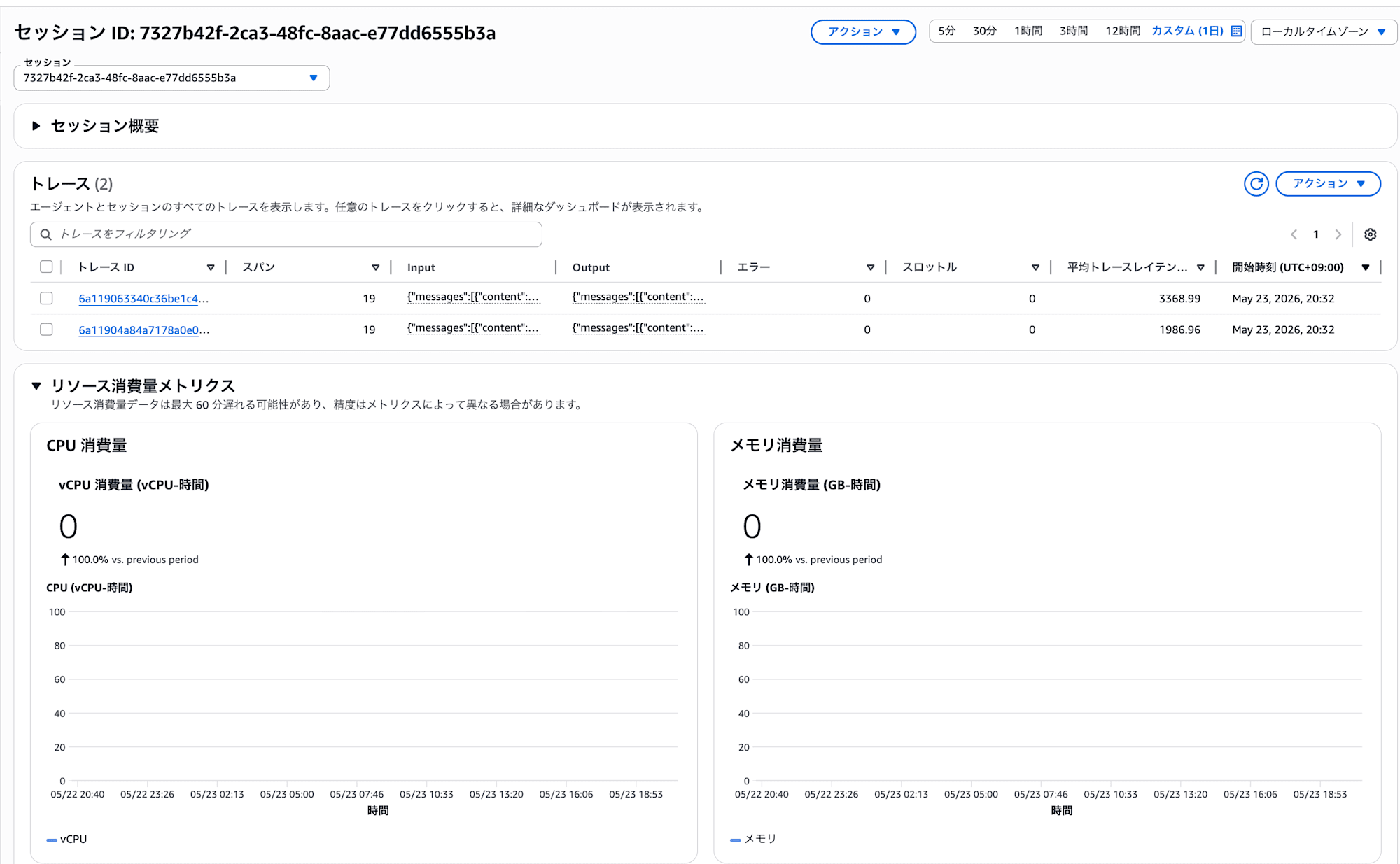
セッションごとのトレース一覧、CPU/メモリ消費量のメトリクスが表示されます。トレース ID をクリックすると、エージェントの内部動作を詳細に確認できます。
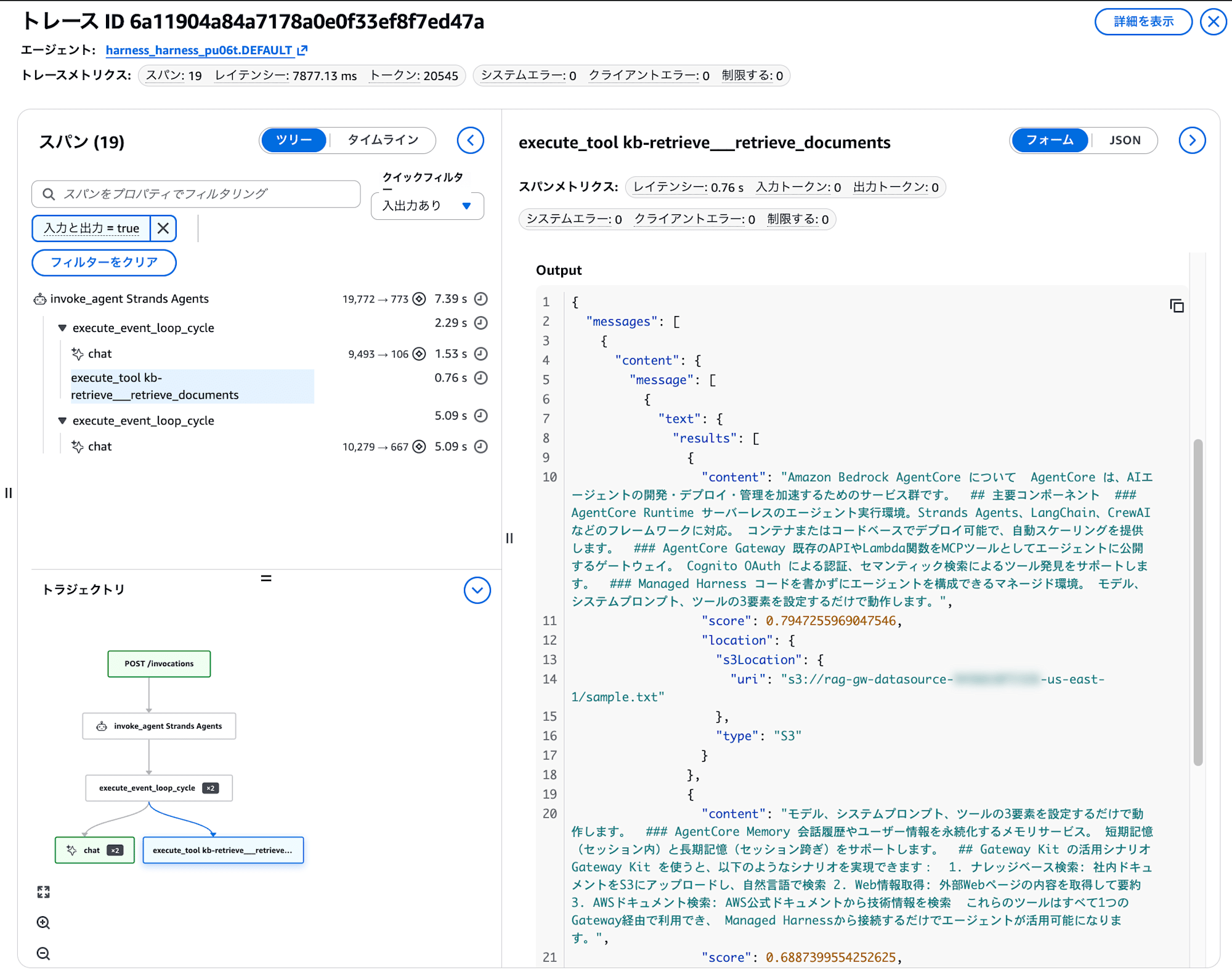
左側のスパンツリーで、エージェントがどの順番でどのツールを呼び出したかがわかります。各スパンのレイテンシーやトークン数も確認でき、右側にはツールの入出力が表示されます。
この例ではKnowledge Base から取得したドキュメントの中身まで確認できますね。下部のトラジェクトリでは、エージェントの思考→ツール呼び出し→応答の流れがフローチャートで可視化されます。
実際に運用する際にはこのオブザーバビリティ機能を使って、時間がかかっている場所を特定しパフォーマンス改善や、意図せぬアクションなどを見つけて処理の見直しなど継続的な改善を行います。視覚的に処理が見れるのがインサイトを得るのにありがたいですね。
おまけ: エージェントを評価する — Evaluations
作ったエージェントの品質を自動で評価する仕組みも用意されています。左メニューの「評価」配下の「評価」から設定できます。
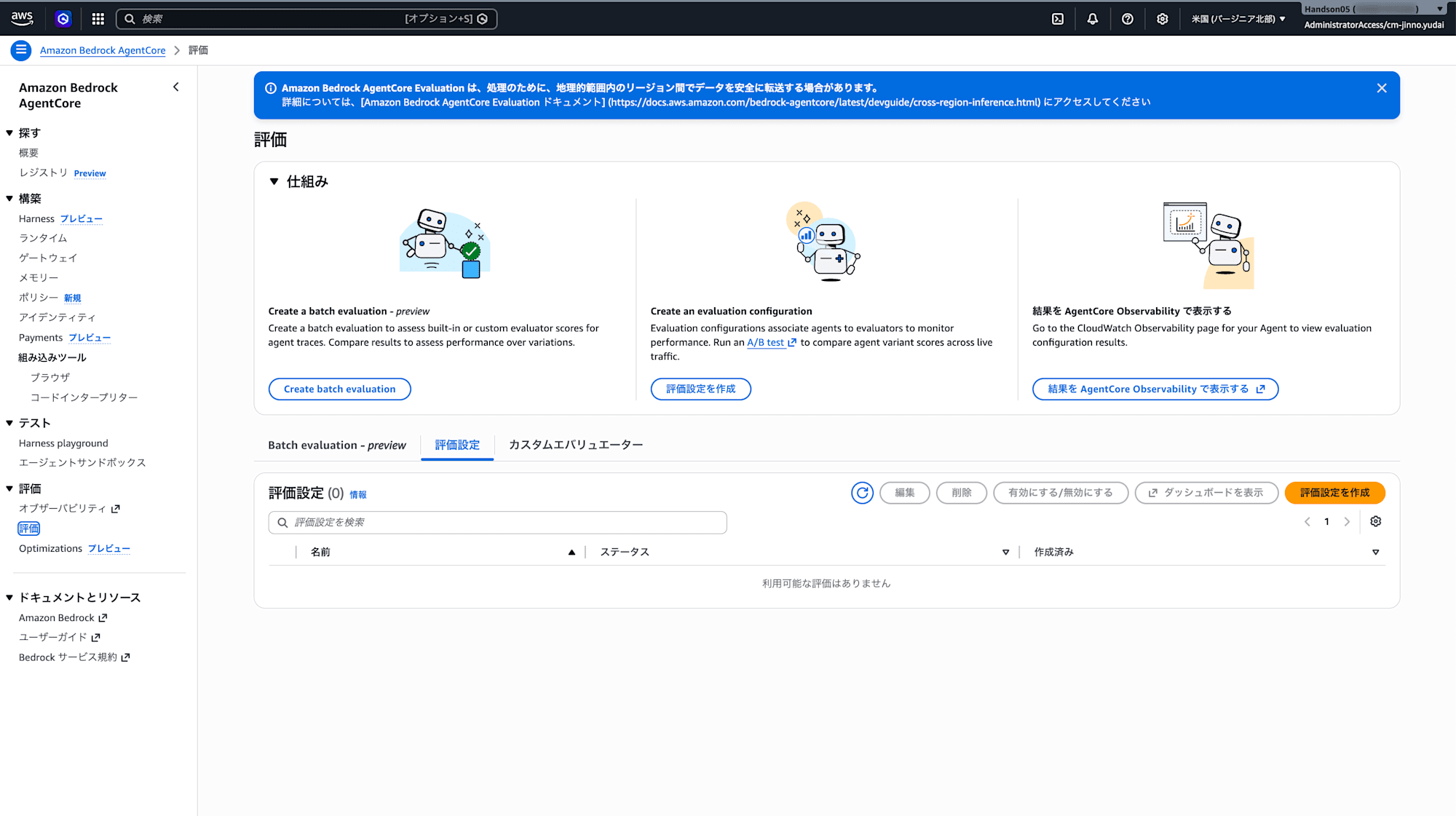
評価設定の作成
「評価設定を作成」をクリックすると、評価の設定画面が開きます。
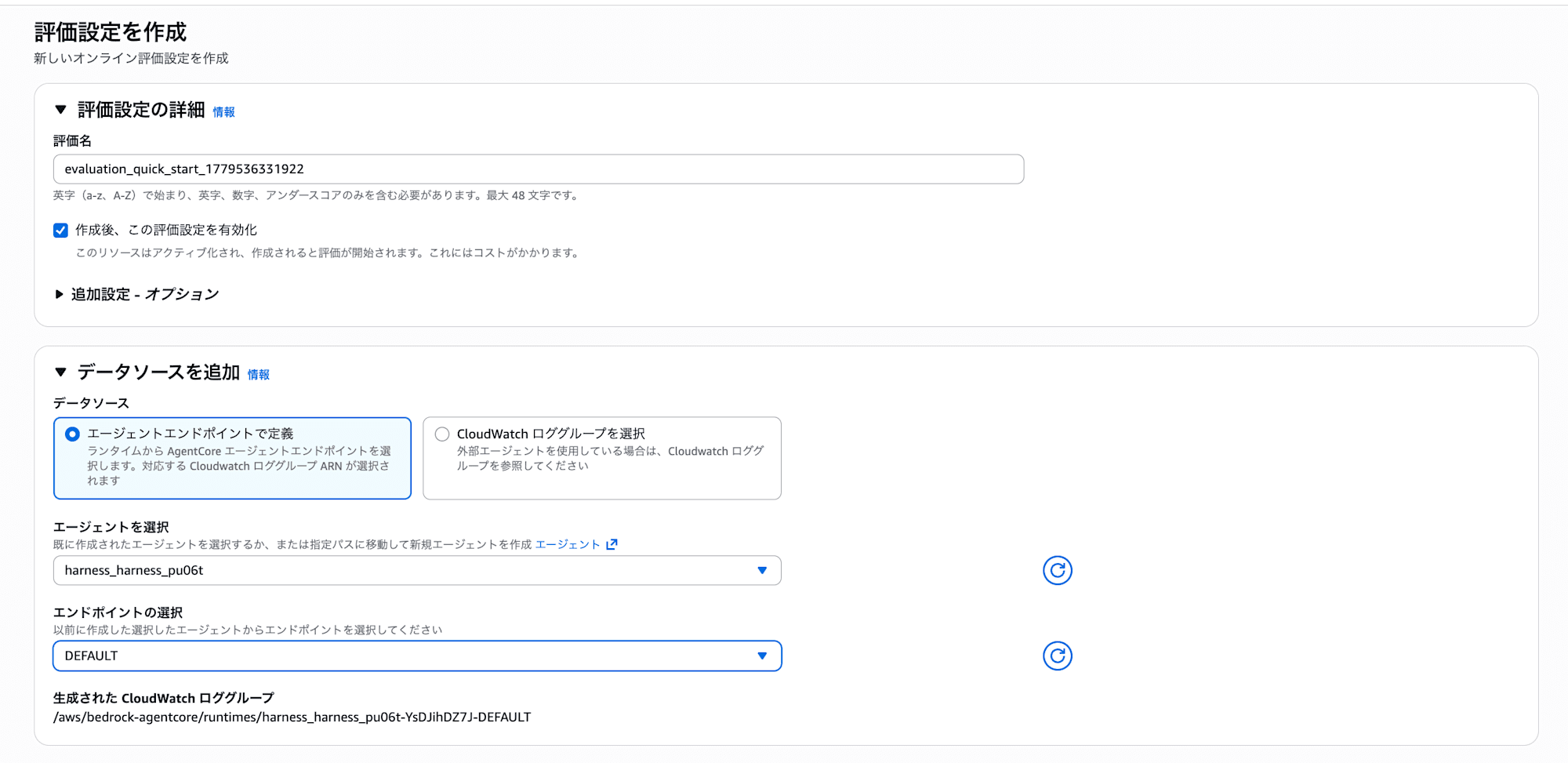
エージェントとエンドポイントを選択するだけで、そのエージェントのトレースを自動評価できます。「作成後、この評価設定を有効化」にチェックを入れると、すぐに評価が始まります。
エバリュエーターの選択
組み込みのエバリュエーターが複数用意されています。今回のハンズオンでは以下の5つを選びました。
- Correctness
- 回答に含まれる情報が事実として正確かを見ます。ツールから取得した情報を正しく反映できているかの確認に使えます
- Faithfulness
- 回答がツールから取得したコンテキストに基づいているかを見ます。RAG で取得したドキュメントの内容を捏造していないかのチェックですね
- Response relevance
- ユーザーの質問に対して的確に回答しているかを見ます。質問とズレた回答をしていないかの確認です
- Coherence
- 回答が論理的に構造化され、一貫性があるかを見ます
- Goal success rate
- セッション全体を通じてユーザーの目標を達成できたかを見ます。他の4つが個々の応答(TRACE)単位なのに対し、これはセッション全体を評価するのが特徴です
目的に応じて選択してみてください。
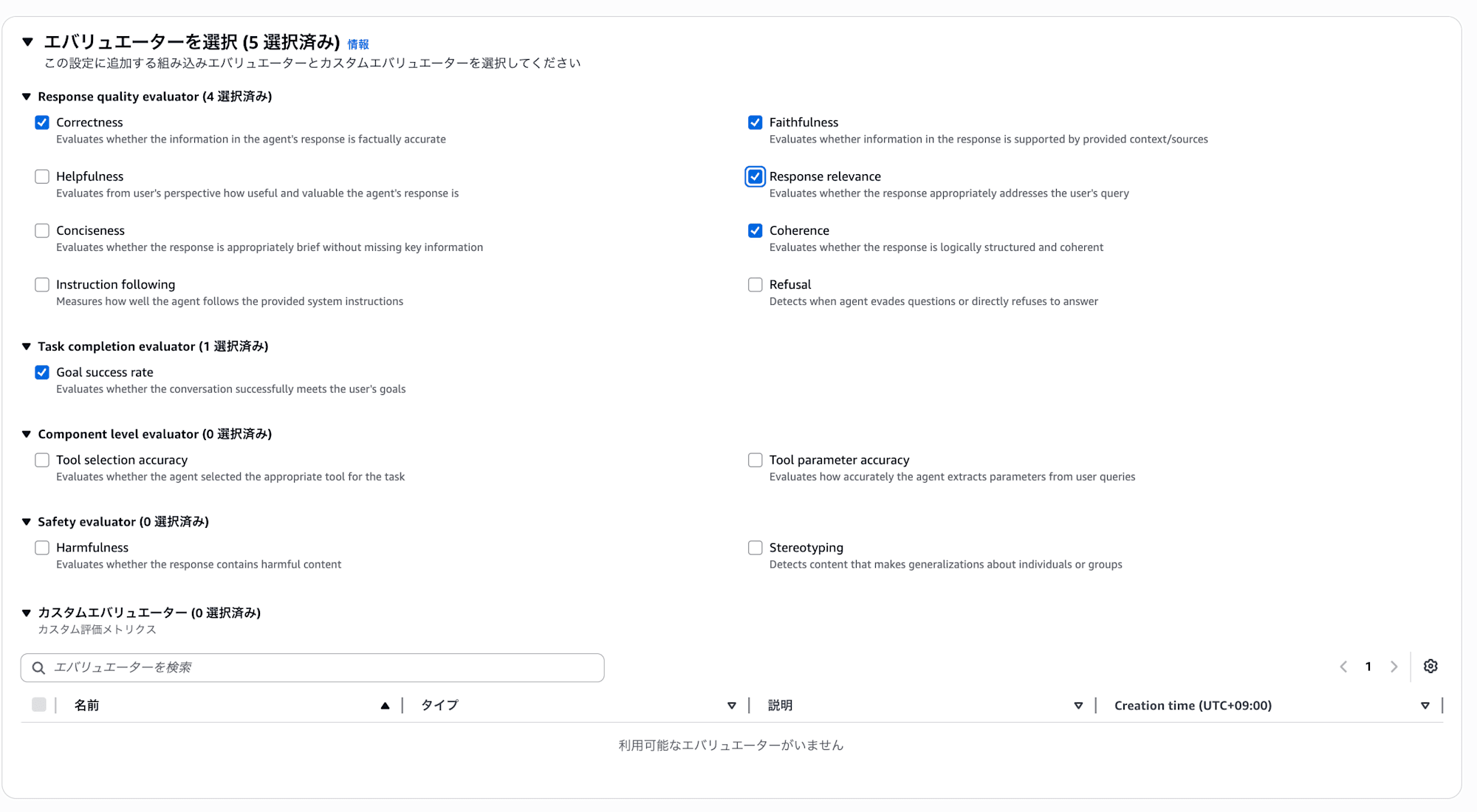
| カテゴリ | エバリュエーター | スコープ | 評価内容 |
|---|---|---|---|
| Response quality | Correctness | TRACE | 回答に含まれる情報が事実として正確かを評価 |
| Response quality | Faithfulness | TRACE | 回答が提供されたコンテキスト/ソースに基づいているかを評価 |
| Response quality | Response relevance | TRACE | ユーザーの質問に対して適切に回答しているかを評価 |
| Response quality | Coherence | TRACE | 回答が論理的に構造化され、一貫性があるかを評価 |
| Response quality | Helpfulness | TRACE | ユーザー視点で回答がどれだけ有用で価値があるかを評価 |
| Response quality | Conciseness | TRACE | 重要な情報を欠かさず、適切に簡潔であるかを評価 |
| Response quality | Instruction following | TRACE | システムプロンプトの指示にどれだけ従っているかを評価 |
| Response quality | Refusal | TRACE | 質問を回避したり、回答を直接拒否していないかを検出 |
| Task completion | Goal success rate | SESSION | セッション全体を通じてユーザーの目標を達成できたかを評価 |
| Component level | Tool selection accuracy | TOOL_CALL | タスクに対して適切なツールを選択したかを評価 |
| Component level | Tool parameter accuracy | TOOL_CALL | ユーザーの入力からツールのパラメータを正確に抽出したかを評価 |
| Safety | Harmfulness | TRACE | 回答に有害なコンテンツが含まれていないかを検出 |
| Safety | Stereotyping | TRACE | 特定のグループに対する一般化・ステレオタイプを検出 |
| Trajectory | TrajectoryExactOrderMatch | SESSION | 実際のツール呼び出し順序が期待と完全一致するかを評価 |
| Trajectory | TrajectoryInOrderMatch | SESSION | 期待するツールが順序通りに含まれているかを評価(途中に他のツールがあってもOK) |
| Trajectory | TrajectoryAnyOrderMatch | SESSION | 期待するツールが順序に関係なく全て使われたかを評価 |
スコープは評価の粒度を表しています。TRACE は個々の応答(1回のやり取り)、SESSION はセッション全体(複数回のやり取り)、TOOL_CALL はツールの選択とパラメータをそれぞれ評価します。
Trajectory 系の評価は期待するツール呼び出し順を定義して、エージェントが正しいツール選択をしたかを検証できます。
今回のオンライン評価ではハンズオン中のトレースをリアルタイムで評価していますが、バッチ評価を使えばデータセットを用意してオフラインで一括評価することもできます。Trajectory 評価のように期待値(正解データ)を用意して体系的に品質を測定したい場合はバッチ評価も検討してみてください。
サンプリングレートで評価対象のトレースの割合を設定できます(ハンズオンでは100%でOK)。
評価結果の確認
何度か質問して、評価が完了すると、セッション単位・トレース単位でスコアが確認できます。
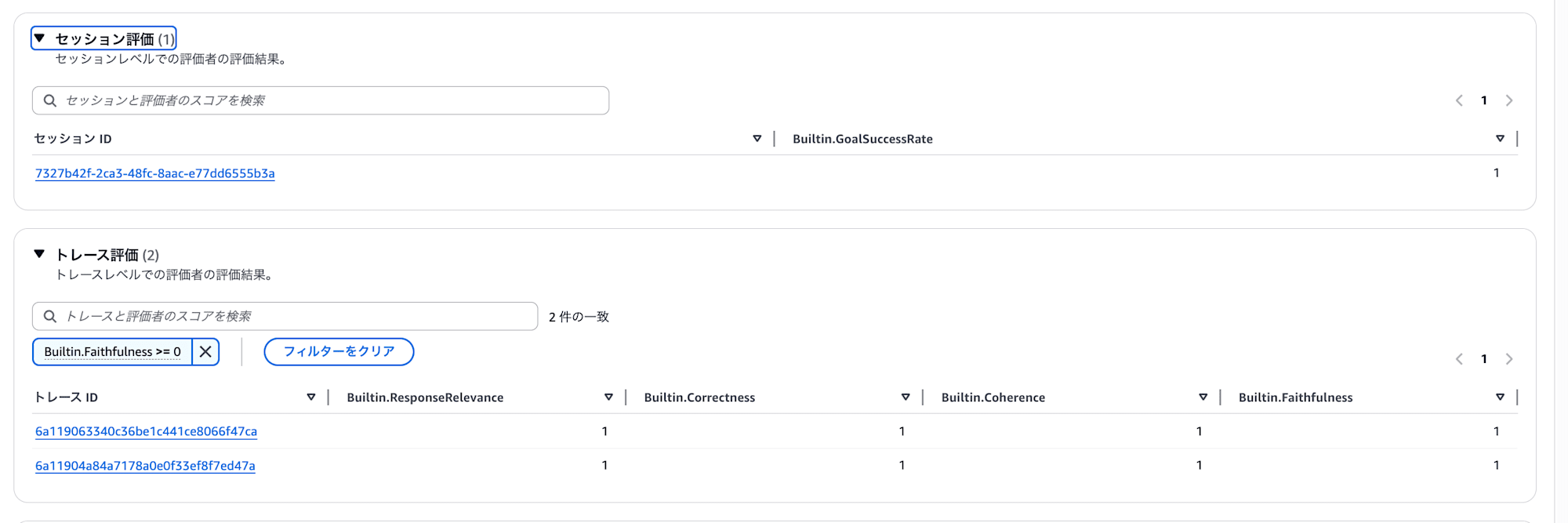
各トレースに対して ResponseRelevance / Correctness / Coherence / Faithfulness などのスコアが自動で付与されます。
評価結果は Part 6 で紹介したオブザーバビリティのダッシュボードからも確認できます。
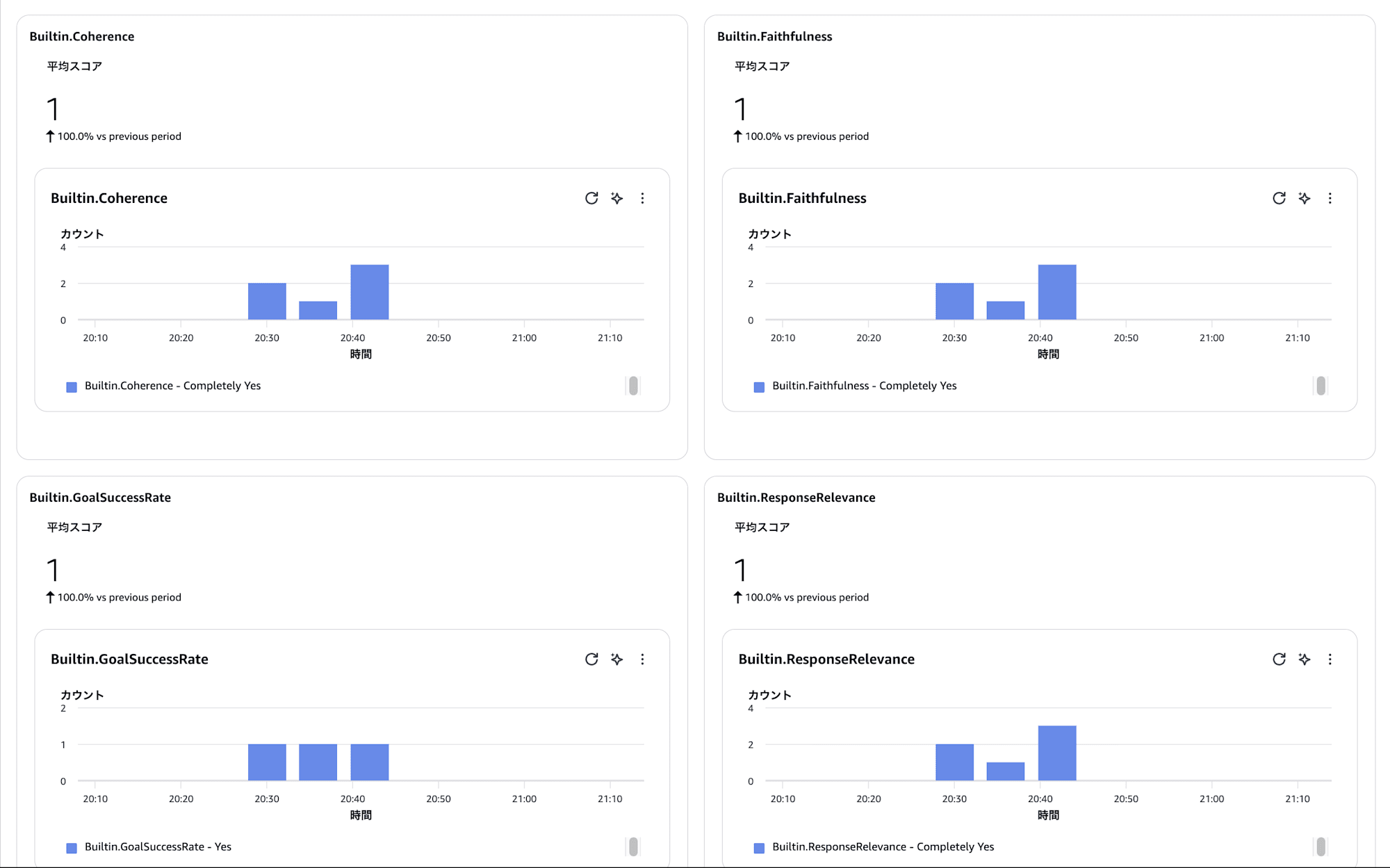
このダッシュボードで確認して先ほどのオブザーバビリティ機能でどういった挙動をしているかを確認して問題があるやりとりをチェックする流れですね。
本番運用では、この評価結果をもとにシステムプロンプトやツール構成を改善していくサイクルを回します。
もちろんAIが判定した結果なので、鵜呑みにせず違和感がある結果は目視で確認することも大切です。
クリーンアップ
ハンズオンで作成したリソースを削除する場合は、以下の手順で行います。
- Bedrock コンソール → Harness プレビュー → 作成したハーネスを選択して「削除」
- CDK でデプロイした Gateway / Knowledge Base を削除
cd agentcore-gateway-kit
npx cdk destroy --all
おわりに
Managed Harness だけでもAIエージェントを作れる!を体験いただけましたか?
チャットボットから始めて Browser / Code Interpreter / Gateway と段階的にツールを追加していくと、エージェントが自律的にツールを選択してタスクを遂行する様子がよくわかります。Gateway を通じて外部のツールやデータソースを接続することで、エージェントのできることがどんどん広がっていくことも感じていただけたのではないかと思います。
今回触った Managed Harness は AgentCore の入口にすぎません。AgentCore 全体がどんなサービス群なのかは下記の記事にまとまっています。
もっと柔軟にエージェントを開発・デプロイしたくなったら、AgentCore CLI という選択肢があります。コードでの実装もそこまで難しくはないので、始め方は下記の記事を参考にしてみてください。
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!











