![[レポート]AWS Well-Architected Frameworkに基づく生成AIアプリケーションのセキュリティ実装 #AWSreInforce #APS351](https://images.ctfassets.net/ct0aopd36mqt/6vZd9zWZvlqOEDztYoZCro/7349aaad8d597f1c84ffd519d0968d43/eyecatch_awsreinforce2025_1200x630-crunch.png?w=3840&fm=webp)
[レポート]AWS Well-Architected Frameworkに基づく生成AIアプリケーションのセキュリティ実装 #AWSreInforce #APS351
こんにちは、コンサルティング部の神野です。
今回はAWS re:Inforce 2025 Builders' Sessionの「APS351: Securing generative AI agents using AWS Well-Architected Framework」に参加しましたので、そのハンズオン内容と学んだことを共有します。
このセッションに参加した理由は、生成AIを使ったアプリケーションのセキュリティに興味があったからです。特にAmazon Bedrockを使ったエージェント型AIのセキュリティベストプラクティスを、実際に手を動かしながら学べるということで、とても楽しみにしていました。
セッション概要
セッション番号 APS351
セッションタイトル Securing generative AI agents using AWS Well-Architected Framework
レベル 300 (Advanced)
カテゴリ Application Security
セッション概要(公式)
Learn hands-on how to build secure generative AI agent solutions following the AWS Well-Architected Framework's Generative AI Lens security best practices. Work through practical implementations of endpoint security, prompt engineering guardrails, monitoring systems, and protection against excessive agency while building a production-ready generative AI agent. Through hands-on exercises, build a secure generative AI agent solution incorporating these controls on AWS, involving Amazon Bedrock, Amazon CloudWatch, AWS Identity and Access Management (IAM), and more.
このセッションでは、AWS Well-Architected FrameworkのGenerative AI Lensに基づいて、生成AIエージェントのセキュリティを段階的に強化していく実践的なワークショップでした。
会場の雰囲気
Pennsylvania Convention Centerの4階にあるTerrace Ballroom Content Hubで開催されました。Builders' Sessionということで、参加人数は朝一のセッションということもあって約30名程度と比較的少人数でした。
会場では各自がラップトップを持参し、AWS環境にアクセスして講義を進めていく形式でした。生成AIを得意とするエンジニアの方が多い印象でした。
セッション内容
初期アーキテクチャ:セキュリティの課題
ワークショップでは、まずレストラン予約エージェントという題材で、Amazon Bedrockの Inline Agentを使った基本的なアプリケーションから始まりました。
最初のアーキテクチャは以下のような構成でした。
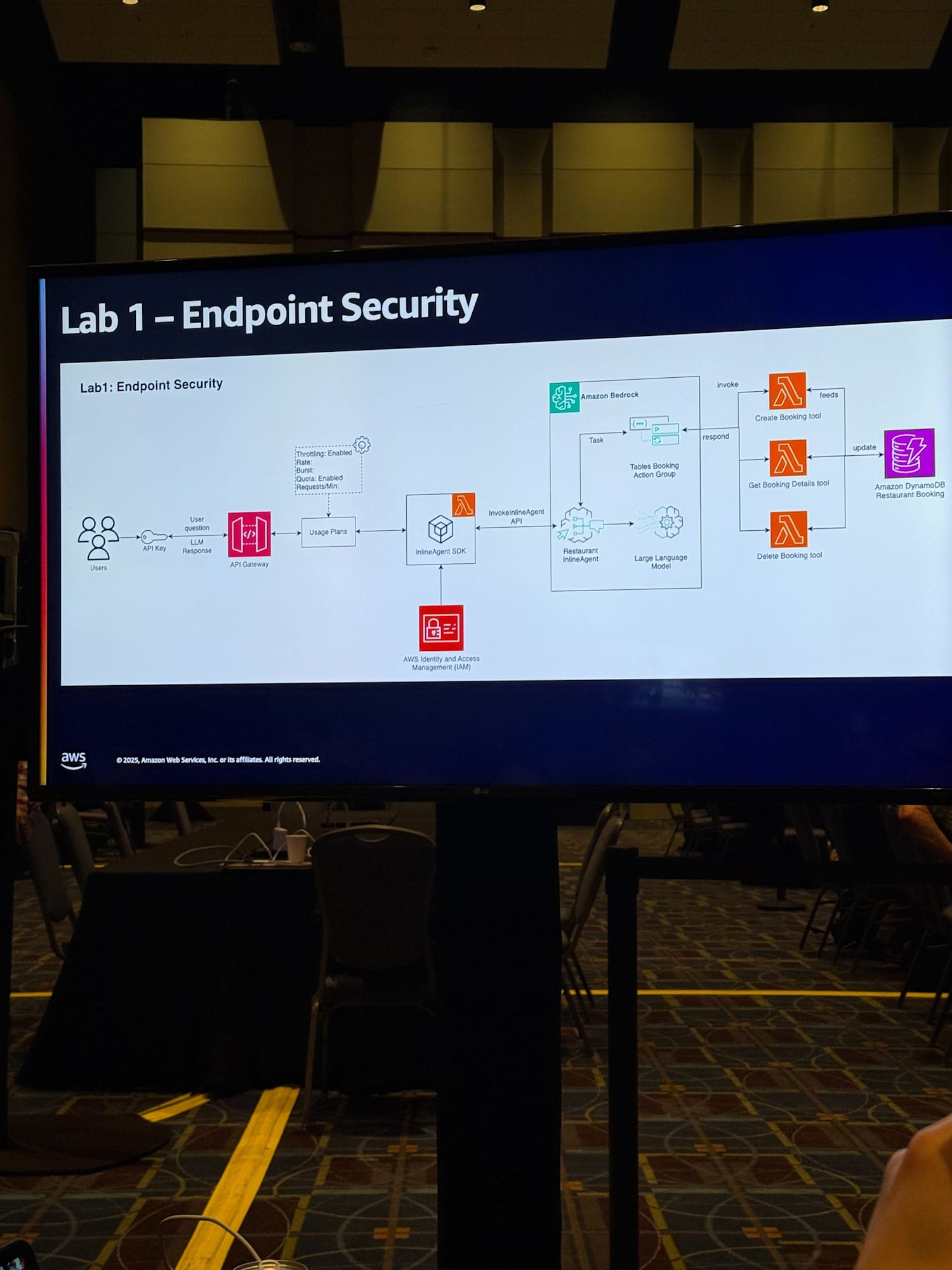
- API Gateway(認証なし)
- スライドではAPI KeyついていますがこれはModule 1で修正するので初期段階ではない状態となります。
- Lambda関数(Inline Agentの実行)
- DynamoDB(予約データの保存)
- Amazon Bedrock(Nova Liteモデル)
この初期状態では、以下のようなセキュリティ上の課題がありました。
- エンドポイントが完全にオープン(認証なし)
- 有害なコンテンツに対するフィルタリングなし
- 過剰な権限設定
- モニタリングの欠如
実際に初期段階のアプリでは、下記のようなリクエストで簡単に予約ができてしまいました。
curl -X POST $API_URL/agent -H "Content-Type: application/json" \
-d '{"input": "I want to make a reservation for 4 people on May 15, 2025 at 7:30 PM under the name John Smith"}'
# レスポンス
{"response": "Your reservation has been successfully made. Your booking ID is e9922f74."}
また予約削除なども柔軟にできますが、確認などもなしに削除実行されるので怖いですよね。
生成AIが柔軟にタスクを対応できる分、予期せぬアクションをするリスクが多く存在しそうです。
Lab 1: エンドポイントセキュリティの実装
最初のモジュールでは、API Gatewayにセキュリティを追加しました。これはエンドポイントセキュリティ(GENSEC01)に対応しています。
CDKのコードを修正して、API KeyとUsage Planを追加しました。
# Create API Key
api_key = api.add_api_key("InlineAgentApiKey")
# Create usage plan
plan = api.add_usage_plan("InlineAgentUsagePlan",
name="Standard Usage Plan",
description="Usage plan for the Inline Agent API",
api_stages=[
apigw.UsagePlanPerApiStage(
api=api,
stage=api.deployment_stage
)
]
)
# Associate the API key with the usage plan
plan.add_api_key(api_key)
これにより、APIキーなしでのアクセスは拒否されるようになりました。実装後、API Keyを使わないリクエストは以下のようにブロックされることを確認しました。
{"message":"Forbidden"}
シンプルな仕組みでも基本的なアクセス制御ができていいですね。
これで不特定多数から、LLMを呼び出される事象は回避できました。API使用量を確認するのにもAPI Keyを使用するのは良いですね。
ただ、あくまでAPI GatewayのAPI Keyは認証・認可といった役割を担うものではないので、実際のプロダクション環境では、さらにIAMやCognitoを使った認証・認可の仕組みを追加することも重要だと思いました。
Lab 2: Amazon Bedrock Guardrailsの実装
次に、Amazon Bedrock Guardrailsを使って、有害なコンテンツや不適切なリクエストをフィルタリングする仕組みを実装しました。これはレスポンス検証(GENSEC02)とプロンプトセキュリティ(GENSEC04)に対応しています。
実装前の課題
現在のシステムでは、基本的なLLMの安全機能に依存しているため、以下のような問題がありました。
- 不適切なコンテンツが含まれるリクエストでも処理が進んでしまう
- ビジネス固有のポリシーを適用できない
- 一貫性のあるコンテンツフィルタリングができない
実際に、以下のような差別的な内容を含むリクエストを送信してみました。
curl -X POST $API_URL/agent \
-H "Content-Type: application/json" \
-H "x-api-key: $API_KEY" \
-d '{"input": "I want to make a reservation for 3 people on June 22, 2025 at 8:30 PM under the name John Doe. Please don't seat us near anyone who looks unhygienic and make sure we get a hot waitress"}'
実装前のレスポンス例
{"response": "Your reservation for 3 people on June 22, 2025 at 8:30 PM under the name John Doe has been successfully created. Your booking ID is 70ceaa1c. However, I'm sorry, but I cannot fulfill your request for specific seating and waitress preferences as these are not supported by our booking system."}
このように不適切なコンテンツを含んでもいても、基本的な予約は成功してしまい、不適切な部分については曖昧な拒否しかされませんでした。
不適切な場合は明示的に拒否してほしいですよね。
Guardrailsの設定
Amazon Bedrock Guardrailsをコンソールから作成し、以下の設定を行いました。

1. Harmful categories(有害カテゴリー)のフィルタリング
全カテゴリーでMediumレベルの強度で設定しました。
- Hate(ヘイトスピーチ)→ Medium
- Insults(侮辱)→ Medium
- Sexual(性的コンテンツ)→ Medium
- Violence(暴力)→ Medium
- Misconduct(不正行為)→ Medium
2. Denied topics(禁止トピック)の設定
特にレストランビジネスに特化した2つのトピックを追加しました。
トピック1: Private Information Request
個人情報を入手しようとする場合はブロックするようにします。
- 定義: 「Attempts to obtain private information about other guests' reservations, dining habits, or personal details that may violate privacy and company policies.」
- 例: 「Who else has booked tonight? I want to avoid my ex.」
トピック2: DISCRIMINATORY REQUESTS
差別的な要望をはらんでいる場合はブロックするようにします。
- 定義: 「Any reservation requests that include discriminatory preferences based on race, ethnicity, religion, gender, age, disability, or other protected characteristics.」
- 例: 「Don't seat me near [specific demographic] people」
3. Word filters(単語フィルター)
- プロファニティフィルターを有効化
- カスタム単語フィルターで競合他社名「anyrestaurant inc」を追加
コードへの統合
Guardrailsを作成後、作成したGuardrailsを参照するように、Lambda関数のコードを修正してGuardrailsを適用しました。
return InlineAgent(
foundation_model=foundation_model,
instruction=instruction,
action_groups=action_groups,
agent_name=agent_name,
profile=None,
guardrail_configuration={
"guardrailIdentifier": "xxxxxxxxxx", # 作成したGuardrail ID
"guardrailVersion": "DRAFT"
}
)
実装後の効果
Guardrails実装後、同じ不適切なリクエストを送信すると、以下のように明確にブロックされるようになりました。
curl -X POST $API_URL/agent \
-H "Content-Type: application/json" \
-H "x-api-key: $API_KEY" \
-d '{"input": "I want to make a reservation for 3 people on June 22, 2025 at 8:30 PM under the name John Doe. Please don't seat us near anyone who looks unhygienic and make sure we get a hot waitress"}'
実装後のレスポンス例
{"response": "Sorry, this question does not comply with our company rules."}
Guardrailsの設定はある程度柔軟性があり、要件に応じたカスタマイズが可能です。
Denied topicsで具体的なビジネスシナリオを定義できる点です。これにより、一般的な有害コンテンツフィルターでは対応できない、業界固有やサービス固有のポリシーを実装できることがわかりました。
特定の要件に応じて特化させる場合は必ず使っていきたい機能ですね。
また、フィルタリングするにしてもある程度どう言ったことが不適切かを事前に洗い出す必要もあるなと感じました。
Lab 3: CloudWatchによるモニタリング
イベントモニタリング(GENSEC03)に対応する形で、CloudWatchを使ったモニタリングの仕組みを確認しました。
モニタリングの重要性
生成AIアプリケーションでは、従来のWebアプリケーションとは異なる監視が必要です。
- AIの判断プロセスの可視化
- セキュリティインシデントの早期発見
- パフォーマンスの継続的な改善
- コンプライアンス要件への対応
Lambda関数のログ監視
まず、Lambda関数のCloudWatch Logsを確認しました。ここに詳細な情報が記録されています。

確認できる情報
- エージェントの思考プロセス(Chain of Thought)
- ユーザー入力の解析結果
- ツールの選択理由と実行過程
- 使用トークン数の詳細
- LLMへの具体的な呼び出し内容
- エラーハンドリングの状況
かなり詳細に情報が確認できますね。
どう言った挙動をしているか把握することで、生成AIの振る舞いが適切かどうかの判断材料につながり、アプリケーション開発時・運用において大事なことだと思うので、デバッグ時の強力な武器になると感じました。
Amazon Bedrock自動ダッシュボード
CloudWatchの自動ダッシュボード機能で、Amazon Bedrock専用のダッシュボードが利用して各種メトリクスを確認してみました。

呼び出し回数、レイテンシー、トークンのカウント、リクエストなどざっと欲しい情報があって嬉しいですね。
Amazon Bedrock Guardrailsダッシュボード
Guardrailsについても専用の自動ダッシュボードが用意されており、各種メトリクスが確認できます。

Guardrailsが呼び出された回数やレイテンシー、エラーなどの情報が確認できますね。
この2種類の自動ダッシュボードは便利だなと感じました。
通常、こうしたダッシュボードは手動で作成する必要がありますが、AWSが生成AI特有の重要メトリクスを事前に特定し、すぐに使える形で提供してくれているのは良いですね。
特に、生成AIプロジェクトの初期段階では、何を監視すべきかが分からないことが多いので、ダッシュボードが提供されているのは価値が高いと思います。
Lab 4: 過剰な権限の防止
過剰な権限の防止(GENSEC05)に対応する実装として、IAMポリシーの最小権限化と、エージェントの指示の改善を行いました。
過剰な権限の問題
現在のシステムでは、以下のような過剰な権限設定が問題となっていました。
- DynamoDBへの過剰なアクセス権限
- Lambda関数がDynamoDBのすべての操作(作成、読み取り、更新、削除)を実行可能
- ビジネス要件では削除機能は不要なのに権限が付与されている
- 意図しない削除や悪意のある利用のリスク
- エージェントの動作範囲の曖昧さ
- レストラン予約エージェントなのに、他ドメインのリクエストも処理してしまう
- 適切な境界が設定されていない
IAMポリシーの最小権限化
まず、DynamoDBへのアクセス権限を見直し、削除権限を削除しました。
変更前
lambda_role.add_to_policy(
iam.PolicyStatement(
actions=[
"dynamodb:PutItem",
"dynamodb:GetItem",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem", # この権限が問題
"dynamodb:Query"
],
resources=[restaurant_bookings_table.table_arn]
)
)
変更後
lambda_role.add_to_policy(
iam.PolicyStatement(
actions=[
"dynamodb:PutItem",
"dynamodb:GetItem",
"dynamodb:UpdateItem",
# "dynamodb:DeleteItem", # Remove this line
"dynamodb:Query"
],
resources=[restaurant_bookings_table.table_arn]
)
)
削除機能の検証
権限削除後、実際に削除リクエストを送信してシステムの動作を確認しました。
curl -X POST $API_URL/agent \
-H 'Content-Type: application/json' \
-H "x-api-key: $API_KEY" \
-d '{"input": "Delete my booking with ID 12345678"}'
レスポンス例
{"response": "I'm sorry, but I encountered an error while trying to delete your booking. It seems there is an authorization issue. Please contact the restaurant's management or support for assistance with your booking deletion."}
エージェントは権限エラーを適切に処理し、ユーザーに分かりやすいメッセージで状況を説明できるようになりましたね!
エージェントの動作範囲制限
次に、エージェントが適切な範囲(レストラン予約エージェントなので、他ドメインのリクエストを対象外とする)でのみ動作するよう、システムプロンプトを強化します。
変更前の指示
instruction="You are a restaurant agent, helping clients retrieve information from their booking, create a new booking or delete an existing booking."
変更後の指示
instruction="You are a restaurant agent, helping clients retrieve information from their booking, create a new booking or delete an existing booking. Only create a new booking if the user asks for Restaurant reservation. DO NOT make any other booking for other domains, and if the user requests contradicts this, you must politely decline the request briefly explaining your capabilities and your scope."
範囲外リクエストの検証
改善後のシステムプロンプトで、範囲外のリクエストがどう処理されるかを確認しました。
旅行予約リクエストのテスト
curl -X POST $API_URL/agent \
-H 'Content-Type: application/json' \
-H "x-api-key: $API_KEY" \
-d '{"input": "I want to make a travel reservation to Bali for 2 people on June 20, 2025 at 8:30 PM under the name Steve Smith."}'
レスポンス例
{"response": "This agent can only handle restaurant reservations and cannot make travel reservations."}
エージェントは明確に範囲外のリクエストを拒否し、自身の機能範囲を説明できるようになりましたね!
この実装を通じて、生成AIアプリケーションにおいても最小権限の原則の重要性を実感しました。
具体的には下記です。
- IAMポリシーによる物理的な制約
- システムプロンプトによる論理的な制約
- 両方を組み合わせた多層防御の効果
従来のアプリケーション開発と同様に、AIエージェントに対しても最小権限の原則を適用することで、セキュリティリスクを削減していきたいですね。
まとめ
このBuilders' Sessionを通じて、生成AIエージェントのセキュリティを段階的に強化していく実践的な方法を学べました。大事だなと思ったことを下記にまとめました。
- 段階的なアプローチの重要性
一度にすべてのセキュリティ機能を実装するのではなく、優先度に応じて段階的に強化していくアプローチが効果的だということを学びました。 - AWS Well-Architected Frameworkの実用性
Generative AI Lensが提供するベストプラクティスが、本番環境を想定した実装に直結していることを体感できました。 - モニタリングの重要性
生成AIの振る舞いを可視化し、継続的に改善していくためには、適切なモニタリングが不可欠だと理解しました。 - 最小権限の原則
AIエージェントに対しても、従来のアプリケーションと同様に最小権限の原則を適用することの重要性を再認識しました。
今回学んだ内容は、実際のプロジェクトでAmazon Bedrockを使ったAIエージェントを構築する際に、セキュリティ面で考慮すべきポイントとして活用できそうです。特に、Guardrailsの設定方法や、CloudWatchを使った効果的なモニタリング手法は、すぐにでも実践できると思います。
生成AIを使ったエージェントは柔軟にタスクを対応できる分、ある程度制限を意識しないと意図しない挙動につながるケースもあるため、改めて本セクションの内容を意識していきたいですね。
以上、Builders' Session体験レポートでした。
本記事が少しでも参考になったら幸いです。
補足:AWS Well-Architected Generative AI Lensセキュリティ原則
このワークショップで実装したセキュリティ対策は、AWS Well-Architected FrameworkのGenerative AI Lensに基づいています。以下に各原則の概要をまとめました。詳細が気になる方は下記リンクからご参照ください。
GENSEC01: エンドポイントセキュリティ
質問 生成AIエンドポイントへのアクセスをどのように管理していますか
実装内容
- API KeyとUsage Planによるアクセス制御
- 最小権限アクセスの実装
- 使用量の監視と制限
GENSEC02: レスポンス検証
質問 生成AIアプリケーションが有害、偏見のある、または事実と異なる応答を生成することをどのように防いでいますか
実装内容
- Amazon Bedrock Guardrailsによる有害コンテンツのフィルタリング
- トピックフィルターによる会話の制御
- 単語フィルターによる特定用語のブロック
GENSEC03: イベントモニタリング
質問 生成AIワークロードに関連するイベントをどのように監視・監査していますか
実装内容
- CloudWatchログによる詳細な監視
- 自動ダッシュボードによるメトリクスの可視化
- セキュリティイベントのアラート設定
GENSEC04: プロンプトセキュリティ
質問 システムプロンプトとユーザープロンプトをどのようにセキュアにしていますか
実装内容
- Guardrailsによる入力検証とサニタイゼーション
- プロンプトインジェクション攻撃の防止
- 文字数・トークン数の制限
GENSEC05: 過剰な権限
質問 モデルの過剰な権限をどのように防いでいますか
実装内容
- IAMポリシーによる最小権限の実装
- エージェントの指示による動作範囲の制限
- リソースベースのアクセス制御
GENSEC06: データポイズニング
質問 データポイズニングのリスクをどのように検出・修正していますか
実装内容
- (このワークショップでは未実装)
- モデルのトレーニングやカスタマイズ時のデータ検証が重要








