
【BigQuery】Vertex AI SearchはObjectRef型からデータの中身を参照できるのか
データ事業本部の川中子(かわなご)です。
今回は非構造データの検索性を向上させるための仕組みについて、
Google Cloudのサービスを使って検証してみました。
主に扱うのは、新しく登場したBigQueryテーブルのデータ型であるObjectRef型と、
Google Cloudが提供する検索プラットフォームであるVertex AI Searchの2つです。
ObjectRef列を持つテーブルをソースにVertex AI Searchを利用してみました。
併せて、直接Cloud Storageをソースにした場合の挙動とも比較をしています。
データ型のObjectRef型については、以下の公式ブログをご参照ください。
今回の検証イメージは以下の通りです。
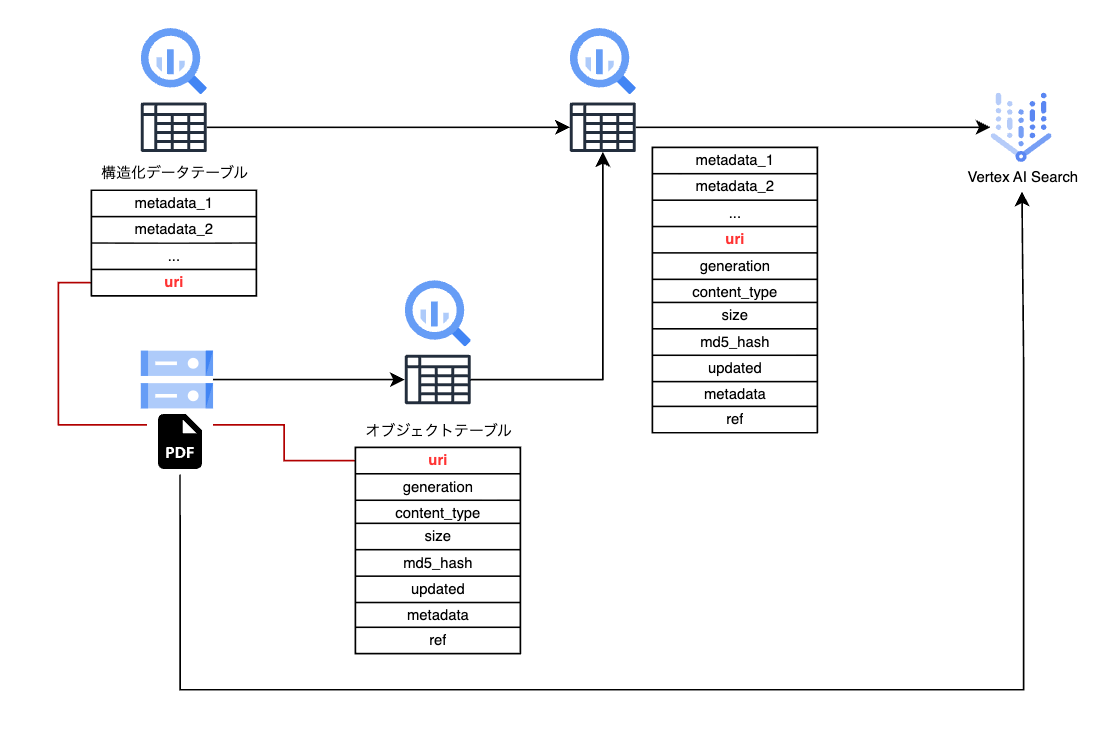
検証準備
テストファイルの準備
検証用に以下の3つのPDFファイルを用意しました。
balanced_diet_healthy_future.pdf
「医食同源」という言葉があるように、食事は私たちの健康を左右する重要な要素です。
バランスの取れた食事は、病気の予防だけでなく、日々の活力や精神的な安定にも
大きく影響します。理想的な食事の基本は、主食・主菜・副菜の組み合わせです。
炭水化物、タンパク質、脂質の三大栄養素に加え、ビタミンやミネラル、食物繊維を
バランス良く摂取することが重要です。特に野菜や果物に含まれる抗酸化物質は、
老化防止や生活習慣病の予防に効果的です。また、食事のタイミングも重要な要素です。
朝食をしっかりと摂ることで代謝が活性化され、夕食は就寝の3時間前までに
済ませることで、消化に負担をかけずに済みます。さらに、よく噛んで食べることで
満腹感が得られ、消化も促進されます。食事は単なる栄養補給ではなく、人生を
豊かにする文化でもあります。健康的な食習慣を通じて、心身ともに充実した
毎日を送りましょう。
exercise_habits_mind_body_transformation.pdf
運動は、私たちの生活に欠かせない健康維持の要素です。定期的な運動習慣は、
単に体力を向上させるだけでなく、精神的な健康や生活の質の向上にも大きく
貢献します。身体的な効果として、運動は心肺機能を強化し、筋力や骨密度を
向上させます。また、血液循環が改善され、生活習慣病のリスクを大幅に
減少させます。さらに、運動によって分泌されるエンドルフィンは、自然の
鎮痛剤として働き、ストレス軽減や気分の向上をもたらします。運動を始める際は、
無理をせず自分のペースで継続することが重要です。ウォーキングやストレッチ
などの軽い運動から始め、徐々に強度を上げていくことで、怪我のリスクを
避けながら効果を実感できます。また、友人や家族と一緒に運動することで、
モチベーションの維持にもつながります。運動は特別なものではなく、日常生活の
一部として取り入れるべき習慣です。階段を使う、一駅歩くなど、小さな変化から
始めて、健康で活力ある人生を築いていきましょう。
quality_sleep_changes_life.pdf
現代社会において、睡眠は軽視されがちな要素の一つです。しかし、質の良い睡眠
こそが、私たちの心身の健康を支える最も重要な基盤なのです。睡眠中、私たちの
脳は記憶の整理と定着を行い、体は細胞の修復と再生に専念します。十分な睡眠を
取ることで、免疫力が向上し、ストレス耐性も高まります。また、適切な睡眠は
集中力や判断力を向上させ、日中のパフォーマンスを大幅に改善します。良質な
睡眠を得るためには、規則正しい就寝時間の確立が重要です。寝室の環境を整え、
就寝前のスマートフォンやテレビの使用を控えることも効果的です。また、
カフェインの摂取は午後3時以降は避け、適度な運動を日常に取り入れることで、
自然な眠気を促進できます。睡眠は単なる休息ではなく、明日への投資です。
質の良い睡眠習慣を身につけることで、より充実した人生を送ることができるでしょう。
これらのファイルを cm-kawanago-unstructured-data-useast1バケットに格納しておきます。
cloudshell $ gsutil ls -l gs://cm-kawanago-unstructured-data-useast1/
104626 2025-08-26T00:56:39Z gs://cm-kawanago-unstructured-data-useast1/balanced_diet_healthy_future.pdf
104030 2025-08-26T00:56:39Z gs://cm-kawanago-unstructured-data-useast1/exercise_habits_mind_body_transformation.pdf
106389 2025-08-26T00:56:39Z gs://cm-kawanago-unstructured-data-useast1/quality_sleep_changes_life.pdf
TOTAL: 3 objects, 315045 bytes (307.66 KiB)
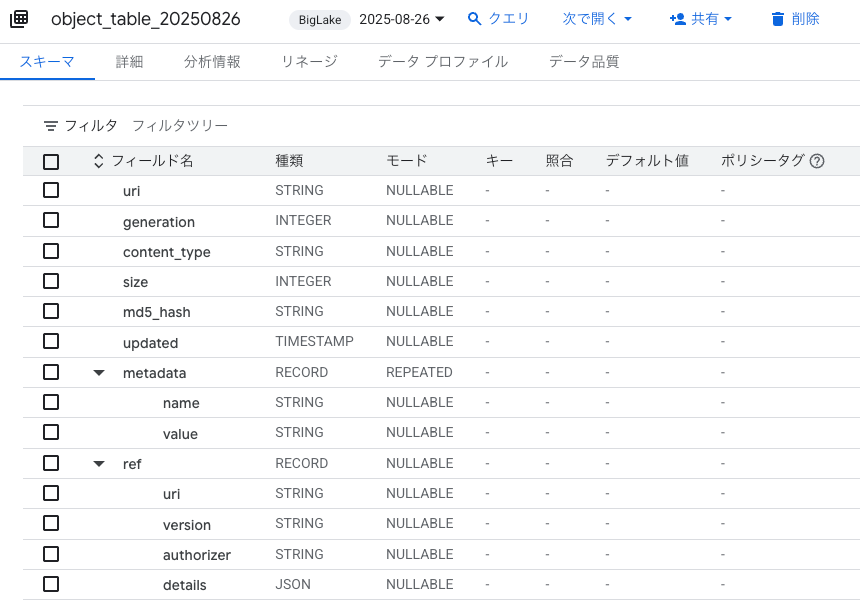
オブジェクトテーブルの作成
先ほど格納したオブジェクトを読み取るためのオブジェクトテーブルを作成します。
手順は以下のブログを参考にしています。
まず、BigQuery接続を作成します。
cloudshell $ bq mk --connection \
--location=us-east1 \
--connection_type=CLOUD_RESOURCE \
object-tables-connection-useast1
# 出力
Connection 123456789012.us-east1.object-tables-connection-useast1 successfully created
次に、サービスアカウントに権限を付与しておきます。
gsutil iam ch serviceAccount:bqcx-123456789012-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com:objectViewer \
gs://cm-kawanago-unstructured-data-useast1
オブジェクトテーブルを作成します。
CREATE EXTERNAL TABLE cm_kawanago_useast1.object_table_20250826
WITH CONNECTION `us-east1.object-tables-connection-useast1`
OPTIONS(
object_metadata = 'SIMPLE',
uris = ['gs://cm-kawanago-unstructured-data-useast1/*']
);
構造化データとの結合
工場のデータ管理情報を格納するサンプルテーブルを作成し、
uri列をキーにオブジェクトテーブルと結合していきます。
CREATE TABLE cm_kawanago_useast1.factory_data_20250826 (
data_id STRING NOT NULL,
factory_code STRING NOT NULL,
prefecture STRING NOT NULL,
data_type STRING NOT NULL,
generated_datetime TIMESTAMP NOT NULL,
production_line STRING,
equipment_id STRING,
process_stage STRING,
uri STRING NOT NULL
);
サンプルデータを挿入します。
最初の3行のURI列には、テスト用オブジェクトのURIを入力しています。
INSERT INTO cm_kawanago_useast1.factory_data_20250826 (
data_id,
factory_code,
prefecture,
data_type,
generated_datetime,
production_line,
equipment_id,
process_stage,
uri
) VALUES
('FAC001_20241201_001', 'TOK001', '東京都', 'CSV', '2024-12-01 08:15:30', 'LINE_A', 'HEALTH_001', 'ASSEMBLY', 'gs://cm-kawanago-unstructured-data-useast1/balanced_diet_healthy_future.pdf'),
('FAC002_20241201_002', 'OSA001', '大阪府', 'JSON', '2024-12-01 09:22:15', 'LINE_B', 'FOOD_02', 'INSPECTION', 'gs://cm-kawanago-unstructured-data-useast1/exercise_habits_mind_body_transformation.pdf'),
('FAC003_20241201_003', 'NGY001', '愛知県', 'LOG', '2024-12-01 10:45:00', 'LINE_C', 'CHICKEN_03', 'PREP', 'gs://cm-kawanago-unstructured-data-useast1/quality_sleep_changes_life.pdf'),
('FAC004_20241201_004', 'FKO001', '福岡県', 'IMAGE', '2024-12-01 11:30:45', 'LINE_A', 'CAMERA_04', 'PACKAGING', 'dummy://storage/factory004/data004.jpg'),
('FAC005_20241201_005', 'SPR001', '北海道', 'VIDEO', '2024-12-01 13:15:20', 'LINE_D', 'SENSOR_05', 'ASSEMBLY', 'dummy://storage/factory005/data005.mp4');
2つのテーブルを uri列をキーに結合します。
CREATE TABLE cm_kawanago_useast1.joined_object_table_20250826 AS
SELECT
f.*,
o.content_type,
o.updated,
o.ref
FROM
cm_kawanago_useast1.factory_data_20250826 f
RIGHT JOIN
cm_kawanago_useast1.object_table_20250826 o
ON
f.uri = o.uri
ORDER BY
f.generated_datetime DESC;
ファイル生成に関わるメタデータと、そのファイルのURIを持つテーブルができました。
これでデータの準備は完了です。
| data_id | factory_code | prefecture | data_type | generated_datetime | production_line | equipment_id | process_stage | uri | content_type | updated | ref |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FAC003_20241201_003 | NGY001 | 愛知県 | LOG | 2024-12-01 10:45:00 | LINE_C | CHICKEN_03 | PREP | gs://cm-kawanago-unstructured-data-useast1/quality_sleep_changes_life.pdf | application/pdf | 2025-08-26 00:56:39 | {"uri":"gs://cm-kawanago-unstructured-data-useast1/quality_sleep_changes_life.pdf"...} |
| FAC002_20241201_002 | OSA001 | 大阪府 | JSON | 2024-12-01 09:22:15 | LINE_B | FOOD_02 | INSPECTION | gs://cm-kawanago-unstructured-data-useast1/exercise_habits_mind_body_transformation.pdf | application/pdf | 2025-08-26 00:56:39 | {"uri":"gs://cm-kawanago-unstructured-data-useast1/exercise_habits_mind_body_transformation.pdf"...} |
| FAC001_20241201_001 | TOK001 | 東京都 | CSV | 2024-12-01 08:15:30 | LINE_A | HEALTH_001 | ASSEMBLY | gs://cm-kawanago-unstructured-data-useast1/balanced_diet_healthy_future.pdf | application/pdf | 2025-08-26 00:56:39 | {"uri":"gs://cm-kawanago-unstructured-data-useast1/balanced_diet_healthy_future.pdf"...} |
検証
前項までで準備したテーブルやバケットをソースに、
Vertex AI Searchを利用して簡易的な検索アプリを作ってみます。
作成手順については以下のチュートリアルを参考にしています。
パターン1:GCSをソースにした検索アプリ
■ アプリの作成
Vertex AI > Vertex AI Searchを開きます。
全て表示を押下します。
データストアを作成を押下します。
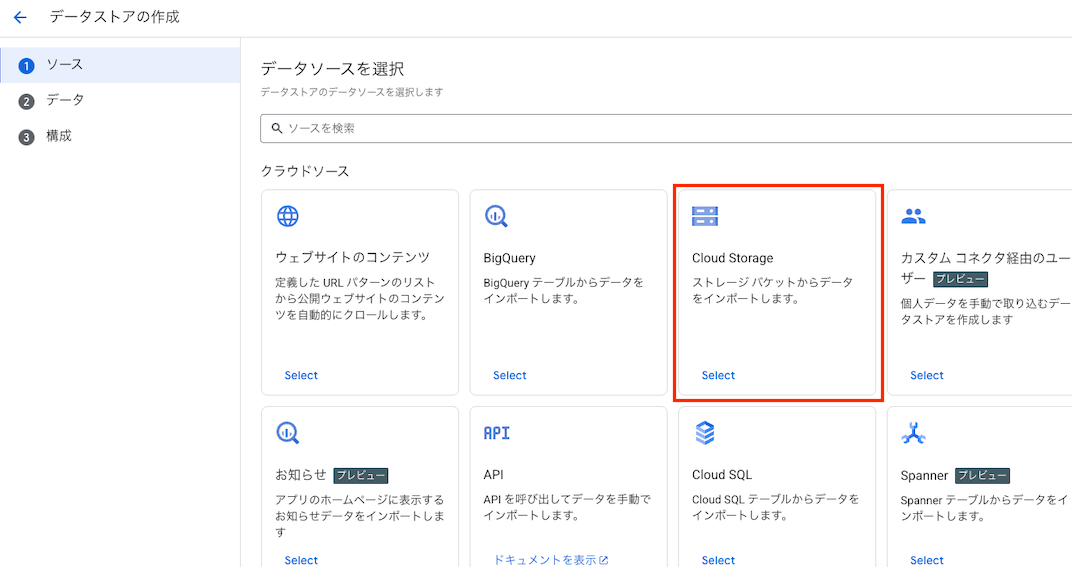
Cloud Storageを選択します。
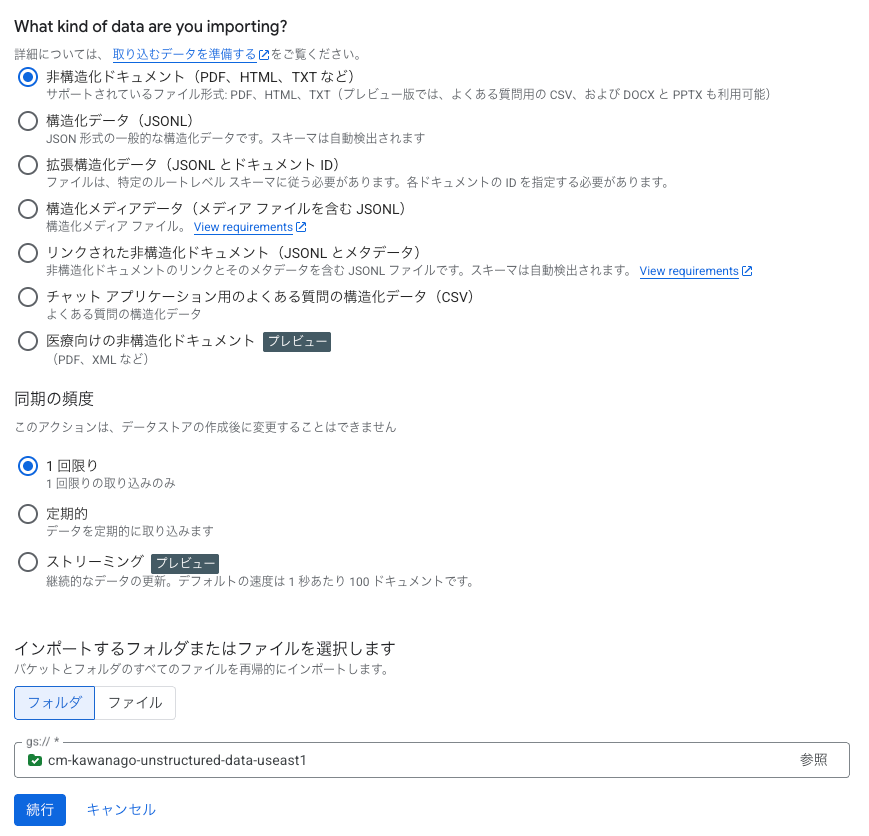
PDFを読み込みたいので 非構造化ドキュメント(PDF、HTML、TXT など)を選択します。
またあくまでも検証用なので、データの同期頻度は 1回限りにしています。
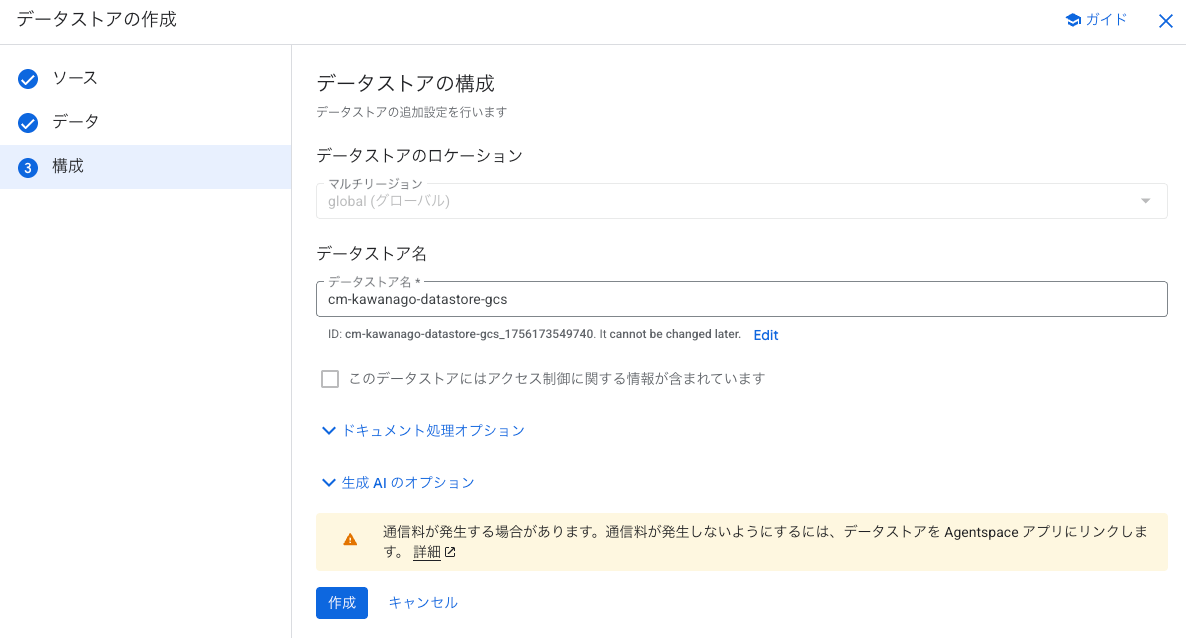
データストア名を設定し、作成を押下します。
次にアプリの一覧に移動し、アプリを作成するを押下します。
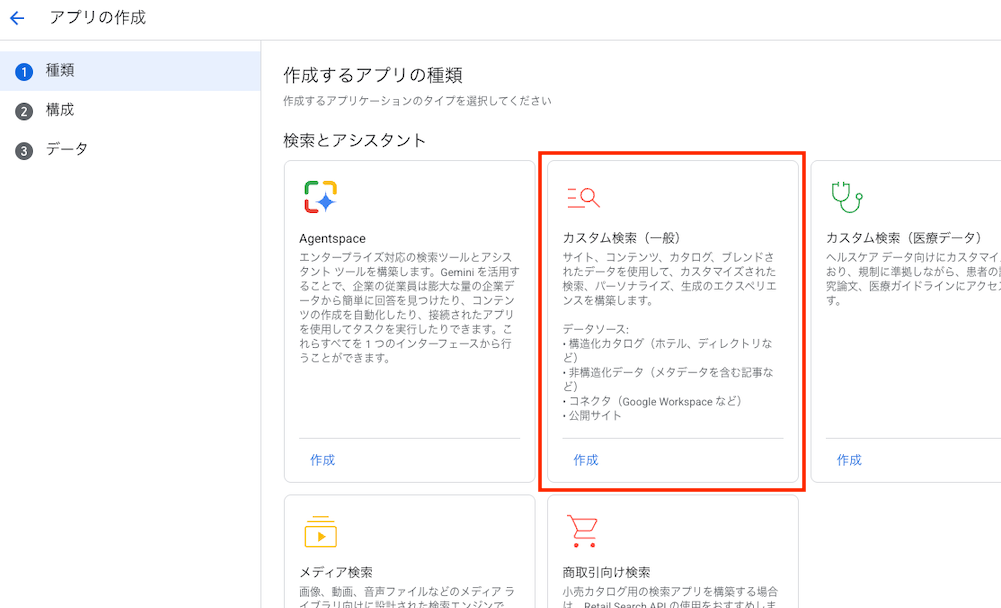
シンプルな検索システムを作りたいので、カスタム検索(一般)を選択します。
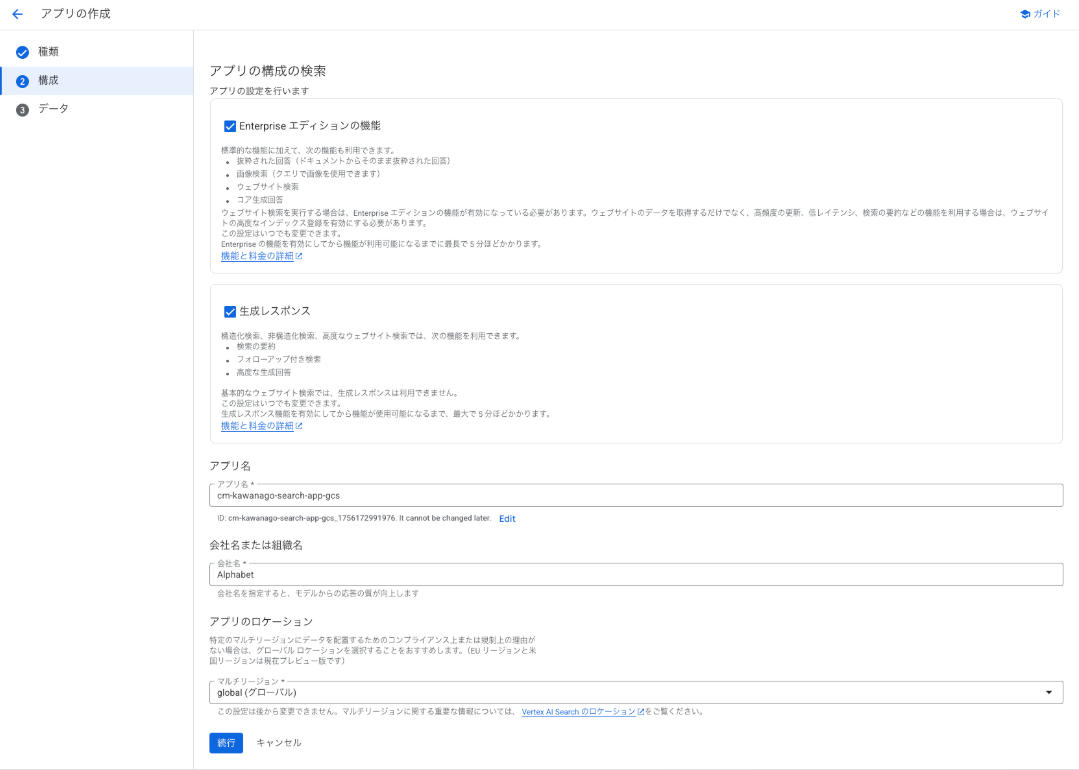
チュートリアルの設定に沿って項目を入力します。
アプリ名は cm-kawanago-search-app-gcsと設定しました。
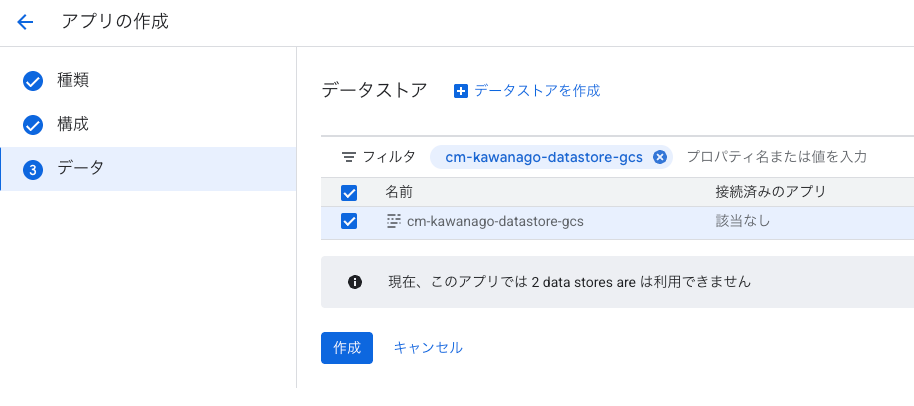
先ほど作成したデータストアを選択し、作成を押下します。
これで1つ目のアプリの作成は完了です。
■ 検索結果の確認
作成されたアプリは、構成ページから回答のカスタマイズが可能です。
デフォルトの 検索タイプでは、検索結果のみが表示されます。
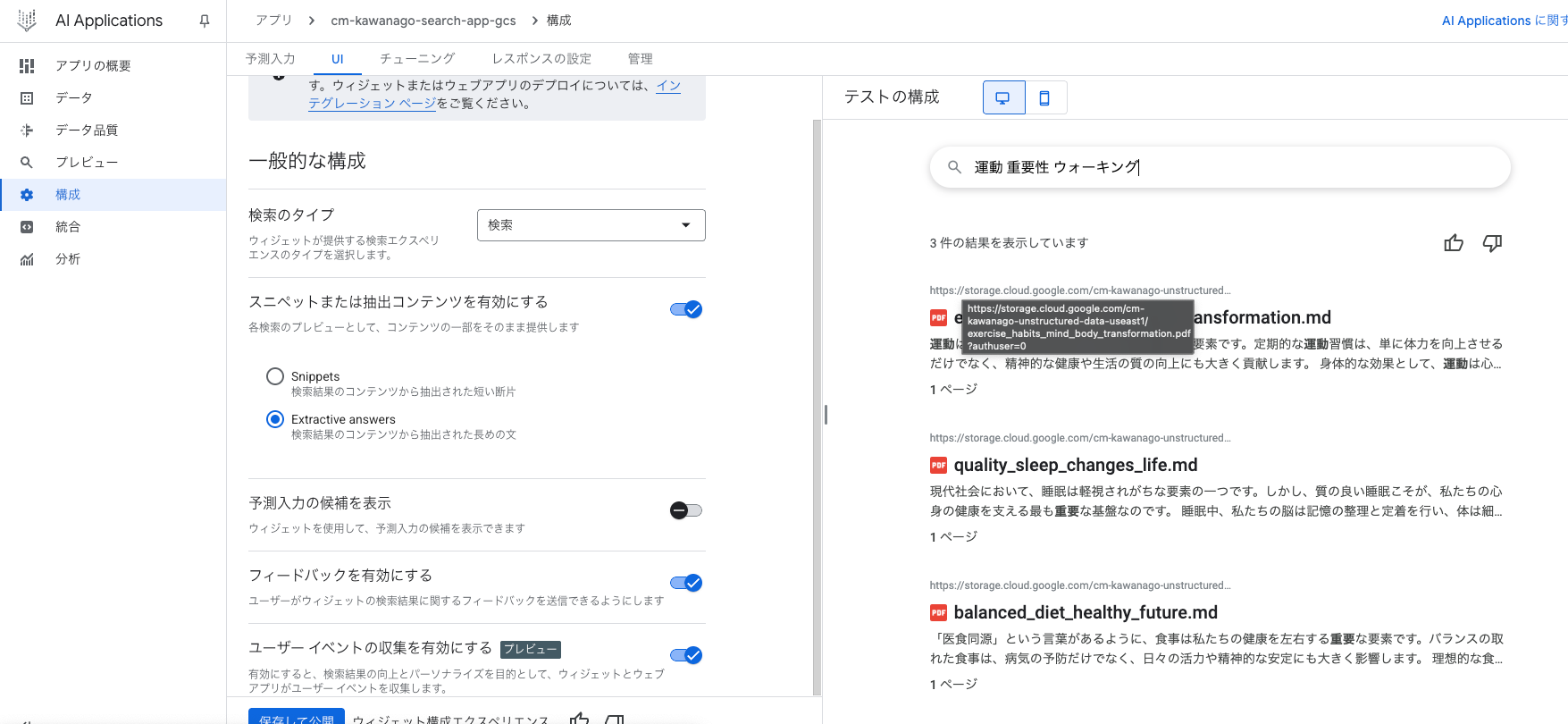
回答付きの検索では検索結果に加え、データを要約した回答を返してくれます。
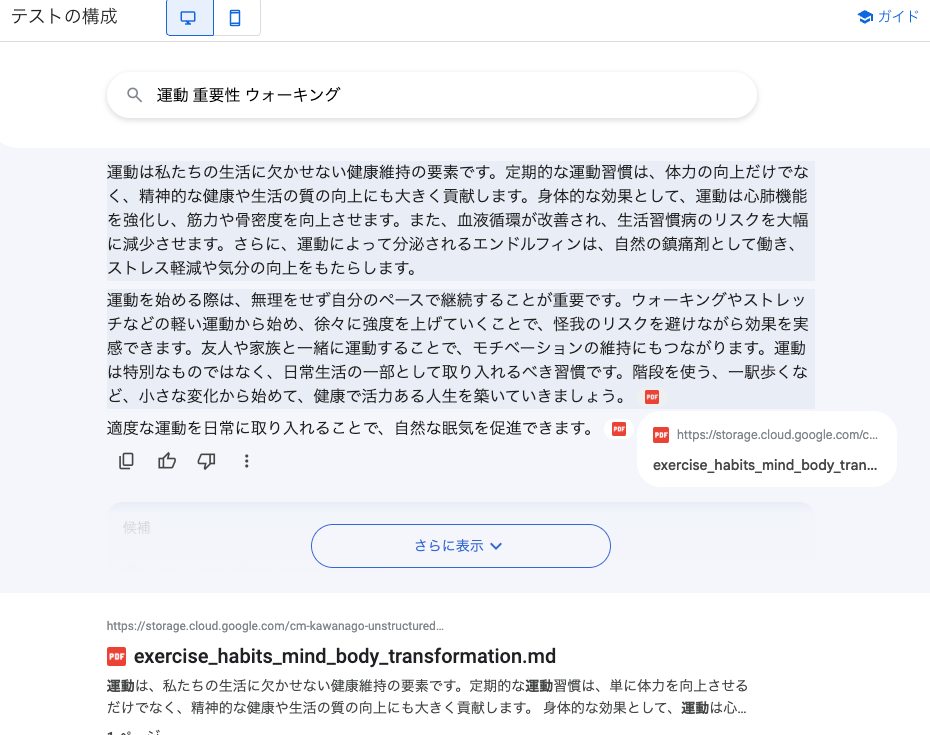
GCSをソースとした場合は、PDFの中身まで検索可能であることが確認できました。
パターン2:BigQueryテーブルをソースにした検索アプリ
■ アプリの作成
次にオブジェクトテーブルと結合したテーブルをソースにアプリを作ります。
基本的な手順は前述の通りで、まずはデータストアから作成します。
今回はクラウドソースに BigQueryを選択します。
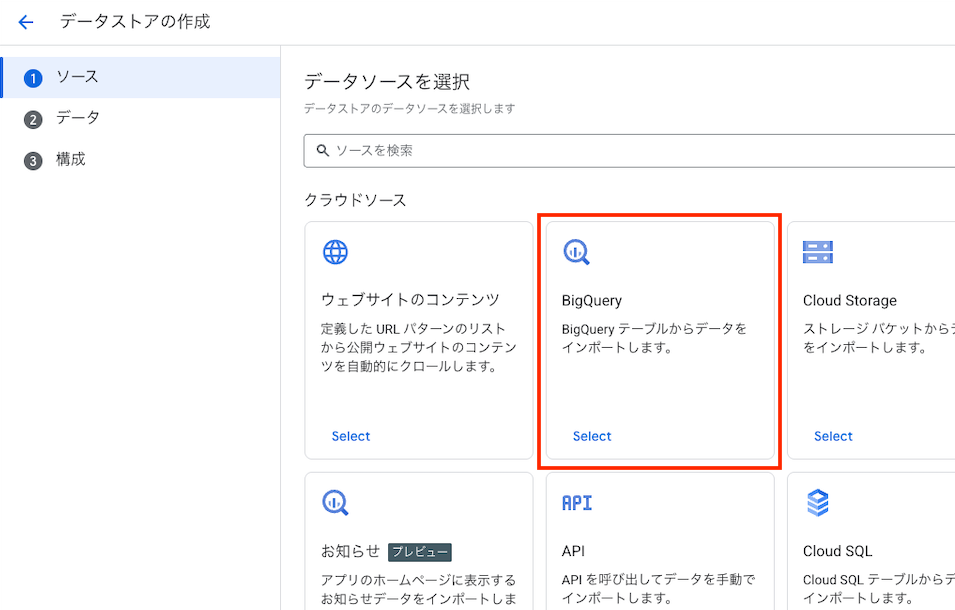
Structured - BigQuery table with your own schemaにチェックを入れ、
先ほど作成したテーブルを選択しています。
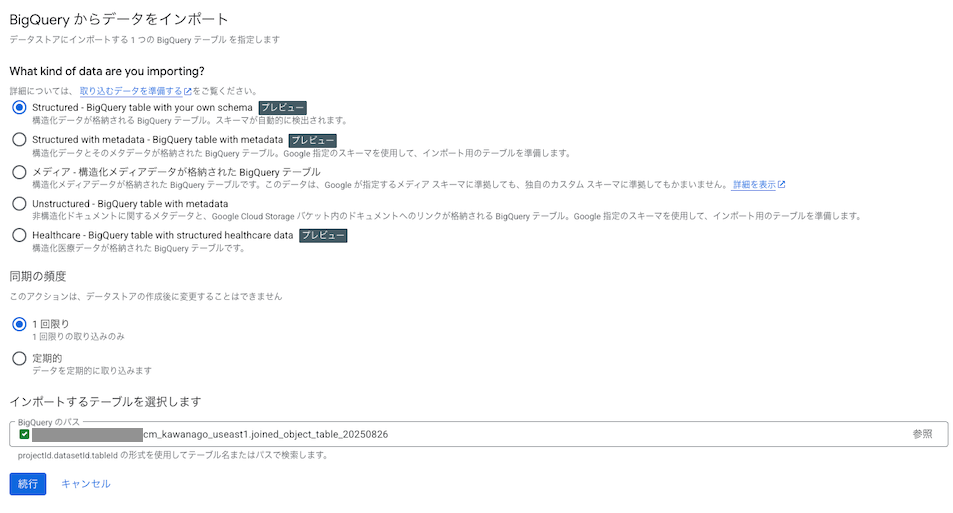
検出されたスキーマをそのまま利用するので、何も変更せずにページ下部の 続行を押下します。
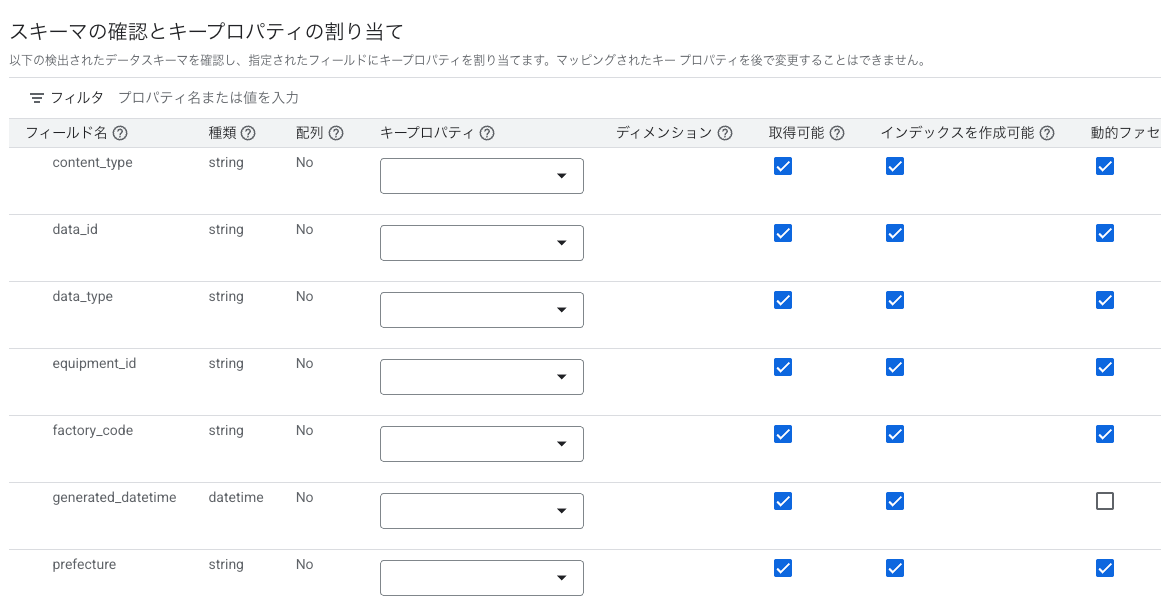
データストア名を設定し、作成を押下します。
cm-kawanago-search-app-bigqueryという名前で新しいアプリを作成し、
直前に作成したデータストアをアタッチしました。
■ 検索結果の確認
GCSソースの時と同じキーワードで検索をかけてみると、
検索ができず 該当する結果が見つかりませんでした。と表示されました。
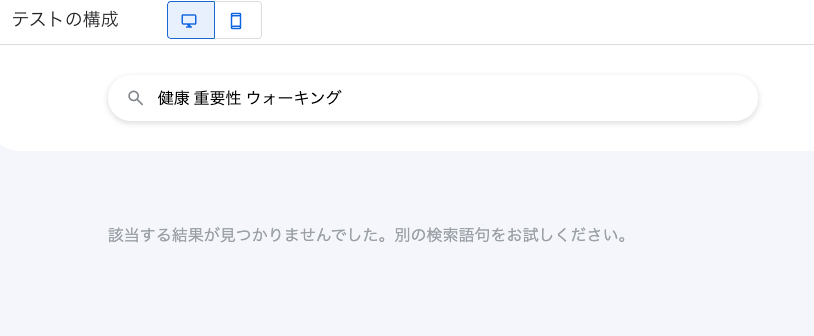
どうやらObjectRef列を持っているテーブルでも、
オブジェクトの中身までは検索ができていないようです。
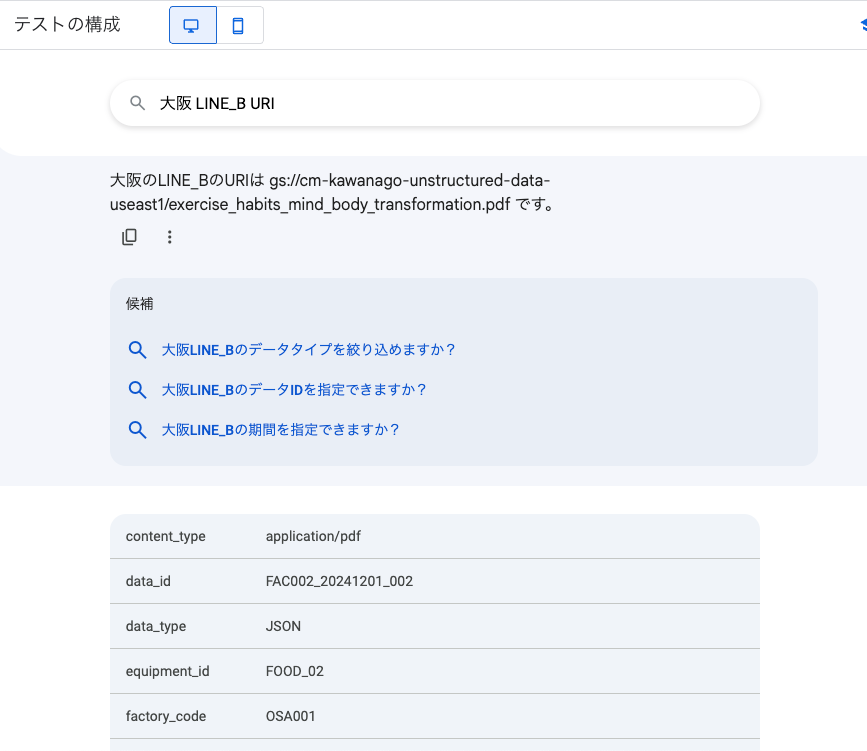
代わりに同一レコードに登録されているメタデータで検索をかけてみます。
メタデータで検索して、紐づくオブジェクトのURIを検索することはできました。
また関連度の高いレコードも、出力結果の下の方に並んで表示されています。
さいごに
扱いたい非構造データが.pdfや.txtなどのテキストベースである場合、
Vertex AI Searchで簡単にRAGシステムを構築できることが分かりました。
ただ構造データと統合したテーブルをソースにした場合、
本検証においてはデータの中身まで見ることはできませんでした。
ObjectRef型を含むテーブルでRAGシステムを構築する場合には、
以下の記事のようにひと手間加える必要がありそうです。
次回、今回作成したテーブルとBigQuery MLを利用して、
より拡張的な非構造オブジェクトの検索にチャレンジしてみようと思います。
少しでも参考になれば幸いです。
最後まで記事を閲覧頂きありがとうございました。








