
意図理解のNova、安定のTitan。4つのEmbeddingモデルの検索精度をLLM-as-a-Judgeで比較してみた
前回の記事では、DevelopersIO の約 6 万件のブログ記事を Amazon S3 Vectors に登録し、サーバーレスなセマンティック検索環境を構築しました。
今回はこの環境を活用し、4つの Embedding モデルで検索精度を比較しました。同一クエリの検索結果を LLM-as-a-Judge で自動採点し、「Nova Embed と Titan V2 を適材適所で併用する」という結論に至った経緯を紹介します。
比較対象モデル
| モデル | 提供元 | 次元数 | 実行環境 |
|---|---|---|---|
| Amazon Nova Embed | AWS (Bedrock) | 1024 | Bedrock API |
| Amazon Titan Embed V2 | AWS (Bedrock) | 1024 | Bedrock API |
| multilingual-e5-large | Microsoft (OSS) | 1024 | EC2 |
| ruri-base | Hugging Face (OSS) | 768 | EC2 |
Bedrock のマネージドモデル 2 つと、OSS モデル 2 つを比較しました。
上記のブログ記事約 6 万件について、165 文字前後の日本語要約と 60 ワード前後の英語要約を各モデルでベクトル化し、S3 Vectors に別々のインデックスとして登録しました(4 モデル × 日英 = 8 インデックス)。
評価方法
検索クエリ(33 種 × 12 パターン)
実際のユースケースを想定し、以下の 12 パターンを用意しました。クエリと検索対象が同じ言語の「同一言語検索」と、異なる言語間で検索する「クロスリンガル検索」に大別しています。
同一言語検索(Same-Language):
| # | 検証パターン | クエリ例 | 狙い |
|---|---|---|---|
| 1 | 日本語→日本語 | 「Lambda コールドスタート 対策」 | 基本性能 |
| 3 | 英語→英語 | "RAG hallucination prevention" | 英語基本性能 |
| 4 | 単語のみ→日本語 | 「React」「Lambda」 | ノイズ耐性 |
| 5 | 単語のみ→英語 | "S3" "CDK" | ノイズ耐性(英語) |
| 6 | 表記揺れ→日本語 | 「サーバーレス関数 タイムアウト 変更」 | 同義語理解 |
| 8 | 意図・課題→日本語 | 「コンテナが勝手に再起動を繰り返す」 | 意図理解 |
| 10 | ニッチ技術→日本語 | 「Projen を使ったプロジェクト管理」 | 低頻度トピック |
クロスリンガル検索(Cross-Lingual):
| # | 検証パターン | クエリ例 | 狙い |
|---|---|---|---|
| 2 | 英語→日本語 | "Lambda cold start mitigation" | クロスリンガル基本 |
| 7 | 表記揺れ(英→日) | "Increase Lambda execution time" | クロスリンガル同義語 |
| 9 | 意図・課題(英→日) | "ECS Fargate tasks restarting loop" | クロスリンガル意図理解 |
| 11 | ニッチ技術(英→日) | "Benefits of using IAM Roles Anywhere" | クロスリンガル低頻度 |
| 12 | 日本語→英語 | 「Lambda コールドスタート 対策」 | 逆方向クロスリンガル |
評価指標: nDCG@10 × LLM-as-a-Judge
各検索結果の Top-10 を LLM に渡し、0〜100 点で採点させました。記事のタイトルだけでなく、日英両方の RAG 要約を読ませて判定精度を上げました。
| スコア | 意味 |
|---|---|
| 100 | クエリの直接的な回答・解決策がズバリ含まれている |
| 80 | 密接に関連し、非常に有益 |
| 50 | トピックは合っているが、意図には一歩届かない |
| 20 | 同じ単語は含まれるが、内容は異なる |
| 0 | 無関係 |
スコアから nDCG(Normalized Discounted Cumulative Gain)を算出しました。上位に良い結果が来るほど高くなる指標で、1.0 が理想です。
Judge には Gemini 3.0 Pro を使用しました。参考として Claude Sonnet 4.5(Amazon Bedrock)でも同一データを採点し、Judge 間の比較も行っています。
検証環境
| 項目 | 値 |
|---|---|
| S3 Vectors インデックス | 8 個(4モデル × 日英) |
| 記事数 | 約 6 万件 / インデックス |
| 検索クエリ | 33 種 |
| 検証パターン | 12 種(同一言語 7 + クロスリンガル 5) |
| 検索回数 | 180 回 |
| Judge | Gemini 3.0 Pro(メイン)/ Claude Sonnet 4.5(参考) |
| リージョン | Bedrock: us-east-1 / S3 Vectors: us-west-2 |
結果
全体ランキング
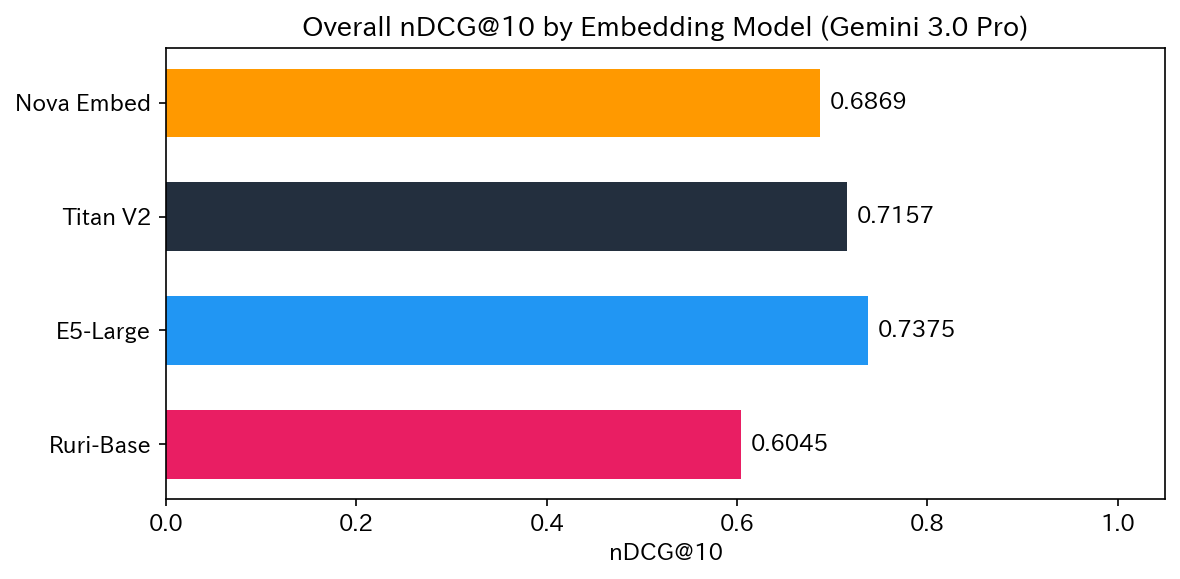
| 順位 | モデル | nDCG@3 | nDCG@10 |
|---|---|---|---|
| 1 | E5-Large | 0.7922 | 0.7375 |
| 2 | Titan V2 | 0.7826 | 0.7157 |
| 3 | Nova Embed | 0.7438 | 0.6869 |
| 4 | Ruri-Base | 0.6600 | 0.6045 |
全体では E5-Large が 1 位でしたが、検証パターンごとに見ると景色が大きく変わりました。
同一言語検索(Same-Language)
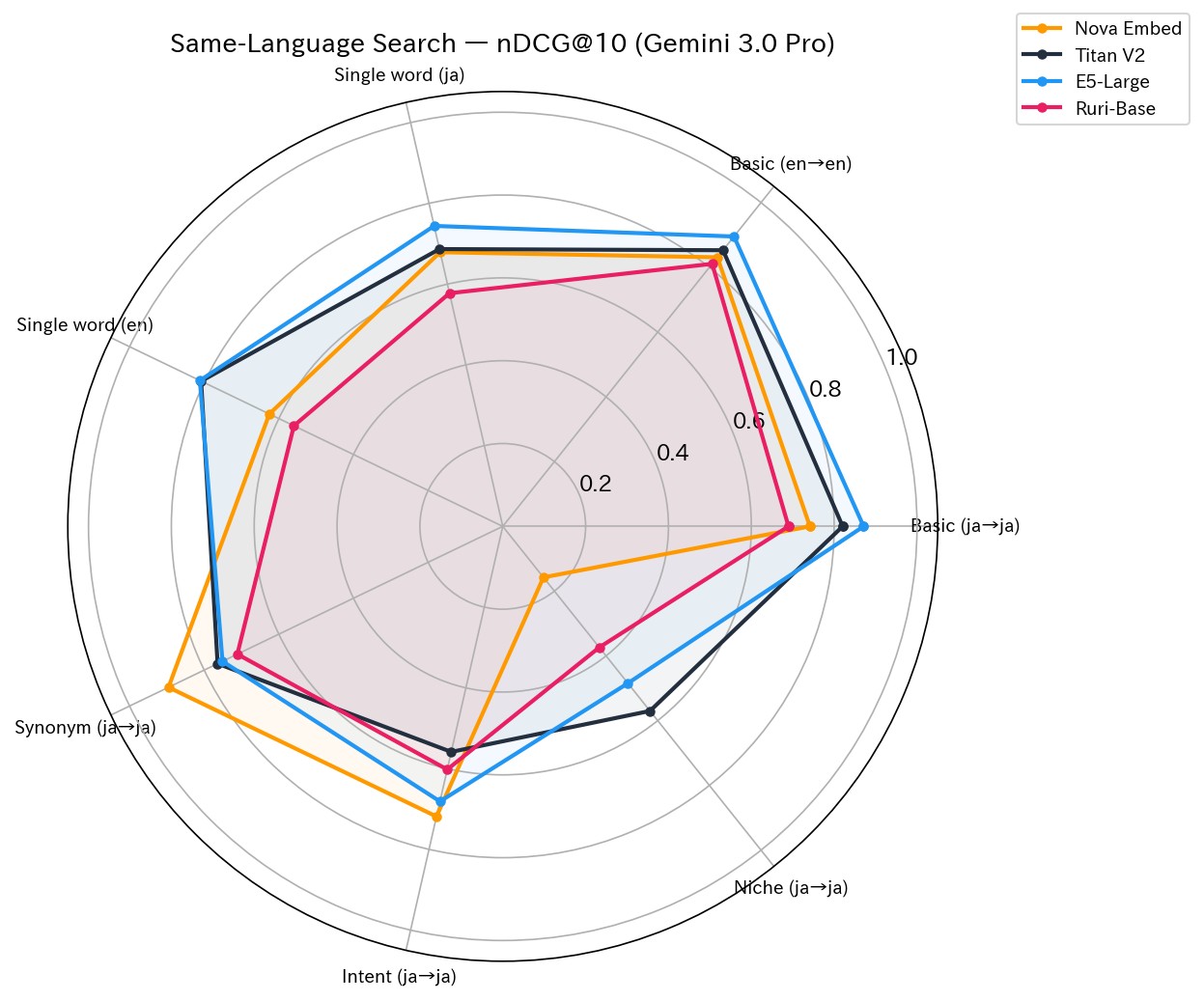
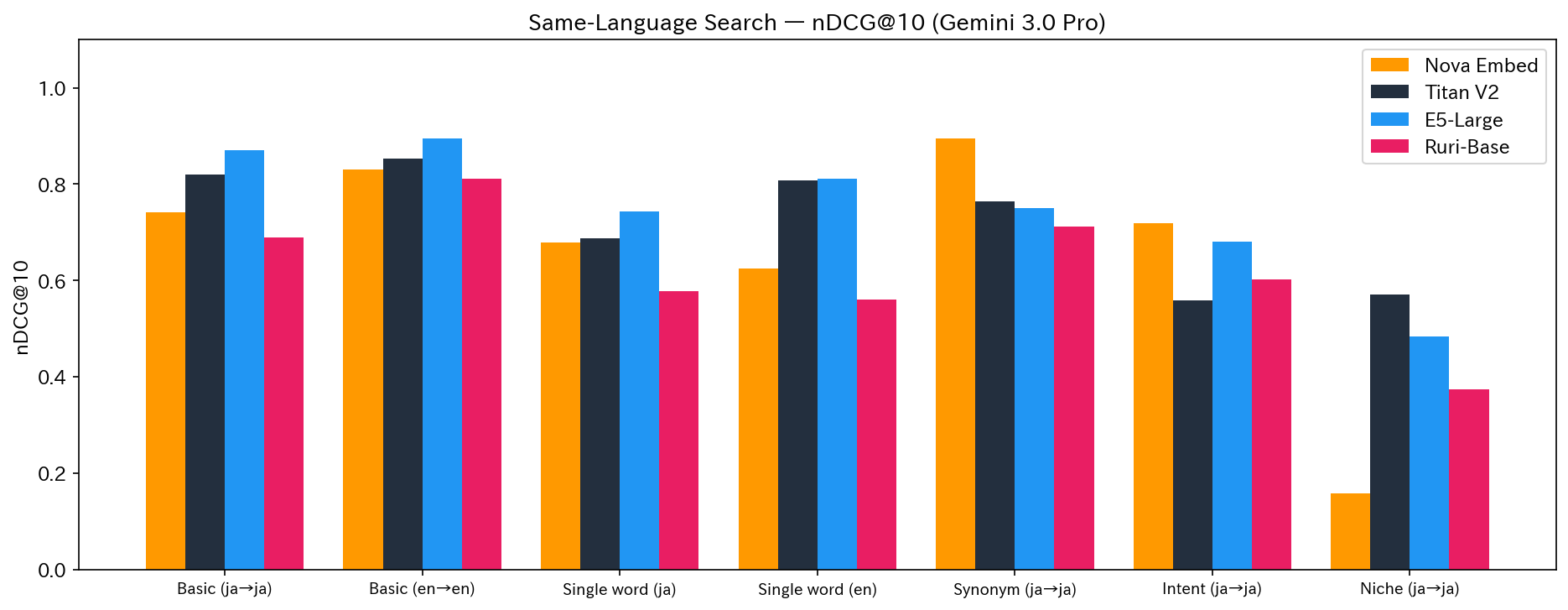
| 検証 | 内容 | Nova | Titan | E5 | Ruri | 1位 |
|---|---|---|---|---|---|---|
| test1 | Basic (ja→ja) | 0.7415 | 0.8205 | 0.8711 | 0.6898 | E5 |
| test3 | Basic (en→en) | 0.8310 | 0.8529 | 0.8953 | 0.8108 | E5 |
| test4 | Single word (ja) | 0.6790 | 0.6868 | 0.7441 | 0.5775 | E5 |
| test5 | Single word (en) | 0.6254 | 0.8082 | 0.8116 | 0.5596 | E5 |
| test6 | Synonym (ja→ja) | 0.8956 | 0.7640 | 0.7510 | 0.7111 | Nova |
| test8 | Intent (ja→ja) | 0.7187 | 0.5586 | 0.6813 | 0.6022 | Nova |
| test10 | Niche (ja→ja) | 0.1576 | 0.5701 | 0.4846 | 0.3738 | Titan |
基本的なキーワード検索(test1, 3, 4, 5)では E5-Large が全勝でした。一方、表記揺れ(test6)と意図理解(test8)では Nova が圧勝しています。
クロスリンガル検索(Cross-Lingual)
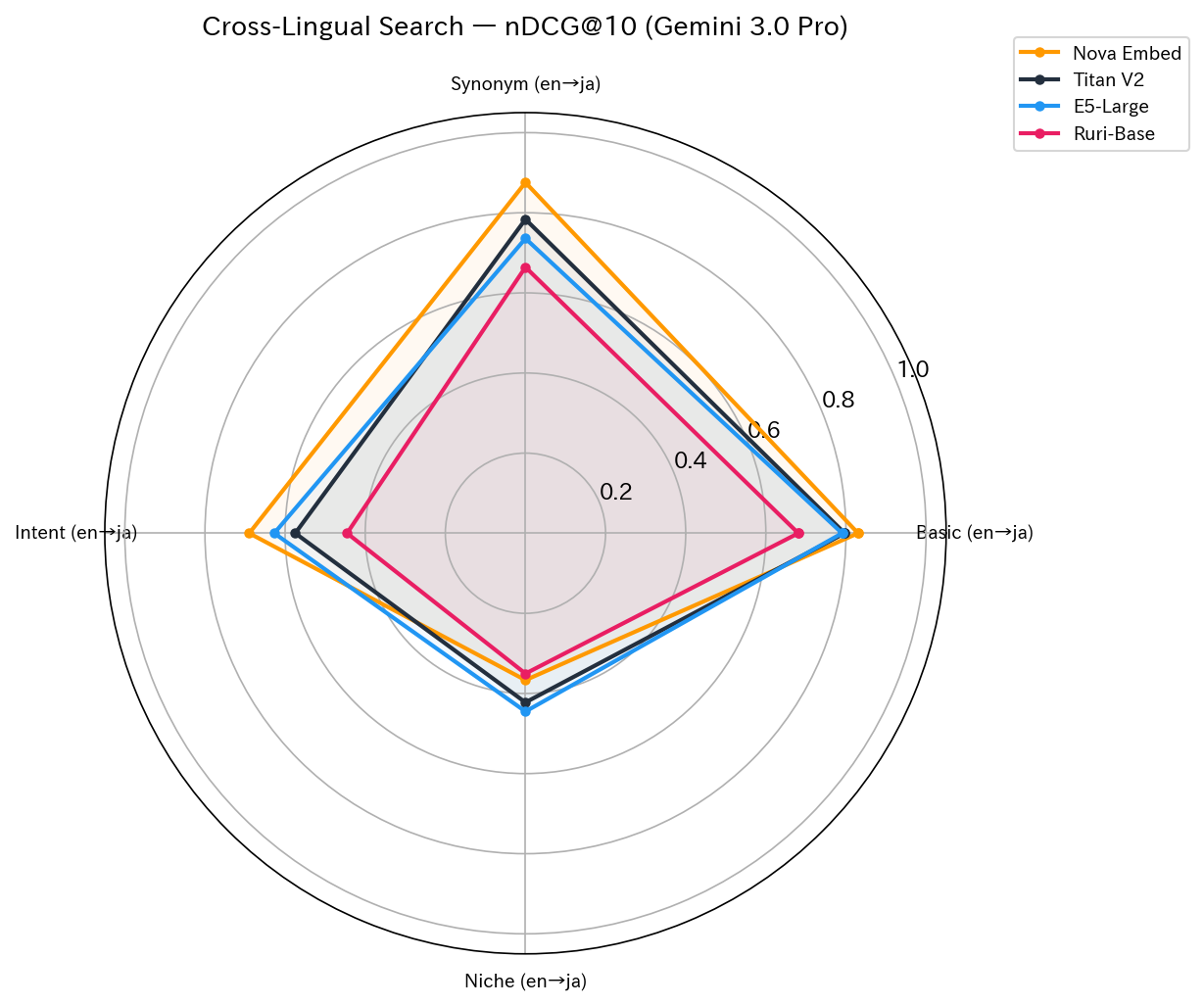
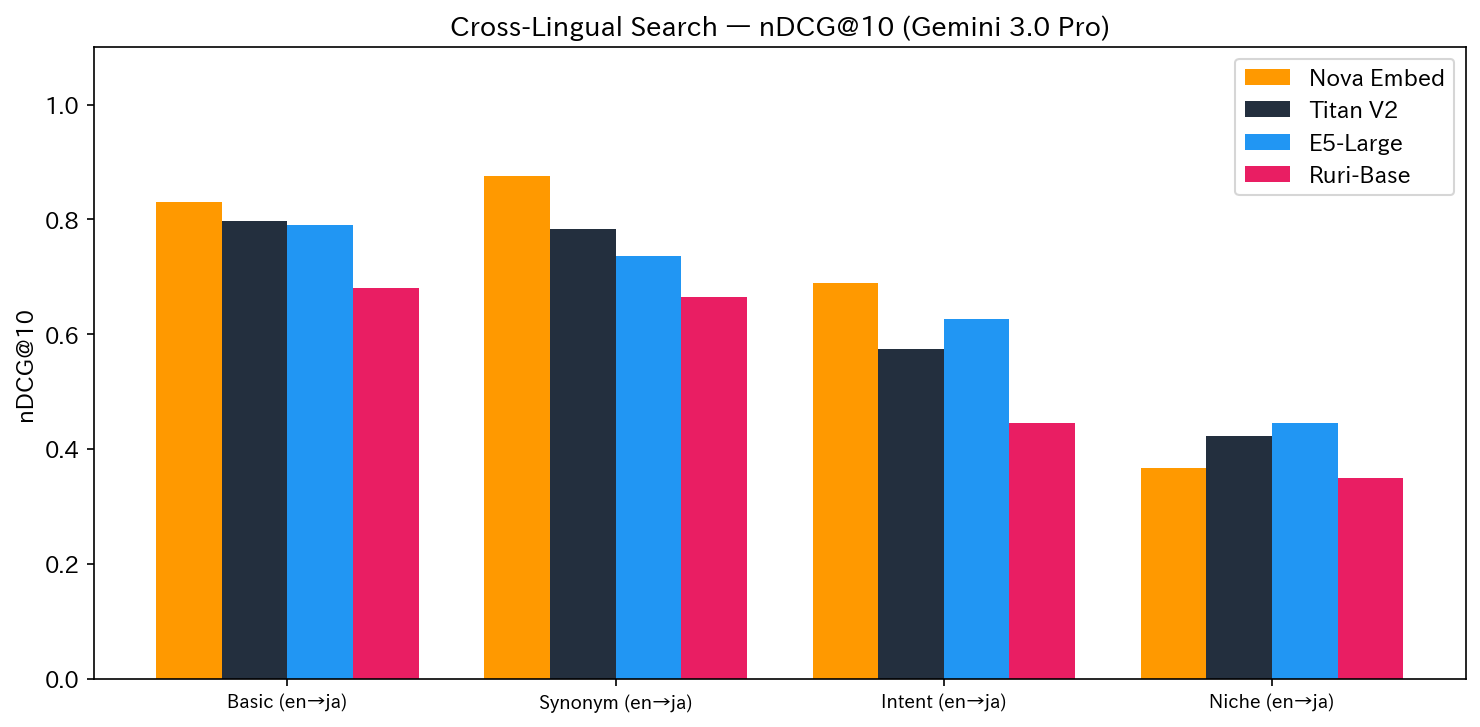
| 検証 | 内容 | Nova | Titan | E5 | Ruri | 1位 |
|---|---|---|---|---|---|---|
| test2 | Basic (en→ja) | 0.8302 | 0.7969 | 0.7904 | 0.6810 | Nova |
| test7 | Synonym (en→ja) | 0.8755 | 0.7837 | 0.7358 | 0.6642 | Nova |
| test9 | Intent (en→ja) | 0.6895 | 0.5746 | 0.6271 | 0.4453 | Nova |
| test11 | Niche (en→ja) | 0.3667 | 0.4224 | 0.4451 | 0.3504 | E5 |
| test12 | Basic (ja→en) | 0.7250 | 0.9511 | 0.9603 | 0.6529 | E5 |
en→ja では Nova が 4 パターン中 3 パターンで 1 位となり、英語クエリから日本語記事を見つける能力が際立っていました。
一方、追試として実施した ja→en(test12: 日本語クエリ→英語インデックス)では結果が逆転しました。Nova は「RAG ハルシネーション 対策」で Top-6 が全て無関係な記事(カンファレンスレポート、アニメ紹介など)となり nDCG@10 = 0.33 と壊滅。Titan(0.95)と E5(0.96)が安定した精度を維持しました。Nova のクロスリンガル能力には en→ja と ja→en で非対称性があることがわかりました。
同一言語 vs クロスリンガル
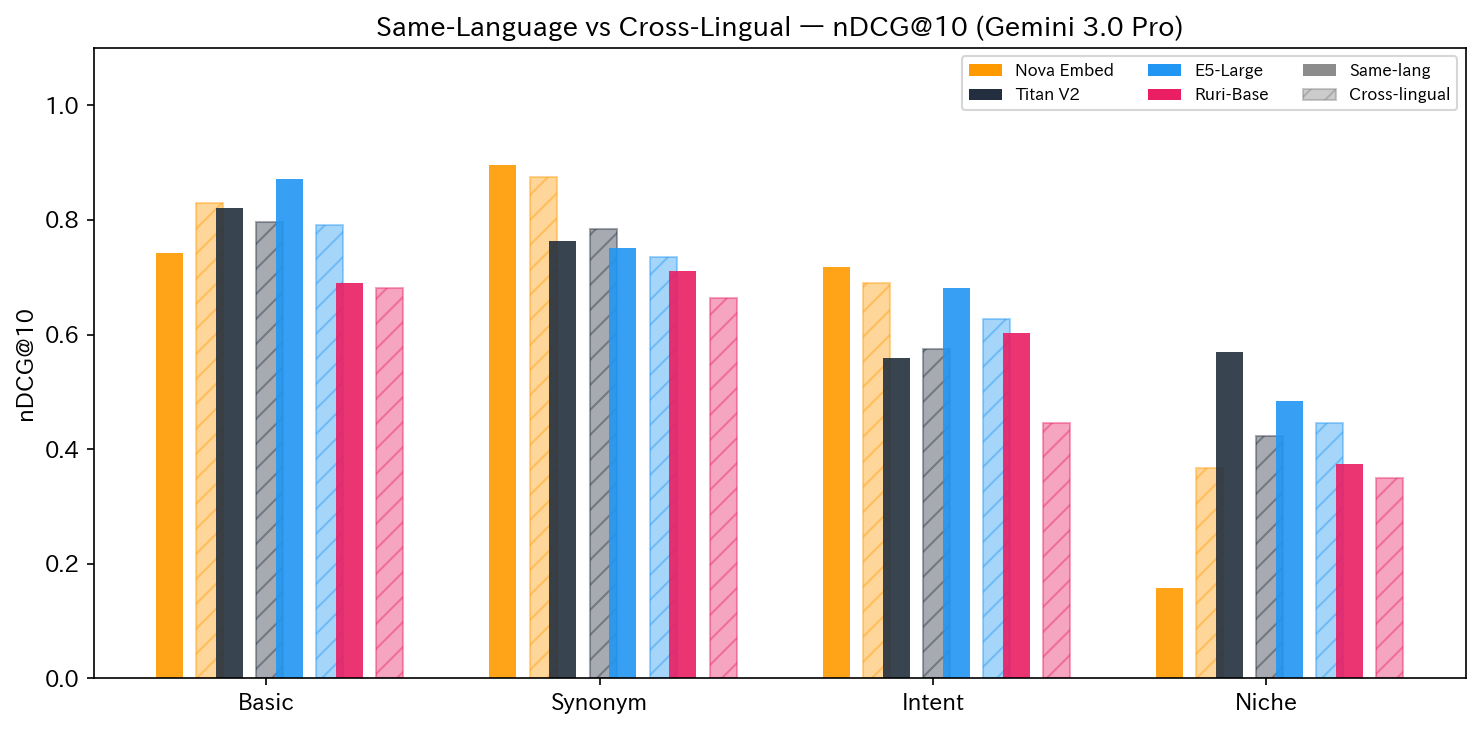
同じカテゴリの同一言語検索とクロスリンガル検索を並べると、興味深い傾向が見えました。
- Nova: en→ja ではほとんど精度が落ちませんでした(Basic: 0.74→0.83、Synonym: 0.90→0.88)。しかし ja→en では大きく崩れるクエリがあり、クロスリンガル能力に方向の非対称性がありました
- Titan / E5: ja→en でも安定した精度を維持しました。英語要約の情報量が多いためか、ja→ja より ja→en の方が高いケースもありました
- Ruri: クロスリンガルで大きく精度が低下しました(Intent: 0.60→0.45、react_hooks の ja→en は nDCG=0.0)
- Niche: 全モデルで同一言語・クロスリンガルともに苦戦しています
ヒートマップ(全パターン一覧)
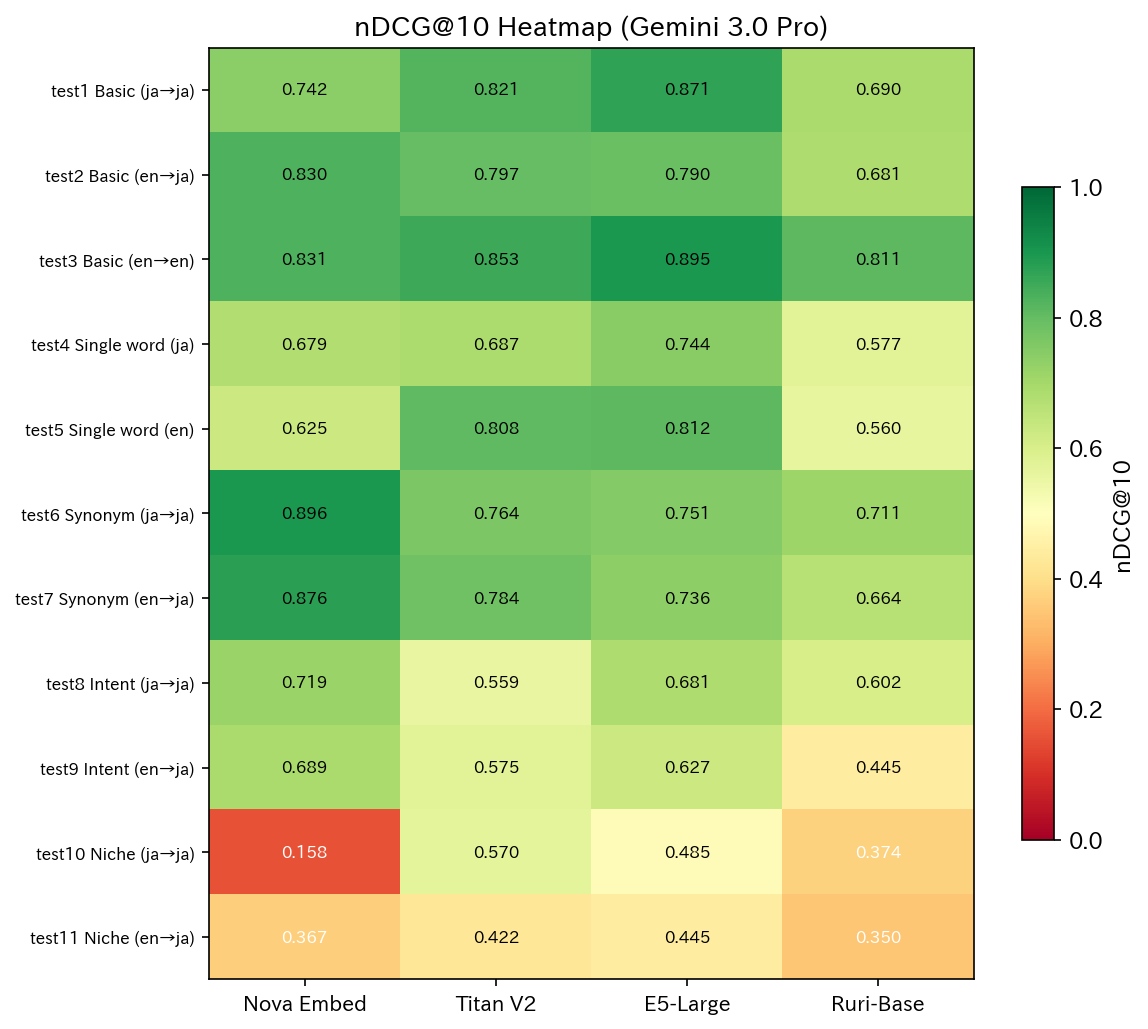
モデル別の特徴
Nova Embed: 意図理解と表記揺れに強い、ニッチに弱い
Nova は表記揺れ(test6: 0.8956)と意図理解(test8: 0.7187)で他モデルを圧倒しました。
以下は表記揺れ型クエリ(test6)の具体例です。「サーバーレス関数 タイムアウト 変更」という、AWS の正式名称を使わない表現で検索しています。
Nova Embed(Top-3):
- タイムアウトと再試行数を設定して、Lambda関数が複数回実行される不具合を修正してみた → score: 100 ✅
- Lambda 関数のログからタイムアウトになったことを確認する方法を教えてください → score: 75
- タイムアウトでエラーとなってしまったLambdaのリカバリを行うLambdaを作成してみました → score: 65
Titan V2(Top-3):
- AWS Systems Manager RunCommand の実行タイムアウト時間を変更するにはどうしたら良いですか? → score: 75
- API Gateway で統合タイムアウト時間を変更する方法を教えてください → score: 95
- [新機能] AWS Elastic Load Balancing(ELB)のタイムアウト値を変更する → score: 40
Nova は「サーバーレス関数」=「Lambda」と意味を理解し、Top-3 が全て Lambda 関連です。Titan は「タイムアウト 変更」という単語に忠実で、SSM や API Gateway など Lambda 以外のサービスが混入しました。
以下は意図理解型クエリ(test8)の具体例です。「コンテナが勝手に再起動を繰り返す」という「困っている状況」を自然言語で入力するパターンです。
Nova Embed(Top-3):
- AMI 作成時に意図しない再起動がありました → score: 20
- systemd で例外時に自動で再起動する → score: 75
- ECR イメージ更新で ECS タスクが CannotPullContainerError → score: 95 ✅
Titan V2(Top-3):
- AMI 作成時に意図しない再起動がありました → score: 30
- 再起動を伴う EC2 メンテナンス対応方法 → score: 35
- ECS で Windows コンテナを起動させ続ける方法 → score: 75
Nova は Top-3 に ECS 関連の高スコア記事(score: 95)を含めることに成功しています。Titan は「再起動」「コンテナ」の単語マッチに留まり、意図に合った記事を上位に持ってこれませんでした。
一方、ニッチ技術(test10: 0.1576)では立場が逆転します。「Projen を使ったプロジェクト管理」の結果です。
Nova Embed(Top-3):
- GitHub Projectsを使った(プロダクト/ スプリント)バックログ管理 → score: 20
- Projectを使ってIssueとIssue未満をいい塩梅で管理する方法 → score: 20
- プロジェクトマネジメントを(非エンジニア)のスタッフ業務に取り入れてみた → score: 15
Titan V2(Top-3):
- 通常のAWS CDK App開発もprojen使ったら快適だった → score: 95 ✅
- 【レポート+やってみた】projen – a CDK for software project configuration #CDK Day → score: 95 ✅
- プロジェクトマネジメント#1 → score: 15
Nova は「プロジェクト管理」という一般的な意味に引きずられ、Projen の記事を1件も見つけられませんでした。Titan は「Projen」という固有名詞を正確に捉え、Top-2 に関連記事をヒットさせています。Nova の意味理解が裏目に出るケースで、Titan が補完する好例です。
Titan Embed V2: 安定した 2 番手
Titan は突出した強みはないものの、全パターンで安定して 2〜3 位に入りました。ニッチ技術(test10: 0.5701)では Nova が壊滅する中で 1 位を獲得しており、苦手分野が少ないバランス型です。
OSS モデル(E5-Large / Ruri-Base): 基本性能は高いが、運用面で採用を見送り
E5-Large は日本語基本検索(test1: 0.8711)、英語基本検索(test3: 0.8953)、単語検索(test4/5)で 1 位を獲得しました。教科書的な検索クエリに対する精度が最も高いモデルです。ただし、表記揺れや意図理解では Nova に劣りました。
Ruri-Base は全 12 パターンで最下位でしたが、768 次元と他モデル(1024 次元)より低い次元数というハンディキャップを考慮すると、健闘した結果とも言えます。
しかし、OSS モデルには運用上の課題がありました。検索ワードのリアルタイムベクトル化には、モデルのロードと推論が必要です。Lambda のような CPU のみの環境では実用的なレイテンシを実現することが難しく、GPU インスタンスを常時稼働させるのもコストに見合いません。
あらかじめベクトル化したデータ同士の類似記事検索であれば活用の余地はありましたが、モデルのファインチューニングや独自の最適化を行う予定もないため、今回は OSS モデルの採用を見送り、Bedrock のマネージドモデルに絞る判断をしました。
ベクトル化速度
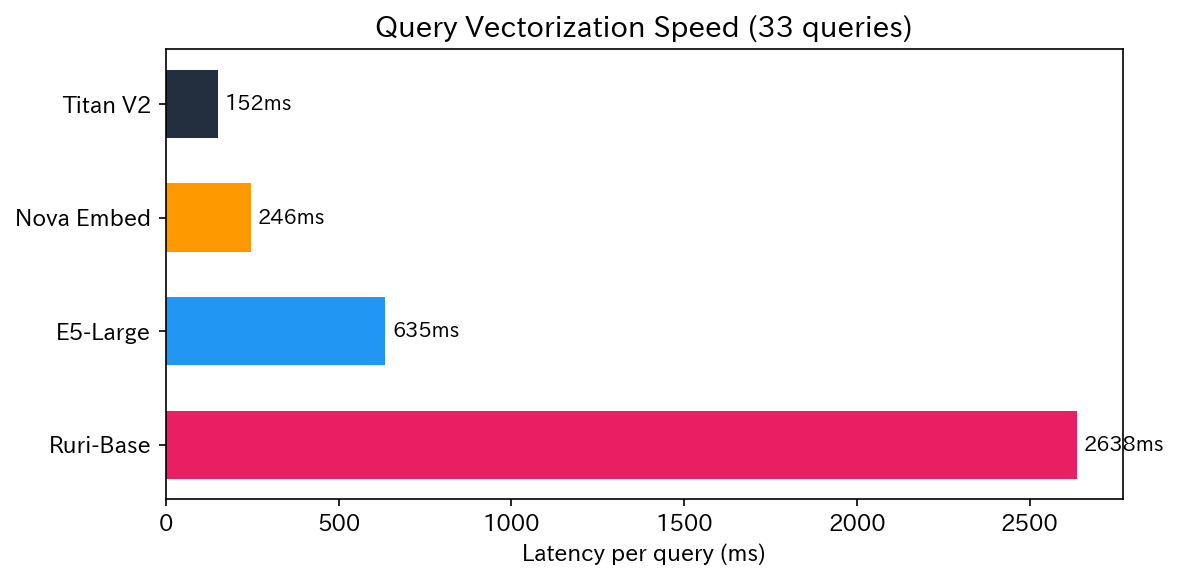
| モデル | 初期化 | 推論(33件) | 1件あたり | 実行環境 |
|---|---|---|---|---|
| Titan V2 | 0.1s | 5.0s | 152ms | Bedrock API |
| Nova Embed | 0.1s | 8.1s | 246ms | Bedrock API |
| E5-Large | 57.8s | 21.0s | 635ms | EC2 |
| Ruri-Base | 4.9s | 87.0s | 2,638ms | EC2 |
Bedrock API 経由のモデルは初期化不要で高速でした。OSS モデルは Docker コンテナの起動とモデルロードが必要で、特に E5-Large は初期化に約 1 分かかる点がネックでした。
参考: Sonnet のセカンドオピニオン
Judge の偏りを検証するため、Claude Sonnet 4.5(Amazon Bedrock)でも同一データを採点しました。
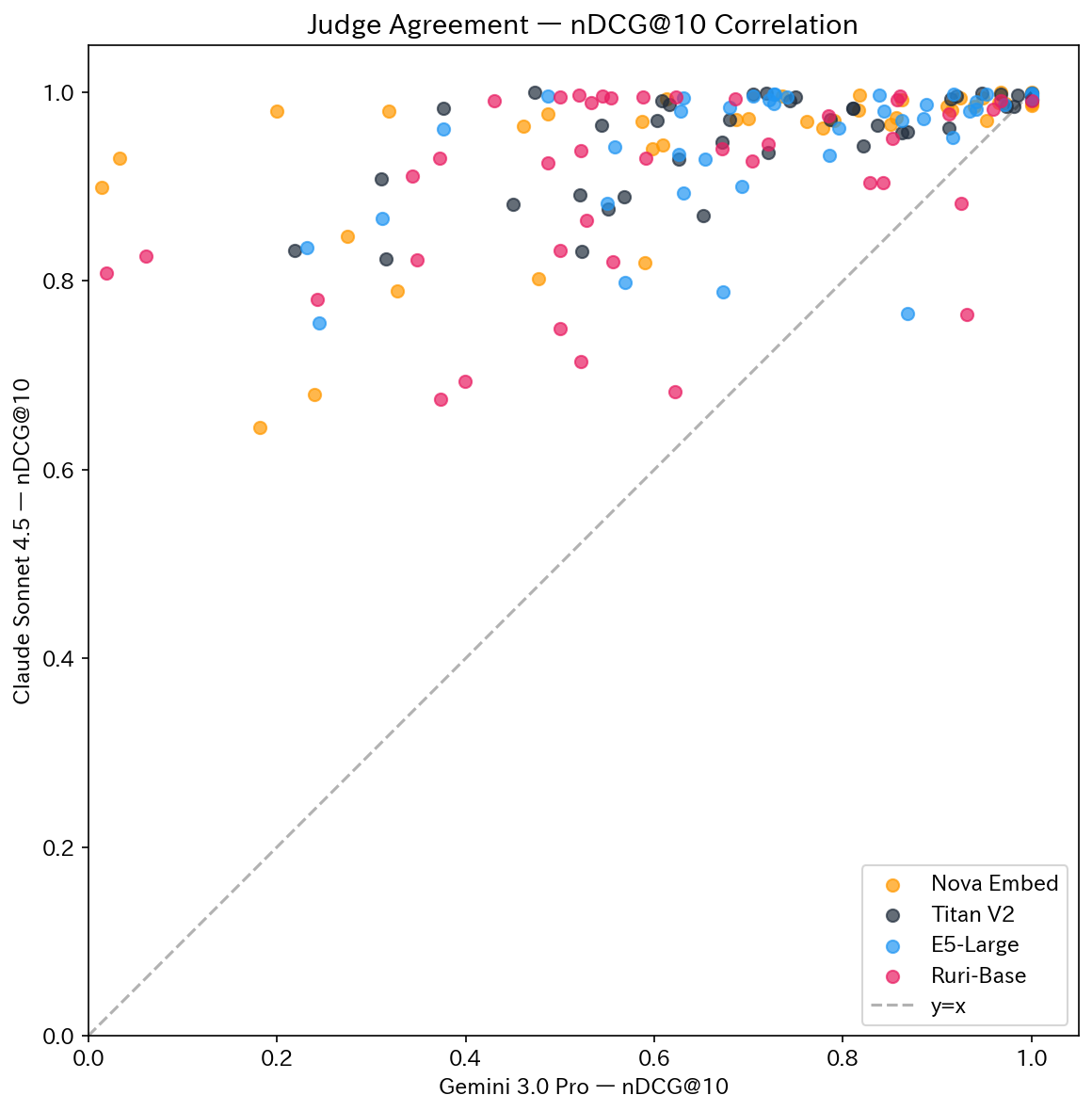
Gemini は 5 段階(0/20/50/80/100)を指示通りに使い分け、モデル間の差が明確に出ました。一方 Sonnet は 0〜100 の連続値を使用し(1,640 件中 69% が指定外の値)、全モデル nDCG@10 = 0.90〜0.95 に集中して差がつきにくい結果でした。
| 検証 | Gemini 1位 | Sonnet 1位 | 一致 |
|---|---|---|---|
| test2 クロスリンガル基本 | Nova | Nova | ✓ |
| test6 表記揺れ | Nova | Nova | ✓ |
| test7 表記揺れ(英→日) | Nova | Nova | ✓ |
| test8 意図理解 | Nova | Nova | ✓ |
| test9 意図理解(英→日) | Nova | Nova | ✓ |
| test10 ニッチ技術 | Titan | Titan | ✓ |
| test1 基本(日→日) | E5 | Titan | ✗ |
| test3 基本(英→英) | E5 | Titan | ✗ |
| test4 単語(日) | E5 | Ruri | ✗ |
| test5 単語(英) | E5 | Titan | ✗ |
| test11 ニッチ(英→日) | E5 | Nova | ✗ |
1 位モデルの一致率は 6/11(55%)でした。Nova が強いパターン(クロスリンガル・表記揺れ・意図理解)と Titan が強いパターン(ニッチ技術)は両 Judge で一致しましたが、基本検索・単語検索では E5 vs Titan で割れました。LLM-as-a-Judge は Judge の選択で順位が変わり得るため、今回の結果は相対的な傾向として捉えてください。
まとめ
Bedrock モデル選定の指針
| ユースケース | 推奨モデル | 理由 |
|---|---|---|
| クロスリンガル検索(英→日) | Nova Embed | 英語クエリ→日本語記事で最高精度 |
| 表記揺れ・同義語への対応 | Nova Embed | 「サーバーレス関数」→「Lambda」を理解 |
| 自然言語での課題検索 | Nova Embed | 意図理解力が最も高い |
| キーワード検索・ニッチ技術 | Titan V2 | 弱点が少なく安定、Nova が苦手な領域を補完 |
総合所感
今回の比較で各モデルの得意・不得意が明確になりました。
単なる「総合スコア」で見れば OSSモデルの E5-Large が 1 位でしたが、今回我々が構築するセマンティック検索基盤では、キーワードが明確な検索よりも、ユーザーが自然言語で曖昧に「困っていること」を入力するユースケースを最重要視しています。
そのため、総合スコアの高さよりも「意図理解(test8)」や「表記揺れ(test6)」に対する強さを評価し、さらに GPU等のインフラ管理が不要な Bedrock のマネージドモデルである Nova Embed をメインに採用する判断をしました。
一方で、検証を通してニッチ技術や単語のみのキーワード検索など、Nova が苦手とする分野も浮き彫りになりました。こうした領域については、弱点が少なく安定している Titan V2 を併用し、適材適所で補完し合う使い分けを検討しています。







