
【CDK】Step FunctionsのDistributedMapでS3バケット名を動的に指定する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
AWS Step Functions(以下、Step Functions)のDistributedMapという機能を使うことで、Amazon S3(以下、S3)のオブジェクトを入力として大規模な並列処理を実行できます。
この記事では、S3バケットにファイルを作成した際のイベント通知によりStep Functionsを起動し、DistributedMapの中でそのS3バケット及びファイルパスを動的に指定する方法について説明します。
うまくいかなかったこと
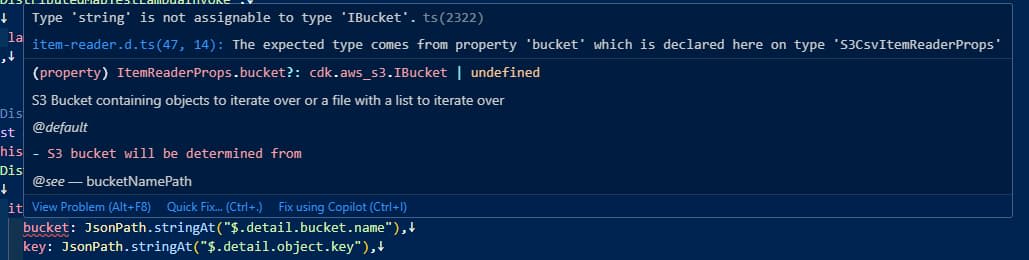
以下のようにbucketプロパティを指定したところ、IBucketインタフェースである必要があるというエラーが発生しました。
// DistributedMapの定義
const distributedMap = new DistributedMap(
this,
"DistributedMapTest",
{
itemReader: new S3CsvItemReader({
bucket: JsonPath.stringAt("$.detail.bucket.name"), // NG
key: JsonPath.stringAt("$.detail.object.key"),
csvHeaders: {
headerLocation: CsvHeaderLocation.FIRST_ROW,
},
}),
itemBatcher: new ItemBatcher({
maxItemsPerBatch: 1000,
}),
},
).itemProcessor(lambdaInvokeState);
対処法
JSONパスで動的にS3バケットを指定する場合は、bucketプロパティではなくbucketNamePathプロパティを使用します。
// DistributedMapの定義
const distributedMap = new DistributedMap(
this,
"DistributedMapTest",
{
itemReader: new S3CsvItemReader({
bucketNamePath: JsonPath.stringAt("$.detail.bucket.name"), // OK
key: JsonPath.stringAt("$.detail.object.key"),
csvHeaders: {
headerLocation: CsvHeaderLocation.FIRST_ROW,
},
}),
itemBatcher: new ItemBatcher({
maxItemsPerBatch: 1000,
}),
},
).itemProcessor(lambdaInvokeState);
new Bucketで作成したS3バケットを直接指定する場合は、bucketプロパティが使えます。
CDKコード全体
今回作成したコードの全体は以下の通りです。
import * as cdk from 'aws-cdk-lib';
import { aws_lambda, aws_lambda_nodejs } from 'aws-cdk-lib';
import { Match, Rule } from 'aws-cdk-lib/aws-events';
import { SfnStateMachine } from 'aws-cdk-lib/aws-events-targets';
import { Bucket } from 'aws-cdk-lib/aws-s3';
import { CsvHeaderLocation, DefinitionBody, DistributedMap, ItemBatcher, JsonPath, S3CsvItemReader, StateMachine } from 'aws-cdk-lib/aws-stepfunctions';
import { LambdaInvoke } from 'aws-cdk-lib/aws-stepfunctions-tasks';
import { Construct } from 'constructs';
import * as path from 'path';
export class CdkStepFunctionsDistributedMapStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// S3バケットの作成
const bucket = new Bucket(this, "StepFunctionsDistributedMapTest", {
bucketName: `step-functions-distributed-map-test`,
eventBridgeEnabled: true,
});
// Lambda関数の定義
const lambda = new aws_lambda_nodejs.NodejsFunction(
this,
"DistributedMapTestLambda",
{
functionName: "DistributedMapTestLambda",
entry: path.join(__dirname, "../lambda/distributed-map-test.ts"),
runtime: aws_lambda.Runtime.NODEJS_22_X,
},
);
const lambdaInvokeState = new LambdaInvoke(
this,
"DistributedMapTestLambdaInvoke",
{
lambdaFunction: lambda,
},
);
// DistributedMapの定義
const distributedMap = new DistributedMap(
this,
"DistributedMapTest",
{
itemReader: new S3CsvItemReader({
bucketNamePath: JsonPath.stringAt("$.detail.bucket.name"),
key: JsonPath.stringAt("$.detail.object.key"),
csvHeaders: {
headerLocation: CsvHeaderLocation.FIRST_ROW,
},
}),
itemBatcher: new ItemBatcher({
maxItemsPerBatch: 1000,
}),
},
).itemProcessor(lambdaInvokeState);
// ステートマシンの作成
const stateMachine = new StateMachine(
this,
"DistributedMapTestStateMachine",
{
stateMachineName: `DistributedMapTestStateMachine`,
definitionBody: DefinitionBody.fromChainable(distributedMap),
},
);
// ステートマシンからS3バケットを読み取り可能にする
bucket.grantReadWrite(stateMachine);
// EventBridgeルールの作成
new Rule(this, "DistributedMapTestRule", {
eventPattern: {
source: ["aws.s3"],
detailType: Match.equalsIgnoreCase("object created"),
resources: [bucket.bucketArn],
},
targets: [new SfnStateMachine(stateMachine)],
});
}
}
S3バケットの作成
// S3バケットの作成
const bucket = new Bucket(this, "StepFunctionsDistributedMapTest", {
bucketName: `step-functions-distributed-map-test`,
eventBridgeEnabled: true,
});
今回はS3バケットにファイルを作成した際にAmazon EventBridgeに対してイベント通知をする必要があるため、eventBridgeEnabledをtrueに設定します。
Lambda関数の定義
// Lambda関数の定義
const lambda = new aws_lambda_nodejs.NodejsFunction(
this,
"DistributedMapTestLambda",
{
functionName: "DistributedMapTestLambda",
entry: path.join(__dirname, "../lambda/distributed-map-test.ts"),
runtime: aws_lambda.Runtime.NODEJS_22_X,
},
);
const lambdaInvokeState = new LambdaInvoke(
this,
"DistributedMapTestLambdaInvoke",
{
lambdaFunction: lambda,
},
);
このLambda関数は、DistributedMapによって分割されたデータを処理するためのものです。
まずNodejsFunctionを作成して、そのLambda関数を起動するためのタスクを作成しています。
今回は、渡されたオブジェクトを単に出力するだけのLambda関数となっています。実際には、この中でDB登録やデータの加工といった必要な処理を行います。
import { Handler } from "aws-cdk-lib/aws-lambda";
export const handler: Handler = async (
event: any,
) => {
console.log("event: ", event);
};
DistributedMapの定義
// DistributedMapの定義
const distributedMap = new DistributedMap(
this,
"DistributedMapTest",
{
itemReader: new S3CsvItemReader({
bucketNamePath: JsonPath.stringAt("$.detail.bucket.name"),
key: JsonPath.stringAt("$.detail.object.key"),
csvHeaders: {
headerLocation: CsvHeaderLocation.FIRST_ROW,
},
}),
itemBatcher: new ItemBatcher({
maxItemsPerBatch: 1000,
}),
},
).itemProcessor(lambdaInvokeState);
今回はitemReaderとして、S3バケットにあるCSVファイルのデータを分散処理するS3CsvItemReaderを指定しました。他にもS3JsonItemReader、S3ManifestItemReader、そしてS3ObjectsItemReaderが存在します。
class S3CsvItemReader · AWS CDK
EventBridgeからは以下のような形式でイベントが渡されます。そのため、$.detail.bucket.nameのようにJSONパスを指定します。
{
"version": "0",
"id": "xxxxxxxxxxxx",
"detail-type": "Object Created",
"source": "aws.s3",
"account": "xxxxxxxxxxxx",
"time": "2025-03-27T10:36:37Z",
"region": "ap-northeast-1",
"resources": [
"arn:aws:s3:::xxxxxxxxxxxx"
],
"detail": {
"version": "0",
"bucket": {
"name": "xxxxxxxxxxxx"
},
"object": {
"key": "generated_data_100_20250327_193528.csv",
"size": 3134,
"etag": "f8f7d614efa39f919fd8a98a8a1fc09d",
"sequencer": "0067E4E3E5713A77CB"
},
"request-id": "xxxxxxxxxxxx",
"requester": "xxxxxxxxxxxx",
"source-ip-address": "xxxxxxxxxxxx",
"reason": "PutObject"
}
}
データをバッチ処理するにはitemBatcherを指定します。これを指定しないと1行ずつ分散処理されます。
itemProcessorとして先ほど作成したLambda関数を起動するタスクを指定します。itemProcessorを指定しない場合、デプロイ時に以下のエラーが発生します。
TypeError: Cannot read properties of undefined (reading 'ProcessorConfig')
ステートマシンの作成
// ステートマシンの作成
const stateMachine = new StateMachine(
this,
"DistributedMapTestStateMachine",
{
stateMachineName: `DistributedMapTestStateMachine`,
definitionBody: DefinitionBody.fromChainable(distributedMap),
},
);
// ステートマシンからS3バケットを読み取り可能にする
bucket.grantReadWrite(stateMachine);
DistributedMapステートからS3バケットにあるファイルを読み取る必要があるので、ステートマシンに対して権限を付与します。
EventBridgeルールの作成
// EventBridgeルールの作成
new Rule(this, "DistributedMapTestRule", {
eventPattern: {
source: ["aws.s3"],
detailType: Match.equalsIgnoreCase("object created"),
resources: [bucket.bucketArn],
},
targets: [new SfnStateMachine(stateMachine)],
});
先ほど作成したS3バケットに対して「Object Created」イベントが発生した場合にStep Functionsを起動するように設定します。
動作確認
このプロジェクトをデプロイし、作成したS3バケットにCSVファイルをアップロードします。
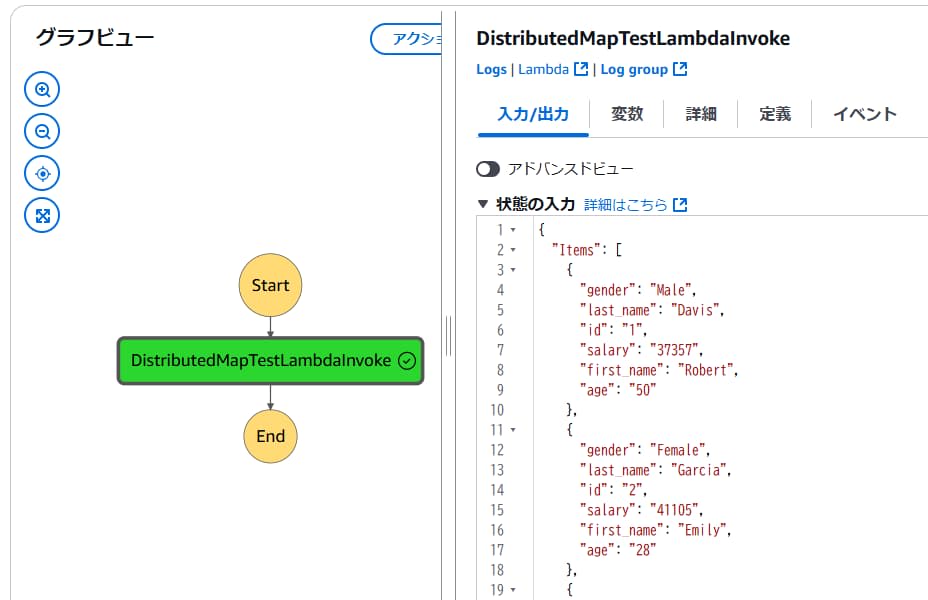
Step Functionsが自動的に起動するので、終了するまで待ちます。終了後、Step Functionsのグラフビューは以下のようになります。
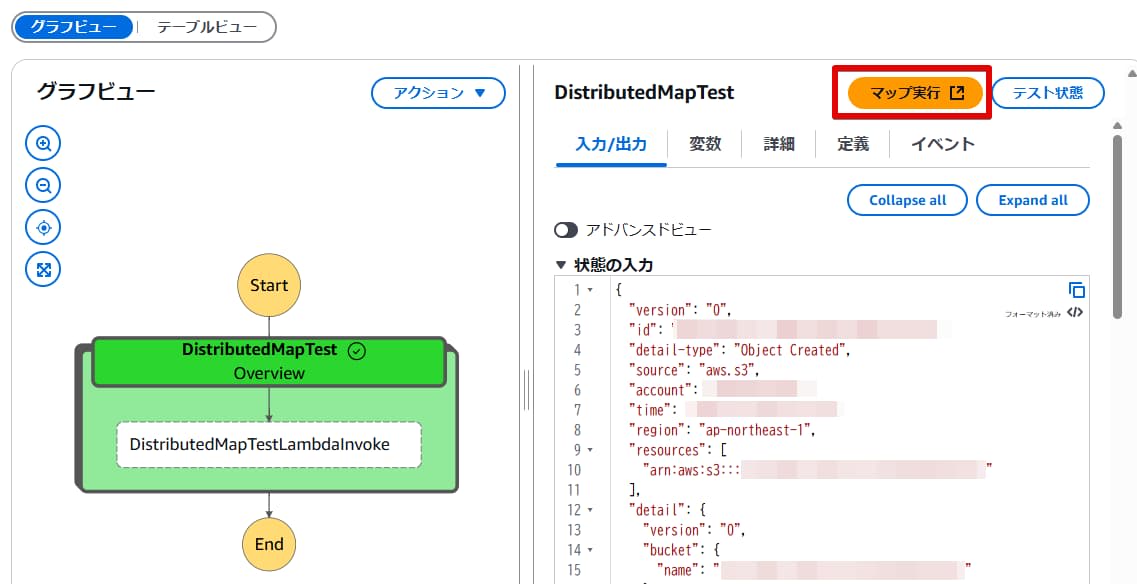
DistributedMapの処理に関する詳細な情報は、「マップ実行」から参照できます。
データの処理ステータスを確認できます。データ量が多く処理に時間がかかる場合、この画面でリアルタイムの処理状況を知ることができます。
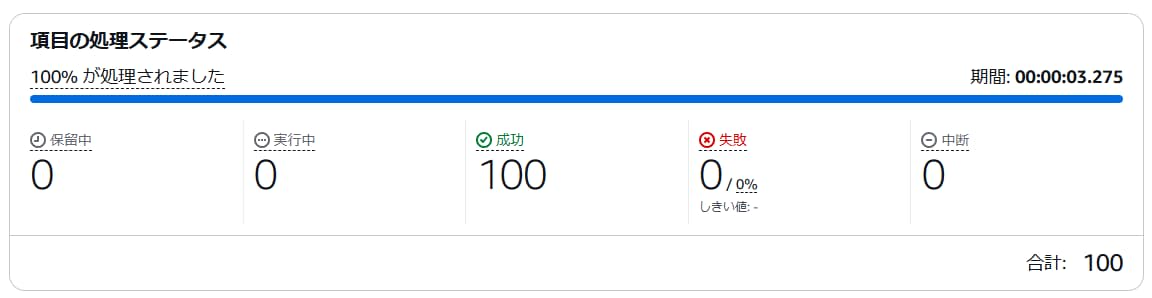
また、画面の最下部に、各Mapごとの実行結果が表示されています。今回はデータが100件なので1回の実行で全データが処理されていますが、データ量が多く分散処理が行われた場合は複数行表示されます。

名前のリンクをクリックすると、各Mapごとのグラフビューや入力値といった詳細情報を確認できます。
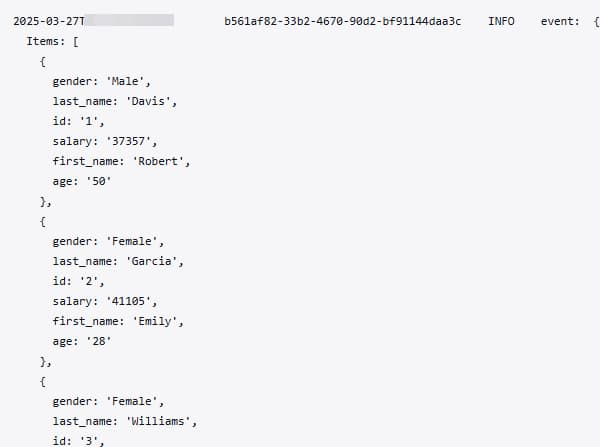
CloudWatchでは、Lambda関数のロググループにStep Functionsから渡された値が出力されています。
おわりに
S3バケットにあるCSVファイルやJSONファイル、またオブジェクト一覧を直接取得できるDistributedMapは便利だと感じました。
この記事がどなたかの参考になれば幸いです。










