Claude Codeがどんなリクエストを飛ばしているか覗いてみた
こんにちは 人材育成室 育成メンバーチームで 研修中の はすと です。
Claude Codeを使っていると、回答がスッと表示されますよね。一括で返ってきているように見えますが、裏ではどんな通信が飛んでいるんだろう?と気になりました。
本記事では、mitmproxyというHTTPデバッグツールを使って、Claude Codeが裏で行っている通信の中身を覗いてみました。普段は意識しない通信の中身を開けてみることで、SSE(Server-Sent Events)やHTTPストリーミングの仕組みが見えてきたので、その過程を共有します。
なぜmitmproxyが必要か
Claude CodeとAnthropic APIサーバー(api.anthropic.com)の間の通信はHTTPSで暗号化されています。そのため、tcpdumpやWiresharkでパケットキャプチャしても、TLSで暗号化されたバイト列しか見えません。
ここで登場するのがmitmproxy(Man-In-The-Middle Proxy)です。名前の通り「中間者」として通信の間に入るプロキシで、開発者がHTTP/HTTPSの通信をデバッグするためのOSSツールです。
通常の通信は以下のような流れです。

mitmproxyを使うと、こうなります。

Claude CodeにはANTHROPIC_BASE_URLという環境変数があり、APIのリクエスト先を変更できます。これをlocalhost上のmitmproxyに向けることで、Claude Codeはmitmproxyに平文HTTPでリクエストを送り、mitmproxyがそれを本物のAPIサーバーにHTTPSで転送する仕組みですね。
ちなみに、Anthropicの公式ドキュメントSecurely deploying AI agentsでも、mitmproxyはエージェントの通信を検査・制御するためのプロキシの選択肢の1つとして挙げられています。
安全性について
mitmproxyはローカルで動作し、自分の通信を自分で覗いているだけなので、セキュリティリスクは基本的にありません。ただし、認証トークンがmitmproxyのログに平文で表示されるため、スクリーンショットを公開する際はマスク処理が必要です。
環境のセットアップ
mitmproxyのインストール
brew install mitmproxy
mitmproxyの起動(reverse proxyモード)
mitmweb --mode reverse:https://api.anthropic.com --listen-port 8000
mitmwebはブラウザベースのUIを持つmitmproxyです。起動すると http://localhost:8081 にWeb UIが開き、通信内容をリアルタイムで確認できます。
Claude Codeの起動
ANTHROPIC_BASE_URL=http://localhost:8000/ claude
ANTHROPIC_BASE_URLを設定することで、Claude CodeのAPIリクエスト先がlocalhostのmitmproxyに向きます。これでセットアップ完了です。
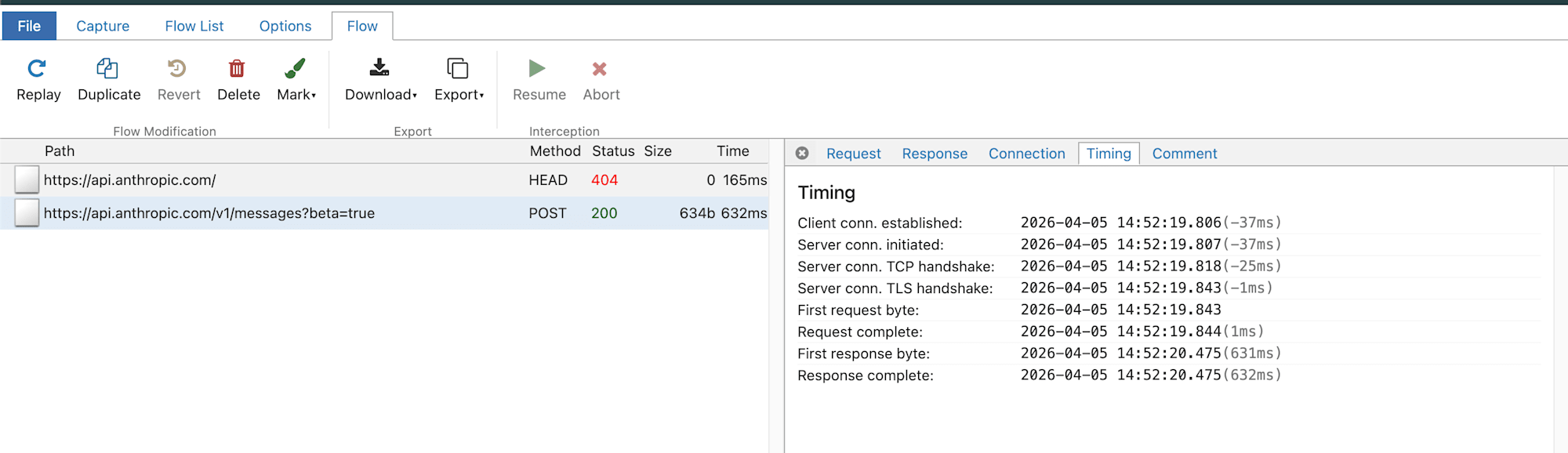

よく見ると、まだ何も入力していないのに2つのリクエストが飛んでいます。これはClaude Codeの初期化処理によるものです。
1つ目はapi.anthropic.comへの単純なリクエストで、リクエストボディはなく、レスポンスもヘッダのみです。APIサーバーへの接続確認と考えられます。
2つ目はclaude-haiku-4-5-20251001(最も安価なモデル)に対して、"quota"というメッセージをmax_tokens: 1で送っているリクエストです。レスポンスは"#"の1トークンだけ。最安モデル×最小トークンという組み合わせから、APIが正常に応答するかの疎通確認が目的と考えられます。
{
"model": "claude-haiku-4-5-20251001",
"id": "msg_01ChUPAu5CfYTQmqQuFUsQL5",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "#"
}
],
"stop_reason": "max_tokens",
"stop_sequence": null,
"stop_details": null,
"usage": {
"input_tokens": 8,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 0,
"cache_creation": {
"ephemeral_5m_input_tokens": 0,
"ephemeral_1h_input_tokens": 0
},
"output_tokens": 1,
"service_tier": "standard",
"inference_geo": "not_available"
},
"context_management": {
"applied_edits": []
}
}
どちらもユーザーの入力を待たずにバックグラウンドで行われるため、起動直後にmitmwebにリクエストが並びます。
通信の中身を覗いてみる
「こんにちは」で何が飛ぶか
Claude Codeで「こんにちは」と入力してみます。
mitmweb のUIを見ると、HTTP POSTリクエストが飛んでいることが確認できます。
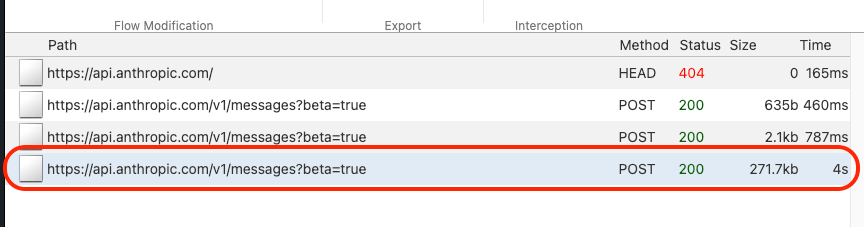
リクエストの中身
エンドポイントはPOST /v1/messagesです。これはAnthropic のMessages APIのエンドポイントそのものです。
リクエストボディのJSON構造は以下のようになっています。
{
"model": "claude-sonnet-4-6",
"messages": [...],
"system": [...],
"tools": [...],
"metadata": {
"user_id": "...",
},
"max_tokens": 8000,
"thinking": {
"type": "adaptive"
},
"output_config": {
"effort": "medium"
},
"stream": true,
}
ここで注目すべきポイントがいくつかあります。
stream: true:レスポンスをSSEでストリーミング受信することを指定しています。これがレスポンスをリアルタイムに受信する仕組みの根幹ですthinking: { type: "adaptive" }:拡張思考(extended thinking)のadaptiveモードです。「考える必要があるか」をモデルが自動判断し、簡単な質問なら考えずに即答、複雑な質問なら立ち止まって考えるという挙動になります。どれくらい深く考えるかは、次のeffortパラメータで制御されますoutput_config: { effort: "medium" }:応答にどれくらい力を入れるかの設定です。max/high/medium/lowの4段階があり、デフォルトはhighです。effortはthinkingの深さだけでなく、応答全体に影響します。lowにするとツール呼び出しの回数が減り説明も簡潔になる一方、highだと丁寧で詳しくなります。Claude Code v2.1.90では、このeffortがmediumに設定されていることが確認できますsystem配列:巨大なシステムプロンプトが含まれています。Claude Codeの振る舞いを定義する指示文で、基本部分だけで約14,000トークンあります。さらにCLAUDE.mdやスキル定義が追加されるため、環境によって総量は変わりますtools配列:Bash、Read、Edit、Write、Glob、Grepなど、Claude Codeが使えるツールの定義が含まれています。v2.1.90時点では15個以上のツールが定義されています- リクエストサイズ:たった「こんにちは」の一言を送るだけでも、JSONのサイズは275.9KBになります。これはシステムプロンプトとツール定義がリクエストに毎回含まれるためです
リクエストヘッダ
POST https://api.anthropic.com/v1/messages?beta=true HTTP/1.1
content-type: application/json
Authorization: Bearer sk-ant-oat01-xxxxx
User-Agent: claude-cli/2.1.90 (external, cli)
connection: keep-alive
anthropic-beta: claude-code-20250219,oauth-2025-04-20,interleaved-thinking-2025-05-14,redact-thinking-2026-02-12,context-management-2025-06-27,prompt-caching-scope-2026-01-05,effort-2025-11-24
...
Authorization: Bearer sk-ant-oat01-...→ Claude CodeがOAuthトークンでAPIに認証していることがわかります。通常のAPI利用ではx-api-keyヘッダを使いますが、Claude Codeはclaude.aiでのログインで取得したOAuthトークンをAuthorization: Bearerで送っていますcontent-type: application/json→ リクエストボディがJSONであることの明示。公式ドキュメントでも必須ヘッダの1つとされていますUser-Agent: claude-cli/2.1.90 (external, cli)→ Claude Codeのバージョンとクライアント種別がわかります。サーバー側でクライアントを識別するための標準的なHTTPヘッダですanthropic-beta→ 有効化されているベータ機能フラグの一覧です。カンマ区切りで並んでおり、Claude Codeがどんな機能を使っているかが見えます
anthropic-betaの各フラグが何を意味するのか見てみると面白いです。
| フラグ | 意味 |
|---|---|
interleaved-thinking |
ツール使用中もthinkingを継続する機能 |
prompt-caching-scope |
プロンプトキャッシュのスコープ制御 |
redact-thinking |
thinking内容の秘匿化 |
context-management |
コンテキスト管理(auto-compact等) |
effort |
effortパラメータの有効化 |
oauth |
OAuth認証 |
ヘッダを見るだけで、Claude Codeが裏で使っている機能の一覧がわかるのが面白いですね。
SSEストリーミングの中身
次にレスポンス側を見てみましょう。ここが本記事の核心です。
Content-Type: text/event-stream; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Cache-Control: no-cache
レスポンスのContent-Typeはtext/event-streamになっています。これがSSE(Server-Sent Events)のMIMEタイプです。
SSEとは
SSE(Server-Sent Events)は、サーバーからクライアントへの一方向のリアルタイム通信の仕組みです。通常のHTTPレスポンスが一括で返ってくるのに対し、SSEではサーバーがコネクションを開いたまま、データを少しずつ送り続けます。
SSEの仕様はWHATWG HTML Living Standardで定義されており、フォーマットは非常にシンプルです。
event: イベント名
data: データ内容
event:でイベントの種類を指定し、data:でデータを送り、空行(\n\n)で1つのイベントが区切られます。詳しくはMDNのSSE解説を参照してください。
実際に流れてくるイベント
Claude Codeのレスポンスでは、Anthropic公式のストリーミングドキュメントに記載されている通り、以下の順序でSSEイベントが流れてきます。
1. message_start ― レスポンスの開始
event: message_start
data: {"type":"message_start","message":{"model":"claude-sonnet-4-6","id":"msg_01SioH3aaUFBKtnGycsZkqDB","type":"message","role":"assistant","content":[],"stop_reason":null,"stop_sequence":null,"stop_details":null,"usage":{"input_tokens":3,"cache_creation_input_tokens":77100,"cache_read_input_tokens":0,"cache_creation":{"ephemeral_5m_input_tokens":0,"ephemeral_1h_input_tokens":77100},"output_tokens":1,"service_tier":"standard","inference_geo":"not_available"}} }
レスポンスのメタ情報が含まれます。input_tokensを見ると、入力トークン数がわかります。「こんにちは」だけなのにcache_creation_input_tokensが77,100トークンもあるのは、システムプロンプトとツール定義の分がキャッシュとして作成されているためです。input_tokens自体は3(「こんにちは」の分)ですが、初回はキャッシュ作成のために大量のトークンが処理されます。
2. content_block_start ― コンテンツブロックの開始
event: content_block_start
data: {"type":"content_block_start","index":0,"content_block":{"type":"text","text":""} }
3. content_block_delta ― テキストが少しずつ流れてくる
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"text_delta","text":"こ"}}
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"text_delta","text":"んにちは!今日は何を探求しますか?"} }
ここがSSEの醍醐味です。テキストが数トークンずつdeltaとして流れてきます。ただし、Claude CodeのUI側ではこれらのdeltaをそのまま1つずつ表示しているわけではありません。Claude CodeはReact/InkベースのTUIアプリとして実装されており(GitHub Issue #31194)、届いたトークンをバッファリングしてからまとめて描画しているようです(GitHub Issue #29213)。そのため、ユーザーからは一括表示のように見えます。通信層ではトークン単位のストリーミングが起きているのに、表示層ではバッファリングされている。この違いが面白いポイントです。
4. ping ― 接続の維持
event: ping
data: {"type":"ping"}
モデルが「考えている」間、コネクションを維持するためにpingイベントが送られます。HTTPのコネクションタイムアウトを防ぐ役割があると考えられます。
5. message_delta と message_stop ― レスポンスの完了
event: message_delta
data: {"type":"message_delta","delta":{"stop_reason":"end_turn","stop_sequence":null,"stop_details":null},"usage":{"input_tokens":3,"cache_creation_input_tokens":77100,"cache_read_input_tokens":0,"output_tokens":20},"context_management":{"applied_edits":[]} }
event: message_stop
data: {"type":"message_stop"}
停止理由(end_turn:モデルが応答を完了した)と、トークン使用量が返ってきます。なお、ここのusageは累積値で、このレスポンス全体で消費したトークンの合計です。
ツール実行時には何が起こるか
Claude Codeの面白いところは、単にテキストを返すだけでなく、ファイルの読み書きやbashコマンドの実行といった「ツール」を使えることです。ツール実行時の通信はどうなっているのか、気になったので覗いてみます。
例えば「このディレクトリのファイル一覧を見せて」と頼んでみます。以下はmitmwebで確認した、このやり取りで飛んだリクエストの一覧です。

リクエスト1:ユーザーのメッセージを送信
まず、ユーザーの入力がAPIに送信されます。リクエストボディのmessages配列にはユーザーのメッセージが含まれています。
{
"model": "claude-sonnet-4-6",
"messages": [
....// 省略
{
"role": "user",
"content": [
{
"type": "text",
"text": "このディレクトリのファイル一覧を見せて",
"cache_control": {
"type": "ephemeral",
"ttl": "1h"
}
}
]
}
],
....// 省略
}
レスポンス1:モデルがツール呼び出しを返す
このリクエストに対して、モデルはテキストではなくツールの呼び出しを返してきます。
event: message_start
data: {"type":"message_start","message":{"model":"claude-sonnet-4-6",..."usage":{"input_tokens":3,"cache_creation_input_tokens":40,"cache_read_input_tokens":77100,...}}}
event: content_block_start
data: {"type":"content_block_start","index":0,"content_block":{"type":"tool_use","id":"toolu_01X3k7n3Bp5x3TiG3jF2HUVY","name":"Bash","input":{}}}
ここで注目したいのがcache_read_input_tokens: 77100です。先ほどの「こんにちは」ではcache_creation_input_tokens: 77100だったのが、今回はcache_readに変わっています。つまり、1回目のリクエストで作成されたキャッシュがヒットして、システムプロンプトの再処理がスキップされていることがわかります。
続いて、ツールの入力(コマンド)がSSEのinput_json_deltaとして少しずつ流れてきます。
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"input_json_delta","partial_json":"{\"comman"}}
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"input_json_delta","partial_json":"d\": \"ls /Users/sasaki.hasuto/workspace\"}"}}
event: content_block_stop
テキストのときはtext_deltaでしたが、ツール呼び出しではinput_json_deltaとしてJSONが少しずつ組み立てられていくのが面白いですね。最終的に{"command": "ls /Users/sasaki.hasuto/workspace"}というBashツールへの入力が完成します。
Claude(モデル)は自分でコマンドを実行するのではなく、「このコマンドを実行してほしい」というリクエストをClaude Codeクライアントに返します。
リクエスト2:ツール実行結果の送信
Claude Codeはローカルでコマンドを実行し、その結果を次のリクエストのmessagesに含めてAPIに送り返します。
{
"model": "claude-sonnet-4-6",
"messages": [
// 省略
{
"role": "user",
"content": "このディレクトリのファイル一覧を見せて"
},
{
"role": "assistant",
"content": [
{
"type": "tool_use",
"id": "toolu_01X3k7n3Bp5x3TiG3jF2HUVY",
"name": "Bash",
"input": {
"command": "ls /Users/sasaki.hasuto/workspace"
}
}
]
},
{
"role": "user",
"content": [
{
"tool_use_id": "toolu_01X3k7n3Bp5x3TiG3jF2HUVY",
"type": "tool_result",
"content": "blog\nCLAUDE.md\ndownload.html\ngtd\nknowledge\nprojects\nrequest-header.json\nresponse.json\nscratchpad\ntools-response.json\nzettelkasten",
"is_error": false,
"cache_control": {
"type": "ephemeral",
"ttl": "1h"
}
}
]
}
],
// 省略
}
このJSONの構造を見ると、ツール実行の流れが会話の形式で表現されていることがわかります。
tool_use(role: "assistant"): レスポンス1でモデルが返した「このツールをこの引数で呼んでほしい」という要求tool_result(role: "user"): Claude Codeがローカルで実行した結果。モデルから見るとツール結果は「ユーザー側から提供された情報」という扱いなので、roleは"user"になりますtool_use_id: どのツール呼び出しに対する結果かを紐付けるID。モデルが複数のツールを同時に呼ぶ場合に、どの結果がどの呼び出しに対応するかを明確にしますis_error: false: 実行が成功したことを示します。trueの場合、モデルにエラーが伝わり、リトライや別のアプローチを考えます
詳しくはTool useのドキュメントを参照してください。
レスポンス2:最終回答
モデルはツールの実行結果を踏まえて、ユーザーへの最終回答をテキストで返します。
event: content_block_delta
data: {"type":"content_block_delta","index":0,"delta":{"type":"text_delta","text":"```\nworkspace/\n├── blog/\n├── CLAUDE.md\n..."}}
event: content_block_stop
つまり、ツール実行を伴うやり取りでは最低でも2往復のHTTPリクエストが発生します。mitmwebで見ると、POST /v1/messagesが複数回飛んでいることが確認できます。
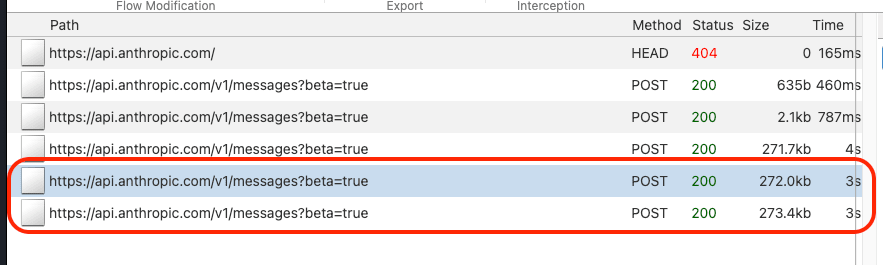
[リクエスト1] ユーザー: 「ファイル一覧を見せて」
↓
[レスポンス1] モデル: tool_use(Bash: ls /Users/sasaki.hasuto/workspace)
↓
[Claude Codeがローカルでコマンドを実行]
↓
[リクエスト2] Claude Code: tool_result(実行結果)
↓
[レスポンス2] モデル: 「以下がファイル一覧です...」
さらに注目すべきは、2回目のリクエストには1回目の会話履歴がすべて含まれていることです。APIはステートレスなので、毎回の会話コンテキストを丸ごと送り直す必要があります。会話が長くなるほどリクエストサイズが膨らんでいく仕組みです。
なぜ WebSocket ではなく SSE なのか
ここまで見てきて、「リアルタイム通信ならWebSocketでは?」という疑問が湧いたので、Claude CodeがSSEを採用している理由を考えてみました。
| 観点 | SSE | WebSocket |
|---|---|---|
| 通信方向 | サーバー→クライアント(一方向) | 双方向 |
| プロトコル | 通常のHTTPのまま動作 | HTTPとは別のプロトコル。接続開始時にHTTPを借りて、その後専用の通信に切り替わる |
| インフラ互換性 | 通常のHTTP通信なので通過しやすい | プロトコル切り替えに非対応のプロキシがあると失敗する場合がある |
Claude Codeのユースケースでは、クライアント→サーバーの通信は普通のHTTP POSTで十分です。サーバー→クライアント方向のストリーミングだけが必要なので、双方向通信のWebSocketは過剰ですね。SSEは通常のHTTPレスポンス(Content-Type: text/event-stream)をそのまま使うだけなので、プロトコルの切り替えも不要で、既存のHTTPインフラをそのまま活用できます。
リアルタイム通信の手段を選ぶ際に、まず「一方向で十分か?」を考えてみて、十分ならSSEを選ぶのが良さそうです。
WebSocketとSSEの違いをもう少し詳しく
WebSocketの「プロトコルの切り替え」とは?
WebSocketはHTTPとは別のプロトコルですが、接続を始めるときだけHTTPの仕組みを借ります。HTTP/1.1ではUpgrade: websocketヘッダを付けて「WebSocketに切り替えたい」とリクエストし、HTTP/2では拡張CONNECT方式(RFC 8441)で接続します。いずれの場合も、接続が確立するとそれ以降はHTTPではなくWebSocket専用の通信になります。この切り替えに対応していないネットワーク機器があると、接続が失敗することがあります。
SSEの「レスポンスを返し続ける」とは?
通常のHTTPでは、サーバーはレスポンスを返したら接続を閉じます。SSEではレスポンスのボディを一括で返さず、少しずつ追記し続けます。接続を閉じないまま、データが発生するたびに書き込む——これが「long-lived(長寿命)なHTTPリクエスト」です。サーバー側は普通のHTTPレスポンスを書き込み続けるだけなので、既存のHTTPフレームワーク(Express、Fastifyなど)でそのまま実装できます。
WebSocketのサーバー実装が複雑な理由
WebSocketは接続後、HTTPではなくなり、「フレーム」という独自のデータ形式でやり取りします。サーバーはこのフレームを自分で組み立て・解析する必要があり、以下のような処理が増えます。
- フレームの解析: データがHTTPのテキストではなくバイナリ形式のフレームで届くため、ヘッダやペイロードを自分でパースする必要がある
- 接続の死活監視(ping/pong): WebSocketは接続を長時間開きっぱなしにするため、「相手がまだいるか?」を確認する仕組みがプロトコルに組み込まれている。電話で相手が無言になったとき「もしもし?」と呼びかけるのがping、「聞こえてるよ」と返事するのがpong。返事がなければ「切れた」と判断して接続を閉じる。サーバーはこのpingの定期送信と、pongが返ってこない場合の切断処理を実装する必要がある
- WebSocket専用のライブラリが必要: HTTPのライブラリでは扱えないため、wsなどの専用ライブラリを別途導入する必要がある
SSEはこれらの処理がすべて不要です。HTTPのまま動くので、フレームの解析もping/pongの管理も要りません。
ただし、大量の接続を開いたまま保持し続けるとサーバーのリソースを消費するという課題は、SSEでもWebSocketでも同じです。
より詳しくは以下のリソースが参考になります。
- Server-Sent Events vs WebSockets - Ably — SSEとWebSocketの違いを図付きで解説
- WebSocket Protocol: RFC 6455 - WebSocket.org — WebSocketのフレーム構造やハンドシェイクの解説
- Using server-sent events - MDN — SSEの仕様と使い方
まとめ
Claude Codeの通信をmitmproxyで覗いてみたことで、色々と新たな発見がありました。
回答がスッと表示されるので一括で返ってきているのかと思いきや、裏ではSSEで数トークンずつ細かくストリーミングされていて、通信層とUI層で挙動が違うというのは驚きでした。
ツール実行のフローも面白かったです。「ファイル一覧を見せて」と頼むと、APIからはまず「lsコマンドを実行してほしい」という指示が返ってきて、Claude Codeがローカルで実行した結果をAPIに送り返し、それを踏まえた回答が返ってくる。1回のやり取りに見えて、裏では2往復のHTTPリクエストが飛んでいました。しかも2回目のリクエストには1回目の会話履歴が丸ごと含まれていて、毎回全部送り直しているということも、通信を覗いてみてわかったことの1つです。
普段何気なく使っているツールでも、中身を覗いてみるとHTTP、SSE、ステートレスAPI設計といった基礎的な技術が組み合わさって動いていることが見えました。普段使っているツールの仕組みが一つずつわかっていくのは非常に面白いです。