
【アップデート】Compute Engine MIG に自動スケーリングイベントの個別監視機能が Preview でリリースされました
はじめに
こんにちは。
クラウド事業本部コンサルティング部の渡邉です。
2026年4月29日、Compute Engine のマネージドインスタンスグループ(MIG)において、個別の自動スケーリングイベントを監視する機能 が Preview としてリリースされました。
これまで MIG の Monitoring タブではグループサイズの推移やオートスケーラーの利用率をグラフで確認できましたが、「いつ・なぜスケールしたのか」をイベント単位で掘り下げるのは容易ではありませんでした。今回の機能追加により、スケールイン・スケールアウトの各イベントの詳細(スケーリングシグナルの種類・実測値・目標値・制約)をコンソール上でひと目で確認できるようになっています。
今回は、この機能の概要と確認できる情報、そして実際の操作手順を見ていきたいと思います。
MIG の自動スケーリングとは
マネージドインスタンスグループ(MIG)は、同一のインスタンステンプレートから作成された VM インスタンスの集合です。オートスケーラーを設定することで、負荷状況に応じてグループ内の VM 数を自動的に増減できます。
スケーリングのシグナルとして、以下を指定できます。
| シグナル | 概要 |
|---|---|
| CPU 使用率 | グループ全体の平均 CPU 使用率 |
| HTTP ロードバランシングの処理能力 | バックエンドの処理能力(RPS・利用率) |
| Cloud Monitoring メトリクス | Pub/Sub のキュー長やカスタムメトリクスなど任意の指標 |
| スケジュール | 事前定義したスケジュールに基づくキャパシティ確保 |
オートスケーラーは設定されたシグナルごとに推奨サイズを計算し、最大値をターゲットサイズとして適用します。スケールイン・スケールアウトには安定化期間(直近10分のピーク)が考慮されるため、急激な負荷変動に対して過剰にスケールしないよう調整されます。
個別スケーリングイベントの監視
今回追加されたのは、MIG の Monitoring タブにある 「グループサイズ」チャートへのイベントタイムラインの追加です。
このタイムラインにはスケールイン・スケールアウトのイベントがブロックとして表示されます。各イベントブロックをホバーすると、以下の詳細情報を含むカードが表示されます。
| 項目 | 内容 |
|---|---|
| タイムスタンプ | イベントの発生タイムスタンプ |
| イベントの種類とサイズ | スケールインまたはスケールアウト、変更前後の VM 数(例: 6 VMs → 1 VM) |
| スケーリングシグナル | スケーリングをトリガーしたシグナル(例: CPU 使用率) |
| シグナル実測値 | シグナルの実測値 |
| シグナル目標値 | シグナルの目標値 |
| 算出サイズ | シグナルの目標値を達成するためにオートスケーラーが算出した VM 数 |
| 制約 | 新しいサイズを制約した設定(例: 最小・最大インスタンス数)。制約がない場合は表示されない |
イベントのグループ化
表示している時間範囲によっては、近接するイベントがまとめて表示されることがあります。この場合、タイムライン上のブロックに「5 events」のように件数が表示されます。個別のイベントを確認するには、グラフ上でドラッグしてズームインするか、カード内の「View events」をクリックします。
なお、グラフのメトリクスは1分ごとにサンプリングされるため、タイムライン上のイベント表示よりもグラフのデータが最大90秒遅延することがあります。
実際に確認してみた
前提条件
- Google Cloud プロジェクトで Compute Engine API が有効化されていること
gcloudCLI がインストール・認証済みであること- 以下の IAM ロールがあること
roles/compute.networkAdmin(VPC・サブネット・ファイアウォール・Cloud Router・Cloud NAT の管理)roles/compute.instanceAdmin.v1(インスタンステンプレート・MIG・オートスケーラーの管理)
ハンズオン環境の構築
以降のコマンドで使用する変数を設定します。環境に合わせて書き換えてください。
PROJECT_ID=your-project-id
REGION=asia-northeast1
ZONE=asia-northeast1-b
1. VPC ネットワークとサブネットの作成
カスタムモードで VPC ネットワークを作成し、asia-northeast1 にサブネットを追加します。
gcloud compute networks create mig-demo-vpc \
--subnet-mode=custom \
--project=${PROJECT_ID}
gcloud compute networks subnets create mig-demo-subnet \
--network=mig-demo-vpc \
--region=${REGION} \
--range=10.0.0.0/24 \
--project=${PROJECT_ID}
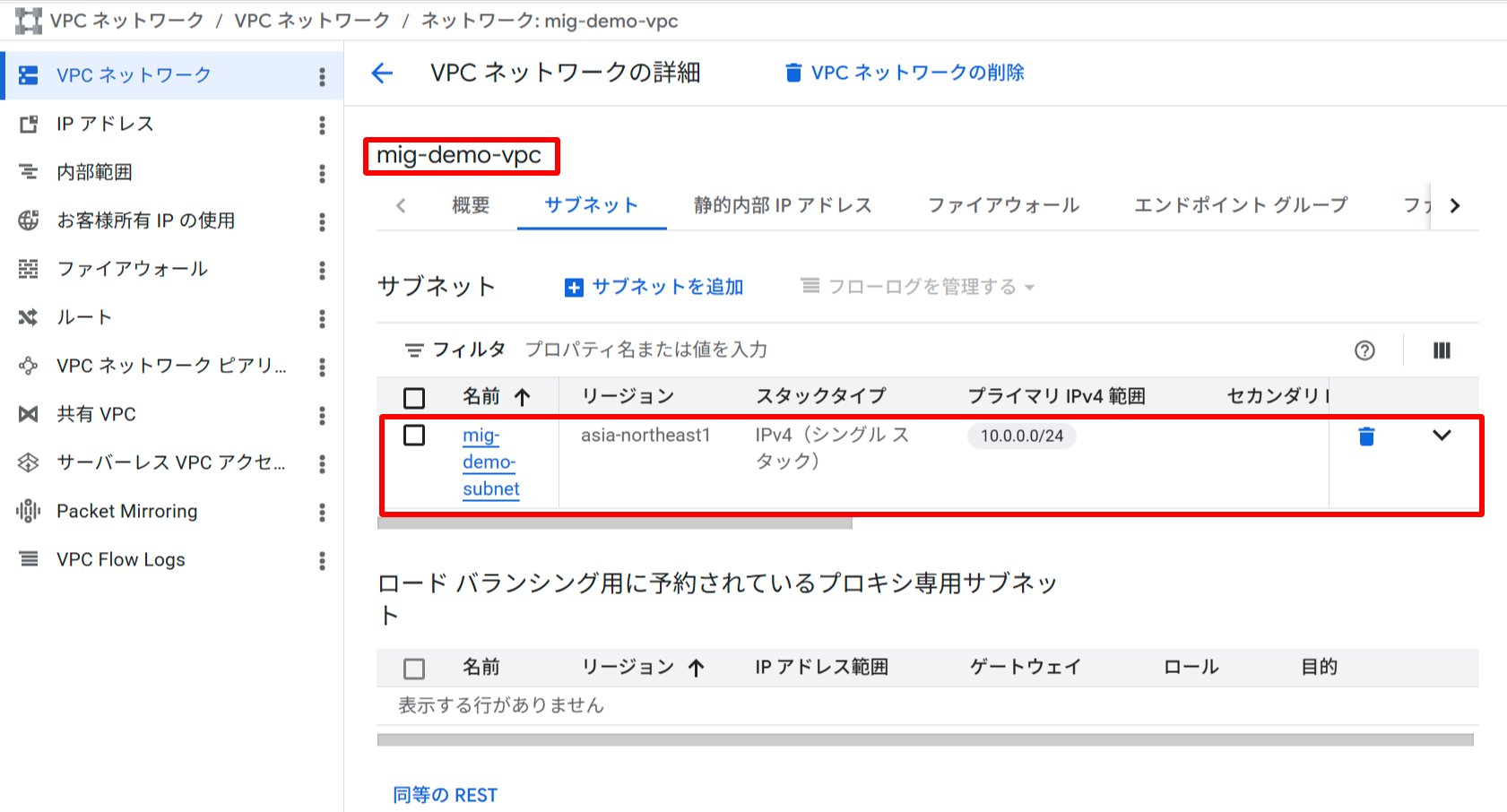
作成した VPC ネットワーク(mig-demo-vpc)とサブネット(mig-demo-subnet)
2. ファイアウォールルールの作成
外部 IP を持たない VM への SSH は IAP TCP 転送経由で行います。IAP が使用する IP レンジ(35.235.240.0/20)からのポート 22 への通信を許可するルールを作成します。
gcloud compute firewall-rules create mig-demo-allow-ssh-iap \
--network=mig-demo-vpc \
--direction=INGRESS \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--project=${PROJECT_ID}
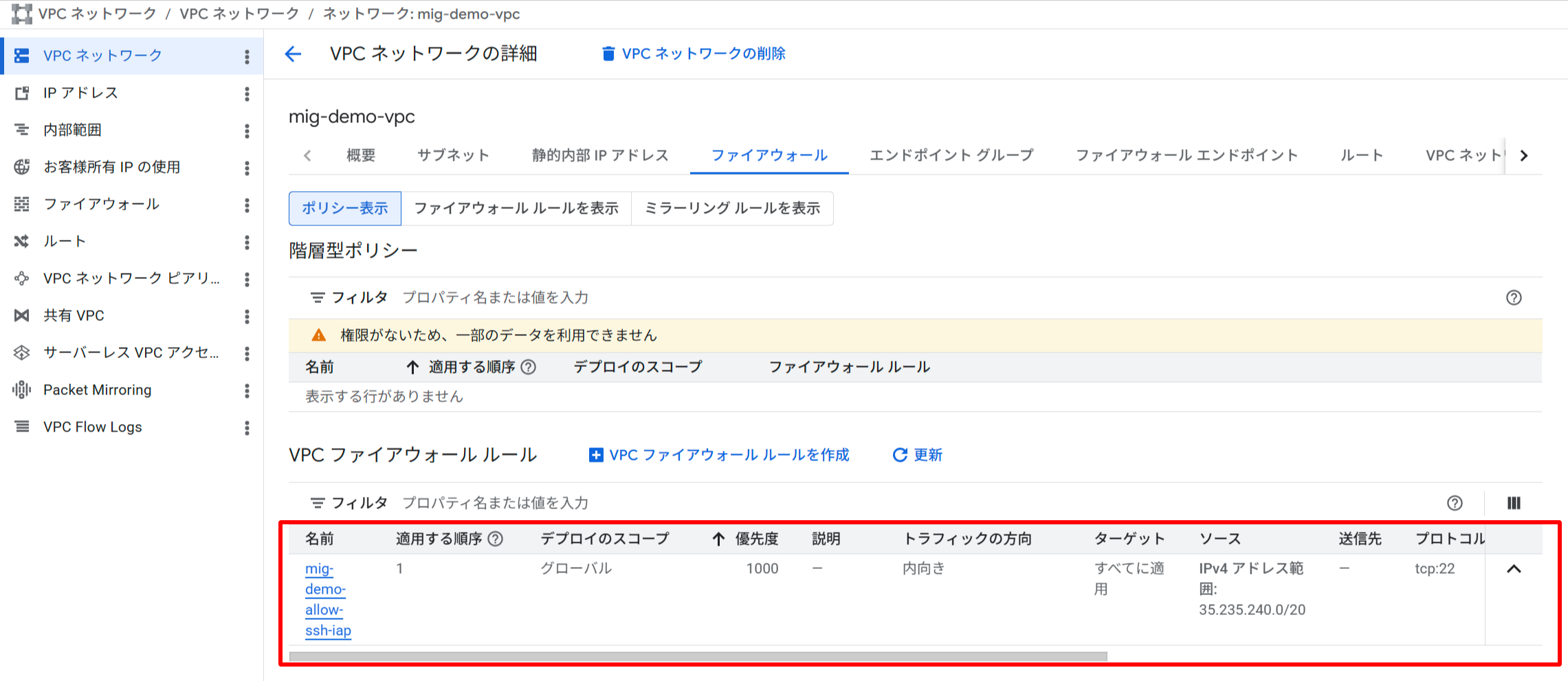
IAP 経由の SSH を許可するファイアウォールルール(mig-demo-allow-ssh-iap)
3. Cloud Router と Cloud NAT の作成
VM はパブリック IP を持たないため、スタートアップスクリプトでのパッケージインストールに Cloud NAT 経由のアウトバウンド通信が必要です。
gcloud compute routers create mig-demo-router \
--network=mig-demo-vpc \
--region=${REGION} \
--project=${PROJECT_ID}
gcloud compute routers nats create mig-demo-nat \
--router=mig-demo-router \
--router-region=${REGION} \
--nat-all-subnet-ip-ranges \
--auto-allocate-nat-external-ips \
--project=${PROJECT_ID}
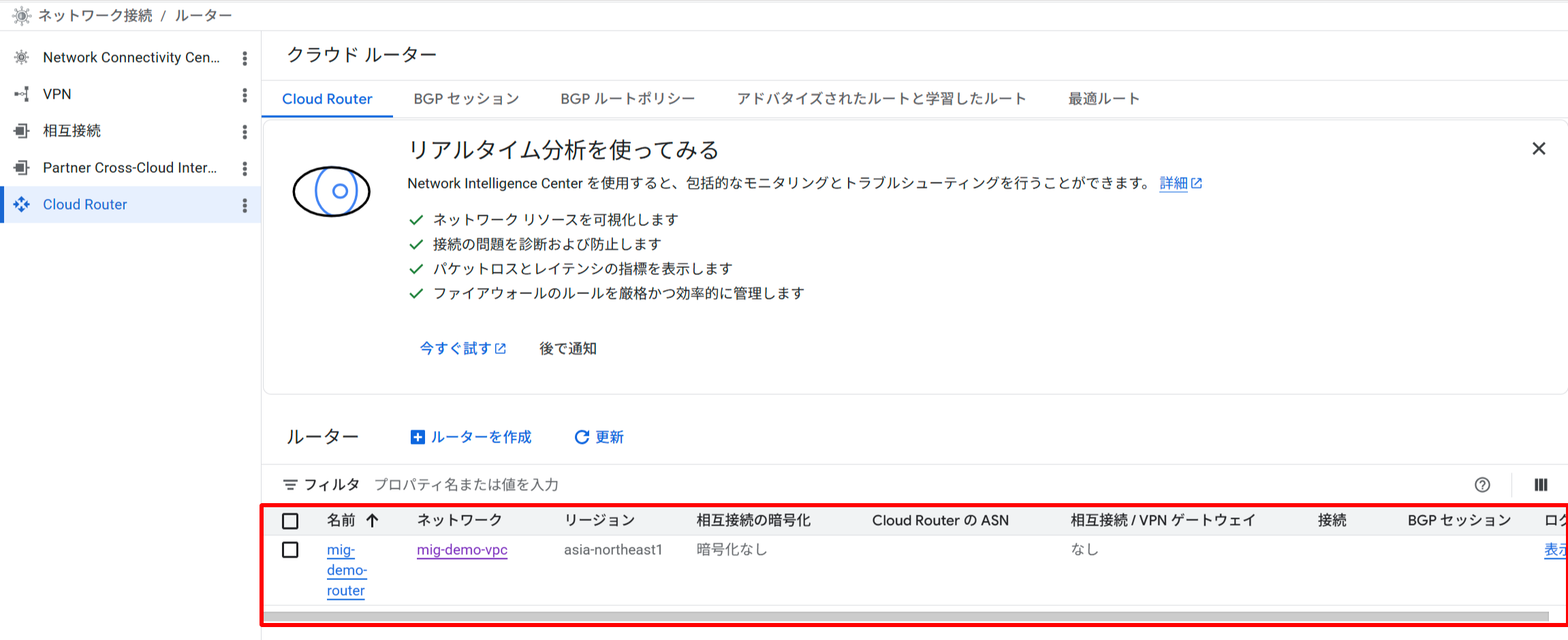
作成した Cloud Router(mig-demo-router)
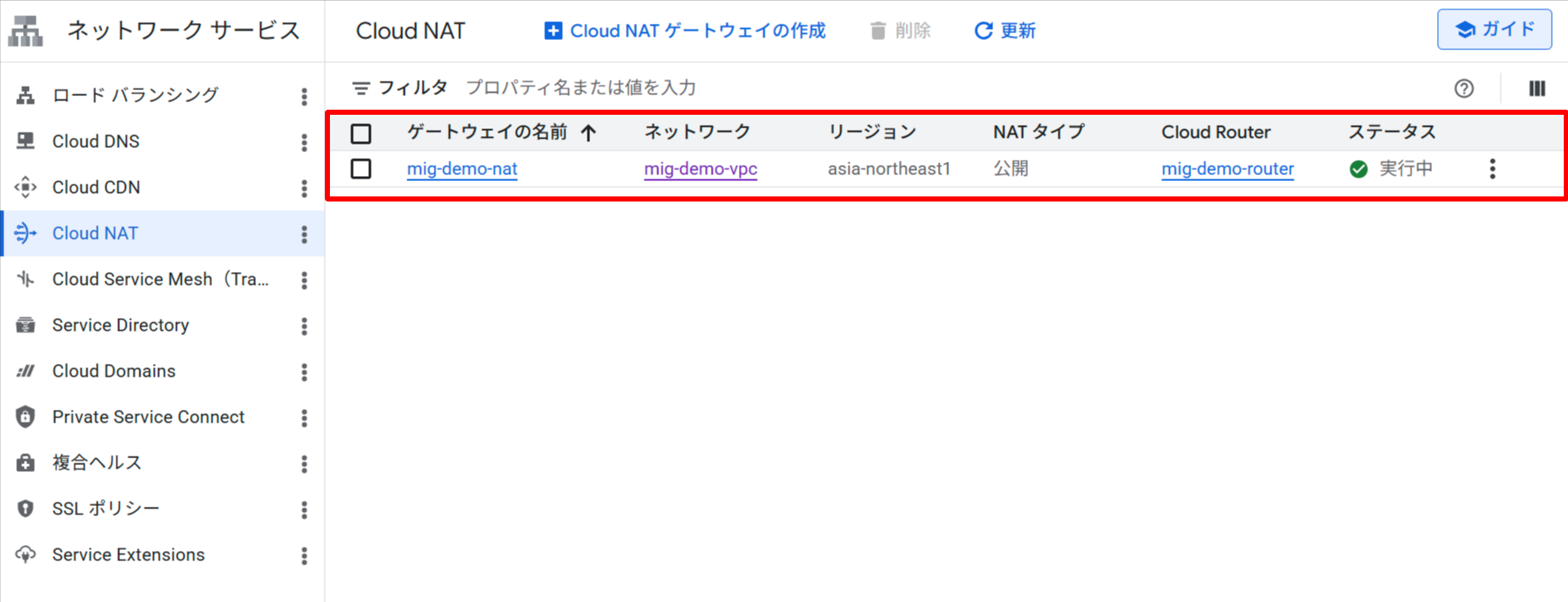
Cloud Router に紐付いた Cloud NAT(mig-demo-nat)
4. インスタンステンプレートの作成
CPU 負荷テストツール(stress)をスタートアップスクリプトでインストールするテンプレートを作成します。外部 IP は割り当てません(--no-address)。
gcloud compute instance-templates create mig-autoscaling-demo-template \
--machine-type=e2-small \
--image-family=debian-12 \
--image-project=debian-cloud \
--network=mig-demo-vpc \
--subnet=mig-demo-subnet \
--region=${REGION} \
--no-address \
--metadata=startup-script='#!/bin/bash
apt-get update -y
apt-get install -y stress' \
--project=${PROJECT_ID}
作成したインスタンステンプレート(mig-autoscaling-demo-template)
5. MIG の作成
初期インスタンス数 1 で MIG を作成します。
gcloud compute instance-groups managed create mig-autoscaling-demo \
--template=mig-autoscaling-demo-template \
--size=1 \
--zone=${ZONE} \
--project=${PROJECT_ID}
作成した MIG(mig-autoscaling-demo)。
6. オートスケーラーの設定
CPU 使用率 60% をターゲットに、最小 1 台・最大 6 台のオートスケーラーを設定します。
gcloud compute instance-groups managed set-autoscaling mig-autoscaling-demo \
--max-num-replicas=6 \
--min-num-replicas=1 \
--target-cpu-utilization=0.60 \
--cool-down-period=60 \
--zone=${ZONE} \
--project=${PROJECT_ID}
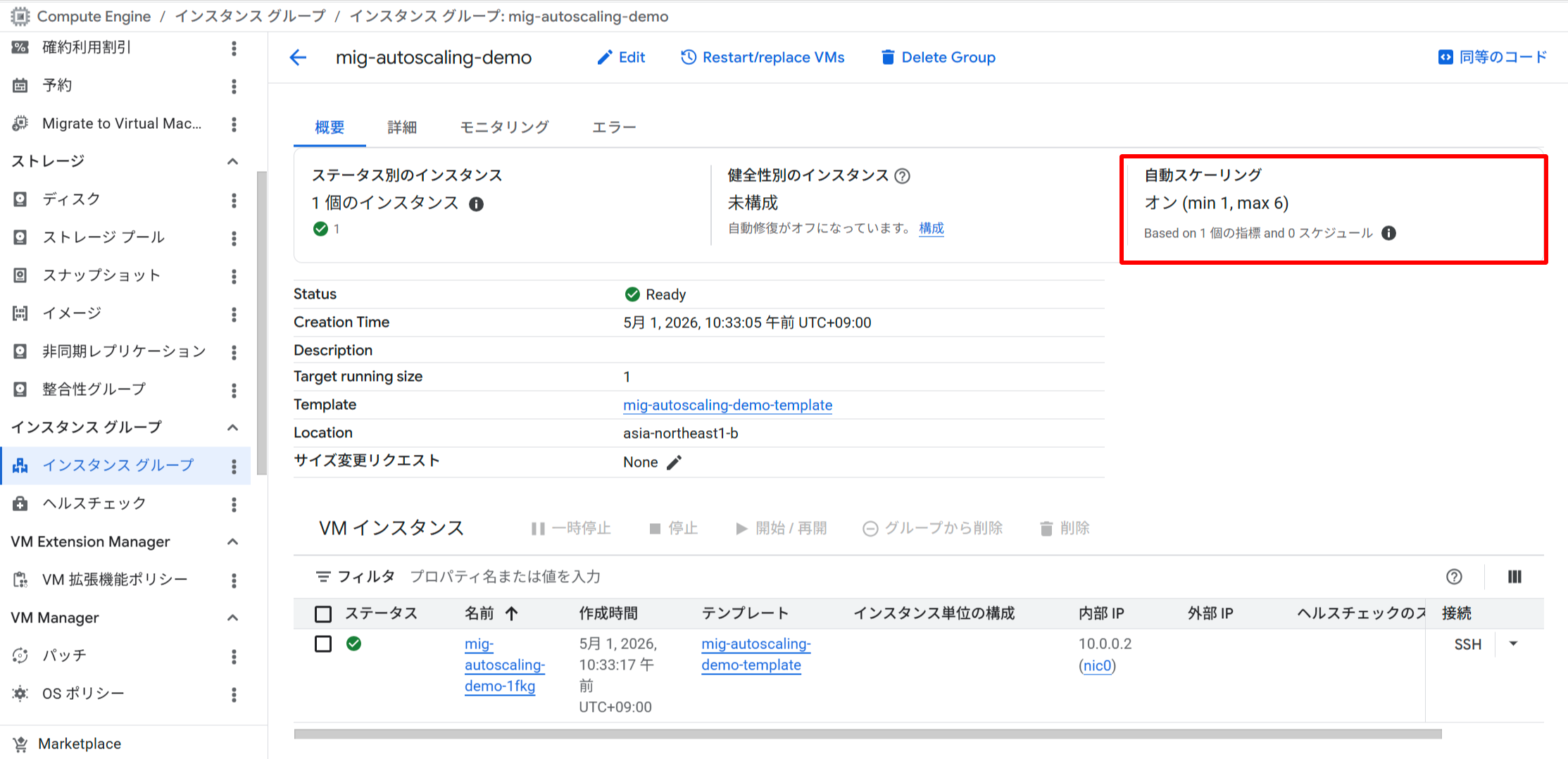
オートスケーラーの設定画面
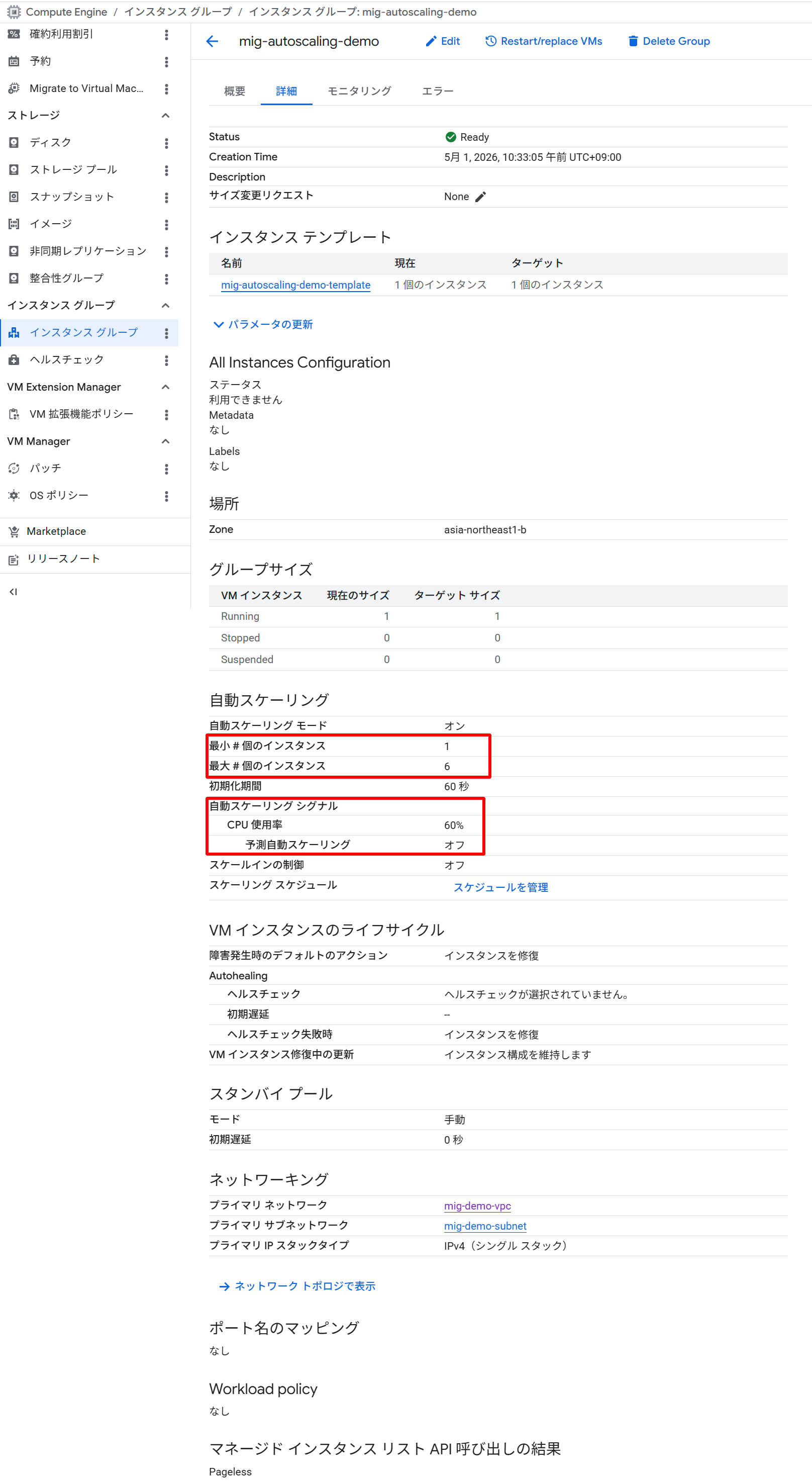
CPU 使用率 60% をターゲットとするオートスケーリングポリシー
7. スケールアウトのトリガー
VM が起動したら IAP 経由で SSH 接続し、stress コマンドで CPU 負荷をかけます。
まず MIG 内の VM 名を確認します。
gcloud compute instance-groups managed list-instances mig-autoscaling-demo \
--zone=${ZONE} \
--project=${PROJECT_ID}
表示された VM 名で IAP 経由の SSH 接続を行います(INSTANCE_NAME は確認した VM 名に置き換えてください)。
gcloud compute ssh INSTANCE_NAME \
--zone=${ZONE} \
--tunnel-through-iap \
--project=${PROJECT_ID}
SSH 接続後、以下のコマンドで全 vCPU に 300 秒間 CPU 負荷をかけます。
stress --cpu $(nproc) --timeout 300
オートスケーラーは CPU 使用率が目標値(60%)を超えたことを検知し、スケールアウトを開始します。スケールアウトが確認できたら Ctrl+C で停止し、exit で SSH 接続を終了してください。
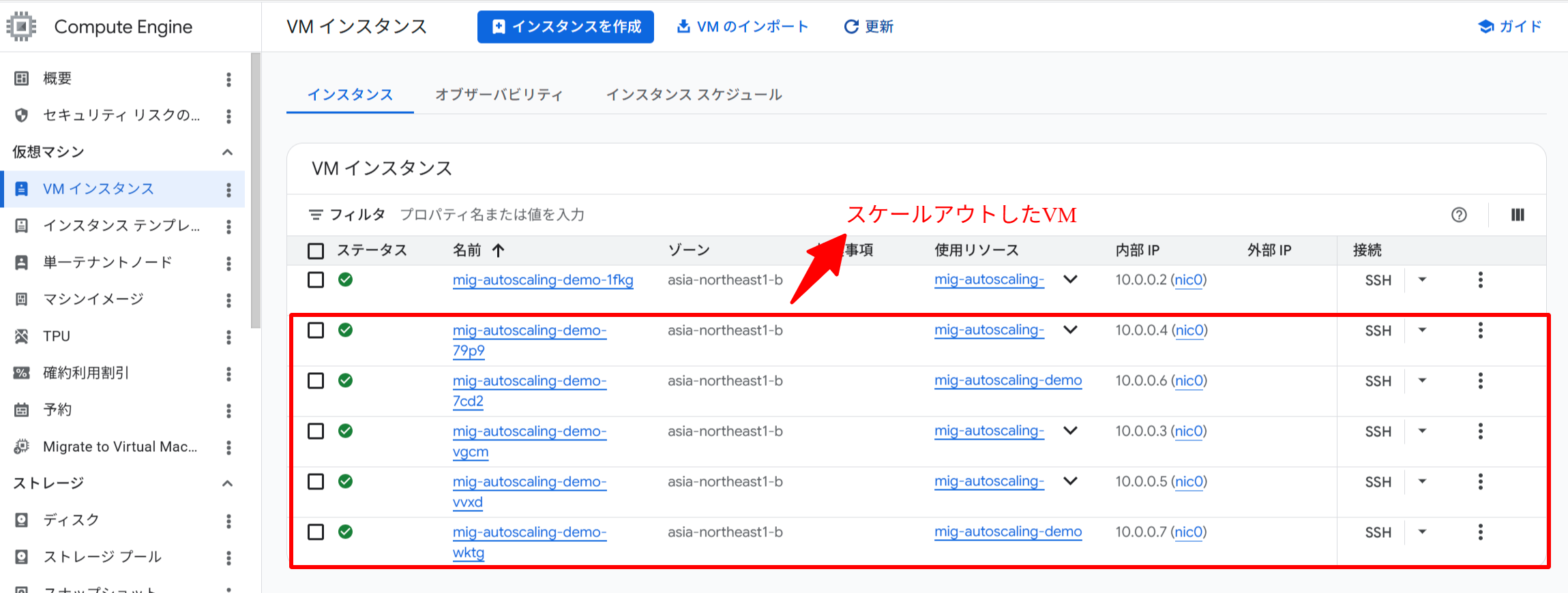
stress コマンド実行後、CPU 使用率が急上昇しスケールアウトが進む様子
負荷を止めると CPU 使用率が低下し、安定化期間(直近 10 分のピーク)を経てスケールインが発生します。
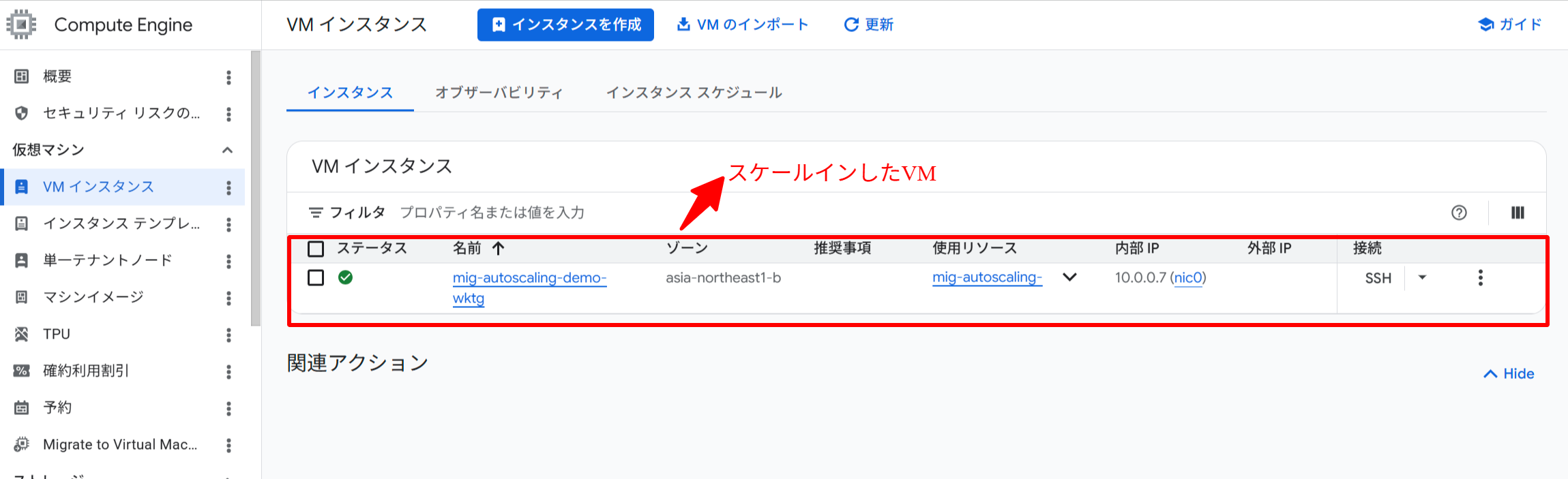
負荷停止後、安定化期間を経てスケールインが発生した様子
スケーリングイベントの確認
1. MIG のモニタリングタブを開く
Google Cloud コンソールで、Compute Engine → インスタンス グループ を開き、mig-autoscaling-demo をクリックします。
Compute Engine インスタンス グループ一覧
次に、「モニタリング」タブを選択します。
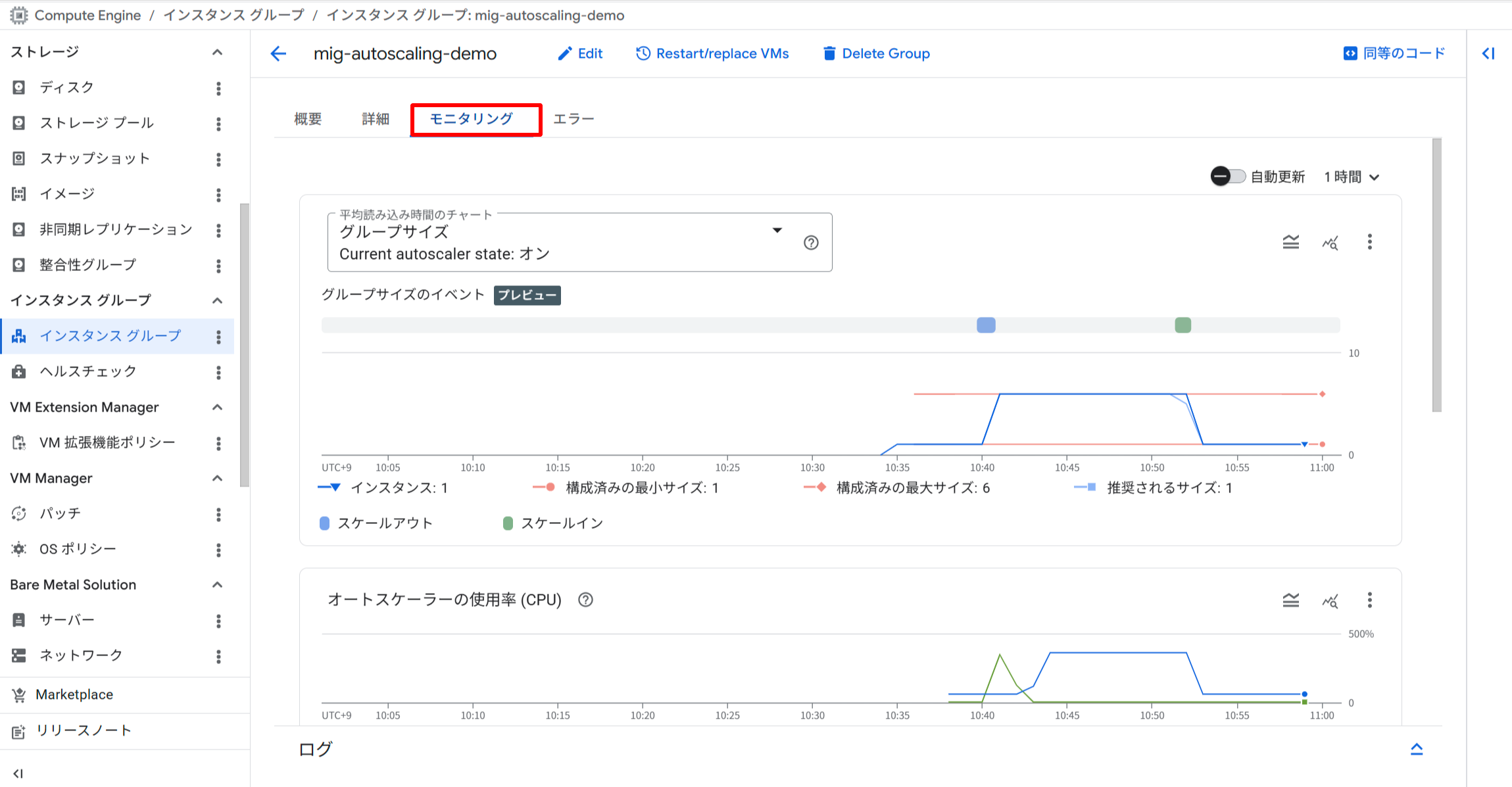
MIG 詳細画面の「モニタリング」タブ
2. グループサイズ チャートのイベントタイムラインを確認する
「グループサイズ」チャートの下部に、イベントタイムラインが表示されます。タイムライン上のブロックがスケーリングイベントを表しています。
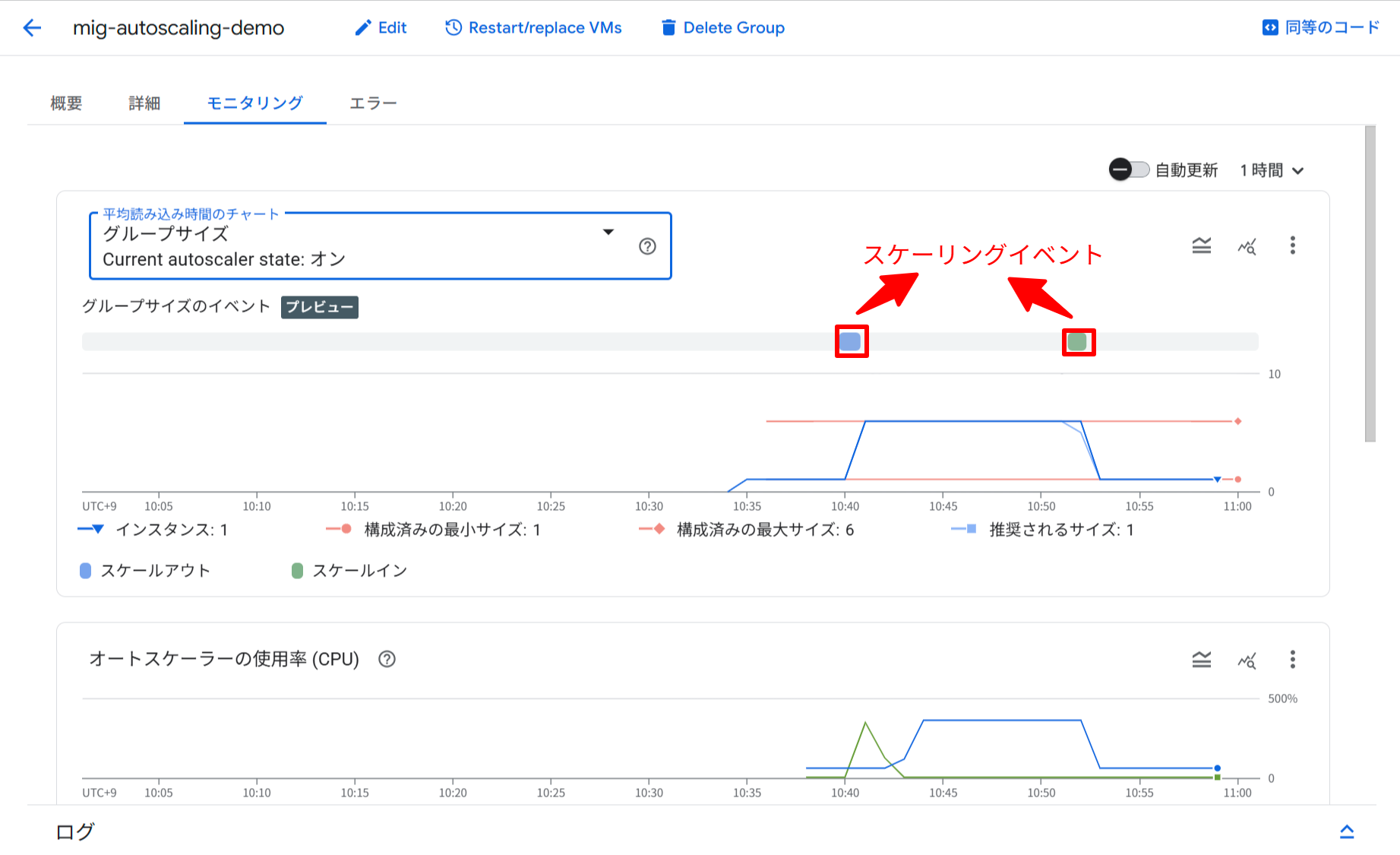
グループサイズチャートの下部にスケーリングイベントのタイムラインが表示されている
時間範囲を絞り込みたい場合は、チャート上でドラッグしてズームするか、右上の時間範囲セレクターを使います。
3. イベントの詳細を確認する
タイムライン上のイベントブロックをホバーすると、スケーリングの詳細カードが表示されます。
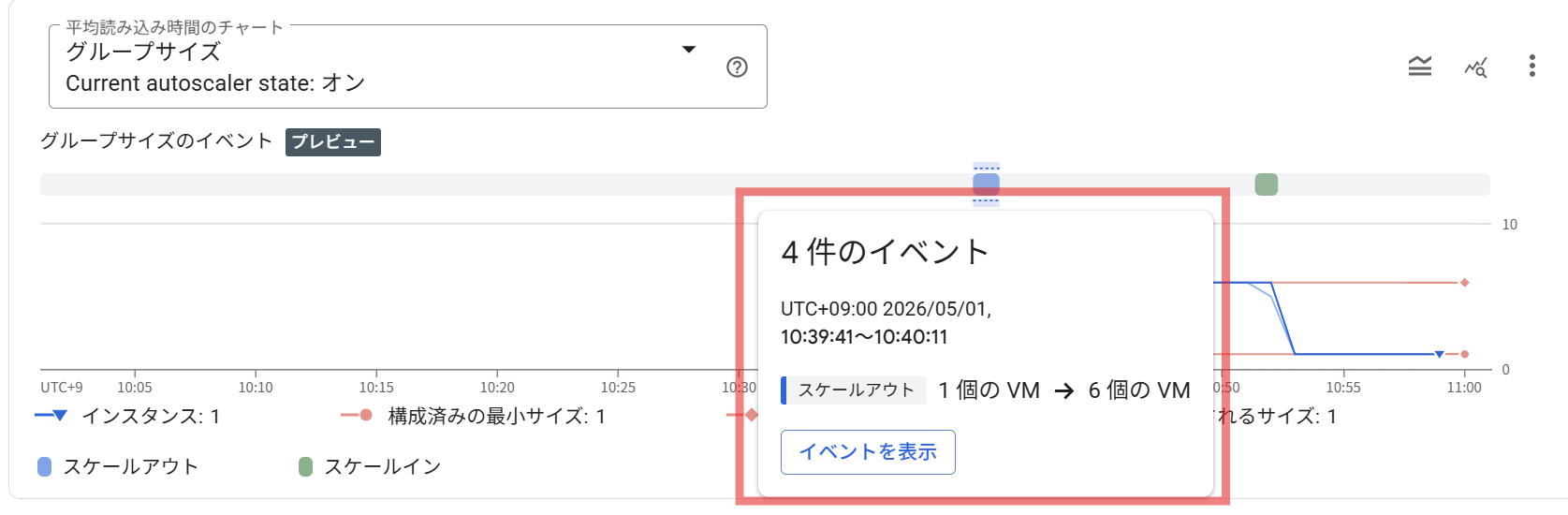
イベントブロックをホバーすると表示されるスケーリングの詳細カード
4. グループ化されたイベントの展開
複数のイベントがまとめて表示されている場合、カード内の「View events」をクリックするか、グラフをズームインすることで個別のイベントとして確認できます。
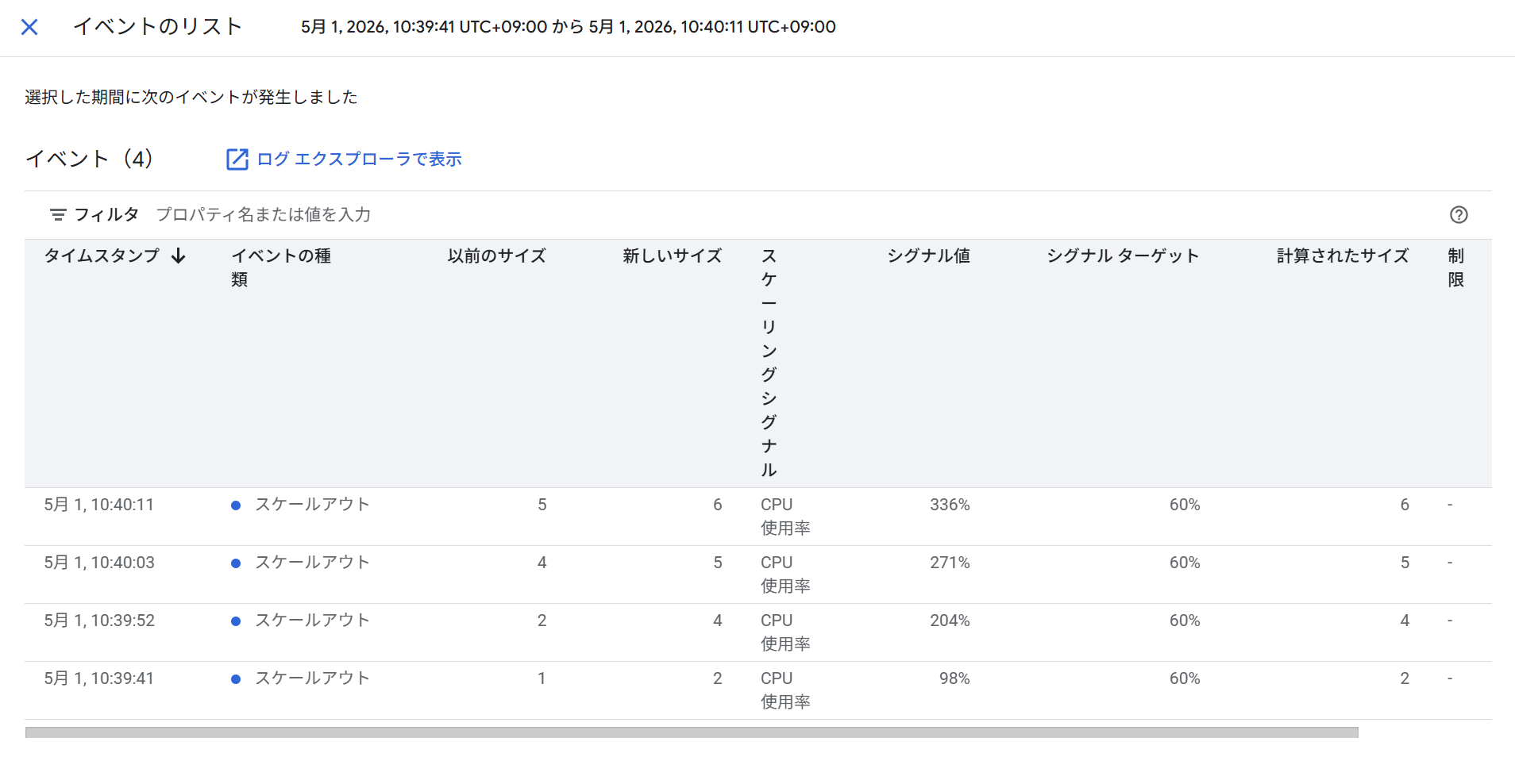
スケールアウトのイベント
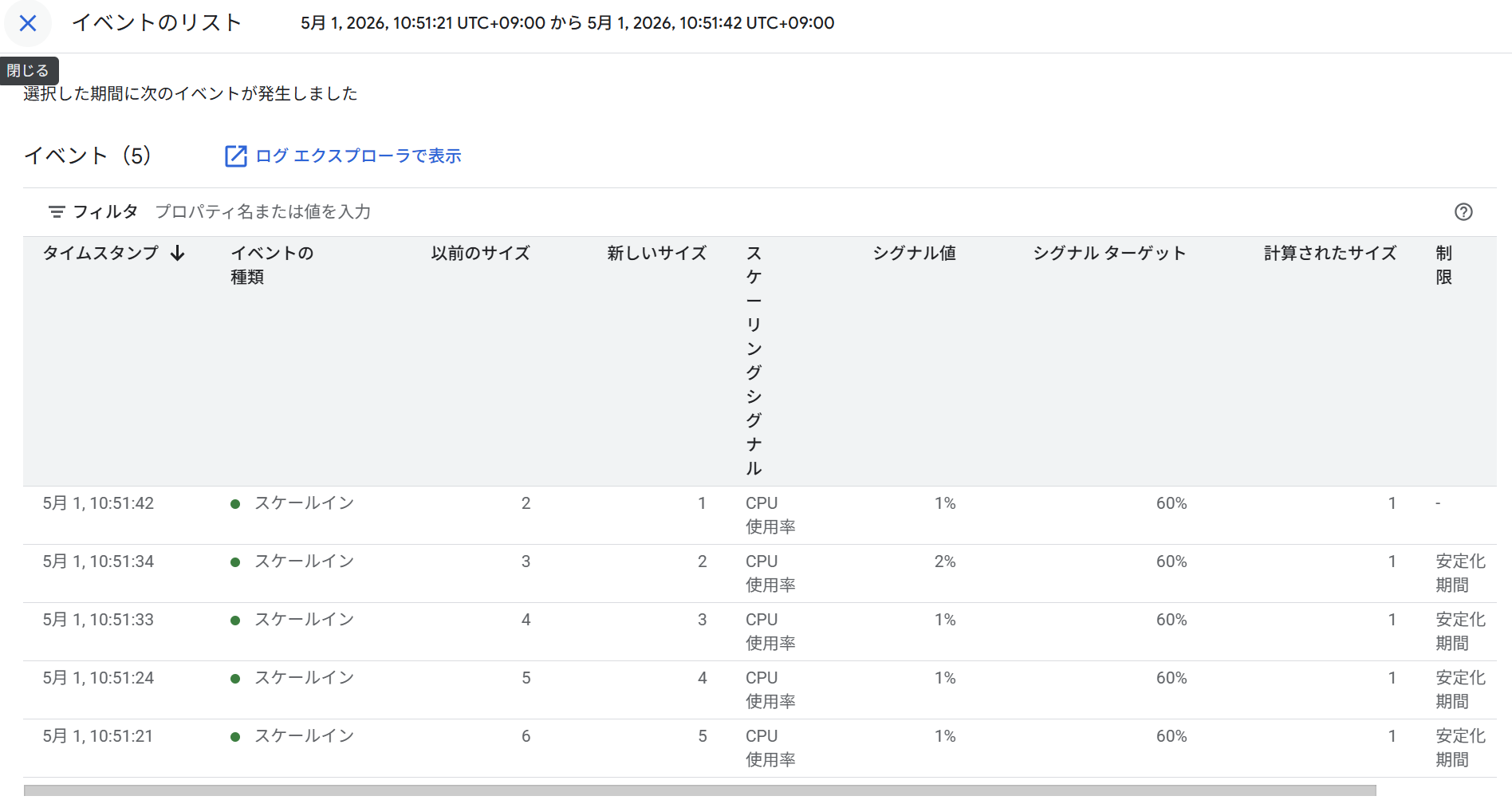
スケールインのイベント
まとめ
今回は、Compute Engine の MIG で個別の自動スケーリングイベントを監視できるようになった機能(Preview)を確認しました。
これまでは「グラフの形からなんとなく推測する」しかなかったスケーリングの理由が、イベント単位で以下の詳細として可視化されるようになりました。
- スケーリングをトリガーしたシグナルの種類
- シグナルの実測値と目標値
- オートスケーラーが算出したサイズ
- サイズを制約した設定
コスト最適化やパフォーマンス調査で「なぜこのタイミングでスケールしたのか?」を追跡する際に非常に役立つ機能です。現時点では Preview ですが、今後 GA となった際にはオートスケーリングの運用・チューニングの標準的な確認手段になるのではないでしょうか。
この記事が誰かの助けになれば幸いです。
以上、クラウド事業本部コンサルティング部の渡邉でした!









