
【Claude Enterprise】Compliance API の アクティビティフィードをGoogle Cloud環境のBigQueryに日次で自動収集する
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
Claude Enterprise を組織導入すると、「誰が・いつ・どのようにClaudeを使ったか」を監査・証跡管理したいニーズが生まれます。Anthropicでは 2026年5月に Compliance API を正式リリースし、組織のアクティビティデータへのプログラムアクセスが可能になりました。
この記事では、Compliance API の アクティビティフィードをGoogle Cloud環境のBigQueryに日次で監査ログを自動収集・蓄積するアーキテクチャの設計と実装を紹介します。
Compliance API とは
Compliance API は、Claude Enterprise 組織のアクティビティデータを REST API 経由で取得できる仕組みです。IT・セキュリティ・法務・コンプライアンスチームが、Claude の利用証跡を継続的に監視・収集するために使います。
取得できるデータ
Compliance API で取得できるデータは以下の通りです。アクティビティフィードでは、Claude Enterprise での認証やユーザー追加・削除などの操作イベントを取得できます。それ以外にも、チャット・プロジェクト・組織情報など複数のエンドポイントが用意されています。
| エンドポイント | 取得できる内容 |
|---|---|
GET /v1/compliance/activities |
全ての操作イベント(認証・チャット・ファイル・管理操作) |
GET /v1/compliance/apps/chats |
チャット一覧(メタデータ) |
GET /v1/compliance/apps/chats/{id}/messages |
チャットのメッセージ本文・添付ファイル |
GET /v1/compliance/apps/projects |
プロジェクト一覧 |
GET /v1/compliance/organizations |
組織・ユーザー・ロール・グループ一覧 |
Activity イベントの主なフィールド
{
"id": "activity_01XyDMpzjS89pFZXqSFUBDr6",
"created_at": "2026-04-10T08:09:10Z",
"organization_id": "org_01Wv6QeBcDfGhJkLmNpQrSt8",
"actor": {
"type": "user_actor",
"email_address": "user@example.com",
"user_id": "user_01TuVwXyZaBcDeFgH2JkLmN4",
"ip_address": "192.0.2.34",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) ..."
},
"type": "claude_chat_created",
"claude_chat_id": "claude_chat_01XyDMpzjS89pFZXqSFUBDr6"
}
actor.type には user_actor(ユーザー操作)、api_actor(APIキーでのアクセス)、scim_directory_sync_actor(OktaなどSCIM同期)など複数の種別があります。user_actor の場合は user_agent にブラウザ情報も含まれるため、どのクライアントからアクセスされたかを追跡できます。
実際に収集されるイベント種別は多岐にわたります。以下は検証で観測されたイベントの例です。
| カテゴリ | イベント種別の例 |
|---|---|
| 認証 | sso_login_initiated / sso_login_succeeded / user_logged_out |
| ユーザー管理 | claude_user_settings_updated / claude_user_role_updated / org_iam_seat_tier_assignment_toggled |
| 組織設定 | claude_organization_settings_updated / org_sso_provisioning_mode_changed |
| グループ操作 | group_list_viewed / group_member_list_viewed |
| チャット | claude_chat_created |
| API アクセス | compliance_api_accessed |
利用条件と認証
- Claude Enterprise プラン(公共部門を除く)のみ利用可能。Claude Console 組織は Activity Feed のみアクセス可
- Primary Owner が Organization Settings > API から有効化したうえで、Compliance Access Key(
sk-ant-api01-...)を発行する - 認証は
x-api-keyヘッダーで行う
API の特性
| 項目 | 内容 |
|---|---|
| ベース URL | https://api.anthropic.com/v1/compliance/* |
| データ鮮度 | イベント発生から 1分以内 にクエリ可能 |
| 保持期間 | 6年間 |
| レート制限 | 600 req/min / 親組織 |
| 最大取得件数 | 1リクエストあたり 5,000件 |
| ページネーション | カーソル方式(after_id / last_id) |
本アーキテクチャの設計方針
1日1回の取得頻度
コンプライアンス監査・ログ蓄積が目的であれば、1日1回の実行で十分かと思います。
理由としては、以下が考えられます。
- 保持期間が6年あるため、翌日取得しても欠損しない
- 監査ログは「後から調査できること」が主目的のため、リアルタイム性は不要
- BigQuery へのバッチ書き込みを利用することでコストを最小にできる
BigQuery への書き込みは「バッチ load ジョブ」を使う
BigQuery への取り込みには2つの方法があります。
| 方式 | 費用 | 特徴 |
|---|---|---|
| ストリーミング挿入 | 課金あり($0.012/200MB) | リアルタイムだがバッファ遅延・重複制約あり |
| バッチ load ジョブ | 無料 | 日次バッチに最適。重複排除制約なし |
監査ログのような日次バッチ取り込みには、コスト・シンプルさの両面でバッチ load ジョブを利用するとよいです。
スキーマ設計:型付きカラム + raw JSON カラム
Compliance API は今後も新しいイベントタイプを追加する可能性があります。主要フィールドを型付きカラムに展開しつつ、元レコード全体を raw(JSON型)カラムに保持することで、スキーマ変更なしで新イベントに追従できます。
CREATE TABLE compliance.activities (
id STRING, -- 重複排除キー
type STRING, -- イベント種別(クラスタリングキー)
created_at TIMESTAMP, -- 発生時刻(パーティションキー)
raw JSON, -- 元レコード全体
_target_date DATE, -- 取得対象日(バックフィル管理用)
_ingested_at TIMESTAMP -- BigQuery取り込み時刻
)
PARTITION BY DATE(created_at)
CLUSTER BY type;
カーソル管理で途中失敗から確実に再開する
1日1回しか実行しないため、失敗時のリカバリが重要になります。ページを1つ取得・書き込みするたびにカーソル(last_id)を Cloud Storage に保存することで、途中で失敗しても次回実行時に続きから再開することができます。
cursor = load_from_gcs()
loop:
page = GET /v1/compliance/activities?after_id={cursor}&limit=1000
write_to_bigquery(page.data) ← 書き込み完了後に
save_cursor(page.last_id) ← カーソルを更新
if not page.has_more: break
カーソルによる再開機能があるため、Cloud Scheduler 側のリトライは無効(retry_count = 0) にします。Scheduler が自動リトライすると前回の実行がまだ動いている状態で二重起動が発生し、BigQuery に重複データが書き込まれるリスクがあるためです。失敗検知は Cloud Monitoring のアラートで行い、リカバリは手動または次回の定期実行に任せます。
Google Cloud で構築する強み
BigQuery のコスト特性がコンプライアンスログと相性が良い
バッチ load ジョブが無料というのは、日次バッチ収集との相性が抜群です。ストリーミング挿入($0.01/200MB)と比べてデータ量が増えるほど差が開きます。
さらに、90日間更新されていないテーブルパーティションはストレージ料金が自動的に約50%引き(ロングタームストレージ)になります。監査ログは書き込み後に更新しないため、3ヶ月を過ぎたパーティションはほぼすべて自動的に安価なロングタームストレージへ移行させることができます。
Compliance API の保持期間が6年であることを踏まえると、長期蓄積コストを大幅に抑えられます。
パーティション+クラスタリングの組み合わせでクエリスキャン範囲を絞り込めるため、監査調査のような「特定期間・特定イベント種別」を絞るクエリのコストを最小化できます。パーティションプルーニングにより、実行前にスキャンバイト数の見積もりも可能です。
Cloud Run Functions のタイムアウト上限が大量ログの取得に必須
Cloud Run Functions は Cloud Run ベースで動作するため、HTTP トリガーで最大 60 分(3600 秒)のタイムアウトが設定できます。1st gen の上限は 9 分だったため、ページネーションが多い大量ログの一括取得には Gen2 が事実上必須です。
| バージョン | タイムアウト上限(HTTP) |
|---|---|
| Cloud Functions 1st gen | 9 分 |
| Cloud Run Functions(Cloud Run) | 60 分 |
BigQuery に蓄積したデータをそのまま BI ツールで可視化できる
BigQuery に蓄積した監査ログは、追加のデータパイプラインなしで以下のツールと直接連携できます。
- Looker Studio(旧 Data Studio): 無料で使えるダッシュボードツール。BigQuery クエリの結果をリアルタイムに可視化でき、監査レポートをチームと共有可能
- Connected Sheets: Google スプレッドシートから BigQuery を直接クエリできる。コンプライアンス担当者が SQL を書かずにピボットテーブルで集計できる
- Looker: エンタープライズ向け BI プラットフォーム。LookML でメトリクスを定義すれば、組織全体で一貫した監査指標を使い回せる
セキュリティコントロールが一気通貫で揃っている
コンプライアンス証跡の管理には、APIキーの保護・通信の認証・アクセス制御・改ざん防止が必要です。Google Cloud ではこれらをネイティブのサービスで一気通貫に構成できます。
| 要件 | Google Cloud のサービス |
|---|---|
| APIキーをコードに残さない | Secret Manager |
| 定時起動の認証 | Cloud Scheduler + OIDC トークン |
| 最小権限アクセス制御 | IAM(バケット・BQ データセット単位) |
| ログバケットの公開アクセス禁止 | public_access_prevention = "enforced" |
| 監査テーブルの誤削除防止 | BigQuery deletion_protection = true |
| インフラ全体をコードで管理 | Terraform + Cloud Storage State バックエンド |
Google Cloud アーキテクチャ
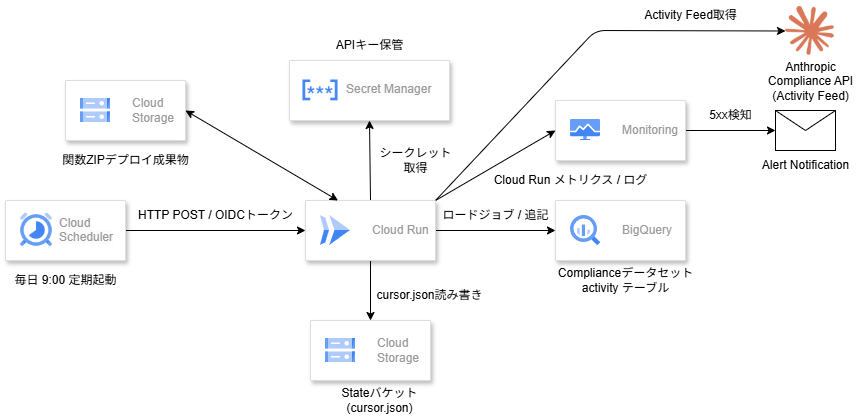
全体の流れは Cloud Scheduler → Cloud Run → BigQuery の3ステップです。外部サービスは Anthropic Compliance API だけで、Google Cloud 内のコンポーネントはすべてマネージドサービスで構成されています。
Google Cloud環境の各リソースはTerraformで作成しました。
| コンポーネント | 役割 |
|---|---|
| Cloud Scheduler | 毎日 9:00 JST(00:00 UTC)に OIDC トークン付き HTTP POST で Cloud Run を起動 |
| Cloud Run(Cloud Run Functions) | Compliance API からアクティビティを取得し BigQuery にロード |
| Secret Manager | Compliance API キーを安全に保管。Cloud Run は起動時にシークレットを取得 |
| Cloud Storage(Stateバケット) | cursor.json を読み書きし、ページネーションの進捗を永続化 |
| Cloud Storage(デプロイバケット) | 関数のソースコード ZIP を格納。Terraform の source として参照 |
| BigQuery | compliance データセットの activities テーブルにロードジョブで追記 |
| Cloud Monitoring | Cloud Run のメトリクス・ログを監視し、5xx エラーをメールでアラート通知 |
実装
Cloud Run Functions コード
ここでは今回実装したコードの主要な処理を抜粋します。
対象日の決定
Cloud Scheduler は 0 0 * * *(毎日 00:00 UTC)で起動するため、datetime.now(UTC).date() - 1日 が「直近の完結した1日分」になります。payload に {"date": "2026-06-04"} を渡せば任意の日付を指定できるため、過去日のバックフィルも同じ関数で行えます。
def _resolve_target_date(payload):
override = (payload or {}).get("date")
if override:
return dt.date.fromisoformat(override)
# Cloud Scheduler は 00:00 UTC 起動なので、前日 = 直近の完結した1日分
return dt.datetime.now(dt.timezone.utc).date() - dt.timedelta(days=1)
1ページ取得(リトライ付き)
429(レート制限)と 5xx(サーバーエラー)のみリトライ対象とし、それ以外(400系)はすぐに例外を上げます。バックオフは min(2^attempt, 60) で指数的に増加させ、最大60秒で頭打ちにしています。
def _fetch_page(api_key, query):
url = "{}{}?{}".format(API_BASE, ACTIVITIES_PATH, urllib.parse.urlencode(query))
req = urllib.request.Request(url, headers={"x-api-key": api_key})
for attempt in range(1, MAX_RETRIES + 1):
try:
with urllib.request.urlopen(req, timeout=HTTP_TIMEOUT_SECONDS) as resp:
return json.loads(resp.read().decode("utf-8"))
except urllib.error.HTTPError as exc:
retryable = exc.code == 429 or exc.code >= 500
if not retryable or attempt == MAX_RETRIES:
raise
backoff = min(2 ** attempt, 60)
time.sleep(backoff)
メインループ
created_at.gte / created_at.lt で取得範囲を対象日の 00:00:00Z〜翌日 00:00:00Z に絞り込み、after_id でページを進めます。BigQuery への書き込みを完了してからカーソルを更新する順序が重要で、これを逆にすると書き込み失敗時にカーソルだけ進んでデータが欠損します。has_more が false になった時点でループを抜けます。
while True:
query = {
"limit": PAGE_LIMIT,
"created_at.gte": window_start, # 対象日 00:00:00Z
"created_at.lt": window_end, # 翌日 00:00:00Z
}
if after_id:
query["after_id"] = after_id
page = _fetch_page(api_key, query)
activities = page.get("data", [])
if activities:
_load_page(_to_rows(activities, date_str, ingested_at)) # BigQuery 書き込み
total += len(activities)
after_id = page.get("last_id") or after_id
# BigQuery 書き込み完了後にカーソルを保存(ここが重要)
_save_cursor({
"date": date_str,
"after_id": after_id,
"completed": not page.get("has_more", False),
"total_collected": total,
})
if not page.get("has_more", False):
break
BigQuery 行への変換
主要フィールドを型付きカラムに展開しつつ、元のレコード全体を json.dumps で文字列化して raw カラムに保持します。Compliance API が将来新しいフィールドを追加しても、raw から JSON_VALUE で取り出せるためスキーマ変更が不要です。
def _to_rows(activities, target_date, ingested_at):
rows = []
for a in activities:
rows.append({
"id": a.get("id"),
"type": a.get("type"),
"created_at": a.get("created_at"),
"raw": json.dumps(a, ensure_ascii=False), # 元レコード全体を保持
"_target_date": target_date,
"_ingested_at": ingested_at,
})
return rows
セットアップ手順
前提条件
- Terraform >= 1.10.0
- gcloud CLI(
gcloud auth application-default login済み) - 課金が有効な Google Cloud プロジェクト
- Compliance API アクセスキー(Claude Enterprise プランで発行)
1. Terraform apply
Terraform State を Cloud Storage に保存する構成になっていますが、State バケット自体も Terraform で作成するため初回だけ手順でローカル実行する必要があります。
その後、Cloud Storageへstateファイルを移行することができます。
# ① backend.tf の backend ブロックをコメントアウトした状態で apply(ローカル State)
terraform init
terraform apply \
-var="project_id=YOUR_PROJECT_ID" \
-var="region=asia-northeast1" \
-var="alert_email=your-email@example.com" \
-var="dataset_id=claude_compliance" \
-var="table_id=activities" \
-var="table_expiration_days=0" # 0 = 無期限保持
# ② backend.tf の backend ブロックのコメントを外す
# backend "gcs" {
# bucket = "YOUR_PROJECT_ID-claude-compliance-tfstate"
# prefix = "compliance-collector-bigquery"
# }
# ↓ コメントを外して有効化
# ③ State を Cloud Storage へ移行
terraform init -migrate-state
2. Compliance API キーを Secret Manager に登録
Claude Enterprise 管理コンソール(claude.ai)で Compliance Access Key を発行します。発行時は read:compliance_activities スコープが必要です。
Terraform ではシークレットの「箱」のみ作成し、キーの値はコードに残さず手動登録します。
printf 'sk-ant-api01-xxxxxxxx' | \
gcloud secrets versions add claude-compliance-api-key \
--project="YOUR_PROJECT_ID" --data-file=-
3. 動作確認
FUNCTION_URI=$(terraform output -raw function_uri)
# Cloud Scheduler を即時実行して定時起動と同じフローを確認
gcloud scheduler jobs run "$(terraform output -raw scheduler_job_name)" \
--location=asia-northeast1
# 実行ログの確認
gcloud functions logs read "$(terraform output -raw function_name)" \
--gen2 --region=asia-northeast1
4. BigQuery でデータを確認
データが正しく取り込まれているか、以下のクエリで確認します。
取り込み件数の確認
まず日付ごとの件数を確認して、収集が継続できているかを確かめます。
-- 直近7日の取り込み件数
SELECT _target_date, COUNT(*) AS n
FROM `YOUR_PROJECT.claude_compliance.activities`
GROUP BY _target_date
ORDER BY _target_date DESC
LIMIT 7;
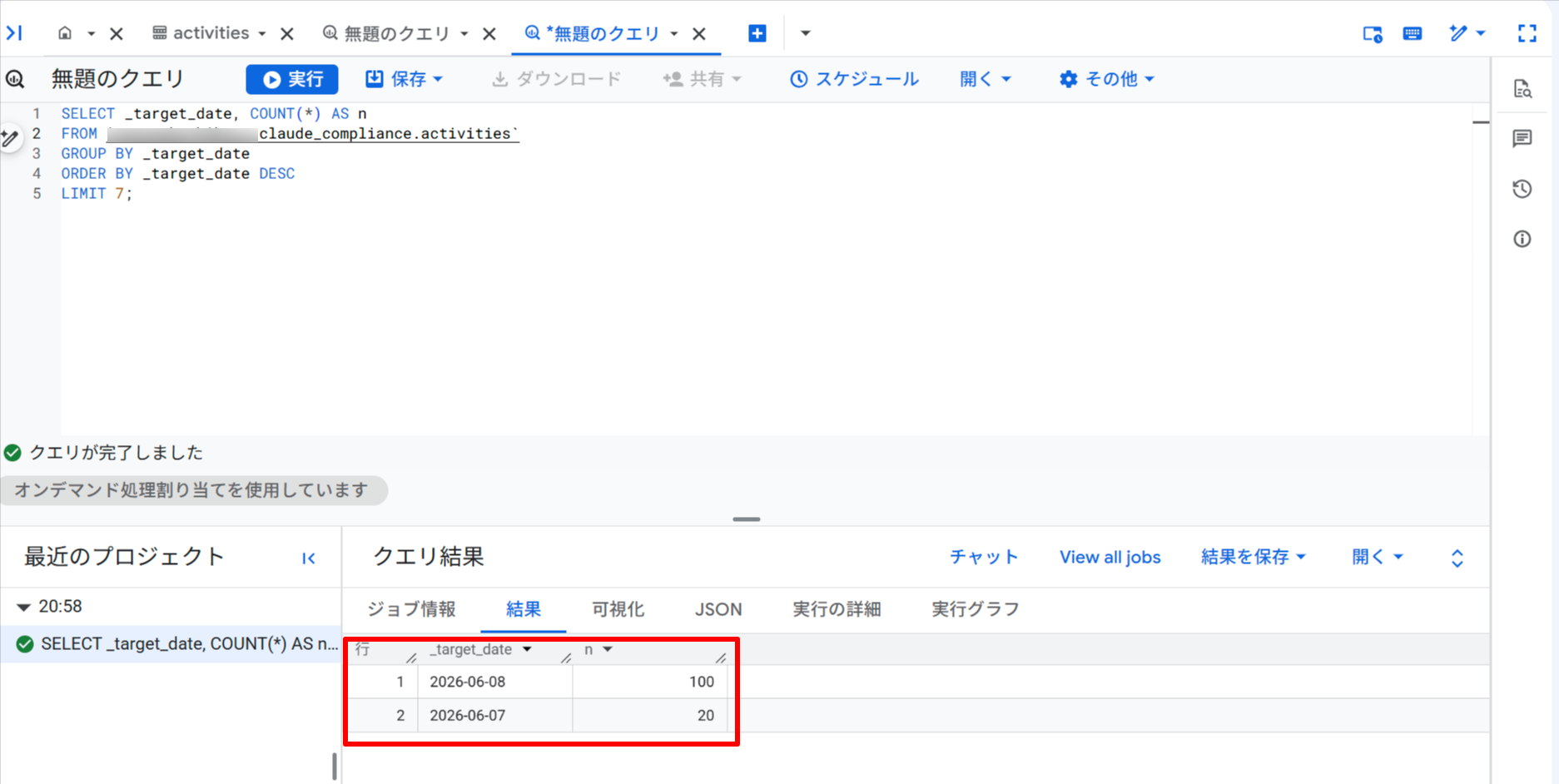
日付ごとの取り込み件数が確認できます。この例では 2026-06-08 に 100 件、2026-06-07 に 20 件が蓄積されています。件数が 0 の日があれば収集失敗を疑うシグナルになります。
イベント種別の分布確認
次にイベント種別の内訳を確認します。どのような操作が多いかを把握しておくと、異常検知のベースラインになります。
-- イベント種別の分布
SELECT type, COUNT(*) AS n
FROM `YOUR_PROJECT.claude_compliance.activities`
WHERE TIMESTAMP_TRUNC(created_at, DAY) = TIMESTAMP("2026-05-17")
GROUP BY type
ORDER BY n DESC;
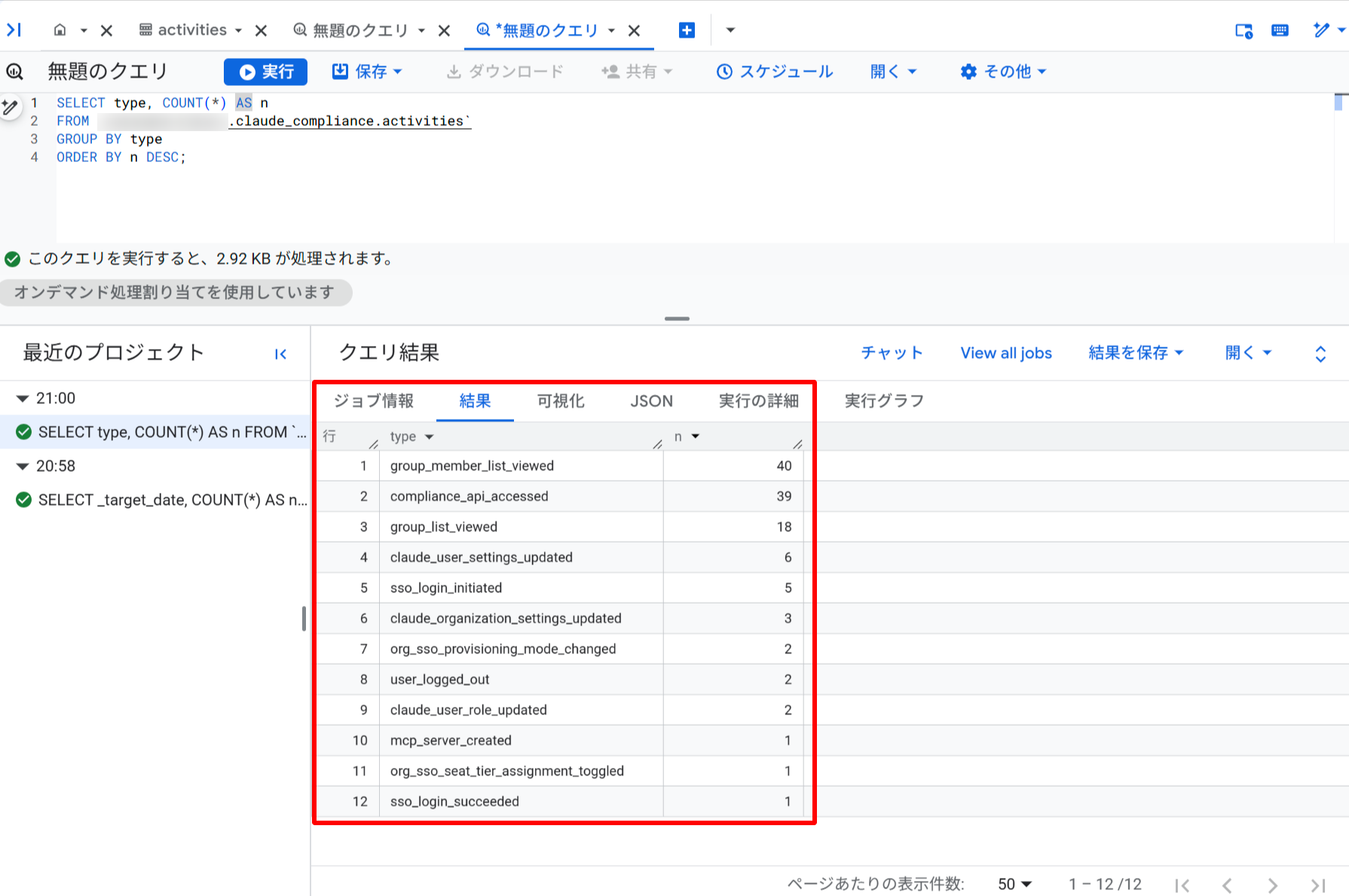
group_member_list_viewed(グループメンバー一覧の閲覧)が最多で、次いで compliance_api_accessed(Compliance API へのアクセス自体のログ)、group_list_viewed が続いています。チャット作成以外にも SSO ログインや設定変更など組織管理系のイベントが幅広く収集されていることが分かります。
raw カラムからの詳細フィールド取得
raw カラムに保持した元レコードから、型付きカラムに展開されていないフィールドも取り出せます。
-- raw カラムからネストされたフィールドを取得
-- raw は STRING として保存されるため JSON_VALUE を二重に適用する
SELECT
-- actor フィールド
JSON_VALUE(JSON_VALUE(raw, '$'), '$.actor.email_address') AS actor_email_address,
JSON_VALUE(JSON_VALUE(raw, '$'), '$.actor.ip_address') AS actor_ip_address,
JSON_VALUE(JSON_VALUE(raw, '$'), '$.actor.type') AS actor_type,
JSON_VALUE(JSON_VALUE(raw, '$'), '$.actor.user_agent') AS actor_user_agent,
JSON_VALUE(JSON_VALUE(raw, '$'), '$.actor.user_id') AS actor_user_id,
-- トップレベルフィールド
JSON_VALUE(JSON_VALUE(raw, '$'), '$.created_at') AS created_at,
JSON_VALUE(JSON_VALUE(raw, '$'), '$.id') AS id,
JSON_VALUE(JSON_VALUE(raw, '$'), '$.organization_id') AS organization_id,
JSON_VALUE(JSON_VALUE(raw, '$'), '$.type') AS type
FROM `YOUR_PROJECT.claude_compliance.activities`
WHERE TIMESTAMP_TRUNC(created_at, DAY) = TIMESTAMP("2026-05-17")
LIMIT 10;
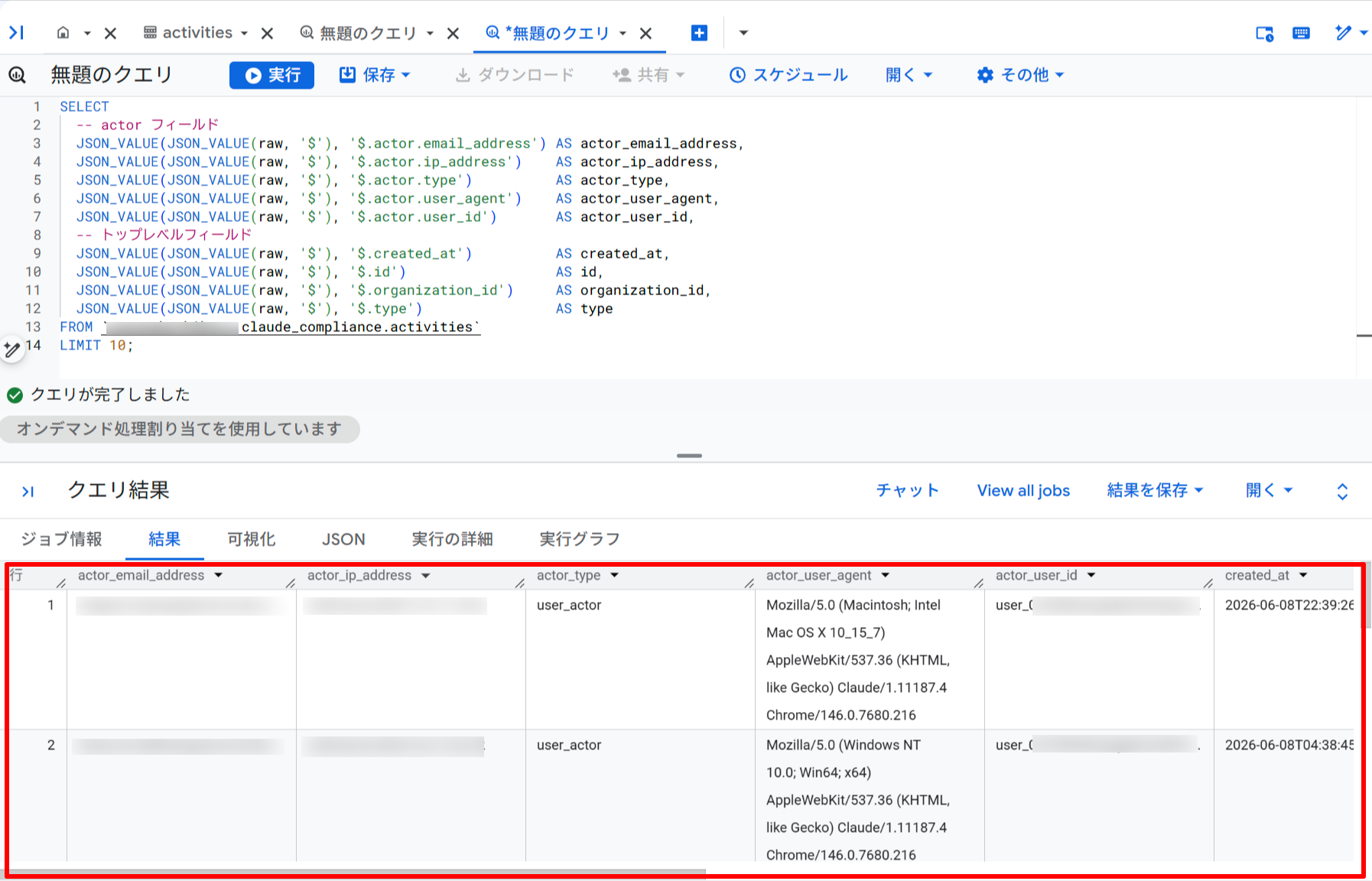
actor_email_address でどのユーザーの操作か、actor_ip_address でアクセス元 IP、actor_user_agent でブラウザ・クライアント情報を確認できます。これらのフィールドを組み合わせることで、「どのユーザーが・どの端末から・何をしたか」を追跡する監査クエリを構築できます。
運用のポイント
重複排除
手動バックフィルなどで同一日を再実行した場合、バッチ load ジョブは追記のため行が重複します。
その場合は、クエリ側で id カラムによる重複排除を行うか、再実行前に対象パーティションを削除してください。
失敗時の対応
Cloud Monitoring のアラートが発火したら、まず Cloud Logging でエラーを確認します。
gcloud functions logs read "claude-compliance-prod-collector-bq" \
--gen2 --region=asia-northeast1
カーソルが残っていれば、次回の Cloud Scheduler 実行または手動実行で途中から自動再開します。
対象日全体を取り直したい場合は Cloud Scheduler に {"date":"YYYY-MM-DD"} を指定して手動実行してください。
まとめ
本記事では、Claude Enterprise の Compliance API を Google Cloud で日次収集・BigQuery に蓄積する構成を紹介しました。
監査ログの主目的は「後から調査できること」であり、Compliance API の保持期間が6年あるため、翌日取得してもデータ欠損のリスクはありません。実行基盤にはCloud Run Functions を選定することで、タイムアウト最大3600秒という余裕を持ちながら大量のログでも完走できます。
BigQuery への書き込みはバッチ load ジョブを使うことで、ストリーミング挿入と異なり取り込みコストがかかりません。スキーマは型付きカラム + raw JSON カラムの構成にしておくと、Compliance API が新しいイベントタイプを追加してもスキーマ変更なしで追従できます。
カーソルはBigQuery への書き込み完了後に更新することが重要です。この順序を守ることで、途中失敗が発生しても次回実行から安全に再開でき、データ欠損を防げます。1日1回の実行だからこそ失敗時の影響が大きいため、Cloud Monitoring で5xxを監視して早期に気づける仕組みを合わせて用意してください。
Compliance API の保持期間が6年あるため、今から有効化・収集を開始すれば長期的な監査証跡として活用できます。まず有効化だけでも早めに実施しておくことをおすすめします。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!











