
BigQuery の description 自動生成機能が日本語対応したので、データプロファイルと組み合わせて試してみた
こんにちは!エノカワです。
この記事は Google Cloud Advent Calendar 2025 の 8日目の記事です。
BigQuery では Gemini を活用してテーブルやカラムの説明(description)を自動生成できる機能があります。
2025年11月5日のアップデートで日本語を含む複数言語での生成もサポートされました。
You can now generate table and column descriptions in all supported Gemini languages when you generate data insights. This feature is generally available (GA).
今回は、この説明の自動生成機能に加えてデータプロファイルを組み合わせることで、より精度の高い説明が生成できるのか検証してみました。
説明の自動生成機能とは
BigQuery の説明の自動生成機能は、Gemini がテーブルのメタデータやデータを分析し、テーブルやカラムの説明を自動で生成してくれる機能です。
BigQuery の「Data Insights(データインサイト)」機能の一部として提供されており、2025年8月25日に GA(一般提供)となりました。
基本的な使い方については、弊社の以下の記事で紹介されています。
上記の記事では「投稿日時点では、description は英語でのみ生成されます」と記載されていますが、2025年11月5日のアップデートで日本語を含む複数言語での生成がサポートされました。
データプロファイルとは
データプロファイルは、テーブルのデータを統計的に分析し、以下のような情報を提供する機能です。
- カラムごとのデータ分布
- NULL 値の割合
- ユニーク値の数
- 最小値・最大値
このプロファイル情報を Gemini が参照することで、カラム名だけでは推測しにくいテーブルでも、より正確な説明を生成できる可能性があります。
詳細は公式ドキュメントをご参照ください。
今回の検証内容
本記事では以下の流れで検証を行います。
- 曖昧なカラム名のテーブル(
col_1,col_2など)で日本語説明付与を試す - データプロファイル実行後に再度説明付与を試し、精度が向上するか確認する
検証1:曖昧なカラム名のテーブルで試す
まずは、カラム名だけでは意味が分かりにくいテーブルで説明生成を試してみます。
使用するテーブル
col_1 〜 col_9 という汎用的なカラム名を持つ検証用テーブルを使用します。
100件のユニークなデータが格納されており、カラム名からは内容を推測できない状態です。
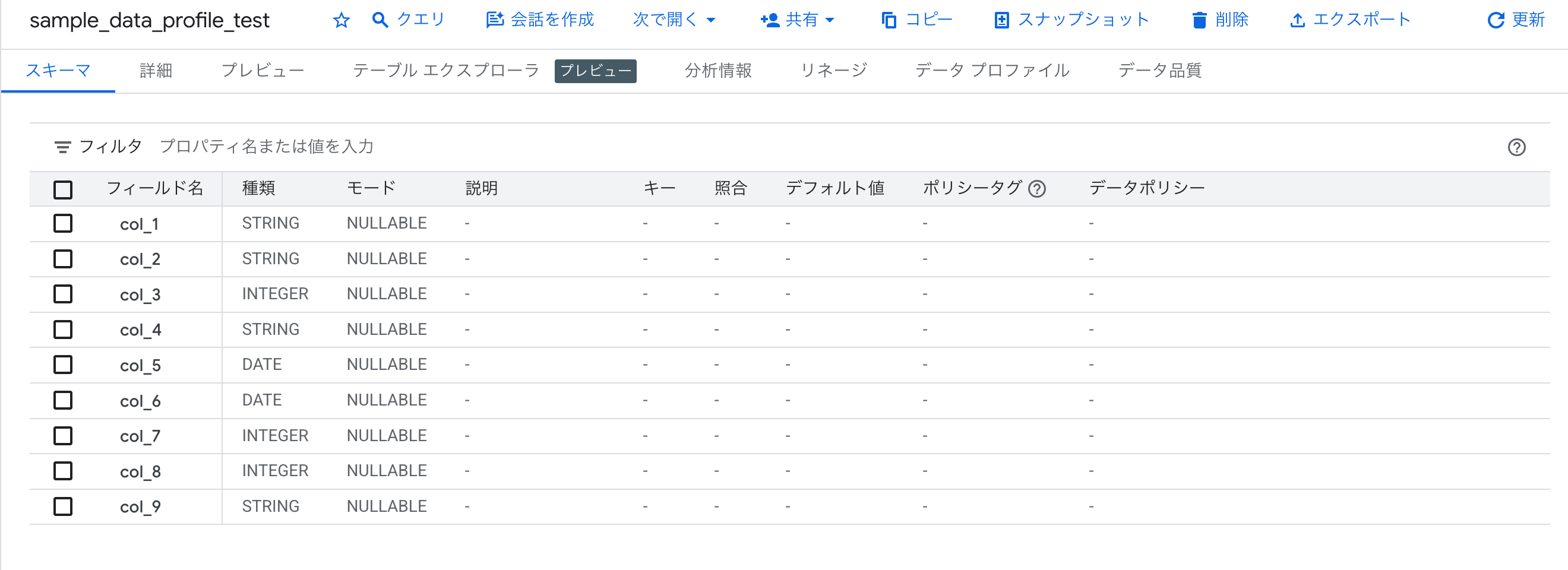
テーブルの中身を見ると、ユーザーID、氏名、年齢、都道府県、日付、金額などのデータが格納されていることが分かります。

カラムの実際の意味
検証結果を評価するため、各カラムの実際の意味を以下に示します。
| カラム名 | 実際の意味 |
|---|---|
col_1 |
ユーザーID |
col_2 |
氏名 |
col_3 |
年齢 |
col_4 |
居住地(都道府県) |
col_5 |
会員登録日 |
col_6 |
最終購入日 |
col_7 |
累計購入金額 |
col_8 |
購入回数 |
col_9 |
会員ランク |
日本語での説明生成を設定
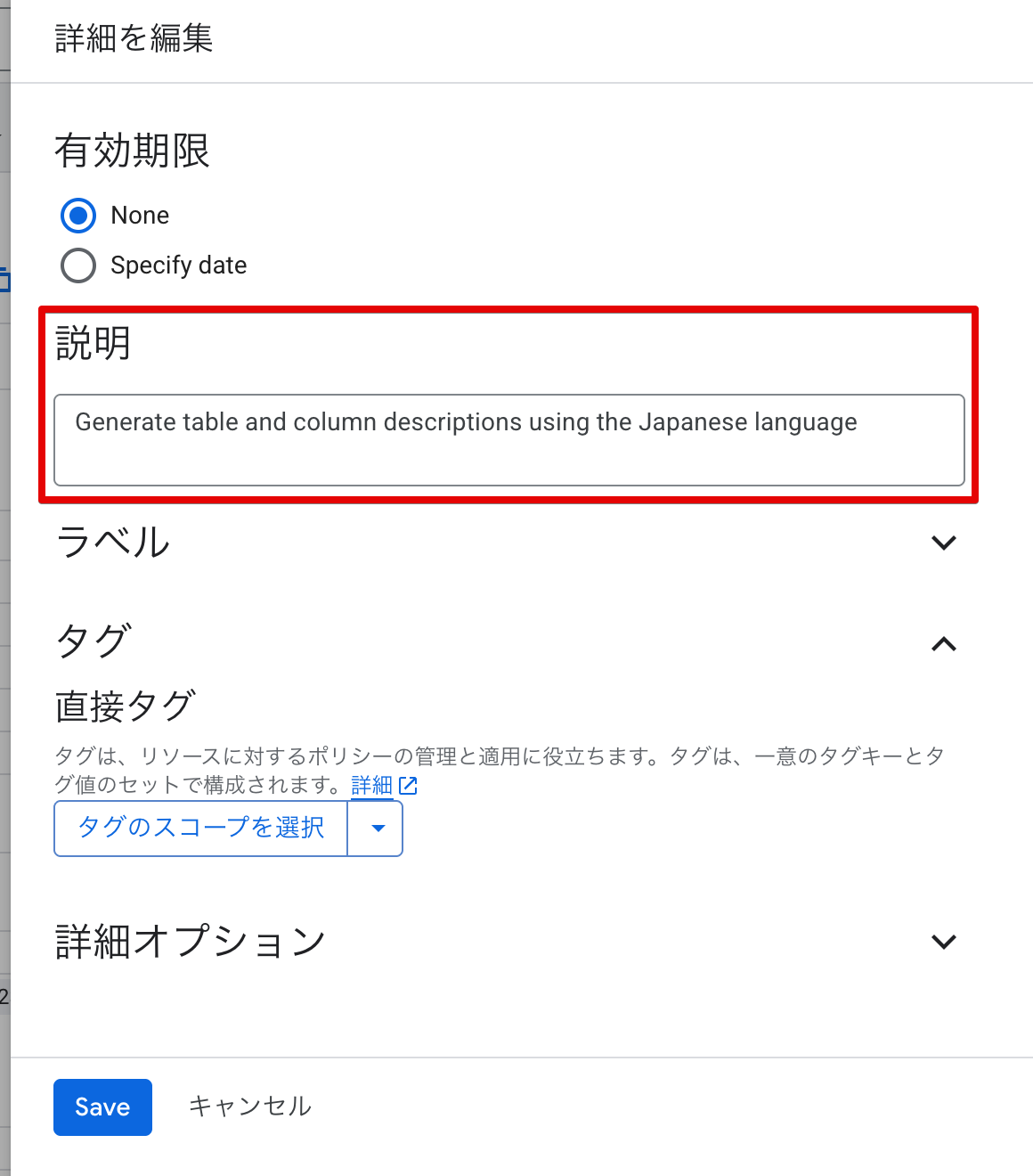
日本語で説明を生成するには、テーブルの説明欄に生成言語を指示する必要があります。
テーブルの「詳細を編集」から説明欄に Generate table and column descriptions using the Japanese language と入力して保存しておきます。
説明生成を実行
「分析情報」タブを開くと、説明生成のボタンが表示されます。
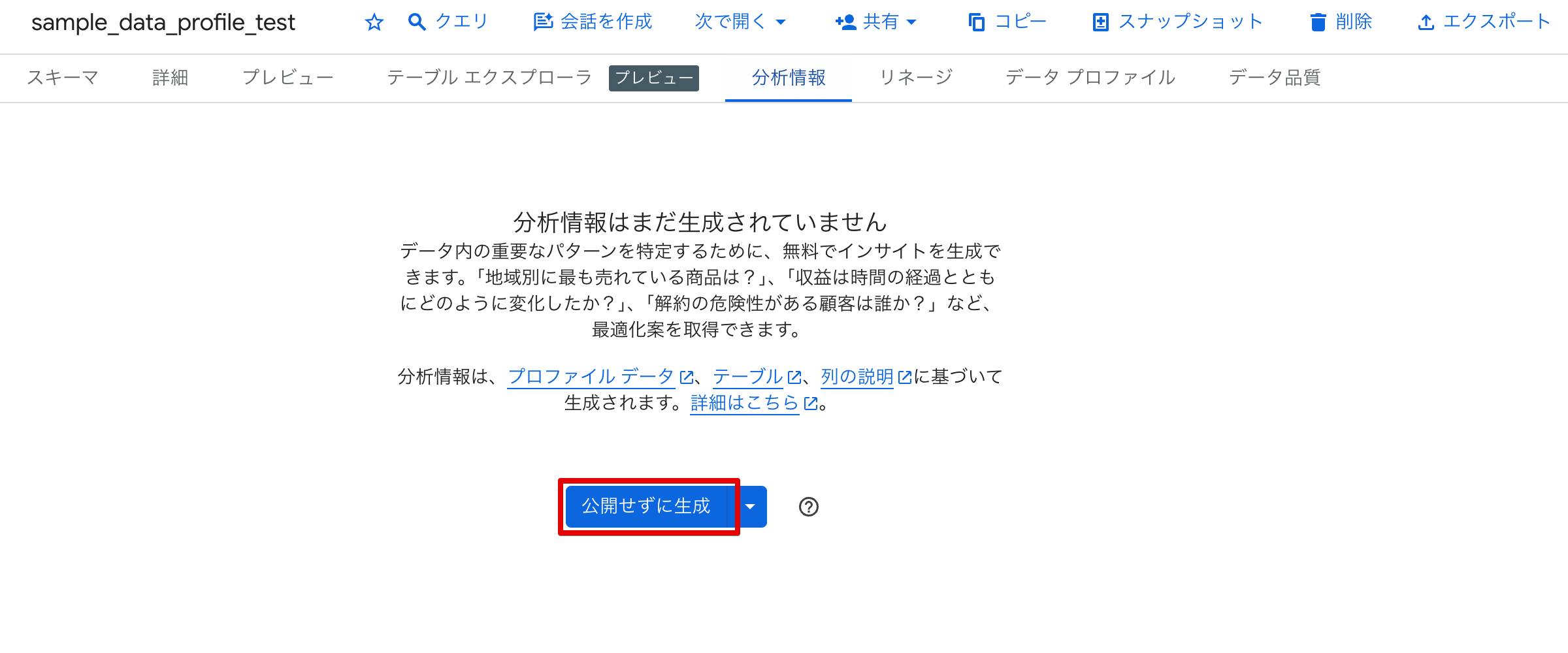
生成ボタンには以下の2つのオプションがあります。
- 公開せずに生成:オンデマンドで説明を生成します。Dataplex Universal Catalog には保存されず、一時的な生成となります
- 公開して生成:生成した説明を Dataplex Universal Catalog に永続化し、組織全体で共有できるようにします
今回は「公開せずに生成」を選択して説明を生成します。
結果
Gemini によって生成されたテーブルの説明と列の説明を確認します。
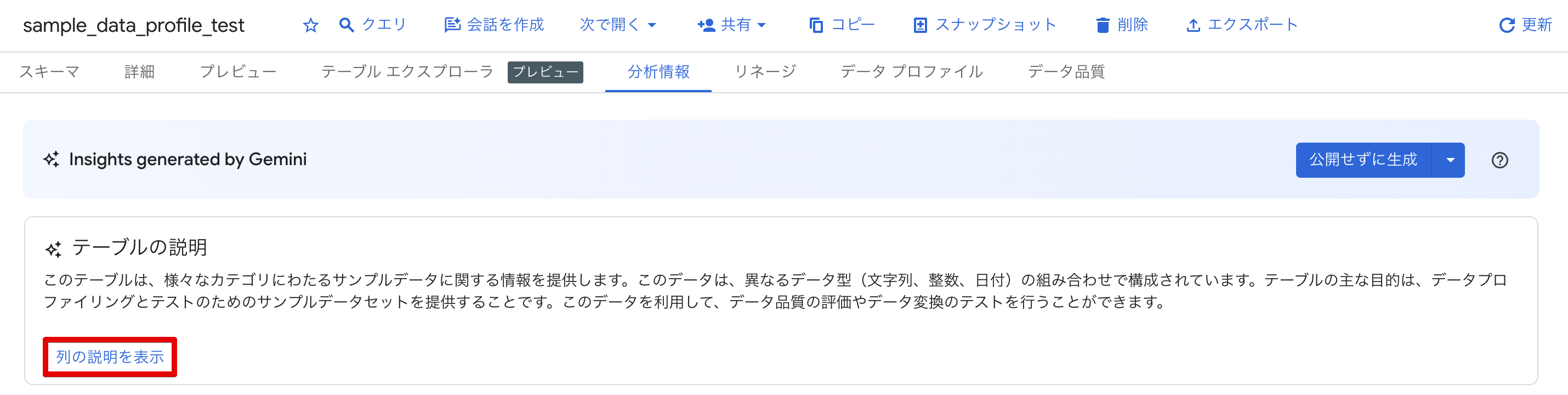
テーブルの説明:
このテーブルは、様々なカテゴリにわたるサンプルデータに関する情報を提供します。このデータは、異なるデータ型(文字列、整数、日付)の組み合わせで構成されています。テーブルの主な目的は、データプロファイリングとテストのためのサンプルデータセットを提供することです。このデータを利用して、データ品質の評価やデータ変換のテストを行うことができます。
テーブル名を sample_data_profile_test としたため、「データプロファイリングとテストのためのサンプルデータセット」という説明が生成されたようです。テーブル名から用途を推測していますが、実際のデータ内容(顧客情報)は認識できていません。
「列の説明を表示」をクリックすると、各カラムの説明が表示されます。
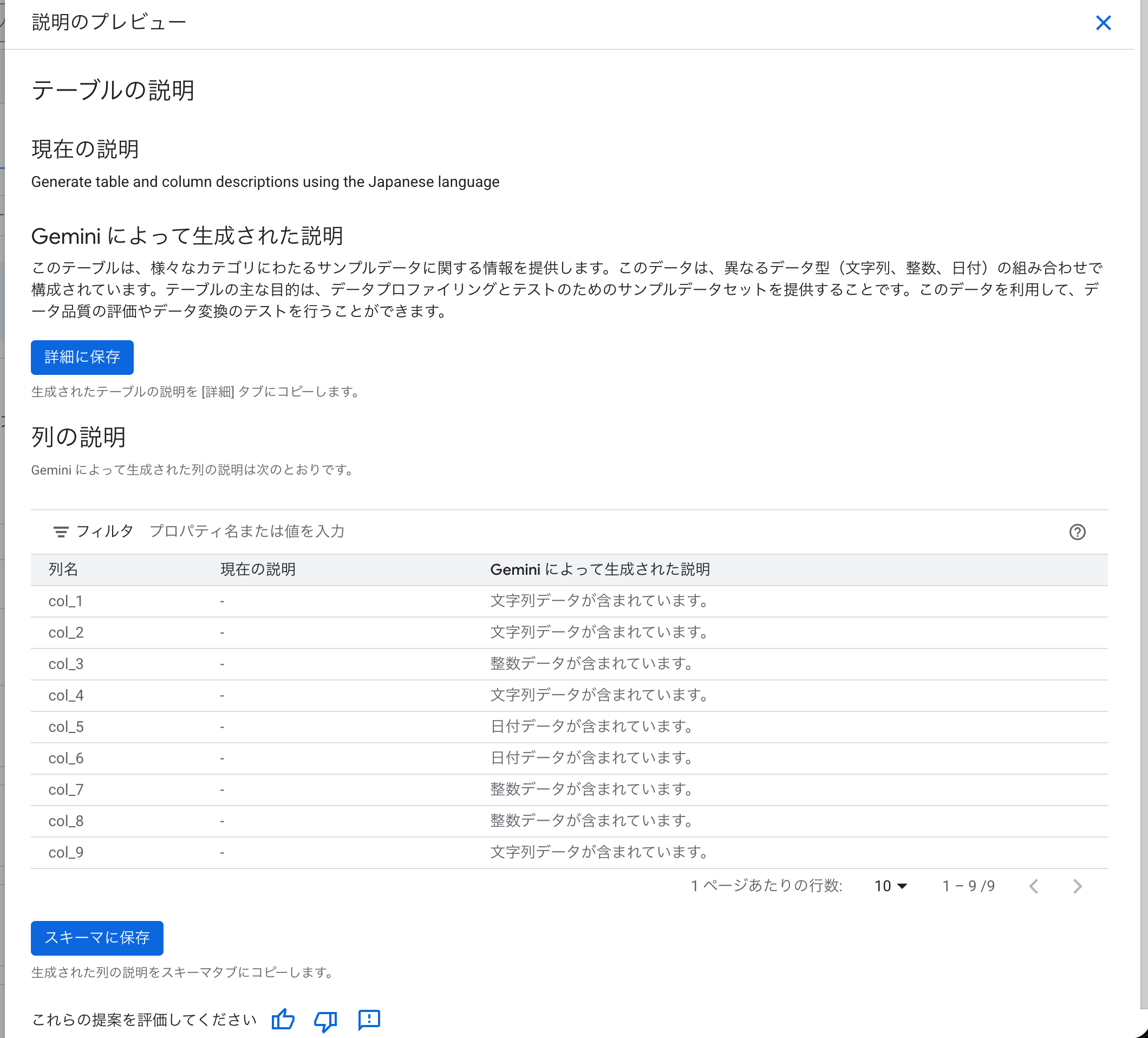
列の説明:
| カラム名 | Gemini によって生成された説明 |
|---|---|
col_1 |
文字列データが含まれています。 |
col_2 |
文字列データが含まれています。 |
col_3 |
整数データが含まれています。 |
col_4 |
文字列データが含まれています。 |
col_5 |
日付データが含まれています。 |
col_6 |
日付データが含まれています。 |
col_7 |
整数データが含まれています。 |
col_8 |
整数データが含まれています。 |
col_9 |
文字列データが含まれています。 |
カラム名とデータ型のみから推測した説明になっており、テーブルの実データは参照されていないようです。
そのため、データ型に基づいた一般的な説明にとどまっています。
検証2:データプロファイル実行後に再度試す
データプロファイルを実行し、再度説明生成を試してみます。
データプロファイルの実行
「データ プロファイル」タブを開き、「クイック データ プロファイル」ボタンをクリックします。
確認ダイアログが表示されます。
Dataplex を使用して、すべての列が 10% のサンプリングでプロファイリングされます。

なお、「クイック データ プロファイル」以外にも、以下のようなカスタマイズオプションが用意されています。
- スコープ設定:増分スキャンまたは全データスキャンの選択
- データフィルタリング:行フィルタや列フィルタの指定
- サンプリング率:0.001~100 の範囲で指定
- 実行スケジュール:定期実行(日次、週次など)またはオンデマンド
プロファイル結果
データプロファイルが完了すると、各カラムの統計情報が表示されます。

col_1 は「U0001」〜「U0100」のようなユニークな値、col_2 は日本人の氏名、col_3 は 22〜55 の範囲の整数(年齢)など、データの特徴が可視化されています。
説明生成を再実行
データプロファイル実行後、「分析情報」タブに戻り、検証1と同様に「公開せずに生成」を選択して説明を生成します。

結果
再度、Gemini によって生成されたテーブルの説明と列の説明を確認します。

テーブルの説明:
このテーブルは、顧客に関するサンプルデータを提供します。顧客の属性や行動に関する情報が含まれています。このデータを利用して、顧客セグメントの分析や、地域ごとの傾向把握が可能です。また、顧客のステータスや、特定の期間に関する情報も含まれています。
データプロファイル実行前は「様々なカテゴリにわたるサンプルデータ」という汎用的な説明でしたが、データプロファイル実行後は「顧客に関するサンプルデータ」と正しく認識できています。
データの中身を踏まえた説明になっており、顧客分析への活用方法まで言及されています。
「列の説明を表示」をクリックすると、各カラムの説明が表示されます。
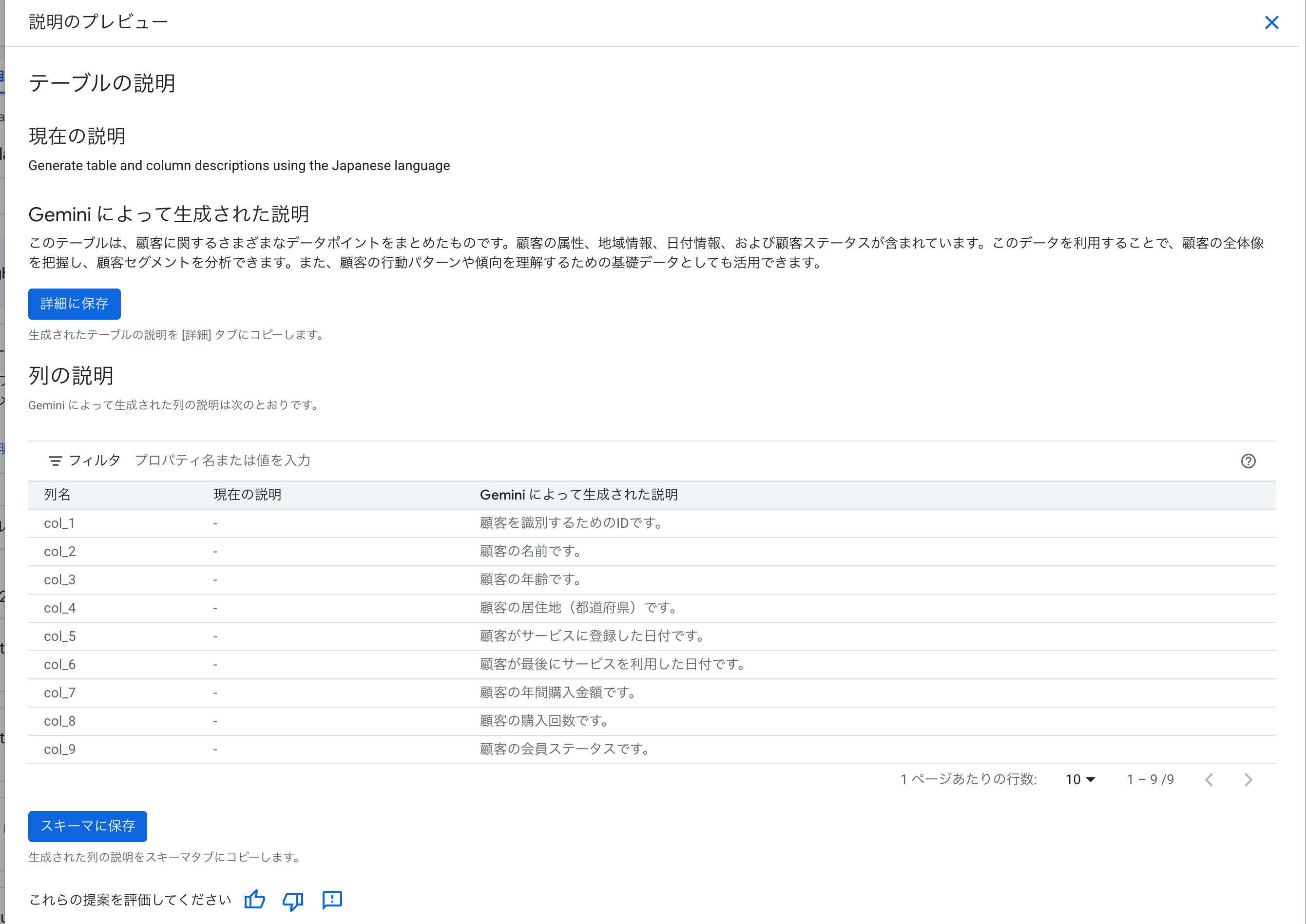
列の説明:
| カラム名 | Gemini によって生成された説明 |
|---|---|
col_1 |
顧客を識別するためのIDです。 |
col_2 |
顧客の名前です。 |
col_3 |
顧客の年齢です。 |
col_4 |
顧客の居住地(都道府県)です。 |
col_5 |
顧客がサービスに登録した日付です。 |
col_6 |
顧客が最後にサービスを利用した日付です。 |
col_7 |
顧客の年間購入金額です。 |
col_8 |
顧客の購入回数です。 |
col_9 |
顧客の会員ステータスです。 |
Gemini がデータプロファイル情報を参照することで、カラム名だけでは分からないデータの意味を正確に推測できました。
もちろん推測に基づく生成のため、必ずしも正しい説明が付与されるとは限らず確認は必要ですが、データプロファイルによってデータの特徴を捉えた説明が生成されていることがわかります。
説明の保存
生成されたテーブルの説明は「詳細に保存」から「提案された説明をコピー」して保存することができます。
生成されたカラムの説明は「スキーマに保存」ボタンでスキーマに反映できます。
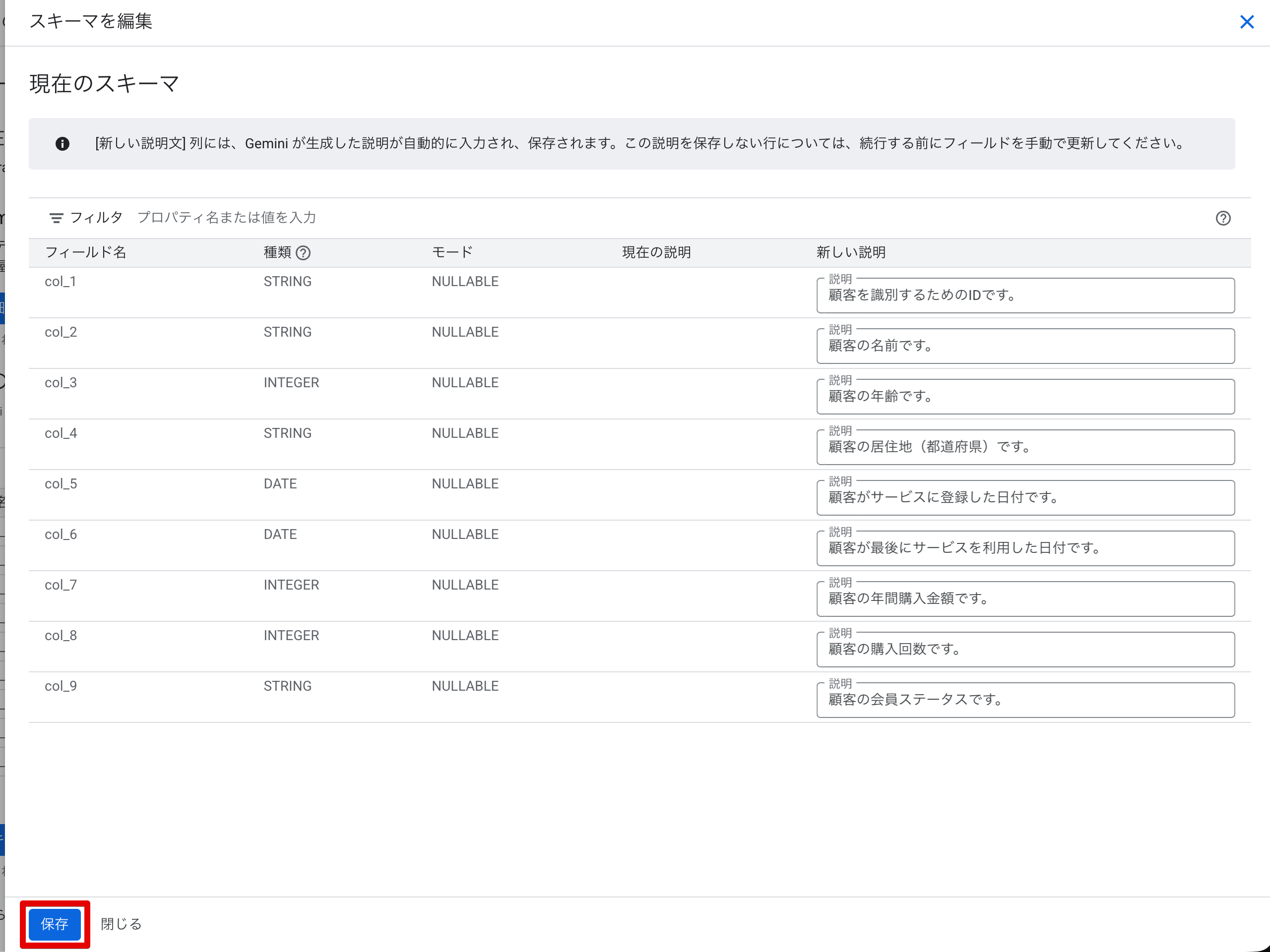
保存後、スキーマタブで説明が反映されていることを確認できます。
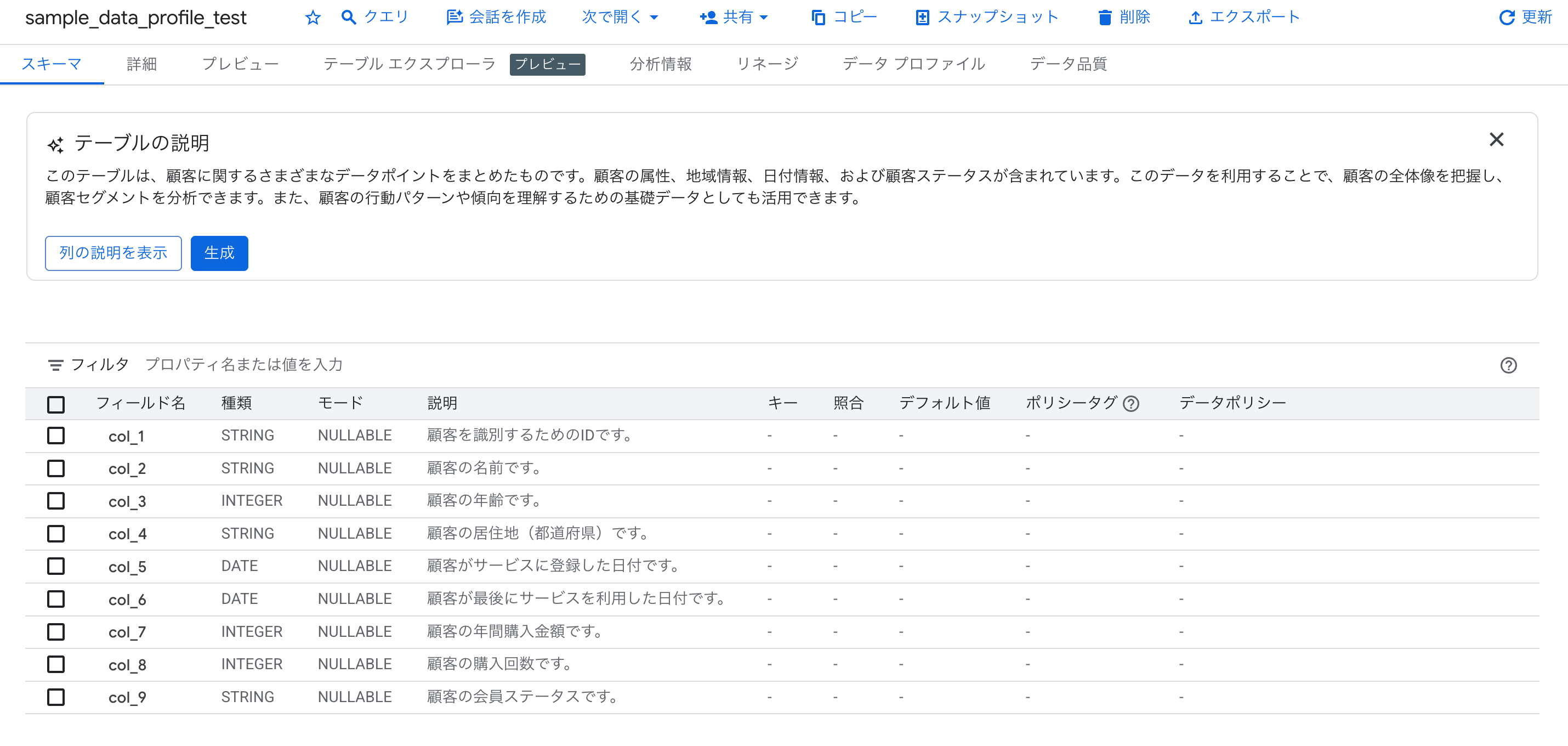
データプロファイル実行前後の比較
データプロファイルの有無によって、生成される説明がどのように変わるかを比較してみましょう。
| カラム名 | 実際の意味 | データプロファイル前 | データプロファイル後 |
|---|---|---|---|
col_1 |
ユーザーID | 文字列データが含まれています。 | 顧客を識別するためのIDです。 |
col_2 |
氏名 | 文字列データが含まれています。 | 顧客の名前です。 |
col_3 |
年齢 | 整数データが含まれています。 | 顧客の年齢です。 |
col_4 |
居住地(都道府県) | 文字列データが含まれています。 | 顧客の居住地(都道府県)です。 |
col_5 |
会員登録日 | 日付データが含まれています。 | 顧客がサービスに登録した日付です。 |
col_6 |
最終購入日 | 日付データが含まれています。 | 顧客が最後にサービスを利用した日付です。 |
col_7 |
累計購入金額 | 整数データが含まれています。 | 顧客の年間購入金額です。 |
col_8 |
購入回数 | 整数データが含まれています。 | 顧客の購入回数です。 |
col_9 |
会員ランク | 文字列データが含まれています。 | 顧客の会員ステータスです。 |
データプロファイル前は単にデータ型を述べるだけでしたが、データプロファイル後は「顧客」という文脈を理解し、各カラムの意味を適切に推測できています。
まとめ
本記事では、BigQuery の説明の自動生成機能とデータプロファイルを組み合わせて、より精度の高いテーブル説明を生成できるか検証しました。
検証の結果、データプロファイルを実行することで、説明の精度が大幅に向上することが確認できました。
テーブルの説明:
- データプロファイル実行前:「様々なカテゴリにわたるサンプルデータ」という汎用的な説明
- データプロファイル実行後:「顧客に関するサンプルデータ」と正しく認識し、顧客分析への活用方法まで言及
カラムの説明:
- データプロファイル実行前:「文字列データが含まれています」のようなデータ型ベースの説明
- データプロファイル実行後:「顧客を識別するためのID」「顧客の年齢」など、ビジネス上の意味を推測した説明
ユースケース
説明の自動生成機能とデータプロファイルの組み合わせは、以下のようなシーンで活用できそうです。
- レガシーシステムから移行したテーブルで、カラム名が不明瞭な場合
- データレイクに蓄積された大量のテーブルにメタデータを付与したい場合
- 新規メンバーがデータの理解を深めるためのドキュメント作成
テーブルやカラムの説明(メタデータ)は、データガバナンスやデータカタログの基盤となる重要な情報です。
しかし、手作業でメタデータを整備するのは時間と労力がかかります。
今回ご紹介した説明の自動生成機能を使えば、メタデータ整備も効率化できます。
特にデータプロファイルとの組み合わせにより、カラム名だけでは表現しきれないデータの意味を補完できることが確認できました。
ぜひ、皆さんのデータ管理にもお役立てください!
それでは、明日以降の クラスメソッド Google Cloud Advent Calendar 2025 も引き続きお楽しみください。










