
BigQuery の Conversational Analytics で自然言語によるデータ分析を試してみた
こんにちは!エノカワです。
2026年1月、BigQuery の Conversational Analytics(会話型分析) が プレビュー になりました。
BigQuery now offers conversational analytics, which accelerates data analysis by enabling insights through natural language. Users can view a predefined sample agent, chat with their BigQuery data or custom agents, and access those agents even outside of BigQuery. They can also use supported BigQuery ML functions in verified queries and in chat. This feature is in Preview.
その後もアップデートが続いています。
- February 24, 2026 — 用語集のカスタム作成・レビュー機能
- March 09, 2026 — Google Cloud Storage との連携(ObjectRef)、SQL エディタからの会話開始、ジョブラベリングなど
自然言語でチャットするだけで、BigQuery のテーブルを分析できる機能です。
「BigQueryのデータを分析したいけど、SQLがよくわからない…」という方にも使いやすい機能になっています。
今回は、この機能を実際に触ってみましたので、その内容をご紹介します。
本記事ではサンプルエージェントと自作エージェントの2パターンで試しています。
Conversational Analytics とは
Conversational Analytics は、チャット形式の自然言語でBigQueryのデータを分析できる機能です。
裏側では Gemini がSQL を自動生成・実行し、結果をテキスト・表・グラフで返してくれます。
大きく2つのコンセプトがあります。
| コンセプト | 説明 |
|---|---|
| データエージェント | どのテーブルを使うか・どう答えるかを定義したもの。 用語集やゴールデンクエリ(検証済みクエリ)を登録して精度を高められる |
| 会話 | ユーザーとデータエージェント間の永続的なチャット。 テーブル名やカラム名を意識せず、日常語で質問できる |
できること
- 「先月の売上合計は?」「最も売れた商品カテゴリは?」など自然言語で質問するだけでデータを取得
- 回答はテキスト・表・グラフで返ってくる
- 「コード」タブから Gemini が生成した SQL を確認できる(SQLの学習にも使える)
- フォローアップ質問で深掘り分析が可能(会話の文脈を引き継いでくれる)
- BigQuery ML 関数(
AI_FORECAST・AI_DETECT_ANOMALIES)と組み合わせた予測・異常検知も自然言語から実行可能
料金
プレビュー期間中は追加料金なしです。
ただし Conversational Analytics が実行する BigQuery のクエリには通常のコンピューティング料金が発生します。
前提
Conversational Analytics を利用するには、以下の API を有効にしておく必要があります。
- BigQuery API
- Gemini Data Analytics API
- Gemini for Google Cloud API
必要なロールや権限の詳細は公式ドキュメントを参照してください。
サンプルエージェントで試す
まずは最も手軽に体験できるサンプルエージェントを使ってみます。
セットアップ不要で、公開データセットへの接続が済んでいる状態で試せます。
エージェント カタログを開く
BigQuery コンソールの左メニューから「エージェント(プレビュー)」を選択します。
「会話」タブが表示されるので、「他のエージェントを探す」または「エージェント カタログ」タブを開きます。
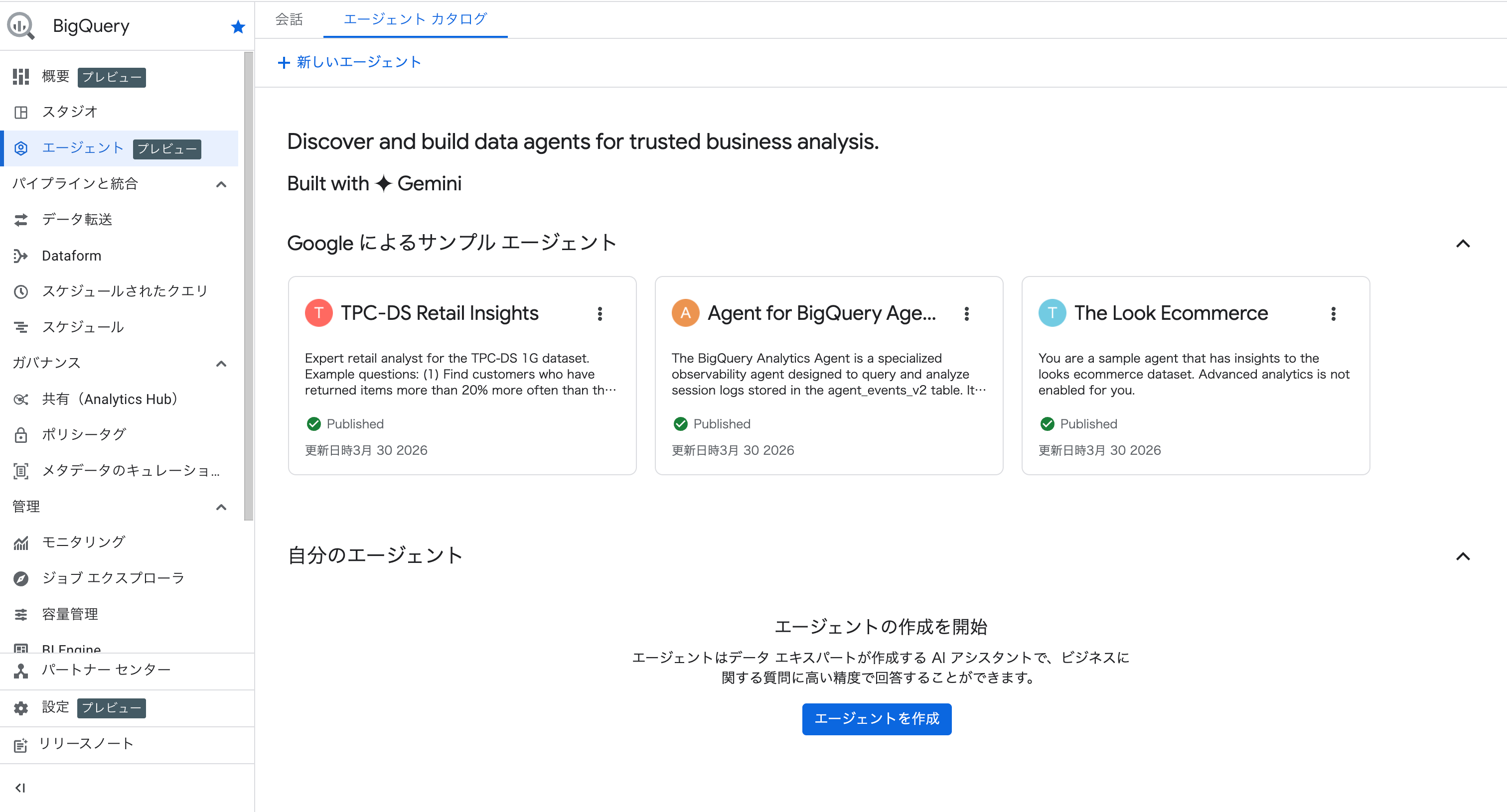
「Google によるサンプル エージェント」として以下が用意されています。
| エージェント名 | 説明 |
|---|---|
| TPC-DS Retail Insights | TPC-DS 1G データセットの小売分析エージェント |
| Agent for BigQuery Agent Analytics Data | エージェントのセッションログを分析するオブザーバビリティエージェント |
| The Look Ecommerce | 公開データセット bigquery-public-data.thelook_ecommerce(ECサイトのデータ)を分析するエージェント |
今回は The Look Ecommerce を使います。
会話を開始する
エージェントカードをクリックすると会話画面が開きます。
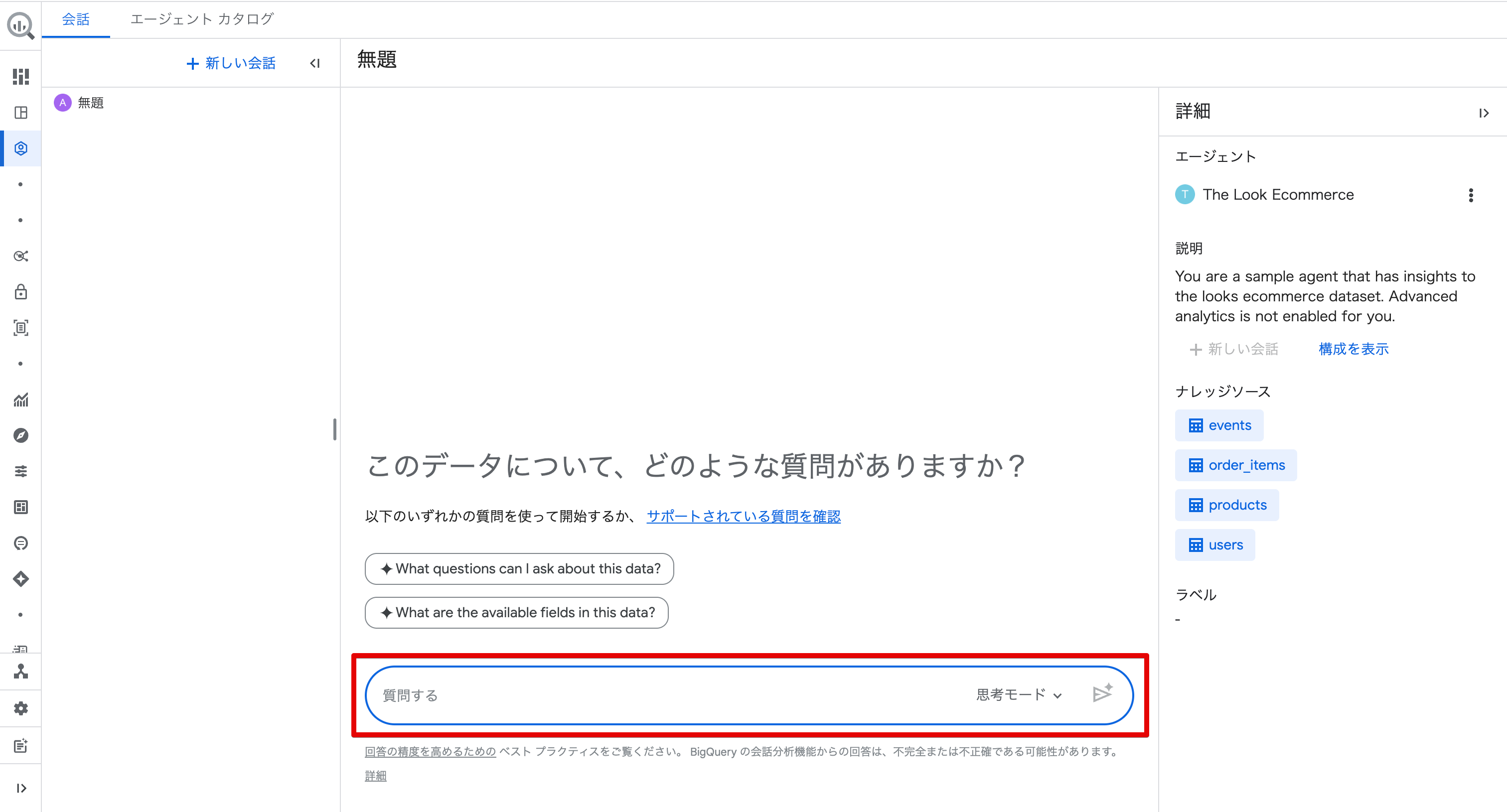
右側の「詳細」パネルにはエージェントの説明やナレッジソース(対象テーブル)が表示されています。
画面下部の「質問する」フィールドに自然言語で質問を入力します。
Gemini が質問の候補を提案してくれるので、最初はそれを選んでもOKです。
入力欄の右側にある「思考モード」をクリックすると、以下の2つのモードを切り替えられます。
| モード | 説明 |
|---|---|
| 高速モード | シンプルな質問に迅速に回答します |
| 思考モード | 複雑な質問に対して、段階的に思考しながら回答します |
今回は「思考モード」を使用しました。
また、「サポートされている質問を確認」をクリックすると、質問の種類の例が表示されます。
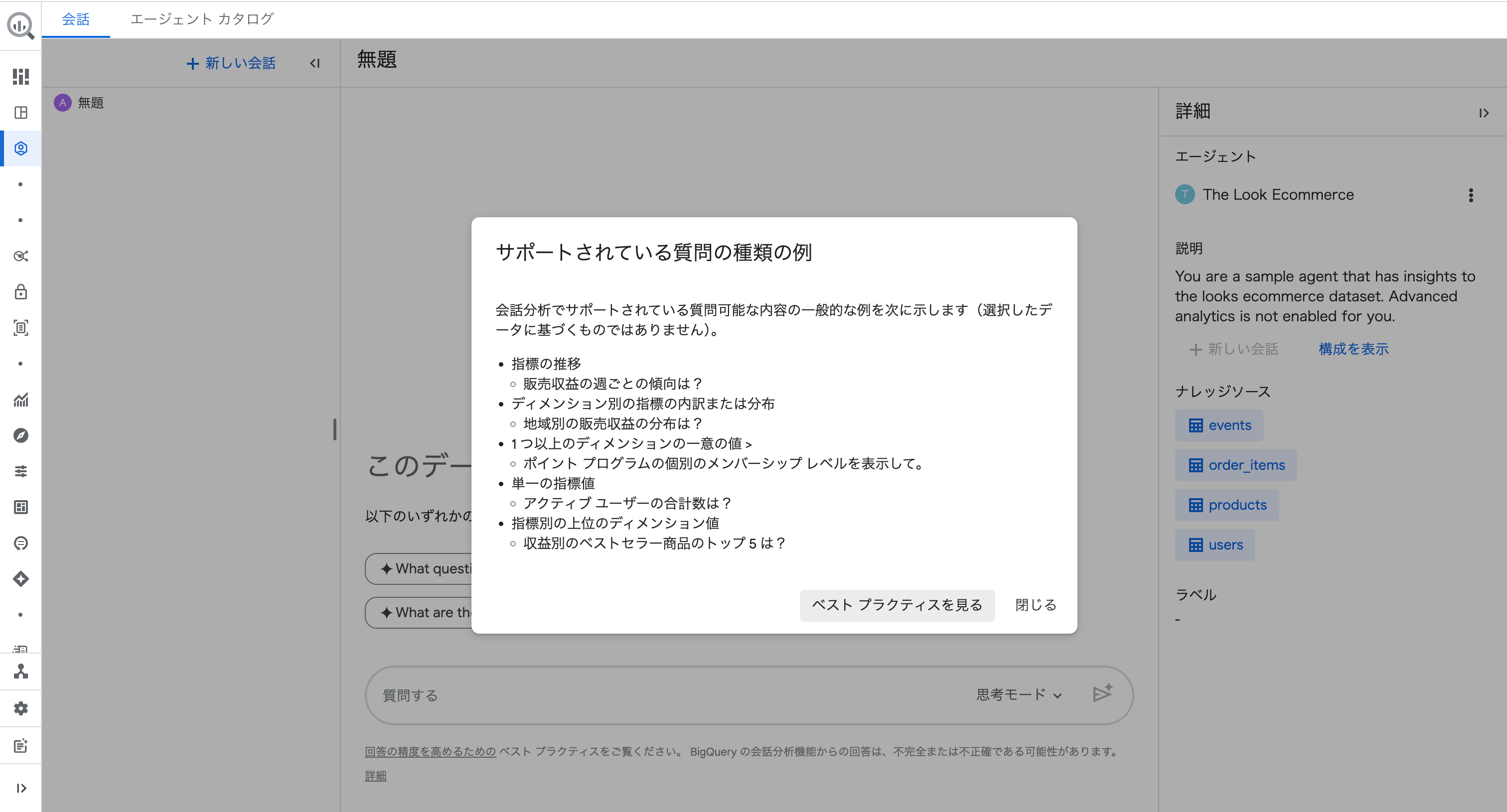
指標の推移、ディメンション別の分布、Top N のランキングなど、どのような質問ができるかを事前に確認できます。
質問してみる
それでは、実際に質問してみましょう。
質問①:「先月の売上合計を教えてください」
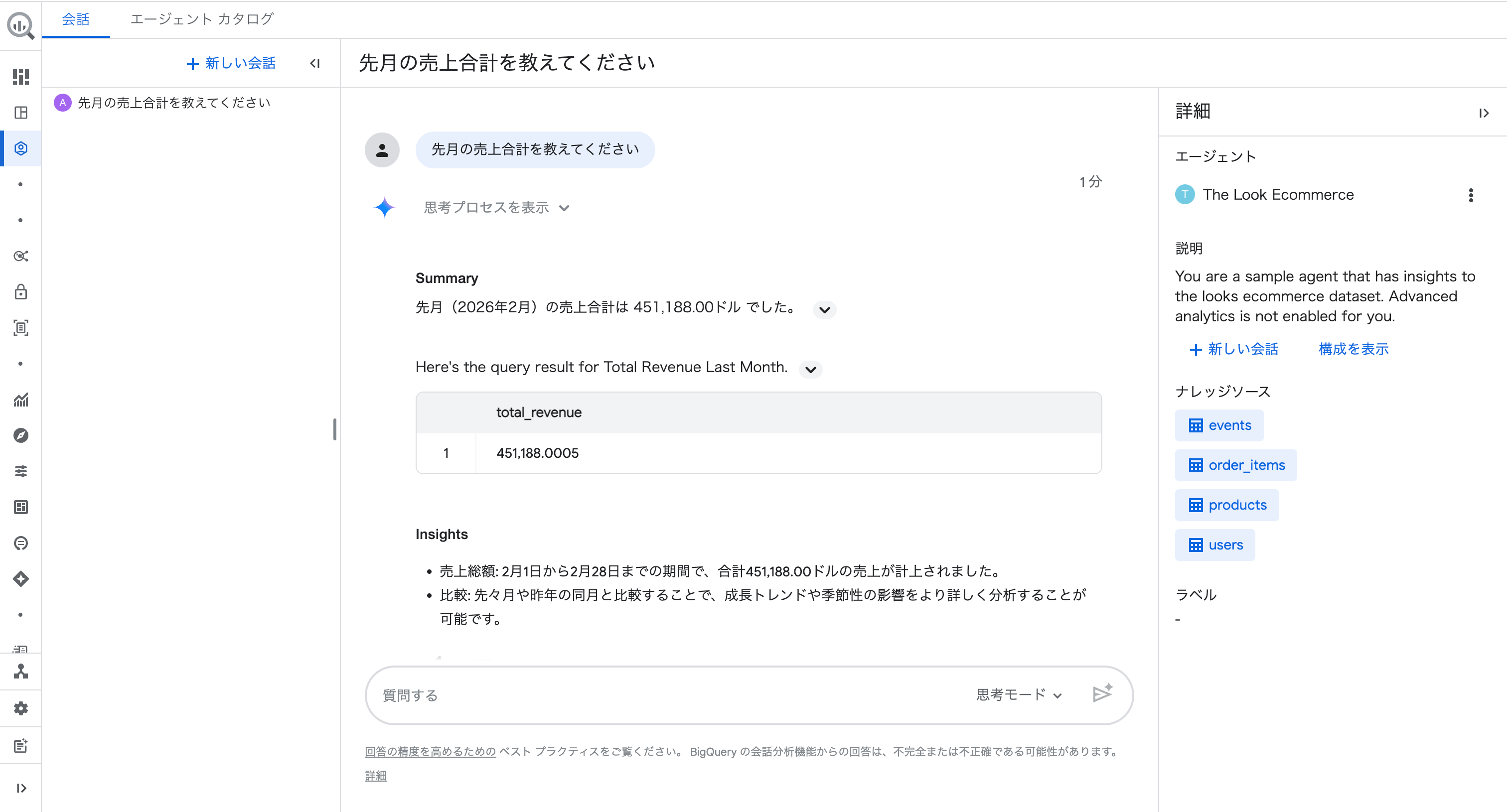
回答は以下の構成で返ってきました。
- Summary(要約):「先月(2026年2月)の売上合計は 451,188.00ドル でした。」とテキストで回答
- 表:
total_revenueカラムに数値が表示 - Insights(洞察):売上総額の説明に加え、「先々月や昨年の同月と比較することで、成長トレンドや季節性の影響をより詳しく分析することが可能です」と次のアクションを提案
さらに、回答の下にはフォローアップ質問の候補が自動で提案されます。
「先月のカテゴリ別の売上内訳を教えてください」「過去12ヶ月の月次売上推移をチャートで表示してください」など、会話の文脈に沿った深掘り質問がワンクリックで実行できます。
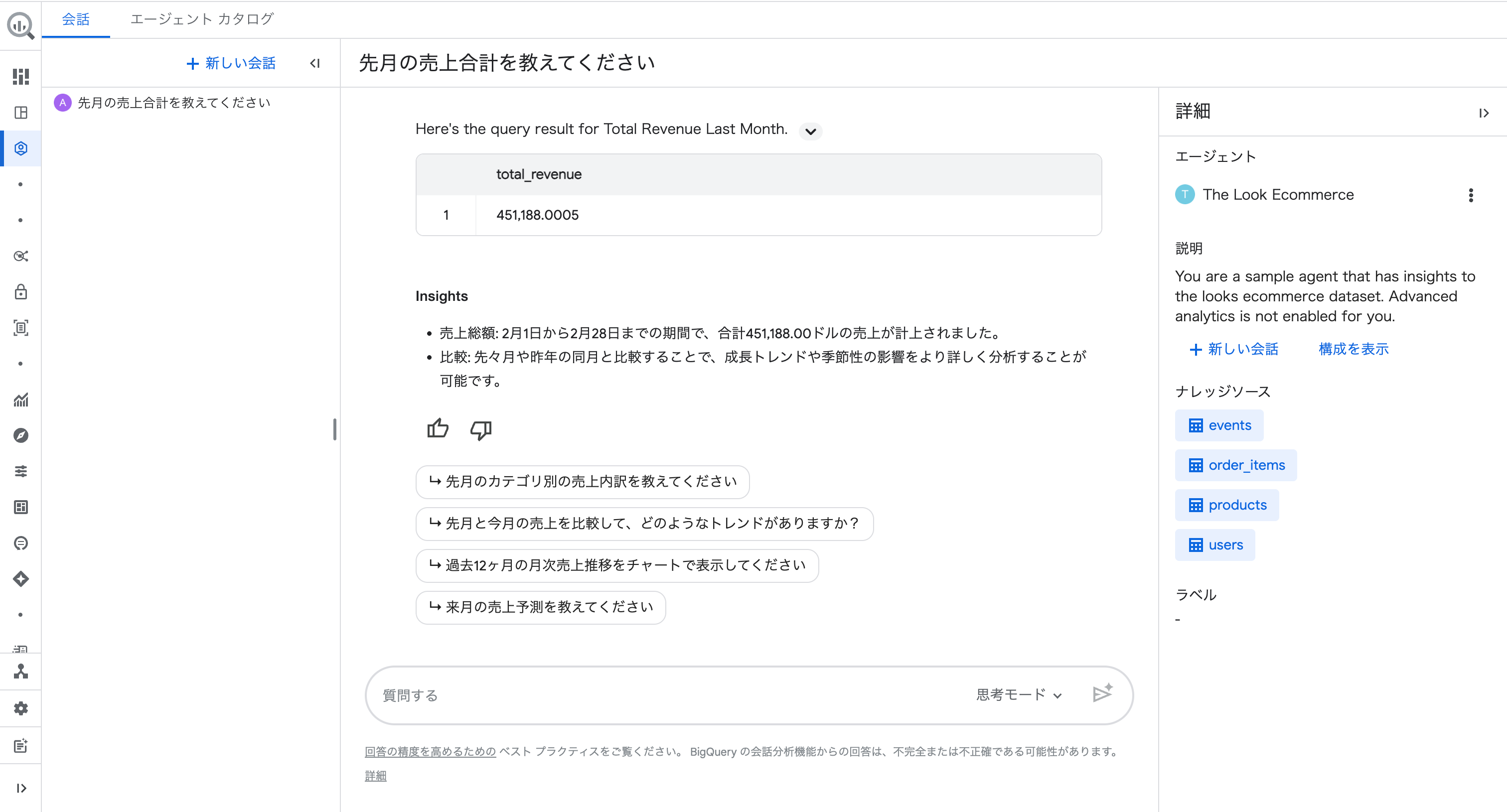
また、「思考プロセスを表示」から Gemini の思考過程も確認できます。
どのテーブルのコンテキストを取得し、どのようにクエリを組み立てたかが英語で表示されます。
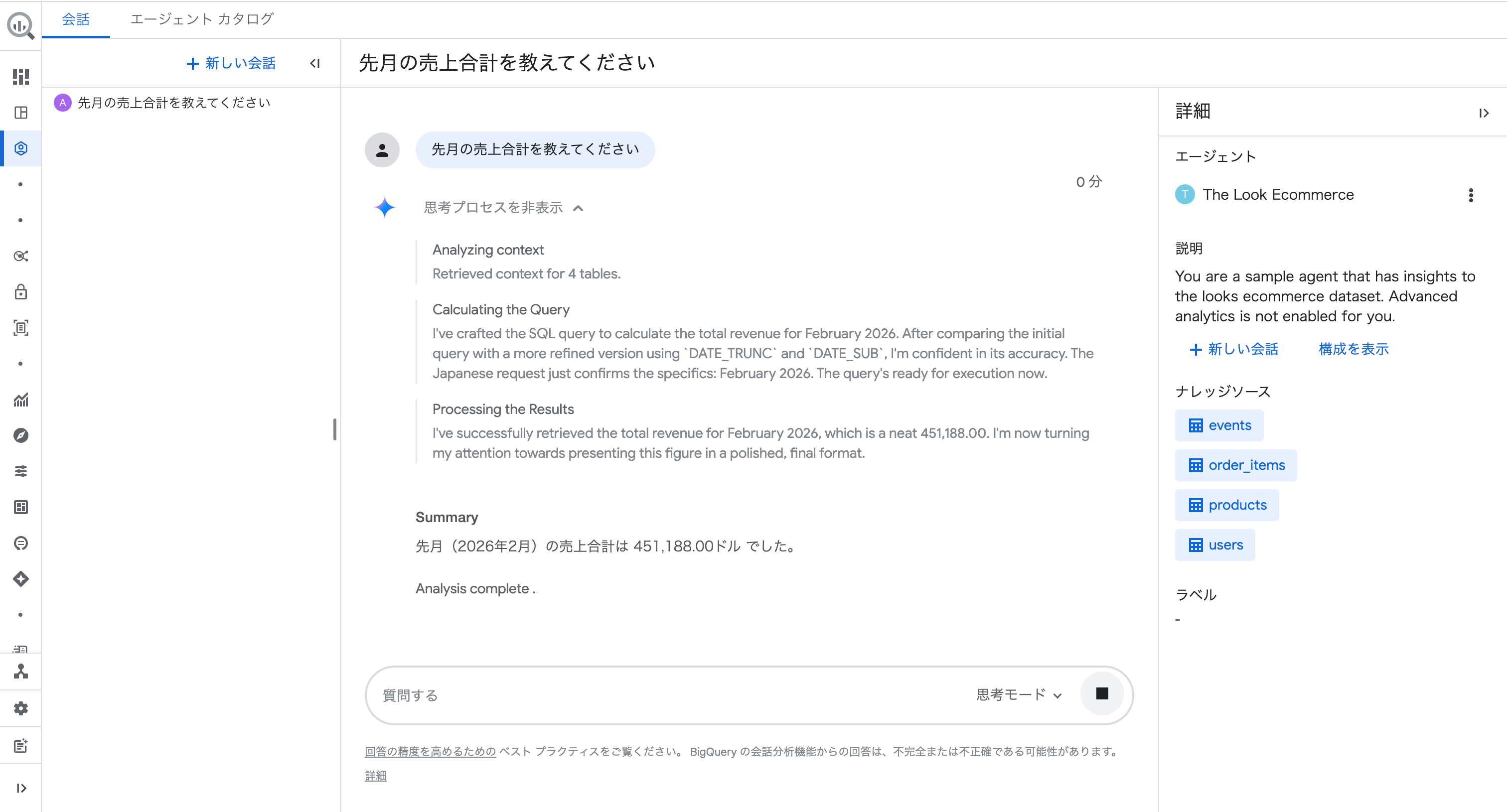
質問②:「先月のカテゴリ別の売上内訳を教えてください」(フォローアップ候補をクリック)
続いて、フォローアップ候補から深掘りしてみます。
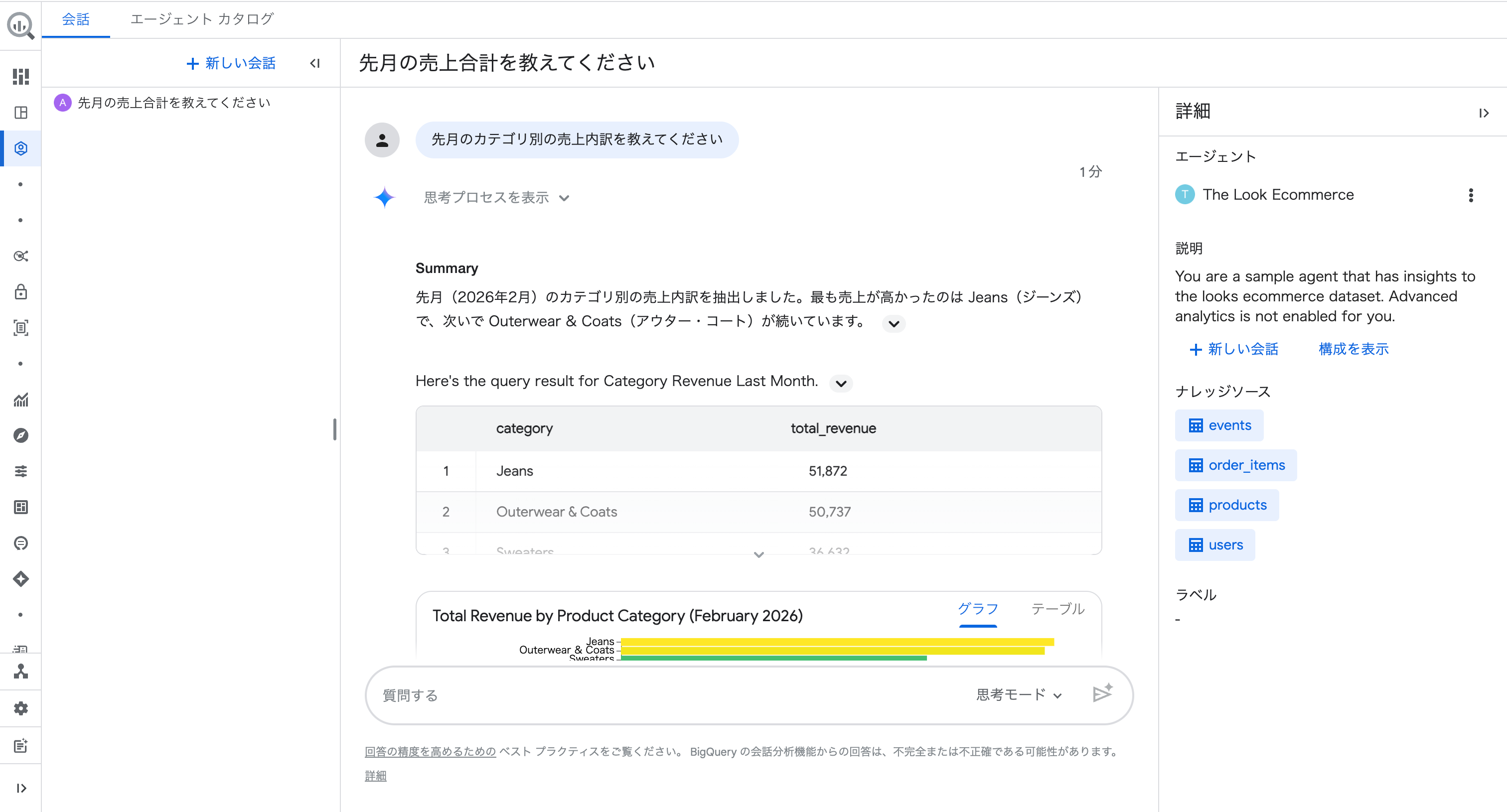
質問①の回答で提案されたフォローアップ候補をクリックしただけで、カテゴリ別の売上内訳が返ってきました。
会話の文脈を引き継いでくれるので、追加の条件を指定する必要がありません。
回答には表に加えて横棒グラフも自動で生成されました。
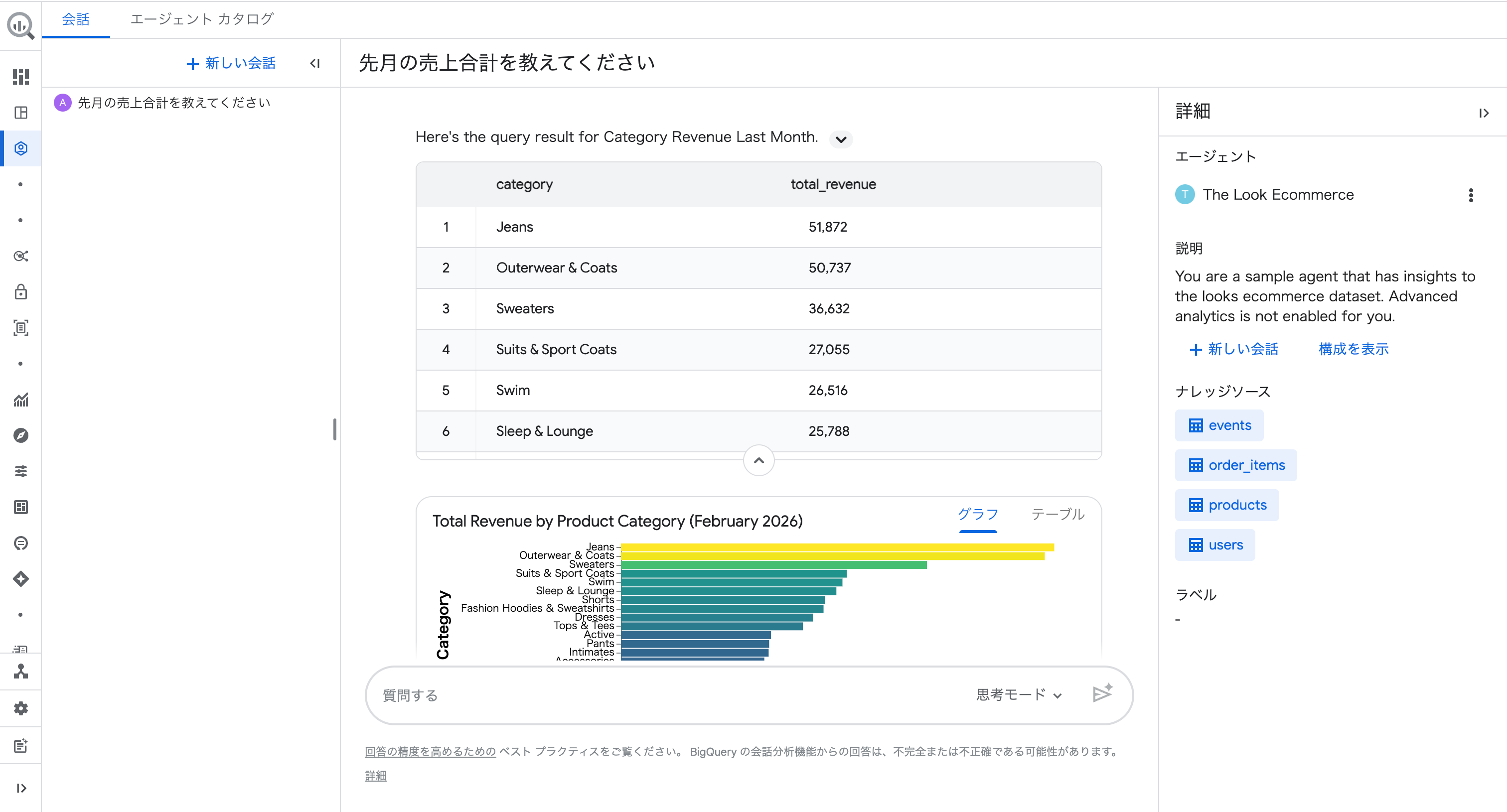
「グラフ」「テーブル」タブで表示を切り替えられます。
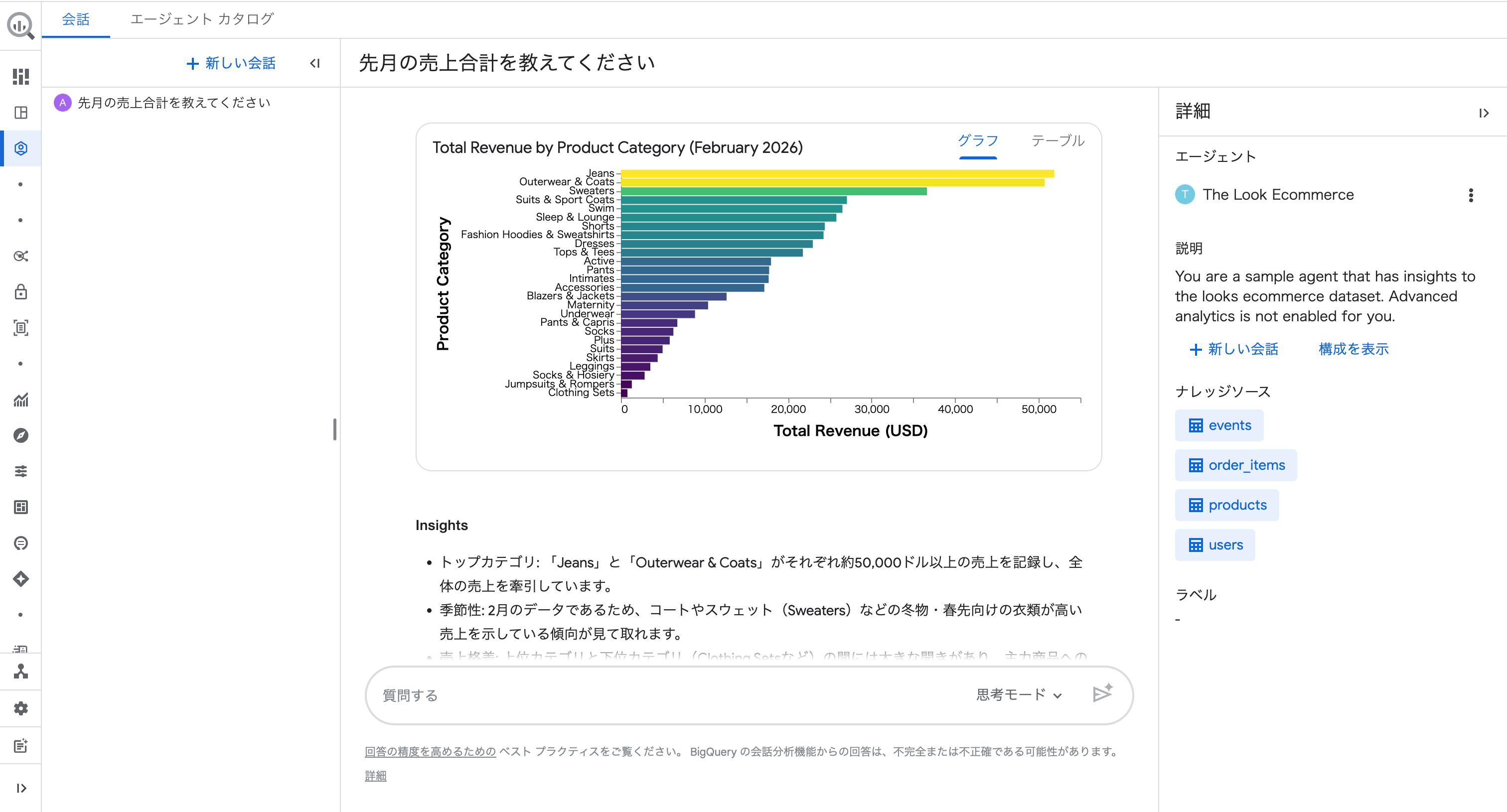
Insights では「Jeans と Outerwear & Coats がそれぞれ約50,000ドル以上の売上を記録し、全体の売上を牽引しています」「2月のデータであるため、コートやスウェットなどの冬物・春先向けの衣類が高い売上を示している傾向が見て取れます」といった分析コメントも返ってきました。
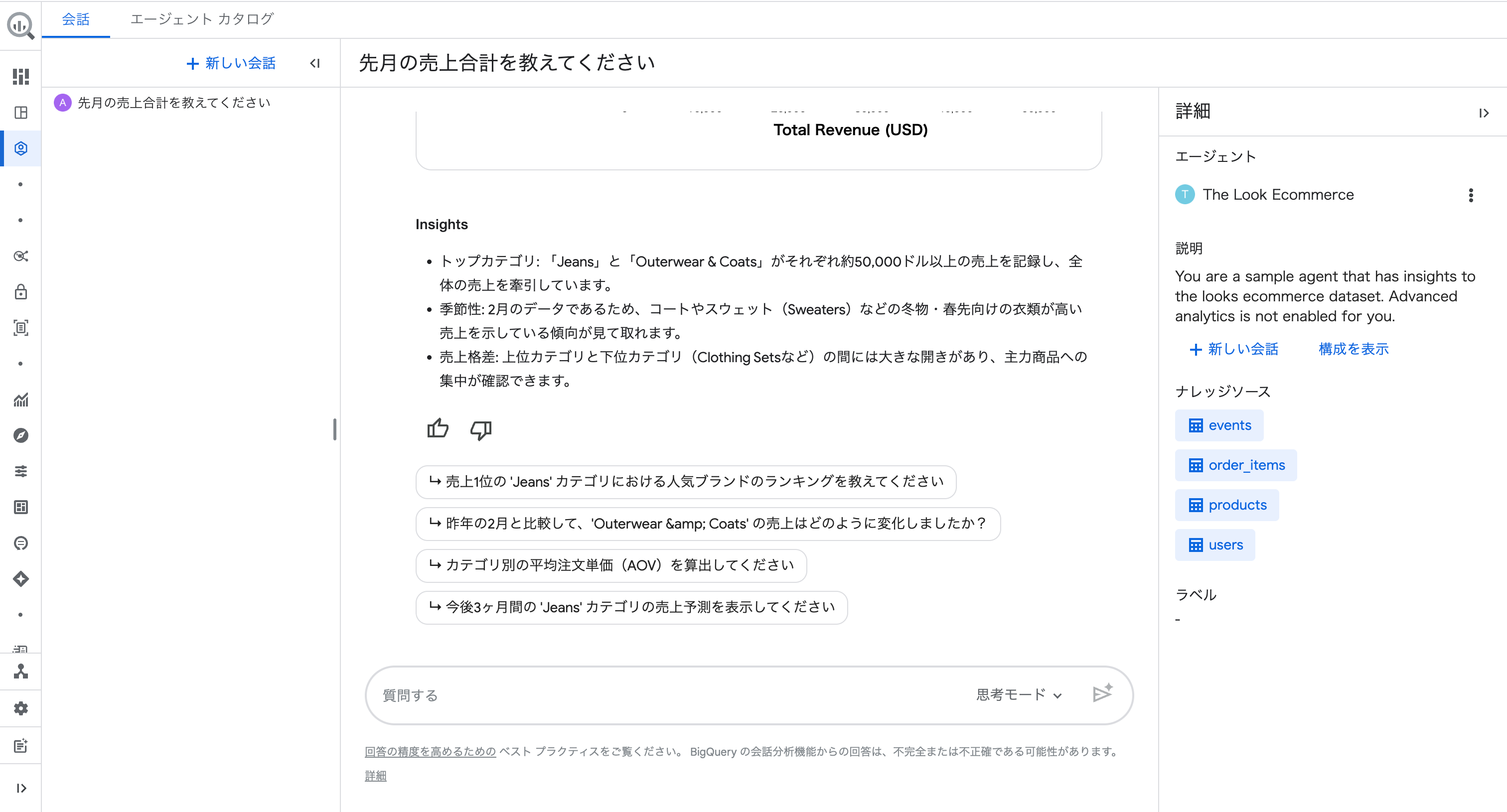
フォローアップ候補には「今後3ヶ月間の 'Jeans' カテゴリの売上予測を表示してください」という予測に関する質問もあります。
現状の分析だけでなく、予測もできるのでしょうか?
試してみましょう。
質問③:「今後3ヶ月間の 'Jeans' カテゴリの売上予測を表示してください」(フォローアップ候補をクリック)
質問②の結果で Jeans が売上1位だったので、このフォローアップ候補を選択しました。
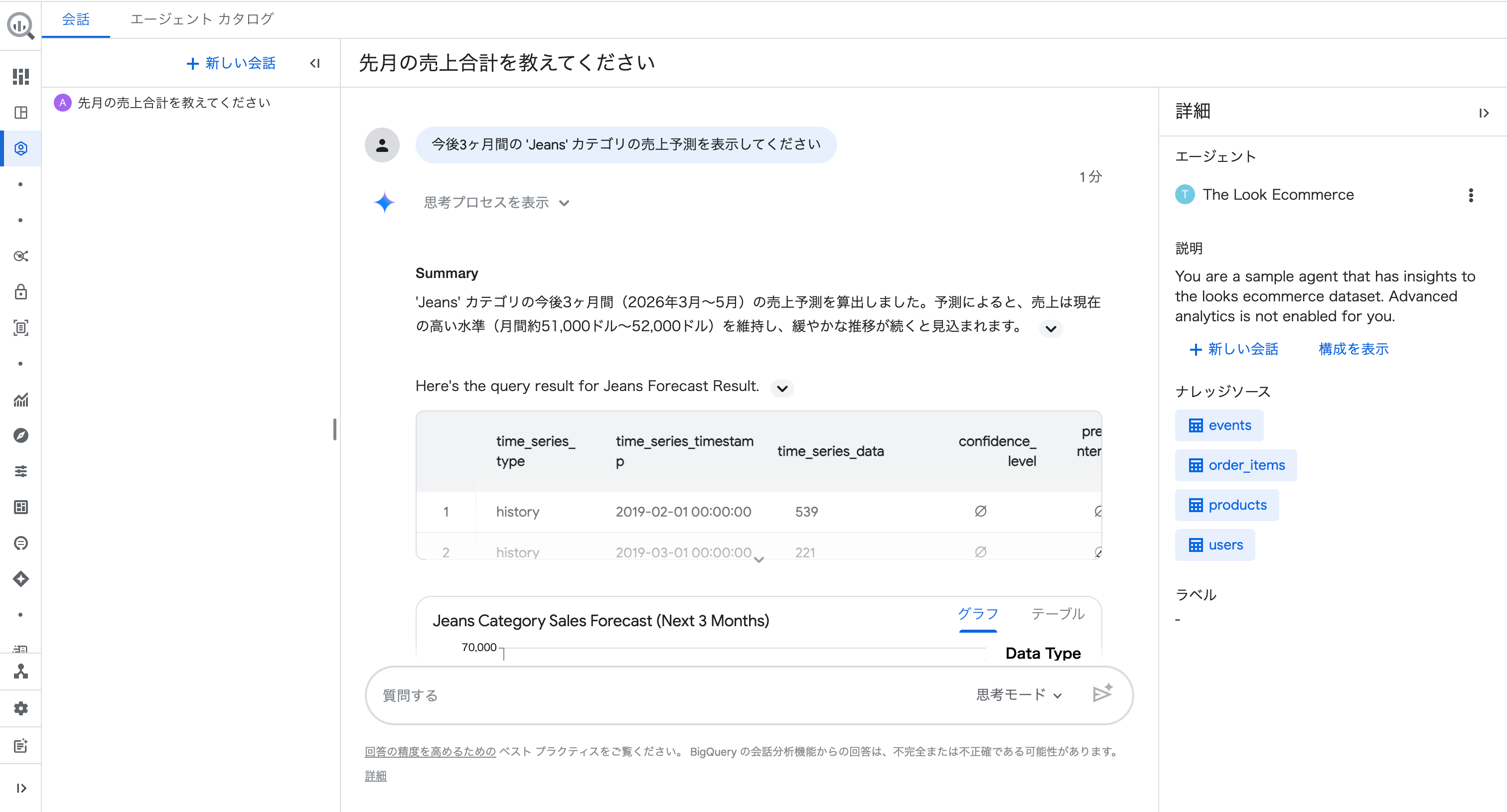
すると、過去の売上推移(青線)と今後3ヶ月の予測(オレンジ)が信頼区間付きのグラフで返ってきました。
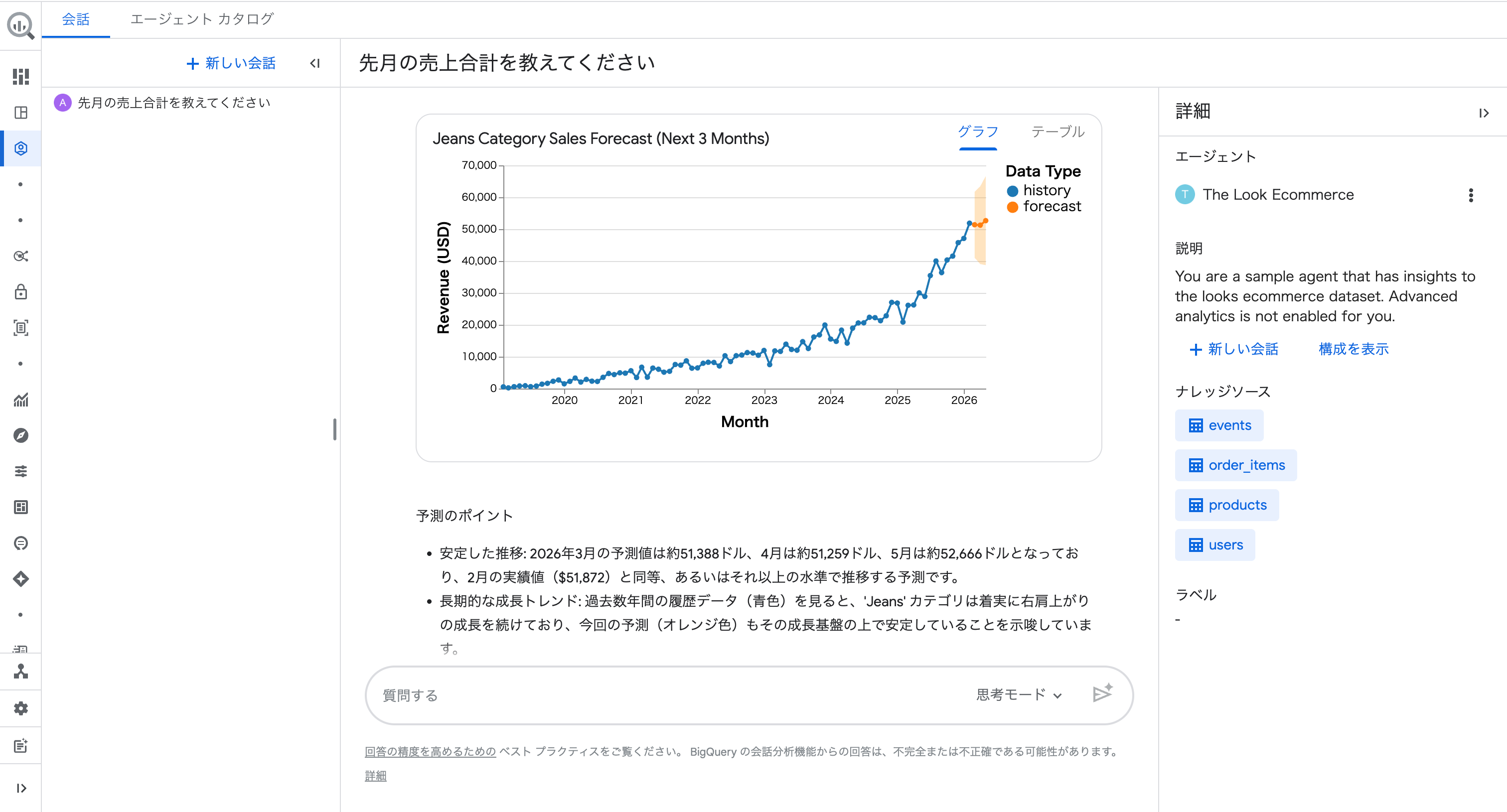
予測のポイントとして「2026年3月の予測値は約51,388ドル、4月は約51,259ドル、5月は約52,666ドルとなっており、2月の実績値($51,872)と同等、あるいはそれ以上の水準で推移する予測です」と具体的な数値が提示されました。
さらに Insights では「予測された売上水準に基づき、欠品を防ぐための在庫補充計画を立てるのが有効です」といったビジネスアクションの提案まで返ってきます。
SQL を書かずに自然言語だけで予測分析までできるのは便利ですね。
生成されたSQLを確認する
各回答の「SQL」セクションを展開すると、Gemini が生成した SQL を確認できます。
「エディタで開く」をクリックすれば BigQuery エディタにそのまま貼り付けることも可能です。
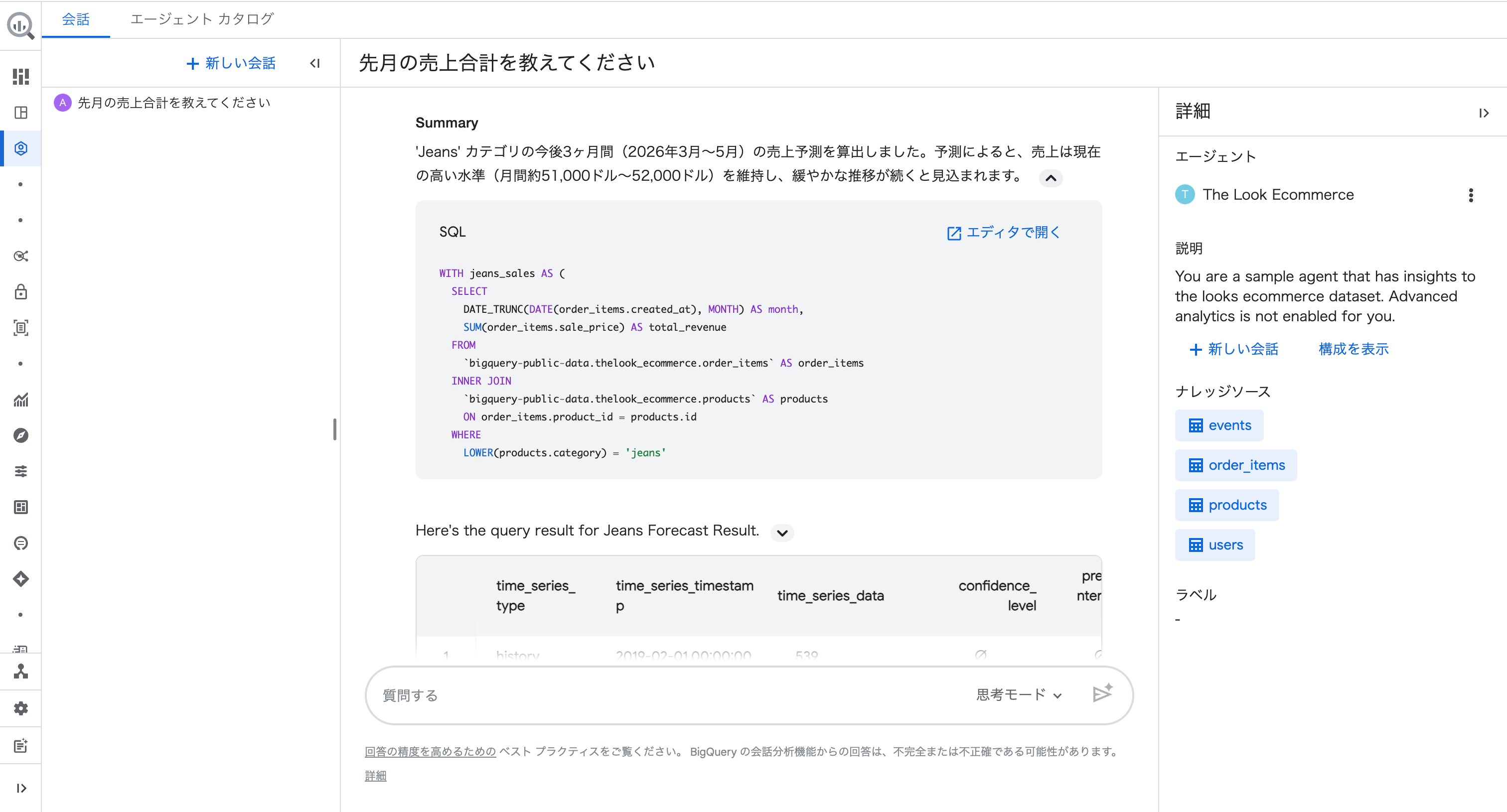
例えば、質問③の売上予測で生成された SQL は以下のとおりです。
WITH jeans_sales AS (
SELECT
DATE_TRUNC(DATE(order_items.created_at), MONTH) AS month,
SUM(order_items.sale_price) AS total_revenue
FROM
`bigquery-public-data.thelook_ecommerce.order_items` AS order_items
INNER JOIN
`bigquery-public-data.thelook_ecommerce.products` AS products
ON order_items.product_id = products.id
WHERE
LOWER(products.category) = 'jeans'
AND DATE(order_items.created_at) < DATE_TRUNC(CURRENT_DATE(), MONTH)
GROUP BY
month
)
SELECT
*
FROM
AI.FORECAST(
TABLE jeans_sales,
data_col => 'total_revenue',
timestamp_col => 'month',
horizon => 3,
output_historical_time_series => TRUE
)
ORDER BY
time_series_timestamp;
CTE で Jeans カテゴリの月次売上を集計し、BigQuery ML の AI.FORECAST 関数で3ヶ月先の予測を実行しています。
「売上予測を表示して」と自然言語で質問しただけで、裏側で ML 関数を含む SQL が自動生成されました。
「なぜこの結果になったの?」と疑問に思ったときに SQL を見て確認できますし、SQL の学習素材としても使えます。
初心者にとって「自然言語で質問 → SQL を見て理解」という学習フローが自然に生まれるのは良いですね!
自分でデータエージェントを作る
サンプルエージェントで感触をつかんだところで、自分でデータエージェントを作成してみます。
今回はサンプルエージェントと同じ TheLook Ecommerce(Google が提供する架空のECサイトのデモデータセット)を使って、自分でエージェントを構築してみます。
エージェントの新規作成
「会話」タブの上部にある「+ 新しいエージェント」をクリックします。
エージェント作成画面が開くので、エージェント名と説明を入力します。
今回は以下のように設定しました。
- エージェント名:
TheLook分析エージェント - エージェントの説明:
TheLook ECサイトの売上・ユーザー分析用エージェント
続いて、「ソースを追加」をクリックしてナレッジソースを登録します。
① ナレッジソース(テーブルの登録)
「ソースを追加」から分析対象のテーブル・ビューを選択します。
「ソースを検索」欄に bigquery-public-data.thelook_ecommerce と入力して検索すると、データセット内のテーブル一覧が表示されます。
今回は以下の3テーブルを選択して登録しました。
order_items(注文明細)users(ユーザー情報)products(商品情報)
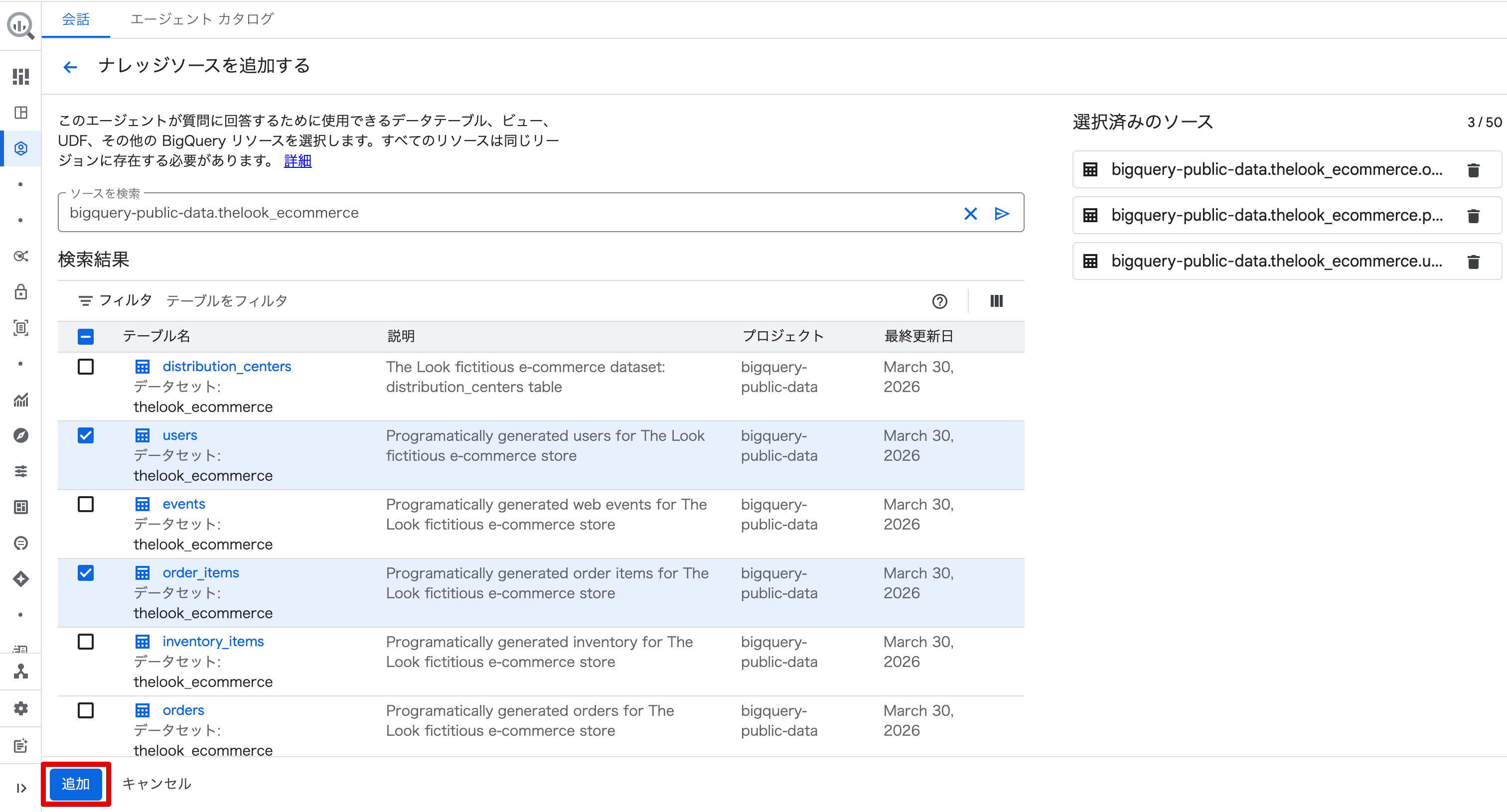
3テーブルを選択して [追加] をクリックします。
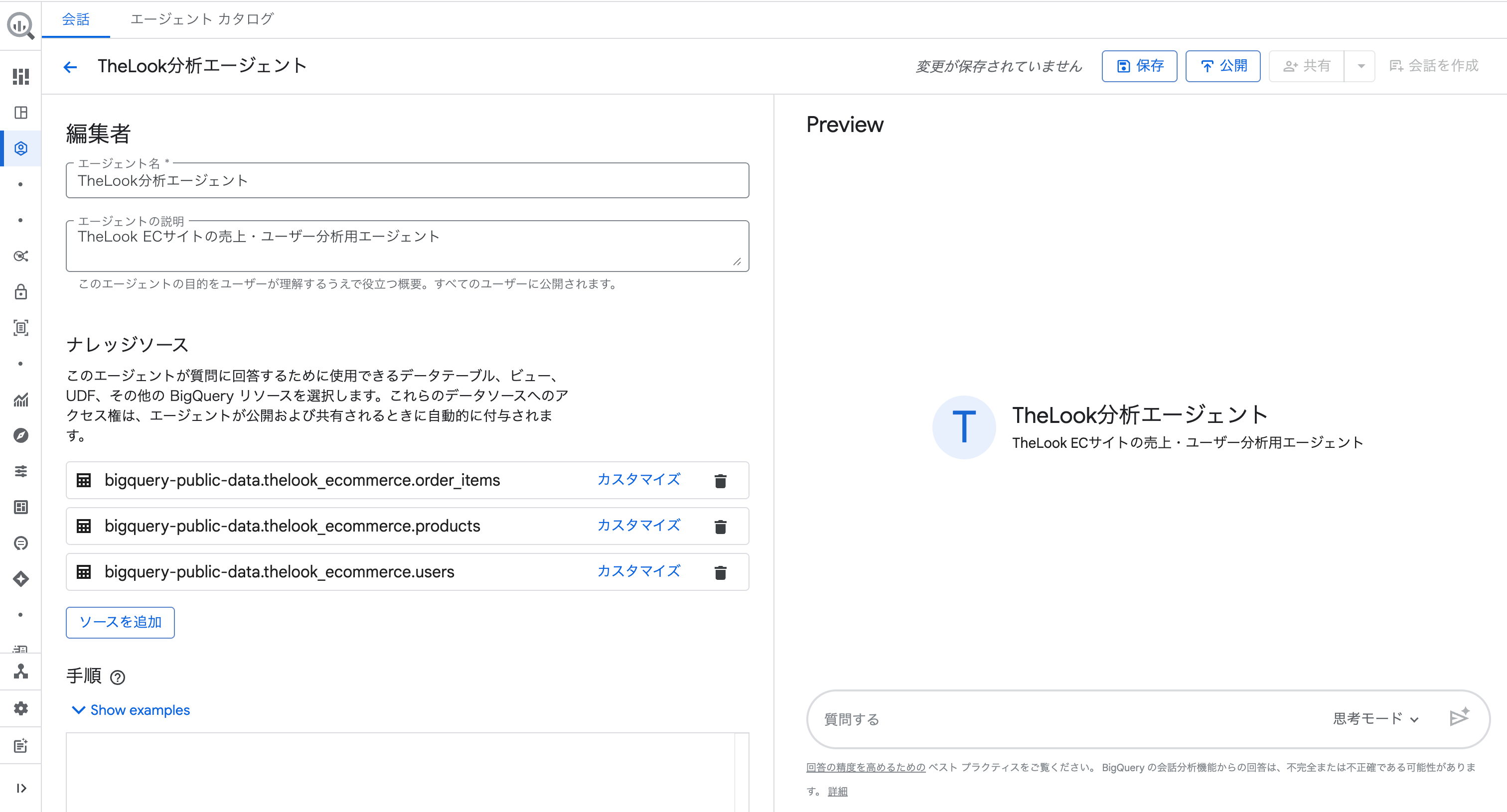
ナレッジソースに3テーブルが追加されました。
各テーブルの「カスタマイズ」からカラムの説明(メタデータ)を付与することもできます。
カラムの意味を Gemini に正確に伝えることで回答精度が向上するため、本格利用する際は設定しておくと良いでしょう。
② 手順(指示の定義)
エージェントへの指示を自然言語で記述します。
ビジネスロジックや計算ルールをここに書きます。
「Show examples」をクリックすると、Gemini が手順の記述例を提案してくれます。
どのような指示を書けばよいか迷ったときに参考になります。
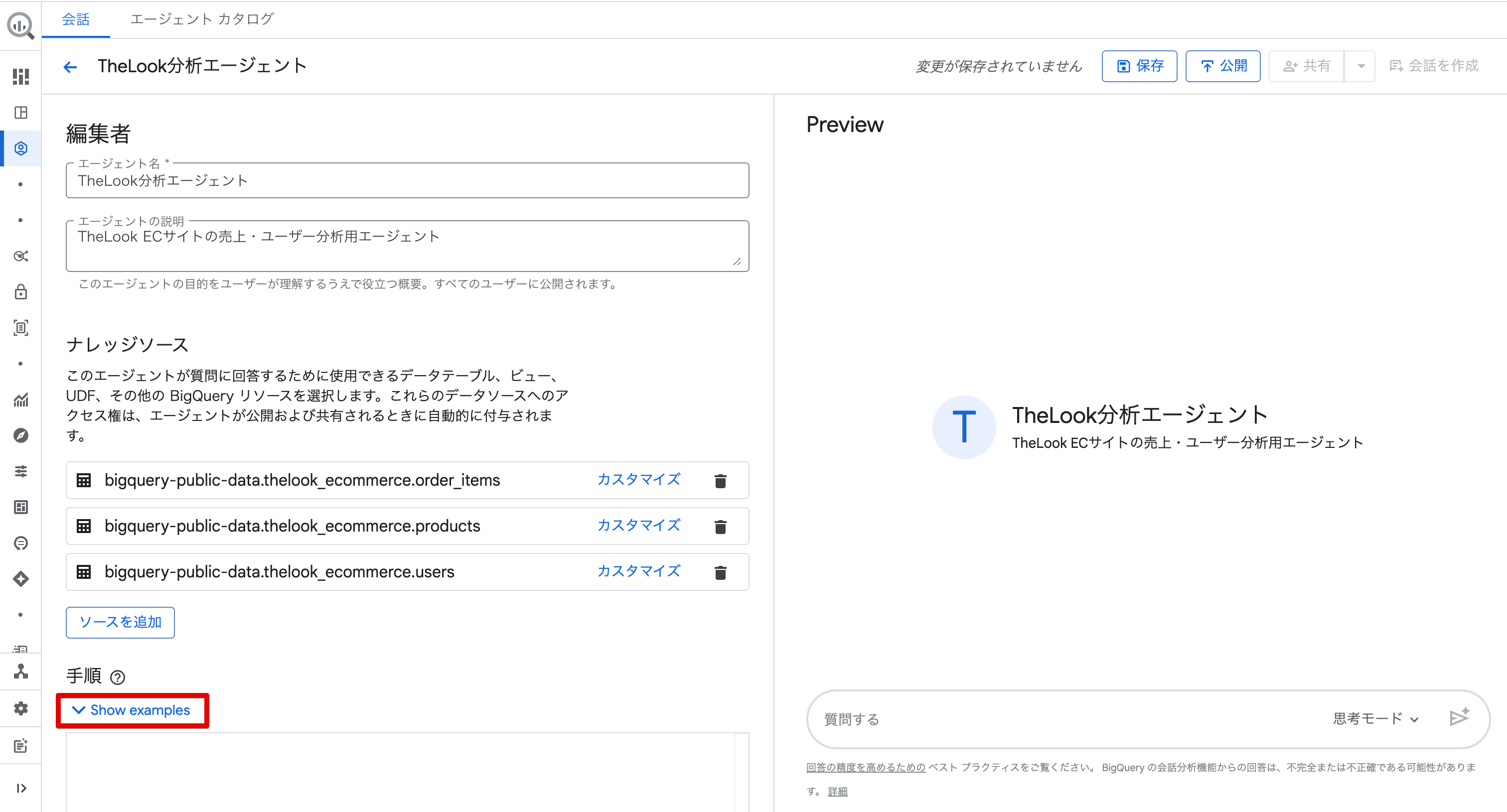
今回は以下の内容を入力しました。
- 売上は order_items テーブルの sale_price カラムを使用してください
- 日付指定がない場合は、直近1ヶ月のデータで集計してください
- ステータスが "Complete" の注文のみを集計対象としてください
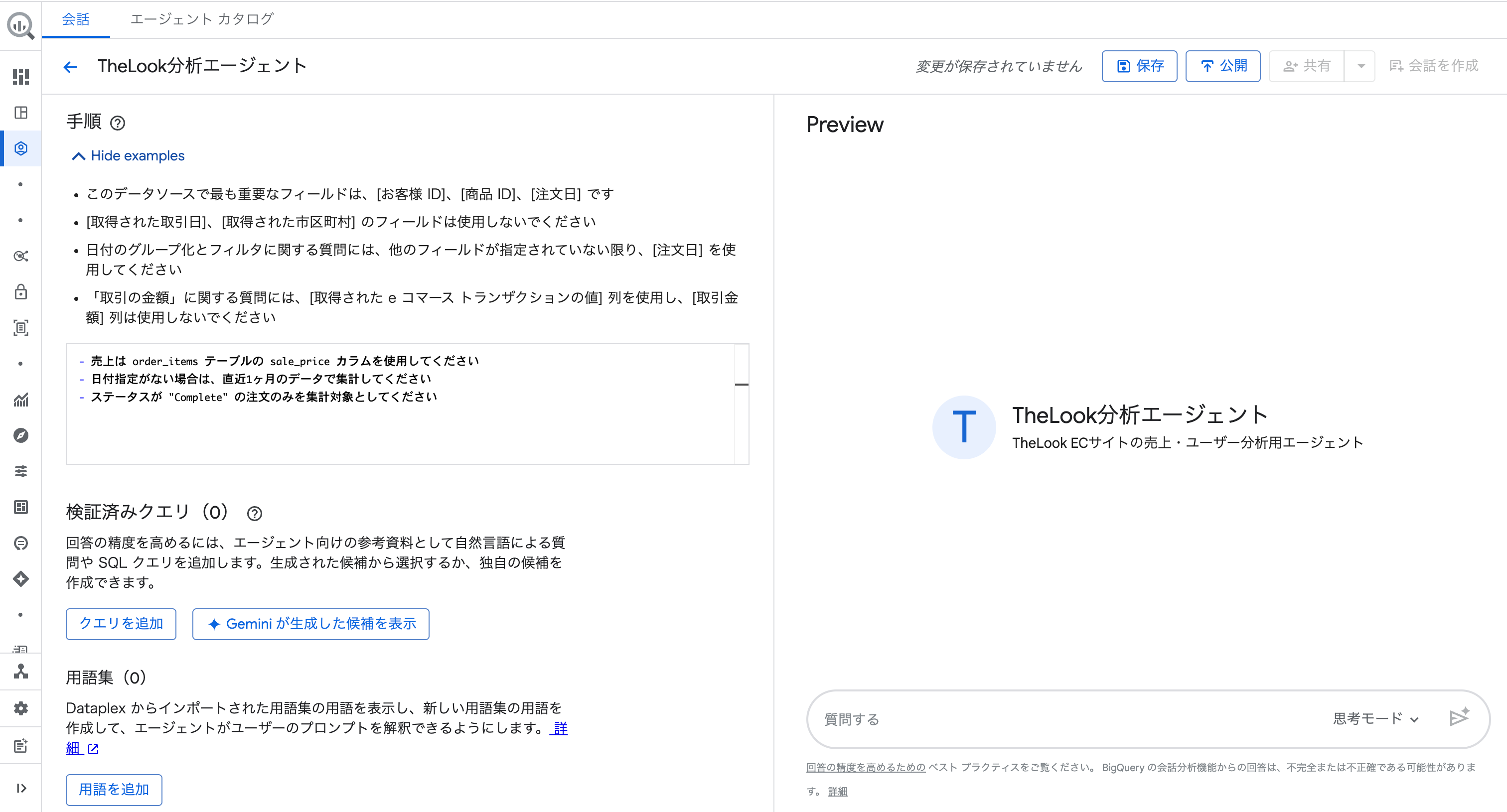
③ その他の設定
エージェント作成画面では、手順のほかにも以下の設定が可能です。
| 設定項目 | 説明 |
|---|---|
| 検証済みクエリ | よく使う質問と正解SQLをセットで登録できる 「Gemini が生成した候補を表示」から候補を自動生成することも可能 |
| 用語集 | ビジネス用語(例:「売上」)と実際のカラム名・計算式の対応を定義できる Dataplex の用語集をインポートすることも可能 |
| 課金される最大バイト数 | 1クエリあたりの最大スキャンバイト数を制限できる コスト管理の観点から本番運用前に設定しておくと安心 |
今回は入門記事のため、手順の設定のみで進めます。
検証済みクエリや用語集を充実させることで、回答精度をさらに向上させることができます。
エージェントを公開する
設定完了後、右上の「公開」ボタンをクリックすると、「チャンネルの公開」ダイアログが表示されます。
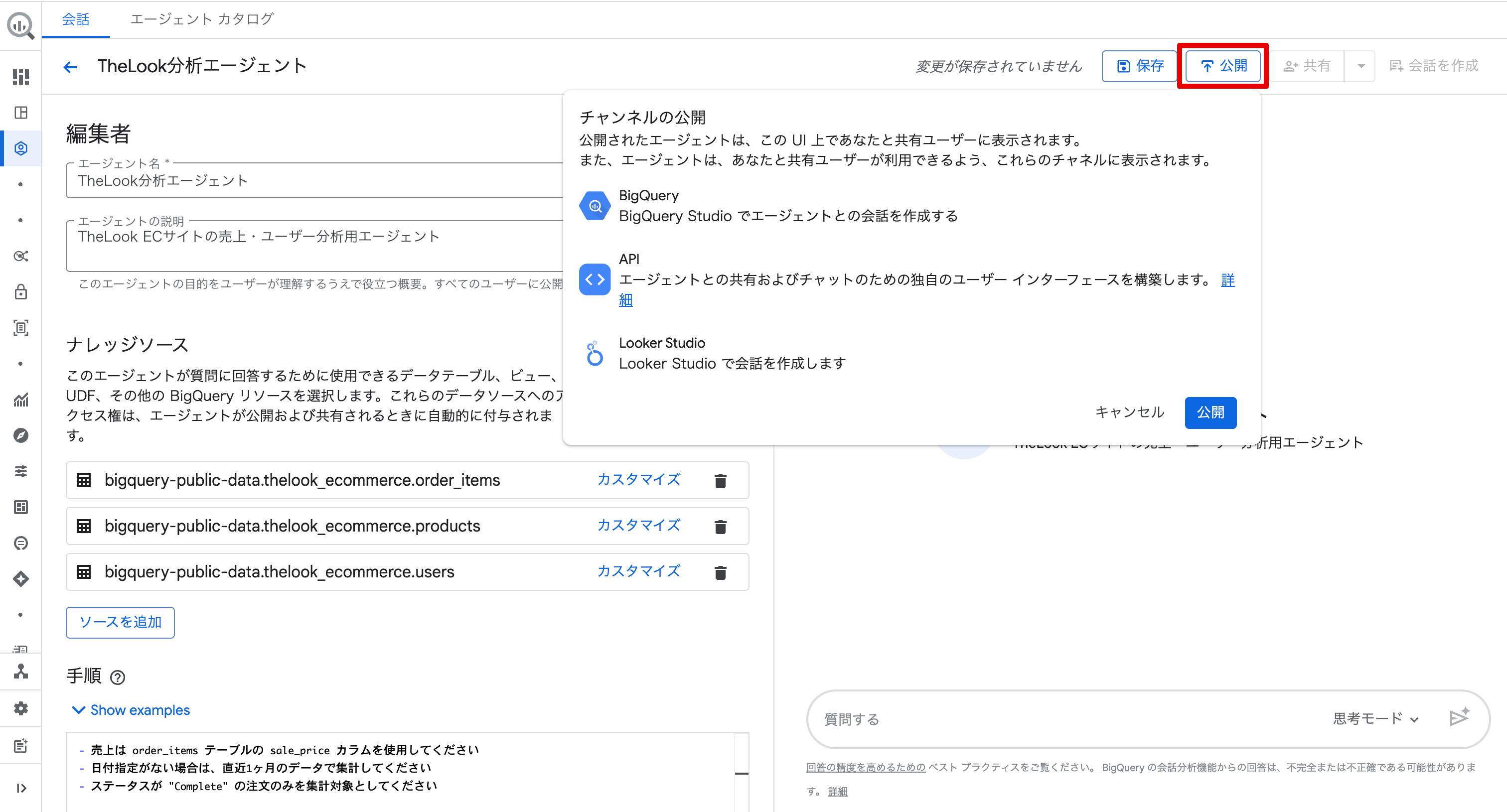
BigQuery Studio・API・Looker Studio の3つのチャンネルで利用可能になることが確認できます。
API を使えば独自の UI を構築できますし、Looker Studio からも直接会話を作成できます。
「保存」と「公開」の違い
「保存」はエージェントの設定を保存するだけです。
「公開」するとプロジェクト内でエージェントが利用可能な状態になります。
ただし、他のユーザーが利用するには公開後に「共有」で個別にアクセス権を付与する必要があります。
エージェントが公開されました。
[閉じる] をクリックしてダイアログを閉じます。
質問してみる
作成したエージェントに対して実際に質問してみましょう。
公開が完了したら、右上の「会話を作成」をクリックします。
会話画面が開きます。
右側のナレッジソースに登録した3テーブル(order_items / products / users)が表示されていることを確認できます。
手順に設定したルールが正しく反映されるかを確認するため、あえて日付を指定せずに質問してみます。
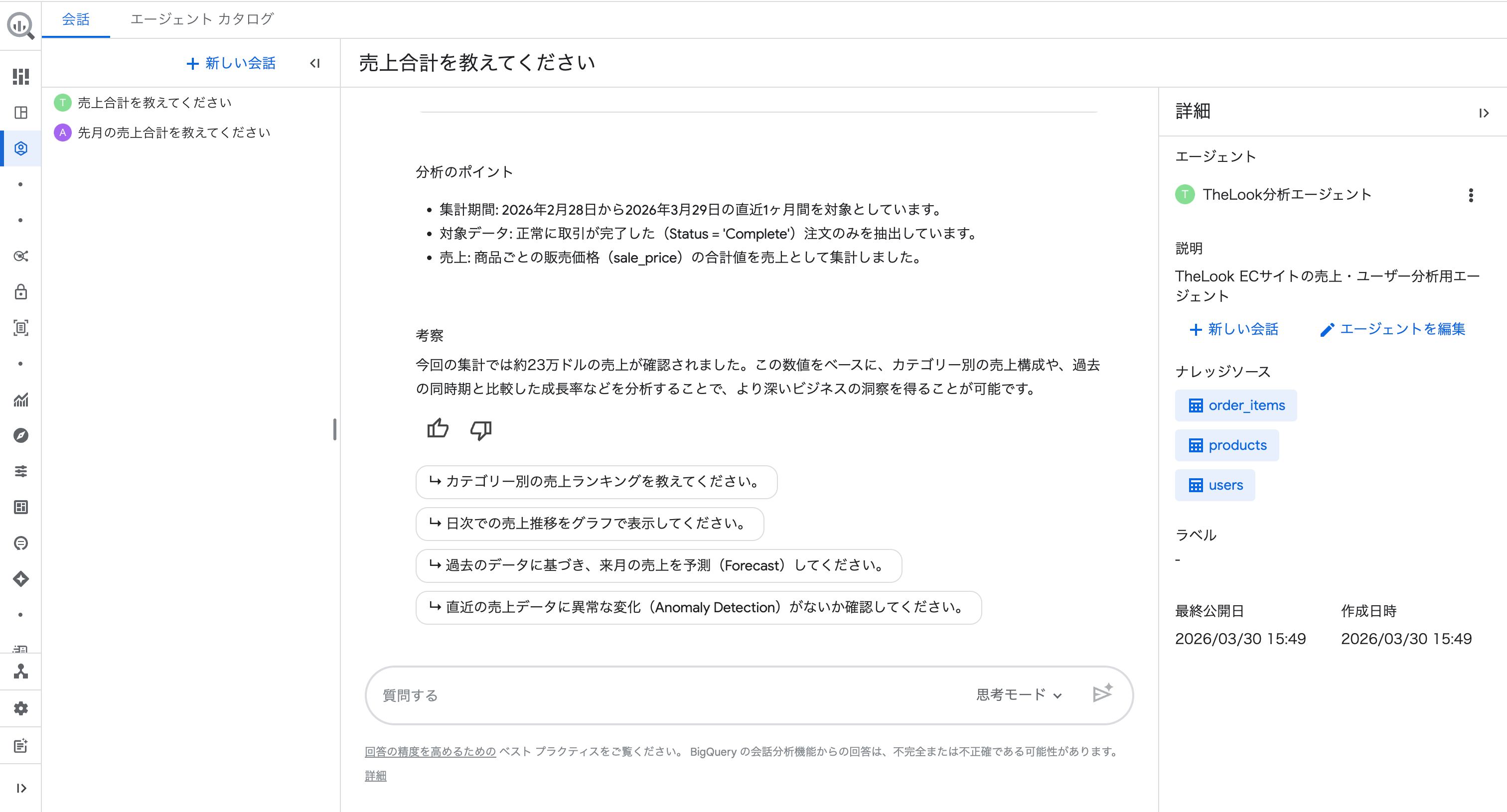
質問:「売上合計を教えてください」
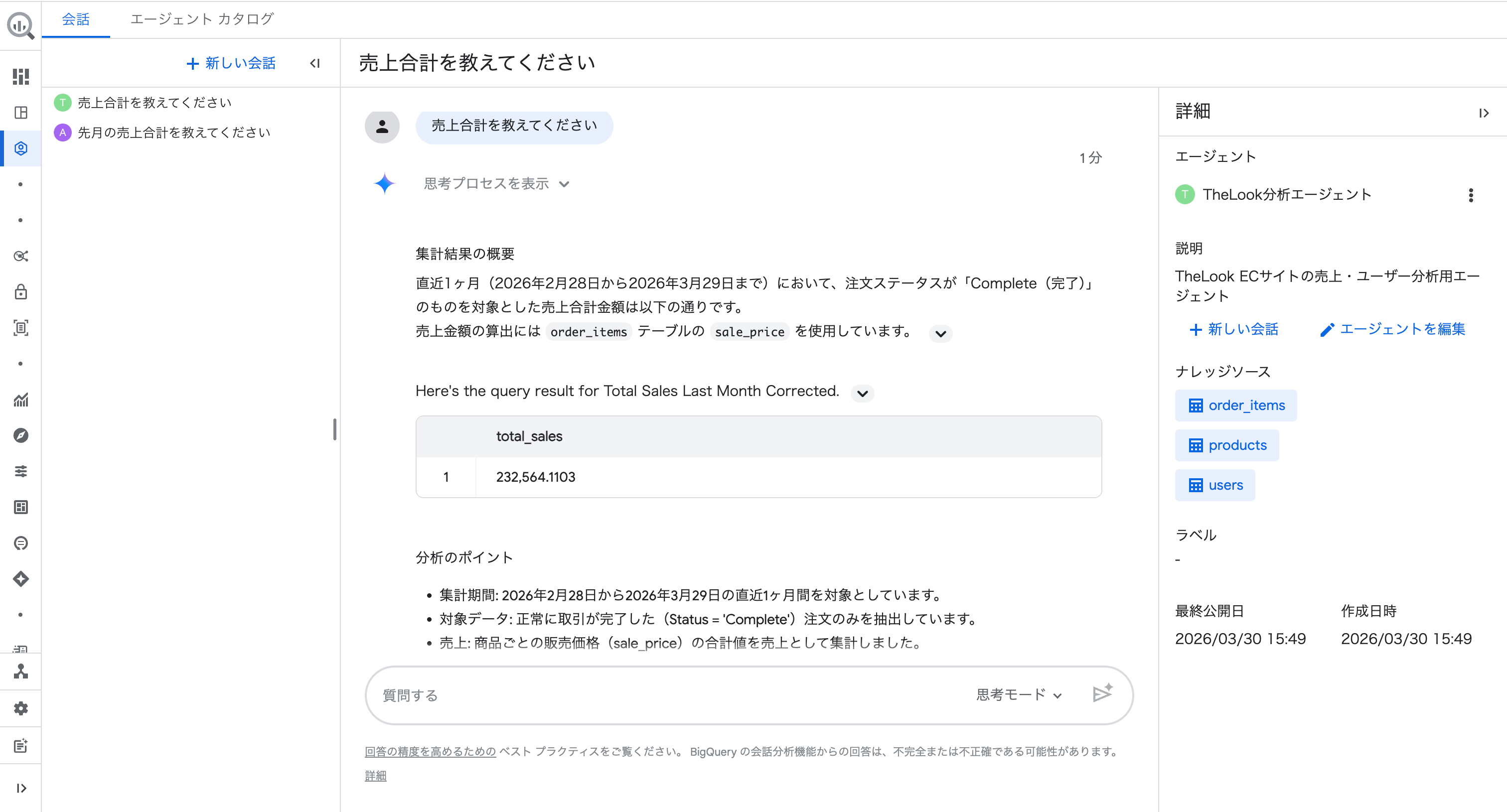
回答には「分析のポイント」として以下が明示されました。
- 集計期間:2026年2月28日から2026年3月29日の直近1ヶ月間
- 対象データ:正常に取引が完了した(
Status = 'Complete')注文のみ - 売上:商品ごとの販売価格(
sale_price)の合計値
生成された SQL を確認すると、手順で定義した3つのルールがすべて WHERE 句に反映されています。
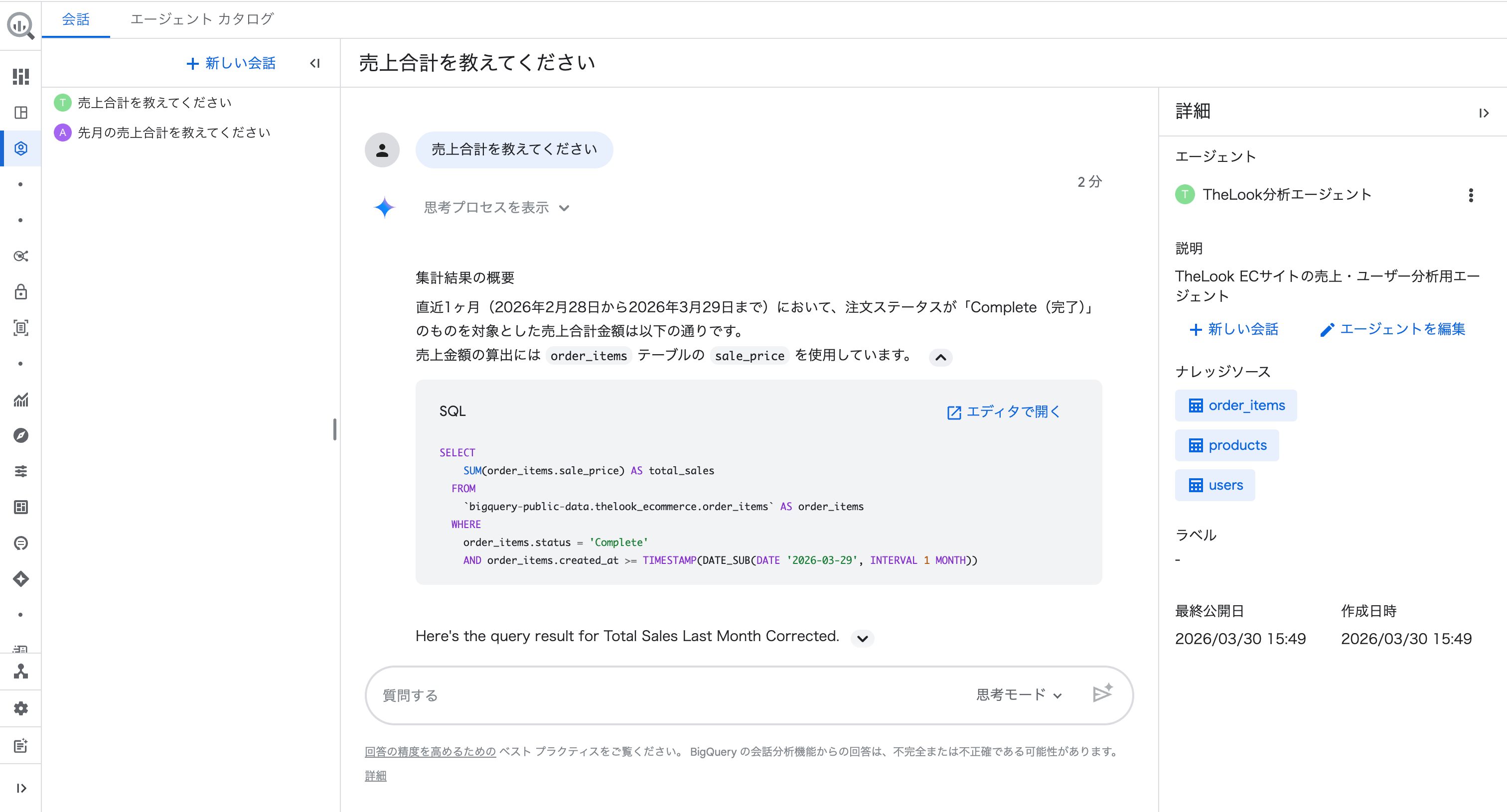
SELECT
SUM(order_items.sale_price) AS total_sales
FROM
`bigquery-public-data.thelook_ecommerce.order_items` AS order_items
WHERE
order_items.status = 'Complete'
AND order_items.created_at >= TIMESTAMP(DATE_SUB(DATE '2026-03-29', INTERVAL 1 MONTH))
日付を指定しなくても直近1ヶ月に絞られ、status = 'Complete' のフィルタも適用されています。
手順にビジネスルールを定義しておくことで、ユーザーがシンプルな質問をしても意図した条件で分析が実行されることが確認できました。
サンプルエージェントとの比較
参考までに、サンプルエージェントで「先月の売上合計を教えてください」と質問したときの SQL と比較してみます。
サンプルエージェントの SQL:
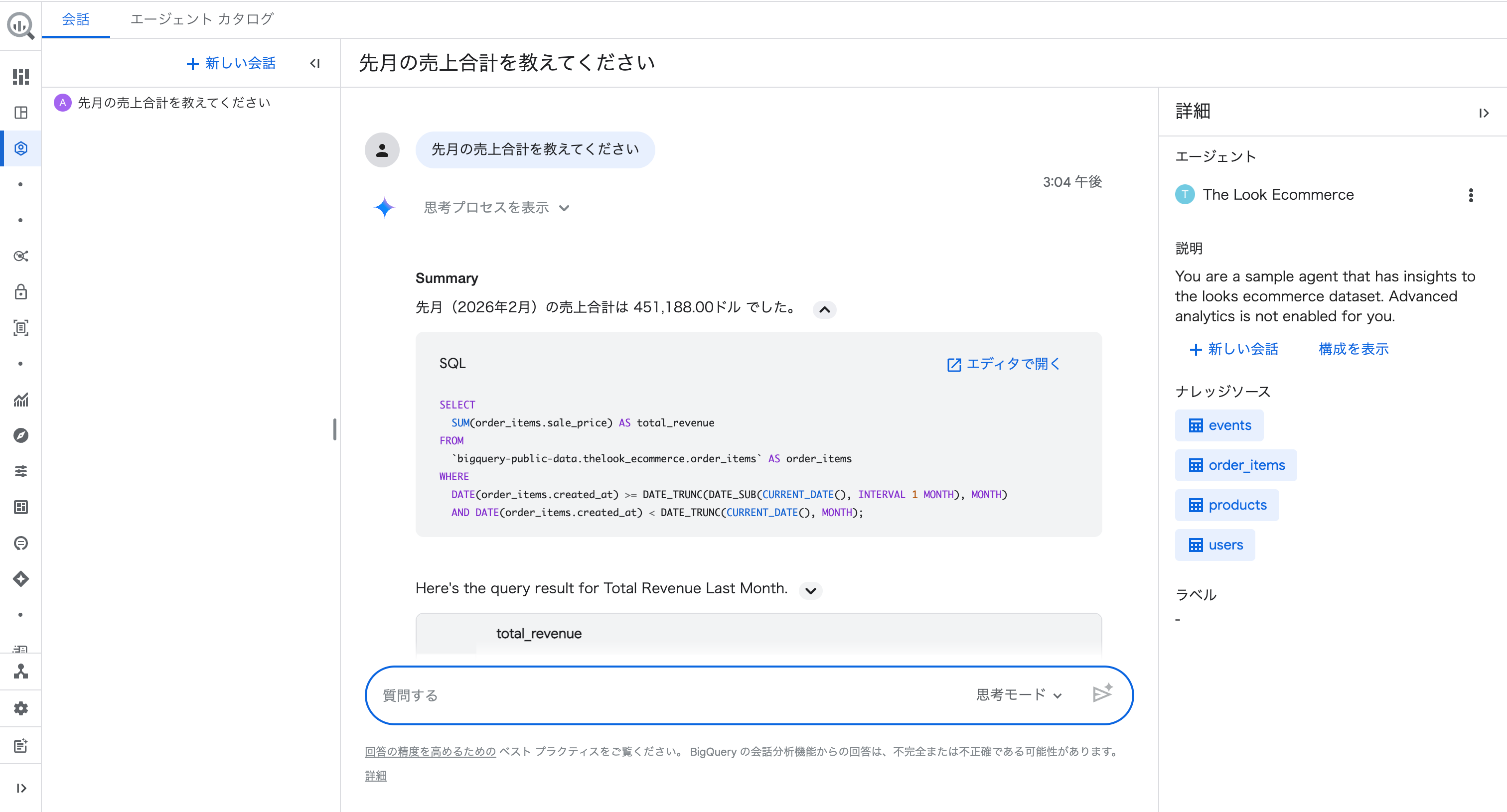
SELECT
SUM(order_items.sale_price) AS total_revenue
FROM
`bigquery-public-data.thelook_ecommerce.order_items` AS order_items
WHERE
DATE(order_items.created_at) >= DATE_TRUNC(DATE_SUB(CURRENT_DATE(), INTERVAL 1 MONTH), MONTH)
AND DATE(order_items.created_at) < DATE_TRUNC(CURRENT_DATE(), MONTH);
| サンプルエージェント | 自作エージェント | |
|---|---|---|
status = 'Complete' フィルタ |
なし | あり |
| 日付の絞り方 | 先月(月単位) | 直近1ヶ月(日単位) |
サンプルエージェントにはステータスのフィルタがなく、キャンセルや返品を含めた売上になっています。
一方、自作エージェントでは手順で定義したルールに従い、完了済みの注文のみが集計対象になっています。
このように、手順を定義することでビジネスロジックに沿った正確な分析が可能になります。
まとめ
以上、BigQuery の Conversational Analytics を試してみました。
実際に使ってみて、チャットでデータ分析ができる体験がとても良かったです。
特に以下の点が便利だと感じました。
- SQL を書かなくても自然言語で BigQuery のデータを分析できる
- フォローアップ候補をクリックするだけで、会話の流れで深掘り分析ができる
- 生成された SQL を確認できるため、SQL の学習素材としても使える
- 自作エージェントで手順(ビジネスルール)を定義しておけば、シンプルな質問でも意図した条件で分析が実行される
今回は基本的な集計と予測を試しましたが、検証済みクエリや用語集を整備することで回答精度をさらに向上させることができます。
また、API や Looker Studio からも利用できるので、活用の幅は広そうです。
これらの機能も機会があれば、触ってみようと思います。
なお、プレビュー段階のため今後仕様が変更される可能性があります。
また、Gemini の出力は必ず生成 SQL で検証してから活用するようにしましょう。
「データは触ってみたいけどSQLは難しそう」という方にとって、まずデータとの対話を体験できる良い入口になると感じました。
サンプルエージェントを使えばセットアップ不要ですぐに試せるので、ぜひ皆様の業務でも活用してみてはいかがでしょうか?










