
【セッションレポート】 Evolution of Game Balancing with Reinforcement Learning in the VLM-LLM Agentic Era/VLM/LLM時代における強化学習によるゲームバランス調整の進歩 ― #CEDEC2025
登壇者: エドガー ハンディ (Independent)
日時: 2025 年 7 月 22 日 (火) 16:40 ~ 17:40
会場: CEDEC2025 第 10 会場
カテゴリ: ENG (エンジニアリング) | レギュラーセッション | 海外招待
概要
本セッションでは、強化学習 (Reinforcement Learning: RL) を活用したゲームバランス調整の手法とその課題、さらに近年急速に進化している大規模言語モデル (Large Language Model: LLM) や視覚言語モデル (Visual Language Model: VLM) を組み合わせた新しいアプローチについて解説されました。
ゲームバランスの調整は、プレイヤー体験を左右する重要な工程である一方で、属人的で繰り返しが多く、開発におけるコストの大きな要因にもなります。ハンディ氏は、この作業に強化学習を取り入れることで自動化の可能性が広がること、さらに LLM や VLM を組み合わせることで、出力の解釈や報酬関数の設計をより直感的に行えるようになることを提案しました。
本報告書では、まずゲームバランス調整における強化学習の活用意義と限界について整理したうえで、エージェントベースの支援手法、実装上の工夫、そして質疑応答から得られた実践的な知見を順に紹介していきます。
ゲームバランス調整における強化学習の意義と限界を整理する
ゲームバランス調整の重要性
ゲームバランスの調整は、完成度の高いゲーム体験を提供するうえで欠かせない工程です。単なる不具合の修正にとどまらず、プレイヤーの挑戦意欲を適切に維持し、理不尽さや退屈さを排除するためには、数値パラメータや挙動の微調整を繰り返す必要があります。こうした調整作業はプレイテストや開発者の経験に基づいて手動で行われることが多く、その属人性と非効率性が長年にわたって課題となってきました。
特に近年のゲーム開発では、複数のキャラクターやスキル、戦術的要素を含む複雑な設計が求められることが多く、バランス調整にかかる負荷は一層大きくなっています。開発後期におけるイテレーション(繰り返しの検証と修正)をどれだけ効率的に回せるかは、プロジェクト全体の品質とコストを左右する重要な要素です。

強化学習がもたらす自動化の可能性
このような状況に対し、強化学習 (Reinforcement Learning: RL) は、ゲーム内でプレイヤーのように行動するエージェントを構築し、反復的なプレイを通じてパラメータの調整や設計の妥当性を検証する手法として注目されています。RL エージェントを活用することで、事前に設定した報酬関数に基づいて目的に沿った行動を自律的に学習させることができ、人手によるプレイテストを一部代替できます。
また、人間のバイアスを排除した定量的な検証や、特定の戦略や操作に偏らない多様な挙動の検出も可能になることから、バランス調整の初期段階における探索作業を効率化できます。とくに PvP ゲームなどにおいて、あるキャラクターが一方的に有利な状況や、引き分けが多発する設計ミスを早期に発見できる点は大きな利点です。
実装上の課題と限界
一方で、RL の導入には複数の技術的・運用的な課題も存在します。まず、報酬関数の設計には明確な目的と十分なドメイン知識が必要であり、誤った定義を与えた場合には学習結果が実際のゲーム意図から逸脱するおそれがあります。さらに、エージェントが生成する行動ログや統計データは高次元かつ複雑であり、出力結果を分析して有意義な知見に落とし込むには相応の時間とスキルが求められます。
また、ルールが複雑なジャンル(例: RPG やカードゲーム)では、単純な行動選択モデルでは対応しきれず、あらかじめ設計されたルールベース AI との併用が必要になる場合もあります。このように、RL は万能ではなく、対象となるゲームジャンルや開発フェーズに応じて適用範囲を見極めることが重要です。
LLM/VLMエージェントによる支援手法とその実装可能性を検討する
強化学習の課題を補完する目的で LLM/VLM を導入する
強化学習適用の問題に対処する手段として、近年の大規模言語モデル (LLM) や視覚言語モデル (VLM) を補助的に導入するアプローチが紹介されました。
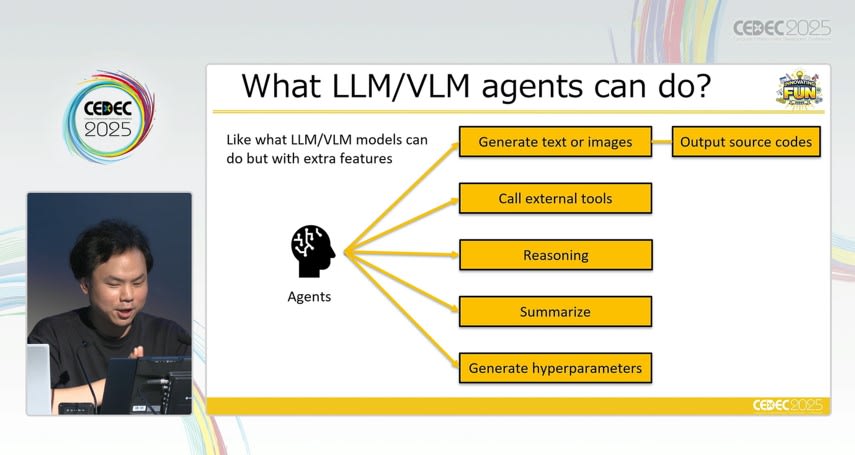
LLM/VLM を用いた開発支援の具体的な役割
LLM は、テキスト入力をもとに高度な推論や指示の解釈ができる汎用的な言語モデルであり、ゲーム設計者が自然言語で記述した目標や制約条件を、強化学習に適した報酬関数へと変換することができます。たとえば、「接戦になるように調整したい」 「一部のキャラクターが使われにくい状況を解消したい」といった抽象的な意図をモデルに伝えることで、目的に沿った数式やパラメータ設定を生成させることが可能になります。
また、VLM は画像や動画などの視覚情報をテキストと統合的に処理できるモデルであり、プレイ画面やエージェントの行動ログを直接解析することで、設計上の問題点を説明文として提示したり、望ましいプレイ状況の例示から逆算して報酬設計を行ったりすることも可能です。
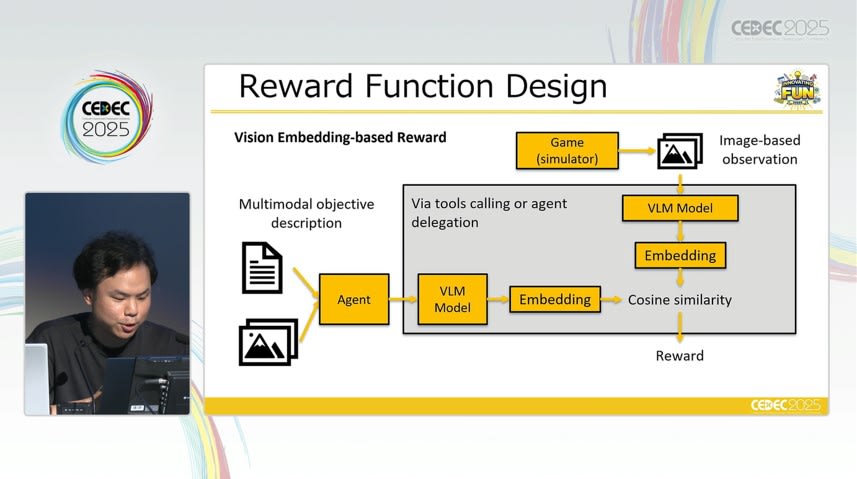
エージェントには、バランス崩壊の検出や改善提案、さらには調整理由の生成まで担うことが期待されています。講演者は、LLM がゲーム開発における「オーケストレーター」として機能する可能性に言及しました。
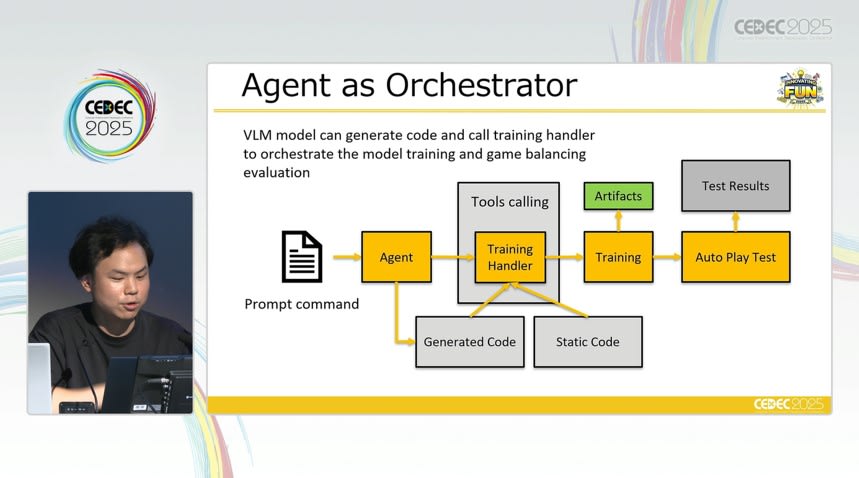
このような支援によって、従来はエンジニアによる手作業や設計者の経験則に頼っていたバランス調整工程が、よりアジャイルかつ直感的に行えるようになることが期待されます。
運用上の限界とトレードオフ
一方で、LLM/VLM を用いた開発支援には制約もあります。質疑応答の中では、以下のような懸念点が共有されました。
- 複雑な RPG などにおいて、強化学習だけでテストプレイの自動化は困難であり、最終的にはハードコードが必要となる場合がある
- データ量を増やせばパラメータチューニングの重要性が下がるわけではなく、入力データの質とハイパーパラメータの調整は依然として重要である
また、LLM の推論時間についてはモデルに依存するものであり、将来的な短縮やキャッシュの活用といった最適化が必要であるとの見解が述べられました。
まとめ
本セッションでは、ゲームバランス調整における強化学習の有効性と、その実装上の課題に対する解決策として、LLM や VLM を活用するアプローチが提示されました。強化学習は一定の自動化効果を持ちますが、報酬関数の設計や出力の解釈には専門性が求められます。これに対し、LLM/VLM エージェントは自然言語や視覚情報を通じた直感的な操作を可能にし、調整作業の効率化と透明性向上に寄与します。
一方で、推論時間や出力の信頼性、ジャンルごとの適用限界といった課題も存在し、現時点での導入には適切な設計判断が求められます。それでもなお、本セッションは、AI が単なる補助ツールではなく、開発者と協働する存在としてゲーム開発に関与していく未来の可能性を示すものとなっていました。








