
Amazon ElastiCache for Valkey + Amazon Bedrock AgentCoreでセマンティックキャッシュを実装してみた
はじめに
こんにちは、チーズナンが大好きなコンサルティング部の神野(じんの)です。
もうかなり前のように感じますが、AWS re:Invent 2025で、「DAT451: Optimize gen AI apps with semantic caching in Amazon ElastiCache」というセッションを視聴しました。
このセッションではElastiCacheをキャッシュ層として活用し、生成AIアプリケーションのコストとレイテンシを削減する手法が紹介されていました。
セッションでは具体的な実装についてはブログを紹介しておりました。
今回はこのブログの内容をAgentCore、Strands Agents、ElastiCache for Valkeyで構築してみようと思い記事を書きました。ブログではLangChainで実装だった部分を私はStrands Agentsで書いてみました。
セマンティックキャッシュ
まずセマンティックキャッシュは、従来の完全一致ベースのキャッシュとは異なり、クエリの意味的な類似性に基づいてキャッシュを検索・再利用する手法です。
例えば、以下のような質問は意味的にはほぼ同じ内容ですが、文字だけ見ると少し違いますよね。
- VPNアプリをラップトップにインストールする方法を教えて
- 会社のVPNをセットアップする手順は?
従来のキャッシュでは文字列が完全に一致しないとヒットしませんでしたが、
セマンティックキャッシュではベクトル埋め込みを使用して類似性を判定するため、同じ回答を再利用できます。
処理の流れを図にすると以下のようになります。
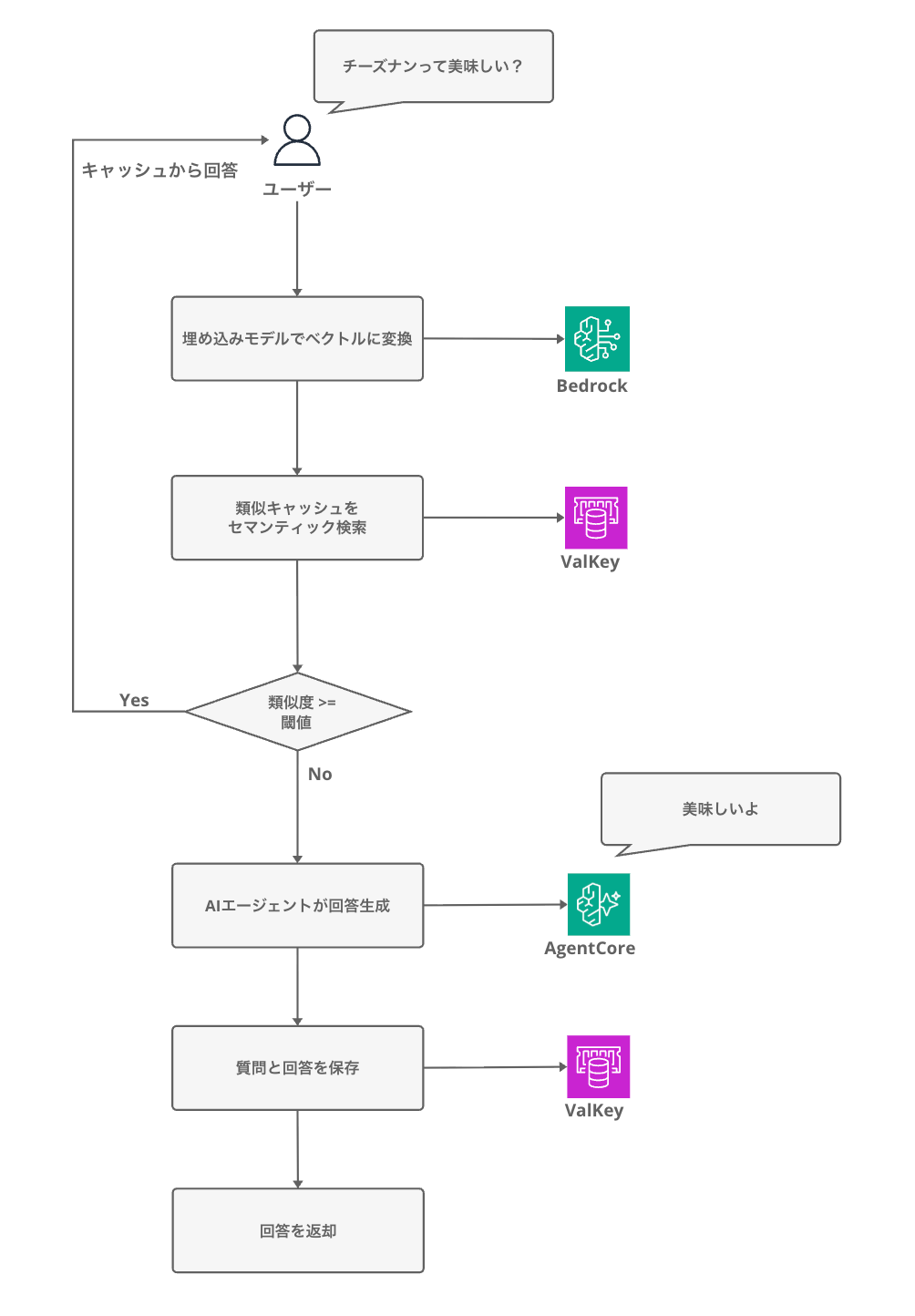
キャッシュヒット時はLLMを呼び出さずに済むため、レイテンシとコストの両方を削減できるという仕組みですね。
AWSブログによると、セマンティックキャッシュを導入することで下記の効果が得られるとのことです。
確かにコストや、レイテンシはかなり違いますね。ここまでできるならすごい・・・
| メトリクス | ベースライン | キャッシュ有効時(閾値0.75) | 改善率 |
|---|---|---|---|
| 平均レイテンシ | 4.35秒 | 0.51秒 | 88% |
| 日次コスト | $49.5 | $6.8 | 86% |
| キャッシュヒット率 | - | 90.3% | - |
自分はこのセッションを聞くまではこういった概念があることさえあまり分かっていなかったので大変勉強になりました。
早速試してみたいと思います。
前提
使用環境
今回使用した環境は下記となります。
| ツール / ライブラリ | バージョン |
|---|---|
| AWS CDK | 2.232.1 |
| @aws-cdk/aws-bedrock-agentcore-alpha | 2.232.2-alpha.0 |
| Node.js | 25.x |
| Python | 3.12 |
| uv | 0.9.26 |
| strands-agents | 1.25.0 |
| bedrock-agentcore | 1.2.1 |
| valkey (Python client) | 6.1.1 |
| ElastiCache for Valkey (エンジン) | 8.2 |
| リージョン | us-west-2 |
アーキテクチャ
今回構築するアーキテクチャは以下の通りです。
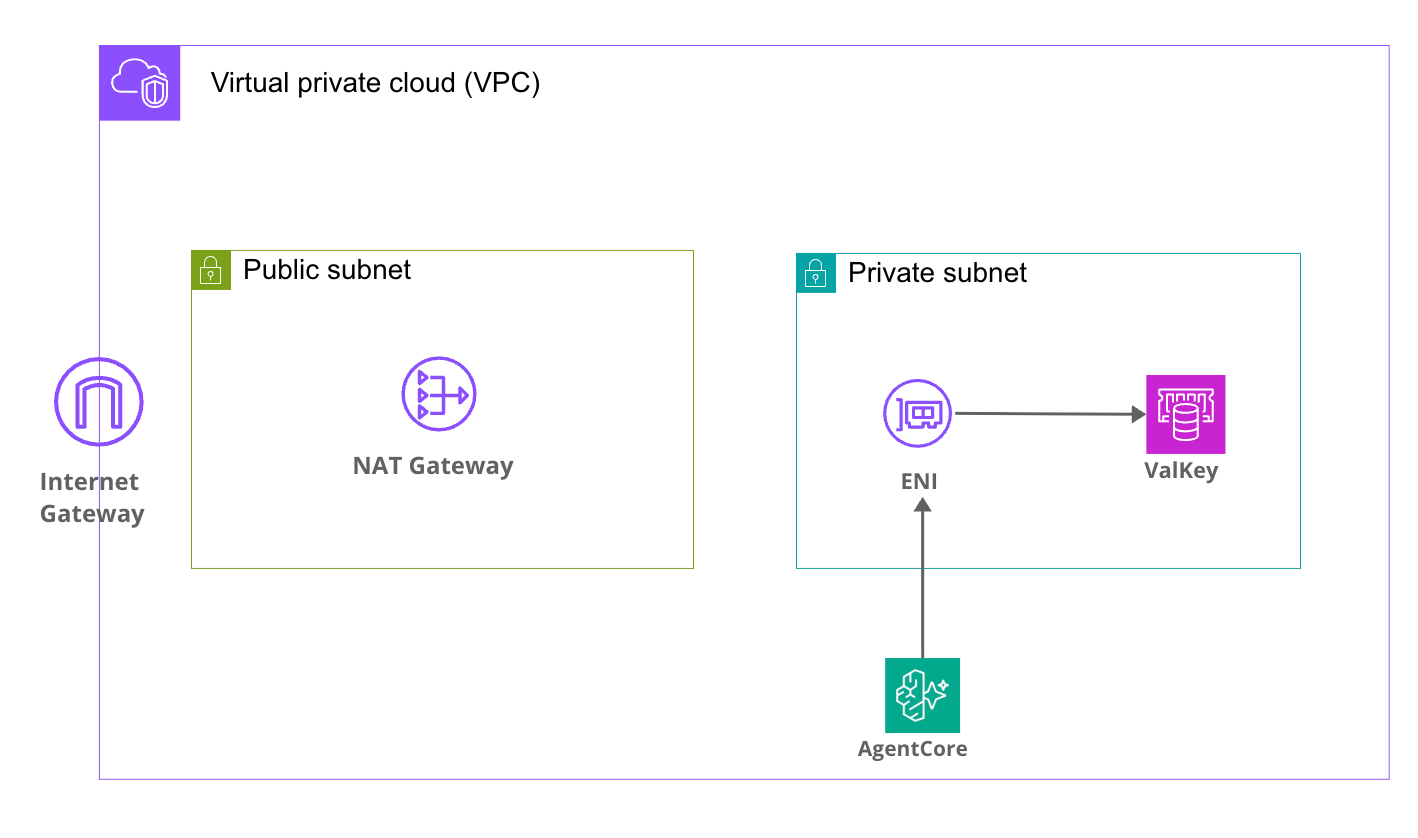
AgentCore RuntimeはVPCモードで動作し、ENIをPrivate Subnetに配置し、VPC内のValkeyと通信する簡易的な作りにしています。
AgentCoreからその他AWSリソース(Bedrockなど)に対してはNAT Gateway経由でアクセスする想定です。
実装
今回のサンプルコードは以下のGitHubリポジトリに公開しています。
リポジトリをクローンして依存関係をインストールします。
git clone https://github.com/yuu551/agentcore-elastic-cache-blog-sample.git
cd agentcore-elastic-cache-blog-sample
pnpm install
なお、あくまで検証目的のサンプルコードですので、本番環境でそのまま利用することは想定していません。
セキュリティ設定やエラーハンドリングなど、運用に必要な考慮事項は含まれていない場合がある点にご注意ください。
ElastiCacheはVPC内に作成する必要があります。
これに伴いAgentCore RuntimeもVPCモードで配置する必要があり、VPC・NAT Gateway・VPCエンドポイントなどのネットワークリソースが一式必要になります。
また、ElastiCache for Valkey ServerlessはVector Searchに対応していないので注意が必要です。今後のサポートに期待ですね。
エージェントの実装
セマンティックキャッシュのロジックを実装していきます。
エージェントフレームワークにはStrands Agentsを使用しています。
AWS公式ブログではLangChainやLangGraphの機能を使ってセマンティックキャッシュを実装していましたが、Strands Agentsにはそのような機能が組み込まれていないため、自分の理解を深めるためにもValkeyのベクトル検索コマンドを直接使って自前で実装しています。
まずは設定をまとめたConfigクラスです。環境変数から各種パラメータを読み込みます。
import os
from dataclasses import dataclass
@dataclass
class Config:
# Valkey 接続設定
valkey_host: str = os.getenv('VALKEY_HOST', 'localhost')
valkey_port: int = int(os.getenv('VALKEY_PORT', '6379'))
valkey_ssl: bool = os.getenv('VALKEY_SSL', 'true').lower() == 'true'
# Amazon Bedrock モデル設定
embedding_model_id: str = os.getenv('EMBEDDING_MODEL_ID', 'amazon.titan-embed-text-v2:0')
llm_model_id: str = os.getenv('LLM_MODEL_ID', 'us.anthropic.claude-haiku-4-5-20251001-v1:0')
# セマンティックキャッシュ設定
similarity_threshold: float = float(os.getenv('SIMILARITY_THRESHOLD', '0.8'))
# AWS / ベクトル検索設定
aws_region: str = os.getenv('AWS_REGION', 'us-west-2')
vector_dims: int = int(os.getenv('VECTOR_DIMS', '1024'))
次にセマンティックキャッシュの処理です。
Valkeyのベクトル検索機能を使ってキャッシュの検索・保存を行います。
Valkeyのベクトル検索コマンドは馴染みのない方も多いと思うので、少し丁寧に解説していきます。(私も全然馴染みがなかったです)
Valkey接続とインデックス作成
import json
import struct
import time
from hashlib import md5
from typing import Optional
import boto3
import valkey
from .config import Config
class SemanticCache:
INDEX_NAME = 'semantic_cache_idx'
KEY_PREFIX = 'cache:'
def __init__(self, config: Config):
self.config = config
# Bedrock クライアント(埋め込みベクトル生成用)
self.bedrock_client = boto3.client('bedrock-runtime', region_name=config.aws_region)
# Valkey クライアント
self.client = valkey.Valkey(
host=config.valkey_host,
port=int(config.valkey_port),
decode_responses=False,
ssl=config.valkey_ssl,
)
self.client.ping()
self._setup_index()
decode_responses=Falseにしているのはベクトルデータをバイナリ形式で扱う必要があるためです。Trueにしてしまうとバイナリが文字列としてデコードされてしまい、ベクトルデータが壊れてしまうので注意が必要ですね。
接続後、_setup_index()でベクトル検索用のインデックスを作成しています。
def _setup_index(self) -> None:
"""ベクトル検索インデックスをセットアップ"""
try:
self.client.execute_command('FT.INFO', self.INDEX_NAME)
except Exception as e:
if 'unknown index name' in str(e).lower() or 'no such index' in str(e).lower():
self.client.execute_command(
'FT.CREATE', self.INDEX_NAME,
'ON', 'HASH',
'PREFIX', '1', self.KEY_PREFIX,
'SCHEMA',
'query', 'TAG',
'embedding', 'VECTOR', 'HNSW', '6',
'TYPE', 'FLOAT32',
'DIM', str(self.config.vector_dims),
'DISTANCE_METRIC', 'COSINE',
)
ここで使っているFT.CREATEはValkey(およびRedis Stack)のSearch機能で提供されるコマンドで、全文検索やベクトル検索のためのインデックスを作成します。
スキーマで使用しているフィールド型について少し補足しておきます。
TAGはValkey Searchで使われるフィールド型の一つで、tenant_idやcategoryのような短い識別子を格納し、完全一致やタグベースのフィルタリングを行うための型です。
各パラメータの意味は下記の通りです。
| パラメータ | 値 | 説明 |
|---|---|---|
| ON HASH | - | Valkeyのハッシュ型データを対象にインデックスを作成 |
| PREFIX 1 cache: | - | cache: で始まるキーだけをインデックス対象にする |
| query TAG | - | クエリ文字列をTAG型で格納(完全一致検索に対応) |
| embedding VECTOR HNSW 6 | - | ベクトルフィールドをHNSWアルゴリズムでインデックス化 |
| TYPE FLOAT32 | - | ベクトルの各要素を32bit浮動小数点で格納 |
| DIM 1024 | - | ベクトルの次元数(Titan V2は1024次元) |
| DISTANCE_METRIC COSINE | - | ベクトル間の距離をコサイン距離で計算 |
ちなみに、HNSWはHierarchical Navigable Small World graphsの略で、高速な近似最近傍探索アルゴリズムです。厳密な全件検索と比べると精度は若干落ちますが、大量のベクトルに対しても高速に検索できるのが特徴です。
とても難しそうな響きなので、もっと腹落ちするほど理解したいですね・・・!ざっくりと精度をトレードオフに大量のベクトルを高速に検索できて便利というふうに理解しました。
FT.INFOでインデックスの存在を確認し、なければ作成するという流れにしています。アプリケーション起動時に毎回呼ばれますが、既にインデックスがあればスキップされるので冪等に動作します。
埋め込みベクトルの生成
def _get_embedding(self, text: str) -> list[float]:
"""Titan Text Embeddings V2でベクトル生成"""
response = self.bedrock_client.invoke_model(
modelId=self.config.embedding_model_id,
contentType='application/json',
accept='application/json',
body=json.dumps({'inputText': text}),
)
return json.loads(response['body'].read())['embedding']
Amazon Titan Text Embeddings V2を使って、テキストを1024次元の数値ベクトルに変換しています。
キャッシュの検索
def search(self, query: str, k: int = 3, min_similarity: Optional[float] = None) -> Optional[dict]:
"""類似クエリを検索"""
threshold = min_similarity if min_similarity is not None else self.config.similarity_threshold
# クエリをベクトルに変換
embedding = self._get_embedding(query)
embedding_bytes = struct.pack(f'{len(embedding)}f', *embedding)
# FT.SEARCH で KNN ベクトル検索を実行
results = self.client.execute_command(
'FT.SEARCH', self.INDEX_NAME,
f'*=>[KNN {k} @embedding $vec AS score]',
'PARAMS', '2', 'vec', embedding_bytes,
'RETURN', '1', 'score',
)
if not results or results[0] == 0:
return None
# ドキュメントキーとスコアを取得
doc_key = results[1]
if isinstance(doc_key, bytes):
doc_key = doc_key.decode('utf-8')
top_fields = results[2]
score_value = top_fields[1]
if isinstance(score_value, bytes):
score_value = score_value.decode('utf-8')
# COSINE距離を類似度に変換(0=完全一致 → 類似度1.0)
distance = float(score_value)
similarity = 1 - (distance / 2)
if similarity < threshold:
return None
# 回答本文はインデックスに載せていないため、HGETで取得
answer = self.client.hget(doc_key, 'answer')
if isinstance(answer, bytes):
answer = answer.decode('utf-8')
return {
'answer': answer,
'score': similarity,
'timing_ms': { ... }, # 処理時間の計測結果(省略)
}
まず_get_embedding()でクエリをベクトルに変換し、struct.pack()でValkeyに渡すためのFLOAT32バイナリ形式に変換しています。
次のFT.SEARCHコマンドがベクトル検索の処理部分です。
*=>[KNN 3 @embedding $vec AS score]という部分がKNN(K近傍)検索クエリで、embeddingフィールドに格納されたベクトルの中から、渡したベクトルに最も近い3件を探してscoreという名前で距離を返すという意味になります。
FT.SEARCHが返すscoreはコサイン距離(0が完全一致、2が正反対)なので、1 - (distance / 2) で0〜1の類似度スコアに変換しています。
この類似度が閾値(0.8)以上であればキャッシュヒットとして回答を返し、下回ればキャッシュミスとしてNoneを返す仕組みです。
キャッシュヒットした場合は、FT.SEARCHの結果に含まれるドキュメントキー(cache:xxxxx)を使ってHGETで回答本文を取得しています。
キャッシュの保存
def store(self, query: str, answer: str) -> bool:
"""クエリと回答をキャッシュに保存"""
key = f"cache:{md5(query.encode('utf-8')).hexdigest()}"
embedding = self._get_embedding(query)
embedding_bytes = struct.pack(f'{len(embedding)}f', *embedding)
self.client.hset(key, mapping={
'query': query,
'answer': answer,
'embedding': embedding_bytes,
})
return True
保存はシンプルですね。クエリのMD5ハッシュをキーにして、Valkeyのハッシュ型(hset)でクエリ・回答・埋め込みベクトルの3つをまとめて保存しています。キーにcache:プレフィックスを付けているため、先ほどFT.CREATEで指定したPREFIX 1 cache:のルールにより、保存と同時に自動的にベクトル検索インデックスに追加されます。
続いてエントリポイントとなるmain.pyです。
import logging
import time
from typing import Any
from bedrock_agentcore.runtime import BedrockAgentCoreApp
from strands import Agent
from .config import Config
from .semantic_cache import SemanticCache
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
config = Config()
cache = SemanticCache(config=config)
agent = Agent(model=config.llm_model_id)
app = BedrockAgentCoreApp()
@app.entrypoint
def invoke(payload: dict) -> dict[str, Any]:
user_message = payload.get('prompt', 'Hello! How can I help you today?')
threshold = payload.get('min_similarity', config.similarity_threshold)
request_start = time.perf_counter()
# 1. セマンティックキャッシュを検索
cache_search_start = time.perf_counter()
cached = cache.search(query=user_message, min_similarity=threshold)
cache_search_ms = (time.perf_counter() - cache_search_start) * 1000
if cached:
total_ms = (time.perf_counter() - request_start) * 1000
return {
'response': cached['answer'],
'cache_hit': True,
'similarity_score': cached['score'],
'timing_ms': {
'cache_search': round(cache_search_ms, 1),
'total': round(total_ms, 1),
**cached.get('timing_ms', {}),
},
}
# 2. キャッシュミス → Strands Agent で回答を生成
agent_start = time.perf_counter()
result = agent(user_message)
agent_ms = (time.perf_counter() - agent_start) * 1000
# result.message は辞書型のため、テキスト部分を抽出
message = result.message
if isinstance(message, dict):
content = message.get('content', [])
answer = content[0].get('text', str(result)) if content else str(result)
else:
answer = str(message)
# 3. 生成した回答をキャッシュに保存
cache_store_start = time.perf_counter()
cache.store(user_message, answer)
cache_store_ms = (time.perf_counter() - cache_store_start) * 1000
total_ms = (time.perf_counter() - request_start) * 1000
return {
'response': answer,
'cache_hit': False,
'model_id': config.llm_model_id,
'timing_ms': {
'cache_search': round(cache_search_ms, 1),
'agent_invocation': round(agent_ms, 1),
'cache_store': round(cache_store_ms, 1),
'total': round(total_ms, 1),
},
}
if __name__ == '__main__':
app.run()
まずキャッシュを検索し、ヒットすればLLMを呼び出さずにそのまま返却します。ミスした場合のみStrands Agentで回答を生成し、その結果をキャッシュに保存する流れですね。
各処理ステップの所要時間をtiming_msとしてレスポンスに含めているので、キャッシュヒット時とミス時でどれくらいレイテンシに差が出るか定量的に確認できるようにします。
デプロイ
以下のコマンドでデプロイを実行します。
pnpm dlx cdk deploy SemanticCacheStack
デプロイが完了すると、以下のようなOutputsが表示されます。
✅ SemanticCacheStack-dev
✨ Deployment time: 617.23s
Outputs:
SemanticCacheStack-dev.AgentCoreConstructRuntimeArnC90D93E6 = arn:aws:bedrock-agentcore:us-west-2:xxxxxxxxxxxx:runtime/semanticCacheAgent-xxxxxxxxxx
SemanticCacheStack-dev.AgentCoreConstructRuntimeId94C4621A = semanticCacheAgent-xxxxxxxxxx
SemanticCacheStack-dev.ElastiCacheConstructClusterEndpointCDBE4A08 = master.semantic-cache-dev-cluster.xxxxx.usw2.cache.amazonaws.com:6379
SemanticCacheStack-dev.StackEnvironment = dev
Runtime ARNとRuntime IDが出力されていればOKです!
動作確認
デプロイしたエージェントを呼び出してみます。今回はboto3を使ったPythonスクリプトで呼び出しています。
まずはuvでPythonプロジェクトをセットアップし、boto3を追加します。
uv init
uv add boto3
呼び出し用のスクリプトinvoke.pyを作成します。AGENT_RUNTIME_ARNにはデプロイ時に出力されたRuntime ARNを設定してください。
invoke.py(クリックで展開)
import argparse
import json
import sys
import uuid
import boto3
# デプロイ時のスタック出力から取得した値
AGENT_RUNTIME_ARN = "arn:aws:bedrock-agentcore:us-west-2:xxxxxxxxxxxx:runtime/semanticCacheAgent-xxxxxxxxxx"
REGION = "us-west-2"
def invoke_agent(prompt: str, session_id: str | None = None, min_similarity: float | None = None) -> None:
"""エージェントを呼び出して結果を表示する。"""
client = boto3.client("bedrock-agentcore", region_name=REGION)
payload_dict = {"prompt": prompt}
if min_similarity is not None:
payload_dict["min_similarity"] = min_similarity
payload = json.dumps(payload_dict, ensure_ascii=False).encode("utf-8")
if session_id is None:
session_id = str(uuid.uuid4())
print(f"━━━ リクエスト ━━━")
print(f" プロンプト: {prompt}")
print(f" セッション ID: {session_id}")
print()
response = client.invoke_agent_runtime(
agentRuntimeArn=AGENT_RUNTIME_ARN,
runtimeSessionId=session_id,
payload=payload,
)
content_type = response.get("contentType", "")
if content_type == "application/json":
raw = b""
for chunk in response.get("response", []):
raw += chunk
result = json.loads(raw.decode("utf-8"))
_print_result(result)
else:
print(f"━━━ レスポンス (content-type: {content_type}) ━━━")
print(response)
def _print_result(result: dict) -> None:
"""レスポンス結果を見やすく表示する。"""
cache_hit = result.get("cache_hit", False)
status = "キャッシュヒット ✓" if cache_hit else "キャッシュミス ✗"
print(f"━━━ レスポンス ({status}) ━━━")
print()
print(result.get("response", ""))
print()
print(f"── メタ情報 ──")
if cache_hit and "similarity_score" in result:
print(f" 類似度スコア: {result['similarity_score']:.4f}")
if not cache_hit and "model_id" in result:
print(f" 使用モデル: {result['model_id']}")
timing = result.get("timing_ms", {})
if timing:
print(f"── 処理時間 ──")
for key, value in timing.items():
label = {
"cache_search": "キャッシュ検索",
"embedding": "埋め込み生成",
"vector_search": "ベクトル検索",
"agent_invocation": "LLM 呼び出し",
"cache_store": "キャッシュ保存",
"total": "合計",
}.get(key, key)
print(f" {label}: {value:.1f} ms")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="セマンティックキャッシュエージェントを呼び出します")
parser.add_argument("prompt", help="エージェントへのクエリ文字列")
parser.add_argument("--session-id", "-s", help="セッション ID(省略時は自動生成)")
parser.add_argument("--min-similarity", "-m", type=float, help="キャッシュヒットの類似度閾値 (0.0〜1.0)")
args = parser.parse_args()
invoke_agent(args.prompt, session_id=args.session_id, min_similarity=args.min_similarity)
準備ができたら呼び出してみます。
uv run invoke.py "セマンティックキャッシュとは何ですか?"
1回目の呼び出しではキャッシュにまだ何も入っていないので、エージェントが回答を生成してくれます。
━━━ リクエスト ━━━
プロンプト: セマンティックキャッシュとは何ですか?
セッション ID: eb3b6afe-bd02-43fb-b550-933e07c9507a
━━━ レスポンス (キャッシュミス ✗) ━━━
# セマンティックキャッシュについて
## 概要
セマンティックキャッシュは、意味的に類似したクエリに対して、キャッシュされた結果を再利用するキャッシング技術です。
(中略)
── メタ情報 ──
使用モデル: us.anthropic.claude-haiku-4-5-20251001-v1:0
── 処理時間 ──
キャッシュ検索: 145.2 ms
LLM 呼び出し: 4802.0 ms
キャッシュ保存: 119.9 ms
合計: 5067.4 ms
合計5067.4msかかっていますね。大部分がLLM呼び出しの時間です。
それでは同じ質問をもう一度投げてみます。
uv run invoke.py "セマンティックキャッシュとは何ですか?"
━━━ リクエスト ━━━
プロンプト: セマンティックキャッシュとは何ですか?
セッション ID: ddd93382-9a59-4959-82d1-8d29c0c04607
━━━ レスポンス (キャッシュヒット ✓) ━━━
# セマンティックキャッシュについて
(先ほどと同じ回答が返却される)
── メタ情報 ──
類似度スコア: 1.0000
── 処理時間 ──
キャッシュ検索: 161.1 ms
合計: 161.1 ms
埋め込み生成: 141.8 ms
ベクトル検索: 18.2 ms
無事キャッシュヒットできました!!よかった!!
1回目は5067.4msかかっていたのに対し、2回目は161.1msで返ってきています。全く同じ質問をしたため、類似度スコアも1.0000で完全一致しています。
ちなみに内訳を見ると、161.1msのうち141.8msが埋め込み生成(Bedrock APIへのリクエスト)で、ベクトル検索自体はわずか18.2msで完了しています。Valkeyのベクトル検索は早いですね。
類似した質問でのキャッシュヒット
次は少し表現を変えた質問を試してみます。意味合いとしてはかなり似ている質問です。キャッシュヒットするでしょうか・・・
uv run invoke.py "セマンティックキャッシュって難しい?"
━━━ リクエスト ━━━
プロンプト: セマンティックキャッシュって難しい?
セッション ID: fcaf3ed5-a2d5-4934-b4b1-c84219724786
━━━ レスポンス (キャッシュヒット ✓) ━━━
# セマンティックキャッシュについて
(先ほどと同じ回答が返却される)
── メタ情報 ──
類似度スコア: 0.9020
── 処理時間 ──
キャッシュ検索: 143.0 ms
合計: 143.0 ms
埋め込み生成: 124.4 ms
ベクトル検索: 17.2 ms
おお、完全一致せずとも類似度から質問を返却できていますね!
「セマンティックキャッシュとは何ですか?」と「セマンティックキャッシュって難しい?」は文字列としては異なりますが、類似度0.9020でキャッシュヒットしていますね。
閾値の0.8を上回っているため、LLMを呼び出さずにキャッシュから返却されています。
無関係な質問ではキャッシュミス
逆に、まったく関係のない質問を投げるとどうなるでしょうか。
uv run invoke.py "チーズナンって美味しい?"
━━━ リクエスト ━━━
プロンプト: チーズナンって美味しい?
セッション ID: 0e8f9a58-d7b8-4793-aaf3-86b17fef66fb
━━━ レスポンス (キャッシュミス ✗) ━━━
# チーズナンについて
(中略)
── メタ情報 ──
使用モデル: us.anthropic.claude-haiku-4-5-20251001-v1:0
── 処理時間 ──
キャッシュ検索: 152.2 ms
LLM 呼び出し: 3443.9 ms
キャッシュ保存: 123.0 ms
合計: 3719.4 ms
全く引っかからず安心しました。
意味的に異なる質問はちゃんとキャッシュミスになり、新たにLLMで回答を生成してくれていますね。
おわりに
セマンティックキャッシュを使ってLLMの呼び出しレイテンシを削減できることが確認できましたね。
特に、同じような質問が繰り返されるチャットボットやFAQシステムでは使ってみたいなと思いました。
キャッシュの生存期間などのチューニングは詳しく考えてみたいですね!
一方で、このためだけにVPCにAgentCoreのENIを配置して使用するかというと悩ましいポイントにもなるなと思ったので、必要に応じて検討したいですね。
本記事が少しでも参考になりましたら幸いです。最後までご覧いただきありがとうございました!
参考










