
Skillに context: fork を1行足すだけで、Claude Codeのコンテキストが綺麗になった
はじめに
こんにちは、AI事業本部・生成AIインテグレーション部・西日本開発チームの政岡です。
Claude CodeのSkill定義frontmatterにcontext: forkというオプションがあるのをご存じでしょうか?
公式ドキュメント「スキルをサブエージェントで実行する」には次のように書かれています。
スキルを分離して実行したい場合は、フロントマターに
context: forkを追加します。スキルコンテンツはサブエージェントを駆動するプロンプトになります。会話履歴にアクセスできません。
つまり、context: forkはSkillをメイン会話から分離して実行するための設定です。
ただ、最初に読んだときは混乱しました。
「別コンテキストで動くなら、それはSubagentと何が違うの?」と思ったからです。(恥ずかしながら、そもそもSkillとSubagentの違いを深く理解できていませんでした。。。)
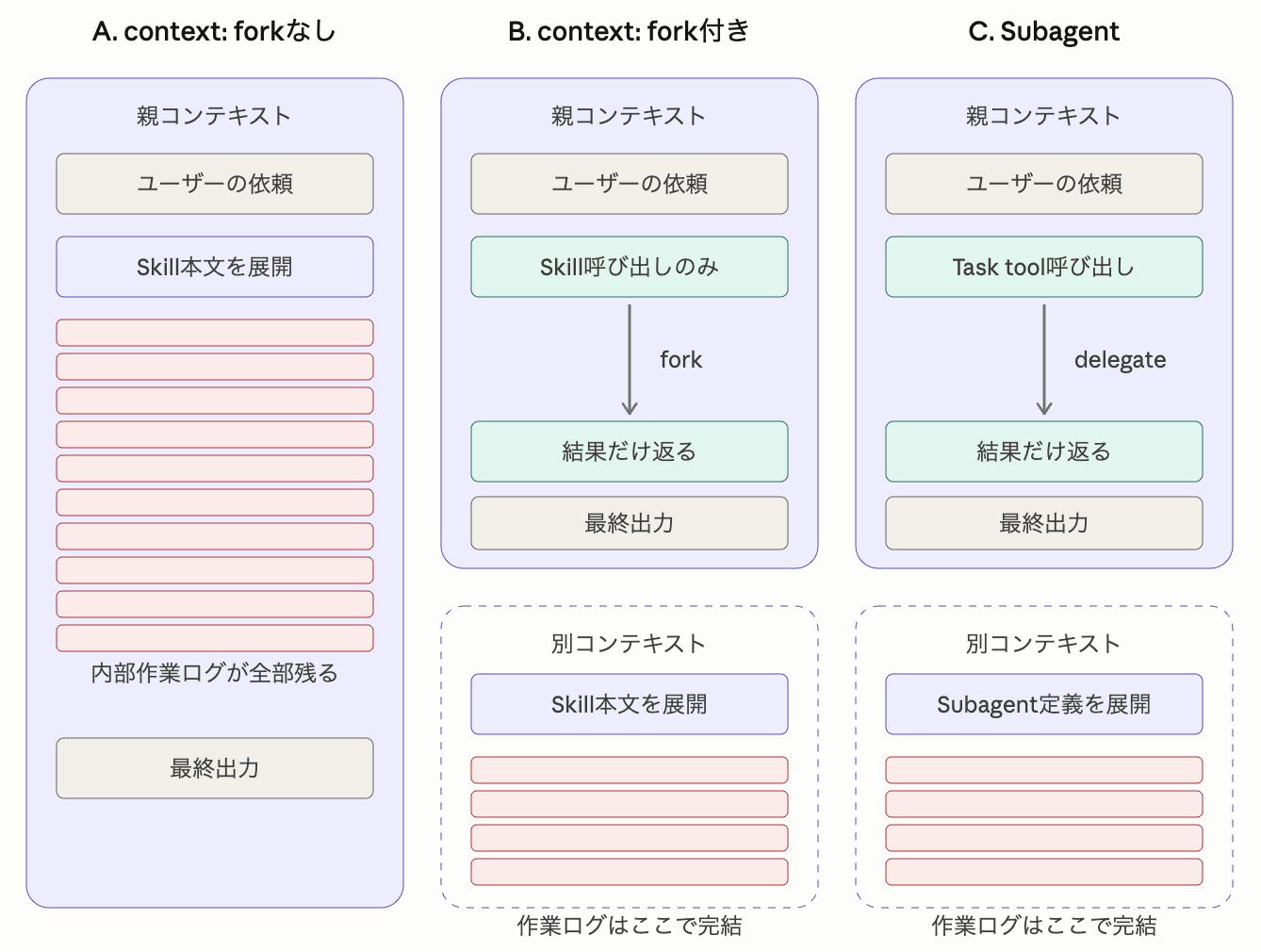
そこで今回は、同じタスクを次の3方式で実行して、メインの会話に何が残るのかを比べてみました。
context: forkなしSkill実行context: fork付きSkill実行- Subagent呼び出し
そのうえで、context: fork付きSkillとSubagentをどう使い分けるとよさそうかを整理します。
TL;DR
SKILL.mdにcontext: forkを付けると、Skill内部の作業ログが親のメイン会話に残らなくなった- 今回の検証では、親のメイン会話全体は10,633字から806字に減り、内部作業ログだけを見ると8,959字から0字になった
context: fork付きSkillとSubagentはどちらも別コンテキストで実行できるが、再利用する単位が違う- 同じ手順を毎回回したいなら
context: fork付きSkill、同じ担当者に任せたいならSubagentが向いている
context: forkは何を解決するのか
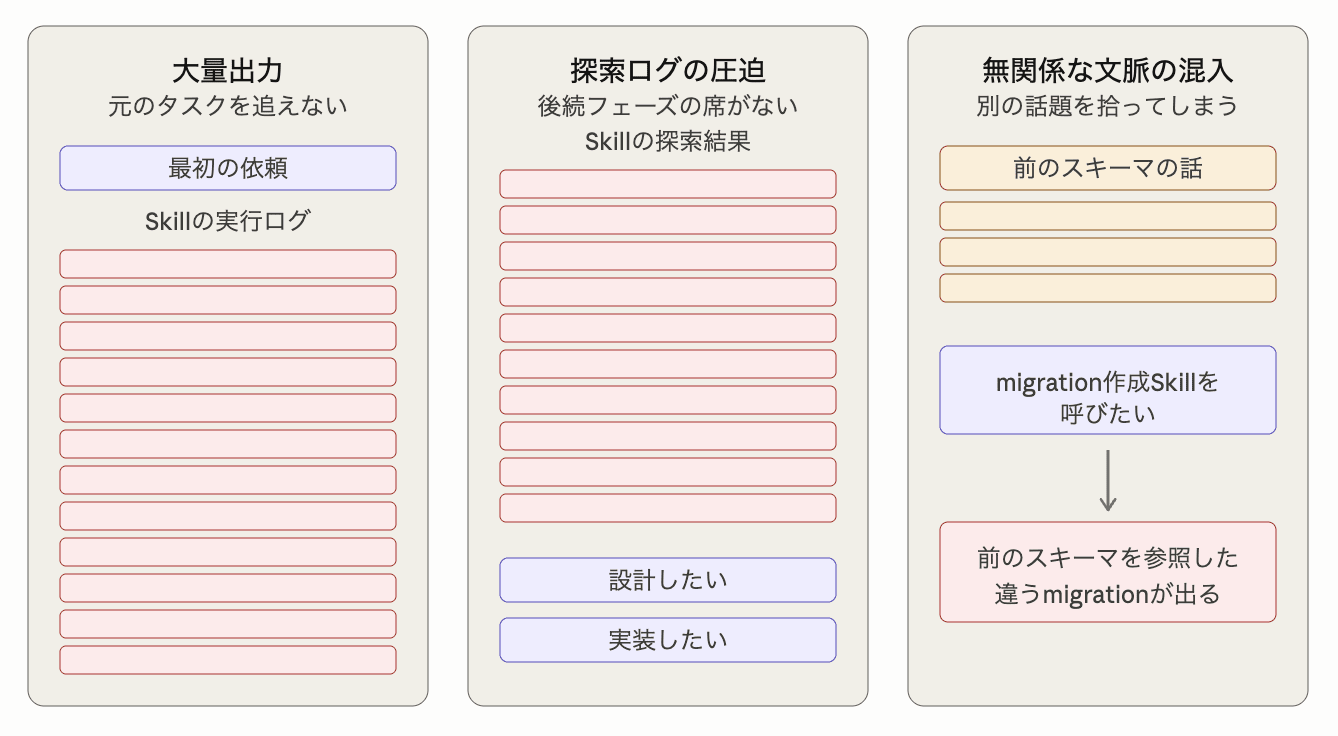
context: forkが効くのは主に次のような場面です。
| 場面 | 何に困っているか |
|---|---|
| 大量出力で元のタスクを追いにくくなる | Skillsによるコード解析などの詳しい出力が会話履歴に残り、Claudeが最初の依頼を追いにくくなる |
| 探索ログが後続フェーズを圧迫する | Skillsによる大量の探索結果が残り、後続の設計や実装に使うメインの会話が埋まってしまう |
| 同じセッションの無関係な文脈が混ざる | migration作成時などに、その前のやりとりで出た別のスキーマ情報を拾ってしまう |
本記事では特に大量の出力で元のタスクを追いにくくなるケースを参考に、context: forkでメインの会話がどれだけすっきりするのかを実測します。
検証のセットアップ
検証する3方式
| 方式 | 定義 | 起動コマンド |
|---|---|---|
A. context: forkなしSkill実行 |
.claude/skills/repo-stats-inline/SKILL.md(frontmatterにcontext: forkなし) |
repo-stats-inline Skillを使って ./sample-repo を分析して |
B. context: fork付きSkill実行 |
.claude/skills/repo-stats-fork/SKILL.md(frontmatterにcontext: forkあり) |
repo-stats-fork Skillを使って ./sample-repo を分析して |
| C. Subagent呼び出し | .claude/agents/repo-stats.md |
repo-stats Subagentを使って、./sample-repo を分析して |
各定義の中身
今回のタスクは、指定したリポジトリ内のファイルを一通り調べて、拡張子ごとのファイル数、各ソースファイルの行数、大きいファイル、TODO/FIXMEの件数をまとめるものです。
3つの定義の本文(タスク手順)は同じ内容になっています。
---
name: repo-stats-fork
description: Produce a statistics report for a small repository — file counts by extension, total lines of code, the five largest files, and the number of TODO/FIXME comments. Runs in a forked subagent so the many intermediate Glob, Read, and Grep calls do not pollute the parent context window. Use when comparing the forked variant against the inline baseline.
context: fork
---
# repo-stats-fork
You are a repository statistics reporter used to benchmark skill execution.
## Task
When the user invokes this skill with a directory path, do the following:
1. Use `Glob` to enumerate every file under that directory (recursive).
2. Group the files by extension and count them.
3. For each text source file (`.py`, `.ts`, `.js`, `.md`, `.toml`, `.txt`, `.yml`, `.yaml`, `.json`), use `Read` to load it and count its lines.
4. Identify the five largest files (by line count).
5. Use `Grep` to count the occurrences of `TODO` and `FIXME` across the codebase (combined).
6. Output the final report in this exact markdown format and nothing else:
```
## リポジトリ統計レポート
**対象**: <path>
### 拡張子別ファイル数
- `.py`: N
- `.md`: N
- ... (only extensions actually present, sorted by count desc)
### 総行数
- 合計: N 行
### 最大ファイル TOP 5
1. `<path>` — N 行
2. ...
### TODO / FIXME
- 合計: N 件
```
## Constraints
- Do not narrate intermediate steps. Do not announce file reads.
- Output only the final report block.
- If a file cannot be read, silently skip it.
検証対象のサンプルリポジトリ
sample-repo/は架空のTODO管理ツール(FastAPI + React/TypeScript)を模した小規模プロジェクトです。
構成はおおよそ次のようになっています。
sample-repo/
├── src/ # FastAPI 側のアプリケーションコード
│ ├── api.py
│ ├── db.py
│ ├── models.py
│ └── ...
├── frontend/ # React / TypeScript 側のコード
│ └── src/
│ ├── api.ts
│ └── ...
├── docs/
│ └── api.md
└── ...
| 指標 | 値 |
|---|---|
| ファイル数 | 36 |
| 総行数 | 1,657行 |
| TODO/FIXME件数 | 14件 |
検証条件
比較しやすいように、3方式ともClaude Codeのバージョン、モデル、入力リポジトリは同じ条件にしました。
| 条件 | 値 |
|---|---|
| Claude Code | v2.1.140 |
| Model | claude-sonnet-4-6 |
| 入力 | ./sample-repo |
| セッション独立性 | 各セッション/exit後の新規起動 |
検証方法
- 各方式を新規セッションで実行
/exportで会話ログをファイル化~/.claude/projects/<hash>/<session-id>.jsonlを取得してjqで集計- fork/Subagentの場合は
<session>/subagents/agent-*.jsonlも取得
検証結果
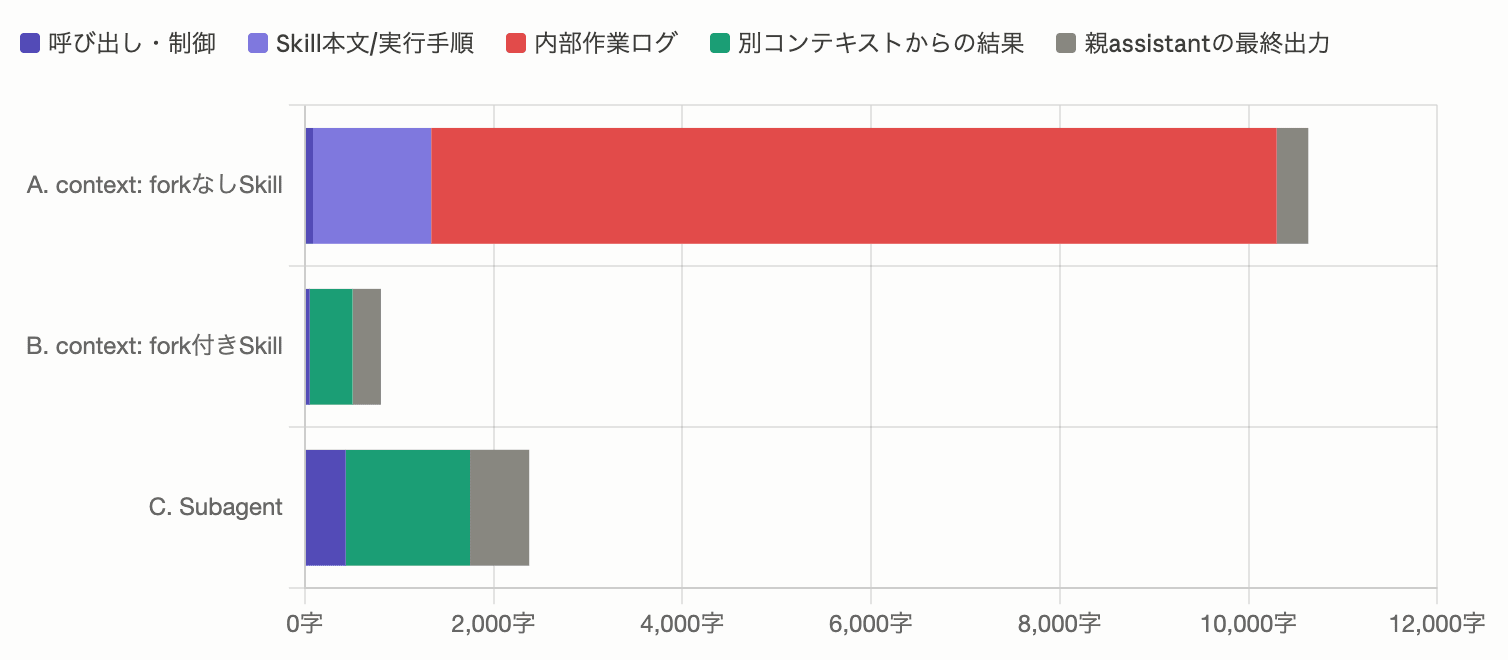
| 親のメイン会話に残ったもの | A context: forkなしSkill実行 |
B context: fork付きSkill実行 |
C Subagent呼び出し |
|---|---|---|---|
| 呼び出し・制御 | 86字 | 50字 | 433字 |
| Skill本文 / 実行手順 | 1,252字 | 0字 | 0字 |
| 内部作業ログ | 8,959字 | 0字 | 0字 |
| 別コンテキストからの結果 | 0字 | 456字 | 1,317字 |
| 親assistantの最終出力 | 336字 | 300字 | 627字 |
| 合計 | 10,633字 | 806字 | 2,377字 |
ここで特に見たいのは、findのファイル一覧や集計コマンドの結果といった内部作業ログです。
context: forkなしSkill実行では、8,959字ぶんの内部作業ログがそのままメイン会話に残りました。一方、context: fork付きSkill実行とSubagent呼び出しでは、内部作業ログはメイン会話には残りませんでした。
つまり、context: forkを付けると、Skillの実行過程は別コンテキスト側に閉じ込められ、メイン会話には結果だけが返ってくる(内部作業ログでメインの会話を汚さずに結果を出力できている)ことがわかります。
どう使い分けるか
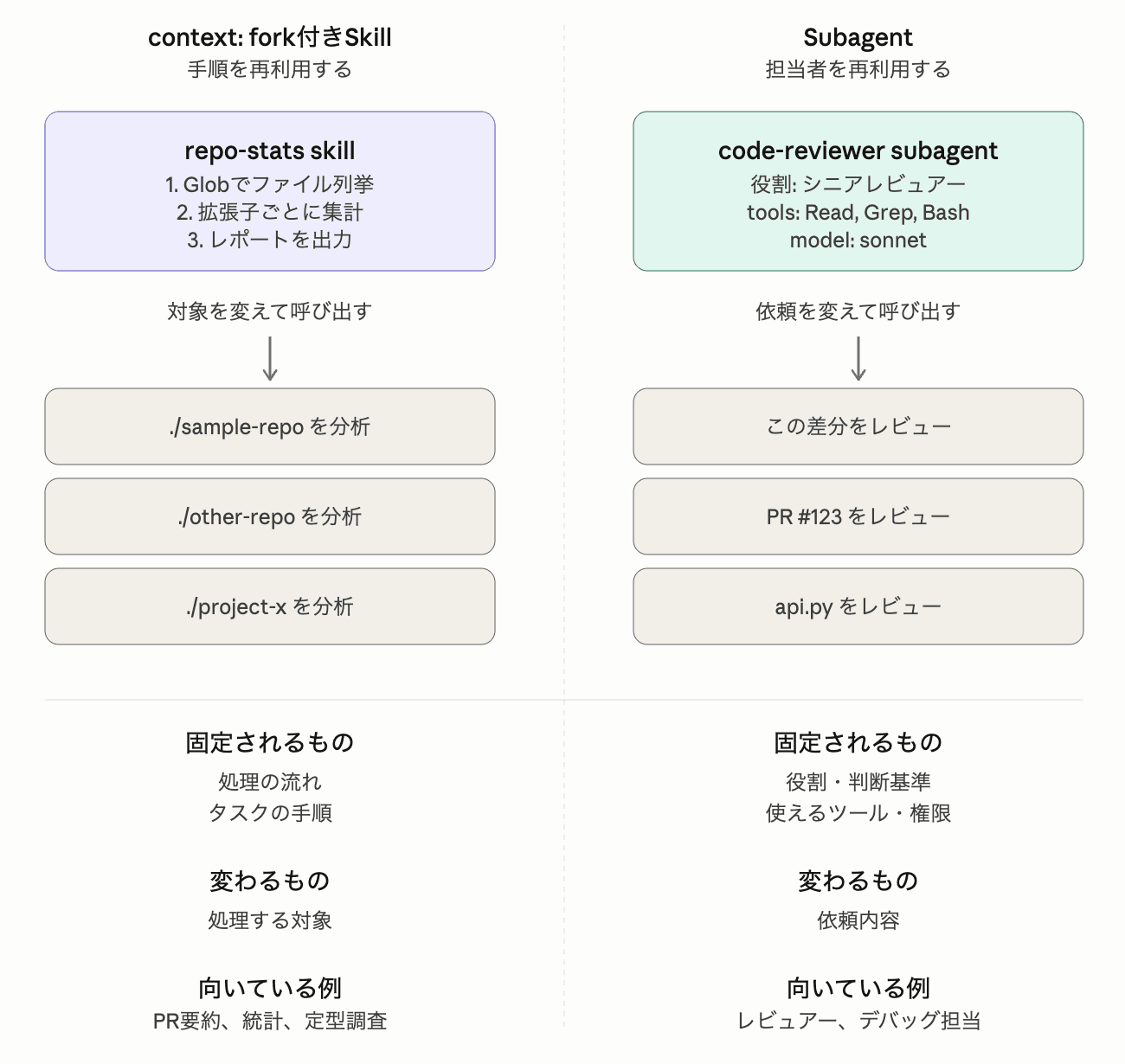
ここまで見ると、context: fork付きSkillとSubagentはかなり似ています。どちらもメイン会話を汚さずに、別コンテキストで作業できます。
では、何を基準に使い分ければよいのでしょうか。個人的には、再利用したいものが手順なのか、担当者なのかで考えると整理しやすいと感じました。
Skillは、基本的にはタスクの手順やワークフローを再利用するための仕組みです。context: forkを付けると、その手順を別コンテキストで実行して、メインの会話には結果だけを戻しやすくなります。たとえば「PRを要約する」「リポジトリ統計を出す」「コードベースを一定の観点で調査する」のように、対象は毎回変わるが処理の流れは同じ作業に向いています。
一方でSubagentは、専用のsystem prompt、tool制限、modelなどを持つ実行単位です。手順も書けますが、中心になるのは役割・判断基準・権限を持った実行主体として再利用することです。たとえば「コードレビュアー」「デバッグ担当」「テスト実行担当」のように、対象や依頼内容は毎回変わるが、役割や判断基準を固定したいケースに向いています。
まとめ
context: forkを付けると、重めのSkillでも内部作業ログを親のメイン会話から切り離せます。今回の検証では、context: forkなしSkill実行で親のメイン会話に残っていた内部作業ログ8,959字が、context: fork付きSkill実行では0字になりました。
Subagentも別コンテキストで実行できるため、表面上はよく似ています。ただ、使い分けるときは「別コンテキストで動くか」だけで見るより、何を再利用したいのかで考える方がわかりやすいです。
同じ手順を毎回回したいならcontext: fork付きSkill。コードレビューや調査担当のように、同じ役割・判断基準・権限を持つ担当者に任せたいならSubagent。今回並べて検証してみて、この整理がいちばんしっくりきました。








