
Google Cloud Storage で大量のオブジェクト削除を工夫してやってみる
こんにちは、すらぼです。
人は生きていると GCS オブジェクトを大量に、同期的に削除しないといけない時があると思います。
非同期であればライフサイクルを使うことでファイル数を問わず大量に削除できます。
数十万個以上のオブジェクトを一括削除する場合は、処理に非常に時間がかかるため、gcloud storage の使用を避けてください。代わりに、次のいずれかの方法を検討してください。
* オブジェクトのライフサイクル管理機能を使用すると、任意の数のオブジェクトを削除できます。この機能を使用してバケット内のオブジェクトを一括削除するには、条件の Age が 0 に設定され、アクションが delete に設定されているライフサイクル構成ルールを設定します。ルールを設定すると、Cloud Storage は非同期で一括削除を実行します。
https://docs.cloud.google.com/storage/docs/deleting-objects?hl=ja#delete-objects-in-bulk
しかし、ライフサイクルで削除する方法は最大で24時間かかるという仕様があります。即時削除が必要な場合、この方法は使えません。
そこで今回は、以下の3つの方法でオブジェクトを大量に削除する方法を比較してみました。
- 並列処理で、1件ずつ削除を行なう
- Batch API でリクエストを送る
- Batch + 並列でやってみる
そもそも大量のファイルを同期削除するときに気にすること
本題に入る前に、大量のファイルを同期削除する場合には以下の2点で注意が必要です。
- 公式推奨の方法ではない
前述の通り、大量のオブジェクトを削除するケースで Google Cloud が推奨する方法はライフサイクルルールを活用することです。
今回の検証では10万件のオブジェクトでの検証をしていますが、この規模であれば削除までのタイムラグを許容できるのであればライフサイクルルールを利用すべきです。
- APIのレート制限
GCSでは、1つのバケットに対して、書き込み系(削除含む)は1秒あたり1,000リクエストに抑えることが理想的です。
GCSの書き込みレート制限は無制限にスケールするものの、秒間 1,000 リクエストの上限から徐々にスケールしていく仕組みとなっています。
そのため、最初の1秒目から秒間1,000リクエストを超える場合、429 エラーが返る可能性が出てきます。徐々にリクエストを増やす仕組みを整えるか、そもそも 秒間 1,000 リクエストを超えないことが理想です。
- バージョニング
バージョニングが有効になっているバケットでは、削除しても非現行バージョンとして残ります。
完全に消す場合はバージョン指定の削除などが必要となり、非常に手間が増えるため、運用自体を見直すべきでしょう。
以上を踏まえて、比較を進めていきます。
比較の条件
今回は以下の条件で比較をしていきます。
- 10万件のダミーファイルを削除する
- ダミーファイルは、
dummy_files/ディレクトリ直下に全て存在する - スクリプトの実行環境は Cloud Shell
ダミーファイル作成には以下のスクリプトを使用しました。
ダミーファイル作成スクリプト
from google.cloud import storage
from concurrent.futures import ThreadPoolExecutor
import time
# === 設定項目 ===
BUCKET_NAME = 'YOUR_BUCKET_NAME' # 自分のバケット名に変更
PREFIX = 'dummy_files/' # GCS上のディレクトリ名
NUM_FILES = 100000 # 作成する件数
MAX_WORKERS = 200 # 並列処理の数
# ===============
def create_dummy_file(client, bucket_name, object_name):
"""GCSに直接小さなテキストデータを作成する関数"""
bucket = client.bucket(bucket_name)
blob = bucket.blob(object_name)
# 中身は適当な文字列
blob.upload_from_string("This is a dummy file.")
def main():
# 認証情報は gcloud auth application-default loginに依存
client = storage.Client()
print(f"{BUCKET_NAME} に {NUM_FILES}件のファイル作成を開始します...")
start_time = time.time()
# マルチスレッドで高速に作成処理を投げる
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
for i in range(NUM_FILES):
object_name = f"{PREFIX}dummy_{i}.txt"
executor.submit(create_dummy_file, client, BUCKET_NAME, object_name)
elapsed_time = time.time() - start_time
print(f"作成完了! 所要時間: {elapsed_time:.2f} 秒")
if __name__ == "__main__":
main()
ちなみに、Cloud Shell で実行すると大体6分程度かかりました。
$ python gcs-put-objects.py
XXXX に 100000件のファイル作成を開始します...
作成完了! 所要時間: 359.42 秒
注意: 並列処理とCloud Shell 自体のマシンスペック
今回の実行環境は Cloud Shell となります。
並列で処理を実行する場合、APIのリクエストレートに達する前に Cloud Shell 側の並列処理側に限界が来るケースが多いです。
例えば、上記のファイル作成スクリプトで並列数を2倍の400に増やしても、完了までにかかる時間は同じでした。つまり、並列数を200など書いてあっても実際に400の並列処理は実現できていません。
これらの前提を踏まえ、あくまで同一環境での速度の検証という趣旨で本記事はお読みください。
並列処理で、1件ずつ削除を行なう
では本題です。
今回は最もシンプルな方法です。1つずつファイルを削除していきます。
ファイルの作成時と同じ方法で、ファイルの削除処理を並列で行います。gcloud storage rm と同じ方法です。
from google.cloud import storage
from concurrent.futures import ThreadPoolExecutor
import time
# === 設定項目 ===
BUCKET_NAME = 'YOUR_BUCKET_NAME' # 自分のバケット名に変更
PREFIX = 'dummy_files/' # 削除対象のディレクトリ名
MAX_WORKERS = 200 # 並列処理の数(APIの同時リクエスト数)
# ===============
def delete_blob(blob):
"""GCSのオブジェクトを1件個別に削除する関数"""
blob.delete()
def main():
# 認証情報は環境変数(GOOGLE_APPLICATION_CREDENTIALS)などに依存
client = storage.Client()
bucket = client.bucket(BUCKET_NAME)
print(f"[{BUCKET_NAME}] 内の [{PREFIX}] 配下を検索中...")
# 削除対象のオブジェクトリストを取得
blobs = list(bucket.list_blobs(prefix=PREFIX))
total_files = len(blobs)
if total_files == 0:
print("削除対象のファイルが見つかりませんでした。")
return
print(f"合計 {total_files} 件のファイル削除を開始します (並列数: {MAX_WORKERS})...")
start_time = time.time()
# マルチスレッドで大量の DELETE リクエストを並列送信する
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
# map関数を使って、取得したblobリストを次々とdelete_blob関数に渡す
executor.map(delete_blob, blobs)
elapsed_time = time.time() - start_time
print(f"削除完了! 所要時間: {elapsed_time:.2f} 秒")
if __name__ == "__main__":
main()
$ python gcs-murtithred-delete.py
[XXXX] 内の [dummy_files/] 配下を検索中...
合計 100000 件のファイル削除を開始します (並列数: 200)...
削除完了! 所要時間: 380.22 秒
並列処理を行いましたが、put と同程度の時間がかかりました。そこそこ時間がかかります。
バッチリクエストを行う
次に、バッチリクエストを行ってみます。
バッチリクエストは、1リクエストあたりに操作するオブジェクトは100件までにするようにドキュメントに記載があります。
1 つのバッチ リクエストには、100 を超える呼び出しを含めないでください。これよりも多くの呼び出しを行う必要がある場合は、複数のバッチ リクエストを使用します。
そのため、100件ごとにチャンクして処理を行ってみます。
from google.cloud import storage
import time
# === 設定項目 ===
BUCKET_NAME = 'YOUR_BUCKET_NAME' # 自分のバケット名に変更
PREFIX = 'dummy_files/' # 削除対象のディレクトリ名
# ===============
def batch_delete():
client = storage.Client()
bucket = client.bucket(BUCKET_NAME)
print("削除対象のファイル一覧を取得中...")
# prefixに一致するファイルのリストを取得
blobs = list(bucket.list_blobs(prefix=PREFIX))
total_blobs = len(blobs)
if total_blobs == 0:
print("削除対象のファイルが見つかりませんでした。")
return
print(f"合計 {total_blobs} 件のファイルをバッチAPIで削除します...")
start_time = time.time()
# 100件ずつに分割(チャンク化)して処理する
chunk_size = 100
for i in range(0, total_blobs, chunk_size):
chunk = blobs[i : i + chunk_size]
with client.batch():
for blob in chunk:
blob.delete()
# 現在の経過時間を計算して出力に追加
elapsed_so_far = time.time() - start_time
print(f" [{i + len(chunk)} / {total_blobs}] 件削除完了... (経過時間: {elapsed_so_far:.2f} 秒)")
total_elapsed_time = time.time() - start_time
print(f"削除完了! 総所要時間: {total_elapsed_time:.2f} 秒")
if __name__ == "__main__":
batch_delete()
$ python gcs-batch-delete.py
削除対象のファイル一覧を取得中...
合計 100000 件のファイルをバッチAPIで削除します...
[100 / 100000] 件削除完了... (経過時間: 3.11 秒)
[200 / 100000] 件削除完了... (経過時間: 6.18 秒)
[300 / 100000] 件削除完了... (経過時間: 9.23 秒)
[400 / 100000] 件削除完了... (経過時間: 12.33 秒)
[500 / 100000] 件削除完了... (経過時間: 15.29 秒)
......
あまりにも時間がかかるので途中で停止しました。1回のリクエストで3秒かかるので、3,000秒くらいかかります。
やはり一度に処理できるのが100件という点と、直列で処理する必要がある点がボトルネックになっているように感じます。
バッチリクエストを並列させてみる
じゃあバッチリクエストも並列させてしまえば早くなるんじゃないか?ということで、試してみます。
from google.cloud import storage
from concurrent.futures import ThreadPoolExecutor
import time
# === 設定項目 ===
BUCKET_NAME = 'YOUR_BUCKET_NAME'
PREFIX = 'dummy_files/'
MAX_WORKERS = 50 # 50スレッドで並列化
CHUNK_SIZE = 100 # Batch APIの上限
# ===============
def delete_batch_chunk(chunk):
"""1000件の塊を受け取り、1つのバッチリクエストで削除する関数"""
client = storage.Client()
bucket = client.bucket(BUCKET_NAME)
with client.batch():
for blob in chunk:
# blobオブジェクトが別クライアント由来だとエラーになる場合があるため
# バッチ内で新しく参照し直すのが安全です
bucket.blob(blob.name).delete()
print(f" {len(chunk)}件のバッチ削除スレッドが完了しました")
def main():
client = storage.Client()
bucket = client.bucket(BUCKET_NAME)
print("ファイル一覧を取得中...")
blobs = list(bucket.list_blobs(prefix=PREFIX))
total_blobs = len(blobs)
if total_blobs == 0:
return
# 1000件ずつのリストのリスト(チャンク)を作成
chunks = [blobs[i:i + CHUNK_SIZE] for i in range(0, total_blobs, CHUNK_SIZE)]
print(f"合計 {total_blobs} 件のファイルを、{len(chunks)}個のバッチに分けてマルチスレッド削除します...")
start_time = time.time()
# マルチスレッドでバッチリクエストを一気に送信
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
executor.map(delete_batch_chunk, chunks)
elapsed_time = time.time() - start_time
print(f"削除完了! 所要時間: {elapsed_time:.2f} 秒")
if __name__ == "__main__":
main()
$ python gcs-batch-murtithred-delete.py
ファイル一覧を取得中...
合計 100000 件のファイルを、1000個のバッチに分けてマルチスレッド削除します...
100件のバッチ削除スレッドが完了しました
.....
.....
削除完了! 所要時間: 85.74 秒
かなり早くなりました。
ただ、実際に割り算してみると 100,000 / 85.74 = 約1,166 と、秒間 1,000 リクエストを超えてます。
メトリクスでも同様の数値が確認できました。
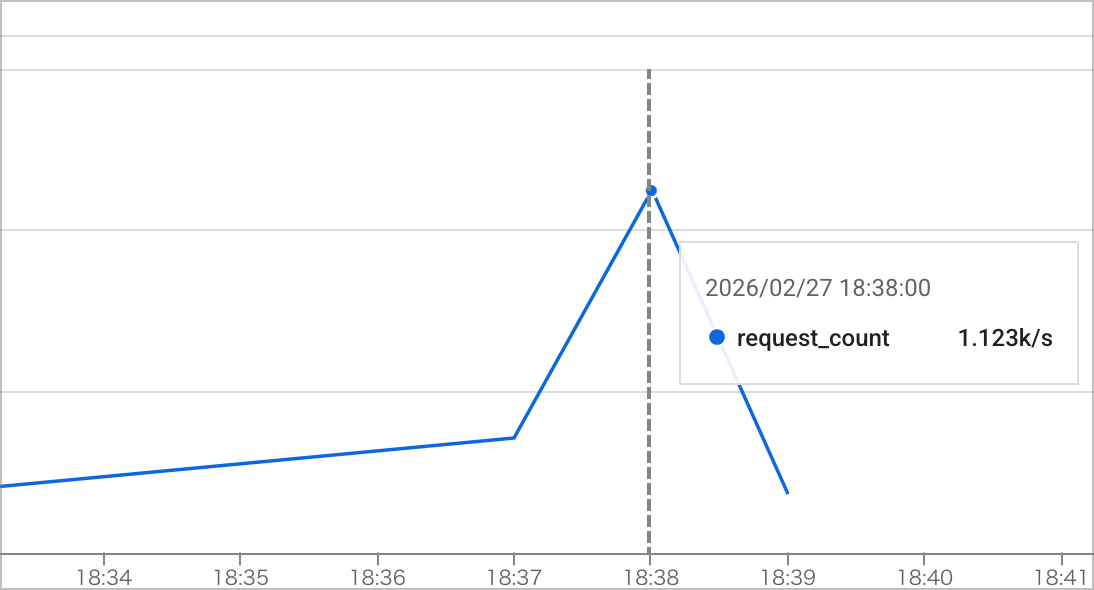
というのも、バッチリクエストは1つに集約しているものの、送った後に100件分の削除リクエストが実行される仕様になっています。
そのため、1回のバッチリクエストで100件分のリクエストが送られることになり、これを並列させることで上記のように大量のリクエストが送られることになります。
今回は並列数を50としたり、Cloud Shell によるスペック的な並列処理上限も存在したためこの程度で済みましたが、これ以上の秒間リクエスト数を求める場合はレート上限を気にする必要が出てきます。
その場合、429エラーのハンドリングなどを考慮する必要が出てきます。
ただ逆に考えると、スペックの制限がある中でも最大限の効率を出せる同期処理の1つと言えそうです。Cloud Run functions など、軽量なコンピューティング環境でも効率的に処理できるため、同期削除をしたい場合は基本的にはこの方法が良さそうです。
結果の比較
3つの方法の結果を表にまとめます。
| 方法 | 所要時間 | 秒間リクエスト数(概算) | 備考 |
|---|---|---|---|
| 並列処理(1件ずつ) | 380.22 秒 | 約 263 req/s | Cloud Shell のスペックがボトルネック |
| バッチ(直列) | 推定 約 3,000 秒 | 約 33 req/s | 途中で停止。1バッチ3秒 × 1,000回 |
| バッチ + 並列 | 85.74 秒 | 約 1,166 req/s | 最速だが秒間1,000リクエストを超過 |
バッチ + 並列が圧倒的に速く、並列処理(1件ずつ)の約4.4倍、バッチ(直列)の約35倍の速度が出ています。
ただし、バッチ + 並列では秒間リクエスト数がレート制限の目安である 1,000 を超えている点には注意が必要です。今回は Cloud Shell のスペック上限が事実上のリミッターとして機能していましたが、より高性能な環境で実行する場合は 429 エラーへの対策を入れる必要があります。
一方、同期的な削除が不要であれば、ライフサイクルによる削除が最も手軽です。API のレート制限を気にする必要がなく、コストもかかりません。最大24時間かかるという制約が許容できるかどうかが判断のポイントになります。
終わりに
GCSで大量のオブジェクトを削除していきました。並列処理によって、かなり処理スピードを上げることができました。1万件程度であれば、通常の処理よりも バッチ + 並列処理によって問題なく効率的に削除できるのではないかと思います。ただし、マシンスペックが高い場合は一瞬でレートリミットを超過する可能性もあるので、並列処理を行う場合は必ずエラーの確認も行うようにする必要がありそうです。
大量のオブジェクトを消したい方の助けになれば幸いです。以上、すらぼでした。
補足: Cloud Shell 側の検証時のスペック
今回の検証は、全て Cloud Shell 上で実施しました。
本題に直接は関係ありませんが、Cloud Shellのスペックについてもコマンドで確認したので記録しておきます。
$ echo "=== CPU情報 ==="
lscpu | grep -E "^CPU\(s\):|^Model name:|^Thread\(s\) per core:|^Core\(s\) per socket:"
echo -e "\n=== メモリ情報 ==="
free -h | grep -E "^Mem:|^Swap:"
echo -e "\n=== OS情報 ==="
grep PRETTY_NAME /etc/os-release
=== CPU情報 ===
CPU(s): 2
Model name: Intel(R) Xeon(R) CPU @ 2.20GHz
Thread(s) per core: 2
Core(s) per socket: 1
=== メモリ情報 ===
Mem: 7.8Gi 2.2Gi 4.3Gi 1.1Mi 1.5Gi 5.6Gi
Swap: 0B 0B 0B
=== OS情報 ===
PRETTY_NAME="Ubuntu 24.04.4 LTS"







