Comparing two datasets for similarities or differences in schema using Alteryx
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Introduction:
Often a developer needs to compare different versions of a dataset for testing workflows or dashboards. Such as comparing a production dataset versus a UAT. Spotting the differences in schemas of datasets is critical when handling the data processing and visualization reports. Using Alteryx it is very easy to spot differences (or similarities) in schemas between two targeted datasets.
How to Achieve it:
Let us begin with two datasets having different schemas as shown below.


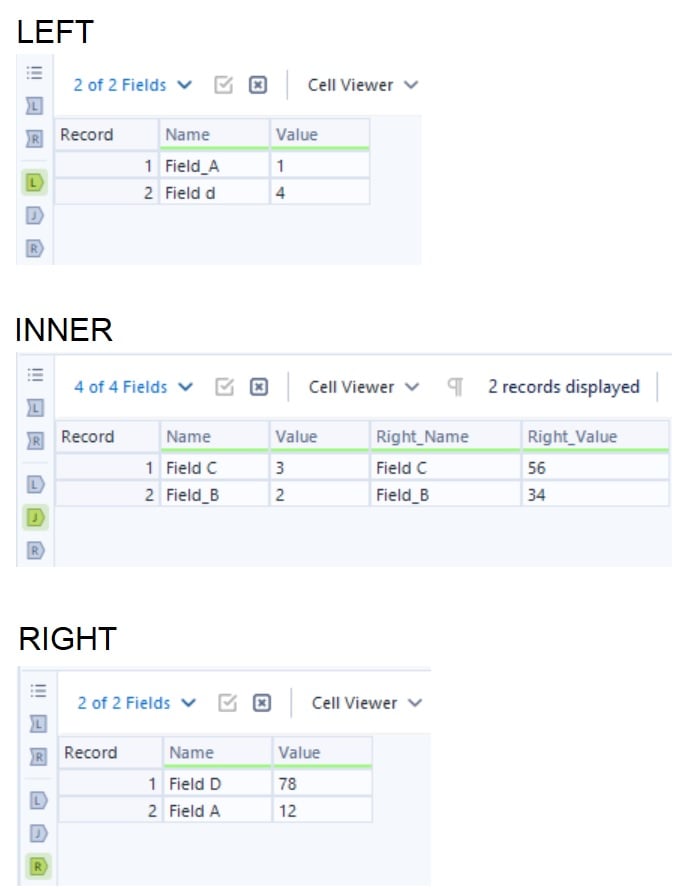
At a glance, one can notice that column names are not consistent. However, comparing very large datasets it is not practical to manually compare each column name for consistency. So Alteryx comes in handy. Connect the datasets in Alteryx and use Sample tools to bring just one row of data per dataset.

Now connect to the Transpose tools with their default configurations to transpose all the columns. Finally just use the Join tool and configure it to join on the “Name” field as shown below.


The matched fields can be distinguished from the unmatched fields. Thus the schema of two datasets can be compared and modified if needed. This technique can be very helpful especially when the column names are case sensitive or with minor typos.
Summary:
Large datasets can be easily compared for their schemas using Alteryx.









