
Amazon Bedrock Knowledge Basesがマルチモーダル検索に正式対応しました #AWSreInvent
AWSが提供するフルマネージドなRAG(Retrieval-Augmented Generation)サービスであるAmazon Bedrock Knowledge Basesがテキストだけでなく、画像、音声、動画といった マルチモーダルデータ の検索を正式にサポートするようになりました。
マルチモーダル と一括りにされていますが、中身が全く異なる2つのアプローチがユーザーに委ねられています
- (前処理 がマルチモーダル)マルチメディアコンテンツをBedrock Data Automation(BDA)でテキスト化して テキスト 埋め込みモデルを利用した テキスト系 検索
- (埋め込み がマルチモーダル)マルチメディアコンテンツに マルチモーダル 埋め込みモデルを直接利用した視覚的な 画像系 検索
Bedrock Knowledge Basesのエンタープライズ検索での適用範囲が大幅に広がりました。
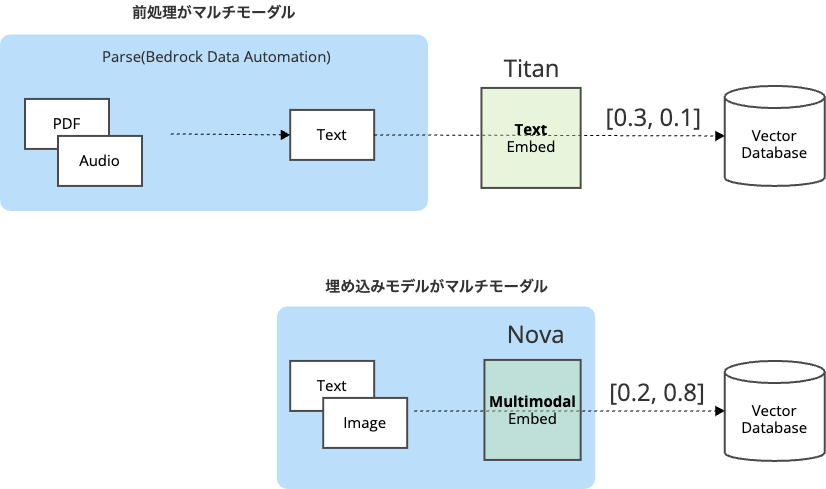
1. テキスト系検索(前処理がマルチモーダル)
テキスト系検索では、画像、動画、音声といった様々なコンテンツ(モード)をテキストという中間表現に変換してから、通常のテキスト埋め込みモデルを用います。
このようなパイプラインを組むことで、議事録、カスタマーサポート、研修セミナーなどを効率よくテキスト検索できるようになります。
Bedrock Knowledge Basesでは、前処理(パーサー)としてBedrock Data Automation(BDA)が利用されます。
前処理後には、以下の様な情報が抽出されます
- 画像・チャートのディスクリプション
- オーディオ・ビデオの文字起こし
- ビデオの要約
2. 画像系検索(埋め込みがマルチモーダル)
テキストだけでなく、画像、動画、音声といった様々なコンテンツ(モード)に対して埋め込みを生成できるモデルをマルチモーダルモデルと呼びます。
このようなモデルを利用することで、画像、製品カタログ、チャートなどを効率よく類似検索できるようになります。
画像系検索では、AWSが2025年10月末に発表されたマルチモーダルな埋め込みモデルAmazon Nova Multimodal Embeddingsが利用されます。
マルチモーダル埋め込みモデルの世界では、テキストも画像も等価に扱われるため、画像をテキストで検索したり、画像で画像を検索したりすることが可能です。
ユースケースごとの使い分け
| ユースケース | マルチモーダル処理 | 埋め込みモデル | 検索条件 | 検索対象 | 前処理 |
|---|---|---|---|---|---|
| テキストをテキストで検索 | なし | テキスト | テキスト | テキスト | なし |
| (NEW)音声・動画・ドキュメントの内容をテキストで検索 | 前処理 | テキスト | テキスト | 音声・動画・ドキュメント | BDA(文字起こし・要約・テキスト抽出) |
| (NEW)画像の類似検索 | 埋め込み | マルチモーダル | テキストまたは画像 | 画像・グラフ | なし |
マルチモーダル対応フォーマット
以下のファイル形式に対応しています。
| ファイルタイプ | Bedrock Data Automation (BDA) | Nova Multimodal Embeddings |
|---|---|---|
| 画像 | .png, .jpg, .jpeg | .png, .jpg, .jpeg, .gif, .webp |
| 音声 | .amr, .flac, .m4a, .mp3, .ogg, .wav | .mp3, .ogg, .wav |
| 動画 | .mp4, .mov | .mp4, .mov, .mkv, .webm, .flv, .mpeg, .mpg, .wmv, .3gp |
| ドキュメント | テキストとして処理 |
マルチモーダルGAまでの道
- 2024/12 : Amazon Bedrock Knowledge Basesのマルチモーダル検索がプレビュー公開
- 2025/03 : Amazon Bedrock Data Automation(BDA)が正式公開
- 2025/10 : Amazon Nova Multimodal Embeddingsが公開
- 2025/11 : Amazon Bedrock Knowledge Basesマルチモーダル検索が正式公開
最後に
Bedrock Knowledge Basesがマルチモーダル検索に正式対応しました。
「マルチモーダル」と一括りにされていますが、ハイレベルな単一サービスとして提供せず、ユースケースに合わせて
- テキストベースの検索
- 視覚的な検索
とパイプラインを明示的に独立に指定させるのは、Amazonらしいなぁと思いました。









