
Cloudflare Logpush から BigQuery へ直接ログを配信できるようになりました(ただし legacy streaming API)
ウィスキー、シガー、パイプをこよなく愛する大栗です。
Cloudflare Logpush が Google BigQuery へのネイティブ配信に対応しました!以前は Google Cloud Storage を経由して BigQuery へ取り込む構成が必要でしたが、直接 BigQuery へストリーミングできるようになっています。
以前の構成 (GCS 経由)
以前のエントリ「Cloudflare の DNS ログを BigQuery のテキスト検索機能で分析してみる」でも紹介しましたが、2022年の時点では Cloudflare Logpush は BigQuery に対応していませんでした。
そのため Cloudflare 社が OSS として提供している logpush-to-bigquery ツールを使って、以下のような構成でログを BigQuery に取り込む必要がありました。
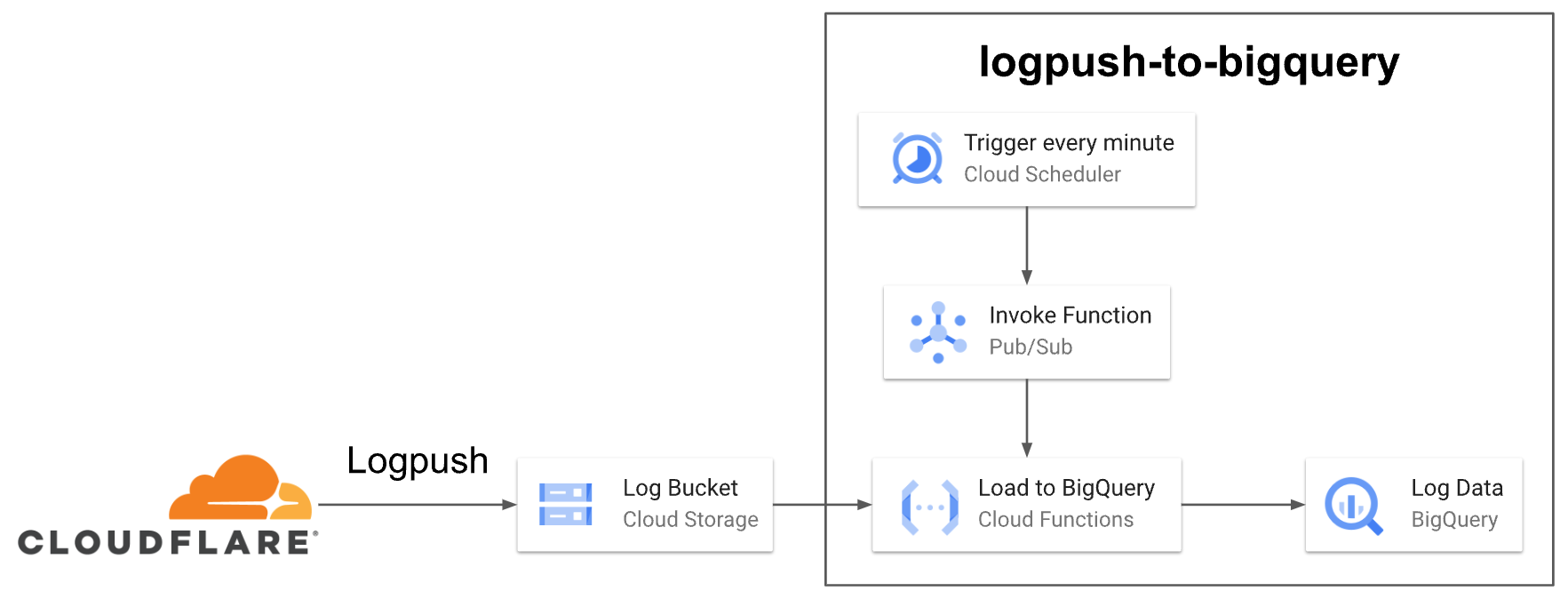
この構成は動作するものの、Cloud Storage、Cloud Scheduler、Pub/Sub、Cloud Functions と複数のサービスを組み合わせる必要があり、構築や運用のコストがかかるものでした。
ネイティブ BigQuery 配信
2026年4月2日のアップデートで、Cloudflare Logpush が BigQuery をネイティブの送信先としてサポートしました。これにより構成が大幅にシンプルになります。
Cloudflare Logpush → BigQuery(Streaming Insert)
中間のサービスが不要になり、Cloudflare から直接 BigQuery にログがストリーミングされます。
使用される API
Logpush は BigQuery の Legacy Streaming API(tabledata.insertAll) を使用します。新しい Storage Write API ではない点に注意が必要です。
Legacy Streaming API と Storage Write API の主な違いは以下の通りです。
| 項目 | Legacy Streaming API(insertAll) | Storage Write API |
|---|---|---|
| プロトコル | REST over HTTP(JSON) | gRPC(Protocol Buffers / Apache Arrow) |
| 無料枠 | なし | 月 2 TiB まで無料 |
| 料金 | $0.012 / 200 MB | $0.03 / GiB (毎月最初の 2TiB は無料) |
| exactly-once | 非保証(ベストエフォート) | サポート |
| Cloudflare Logpush | 対応(今回のアップデート) | 非対応 |
Legacy Streaming API が使われるため、Storage Write API の無料枠(月 2 TiB)は適用されません。
他の送信先との違い
S3、GCS、Azure への Logpush では、送信先バケットの所有権を確認するための ownership challenge が必要です。BigQuery への配信では ownership challenge が不要 です。サービスアカウントの認証情報で直接アクセスするため、セットアップがよりシンプルになっています。
制限事項
BigQuery Streaming Insert のクォータ制限に注意が必要です。
| 制限 | 値 |
|---|---|
| HTTP リクエストサイズ上限(非圧縮) | 10 MB |
| 行サイズ上限 | 10 MB |
| リクエストあたり最大行数 | 50,000 行 |
Logpush ジョブの max_upload_bytes と max_upload_records を BigQuery のクォータに合わせて調整してください。デフォルトの設定例では max_upload_bytes を 5,000,000(5 MB)、max_upload_records を 50,000 に設定しています。
クォータが不足する場合は、Google Cloud Console の IAM & Admin > Quotas ページから引き上げをリクエストできます。
やってみる
実際に Cloudflare Workers のログを Logpush 経由で BigQuery へ配信してみます。Workers Trace Events のログには console.log() の出力やキャッチされなかった例外が含まれるため、Workers のデバッグや分析に有用です。
前提条件
- Cloudflare Workers Paid プラン(Workers Trace Events Logpush が利用可能)
- Google Cloud プロジェクト
- Cloudflare API トークン(アカウントレベルの
Logs Edit権限)
BigQuery の準備
BigQuery にログを格納するデータセットとテーブルを作成します。gcloud CLI と bq コマンドを使用します。
$ PROJECT_ID=<PROJECT_ID>
$ DATASET_ID=cloudflare_logs
$ TABLE_ID=workers_trace_events
Workers Trace Events のスキーマファイル schema.json を用意してテーブルを作成します。Workers Trace Events のデータセット定義に基づくフィールドは以下の通りです。
| フィールド名 | Cloudflare の型 | BigQuery の型 | 説明 |
|---|---|---|---|
| CPUTimeMs | int | INTEGER | CPU 使用時間(ミリ秒) |
| DispatchNamespace | string | STRING | Worker の dispatch namespace |
| Entrypoint | string | STRING | Worker の実行開始エントリーポイントクラス名 |
| Event | object | STRING | ソースイベントの詳細 |
| EventTimestampMs | int | INTEGER | イベント受信時刻(ミリ秒) |
| EventType | string | STRING | イベント種別(fetch 等) |
| Exceptions | array[object] | STRING | キャッチされなかった例外の一覧 |
| Logs | array[object] | STRING | console.log() の出力一覧 |
| Outcome | string | STRING | 実行結果(ok または exception) |
| ScriptName | string | STRING | Worker スクリプト名 |
| ScriptTags | array[string] | STRING | Worker を分類するユーザー定義タグ |
| ScriptVersion | object | STRING | 呼び出されたスクリプトのバージョン情報 |
| WallTimeMs | int | INTEGER | Worker の実行経過時間(ミリ秒)。waitUntil() の処理時間を含む |
Event、Exceptions、Logs、ScriptTags、ScriptVersion は Cloudflare 側では object や array 型です。ドキュメントによると、Logpush の output_options で stringify_object: true を設定すれば JSON 文字列としてシリアライズされるとなっていますが、上手くシリアライズされなかったため今回は対象外のフィールドとします。
schema.json は以下の通りです。
[
{
"name": "CPUTimeMs",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "DispatchNamespace",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "Entrypoint",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "EventTimestampMs",
"type": "INTEGER",
"mode": "NULLABLE"
},
{
"name": "EventType",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "Outcome",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "ScriptName",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "WallTimeMs",
"type": "INTEGER",
"mode": "NULLABLE"
}
]
スキーマファイルを用意したら、テーブルを作成します。
$ bq mk --table "${PROJECT_ID}:${DATASET_ID}.${TABLE_ID}" schema.json
Table '{PROJECT_ID}:cloudflare_logs.workers_trace_events' successfully created.
サンプル Workers の準備
サンプルの Workers を構成します。
$ npm create cloudflare@latest -- sample-worker
確認される内容は以下の内容で設定しています。
What would you like to start with?:Hello World exampleWhich template would you like to use?:Worker onlyWhich language do you want to use?:JavaScriptDo you want to add an AGENTS.md file to help AI coding tools understand Cloudflare APIs?:NoDo you want to use git for version control?:NoDo you want to deploy your application?:No
作成されたディレクトリに移動します。
$ cd sample-worker
ログを収集する Worker で Logpush を有効にする必要があります。wrangler.jsonc で "logpush": true を追加します。
{
"$schema": "node_modules/wrangler/config-schema.json",
"name": "sample-worker",
"main": "src/index.js",
"compatibility_date": "2026-04-08",
"logpush": true,
"observability": {
"enabled": true,
},
"upload_source_maps": true,
"compatibility_flags": ["nodejs_compat"],
}
設定後に wrangler deploy で Worker をデプロイしてください。
$ wrangler deploy
⛅️ wrangler 4.54.0 (update available 4.81.0)
─────────────────────────────────────────────
Total Upload: 20.36 KiB / gzip: 4.90 KiB
Worker Startup Time: 16 ms
Uploaded sample-worker (5.36 sec)
Deployed sample-worker triggers (4.55 sec)
https://sample-worker.abcd1234.workers.dev
Current Version ID: 12345678-abcd-1234-abcd-abcd1234ef56
Logpush の設定
Google Cloud サービスアカウントの作成
Google Cloud Console で、Logpush 用のサービスアカウントを作成します。
IAM と管理 > サービス アカウント に移動して、+ サービス アカウントを作成 をクリックします。
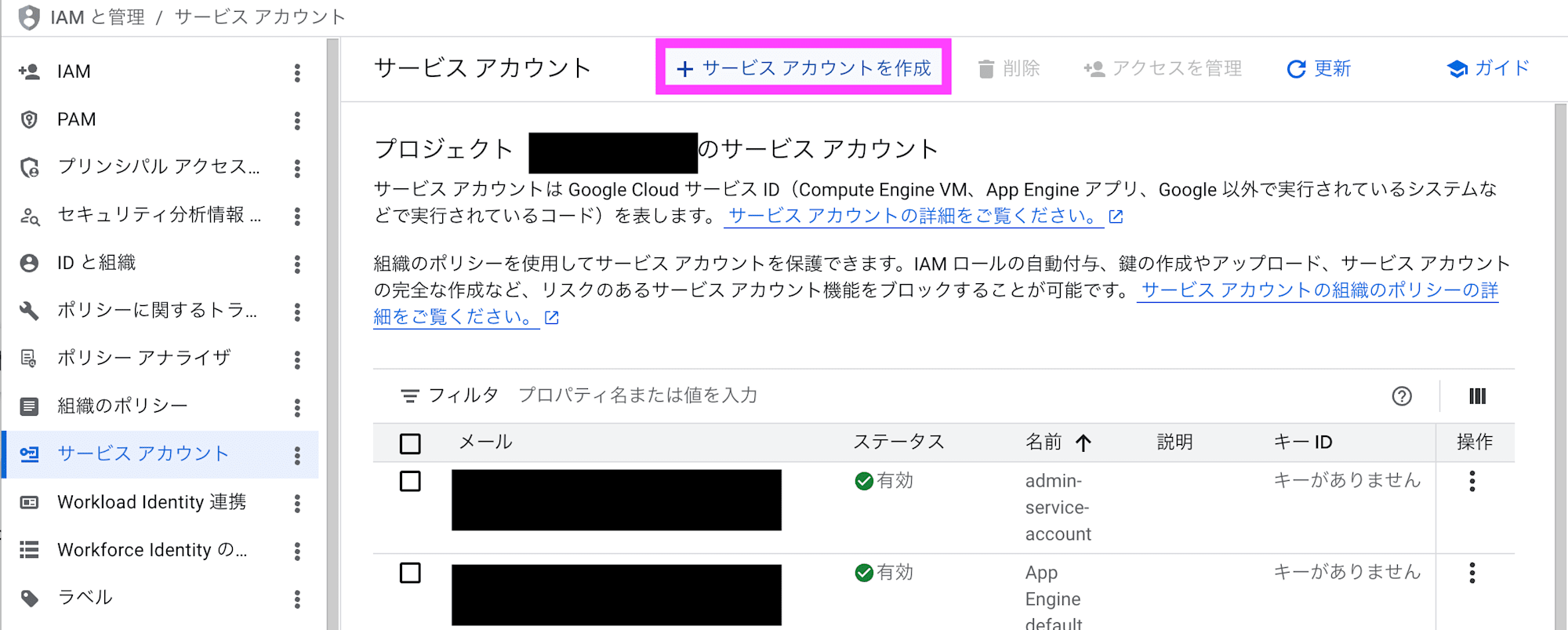
サービス アカウント名、サービス アカウント ID、サービス アカウントの説明を入力して作成して続行をクリックします。
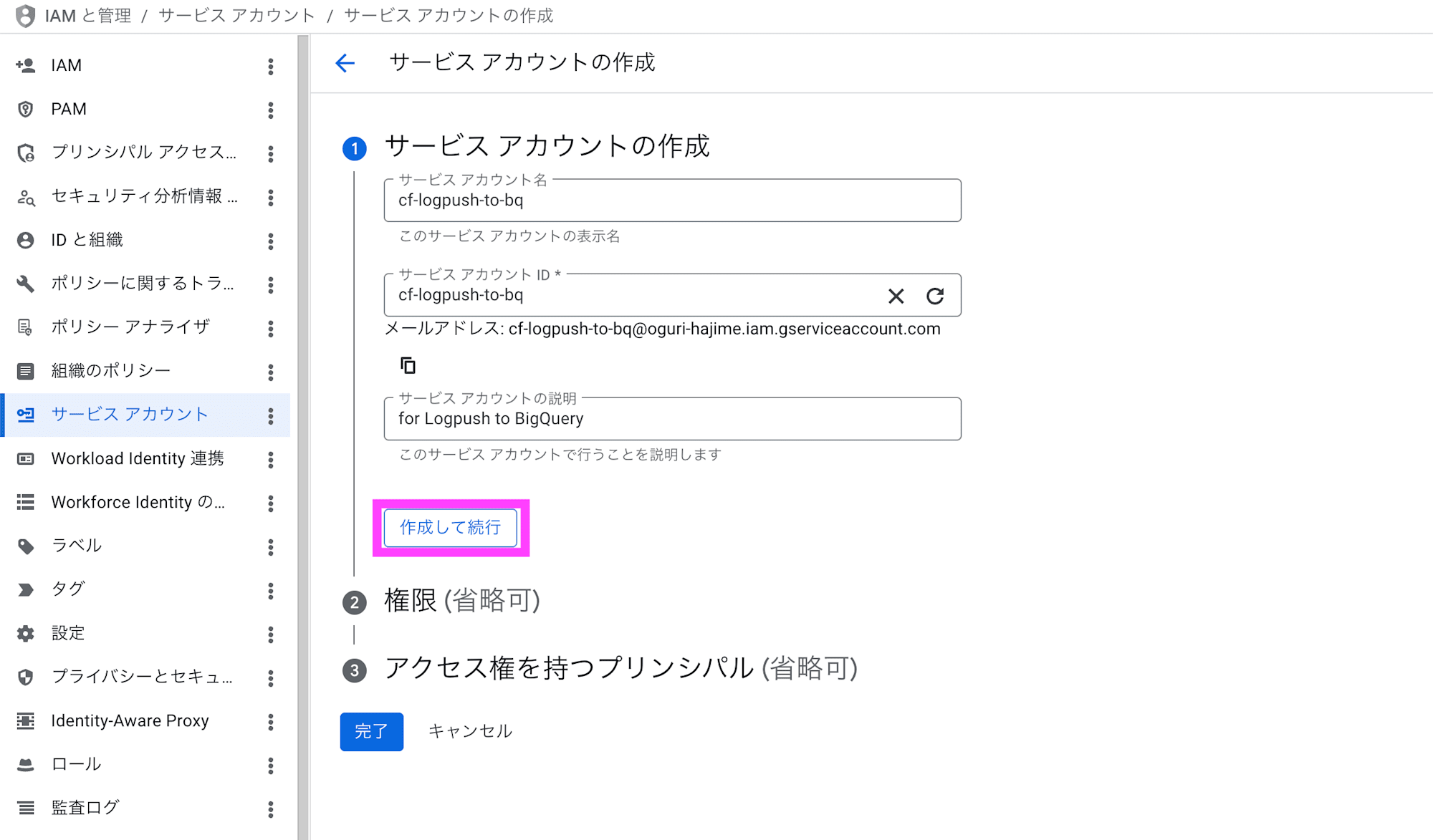
ロールでBigQuery データ編集者を選択して完了をクリックします。
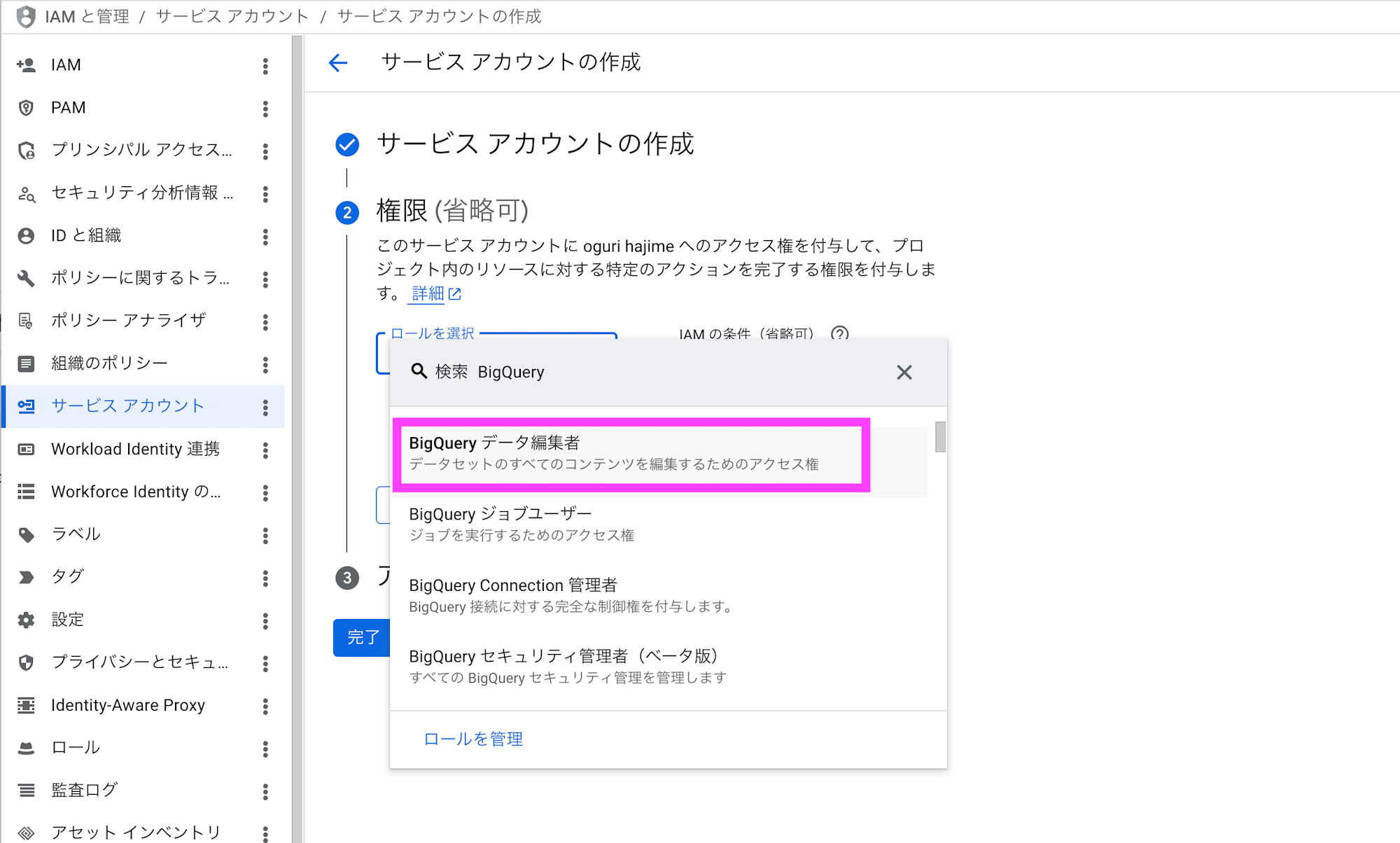
作成したサービス アカウントを選択して、鍵タブから新しい鍵を作成をクリックします。
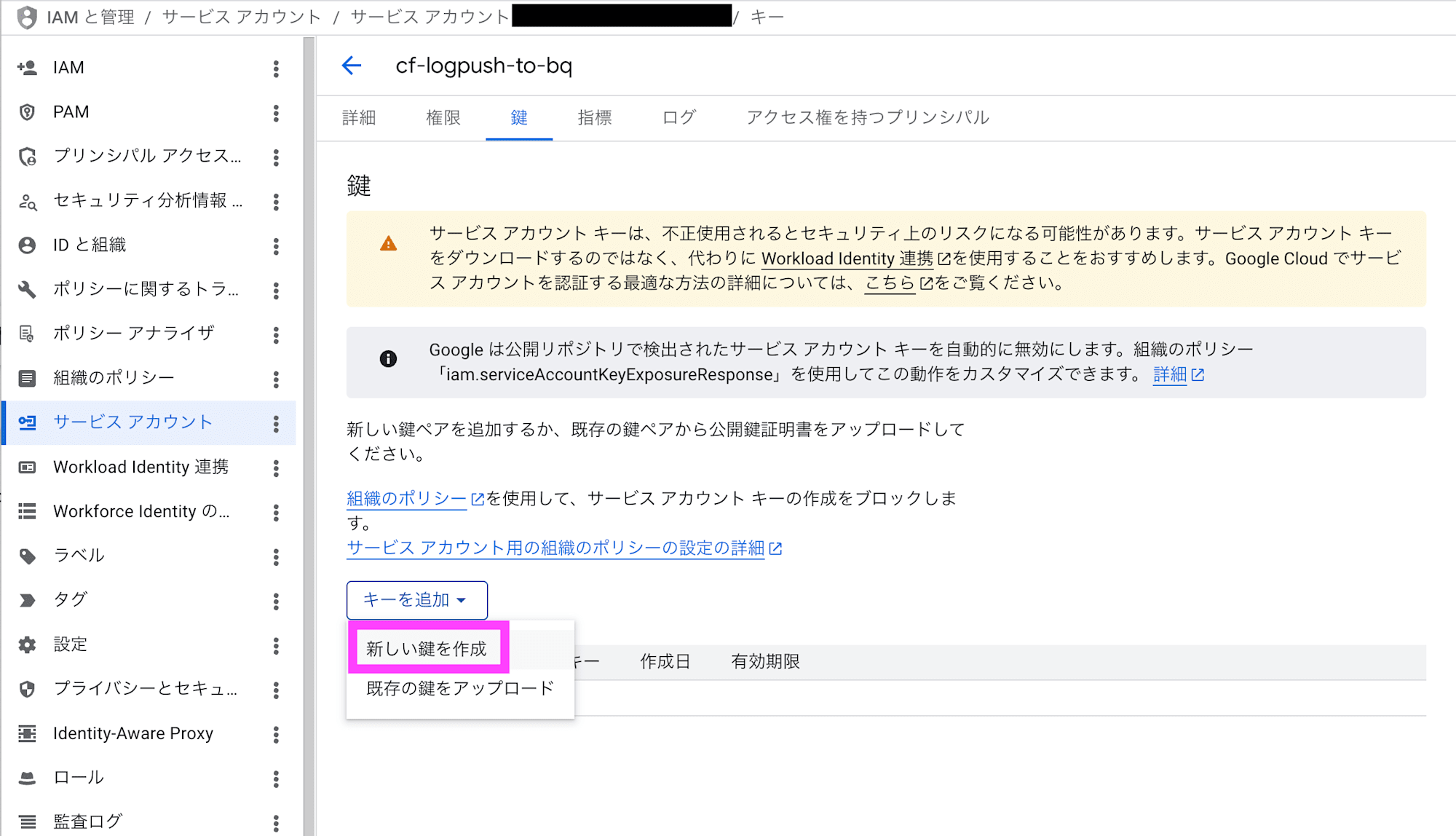
キータイプでJSONを選択して作成をクリックします。

秘密鍵が保存されます。

認証情報のエンコード
ダウンロードしたサービスアカウントの JSON キーを Base64 エンコードします。
$ cat /path/to/service-account-key.json | base64
エンコードされた値を destination_conf の credentials パラメータに使用します。
Logpush ジョブの作成
Cloudflare API を使って Logpush ジョブを作成します。Workers Trace Events はアカウントレベルのデータセットのため、エンドポイントは accounts/$ACCOUNT_ID を使用します(ゾーンレベルの zones/$ZONE_ID ではありません)。
$ curl "https://api.cloudflare.com/client/v4/accounts/$ACCOUNT_ID/logpush/jobs" \
--request POST \
--header "Authorization: Bearer $CLOUDFLARE_API_TOKEN" \
--json '{
"name": "workers-logpush-bigquery",
"destination_conf": "bq://projects/<PROJECT_ID>/datasets/<DATASET_ID>/tables/<TABLE_ID>?credentials=base64:<ENCODED_VALUE>",
"output_options": {
"field_names": [
"CPUTimeMs",
"DispatchNamespace",
"Entrypoint",
"EventTimestampMs",
"EventType",
"Outcome",
"ScriptName",
"WallTimeMs"
],
"timestamp_format": "rfc3339",
"stringify_object": true
},
"max_upload_bytes": 5000000,
"max_upload_records": 50000,
"dataset": "workers_trace_events",
"enabled": true
}'
destination_conf のフォーマットは以下の通りです。
bq://projects/<PROJECT_ID>/datasets/<DATASET_ID>/tables/<TABLE_ID>?credentials=<ENCODED_VALUE>
credentials の値には以下の2つのエンコード方式が使用できます。
| エンコード方式 | プレフィックス | 例 |
|---|---|---|
| Base64 | base64: |
credentials=base64:eyJhbGci... |
| URL エンコード | url: |
credentials=url:%7B%22type%22... |
レスポンスの確認
正常に作成されると以下のようなレスポンスが返ります。
{
"errors": [],
"messages": [],
"result": {
"id": <JOB_ID>,
"dataset": "workers_trace_events",
"frequency": "high",
"kind": "",
"max_upload_bytes": 5000000,
"max_upload_records": 50000,
"enabled": true,
"name": "workers-logpush-bigquery",
"output_options": {
"field_names": [
"CPUTimeMs",
"DispatchNamespace",
"Entrypoint",
"EventTimestampMs",
"EventType",
"Outcome",
"ScriptName",
"WallTimeMs"
],
"timestamp_format": "rfc3339",
"stringify_object": true
},
"destination_conf": "bq://projects/<PROJECT_ID>/datasets/<DATASET_ID>/tables/<TABLE_ID>?credentials=<ENCODED_VALUE>",
"last_complete": null,
"last_error": null,
"error_message": null,
"time_created": "2026-04-08T08:36:13Z"
},
"success": true
}
ジョブの作成時に、Cloudflare は空のデータでテストアップロードを行い、BigQuery への書き込みが可能かを検証します。そのため BigQuery テーブルに空データの行が1行挿入される場合があります。
特定の Worker のログだけを収集したい場合や、例外が発生したリクエストのみを対象にしたい場合は、Logpush のフィルター機能を使用できます。
Workers の URL に何度かアクセスしてから BigQuery でデータを確認してみるとログが保存されています。
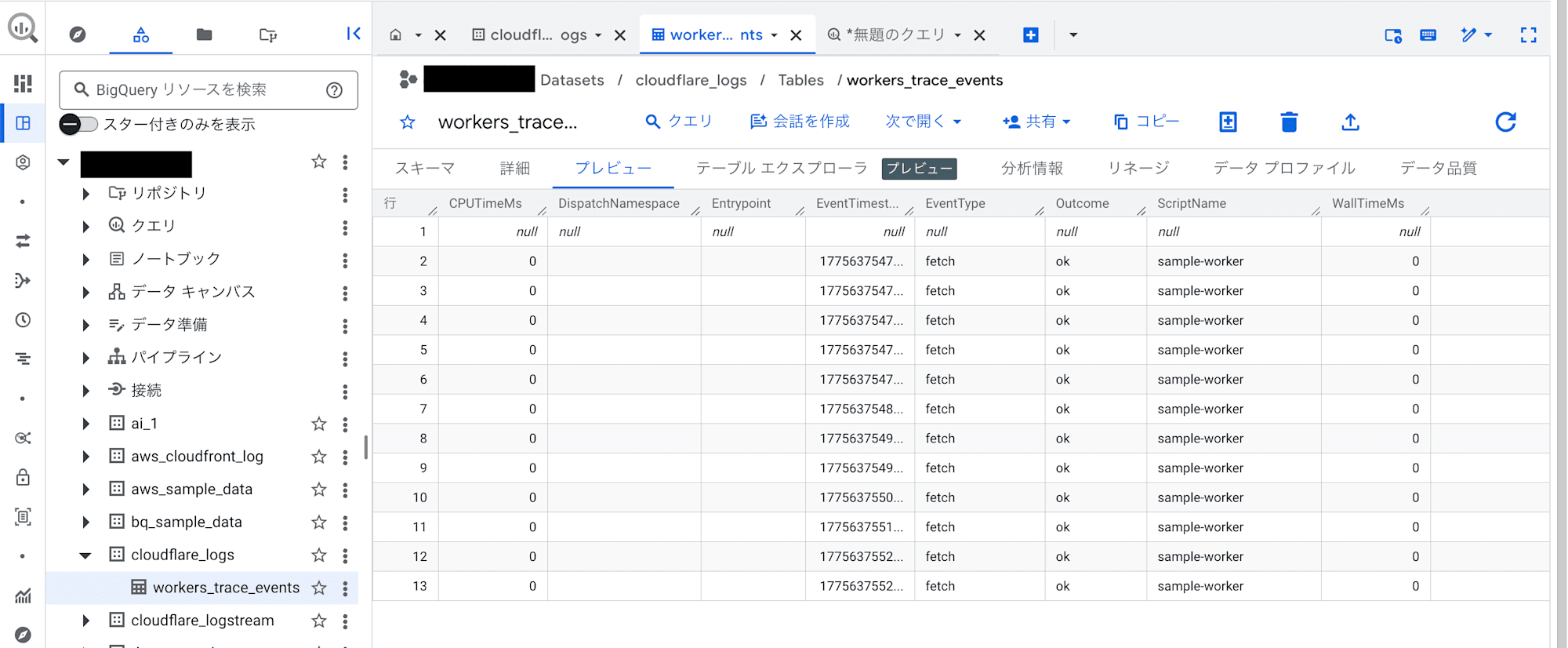
さいごに
2022年に Cloudflare のログを BigQuery で分析するエントリを書いた際には、Cloud Storage、Cloud Scheduler、Pub/Sub、Cloud Functions と複数のサービスを組み合わせる必要がありました。今回のネイティブ対応により、Cloudflare から直接 BigQuery へログをストリーミングできるようになり、構成が大幅にシンプルになりました。
ただし、使用される API は Legacy Streaming API(tabledata.insertAll)であり、新しい Storage Write API ではありません。Storage Write API であれば月 2 TiB の無料枠が利用できるため、大量のログを扱う場合にはコスト面で差が出ます。
とはいえ、中間サービスの構築・運用が不要になるメリットは大きく、Cloudflare のログを BigQuery で分析したいケースでは積極的に活用していきたいと思います。今回試した Workers Trace Events のように console.log() の出力や例外情報を BigQuery に蓄積できるのは、Workers の運用やデバッグにおいて心強い選択肢です。将来的に Storage Write API への対応も期待したいです。
Logpush の output_options で stringify_object を有効化したときの対応はどこかで確認したいです。







