
Lambdaから大量にDSQLに接続してエラー発生有無を確認してみた
リテールアプリ共創部@大阪の岩田です。
re:Invent 2024 で発表されたAurora DSQLは事実上無制限にスケールする分散SQLデータベースとされています。
従来のRDBは最大同時接続数等の観点からLambdaとの相性が悪いことは知られていますが、DSQLは「事実上無制限にスケールする」とのことなので、同時接続数のことを考慮しなくてもインフラ側でよしなにやってくれそうです。実際にLambda関数を大量に同時起動して、DSQLへの同時アクセスを試してみたので結果をご紹介します。
環境
今回検証に利用した環境です。
- Lambda
- ランタイム: Node.js22x
- アーキテクチャ: arm64
- リージョン: バージニア(us-east-1)
- メモリ割り当て: 1769M
- EC2
- インスタンスタイプ: m5.large
- リージョン: バージニア(us-east-1)
- hey: v0.1.4
- ライブラリ等
- pg: 8.16.3
- @aws-sdk/dsql-signer: 3.864.0
やってみる
それでは早速検証していきましょう。
まずはテスト用のLambdaを準備します。今回は以下のコードを準備しました。
import { Client } from 'pg'
import { DsqlSigner } from '@aws-sdk/dsql-signer';
const region = process.env.AWS_REGION;
const clusterEndpoint = `${process.env.DSQL_CLUSTER_IDENTIFIER}.dsql.${region}.on.aws`
const signer = new DsqlSigner({
hostname: clusterEndpoint,
region,
});
const token = await signer.getDbConnectAdminAuthToken();
const getNewClient = () => (
new Client({
host: clusterEndpoint,
port: 5432,
database: 'postgres',
user: 'admin',
password: token,
ssl:true
})
);
let client = null;
let connected = false;
export const lambdaHandler = async (event, context) => {
if (!connected) {
client = getNewClient();
await client.connect();
connected = true;
}
await client.query(`SELECT pg_sleep(5)`);
return {
statusCode: 200,
body: JSON.stringify({
message: 'Hello from DSQL!',
})
}
};
DSQLへの接続が確立されていない場合はDSQLに接続し、SELECT pg_sleep(5)を実行するだけの処理です。SQLは何でも良いのですが、SELECT NOW()等だと一瞬で終了してしまい、Lambdaの同時実行数を上げづらいためpg_sleepを実行するようにしています。
このLambdaを以下のSAMテンプレートでデプロイし、API GW → Lambdaという構成を作ります。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Globals:
Function:
Timeout: 10
Tracing: Active
MemorySize: 1769
Api:
TracingEnabled: true
Resources:
Dsql:
Type: AWS::DSQL::Cluster
Properties:
DeletionProtectionEnabled: false
DsqlTestFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello-world/
Handler: app.lambdaHandler
Runtime: nodejs22.x
Architectures:
- arm64
Layers:
- arn:aws:lambda:us-east-1:615299751070:layer:AWSOpenTelemetryDistroJs:8
Role: !GetAtt LambdaRole.Arn
Environment:
Variables:
OTEL_NODE_ENABLED_INSTRUMENTATIONS: pg
AWS_LAMBDA_EXEC_WRAPPER: /opt/otel-instrument
DSQL_CLUSTER_IDENTIFIER: !Ref Dsql
Events:
api:
Type: Api
Properties:
Path: /dsql
Method: get
LambdaRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- 'lambda.amazonaws.com'
Action: sts:AssumeRole
Policies:
-
PolicyName: dsql-blog-policy
PolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Action:
- 'dsql:*'
- "logs:*"
- "xray:*"
Resource: '*'
あとで分析しやすいようAWSが公開しているADOTのレイヤー arn:aws:lambda:us-east-1:615299751070:layer:AWSOpenTelemetryDistroJs:8 を紐づけ、環境変数OTEL_NODE_ENABLED_INSTRUMENTATIONSにpgを指定することでpgによる接続処理等詳細にトレースできるように設定しています。
準備ができたらsam build && sam deployで検証環境を一式デプロイします。
Lambdaの同時実行数1,000で計測してみる
準備ができたらheyコマンドを使ってAPI GWにリクエストを発行します。今回は以下のコマンドで(ほぼ)同時に1,000リクエストを発行しました。
10:50スタート
hey -c 1000 -n 1000 https://<API GWのID>.execute-api.us-east-1.amazonaws.com/Prod/dsql
なお、コマンド実行前にsam deleteとsam deployで全リソースの削除と再デプロイを実施しているのでLambdaやDSQLのクエリプロセッサーにはwarm環境が存在せず、初回アクセスはコールドスタートが発生しているはずです。結果は以下の通りになりました。
Summary:
Total: 8.4554 secs
Slowest: 8.4390 secs
Fastest: 7.3154 secs
Average: 7.9864 secs
Requests/sec: 118.2682
Total data: 30000 bytes
Size/request: 30 bytes
Response time histogram:
7.315 [1] |
7.428 [1] |
7.540 [6] |■
7.652 [3] |■
7.765 [73] |■■■■■■■■■■■■
7.877 [192] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
7.990 [215] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
8.102 [234] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
8.214 [217] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
8.327 [52] |■■■■■■■■■
8.439 [6] |■
Latency distribution:
10% in 7.7795 secs
25% in 7.8664 secs
50% in 7.9947 secs
75% in 8.1087 secs
90% in 8.1809 secs
95% in 8.2224 secs
99% in 8.3095 secs
Details (average, fastest, slowest):
DNS+dialup: 0.5355 secs, 7.3154 secs, 8.4390 secs
DNS-lookup: 0.0695 secs, 0.0043 secs, 0.1601 secs
req write: 0.0735 secs, 0.0001 secs, 0.1683 secs
resp wait: 7.3768 secs, 6.8654 secs, 7.8326 secs
resp read: 0.0000 secs, 0.0000 secs, 0.0002 secs
Status code distribution:
[200] 1000 responses
[200] 1000 responsesの出力の通り接続エラーは発生していないことが分かります!
各種メトリクスを確認してみる
テスト実行後の各種メトリクスを確認してみましょう。
まずLambdaの同時実行数です。
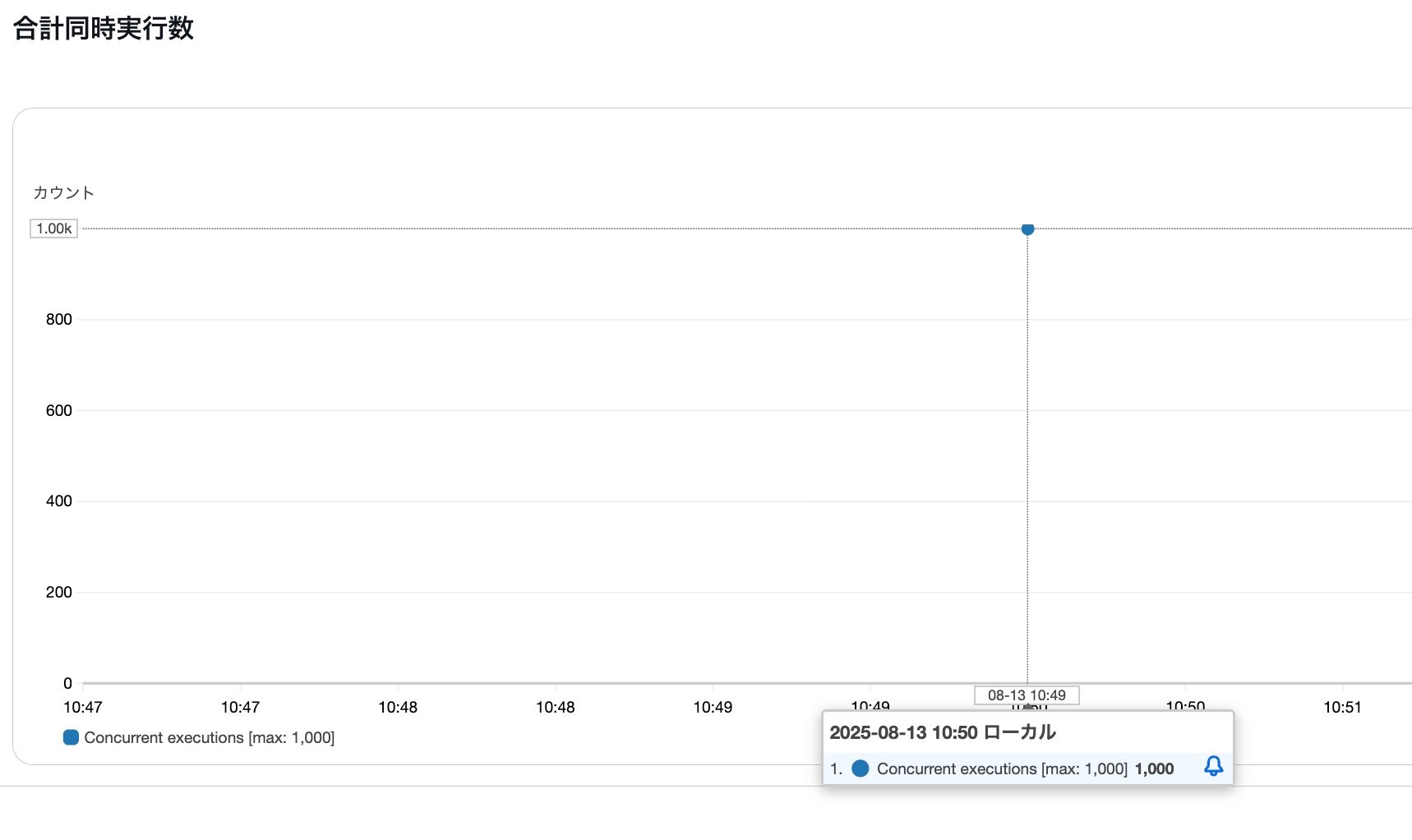
期待通り1,000同時実行できていますね。
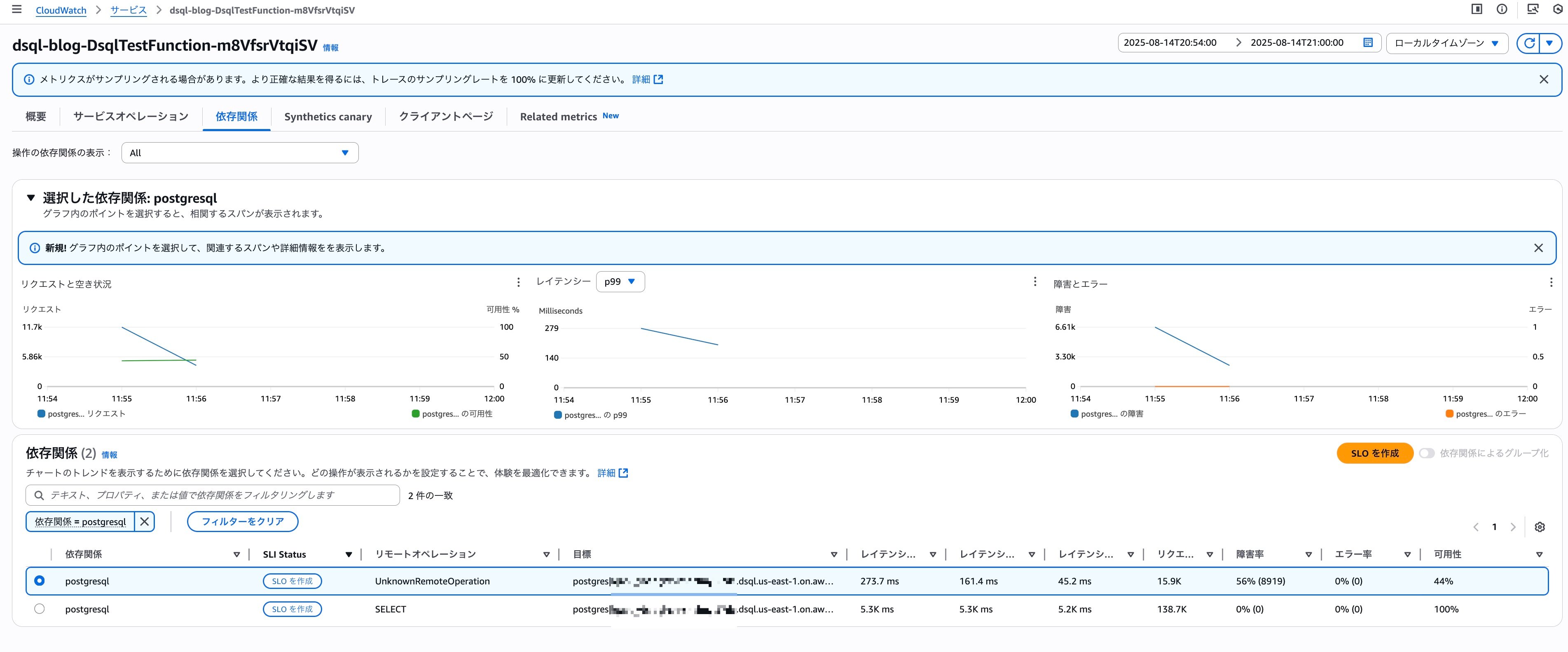
試しに1件X-Rayからトレース結果を確認してみました。
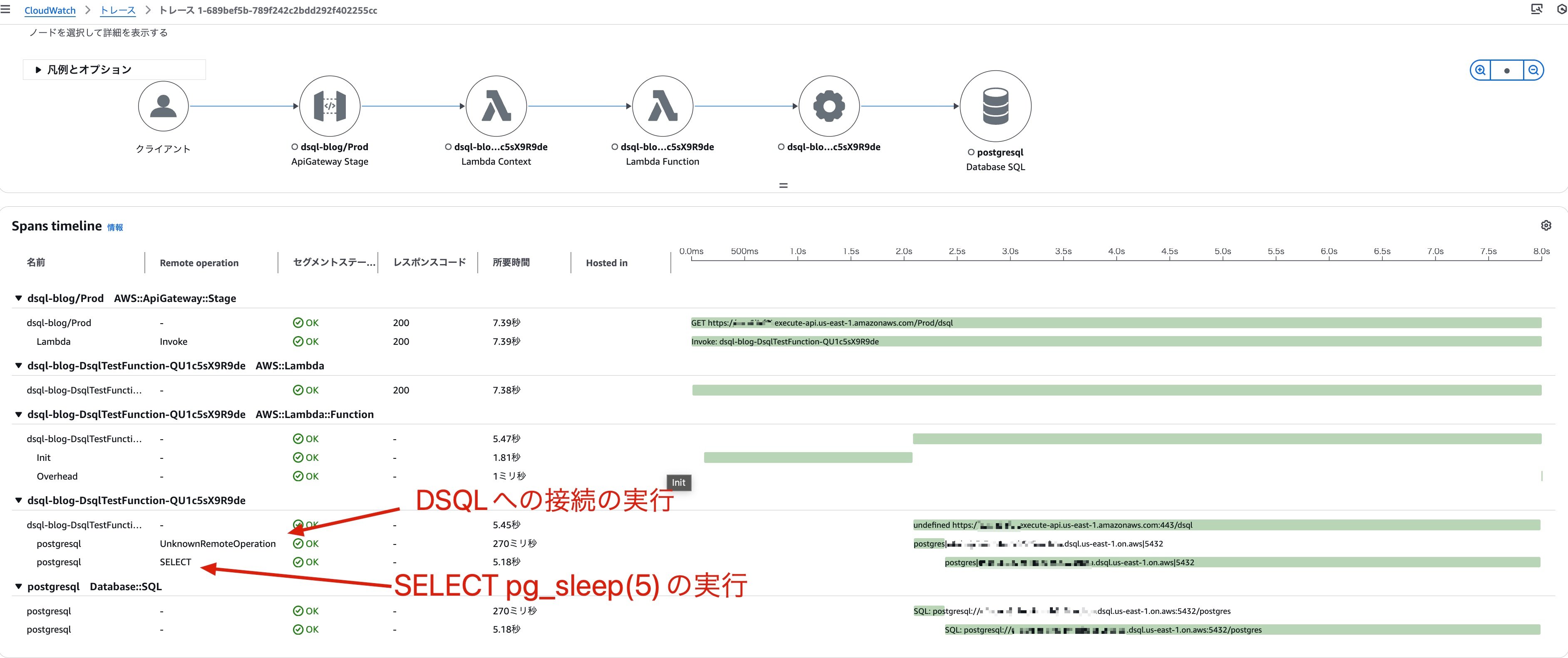
Remote operationにUnknownRemoteOperationと表示されているのがawait client.connect();でDSQLに接続している処理、SELECTと表示されているのがawait client.query...でDSQLにSELECT文を発行している処理です。
接続に270ミリ秒というのはかなり時間がかかっている印象ですが、クエリプロセッサーの実体であるFirecrackerのMicroVMがコールドスタートを引いたとかでしょうか?現時点ではDSQLのメトリクスからコールドスタート有無を判断することはできないですが、この辺りのアーキテクチャの裏側を色々妄想してみるのも楽しそうです。
Transaction Searchを使って以下のクエリでDB関連操作のレイテンシを集計してみました。
filter ispresent(attributes.db.name)
| stats count(*) as cnt,
min(durationNano / 1000000) as min,
max(durationNano / 1000000) as max,
avg(durationNano / 1000000) as avg,
pct(durationNano / 1000000, 95) as p95,
pct(durationNano / 1000000, 90) as p90,
pct(durationNano / 1000000, 50) as p50
by name
結果は以下の通りになりました。
| 操作 | 件数 | 最小値 | 最大値 | 平均値 | 95%タイル | 90%タイル | 中央値 |
|---|---|---|---|---|---|---|---|
| pg.query:SELECT postgres | 1000 | 5117.8592 | 5395.1828 | 5173.2771 | 5301.3292 | 5264.3679 | 5129.325 |
| pg.connect | 1000 | 52.449 | 454.812 | 218.8274 | 334.3186 | 310.4837 | 233.0551 |
pg.connectの方は最小値52.449msに対して最大値454.812msと結構分散が大きい印象です。やはりクエリプロセッサーのコールドスタートが関連しているのでしょうか?また別途検証してみたいと思います。
Lambdaの同時実行数を約7,000まで引き上げてみる
Lambdaの同時実行数1,000では特にエラー等発生しないことが確認できたので、さらに同時実行数を上げてみます。以前以下のブログを書いた時にLambdaの同時実行数を7,000まで上限緩和申請しているので7,000同時実行まで挑戦します。
改めてsam delete && sam deployで検証環境を作り直し、今度はheyコマンドで7,000リクエストを発行してみます。
hey -c 7000 -n 250000 -q 1 https://<API GWのID>.execute-api.us-east-1.amazonaws.com/Prod/dsql
結果は以下のようになりました。
Summary:
Total: 193.5898 secs
Slowest: 19.6279 secs
Fastest: 0.0110 secs
Average: 3.5422 secs
Requests/sec: 1265.5624
Total data: 7987410 bytes
Size/request: 32 bytes
Response time histogram:
0.011 [1] |
1.973 [84408] |■■■■■■■■■■■■■■■■■■■■■■■■■■
3.934 [15137] |■■■■■
5.896 [128119] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
7.858 [11581] |■■■■
9.819 [4061] |■
11.781 [1520] |
13.743 [78] |
15.705 [93] |
17.666 [0] |
19.628 [1] |
Latency distribution:
10% in 0.1668 secs
25% in 0.5442 secs
50% in 5.0286 secs
75% in 5.0340 secs
90% in 5.6061 secs
95% in 6.5266 secs
99% in 9.3013 secs
Details (average, fastest, slowest):
DNS+dialup: 0.1016 secs, 0.0110 secs, 19.6279 secs
DNS-lookup: 0.1359 secs, 0.0000 secs, 4.0230 secs
req write: 0.0358 secs, 0.0000 secs, 4.0838 secs
resp wait: 3.2332 secs, 0.0109 secs, 19.5949 secs
resp read: 0.0188 secs, 0.0000 secs, 2.4516 secs
Status code distribution:
[200] 138759 responses
[500] 97321 responses
[502] 8919 responses
Error distribution:
[1] Get "https://faawmhbgr0.execute-api.us-east-1.amazonaws.com/Prod/dsql": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
今度は500エラーが大量に発生していますね。負荷掛け用のクライアント側でもエラーが発生していますが、1件なのでまあ無視で良いでしょう。Lambdaのメトリクスを確認してみましょう。
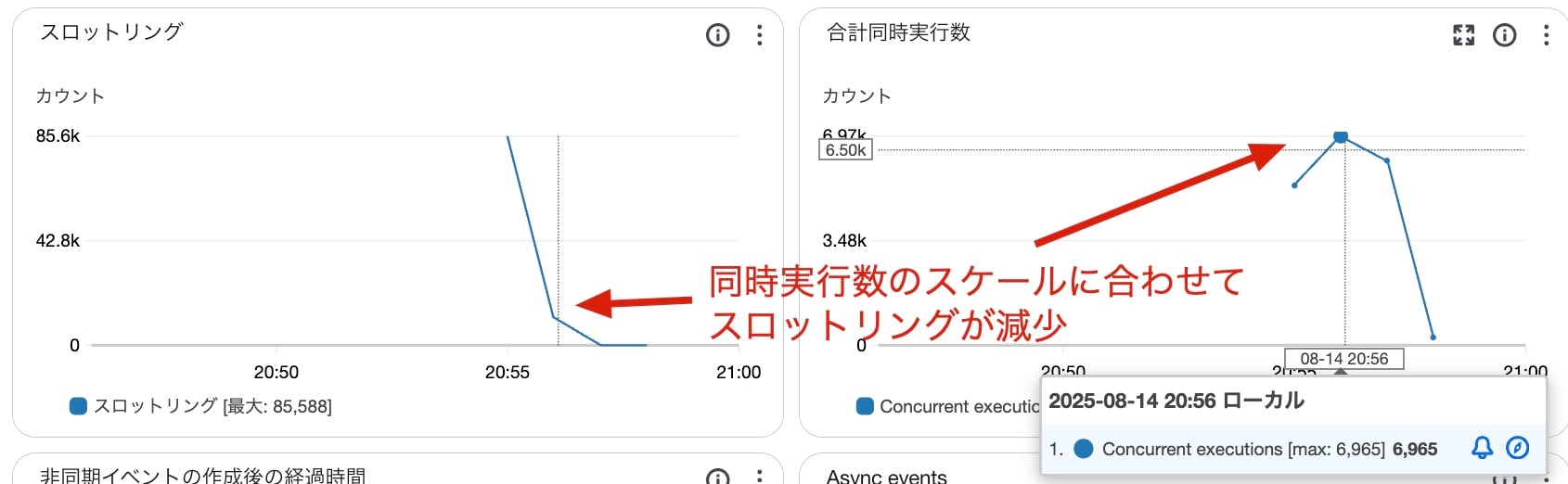
計測を開始したのは20:55頃ですが、20:56頃に同時実行数が約7,000にスケールアウトするとともにスロットリングエラーが減少していることが分かります。
トレースマップで全体像を確認してみます。
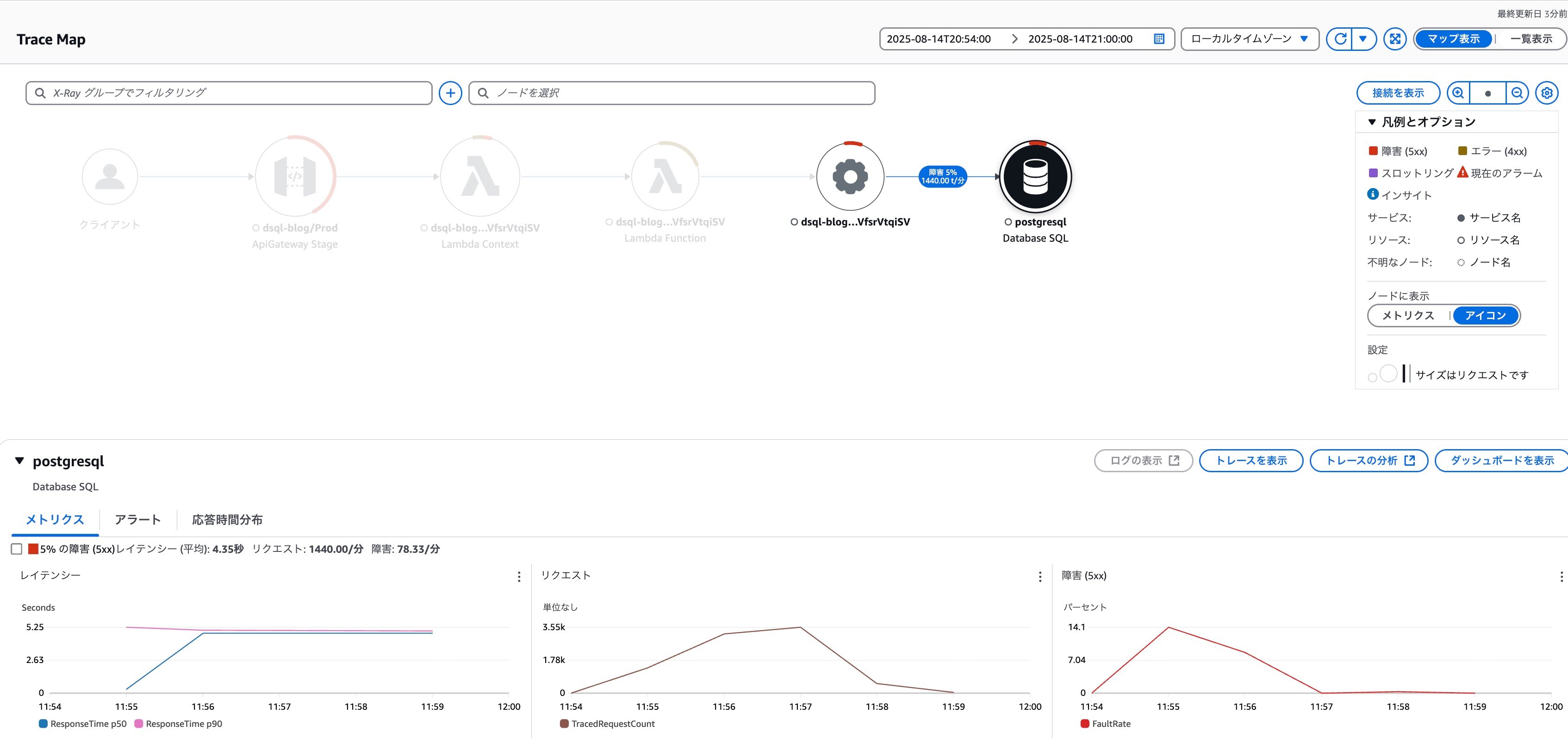
Lambdaのスロットリングエラーより割合は少ないですが、DSQL関連のオペレーションでもエラーが発生していることが分かります。
Application SignalsでDSQL関連オペレーションの状況を確認すると接続処理の56%で障害が発生していたことが分かります。
続いてLambdaのログからDSQL関連オペレーションでどのようなエラーが発生していたのか確認してみましょう。
ERRという文字列でログを検索すると以下のようなログが大量に出力されていました。
{
"errorType": "error",
"errorMessage": "unable to accept connection, rate exceeded",
"code": "53400",
"length": 110,
"name": "error",
"severity": "FATAL",
"detail": "Session Id: svtcuhakmrll35mtgjvooj5gzy",
"stack": [
"error: unable to accept connection, rate exceeded",
" at Parser.parseErrorMessage (/var/task/node_modules/pg-protocol/dist/parser.js:285:98)",
" at Parser.handlePacket (/var/task/node_modules/pg-protocol/dist/parser.js:122:29)",
" at Parser.parse (/var/task/node_modules/pg-protocol/dist/parser.js:35:38)",
" at TLSSocket.<anonymous> (/var/task/node_modules/pg-protocol/dist/index.js:11:42)",
" at TLSSocket.emit (node:events:518:28)",
" at addChunk (node:internal/streams/readable:561:12)",
" at readableAddChunkPushByteMode (node:internal/streams/readable:512:3)",
" at Readable.push (node:internal/streams/readable:392:5)",
" at TLSWrap.onStreamRead (node:internal/stream_base_commons:189:23)",
" at TLSWrap.callbackTrampoline (node:internal/async_hooks:130:17)"
]
}
レートリミットに抵触してDSQLに接続が確立できなかったようですね。
CW Logs Insightsのクエリでエラーメッセージごとに1秒毎のエラー件数を集計してみましょう。
filter ispresent(errorMessage)
| stats count(*) by errorMessage,bin(1s) as t
| sort t
結果は以下の通りです。エラーのパターンとしては全てunable to accept connection, rate exceededでした。
| errorMessage | t | count(*) |
|---|---|---|
| unable to accept connection, rate exceeded | 2025-08-14 11:55:23.000 | 88 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:24.000 | 171 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:25.000 | 171 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:26.000 | 47 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:27.000 | 377 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:28.000 | 72 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:29.000 | 222 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:30.000 | 123 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:31.000 | 105 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:32.000 | 187 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:33.000 | 51 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:34.000 | 74 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:35.000 | 18 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:36.000 | 400 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:37.000 | 120 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:38.000 | 1571 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:39.000 | 490 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:40.000 | 133 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:41.000 | 6 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:42.000 | 27 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:43.000 | 86 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:45.000 | 26 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:46.000 | 76 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:47.000 | 1 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:48.000 | 5 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:49.000 | 75 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:50.000 | 1 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:51.000 | 83 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:52.000 | 282 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:53.000 | 215 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:54.000 | 447 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:55.000 | 21 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:56.000 | 60 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:57.000 | 236 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:58.000 | 163 |
| unable to accept connection, rate exceeded | 2025-08-14 11:55:59.000 | 357 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:00.000 | 69 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:01.000 | 130 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:02.000 | 259 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:03.000 | 85 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:04.000 | 166 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:05.000 | 85 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:06.000 | 166 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:07.000 | 265 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:08.000 | 99 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:09.000 | 254 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:10.000 | 132 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:11.000 | 146 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:12.000 | 86 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:13.000 | 199 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:14.000 | 75 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:15.000 | 26 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:16.000 | 6 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:17.000 | 45 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:18.000 | 19 |
| unable to accept connection, rate exceeded | 2025-08-14 11:56:19.000 | 1 |
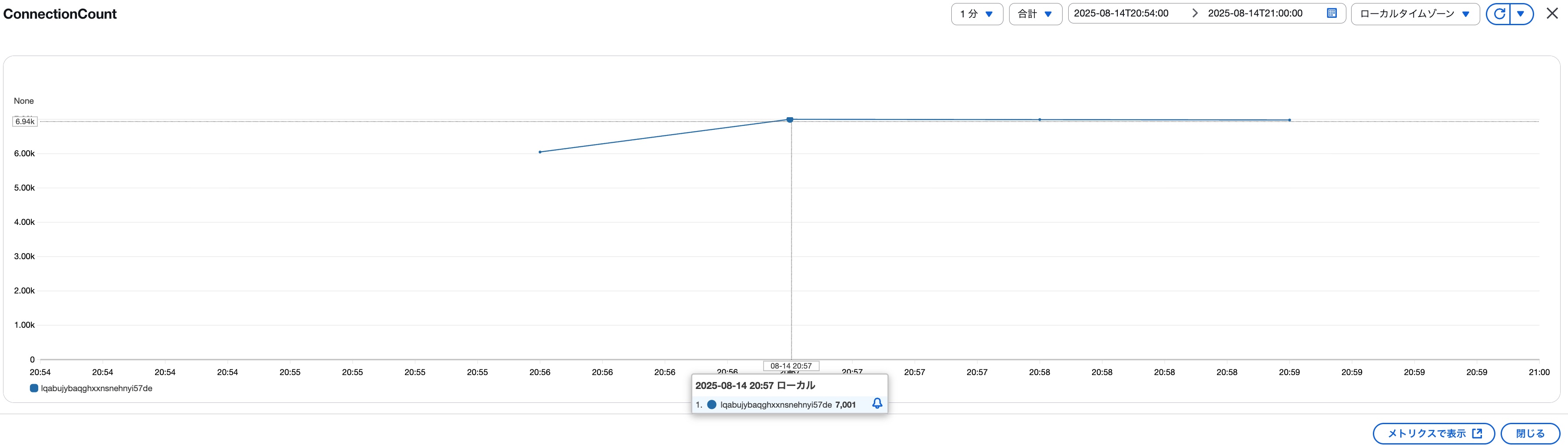
DSQLのメトリクスからConnectionCountがどのように推移していたか確認してみましょう。結果は以下の通りで20:57に7,001接続に到達していました。※テストシナリオの想定としては7,000になる予定でしたが、まあどこかの処理で誤差が生じたのでしょうか?
先ほどの接続ログから確認する限り最後に接続エラーが発生したのは20:56:19台なので20:57台にLambdaの同時実行数 ≒ DSQLのConnectionCountとなるのは整合性が取れていますね。
改めてDSQLの制限を確認してみる
これまでの検証結果をまとめると、Lambdaの同時実行数を一気に1,000までスパイクさせてもエラーは出ませんでしたが、7,000まであげるとunable to accept connection, rate exceededのエラーが発生していました。ちょっと順序が逆な気はしますが、改めてDSQLの制限事項についてドキュメントを確認してみます。2025/8現在は以下の通りの制限が存在します。
※公式ドキュメントから同時接続数関連の項目だけ抜粋
| 説明 | デフォルトの制限 | 設定可能? | Aurora DSQL エラーコード | エラーメッセージ |
|---|---|---|---|---|
| クラスターあたりの最大接続数 | 10,000 接続 | はい | TOO_MANY_CONNECTIONS(53300) |
Unable to accept connection, too many open connections. |
| クラスターあたりの最大接続レート | 100 接続/秒 | いいえ | CONFIGURED_LIMIT_EXCEEDED(53400) |
Unable to accept connection, rate exceeded. |
| クラスターあたりの最大接続バーストキャパシティ | 1,000 接続 | いいえ | エラーコードなし | エラーメッセージなし |
| 接続のリフィルレート | 100 接続/秒 | いいえ | エラーコードなし | エラーメッセージなし |
エラーメッセージから今回の検証は クラスターあたりの最大接続レートの制限 100 接続/秒に抵触したことが分かります。クラスターあたりの最大接続数はデフォルト10,000接続なので今回の検証パターンの上限である7,000接続は問題なく捌ける数値となっています。
気になるのが最初に検証したLambdaの同時実行数1,000のパターンです。 クラスターあたりの最大接続レートの制限 100 接続/秒からするとエラーが発生しても良さそうですが、エラーは発生しませんでした。負荷掛けに使ったクライアント側の問題でRPSが100まで上がりきらなかったのでしょうか?それとも クラスターあたりの最大接続バーストキャパシティは1,000接続/秒までバースト可能という意味なんでしょうか?
改めてLambdaの同時実行数1,000で検証した時のログを確認してみましょう。Transaction Searchから以下のクエリを実行します。
filter name = "pg.connect"
| stats count(*) as cnt by ceil(startTimeUnixNano/1000000/1000) as startTimeUnix
| display startTimeUnix, fromMillis(startTimeUnix * 1000) as approximateStartTime, cnt
| sort startTimeUnix
pg.connectを実行開始した時刻を秒単位に丸めて、毎秒何件のログが存在するかを抽出しています。わかりやすい用に
結果は以下の通りでした。
| startTimeUnix | approximateStartTime | cnt |
|---|---|---|
| 1755049821 | 2025-08-13 01:50:21.000 | 190 |
| 1755049822 | 2025-08-13 01:50:22.000 | 810 |
UTC01:50:22台には810の接続を試行していることが分かります。これで接続エラーが1件も出ていなかったということはクラスターあたりの最大接続バーストキャパシティは接続レートに対するバーストキャパシティであると考えて良さそうです。
同じクエリをLambdaの同時実行数7,000まで引き上げた時間帯に対して実行すると結果は以下の通りでした。
| startTimeUnix | approximateStartTime | cnt |
|---|---|---|
| 1755172519 | 2025-08-14 11:55:19.000 | 134 |
| 1755172520 | 2025-08-14 11:55:20.000 | 826 |
| 1755172521 | 2025-08-14 11:55:21.000 | 261 |
| 1755172522 | 2025-08-14 11:55:22.000 | 110 |
| 1755172523 | 2025-08-14 11:55:23.000 | 97 |
| 1755172524 | 2025-08-14 11:55:24.000 | 186 |
| 1755172525 | 2025-08-14 11:55:25.000 | 274 |
| 1755172526 | 2025-08-14 11:55:26.000 | 230 |
| 1755172527 | 2025-08-14 11:55:27.000 | 221 |
| 1755172528 | 2025-08-14 11:55:28.000 | 430 |
| 1755172529 | 2025-08-14 11:55:29.000 | 188 |
| 1755172530 | 2025-08-14 11:55:30.000 | 329 |
| 1755172531 | 2025-08-14 11:55:31.000 | 187 |
| 1755172532 | 2025-08-14 11:55:32.000 | 276 |
| 1755172533 | 2025-08-14 11:55:33.000 | 213 |
| 1755172534 | 2025-08-14 11:55:34.000 | 195 |
| 1755172535 | 2025-08-14 11:55:35.000 | 95 |
| 1755172536 | 2025-08-14 11:55:36.000 | 184 |
| 1755172537 | 2025-08-14 11:55:37.000 | 556 |
| 1755172538 | 2025-08-14 11:55:38.000 | 224 |
| 1755172539 | 2025-08-14 11:55:39.000 | 1581 |
| 1755172540 | 2025-08-14 11:55:40.000 | 630 |
| 1755172541 | 2025-08-14 11:55:41.000 | 164 |
| 1755172542 | 2025-08-14 11:55:42.000 | 183 |
| 1755172543 | 2025-08-14 11:55:43.000 | 68 |
| 1755172544 | 2025-08-14 11:55:44.000 | 164 |
| 1755172545 | 2025-08-14 11:55:45.000 | 94 |
| 1755172546 | 2025-08-14 11:55:46.000 | 181 |
| 1755172547 | 2025-08-14 11:55:47.000 | 189 |
| 1755172548 | 2025-08-14 11:55:48.000 | 4 |
| 1755172549 | 2025-08-14 11:55:49.000 | 198 |
| 1755172550 | 2025-08-14 11:55:50.000 | 148 |
| 1755172551 | 2025-08-14 11:55:51.000 | 132 |
| 1755172552 | 2025-08-14 11:55:52.000 | 174 |
| 1755172553 | 2025-08-14 11:55:53.000 | 393 |
| 1755172554 | 2025-08-14 11:55:54.000 | 316 |
| 1755172555 | 2025-08-14 11:55:55.000 | 570 |
| 1755172556 | 2025-08-14 11:55:56.000 | 65 |
| 1755172557 | 2025-08-14 11:55:57.000 | 208 |
| 1755172558 | 2025-08-14 11:55:58.000 | 313 |
| 1755172559 | 2025-08-14 11:55:59.000 | 316 |
| 1755172560 | 2025-08-14 11:56:00.000 | 427 |
| 1755172561 | 2025-08-14 11:56:01.000 | 165 |
| 1755172562 | 2025-08-14 11:56:02.000 | 233 |
| 1755172563 | 2025-08-14 11:56:03.000 | 318 |
| 1755172564 | 2025-08-14 11:56:04.000 | 234 |
| 1755172565 | 2025-08-14 11:56:05.000 | 275 |
| 1755172566 | 2025-08-14 11:56:06.000 | 165 |
| 1755172567 | 2025-08-14 11:56:07.000 | 281 |
| 1755172568 | 2025-08-14 11:56:08.000 | 309 |
| 1755172569 | 2025-08-14 11:56:09.000 | 263 |
| 1755172570 | 2025-08-14 11:56:10.000 | 292 |
| 1755172571 | 2025-08-14 11:56:11.000 | 268 |
| 1755172572 | 2025-08-14 11:56:12.000 | 243 |
| 1755172573 | 2025-08-14 11:56:13.000 | 227 |
| 1755172574 | 2025-08-14 11:56:14.000 | 230 |
| 1755172575 | 2025-08-14 11:56:15.000 | 212 |
| 1755172576 | 2025-08-14 11:56:16.000 | 116 |
| 1755172577 | 2025-08-14 11:56:17.000 | 159 |
| 1755172578 | 2025-08-14 11:56:18.000 | 52 |
| 1755172579 | 2025-08-14 11:56:19.000 | 70 |
| 1755172580 | 2025-08-14 11:56:20.000 | 20 |
| 1755172581 | 2025-08-14 11:56:21.000 | 29 |
| 1755172582 | 2025-08-14 11:56:22.000 | 24 |
| 1755172602 | 2025-08-14 11:56:42.000 | 1 |
先程のエラーログの集計と合わせると以下のようになります。
| 時間帯 | 接続試行数 | 接続エラー発生数 |
|---|---|---|
| 2025-08-14 11:55:19.000 | 134 | 0 |
| 2025-08-14 11:55:20.000 | 826 | 0 |
| 2025-08-14 11:55:21.000 | 261 | 0 |
| 2025-08-14 11:55:22.000 | 110 | 0 |
| 2025-08-14 11:55:23.000 | 97 | 88 |
| 2025-08-14 11:55:24.000 | 186 | 171 |
| 2025-08-14 11:55:25.000 | 274 | 171 |
| 2025-08-14 11:55:26.000 | 230 | 47 |
| 2025-08-14 11:55:27.000 | 221 | 377 |
| 2025-08-14 11:55:28.000 | 430 | 72 |
| 2025-08-14 11:55:29.000 | 188 | 222 |
| 2025-08-14 11:55:30.000 | 329 | 123 |
| 2025-08-14 11:55:31.000 | 187 | 105 |
| 2025-08-14 11:55:32.000 | 276 | 187 |
| 2025-08-14 11:55:33.000 | 213 | 51 |
| 2025-08-14 11:55:34.000 | 195 | 74 |
| 2025-08-14 11:55:35.000 | 95 | 18 |
| 2025-08-14 11:55:36.000 | 184 | 400 |
| 2025-08-14 11:55:37.000 | 556 | 120 |
| 2025-08-14 11:55:38.000 | 224 | 1571 |
| 2025-08-14 11:55:39.000 | 1581 | 490 |
| 2025-08-14 11:55:40.000 | 630 | 133 |
| 2025-08-14 11:55:41.000 | 164 | 6 |
| 2025-08-14 11:55:42.000 | 183 | 27 |
| 2025-08-14 11:55:43.000 | 68 | 86 |
| 2025-08-14 11:55:44.000 | 164 | 0 |
| 2025-08-14 11:55:45.000 | 94 | 26 |
| 2025-08-14 11:55:46.000 | 181 | 76 |
| 2025-08-14 11:55:47.000 | 189 | 1 |
| 2025-08-14 11:55:48.000 | 4 | 5 |
| 2025-08-14 11:55:49.000 | 198 | 75 |
| 2025-08-14 11:55:50.000 | 148 | 1 |
| 2025-08-14 11:55:51.000 | 132 | 83 |
| 2025-08-14 11:55:52.000 | 174 | 282 |
| 2025-08-14 11:55:53.000 | 393 | 215 |
| 2025-08-14 11:55:54.000 | 316 | 447 |
| 2025-08-14 11:55:55.000 | 570 | 21 |
| 2025-08-14 11:55:56.000 | 65 | 60 |
| 2025-08-14 11:55:57.000 | 208 | 236 |
| 2025-08-14 11:55:58.000 | 313 | 163 |
| 2025-08-14 11:55:59.000 | 316 | 357 |
| 2025-08-14 11:56:00.000 | 427 | 69 |
| 2025-08-14 11:56:01.000 | 165 | 130 |
| 2025-08-14 11:56:02.000 | 233 | 259 |
| 2025-08-14 11:56:03.000 | 318 | 85 |
| 2025-08-14 11:56:04.000 | 234 | 166 |
| 2025-08-14 11:56:05.000 | 275 | 85 |
| 2025-08-14 11:56:06.000 | 165 | 166 |
| 2025-08-14 11:56:07.000 | 281 | 265 |
| 2025-08-14 11:56:08.000 | 309 | 99 |
| 2025-08-14 11:56:09.000 | 263 | 254 |
| 2025-08-14 11:56:10.000 | 292 | 132 |
| 2025-08-14 11:56:11.000 | 268 | 146 |
| 2025-08-14 11:56:12.000 | 243 | 86 |
| 2025-08-14 11:56:13.000 | 227 | 199 |
| 2025-08-14 11:56:14.000 | 230 | 75 |
| 2025-08-14 11:56:15.000 | 212 | 26 |
| 2025-08-14 11:56:16.000 | 116 | 6 |
| 2025-08-14 11:56:17.000 | 159 | 45 |
| 2025-08-14 11:56:18.000 | 52 | 19 |
| 2025-08-14 11:56:19.000 | 70 | 1 |
| 2025-08-14 11:56:20.000 | 20 | 0 |
| 2025-08-14 11:56:21.000 | 29 | 0 |
| 2025-08-14 11:56:22.000 | 24 | 0 |
| 2025-08-14 11:56:42.000 | 1 | 0 |
UTC11:55:20台の826接続は耐えてるので、やはりクラスターあたりの最大接続バーストキャパシティは接続レートに対するバーストキャパシティで間違い無いように見えます。その後11:55:23台から接続エラーが発生しだしているので、バーストキャパシティを使い切って100接続/秒しか処理できなくなったのでしょうかね。最終的に接続エラーが収まったのは11:56:20台で、この頃には接続試行数は20まで下がっています。
まとめ
DSQLの可用性について検証してみました。今回は実行したSQLがpg_sleepのみでなので、DSQLのルーター → クエリプロセッサーまでで処理が完了し、クエリプロセッサー → ストレージへのアクセスは発生していないと考えられます。実際のワークロードではストレージも利用することになるので、あくまで今回の検証結果は参考情報となりますが、それでもルーターやクエリプロセッサーがスパイクアクセスに対する耐性を備えていることは確認できました。これだけ同時接続数への耐性があれば、Lambdaと組み合わせて問題が発生することも無さそうです。
同時接続数以外の部分では色々と考慮すべき点がありそうですが、その辺もおいおい検証していきたいと思います。








