
【セッションレポート】 ライブサービスゲームQAのパフォーマンス検証による品質改善の取り組み #CEDEC2025
登壇者: 小野 粋哉 (株式会社WFS)、 勅使川原 大輔 (株式会社WFS)
日時: 2025 年 7 月 24 日 (木) 15:00 ~ 15:25
会場: CEDEC2025 第 5 会場
カテゴリ: PRD (プロダクション) | ショートセッション | 公募
概要
本セッション「ライブサービスゲームQAのパフォーマンス検証による品質改善の取り組み」では、株式会社 WFS の QA チームが実践する、パフォーマンス劣化の事前検知とリリース後の迅速な事後対応を両立する検証体制が紹介されました。特に、リッチな演出や継続的なアップデートが求められるライブサービス型ゲームにおいて、デグレードやクラッシュの早期発見、ユーザー報告をもとにした改善サイクルが品質向上の鍵となることが強調されました。
WFS が運営する『ヘブンバーンズレッド』などのタイトルでは、Jenkins と Slack を用いた自動化パイプラインや Airtest スクリプトによる検証動画取得を組み合わせ、定期的な測定・可視化を行うことで、アップデートによるパフォーマンス劣化を未然に防いでいます。さらに、ユーザーの問い合わせや SNS の声をもとに、CS チームと連携して事後検証を行い、クラッシュ率を 90% 削減するなどの成果を挙げています。
パフォーマンス課題の背景と検証体制
近年のライブサービスゲームにおいては、演出やグラフィックのリッチ化にともない、端末への負荷やパフォーマンスの維持がますます難しくなってきています。WFS では、タイトル運営において以下のような課題が顕在化していました。
- 追加アップデート時に、既存コンテンツのパフォーマンスが劣化する「デグレード」
- 長時間プレイや特定状況下で発生する「スムーズでない動作」
- 一部端末における「特定箇所でのクラッシュ」
こうした課題に対し、WFS の QA チームは 2段構えのパフォーマンス検証体制を構築しました。
1 つは「定期的なパフォーマンス計測による事前検知」です。Jenkins を用いて複数の計測項目を定期的に取得し、Slack 通知・スプレッドシートへの集約を通じて可視化します。

さらに Airtest スクリプトを活用して検証シーンごとの動画取得とログ収集も自動化しており、開発段階でのパフォーマンス悪化を未然に検出できるようになっています。

もう 1 つは「CSチームと連携した迅速な事後検知」です。SNS や問い合わせ窓口に寄せられたパフォーマンス関連の報告を CS チームが収集し、QA チームと連携して再現検証を実施します。必要に応じて類似端末を用意し、事象の再現性を担保しながら原因を特定する体制を整備しています。
これらの事前・事後両面からのアプローチにより、パフォーマンス課題の早期発見と迅速な改善対応が可能となっています。
事例1: ヘブンバーンズレッド (事前検知)
事前検知の取り組み事例として紹介されたのが、WFS が運営するスマートフォン向け RPG 『ヘブンバーンズレッド』です。このタイトルでは、定期的なパフォーマンス測定を QA 業務に組み込み、アップデートによる性能劣化の兆候を早期に察知できるような体制が整備されています。
Jenkins を基盤とした自動計測パイプラインでは、指定したシーンにおけるアプリの各種パフォーマンス指標 (ロード時間、消費メモリ、CPU/GPU 使用率など) を継続的に取得し、結果を Slack に通知・スプレッドシートへ集約するしくみが構築されています。さらに Airtest を用いたスクリプトによって操作の自動化と動画記録も行われ、異常の検出と原因分析がしやすい状態が保たれています。これらの測定値は端末・バージョンごとに分けて記録され、バージョンごとの傾向をグラフで可視化することで、どの更新から問題が発生しているのかが明確になります。実際の運用では、特定バージョンからロード時間が急激に増加していることを検出し、リリース前に修正を行うことで品質劣化を未然に防ぐことができたとのことです。
具体的に検出された問題としては以下のようなものが挙げられていました。
- バトル中に徐々にメモリ使用量が増加していく
- 特定キャラクターのスキル演出におけるロード時間の増加
- 巨大ボス演出時に処理が重くなりクラッシュが発生する
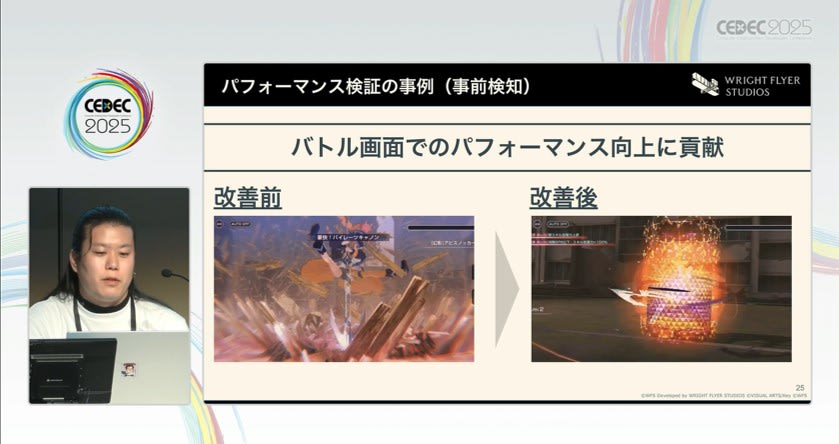
こうした課題が数値と動画によって可視化されることで、開発チームに対しての報告も明確になり、対応優先度の判断が容易になります。セッション内では、実際にバトル演出の一部を軽量化した「改善前/改善後」の比較動画も紹介されており、検証による改善効果が視覚的にも確認できる内容となっていました。
事例2: 運用中タイトル (事後検知)
事後検知の取り組み事例として紹介されたのは、WFS が運用する別タイトルにおいて、リリース後に発覚したバトル中のクラッシュ問題への対応です。このケースでは、ユーザーからの問い合わせや SNS 上の報告をもとに、CS チームと QA チームが連携し、問題の再現と原因特定を進めました。
CS チームがクラッシュの多発を検知したのは、バトル画面に関する内容でした。報告があった内容を集約し、該当するプレイ環境や状況を調査した結果、特定端末での再現性があることが判明しました。これを受けて QA チームでは、以下のような条件下での検証を実施しました。
- テスト端末はクラッシュ報告と同等の機種を用意
- 戦闘は固定パーティ・固定敵・オート進行で連続実施
- メモリ使用量やロード時間などのログを収集し、Airtest による動画記録を併用
こうした検証によって、クラッシュが特定状況下でのみ発生していることを突き止めることができ、エンジニアチームに対して「発生条件の整理」と「優先度の高い改善要請」を迅速に行うことが可能となりました。さらに、再現確認後は類似端末を用いて検証を繰り返し、同様の問題が他環境でも生じていないかを確認するなど、横展開を見据えた再発防止策も実施されました。ログと集計表を通じた可視化によって、クラッシュ回数の推移が明確になり、最終的には該当バトルでのクラッシュ率を大幅に改善することができたとのことです。最終的に クラッシュ件数の 90% 削減 に繋がったことは、セッションの最後でも強調されていました。
まとめと所感
本セッションでは、WFS における QA チームの取り組みとして、事前の定期的なパフォーマンス検証と、リリース後の迅速な事後対応の両立が紹介されました。パフォーマンス問題は一度ユーザーに影響を与えると、信頼の低下や離脱につながるため、いかに早期に発見・修正できるかが重要です。
印象的だったのは、ツールの活用と組織連携が両輪となって機能している点です。Jenkins や Airtest を駆使した自動化パイプラインにより、開発段階での可視化と通知をルーチン化しつつ、リリース後は CS チームとの密な情報共有によって、再現性のある検証体制を実現していました。数値や動画といった「視覚的で共有しやすい形式」での成果物が、開発・QA・CS の間の円滑なコミュニケーションを支えていることも伝わってきました。クラッシュ率の 90% 削減という成果は、検証の仕組みそのものが品質改善のボトルネックを大きく解消した好例といえるでしょう。単なる不具合の再現に留まらず、「どのようにパフォーマンスを維持・向上させていくか」という QA の主体的な視点が随所に表れていたセッションでした。










