
うっかりブログ本文や画像内にAWSアカウントIDが公開されていないかDLP APIでチェックしてみた。※ただし801119661308はOK
リテールアプリ共創部@大阪の岩田です。
以前こんなブログを書いたのですが、私は社内のSlackチャンネルにてDevelopersIOの新着記事をチェックするSlackアプリを作成・運用しています。
最近このアプリを拡張し、記事内の画像に機密情報が含まれていないかGoogle CloudのDLP APIでチェックする機能を追加しました。色々なチェック処理を組み込んだのですが、このブログではDLP APIを使って文字列/画像内にAWSアカウントIDが含まれていないかチェックする方法についてご紹介します。
脱線してちょっと前置き
AIに聞けば何でも回答が得られる時代になりましたが、一方でAIの回答が正確である保証はなく、我々人間はAIの回答に対して裏付けを取るのが重要です。そんな中でDevelopersIOは「やってみた」ブログであり続け、記事には「やってみた」の過程や結果としてコマンドの出力結果や構築したリソースの画面キャプチャが多数存在します。これらはブログ記事の正確性を裏付けるエビデンスとして機能する有益な情報であり、読者はこれらの情報から記事の内容が正しいと判断できます。その一方で「やってみた」結果をそのまま公開すると、誤って機密情報まで公開されてしまうリスクもあります。
リスクを恐れて「やってみた」を避けるのではなく、技術でリスクを軽減する。そんな仕組みが作れないかと考えてDLP APIを利用してみました。
やってみる
それでは実際にDLP APIを叩きながらAWSアカウントIDのチェックを試していきましょう。
DLP APIの動作確認には Google APIs Explorer を使うと自分でUIを操作しながらHTTPリクエストが組み立てられるので便利です。
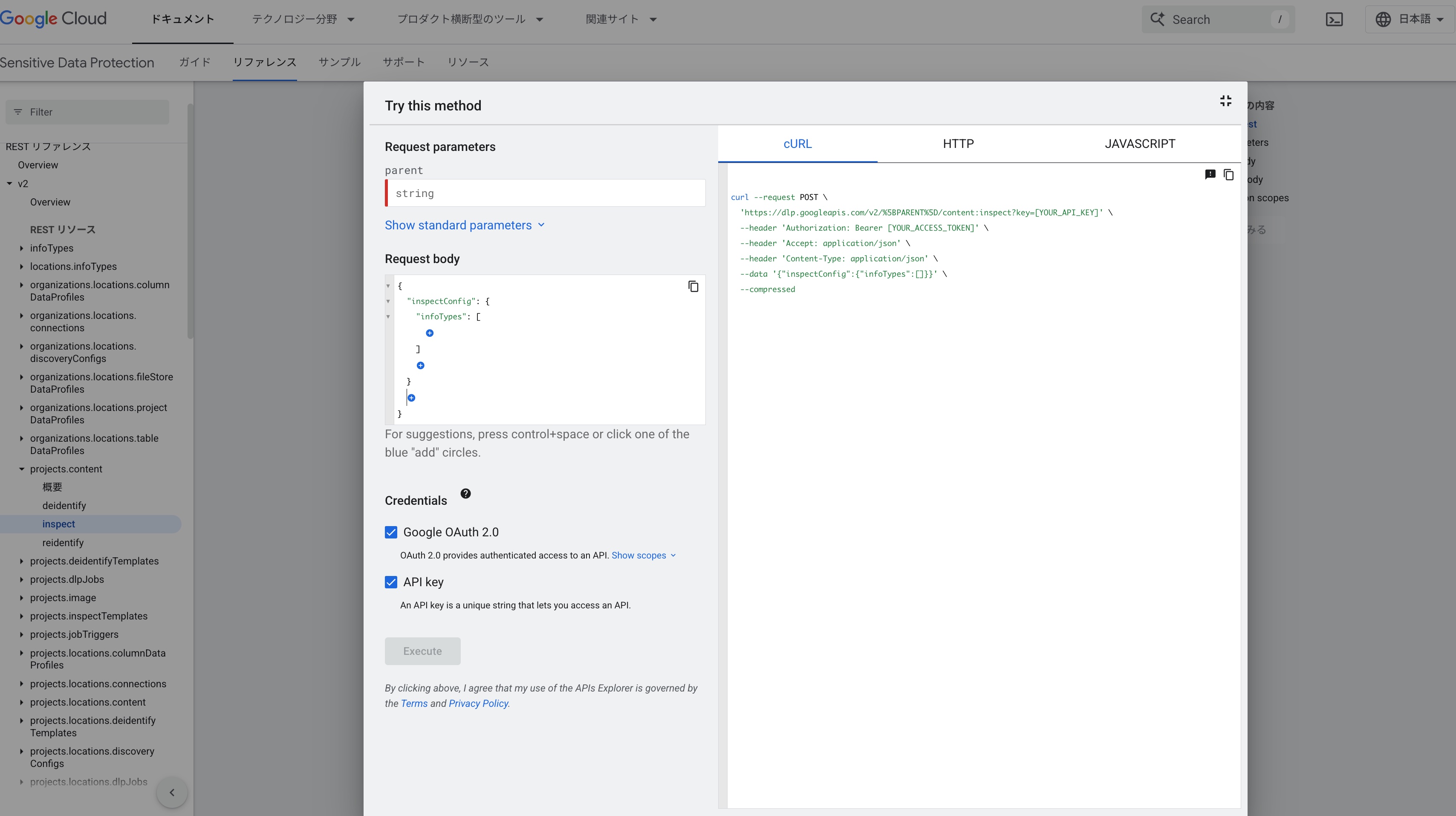
まずは数字12桁の正規表現でチェック
組み込みのinfoType 検出器にはAWSアカウントIDをチェックするような検出器は存在しません。そのためカスタムのinfoType検出器を作成してAWSアカウントIDの検出を試みます。
infoType 検出器リファレンス | Sensitive Data Protection | Google Cloud
まずは何も考えずに\d{12}という正規表現で数字12桁で構成される文字列をチェックしてみましょう。^\d{12}$にしていないのは単体のAWSアカウントID以外にARNも検出したいという意図があります。最終的なリクエストは以下の通りです。
※以後のコマンドはすべて環境変数PROJECT_IDにGoogle CloudのプロジェクトID、ACCESS_TOKENにアクセストークンが設定されている前提です。
curl --location "https://content-dlp.googleapis.com/v2/projects/${PROJECT_ID}/content:inspect?alt=json" \
--header "authorization: Bearer ${ACCESS_TOKEN}" \
--header "content-type: application/json" \
--data '{
"inspectConfig": {
"customInfoTypes": [
{
"infoType": {
"name": "AWS_ACCOUNT_ID"
},
"regex": {
"pattern": "\\d{12}"
}
}
]
},
"item": {
"value": "111111111111"
}
}'
inspectConfigのcustomInfoTypesで正規表現パターンを指定し検査対象としてitemのvalueで111111111111という文字列を指定しています。レスポンスは以下の通りになりました。数字12桁の羅列を正常に検出できています。※ALL 1なので明らかにダミーのAWSアカウントですが、こういうケースの除外は後ほど対応します。
あとはitemのvalueにブログの本文を渡せばAWSアカウントIDのマスク漏れをチェックできそうです。
{
"result": {
"findings": [
{
"infoType": {
"name": "AWS_ACCOUNT_ID",
"sensitivityScore": {
"score": "SENSITIVITY_HIGH"
}
},
"likelihood": "VERY_LIKELY",
"location": {
"byteRange": {
"end": "12"
},
"codepointRange": {
"end": "12"
}
},
"createTime": "2025-10-28T01:12:39.852Z",
"findingId": "2025-10-28T01:12:39.852235Z4682318203859260581"
}
]
}
}
13桁以上の数字の羅列はAWSアカウントIDと判定されないようにする
とりあえず上記の正規表現を使って試験的に運用していたのですが、以下の記事がDLP APIのチェックに引っかかってしまいました。
詳細を見てみると lastLogon : 134045404301063589等の記述が引っかかっていました。確かに134045404301063589は\d{12}という正規表現に一致しますね。。。。ということで13桁以上の数値はAWSアカウントIDと判定しないように正規表現を修正しましょう。AIに相談すると否定先読みと否定後読みを使って(?<!\d)\d{12}(?!\d)という正規表現でチェックすることをオススメされました。正規表現を修正して134045404301063589という文字列をチェックしてみましょう。
curl --location "https://content-dlp.googleapis.com/v2/projects/${PROJECT_ID}/content:inspect?alt=json" \
--header "authorization: Bearer ${ACCESS_TOKEN}" \
--header 'content-type: application/json' \
--data '{
"inspectConfig": {
"customInfoTypes": [
{
"infoType": {
"name": "AWS_ACCOUNT_ID"
},
"regex": {
"pattern": "(?<!\\d)\\d{12}(?!\\d)"
}
}
]
},
"item": {
"value": "134045404301063589"
}
}'
以下のレスポンスが返却されてきました。否定後読みがうまくパースできていないようです。
{
"error": {
"code": 400,
"message": "parsing '(?<!\\d)\\d{12}(?!\\d)': invalid perl operator: (?<!",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.ErrorInfo",
"reason": "3",
"domain": "dlp.googleapis.com"
}
]
}
}
Sensitive Data Protectionのリファレンスによると正規表現パターンはre2構文で記述する必要があるようです。そのため否定先読みと否定後読みが使えません。正規表現を(?:^|[^\d])(\d{12})(?:$|[^\d])に変更し、13桁以上の数値は抽出されないようにし再挑戦します。
curl --location "https://content-dlp.googleapis.com/v2/projects/${PROJECT_ID}/content:inspect?alt=json" \
--header "authorization: Bearer ${ACCESS_TOKEN}" \
--header 'content-type: application/json' \
--data '{
"inspectConfig": {
"customInfoTypes": [
{
"infoType": {
"name": "AWS_ACCOUNT_ID"
},
"regex": {
"pattern": "(?:^|[^\\d])(\\d{12})(?:$|[^\\d])"
}
}
]
},
"item": {
"value": "134045404301063589"
}
}'
今度は無事にレスポンスが取得できました。
{
"result": {}
}
これで期待通り134045404301063589はAWSアカウントIDと判定されないようになりました!
特定のAWSアカウントIDは除外する
正規表現を修正してから数日経過後、Slack Botから以下の通知が飛んできました。
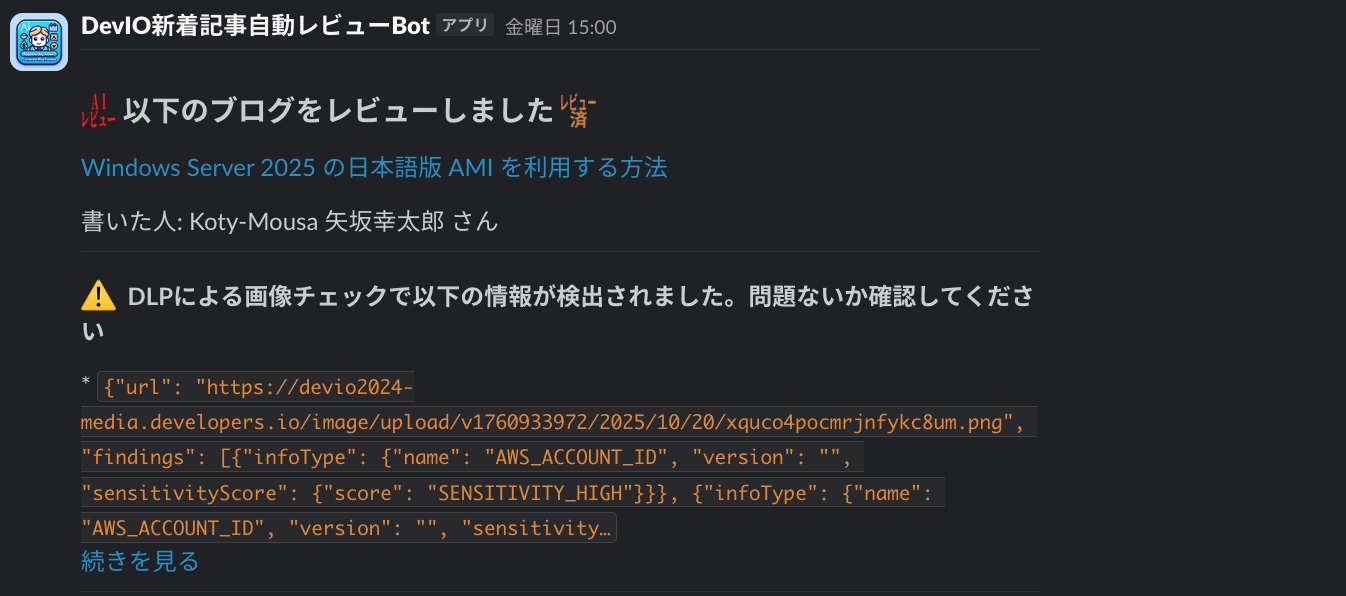
以下ブログの画像からAWSアカウントIDが検出されたようです。
しかし、詳細を見てみると...
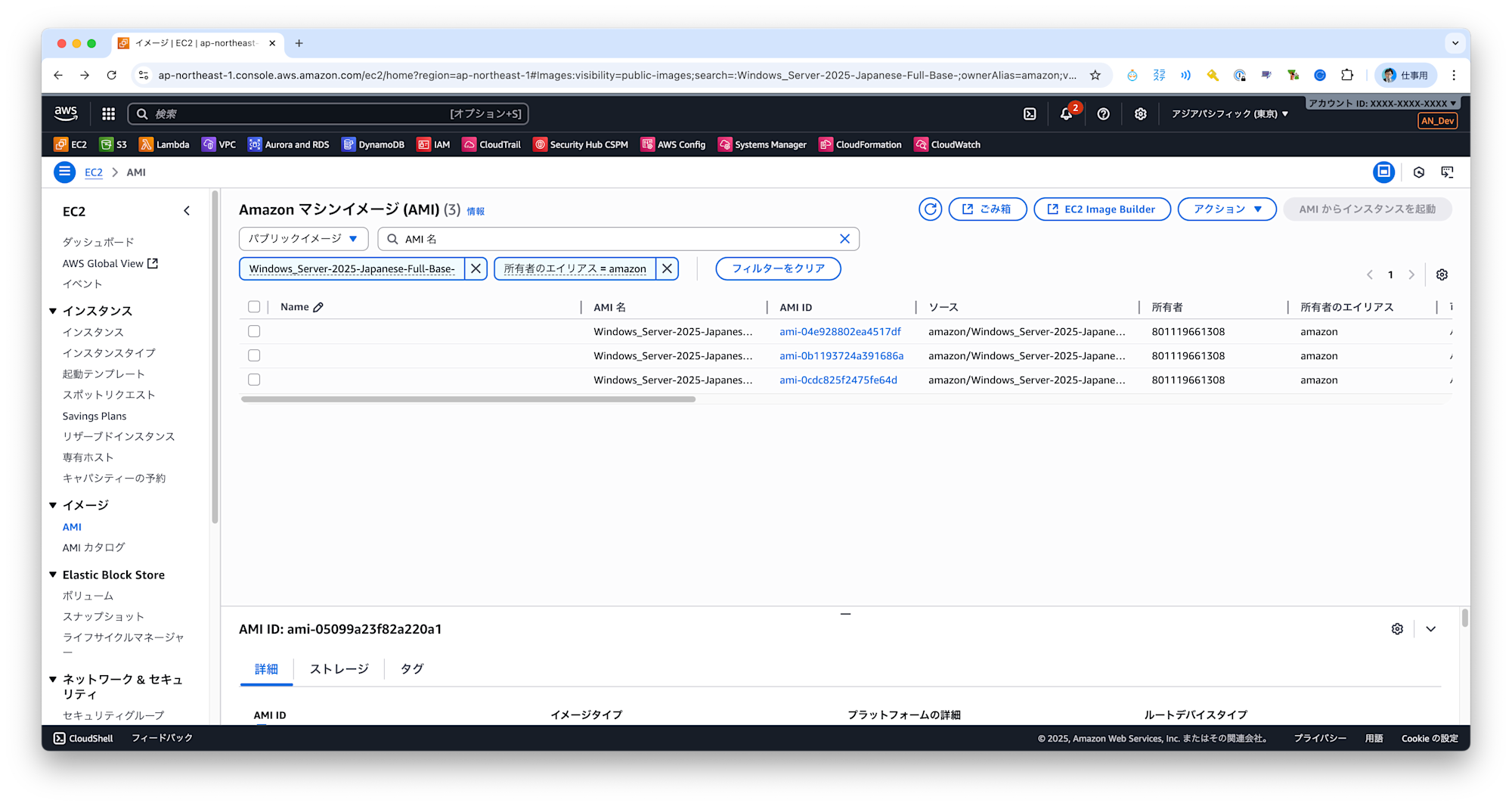
右上のアカウントIDはバッチリ匿名化されています。どうも検出されたのはAMI一覧に表示されている801119661308のようです。このAWSアカウントIDはAWSのアカウントIDであり、以下のドキュメント等でも公開されているものです。そのため機密情報のチェックとしては検出対象外にしたい文字列です。
AWSWindows AMI 通知をサブスクライブする - AWS Windows AMIs
ということで、除外ルールを使ってこのアカウントIDが検出されないようにしてみます。除外ルールはruleSetのrules配下にexclusionRuleを列挙することで指定できます。今回はexclusionRuleに正規表現を指定するregex、と辞書を指定するdictionaryを併用して特定のAWSアカウントIDを除外してみます。
まず123456789012や012345678912のようなダミーを除外するために{"regex": {"pattern": "123456"}}という正規表現を追加します。続いて111111111111等のダミーAWSアカウントIDや先程の801119661308のような秘匿不要なAWSアカウントIDを除外するために{"dictionary": {"wordList": {"words":["000000000000","111111111111"...]}}}を追加します。
最終的なリクエストは以下の通りです。
curl --location "https://content-dlp.googleapis.com/v2/projects/${PROJECT_ID}/content:inspect?alt=json" \
--header "authorization: Bearer ${ACCESS_TOKEN}" \
--header 'content-type: application/json' \
--data ' {
"inspectConfig": {
"customInfoTypes": [
{
"infoType": {
"name": "AWS_ACCOUNT_ID"
},
"regex": {
"pattern": "(?:^|[^\\d])(\\d{12})(?:$|[^\\d])"
}
}
],
"ruleSet": [
{
"rules": [
{
"exclusionRule": {
"regex": {
"pattern": "123456"
},
"matchingType": "MATCHING_TYPE_PARTIAL_MATCH"
}
},
{
"exclusionRule": {
"matchingType": "MATCHING_TYPE_PARTIAL_MATCH",
"dictionary": {
"wordList": {
"words": [
"000000000000",
"111111111111",
"222222222222",
"333333333333",
"444444444444",
"555555555555",
"666666666666",
"777777777777",
"801119661308",
"888888888888",
"999999999999"
]
}
}
}
}
],
"infoTypes": [
{
"name": "AWS_ACCOUNT_ID"
}
]
}
]
},
"item": {
"value": "801119661308"
}
}'
レスポンスです。
{
"result": {}
}
リクエストには801119661308を指定していましたが、機密情報は検出されませんでした。
今度は先程の画像も検査してみましょう。画像を検査したい場合は以下のように画像ファイルをbase64エンコードした文字列をリクエストで渡します。
{
"item": {
"byteItem": {
"data": "<画像ファイルをbase64エンコードした文字列>",
"type": "IMAGE"
}
}
}
リクエスト全体は以下の通りです。
curl --location "https://content-dlp.googleapis.com/v2/projects/${PROJECT_ID}/content:inspect?alt=json" \
--header "authorization: Bearer ${ACCESS_TOKEN}" \
--header 'content-type: application/json' \
--data ' {
"inspectConfig": {
"customInfoTypes": [
{
"infoType": {
"name": "AWS_ACCOUNT_ID"
},
"regex": {
"pattern": "(?:^|[^\\d])(\\d{12})(?:$|[^\\d])"
}
}
],
"ruleSet": [
{
"rules": [
{
"exclusionRule": {
"regex": {
"pattern": "123456"
},
"matchingType": "MATCHING_TYPE_PARTIAL_MATCH"
}
},
{
"exclusionRule": {
"matchingType": "MATCHING_TYPE_PARTIAL_MATCH",
"dictionary": {
"wordList": {
"words": [
"000000000000",
"111111111111",
"222222222222",
"333333333333",
"444444444444",
"555555555555",
"666666666666",
"777777777777",
"801119661308",
"888888888888",
"999999999999"
]
}
}
}
}
],
"infoTypes": [
{
"name": "AWS_ACCOUNT_ID"
}
]
}
]
},
"item": {
"byteItem": {
"data": "...",
"type": "IMAGE"
}
}
}'
レスポンスです。
{
"result": {}
}
無事に機密情報は検出されませんでした!
今回は説明を割愛しますが、同様に以下のようなケースについても特定パターンを除外するように設定できると良いでしょう。
-
infoTypeが
EMAIL_ADDRESSかつ、ドメインにexample.comを利用している場合 -
infoTypeが
IP_ADDRESSかつ、ループバックアドレスやプライベートIPを利用している場合- 正規表現でプライベートIPをチェックするのは大変そうなので、ある程度はFalsePositiveを許容しつつ手抜きしたいところですが..
まとめ
DLP APIは機密情報の誤公開の抑止力として活用できるサービスです。一方で以下に記載されている通りこれ単体で法令遵守を保証するような仕組みではないので、あくまで補助ツールとして活用するのが良いでしょう。
重要: 組み込みの infoType 検出器は、完全に正確な検出方法ではありません。たとえば、これらの検出器によって法令要件の遵守を保証することはできません。どのデータが機密であるか、それを保護する最善の方法は何かを決めるのは、お客様の責任です。構成が要件を確実に満たしているかどうか、設定内容を検証することをおすすめします。
infoType と infoType 検出器 | Sensitive Data Protection | Google Cloud
参考
- Sensitive Data Protection の概要 | Google Cloud
- infoType 検出器リファレンス | Sensitive Data Protection | Google Cloud
- カスタムの infoType 検出器 | Sensitive Data Protection | Google Cloud
- スキャン結果を絞り込むための infoType 検出器の変更 | Sensitive Data Protection | Google Cloud
- Regex | Sensitive Data Protection | Google Cloud Documentation
- Method: projects.content.inspect | Sensitive Data Protection | Google Cloud Documentation









