
BigQueryでの権限制御まとめ〜承認済みビュー・承認済みデータセット・行列アクセス制御・データマスキング〜
はじめに
こんにちは、データ事業本部の渡部です。
今回はBigQueryの権限制御における主要機能を実際に試しつつまとめます。
タイトルの通り、以下を検証していきます。
- 承認済みビュー
- 承認済みデータセット
- 行列アクセス制御
- データマスキング
前提
今回使用するデータセット・テーブルは以下のとおりです。
- データセット:
sample_watanabe_store - テーブル:
products
CREATE TABLE `projects.sample_watanabe_store.products`
(
product_id INT64,
product_name STRING,
category STRING,
price FLOAT64,
stock_quantity INT64
);
| product_id | product_name | category | price | stock_quantity |
|---|---|---|---|---|
| 1 | iPhone 15 | Electronics | 129800.0 | 50 |
| 2 | MacBook Air | Electronics | 164800.0 | 25 |
| 3 | Nike Air Max | Shoes | 12100.0 | 100 |
| 4 | Levi's Jeans | Clothing | 8900.0 | 75 |
| 5 | コーヒーメーカー | Appliances | 15400.0 | 30 |
| 6 | ワイヤレスイヤホン | Electronics | 19800.0 | 80 |
| 7 | ランニングシューズ | Shoes | 9800.0 | 60 |
| 8 | Tシャツ | Clothing | 2980.0 | 200 |
また上記テーブルをソースとするビュー定義は以下です。またテーブルとは別のデータセットに作成します。
- ビュー:
products_view
CREATE VIEW `projects.dataset01.products_view` AS (
SELECT
product_id,
product_name,
price,
stock_quantity
FROM
`sample_watanabe_store.products`
)
承認済みビュー
とは?
承認済みビューは名前からはどういうものかが想像しづらいのですが、元のテーブルへのアクセス権を承認されたビューのことです。
もしユーザーに対して普通のビューの参照権限を与えるとなった場合は、その元となるテーブルに対しても権限がなければ参照することはできません。本来ビューを見せたいのにテーブルも見れるとなったら困る場面もありますね。
対して承認済みビューはビューの参照権限さえあれば、元となるテーブルに対して参照権限をふらずとも参照可能です。
よく承認済みビューの承認の意味を混同してしまうのですが、
承認済みビューはソーステーブルが所属するデータセットに対して「ビューからのアクセスを承認する」というもので、ユーザーに対して参照権限を承認したビューというものではありません。
ユーザーへの参照権限は別に設定する必要があります。
試してみる
ビューをテーブルのデータセットとは異なるdataset_01に作成します(異なるデータセットに作成しないといけないわけではないですが、権限設定の運用上のわかりやすさからわけます)。
productsテーブルへのSELECTクエリをBigQueryコンソールで実行し、保存から「ビューを保存」を選択します。これでビューが作成されます。
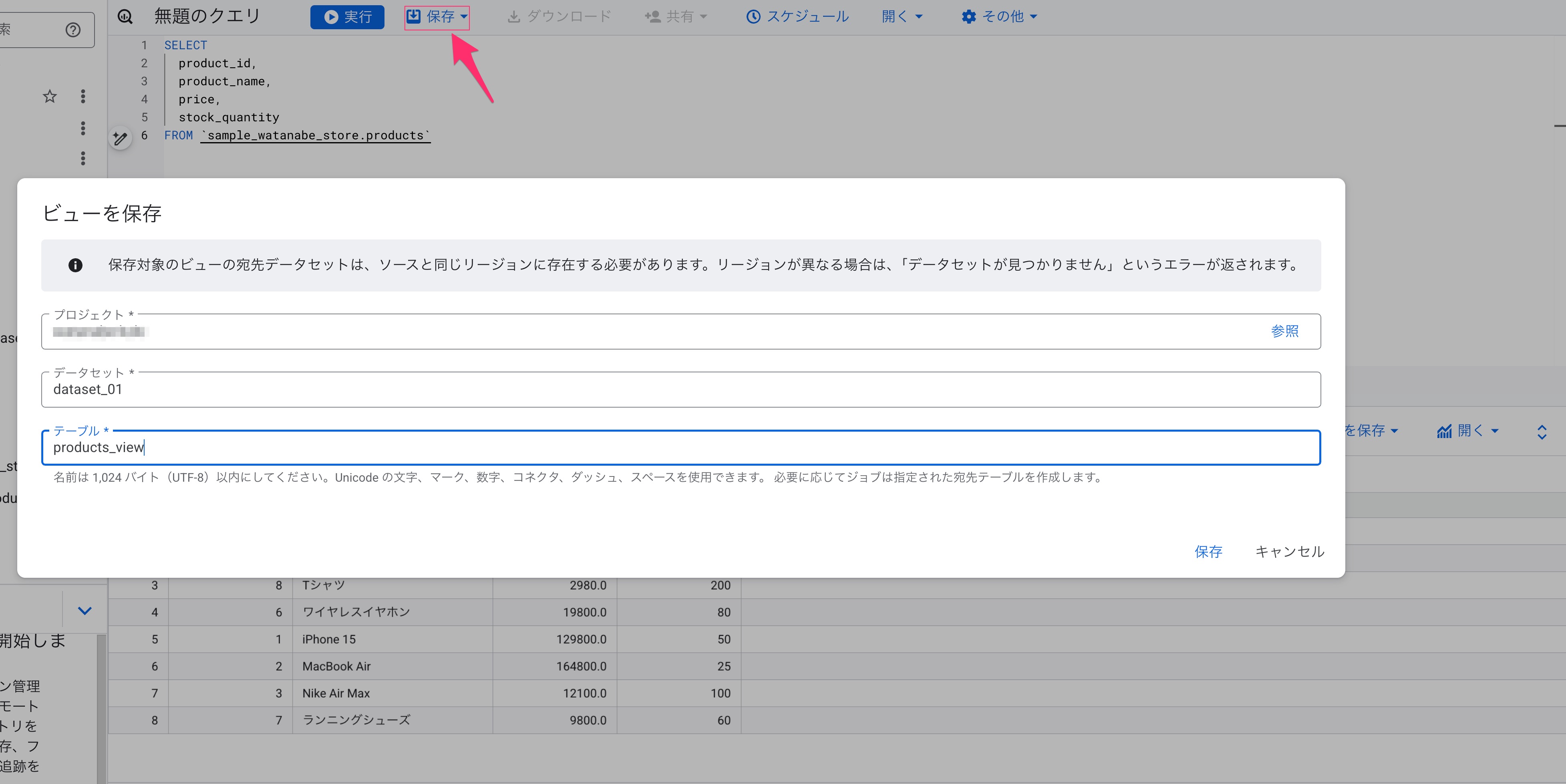
続いてビューに対してアクセス権をユーザーに付与します。
products_viewの「共有」から「Share」を選択します。
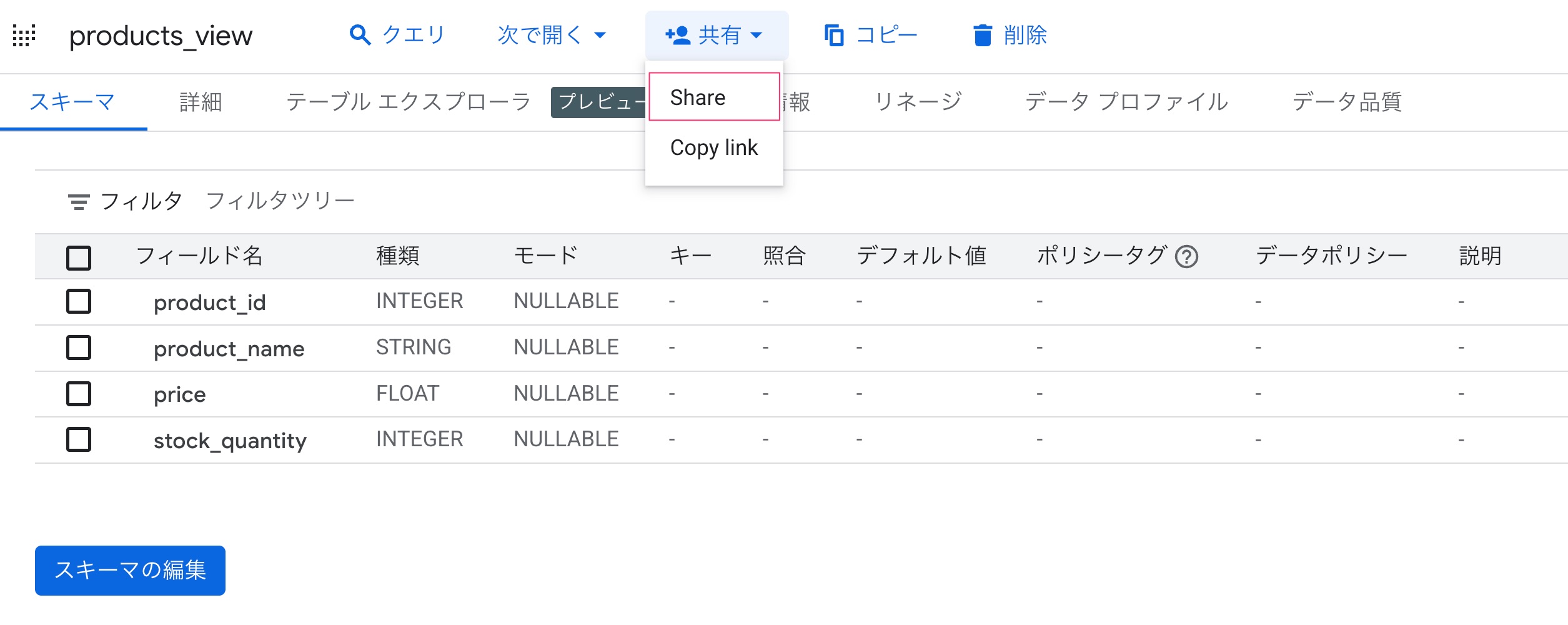
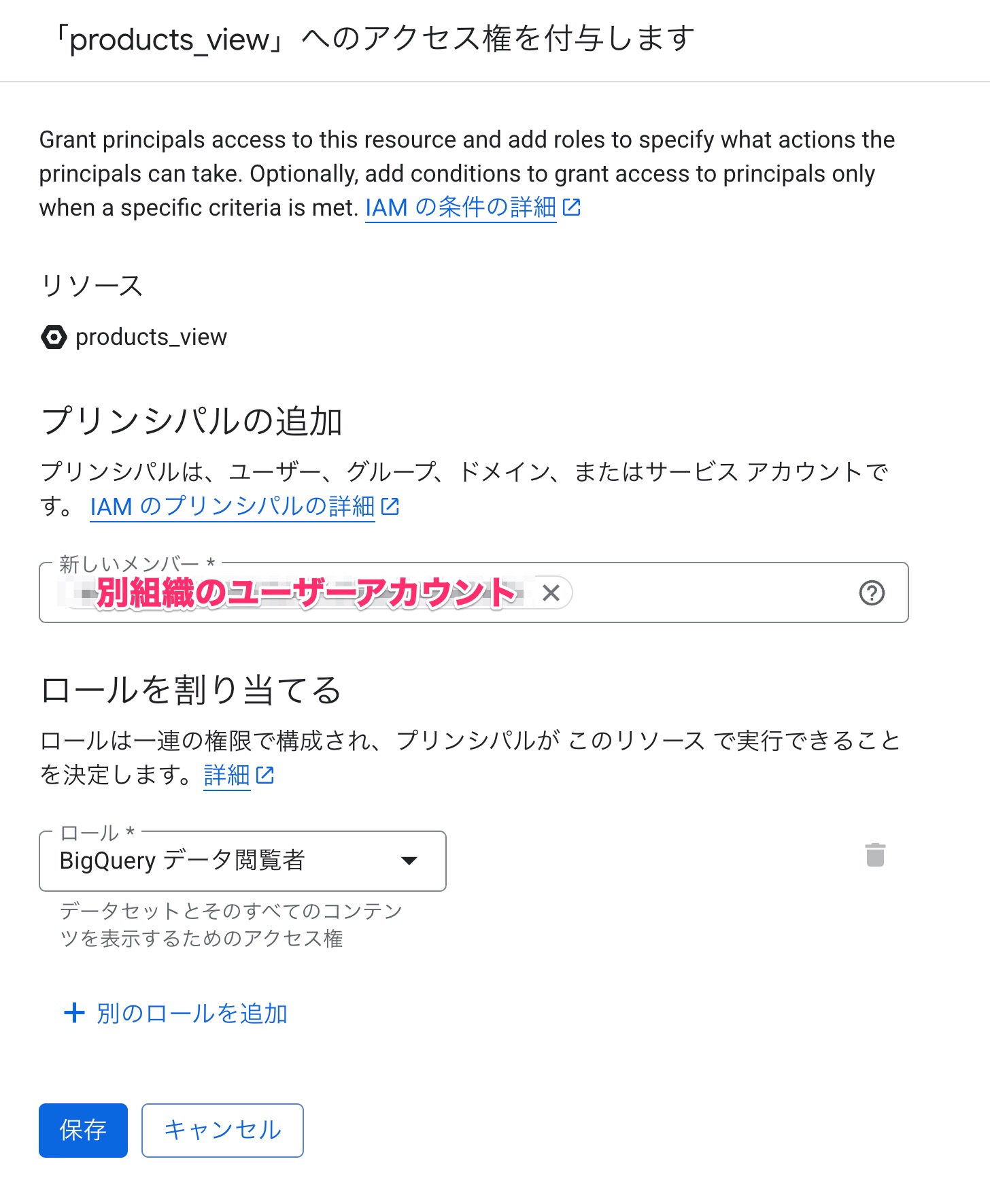
新しいメンバーにアクセス権を付与したいユーザーアカウントを設定します。
ロールは参照権を渡すため、BigQueryデータ閲覧者を割り当てました。
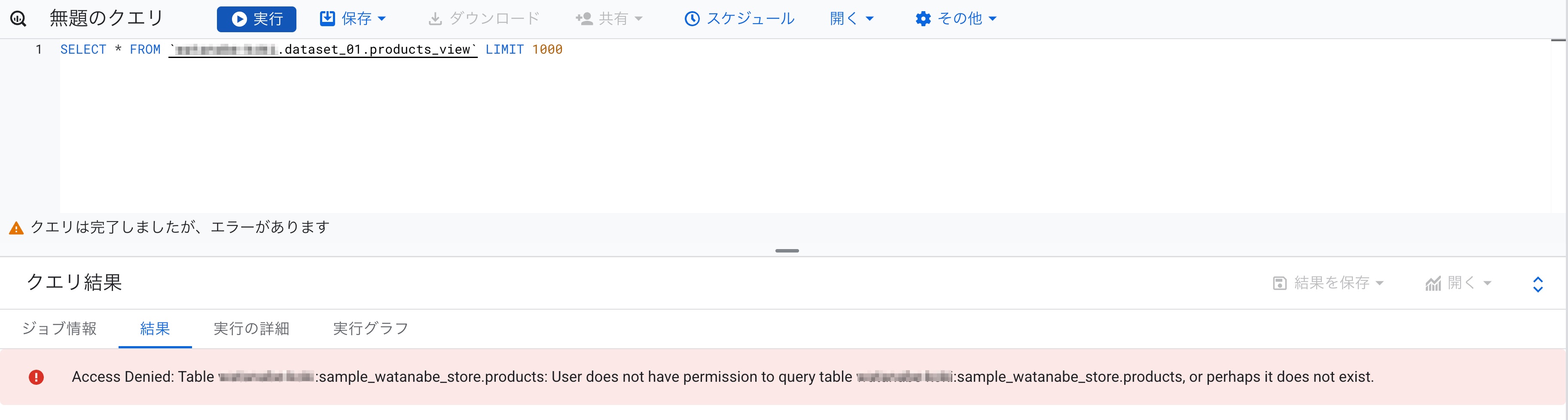
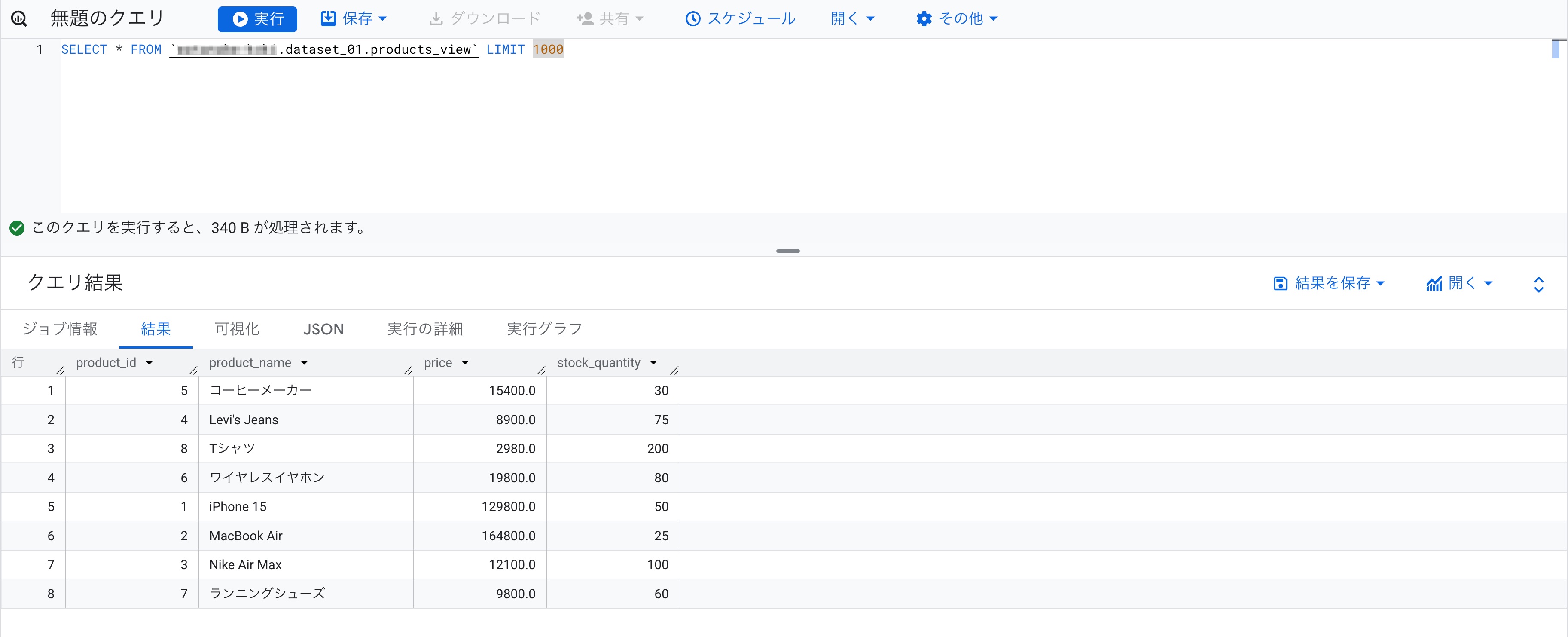
さてここで、参照権限を割り当てられたユーザーからビューに対するクエリを実行しました。
Access Deniedです。
それもそのはず、まだ承認済みビュー化させていない、通常ビューなのでソーステーブルへの参照権限も必要となり、その権限を割り当てていないユーザーではアクセスできないということです。
ということでビューを承認済みビュー化します。
テーブルが保存されているデータセットsample_watanabe_storeを選択し、「共有」から「ビューを承認」を選択します。
ソーステーブルが所属するデータセットに対してアクセスを承認させるビューを設定します。
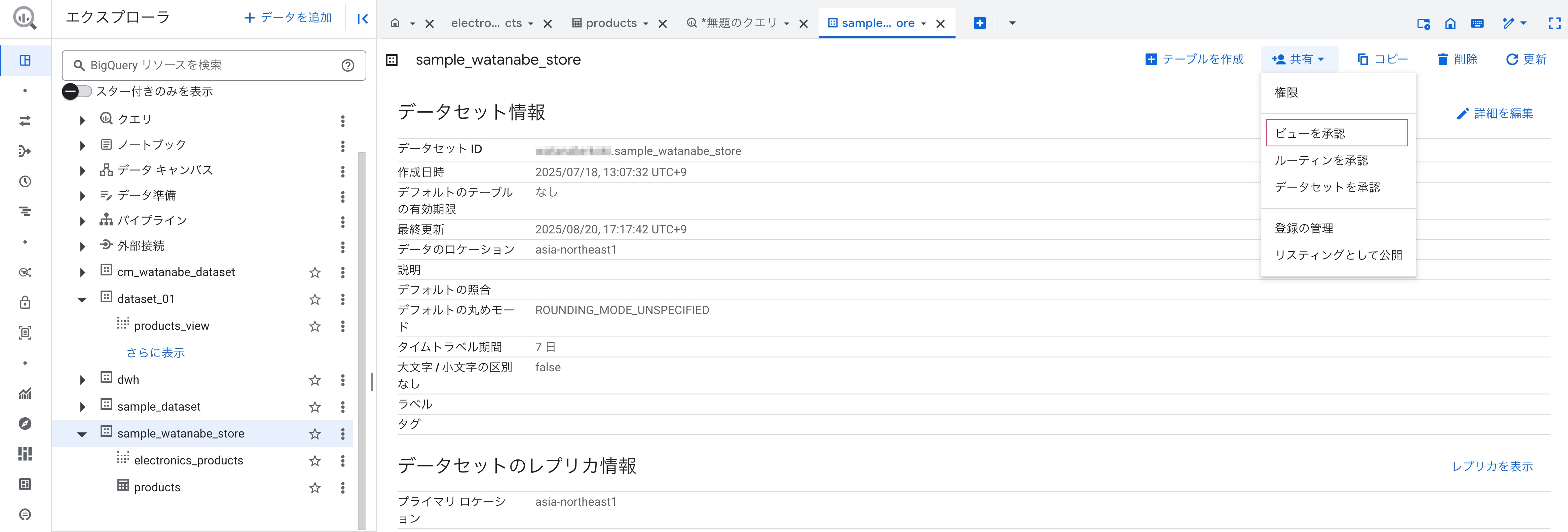
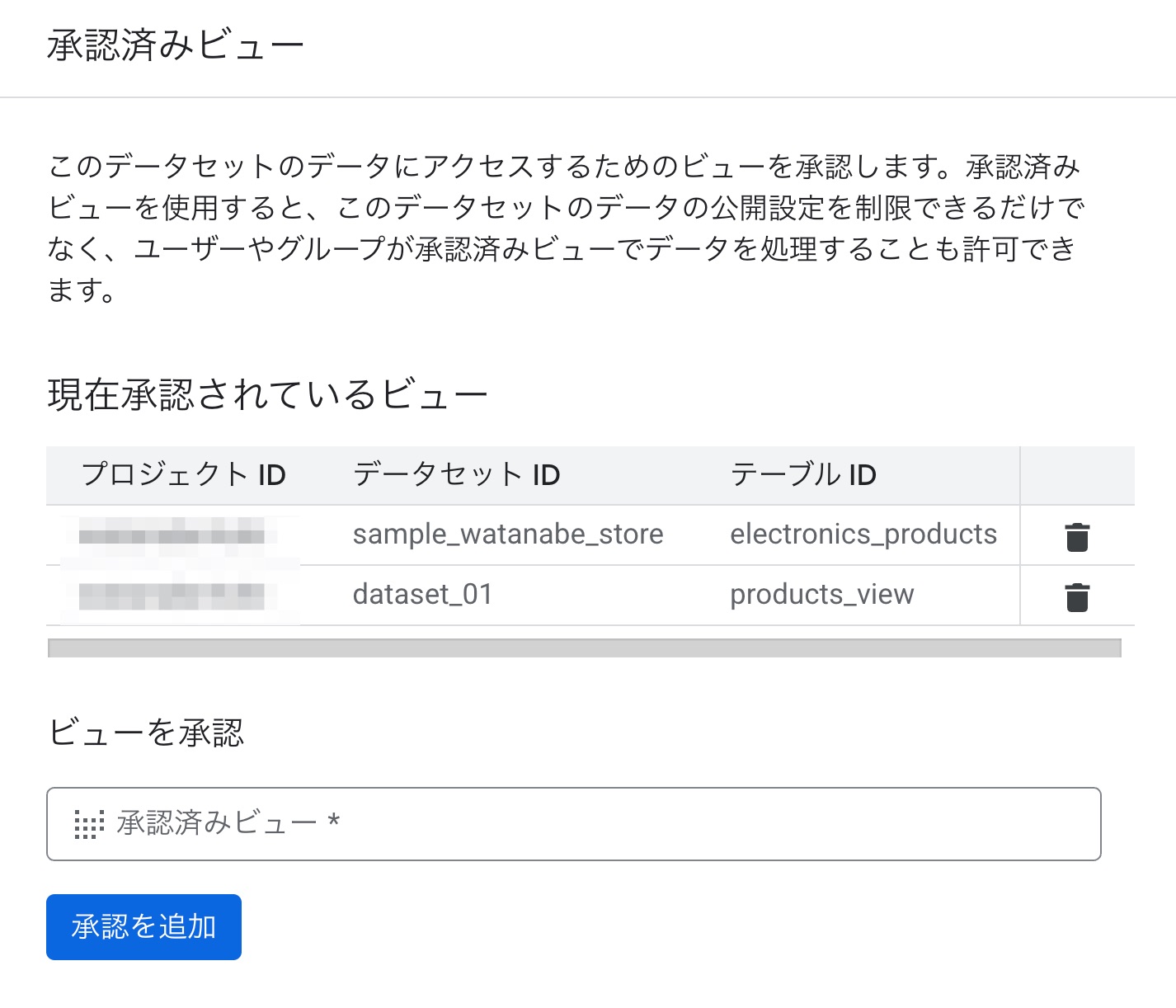
承認済みビューの箇所に、products_viewを入力して「承認を追加」を押します。
承認済みビューは上部に表示されることになります。
別のユーザーアカウントからクエリが実行できました。
承認済みビューは、「データセットへのアクセスが承認されたビュー」、そういうように捉えることが大切です。
承認済みデータセット
とは?
承認済みデータセットですが、こちらは承認済みビューと似ております。
ビュー(だけでなくマテビュー・ルーティンもですが)をまとめたデータセットに、ソースデータが所属するデータセットへのアクセスを承認させる機能になります。
承認済みビューだと一つずつ承認設定していく必要がありますが、データセットにビューをまとめて承認済みデータセット化をすることで一度の設定でよくなるというのが嬉しいです。
新しく承認済みビューを作りたいとなった場合も、ビューを承認済みデータセットにいれるだけで擬似的に承認済みビュー化されるという認識です。
試してみる
検証用にデータセットとビューを新しく用意しました。
ビュー定義は承認済みビューで使用したものと同じとなります。
- データセット:
dataset_02 - ビュー:
products_view2
ソースデータが含まれるデータセットを選択して、「共有」から「データセットを承認」を選択します。
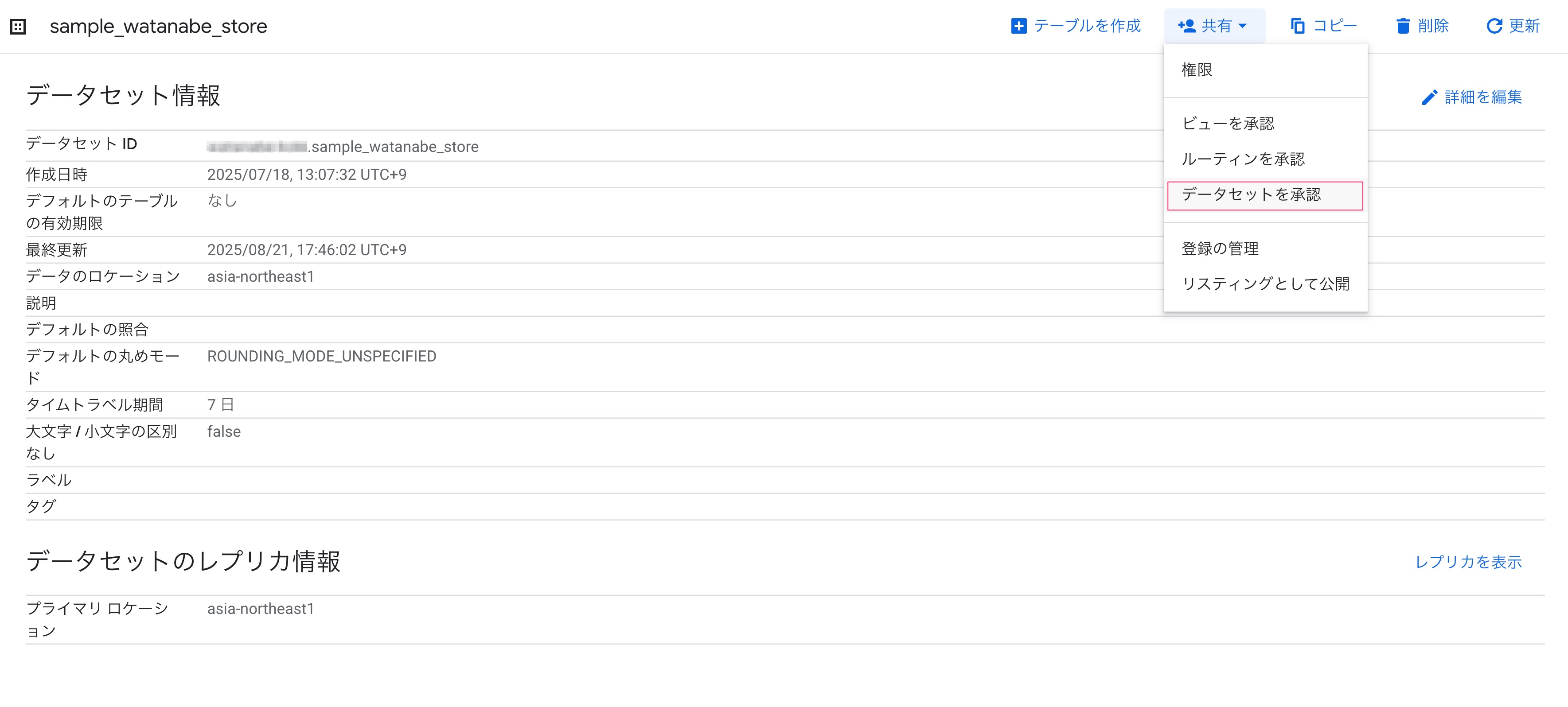
データセットを入力して、「承認を追加」します。
これでデータセットが承認済みデータセット化します。
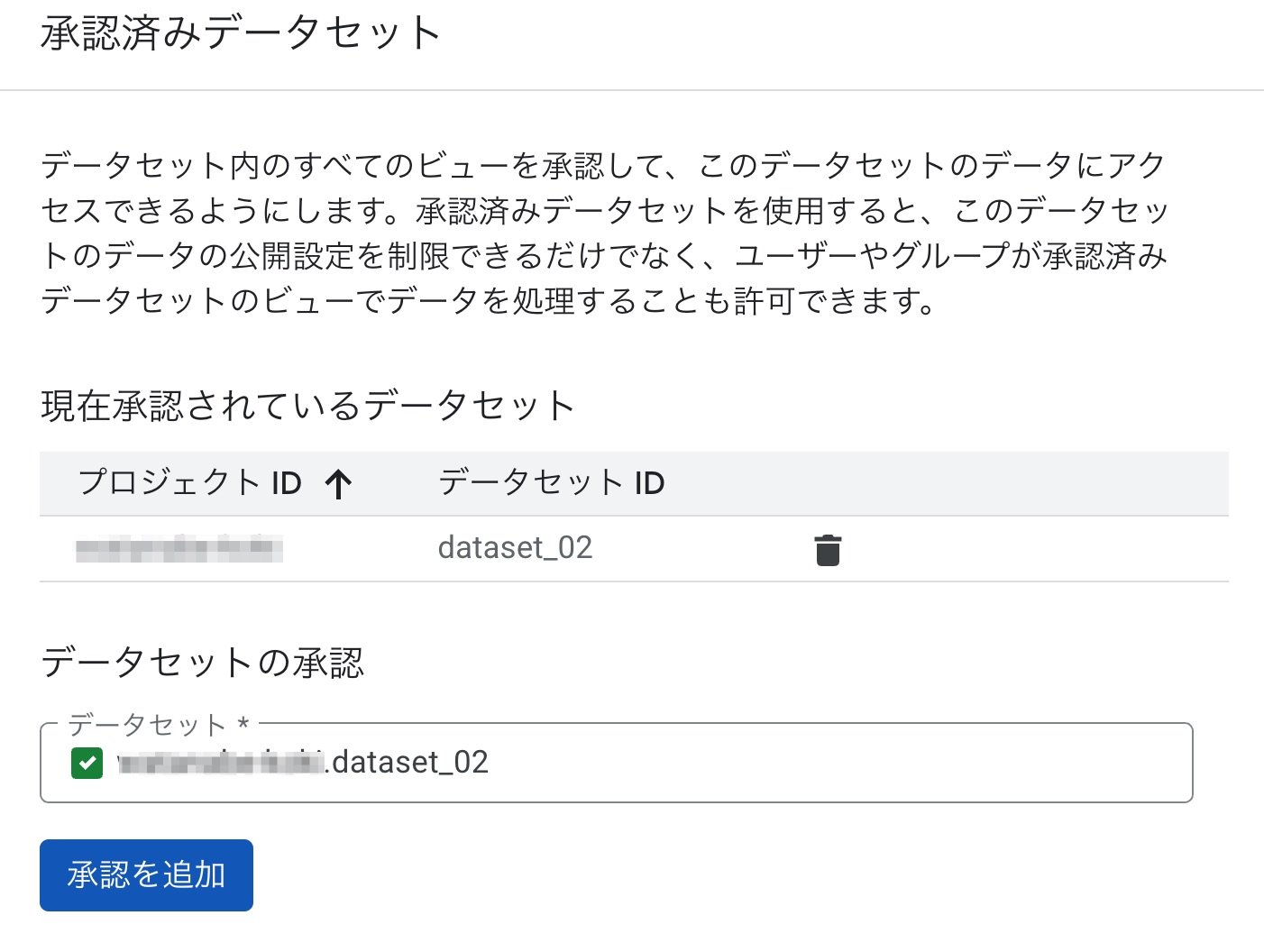
承認済みデータセットにするデータセットを選択し、「共有」から「権限」を選択します。
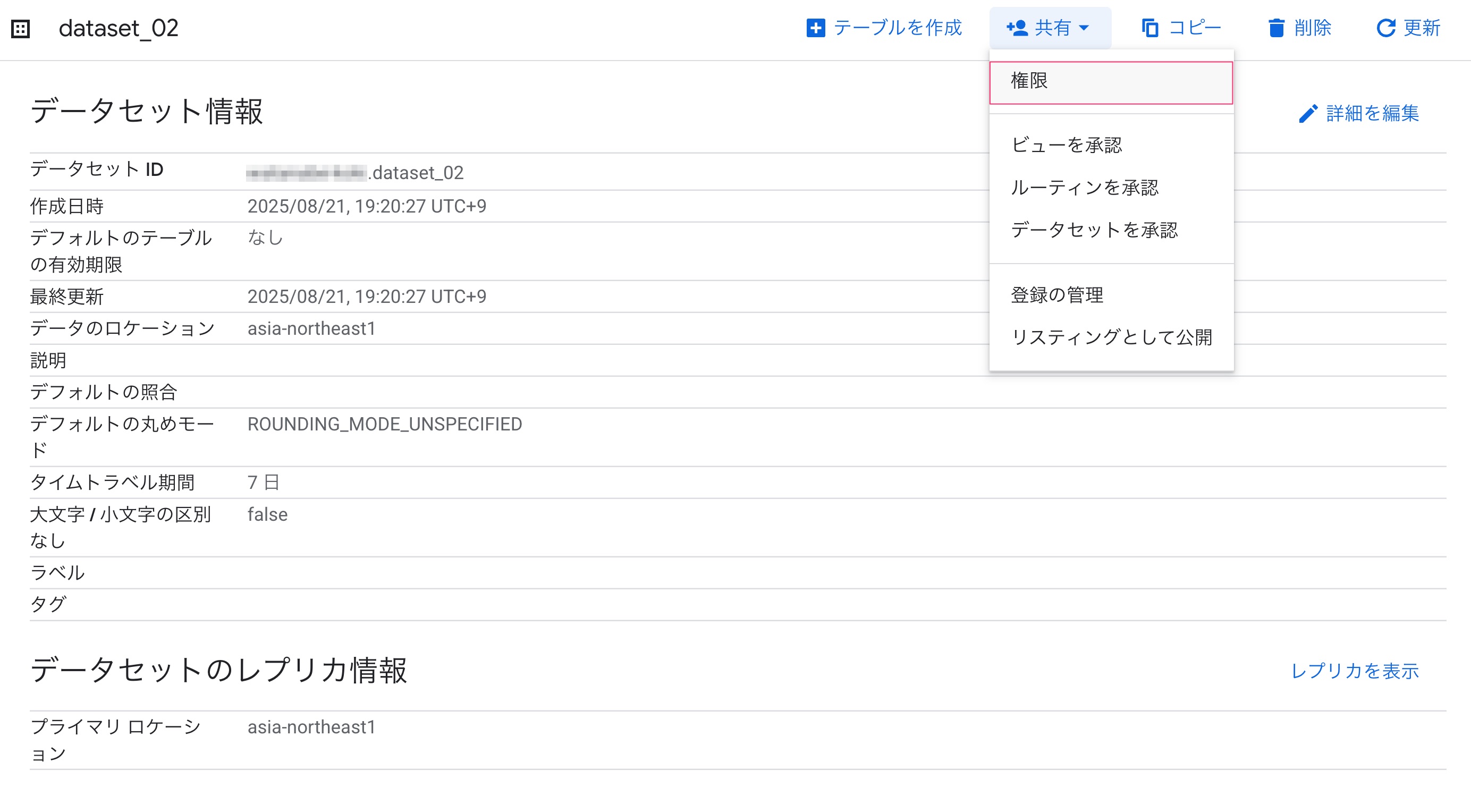
「プリンシパルを追加」します。
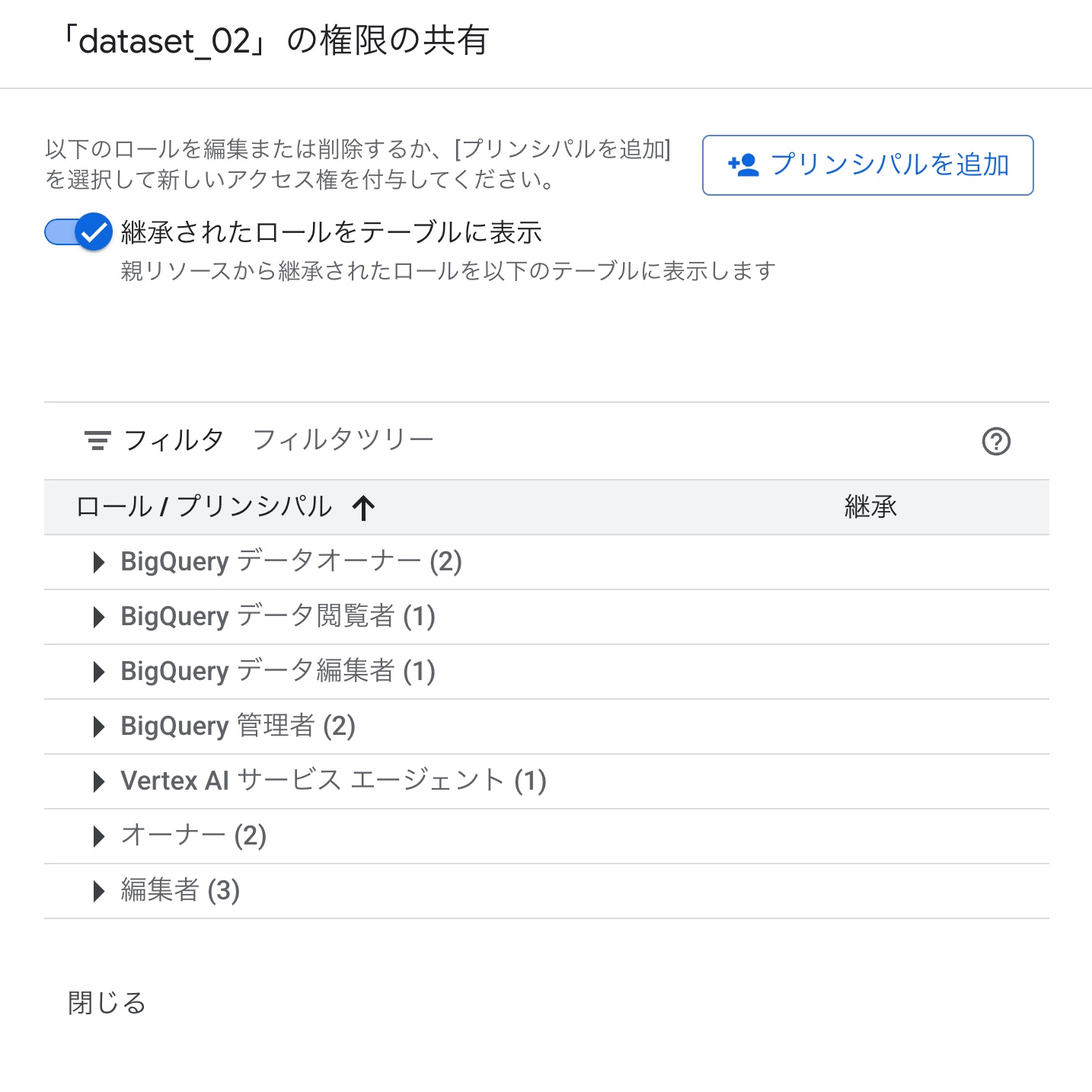
アクセス権を付与したいユーザーアカウントを入力して、BigQueryデータ閲覧者のロールを割り当てます。
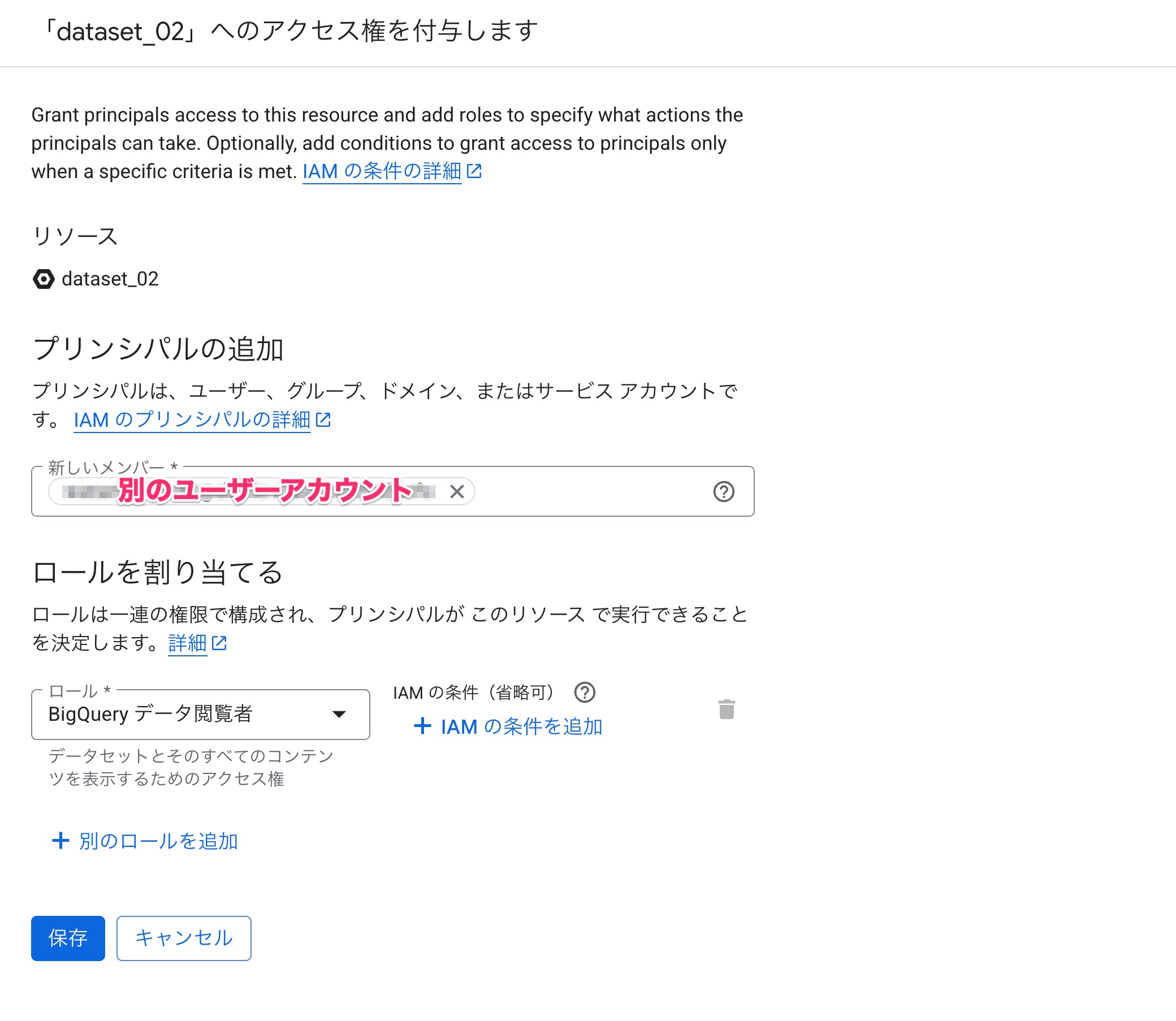
別のユーザーアカウントに切り替えて承認済みデータセット内にあるビューのクエリ実行が成功しました。
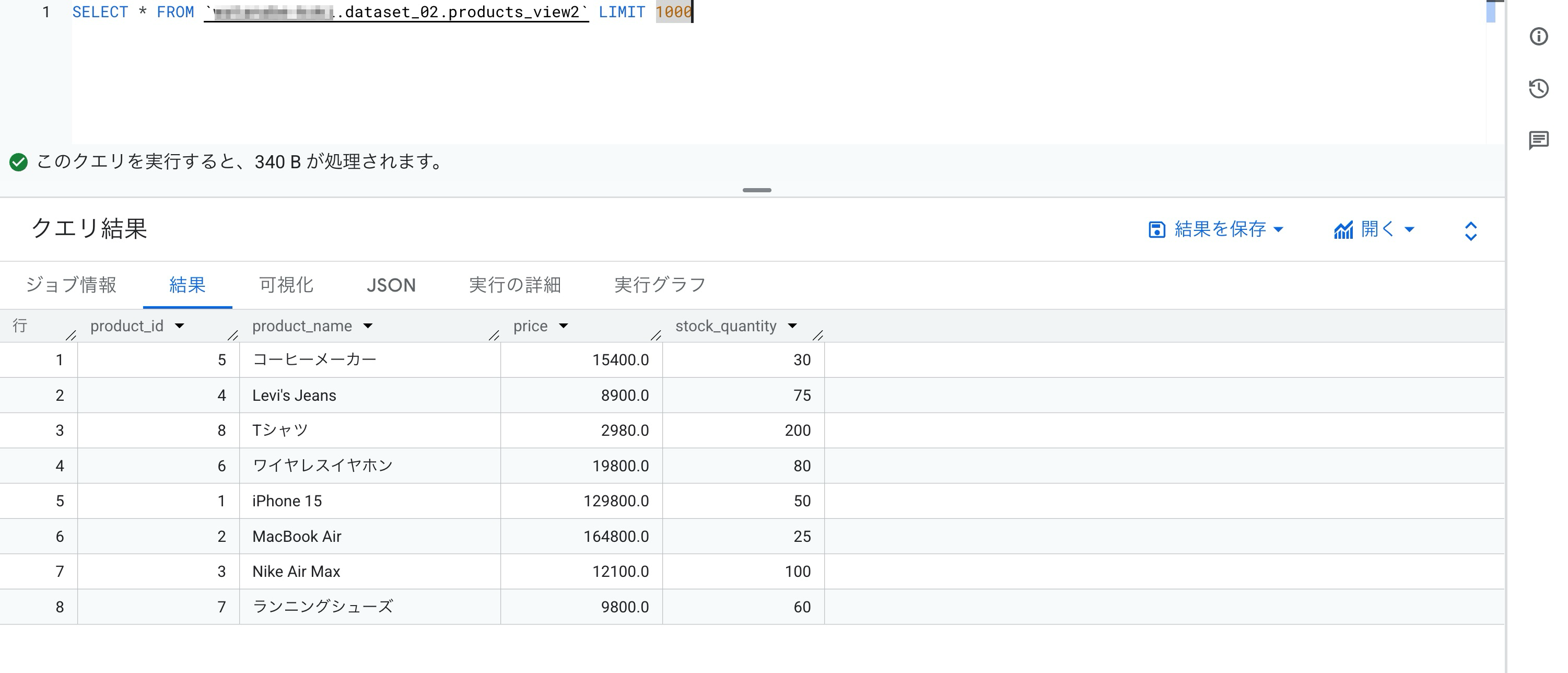
このように承認済みデータセット内にあるビューに対して、テーブルへの権限を与えずともクエリ実行できることが確認できました。
行列レベルアクセス制御
とは?
行や列に対する見せる見せないの制御をします。
例えば行ならば日本のユーザーには日本のデータのみを見せるようにさせたり、列ならば電話番号や名前など個人情報にあたるものは見れないようにしたりを設定することが可能です。
上記のアクセス制御はビューを作成することでも実現は可能なのですが、プリンシパルごとにアクセス制御を変えたい場合にプリンシパル分ビューを作ることは大変ですし、ビューの管理数も増えてしまいます。
見せたくないものは見せないように行列レベルアクセス制御をしましょう。
列レベルアクセス制御を試してみる
コンソールでの操作についての公式ドキュメントはこちらです。
列レベルのアクセス制御によるアクセス制限 | BigQuery | Google Cloud
分類とポリシータグを作成するのに、Google Cloud Data Catalog APIの有効化が必要なので、有効にします。
まずはポリシータグを所属させる分類を作成します。
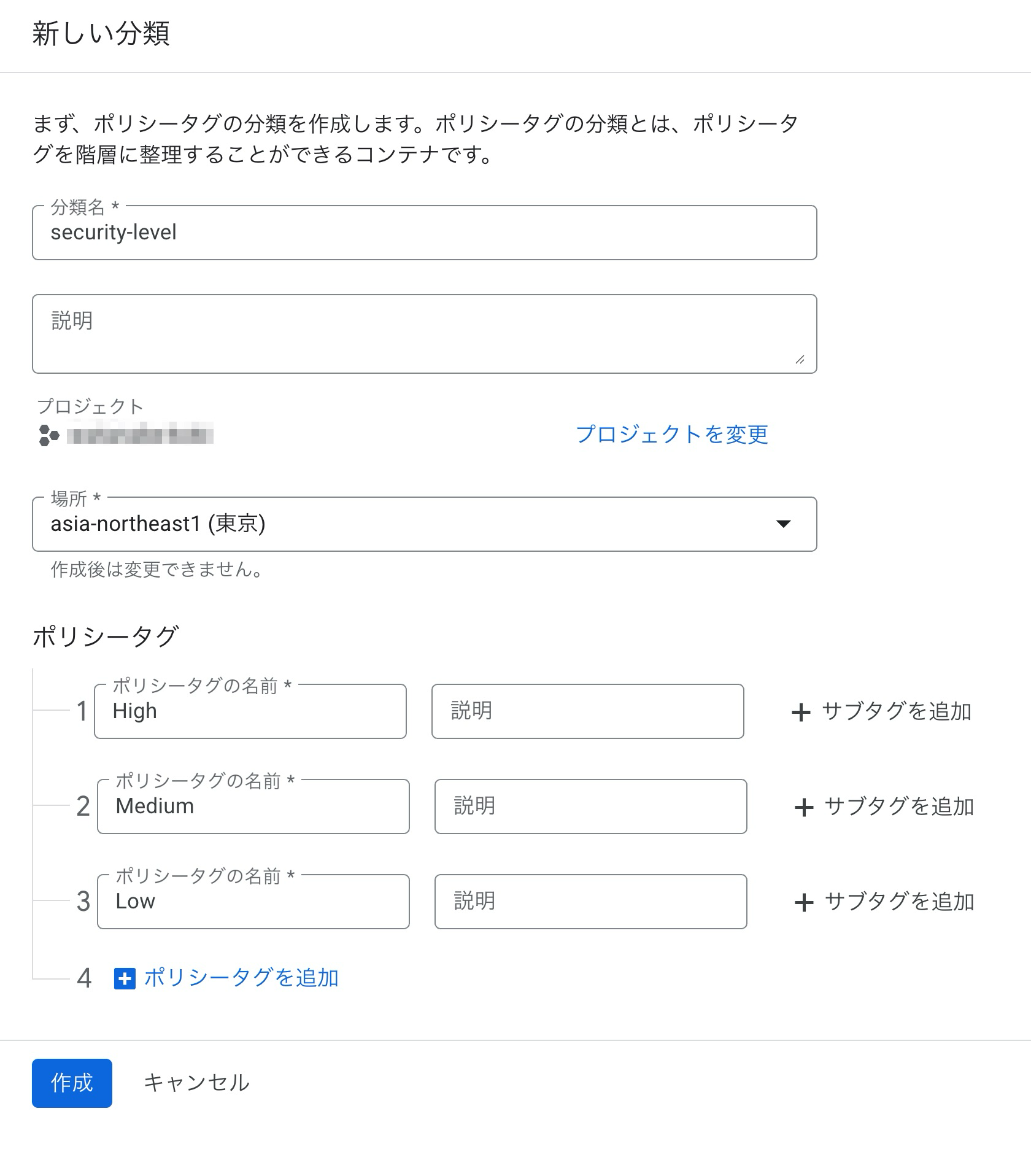
security-levelという分類を作成しました。
ポリシータグとして、High・Medium・Lowを割り当てました。
作成した分類の中にある「ポリシータグ」からHighを選択して、右側の「情報パネル」からプリンシパルを追加します。
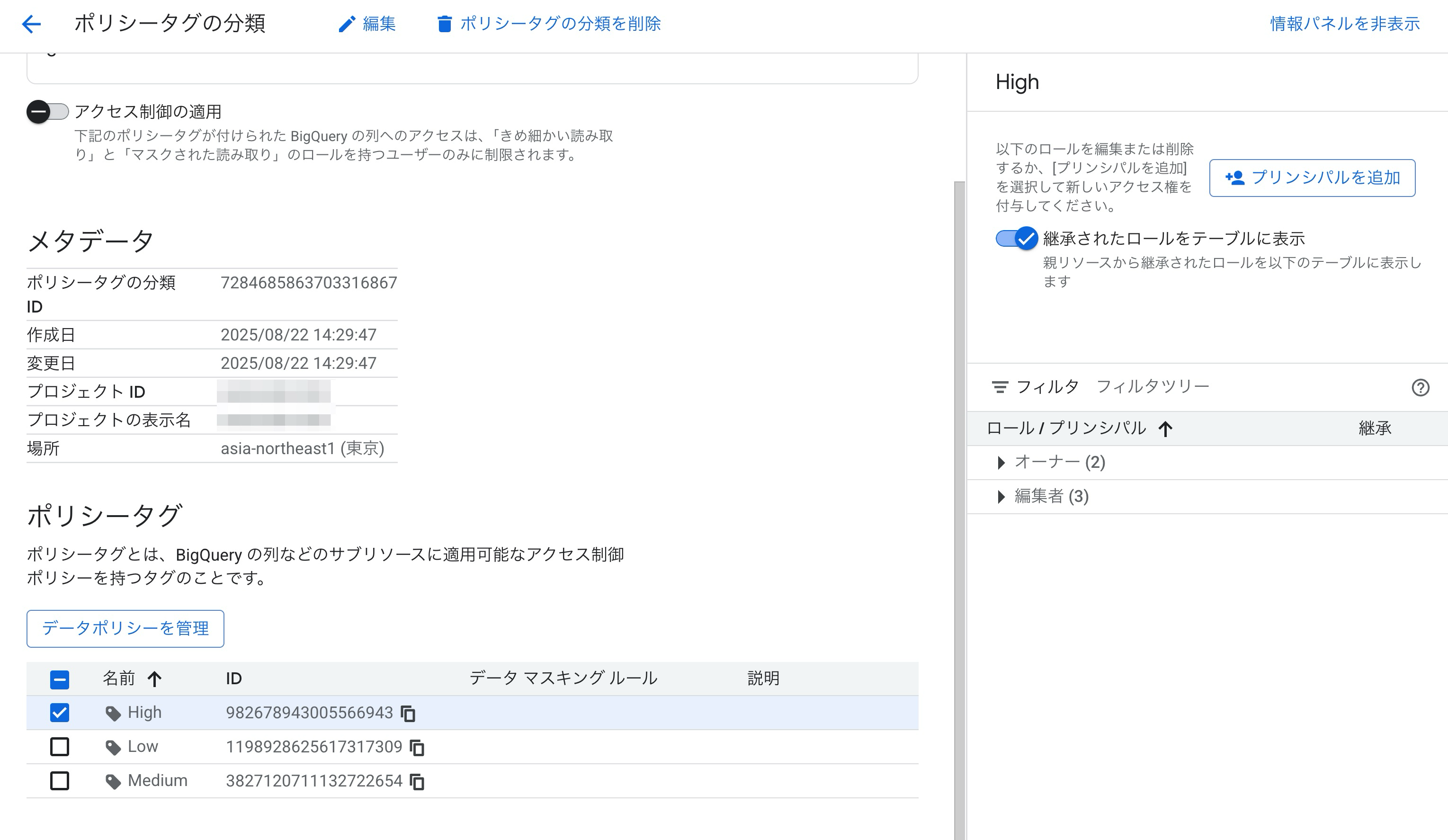
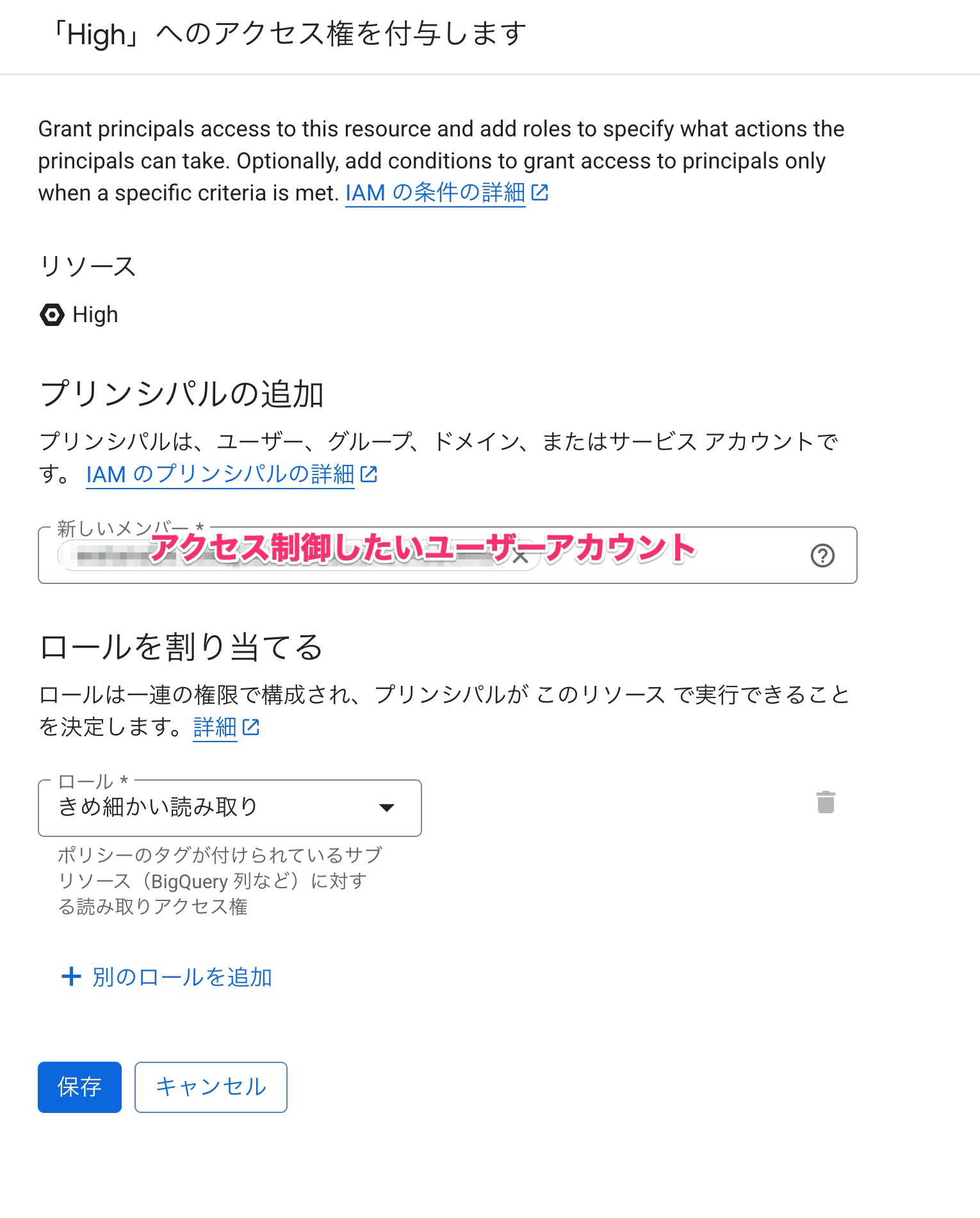
ポリシータグに対してアクセス権を付与したいプリンシパルを指定します。
ここではユーザーアカウントを指定しました。
そして列レベルアクセス制御の肝であるのですが、割り当てるロールはきめ細かい読み取りを指定することで参照権限を渡すことが可能です。
datacatalog.と入力することでもプルダウンで表示されます。
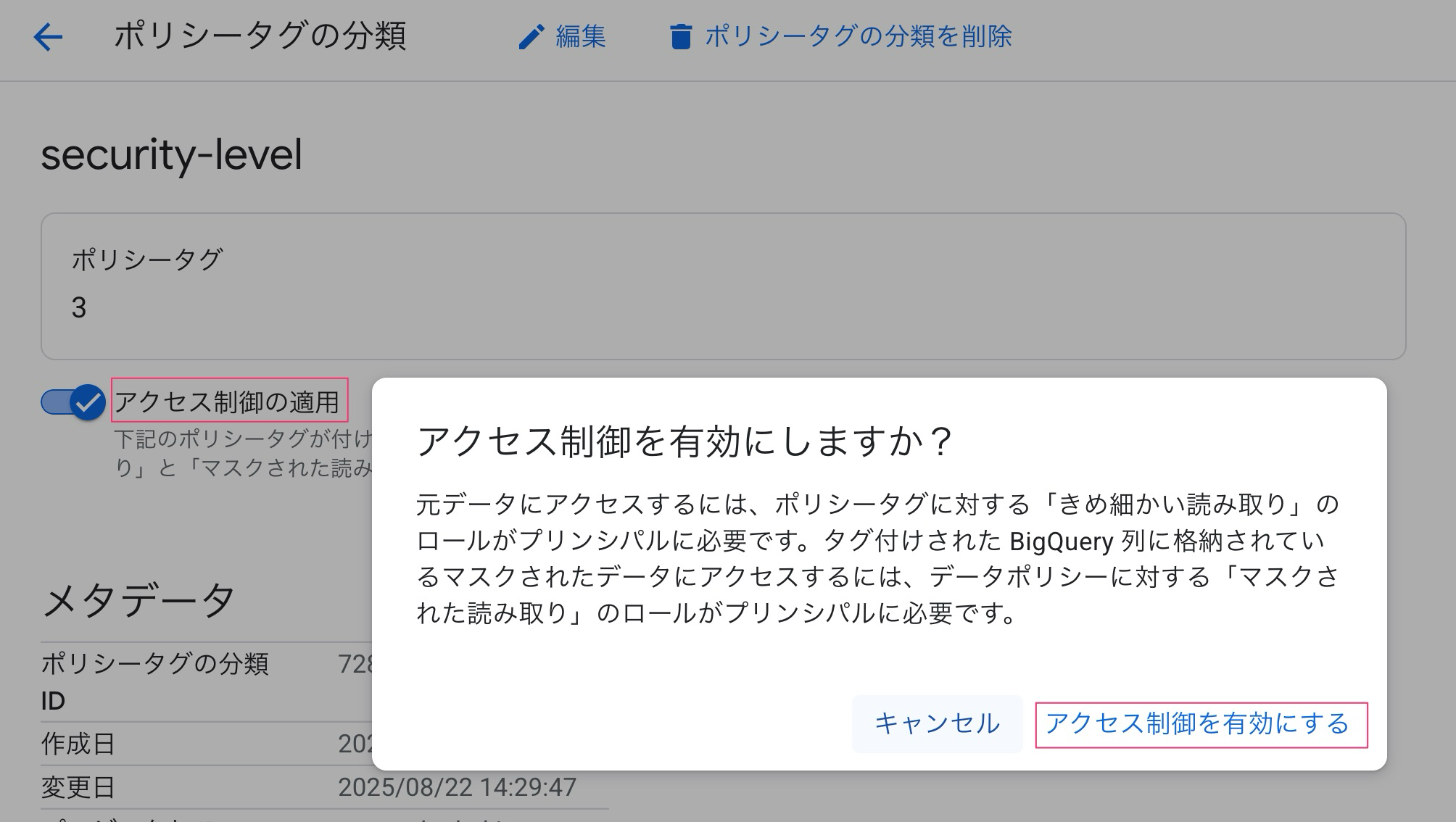
そして忘れちゃいけないのが、「アクセス制御の適用」です。
これをしないとアクセス制御されずにテーブルにアクセス権があればデータアクセスできてしまいます。
続けてテーブルの列にポリシータグを割り当てます。
BigQueryコンソール上でテーブルを選択して、「スキーマの編集」をします。
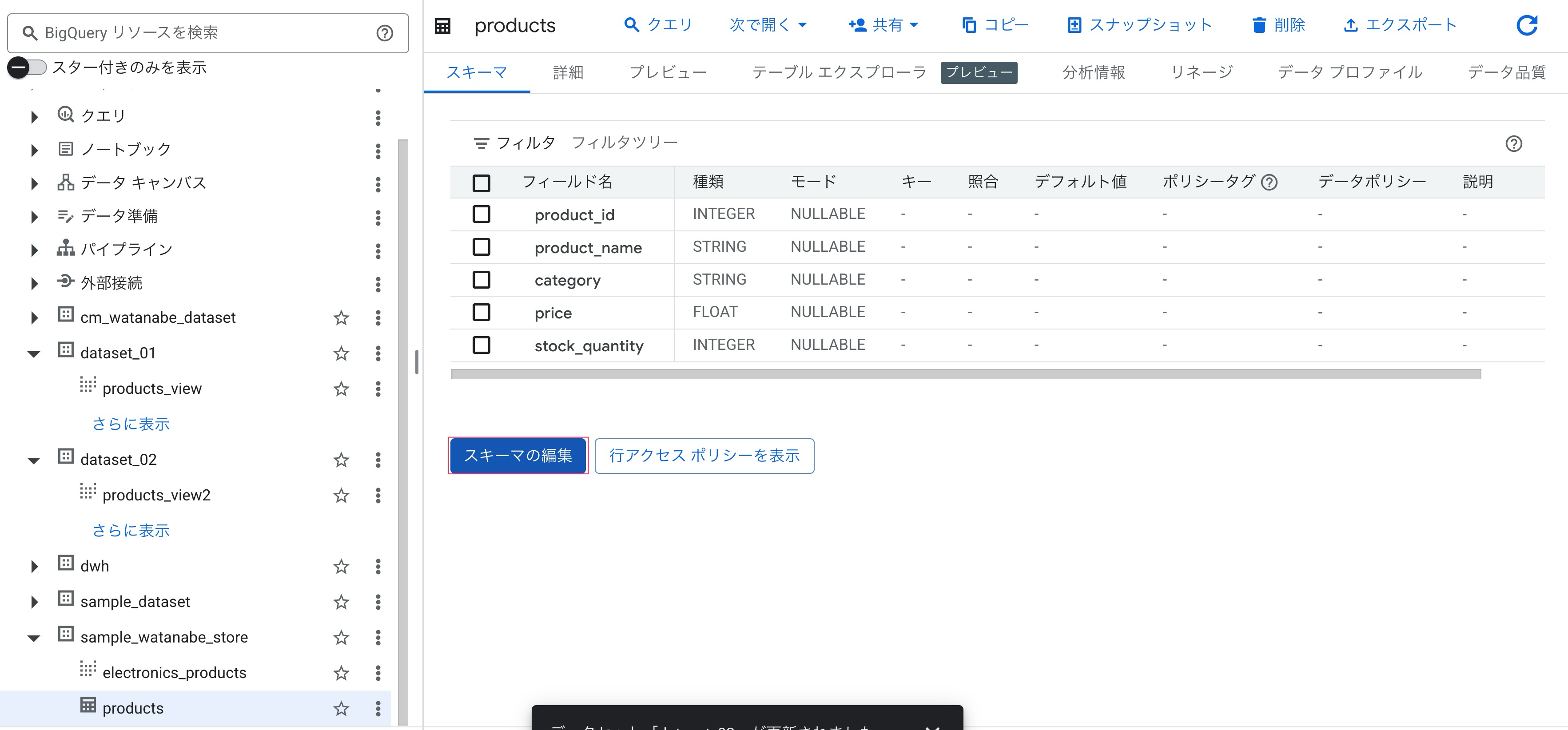
ポリシータグを割り当てたい列を選択します。
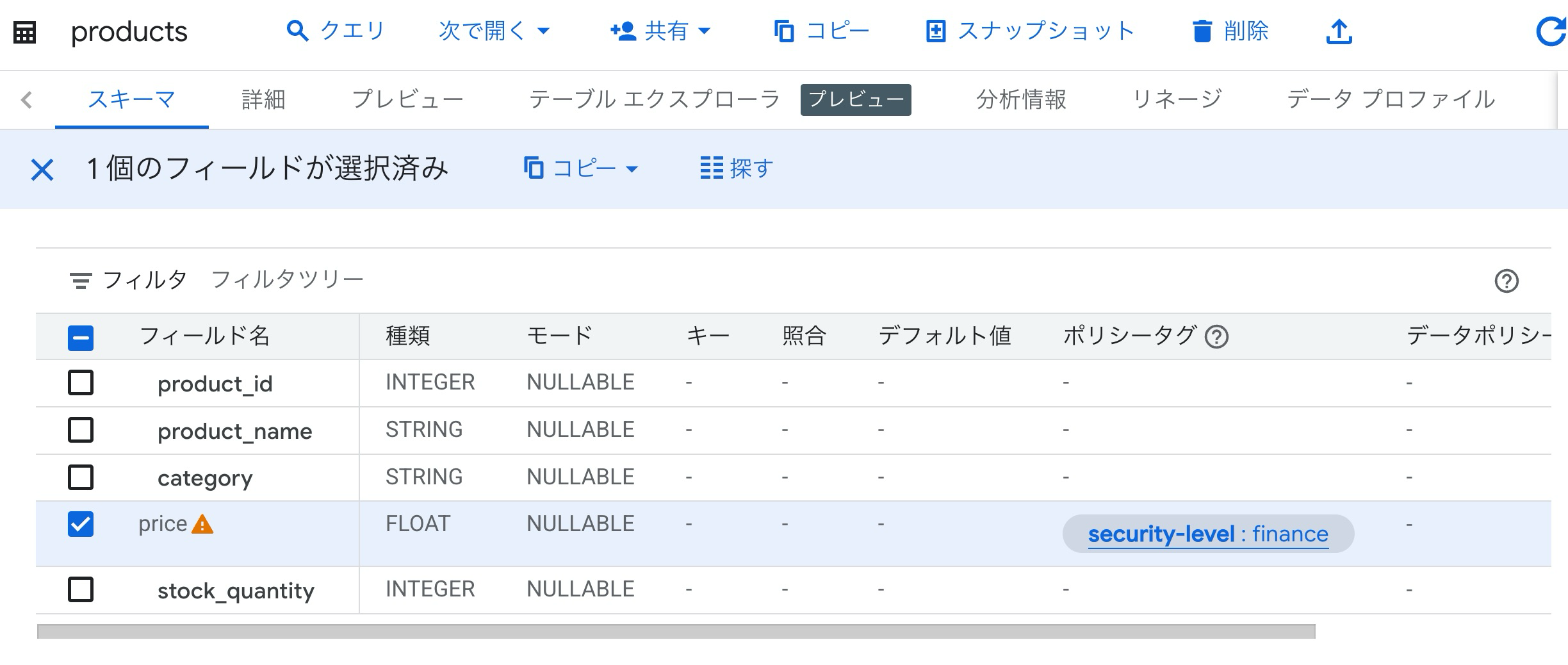
今回はproduct_nameに対して、作成した分類security-levelのポリシータグHighを割り当てました。
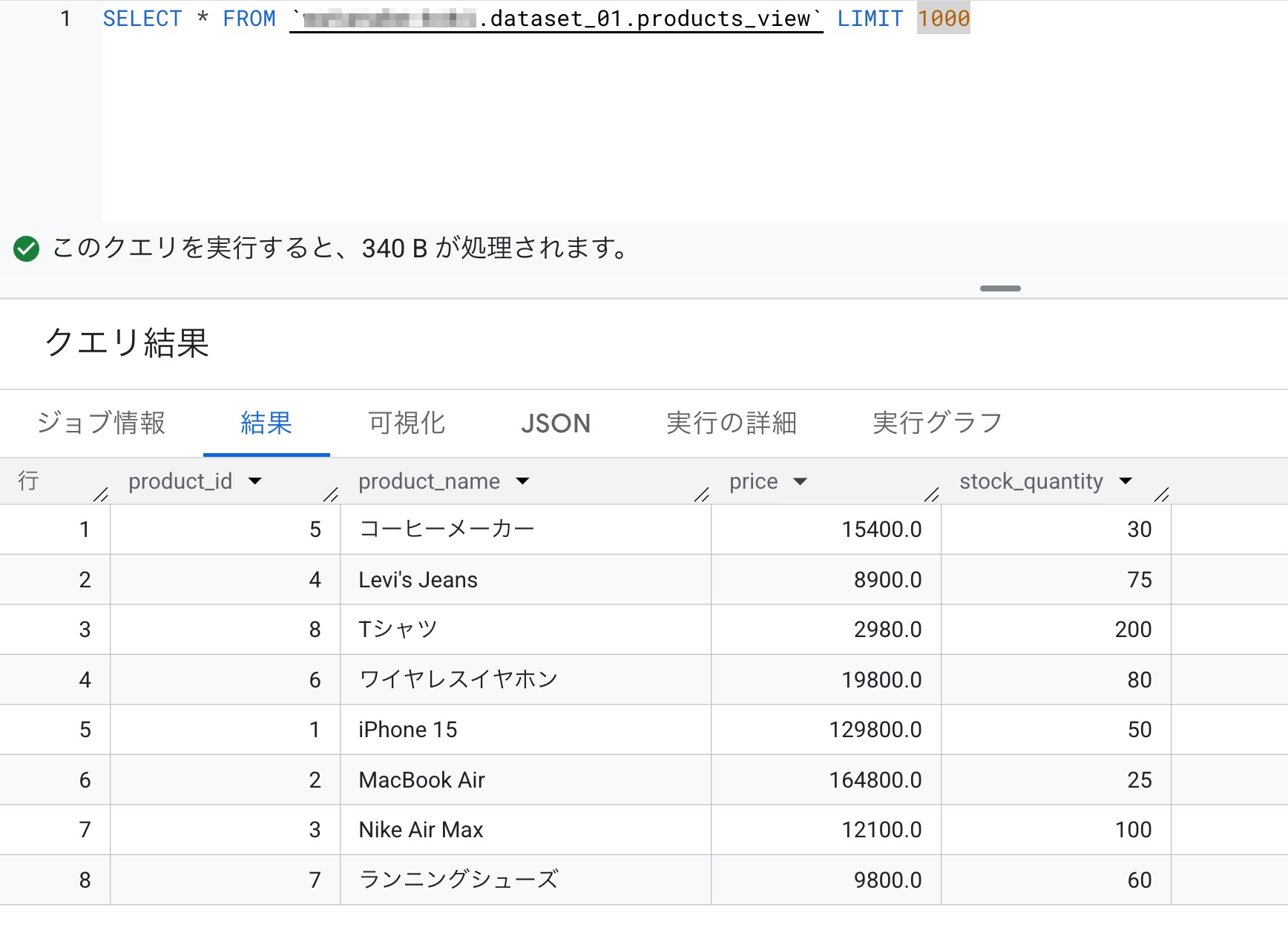
ポリシータグを付与したproductsテーブルをソースとしている承認済みビューに対して、列レベル制御でアクセス権を付与されたユーザーでクエリを実行してみると、product_nameを含めてデータが参照できました。
試しにポリシータグへのきめ細かい読み取りロールの割り当てをユーザーから取り除いてクエリを実行してみました。
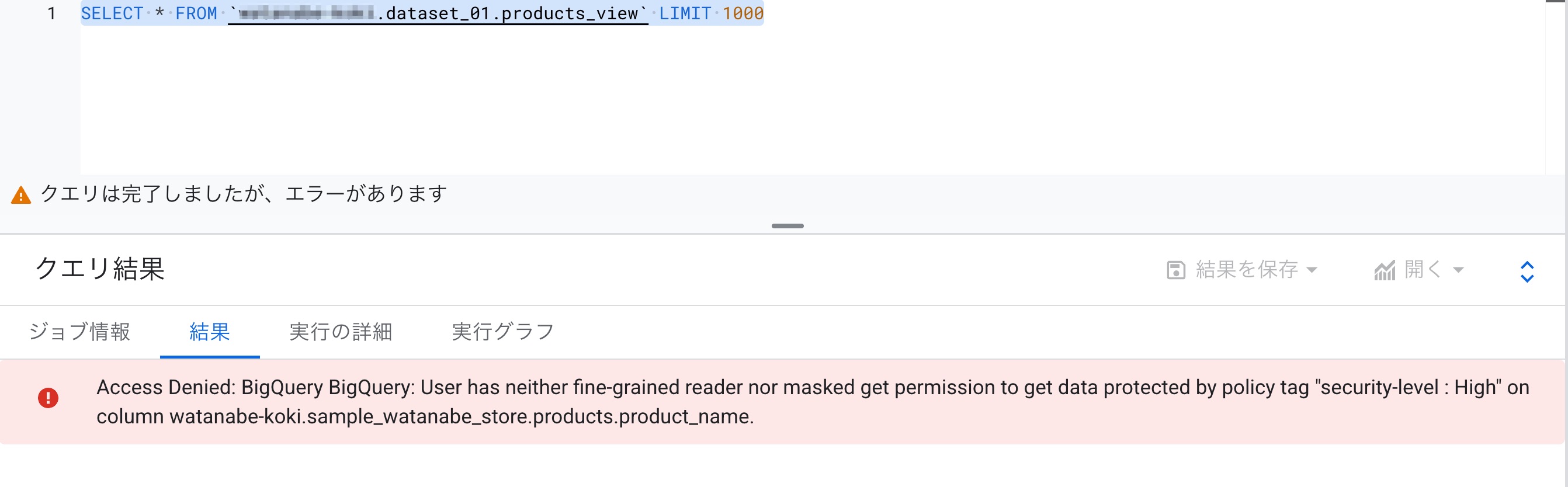
失敗しましたね。
てっきり権限がない列以外取得できるのかなと思っていたのですが、BigQueryはエラーとなるようです(ちなみにRedshiftは成功します)。
列を明示的にSELECTするか、以下のようにEXCEPTを使用してアクセス権がない列を除外したSELECTをする必要があります。
SELECT * EXCEPT (column1,column2,...) FROM ...
行レベルアクセス制御を試してみる
行レベルアクセス制御では、列レベルアクセス制御で使用したポリシータグは使用しません。
使用するのは行レベルアクセスポリシーです。
行レベルアクセス制御は以下の簡単なDDLで実現できます。
CREATE ROW ACCESS POLICY column_filter
ON project.dataset.my_table
GRANT TO ('user:abc@example.com')
FILTER USING (column = 'APAC');
アクセス権はユーザーやグループ、ドメインに割り当てられますが、詳しい書き方は以下をご覧ください。
Principal identifiers | IAM Documentation | Google Cloud
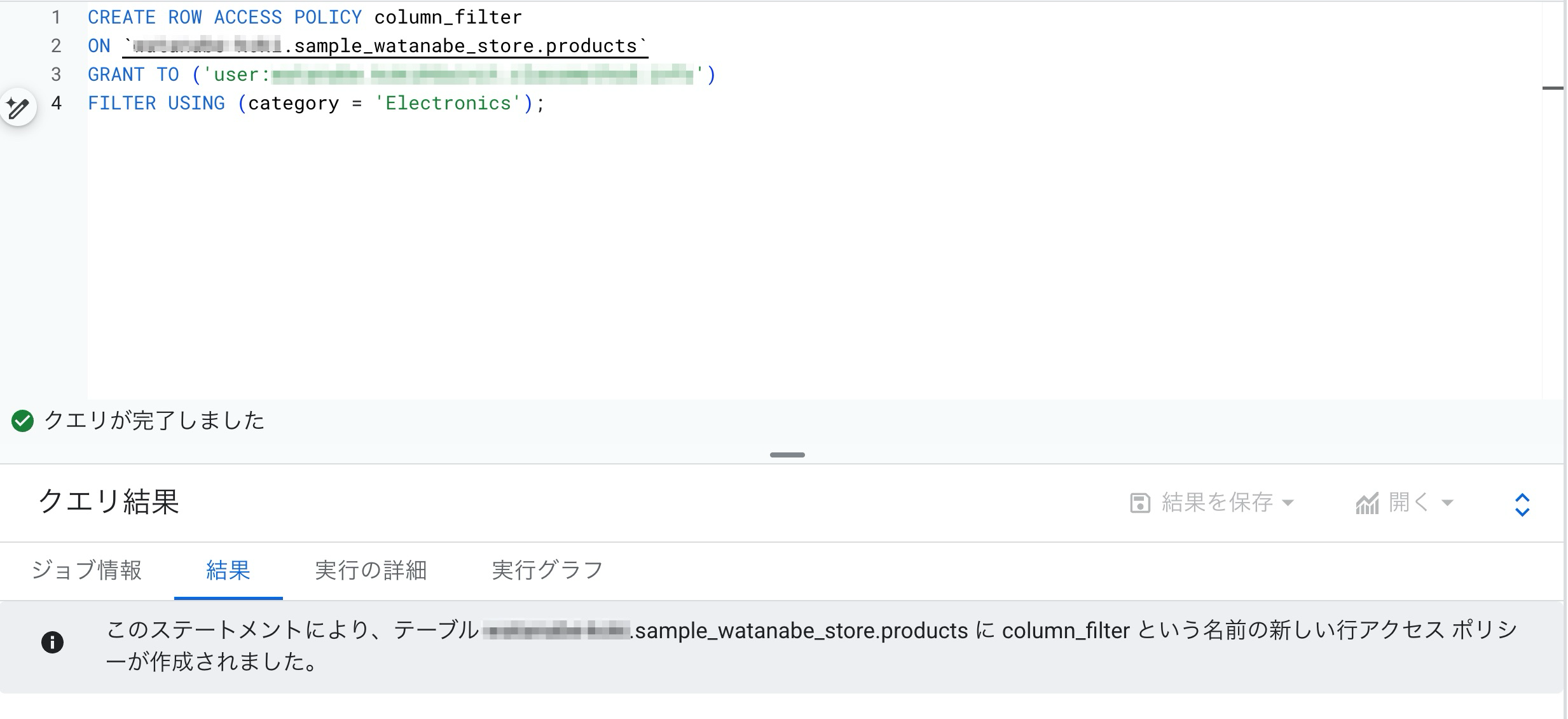
productsテーブルに対して行レベルアクセスポリシーを設定します。
使用したクエリはマスキングしていますが、以下となります。
category = 'Electronics'である行をアクセスさせるポリシーです。
CREATE ROW ACCESS POLICY column_filter
ON `project.sample_watanabe_store.products`
GRANT TO ('user:abc@example.com')
FILTER USING (category = 'Electronics');
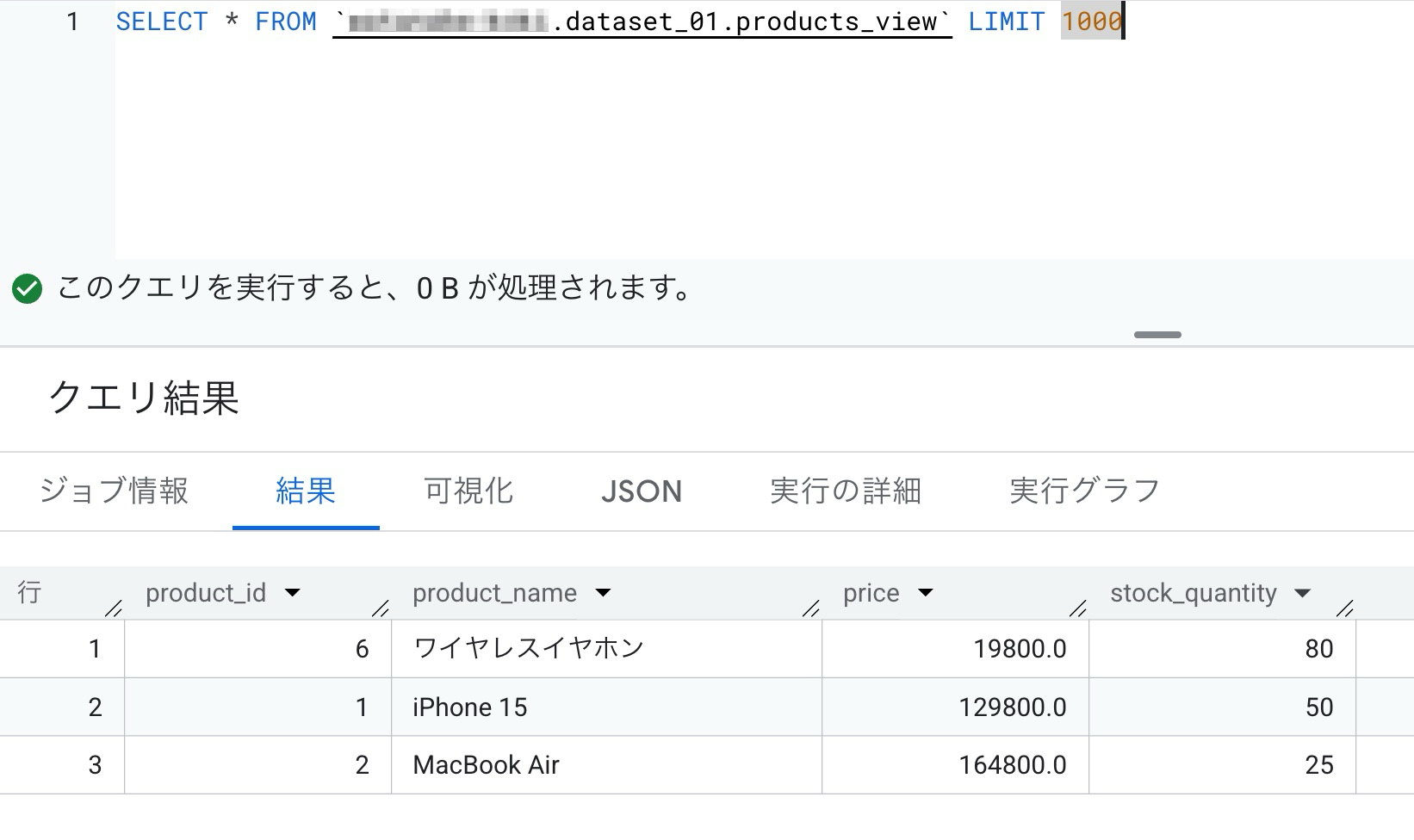
productsテーブルをソースとする承認済みビューに対してクエリを実行しました。
先ほどまで8行出力されていましたが、行レベルアクセス制御がなされて3行の出力になりました。
さらに詳しくはこちらの公式ドキュメントをご参考ください。
BigQuery の行レベルのセキュリティの概要 | Google Cloud
データマスキング
とは?
データマスキングは、それぞれのプリンシパル(ユーザーとかグループ)ごとにデータ列の見せ方を変える機能です。
列レベルアクセス制御が見せる・見せないの制御であるのに対して、事前定義されたルールもしくはカスタムで定義できるUDF(ユーザー定義関数)を使用して、透過的にデータ列が加工された形で表示されるようになります。
ちなみにデータマスキングは列レベルアクセス制御でも使用したポリシータグを使用します。
そのポリシータグに、それぞれのプリンシパルに対するマスキングルールを定義していく形になります。
またマスクされた状態でデータを表示させるには、マスクされた読み取り(Masked Reader)ロールを同時に設定する必要があります。列レベル制御ではきめ細かい読み取り(Fine-Grained Reader)ロールでしたね。
マスキングの種類とその評価優先度としては以下のようになります。
- カスタム マスキング ルーティン(これがUDFにあたります)
- ハッシュ(SHA-256)
- メールマスク
- 末尾の 4 文字
- 先頭の 4 文字
- 年月日マスク
- デフォルトのマスキング値
- null 化
同じポリシータグに複数のマスキングルールが設定できるため、例えば2つのグループに所属するメンバーが、データポリシーで2つのグループに対するマスキングルールが設定されていた場合は上記の評価順でテーブル列がマスクされることとなります。
上記のマスキングルールの評価優先度についてわかりやすい図が公式ドキュメントにあったため、引用します。
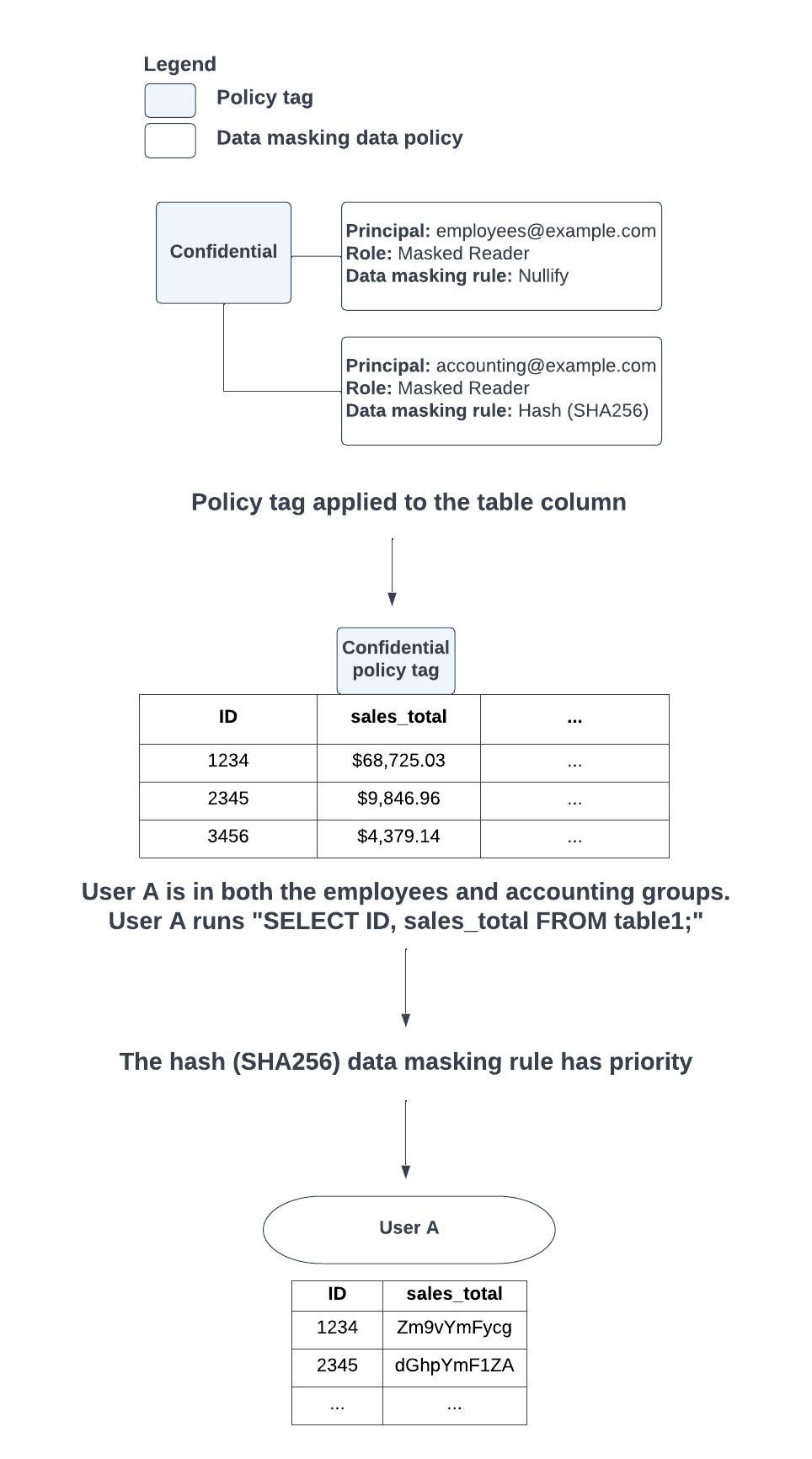
(引用元:Data masking rules)
これはemployeesにもaccountingにも所属するユーザーがクエリをした際にhashのマスクが優先されることを示しています。
ポリシータグのアクセス制御における評価論理
列レベル制御とデータマスキングにはポリシータグを使用すると述べました。
このポリシータグが複雑に絡み合ってきたときにどう評価されるのかについては理解するのに時間がかかるので、公式ドキュメントにある図を引用しつつ少しだけ詳しく解説します。
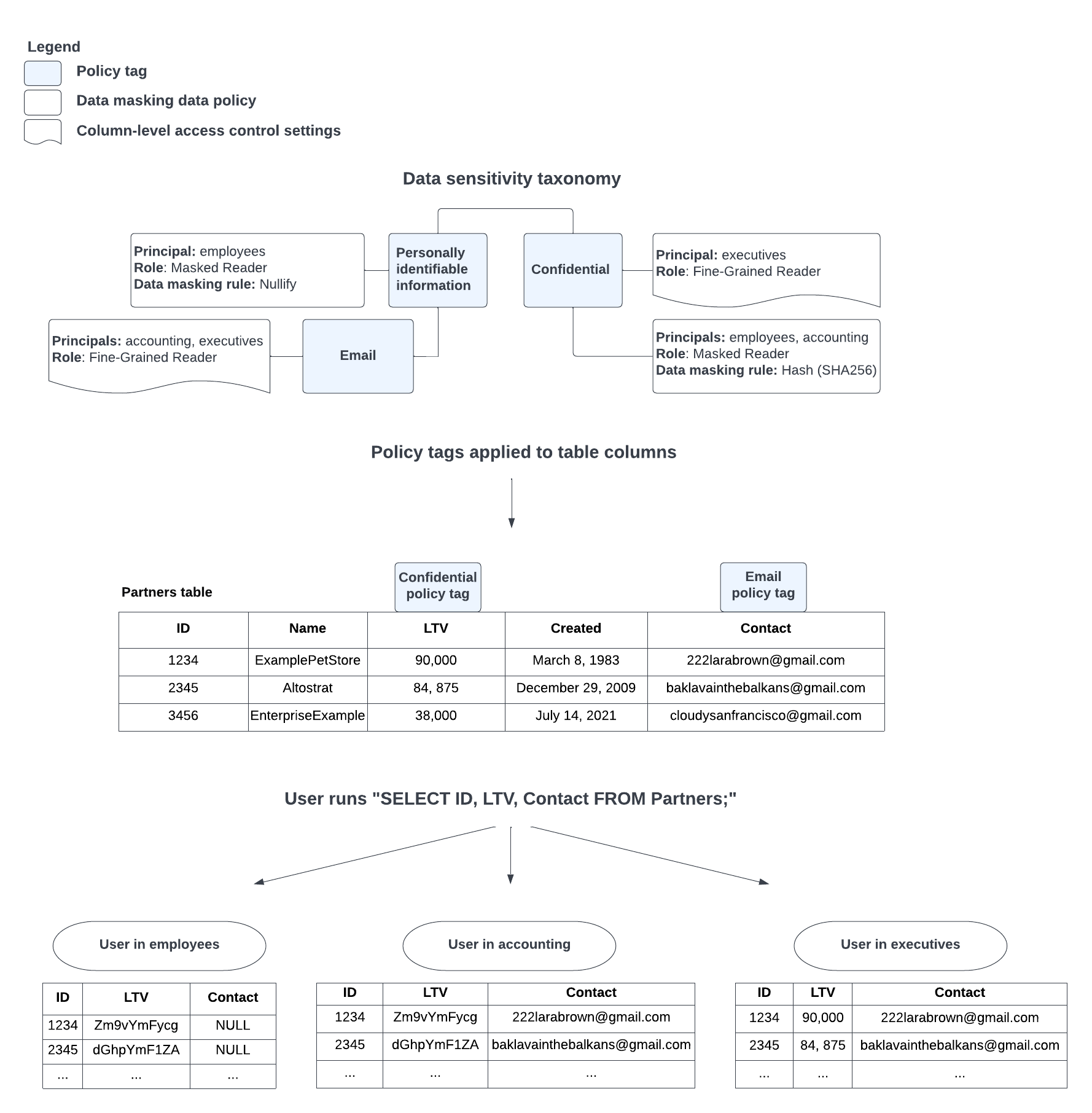
(データ マスキングの概要 | BigQuery | Google Cloudから引用)
この図は上から以下を示しています。
- 分類とポリシータグの一覧、それぞれのプリンシパルに対するマスキングルールと列レベル制御の割り当て
- テーブル列へのポリシータグの割り当て
- それぞれのプリンシパルがデータ参照したときの見え方
employeesのデータの見え方を追っていきます。
ポリシータグはPersonally identifiable informationとEmail・Confidentialというポリシータグで、employeesはPersonally identifiable informationタグでnullのマスキングルール、Confidentialタグでhashのマスキングルールを設定されています。
テーブル列にはEmailとConfidentialのタグが割り当てられています。
クエリ結果を見てみると、ConfidentialのつくLTVはhash化されていますね。これには不思議はありません。
ただEmailのタグがつくContactがNULLとなっています。
employeesはEmailのタグに対しては制御がかけられていないのに、どうしてでしょう?
これはポリシータグには制御の継承という仕組みがあるためです。
図のPersonally identifiable informationとEmailのタグを見てみましょう。階層化されていますよね。実はポリシータグは5段階まで階層化することができます。
Personally identifiable informationでemployeesに対してnullのマスキングルールが設定されているため、その継承がされているEmailのタグが割り当てられているテーブル列に対してマスキングルールが適用され、ContactがNULLとして表示されたというわけです。
評価順としては昇順になります。
今回の例だとまずはEmaliタグの制御を確認し、employeesに対しては制御がかけられていないので、次の上位のタグPersonally identifiable informationを確認し、employeesに対してマスクルールがかけられていたため、それが適用されたという形です。
今回は2階層でしたが、3階層だとしても最初に評価された制御が優先的に適用されます。
さらに理解が深められる例が公式ドキュメントに記載されています。抜粋を添付します。

さらに詳しくは上記引用元たる以下をご参考いただければと思います。
データ マスキングの概要 | BigQuery | Google Cloud
列を除外することなくクエリが可能
試してみる
行列レベルアクセス制御を取り除いたproductsテーブルを使用します。
ポリシータグにはHighのサブタグとして、financeタグを用意しました。
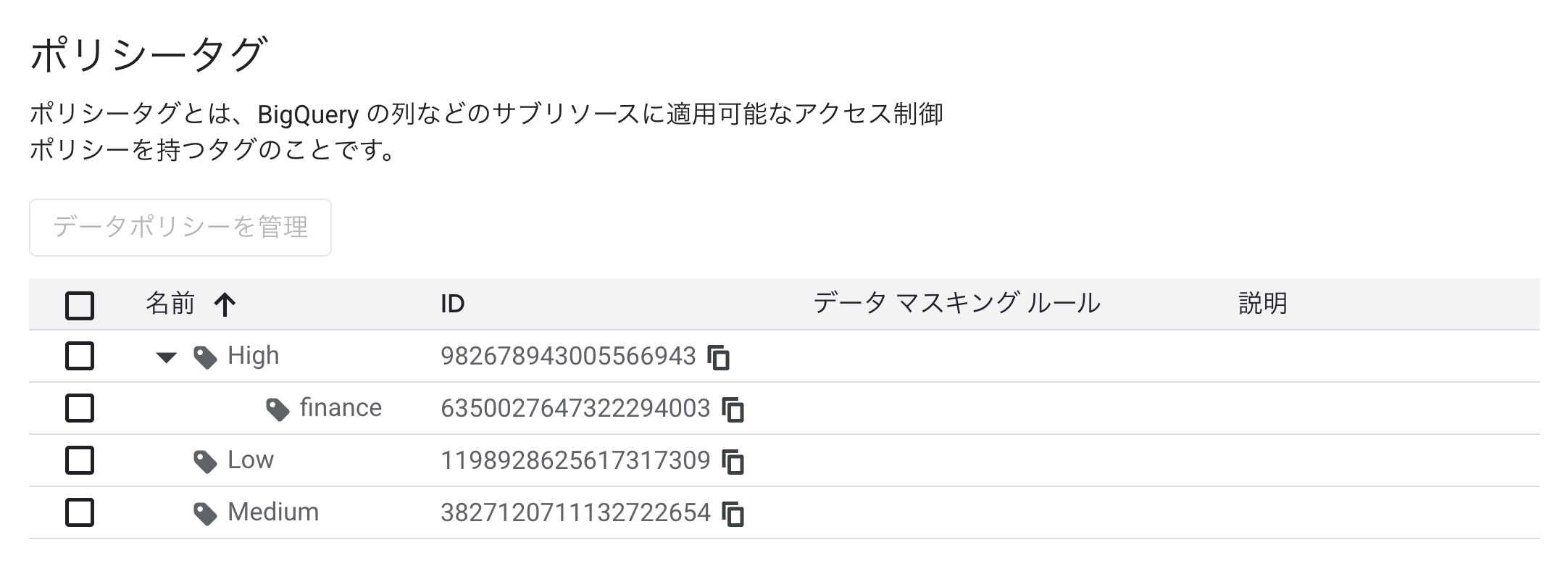
続けてfinanceタグに対してプリンシパルを追加します。
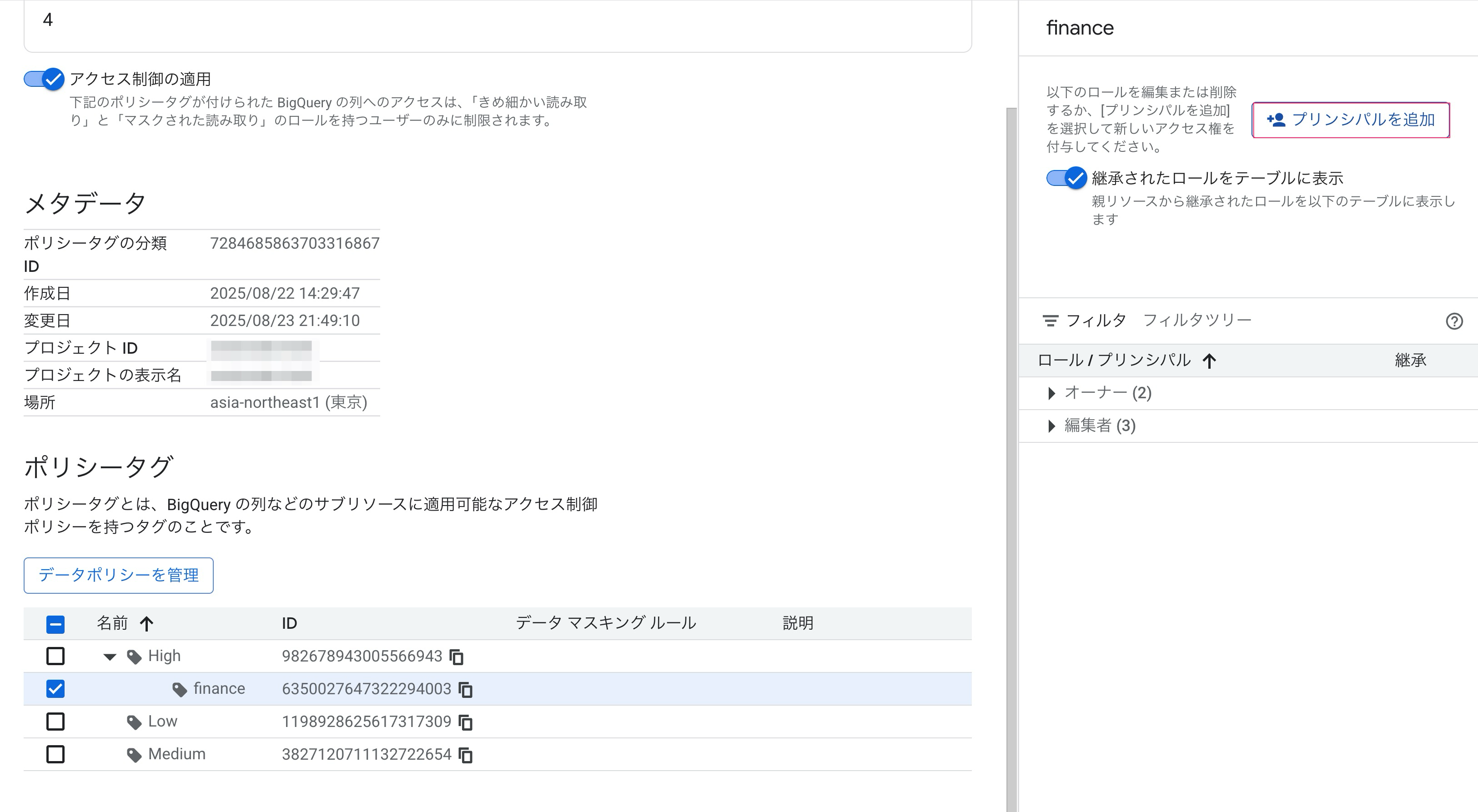
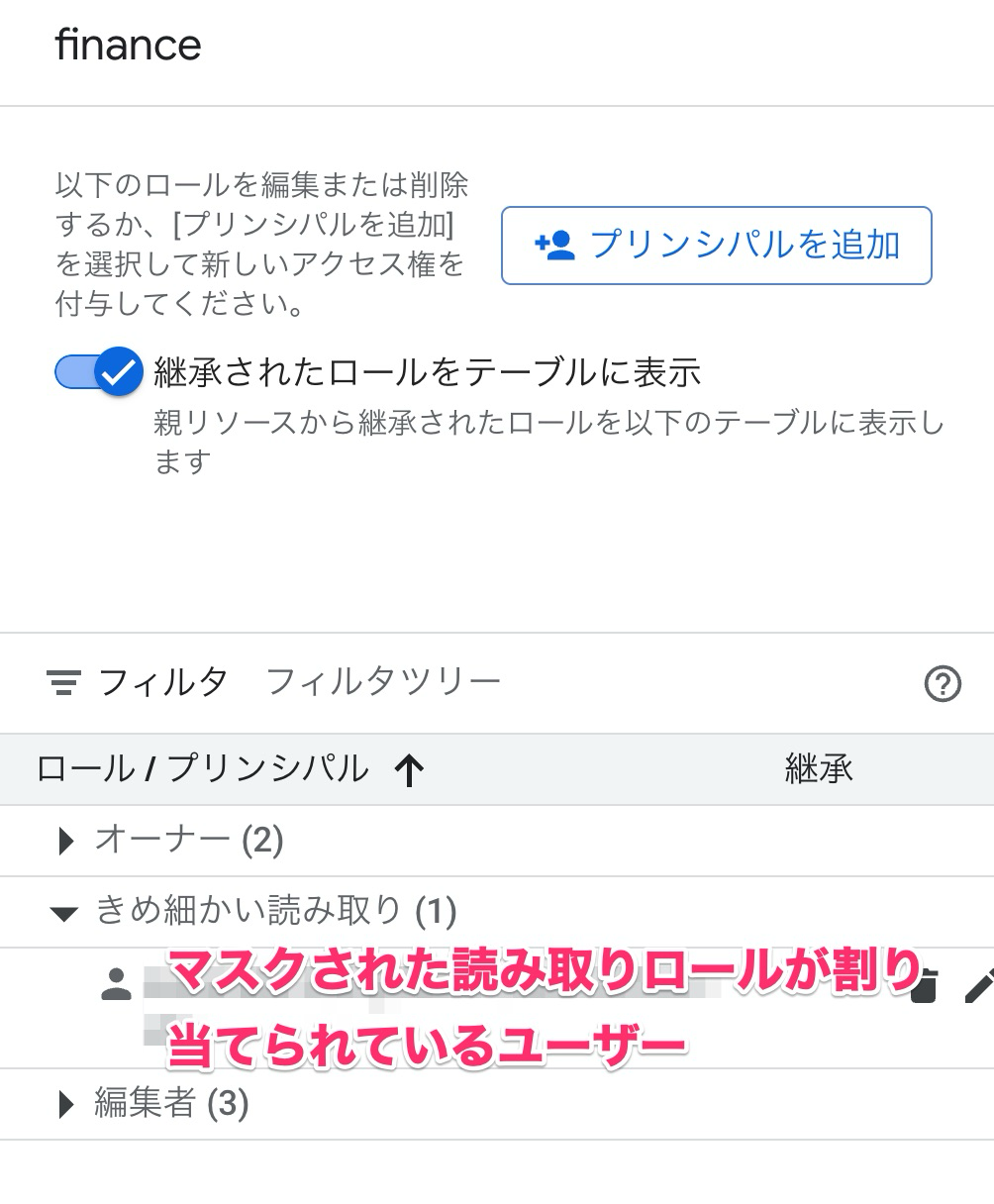
しかしマスクされた読み取りロールが表示されません。
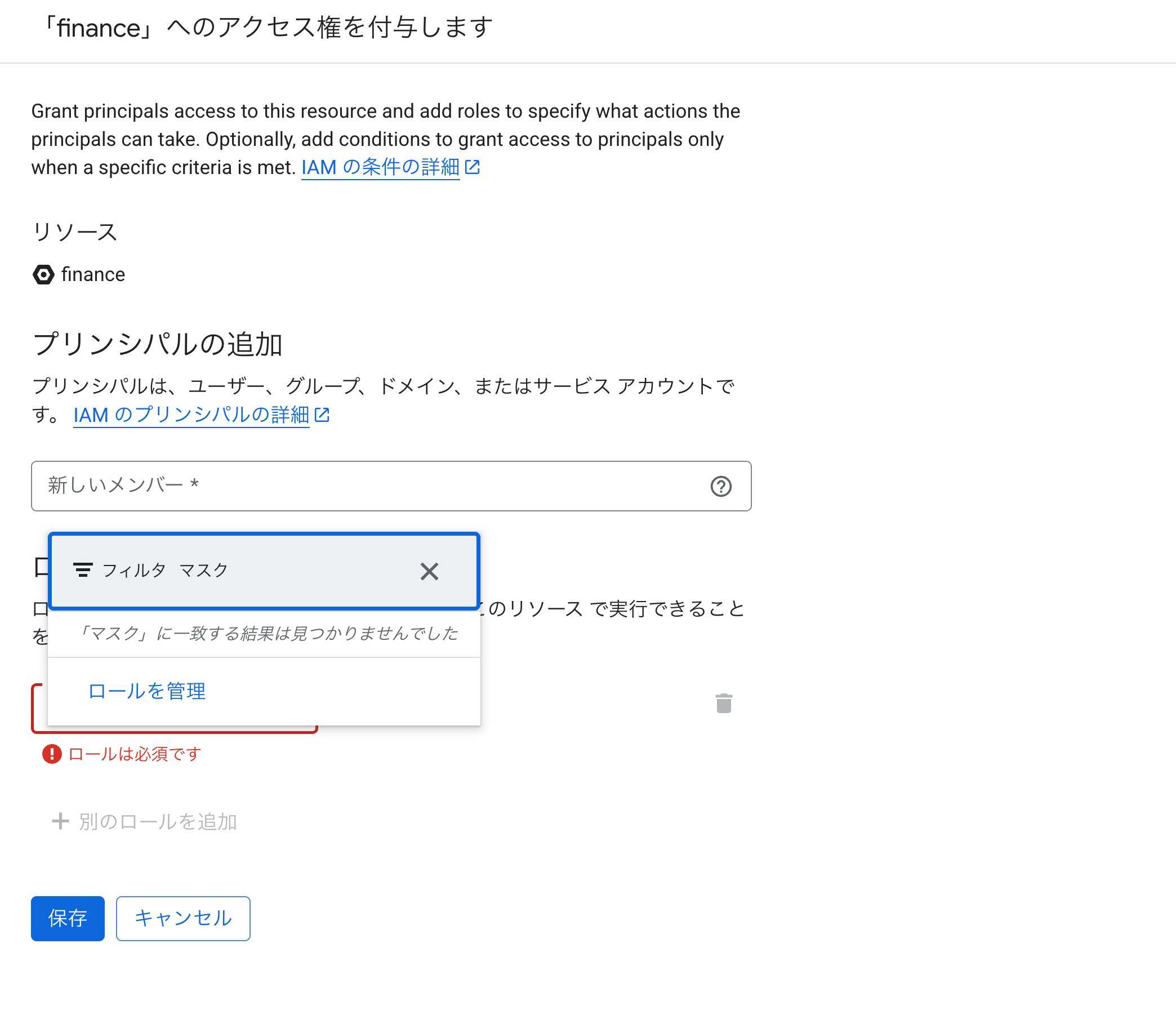
日本語だと出ないのかな?と思い「ロールを管理」から英語名を見つけて、改めて検索しても表示されません。
それもそのはず、マスクされた読み取りロールはデータポリシーの追加時に自動的にプリンシパルに割り当てられるものだったのです。
列レベルアクセス制御と違いますね。
ということで、「データポリシーを管理」でマスキングルールを設定します。
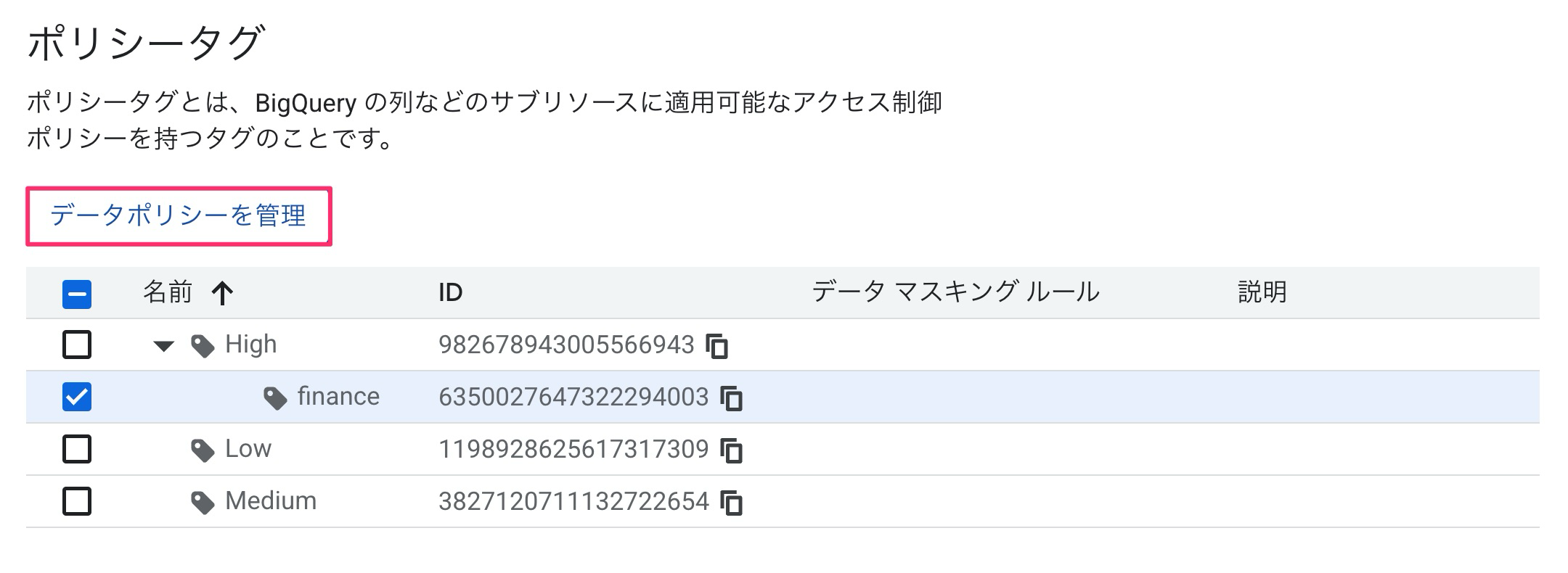
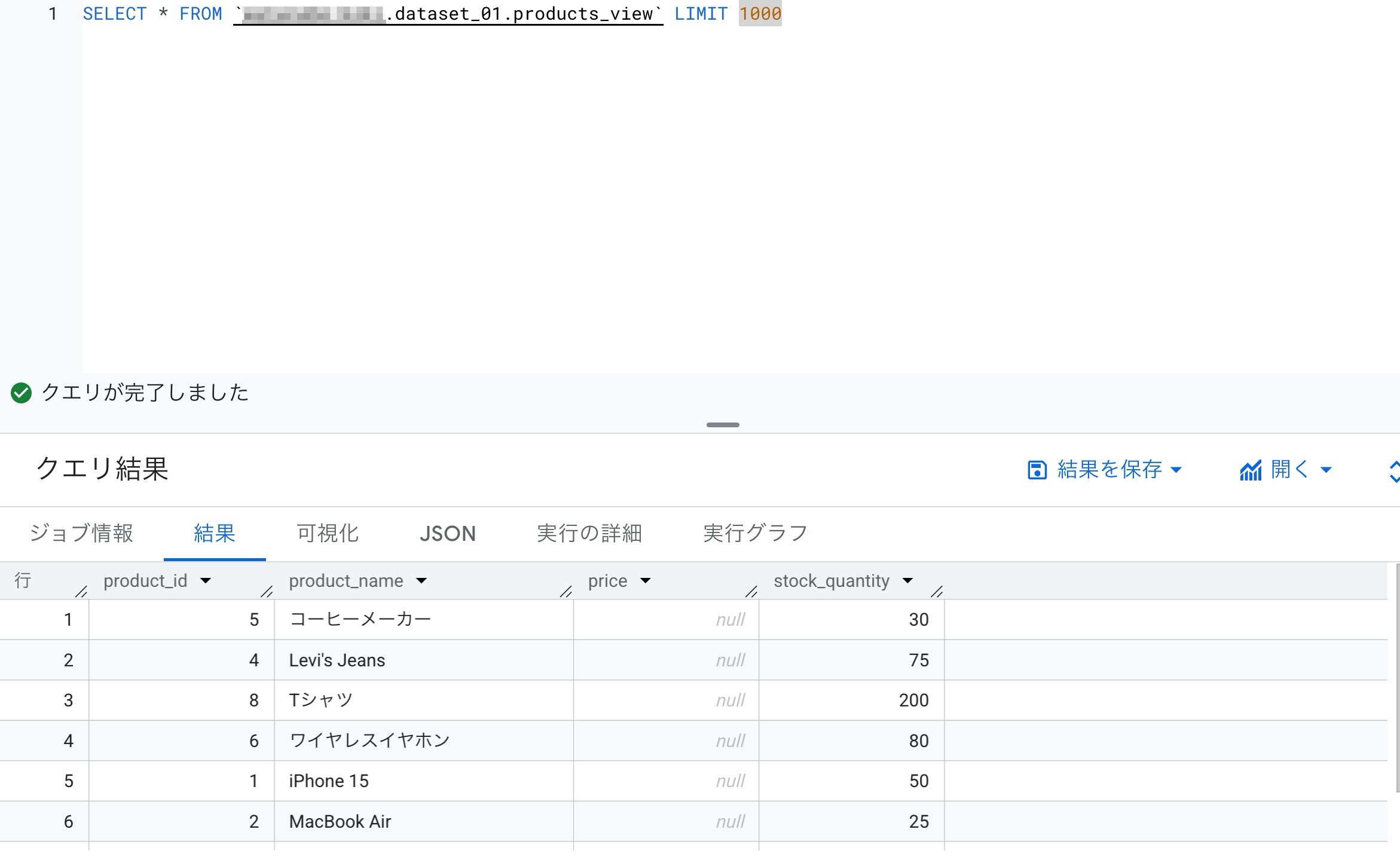
マスキングルールはnull化を選択して、クエリするプリンシパルを設定しました。
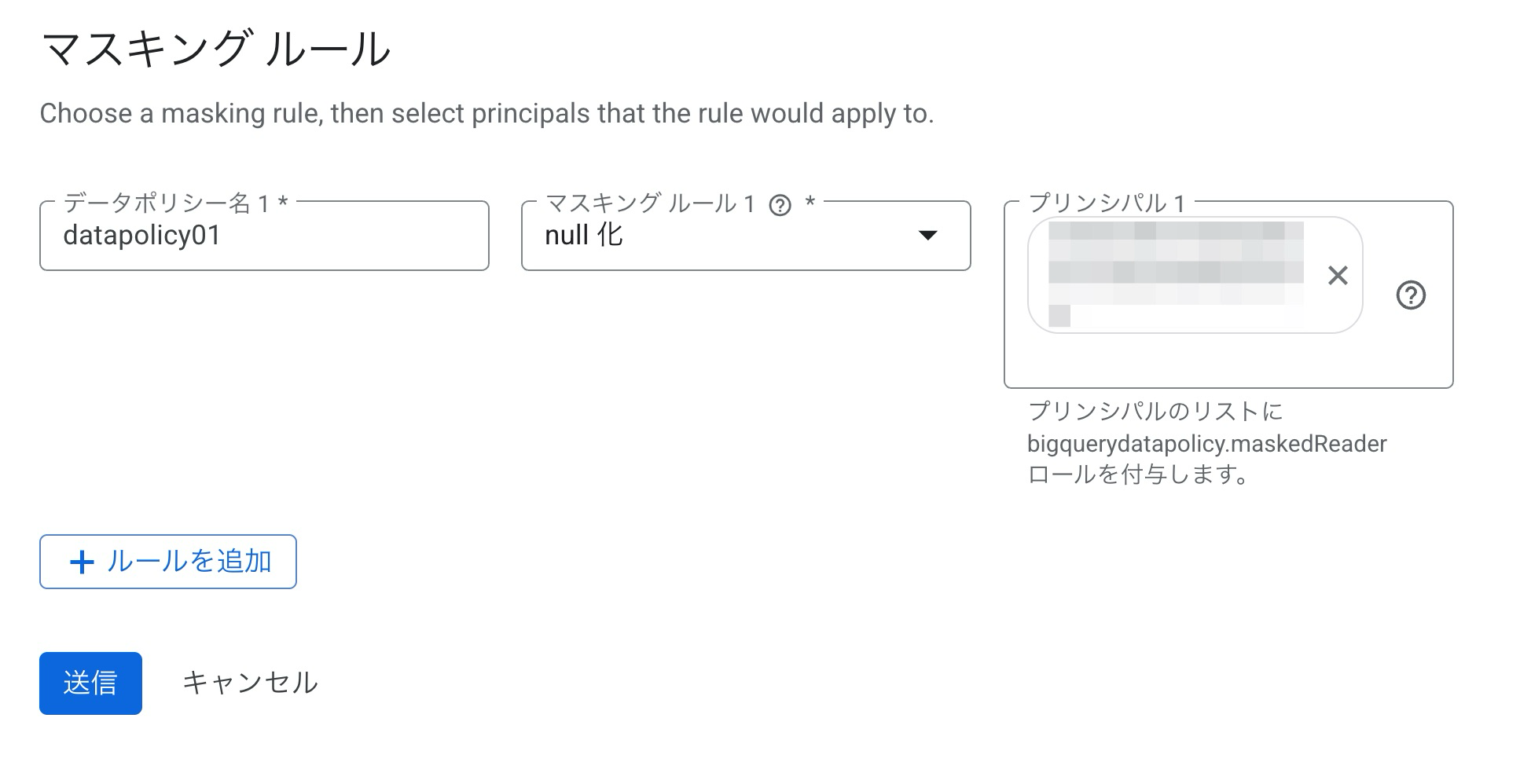
productsテーブルのpriceにfinanceタグを割り当てました。
クエリを実行すると、priceがnullとしてマスク表示されました。
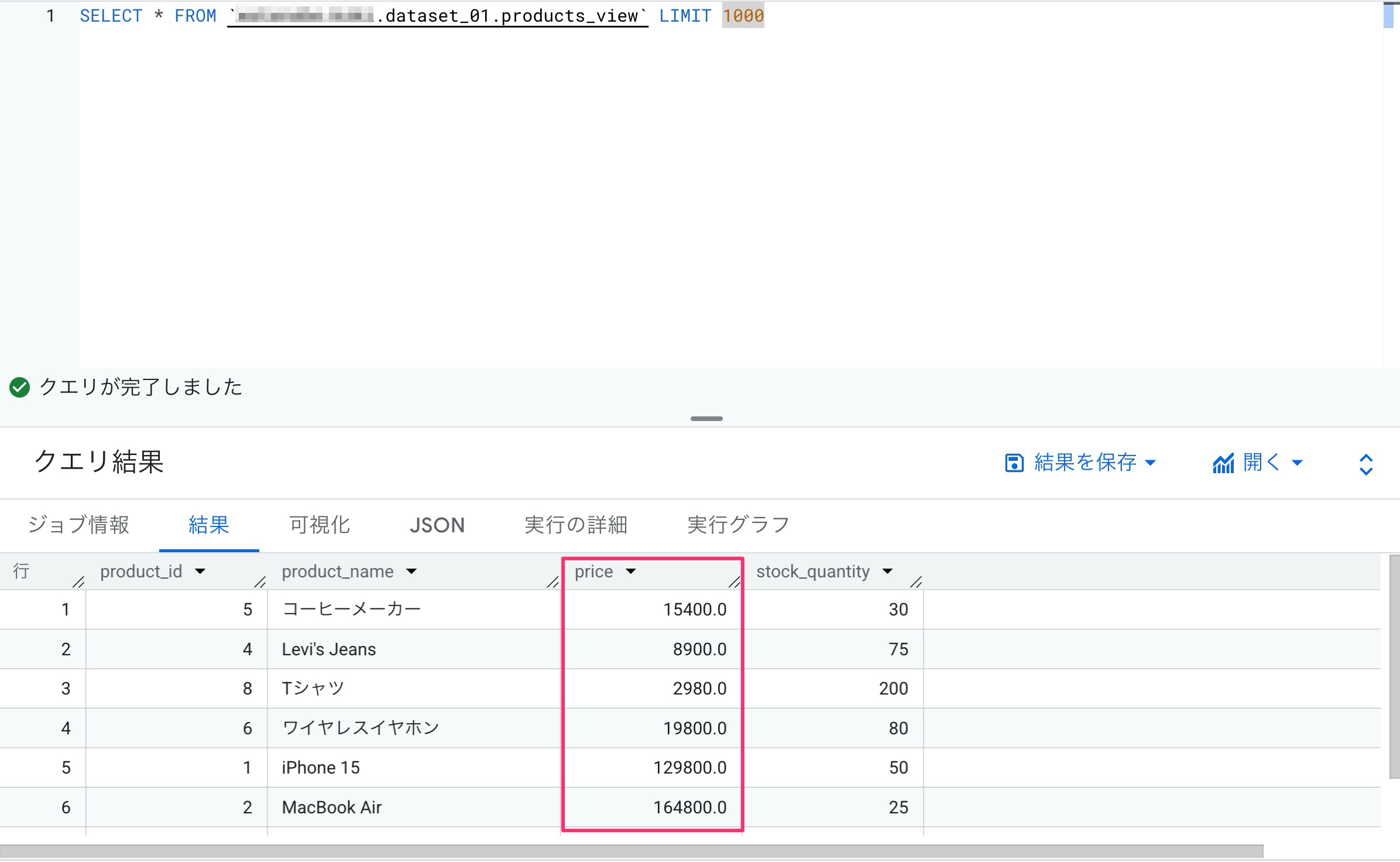
ちなみに、同じタグにきめ細かい読み取りロールを同じプリンシパルに割り当てた場合はどうなるんだろう?と思って試してみると、データはマスクされずに表示されました。
OR条件で広い権限の方が優先されると推測されます。
おわりに
いかがでしたでしょうか。
承認済みビュー・データセットは、ソースデータの権限を割り当てることなく本来あるべきデータ提供の仕組みを提供する意味で有用です。
また行列アクセス制御・データマスキングは、プリンシパルごとのきめ細かい権限制御に有用で、特に列レベルとマスキングについてはタグを使用した制御が可能なので、権限運用にも便利ですね。
今回の検証ではユーザーアカウントを使用して検証しましたが、入退場のことも考えるとグループを使用してグループに対して権限制御をするとよいでしょう。
公式ドキュメントでは今回記事に記載した内容がより詳しく記載されていますので、実際に権限制御機能を使用する際はご参考いただければと思います。
BigQuery でポリシータグを使用する際のベスト プラクティス | Google Cloud









