
Cloud Logging のフォルダ/組織 Sink で監査ログを集約し、Observability Analytics + BigQuery で横断分析してみた
組織配下の全プロジェクトの監査ログを1つの Cloud Logging バケットに集めて、BigQuery でプロジェクト横断 SQL 分析できる状態までを Terraform で構築してみました。
集約バケット側の構成については以下の記事でも触れていますので、合わせて参照してみてください。
なぜこの構成なのか
プロジェクト単位でログバケットを置く運用では、プロジェクトをまたいだ監査ログを横断クエリできません。SetIamPolicy の発生数をプロジェクト別に並べるとか、特定ユーザーの行動を全プロジェクトで追うといった分析はログ自体が1か所に集まっていることが前提になります。
集約 Sink で1か所にまとめ、そのバケットに Observability Analytics(旧称 Log Analytics)を有効化すると、Cloud Logging バケットにデータを置いた状態のまま BigQuery 側からも SQL で読み取れます。
Direct Routing で BigQuery にコピーする方式だと Cloud Logging と BigQuery の双方にデータが保管され、スキーマも独自の camelCase 短縮形になります。集約 + Observability Analytics ならデータの実体は Cloud Logging バケット1か所のみで、スキーマも標準形のままなので、特別な理由がなければこちらの方が扱いやすい印象です。
全体構成
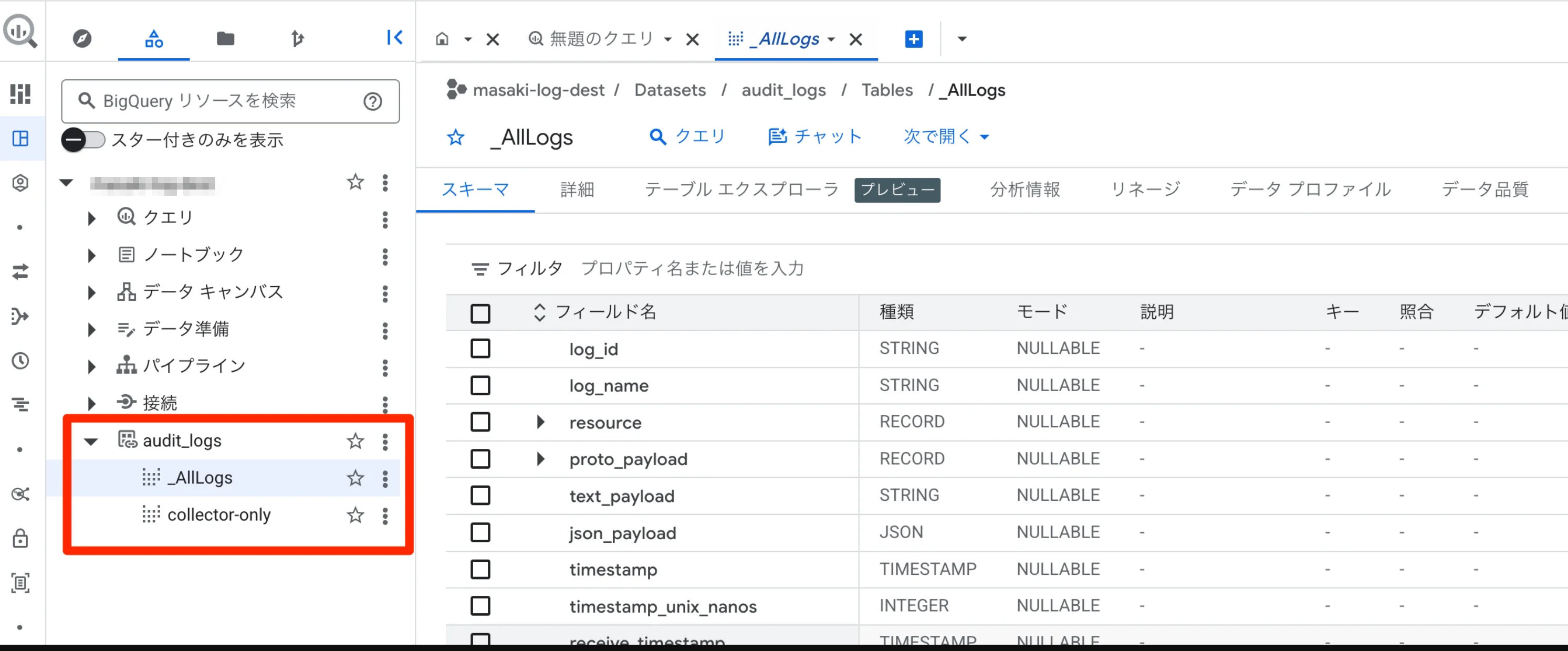
データの実体は集約先バケットの1か所だけです。BigQuery 側からは Linked Dataset 経由で _AllLogs を読みます。
前提
- 集約先プロジェクトが用意され、Cloud Logging API / BigQuery API が有効
- 集約対象スコープ(フォルダ or 組織)に対して作業者が
roles/logging.admin相当の権限を持つ - Terraform
hashicorp/googleプロバイダ v6 以降
検証は、masaki-lab フォルダ配下の3プロジェクト(集約先含む)を対象に、フォルダレベル Sink で実施しました。組織レベル Sink でも google_logging_folder_sink を google_logging_organization_sink に置き換えるだけで同じ構成になります。
Terraform 実装
作成するリソースは以下の5つです。
- Observability Analytics 有効化バケット
- Linked BigQuery Dataset
- 集約 Sink(フォルダ or 組織)
- Sink Writer Identity への IAM 付与
- Log View による読み取り絞り込み
Observability Analytics 有効化バケット
集約先となる Cloud Logging バケットを作ります。
resource "google_logging_project_bucket_config" "audit_logs" {
project = var.collector_project_id
location = var.location
bucket_id = "audit-logs"
retention_days = 30
enable_analytics = true
description = "監査ログ集約バケット(Observability Analytics 有効)"
}
enable_analytics = trueで Observability Analytics を有効化します- 不可逆操作です。一度
trueにするとfalseには戻せません。Terraform でfalseに書き換えてもバケットの状態は変わらないので注意してください - 取り消したい場合はバケットを削除するしか手段がなく、7日間
DELETE_REQUESTEDの soft delete 期間に入ります
Linked BigQuery Dataset
Cloud Logging バケットを BigQuery 側から読むための Linked Dataset を作ります。
resource "google_logging_linked_dataset" "audit_logs" {
link_id = "audit_logs"
parent = "projects/${var.collector_project_id}"
bucket = google_logging_project_bucket_config.audit_logs.id
location = var.location
description = "Linked dataset for audit-logs"
}
link_idがそのまま BigQuery dataset 名になります- BigQuery dataset の命名規則上、ハイフン (
-) は使えません。バケット名のハイフンをアンダースコアに置換した命名にしておくと分かりやすいです - 1バケットあたり Linked Dataset は1個までという制約があります
集約 Sink
集約対象スコープ(フォルダ or 組織)の監査ログを集約先バケットへルーティングする Sink を作ります。
resource "google_logging_folder_sink" "audit_to_bucket" {
name = "folder-audit-to-bucket"
folder = var.folder_id
destination = "logging.googleapis.com/projects/${var.collector_project_id}/locations/${var.location}/buckets/audit-logs"
filter = "logName:cloudaudit.googleapis.com"
include_children = true
}
include_children = trueでフォルダ配下のサブフォルダ・プロジェクトすべてが対象になります。デフォルトのfalseのままだと配下のプロジェクトのログが集まらないので、集約用途ではtrueを指定するのが一般的ですdestinationは集約先バケットのフルパス(logging.googleapis.com/projects/.../locations/.../buckets/...)filterを絞らないと全ログが流入してストレージコストが跳ね上がります。logName:cloudaudit.googleapis.comで監査ログだけに絞っておきます
組織レベルにする場合は google_logging_organization_sink を使い、folder の代わりに org_id を指定します。
resource "google_logging_organization_sink" "audit_to_bucket" {
name = "org-audit-to-bucket"
org_id = var.organization_id
destination = "logging.googleapis.com/projects/${var.collector_project_id}/locations/${var.location}/buckets/audit-logs"
filter = "logName:cloudaudit.googleapis.com"
include_children = true
}
Data Access ログは件数が大きくなりやすいので、必要でなければ Admin Activity のみに絞り込むなど、用途に応じて filter を調整するのが良いと思います。
フィルタ構文の詳細は Logging クエリ言語 を参照してください。
Sink Writer Identity への IAM 付与
集約 Sink を作ると Writer Identity が自動生成され、writer_identity 属性で参照できます。
これに集約先プロジェクトへの roles/logging.bucketWriter を付与しないとログが届きません。
resource "google_project_iam_member" "sink_writer" {
project = var.collector_project_id
role = "roles/logging.bucketWriter"
member = google_logging_folder_sink.audit_to_bucket.writer_identity
}
同一プロジェクト内のバケット宛て Sink (google_logging_project_sink + unique_writer_identity = false)は Writer Identity が None になり、Service Account を介さず書き込まれるため IAM 付与は要りません(参考: Set destination permissions)。
一方でフォルダ・組織 Sink は Writer Identity が必ず作られるため、明示的に bucketWriter を付与する必要があります。
Log View による読み取り絞り込み
集約管理者やセキュリティチームは _AllLogs を直接読んで全プロジェクトを横断分析すればよく、ここまでの構成だけでも横断分析環境としては成立しています。
一方で「開発チームには自分たちのプロジェクトの監査ログだけ見せたい」「Data Access ログは特定の役職にしか見せたくない」のように、役割ごとに見える範囲を切り分けたいケースでは Log View が役に立ちます。集約バケットの中に、フィルタで絞った仮想ビューを切り、ビュー単位で IAM を付ける構成です。
resource "google_logging_log_view" "project_a_only" {
name = "project-a-only"
bucket = google_logging_project_bucket_config.audit_logs.id
description = "project-a のログだけ閲覧可能にする View"
filter = "resource.labels.project_id = \"project-a\""
}
resource "google_logging_log_view_iam_member" "project_a_only_viewer" {
parent = "projects/${var.collector_project_id}"
location = var.location
bucket = google_logging_project_bucket_config.audit_logs.bucket_id
name = google_logging_log_view.project_a_only.name
role = "roles/logging.viewAccessor"
member = "user:viewer@example.com"
}
Terraform ファイル一式
ここまでで紹介した 5 リソースと、合わせて必要になる変数・プロバイダ定義を1つにまとめた Terraform 一式です。
main.tf / variables.tf / terraform.tf
resource "google_logging_project_bucket_config" "audit_logs" {
project = var.collector_project_id
location = var.location
bucket_id = "audit-logs"
retention_days = 30
enable_analytics = true
description = "監査ログ集約バケット(Observability Analytics 有効)"
}
resource "google_logging_linked_dataset" "audit_logs" {
link_id = "audit_logs"
parent = "projects/${var.collector_project_id}"
bucket = google_logging_project_bucket_config.audit_logs.id
location = var.location
description = "Linked dataset for audit-logs"
}
resource "google_logging_folder_sink" "audit_to_bucket" {
name = "folder-audit-to-bucket"
folder = var.folder_id
destination = "logging.googleapis.com/projects/${var.collector_project_id}/locations/${var.location}/buckets/${google_logging_project_bucket_config.audit_logs.bucket_id}"
filter = "logName:cloudaudit.googleapis.com"
include_children = true
}
resource "google_project_iam_member" "sink_writer" {
project = var.collector_project_id
role = "roles/logging.bucketWriter"
member = google_logging_folder_sink.audit_to_bucket.writer_identity
}
resource "google_logging_log_view" "project_a_only" {
name = "project-a-only"
bucket = google_logging_project_bucket_config.audit_logs.id
description = "project-a のログだけ閲覧可能にする View"
filter = "resource.labels.project_id = \"project-a\""
}
resource "google_logging_log_view_iam_member" "project_a_only_viewer" {
count = var.log_view_viewer == null ? 0 : 1
parent = "projects/${var.collector_project_id}"
location = var.location
bucket = google_logging_project_bucket_config.audit_logs.bucket_id
name = google_logging_log_view.project_a_only.name
role = "roles/logging.viewAccessor"
member = var.log_view_viewer
}
variable "collector_project_id" {
description = "集約先プロジェクト ID(バケット・Linked Dataset の置き場)"
type = string
}
variable "folder_id" {
description = "集約対象フォルダ ID(数値のみ)"
type = string
}
variable "location" {
description = "Cloud Logging バケット location"
type = string
default = "asia-northeast1"
}
variable "log_view_viewer" {
description = "Log View へのアクセスを許可するメンバー(例: user:foo@example.com, group:team@example.com)"
type = string
default = null
}
terraform {
required_version = ">= 1.15"
required_providers {
google = {
source = "hashicorp/google"
version = "~> 6.0"
}
}
}
やってみた
Terraform 適用
terraform apply で5つのリソースを作成します。
$ terraform apply -auto-approve
...
google_logging_project_bucket_config.audit_logs: Creation complete after 1m57s
google_logging_folder_sink.audit_to_bucket: Creation complete after 2s
google_logging_log_view.collector_only: Creation complete after 6s
google_project_iam_member.sink_writer: Creation complete after 8s
google_logging_linked_dataset.audit_logs: Creation complete after 1m57s
Apply complete! Resources: 5 added, 0 changed, 0 destroyed.
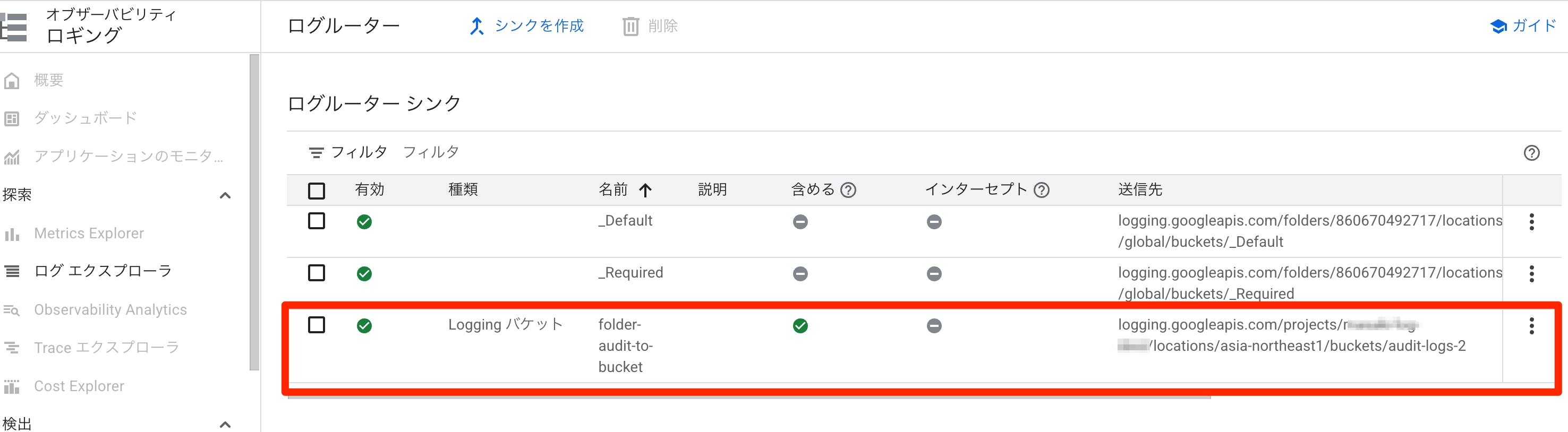
監査ログを発生させる
フォルダ配下のプロジェクト2つで SA の作成・削除を行って Admin Activity ログを発生させます。
for P in project-a project-b; do
gcloud iam service-accounts create test-trigger --project=${P}
gcloud iam service-accounts delete test-trigger@${P}.iam.gserviceaccount.com \
--project=${P} --quiet
done
BigQuery 経由でクエリ
Sink Writer Identity への IAM 設定の反映には少し時間がかかります。検証では、apply 直後に発生させたログは届かず、3分ほど待ってから再度ログを発生させたら集約先バケットに流入しました。
プロジェクト別の Activity ログ件数を取ります。Observability Analytics 経由の _AllLogs では resource.labels が JSON 型なので、文字列として扱うときは JSON_VALUE で取り出します。
SELECT
JSON_VALUE(resource.labels.project_id) AS project,
proto_payload.audit_log.method_name AS method,
COUNT(*) AS call_count
FROM `<COLLECTOR_PROJECT>.audit_logs._AllLogs`
WHERE timestamp >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)
AND log_id = 'cloudaudit.googleapis.com/activity'
AND proto_payload.audit_log.method_name LIKE '%ServiceAccount%'
GROUP BY project, method
ORDER BY call_count DESC
+-----------+------------------------------------------+------------+
| project | method | call_count |
+-----------+------------------------------------------+------------+
| project-a | google.iam.admin.v1.CreateServiceAccount | 2 |
| project-a | google.iam.admin.v1.DeleteServiceAccount | 2 |
| project-b | google.iam.admin.v1.CreateServiceAccount | 1 |
| project-b | google.iam.admin.v1.DeleteServiceAccount | 1 |
+-----------+------------------------------------------+------------+
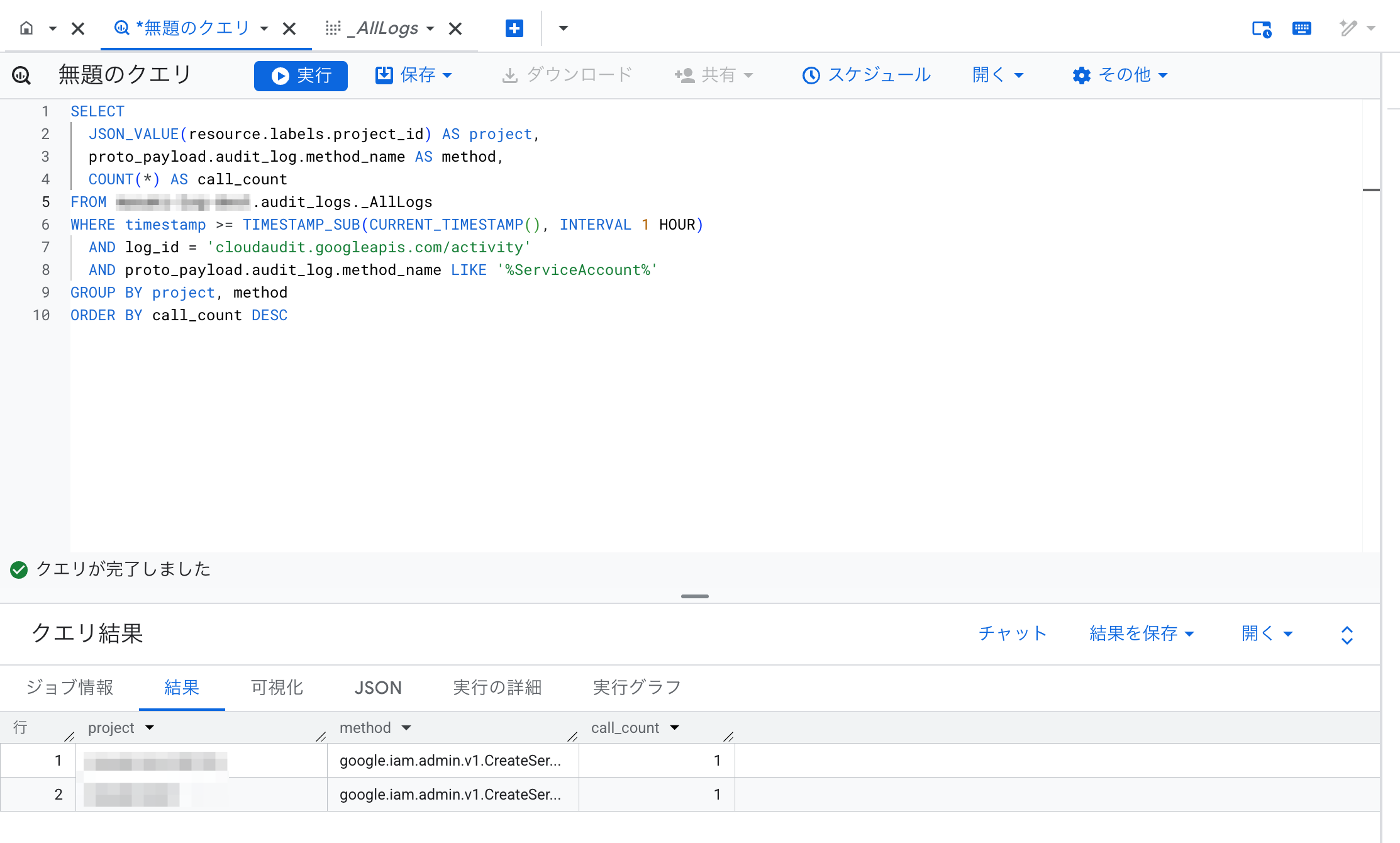
両プロジェクトの監査ログが集約先1か所に集まり、JSON_VALUE(resource.labels.project_id) で GROUP BY できました。
特定ユーザーの行動を全プロジェクト横断で並べたいときも同じテーブル1つで済みます。
SELECT
timestamp,
JSON_VALUE(resource.labels.project_id) AS project,
proto_payload.audit_log.method_name AS method
FROM `<COLLECTOR_PROJECT>.audit_logs._AllLogs`
WHERE timestamp >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)
AND proto_payload.audit_log.authentication_info.principal_email
= 'user@example.com'
AND proto_payload.audit_log.method_name LIKE '%ServiceAccount%'
ORDER BY timestamp DESC
+---------------------+-----------+------------------------------------------+
| timestamp | project | method |
+---------------------+-----------+------------------------------------------+
| 2026-05-20 00:25:22 | project-a | google.iam.admin.v1.DeleteServiceAccount |
| 2026-05-20 00:25:20 | project-a | google.iam.admin.v1.CreateServiceAccount |
| 2026-05-20 00:25:19 | project-b | google.iam.admin.v1.DeleteServiceAccount |
| 2026-05-20 00:25:17 | project-b | google.iam.admin.v1.CreateServiceAccount |
+---------------------+-----------+------------------------------------------+
おわりに
集約 Sink から Observability Analytics・Linked Dataset・Log View まで Terraform で構築しました。
組織配下の監査ログを BigQuery で横断 SQL 分析できる基盤がそのまま立ち上がりました。
Sink 側は include_children と Writer Identity への bucketWriter 付与の2点を押さえれば、あとはバケット側の構成は単一プロジェクトのケースと同じです。









