
ヘッドレス CMS が速い理由を実測する: 検索と絞り込みを Contentful 側に任せる
はじめに
ヘッドレス CMS は速いと聞くことがあります。しかし、何がどう速いのかは、概念的な説明になりがちです。
たとえば Web サイトで記事一覧を作るとき、検索や絞り込みを付けたい一方で、表示速度を落としたくないという要件が出てきます。さらに、記事数が将来増えても困らない設計にしたい、という要件もよく出てきます。このとき重要なのは、フィルタリング処理をどこで実行するか です。アプリ側で全件を受け取り、アプリ側でフィルタリングする方法のほか、「データを持つ側」でフィルタリングし必要な分だけ返してもらう方法 も考えられます。後者は、Web 設計におけるマイクロサービス化の考え方と相性が良いです。データを持つヘッドレス CMS が検索や絞り込みの責務を担い、呼び出し側は必要最小限を要求します。(これは SQL の WHERE 句をデータベースに任せる発想と似ています。)
本記事の狙いは Contentful を例として使い、フィルタリング処理を「データを持つ側」に任せるメリット を実測値で確認することです。
ヘッドレス CMS とは
ヘッドレス CMS とは、コンテンツの管理と表示を分離する CMS です。管理画面でコンテンツを編集し、Web アプリケーションは API を通じてコンテンツを取得して表示します。
Contentful とは
Contentful とは、ヘッドレス CMS を SaaS として提供するサービスです。管理画面で Content Model を定義し、Entry を作成して公開できます。Contentful の Content Delivery API (以下、CDA) とは、公開済みコンテンツを取得するための read-only の REST API です。アプリケーションは HTTP で JSON を取得し、クエリパラメータで検索や返却フィールドの制御ができます。
対象読者
- ヘッドレス CMS のメリットを、実測ベースで理解したい方
- 記事一覧に検索や絞り込みを付けたいが、設計の勘所が分からない方
- 全件取得してフィルタリングする実装が、将来どの程度の負荷になり得るか不安な方
参考
検証方針
本記事では、CDA の次の 2 つの機能を使います。
- フィルタリング:
fields.title[match]によるフィールド単位の全文検索 - フィールド選択:
selectによるレスポンスのフィールド絞り込み
ヘッドレス CMS の強みを確認するため、ベンチマークを行います。今回は処理完了までの時間を比較します。ここでの処理完了とは、HTTP 取得と JSON parse が終わり、配列として扱える状態になった時点までの時間を指します。
比較対象
比較する方法は 2 つです。
-
手法 A
全件取得してアプリ側でフィルタリングします。100 件をまとめて取得し、titleをアプリ側でincludes判定します。一覧に不要なbodyも取得します。 -
手法 B
ヘッドレス CMS 側でフィルタリングして必要フィールドだけ取得します。fields.title[match]でヘッドレス CMS 側検索を行い、selectでtitleとslugだけを返します。
検証用データの投入
CDA は公開済みコンテンツを配信します。したがって、比較対象の Entry を publish 済みにしておく必要があります。
Content type の作成
Content type は blogPost とし、フィールドは次の 3 つにします。
- title (Short text)
- slug (Short text)
- body (Long text)
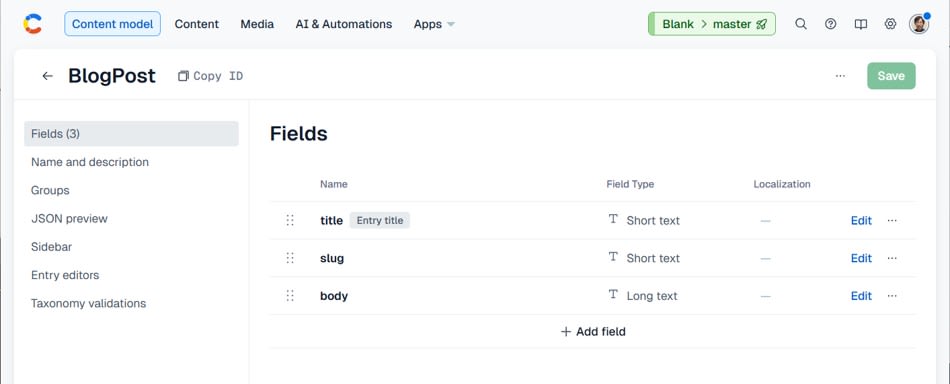
body は一覧では使いません。ただし差を出しやすくするため、検証用データでは body を大きくします。
セットアップ
TypeScript を実行するため、tsx を使います。
npm init -y
npm i contentful-management dotenv
npm i -D tsx typescript @types/node
環境変数の設定
.env を作成します。
CF_SPACE_ID=xxxxx
CF_ENV=master
CF_LOCALE=en-US
CF_MANAGEMENT_TOKEN=xxxxx
CF_CONTENT_TYPE=blogPost
CF_TOTAL=100
CF_FROM=1
CF_HIT_COUNT=50
CF_KEYWORD=NEEDLE
CF_BODY_CHARS=20000
CF_LOCALE は Space の Settings > Locales の内容に合わせてください。
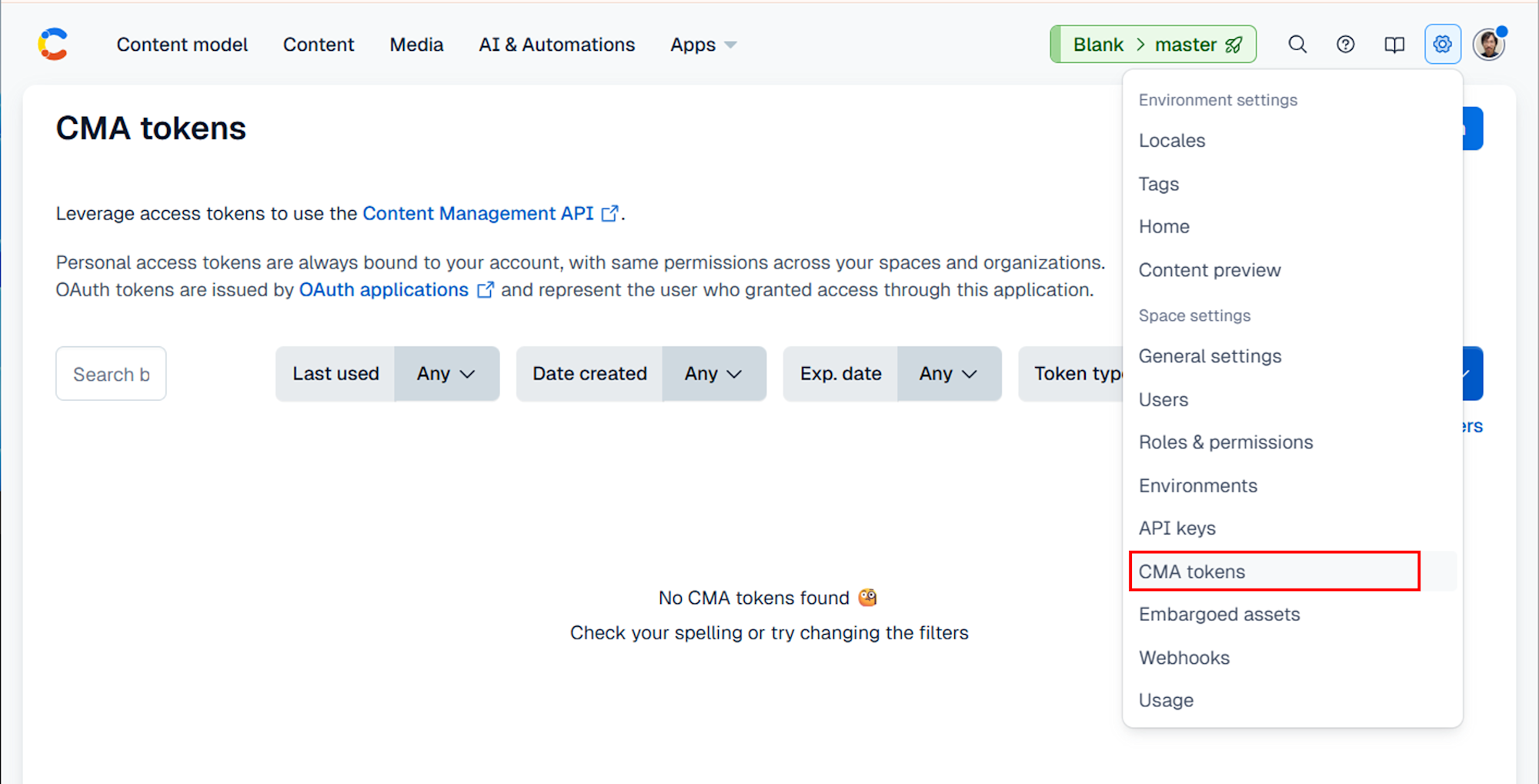
また、CF_MANAGEMENT_TOKEN は Space Settings > CMA tokens から作成します。
データ投入スクリプト (seed.ts)
import "dotenv/config";
import { createClient } from "contentful-management";
const {
CF_SPACE_ID,
CF_ENV = "master",
CF_LOCALE = "en-US",
CF_MANAGEMENT_TOKEN,
CF_CONTENT_TYPE = "blogPost",
CF_TOTAL = "100",
CF_FROM = "1",
CF_HIT_COUNT = "50",
CF_KEYWORD = "NEEDLE",
CF_BODY_CHARS = "20000",
} = process.env;
if (!CF_SPACE_ID || !CF_MANAGEMENT_TOKEN) {
throw new Error("CF_SPACE_ID and CF_MANAGEMENT_TOKEN are required");
}
const TOTAL = Number(CF_TOTAL);
const FROM = Number(CF_FROM);
const HIT_COUNT = Number(CF_HIT_COUNT);
const BODY_CHARS = Number(CF_BODY_CHARS);
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
function makeBody(n: number): string {
const chunk = "Lorem ipsum dolor sit amet. ";
let s = "";
while (s.length < n) s += chunk;
return s.slice(0, n);
}
async function main(): Promise<void> {
const client = createClient({ accessToken: CF_MANAGEMENT_TOKEN });
const space = await client.getSpace(CF_SPACE_ID);
const env = await space.getEnvironment(CF_ENV);
const body = makeBody(BODY_CHARS);
for (let i = FROM; i <= TOTAL; i++) {
const slug = `post-${String(i).padStart(4, "0")}`;
// `fields.title[match]` は全文検索であり、厳密な部分一致ではありません。
// 本検証ではヒットを安定させるため、キーワードを title の先頭に置きます。
const title = i <= HIT_COUNT ? `${CF_KEYWORD} post ${i}` : `post ${i}`;
const entry = await env.createEntry(CF_CONTENT_TYPE, {
fields: {
title: { [CF_LOCALE]: title },
slug: { [CF_LOCALE]: slug },
body: { [CF_LOCALE]: body },
},
});
await entry.publish();
// 制限を回避するための待機です。
await sleep(200);
process.stdout.write(".");
}
process.stdout.write("\nDone.\n");
}
main().catch((e) => {
console.error(e);
process.exitCode = 1;
});
実行します。
npx tsx seed.ts
....................................................................................................
Done.
データが挿入されていることをコンソールで確認します。
処理完了までの時間計測
A と B を同条件で実行し、処理完了までの時間を比較します。CDA にはレート制限がありますが、今回のような少数回の計測では問題になりにくいです。
環境変数の設定
.env に追記します。
CF_DELIVERY_TOKEN=xxxxx
CF_RUNS=5
CF_DELIVERY_TOKEN を取得するには、 Space Settings > API keys から API キーを作成します。Content Delivery API の値を使用します。
計測スクリプト (bench.ts)
全件取得はレスポンスサイズ上限に当たる場合があるため、skip と limit によるページングで取得します。
.env に次を追記します。
CF_LIMIT=100
CF_PAGE_SIZE=100
bench.ts は次の通りです。
import "dotenv/config";
import { performance } from "node:perf_hooks";
type EntryLike = {
fields?: {
title?: string;
slug?: string;
};
};
const {
CF_SPACE_ID,
CF_ENV = "master",
CF_DELIVERY_TOKEN,
CF_CONTENT_TYPE = "blogPost",
CF_KEYWORD = "NEEDLE",
CF_RUNS = "5",
CF_LIMIT = "100",
CF_PAGE_SIZE = "100",
} = process.env;
if (!CF_SPACE_ID || !CF_DELIVERY_TOKEN) {
throw new Error("CF_SPACE_ID and CF_DELIVERY_TOKEN are required");
}
const RUNS = Number(CF_RUNS);
const LIMIT = Number(CF_LIMIT);
const PAGE_SIZE = Number(CF_PAGE_SIZE);
const baseUrl = `https://cdn.contentful.com/spaces/${CF_SPACE_ID}/environments/${CF_ENV}/entries`;
const authHeader = { Authorization: `Bearer ${CF_DELIVERY_TOKEN}` };
async function fetchJson(url: string): Promise<any> {
const res = await fetch(url, { headers: authHeader });
if (!res.ok) throw new Error(`HTTP ${res.status}: ${await res.text()}`);
return res.json();
}
function urlWith(params: Record<string, string | number>): string {
const u = new URL(baseUrl);
for (const [k, v] of Object.entries(params)) u.searchParams.set(k, String(v));
return u.toString();
}
function median(values: number[]): number {
const a = [...values].sort((x, y) => x - y);
const mid = Math.floor(a.length / 2);
return a.length % 2 ? a[mid] : (a[mid - 1] + a[mid]) / 2;
}
async function runA(): Promise<{ ms: number; hits: number }> {
const t0 = performance.now();
const itemsAll: EntryLike[] = [];
for (let skip = 0; skip < LIMIT; skip += PAGE_SIZE) {
const limit = Math.min(PAGE_SIZE, LIMIT - skip);
const url = urlWith({
content_type: CF_CONTENT_TYPE!,
limit,
skip,
order: "sys.createdAt",
});
const data = await fetchJson(url);
const items = (data.items ?? []) as EntryLike[];
itemsAll.push(...items);
}
const hits = itemsAll.filter((e) => (e.fields?.title ?? "").includes(CF_KEYWORD!)).length;
const t1 = performance.now();
return { ms: t1 - t0, hits };
}
async function runB(): Promise<{ ms: number; hits: number }> {
const url = urlWith({
content_type: CF_CONTENT_TYPE!,
limit: LIMIT,
"fields.title[match]": CF_KEYWORD!,
select: "sys.id,fields.title,fields.slug",
});
const t0 = performance.now();
const data = await fetchJson(url);
const items = (data.items ?? []) as EntryLike[];
const t1 = performance.now();
return { ms: t1 - t0, hits: items.length };
}
async function bench(
name: string,
fn: () => Promise<{ ms: number; hits: number }>,
): Promise<void> {
const times: number[] = [];
let hits = 0;
for (let i = 0; i < RUNS; i++) {
const r = await fn();
times.push(r.ms);
hits = r.hits;
}
console.log(`- ${name}`);
console.log(` - median: ${Math.round(median(times))} ms`);
console.log(` - runs: ${times.map((t) => Math.round(t)).join(", ")} ms`);
console.log(` - hits: ${hits}`);
}
async function main(): Promise<void> {
console.log("# Results (ms)");
await bench("A: 全件取得してアプリ側でフィルタリング", runA);
await bench("B: ヘッドレス CMS 側でフィルタリング + select", runB);
}
main().catch((e) => {
console.error(e);
process.exitCode = 1;
});
実行します。
npx tsx bench.ts
出力は次のようになりました。
# Results (ms)
- A: 全件取得してアプリ側でフィルタリング
- median: 28 ms
- runs: 495, 30, 28, 28, 20 ms
- hits: 50
- B: ヘッドレス CMS 側でフィルタリング + select
- median: 10 ms
- runs: 295, 11, 9, 10, 9 ms
- hits: 50
結果
中央値を比較すると、B は A よりも短い時間で処理が完了しました。
| 取得方法 | 時間 (ms, median) |
|---|---|
| A: 全件取得してアプリ側でフィルタリング | 28 |
| B: ヘッドレス CMS 側でフィルタリング + select | 10 |
中央値ベースでは、B は A の約 2.8 倍速くなりました。
なお、どちらの方法でも最初の 1 回目が大きな値になっています。DNS 解決や TLS ハンドシェイク、HTTP 接続の確立などが初回に集中するためです。本記事では、その影響を避けるため、中央値を採用しました。
追実験: 記事数を増やして伸び方を確認する
100 件だけの比較では、たまたま小さな差が出ただけなのか、件数が増えるほど差が広がる構造なのかを判断しにくいです。そこで追実験では、記事数を 500 件、1000 件に増やし、処理完了までの時間がどのように増えるかを観察します。狙いは、
事前に決める条件
この観察を分かりやすくするため、ヒット件数
追加データを投入する
100 件のデータがある前提で、101 件目以降を追加投入して 1000 件に増やします。seed.ts はすでに CF_FROM と CF_TOTAL で作成範囲を指定でき、CF_HIT_COUNT でキーワードを入れる件数を固定できます。
.env を次のように変更します。
CF_TOTAL=1000
CF_FROM=101
CF_HIT_COUNT=50
実行します。
npx tsx seed.ts
この手順では、101 件目以降はキーワードを含まない title で作られます。そのため、ヒット件数は 50 件のままになります。
計測を 500 件、1000 件で実行する
bench.ts は CF_LIMIT と CF_PAGE_SIZE を読み取り、A はページングして合計 CF_LIMIT 件を取得します。B は fields.title[match] により 50 件だけ返るため、CF_LIMIT を大きくしても返却件数は増えません。
まず 500 件として計測します。
CF_LIMIT=500
CF_PAGE_SIZE=100
npx tsx bench.ts
# Results (ms)
- A: 全件取得してアプリ側でフィルタリング
- median: 146 ms
- runs: 2126, 125, 122, 158, 146 ms
- hits: 50
- B: ヘッドレス CMS 側でフィルタリング + select
- median: 10 ms
- runs: 240, 10, 9, 11, 10 ms
- hits: 50
次に 1000 件として計測します。
CF_LIMIT=1000
CF_PAGE_SIZE=100
npx tsx bench.ts
結果は次のようになりました。
# Results (ms)
- A: 全件取得してアプリ側でフィルタリング
- median: 225 ms
- runs: 2460, 242, 225, 224, 215 ms
- hits: 50
- B: ヘッドレス CMS 側でフィルタリング + select
- median: 10 ms
- runs: 555, 12, 10, 8, 9 ms
- hits: 50
追実験の結果
結果を表とグラフにまとめます。
| 記事数 |
A: 全件取得してアプリ側でフィルタリング (ms, median) | B: ヘッドレス CMS 側でフィルタリング + select (ms, median) |
|---|---|---|
| 100 | 28 | 10 |
| 500 | 146 | 10 |
| 1000 | 225 | 10 |
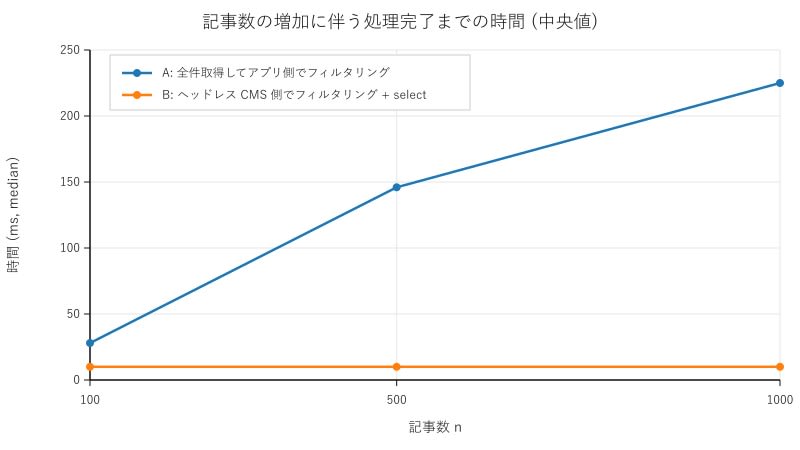
A は記事数を 100 件から 500 件、1000 件へ増やすと、中央値が 28 ms、146 ms、225 ms へ増加しました。つまり、この実験条件では、記事数 CF_PAGE_SIZE=100 としているため、取得対象が 500 件のときは 5 回、1000 件のときは 10 回の HTTP リクエストを行っています。
一方で B は、記事数を 100 件、500 件、1000 件へ増やしても、中央値が 10 ms 前後 (10 ms、10 ms、10 ms) でした。つまり、この実験条件では、記事数
考察: なぜデータを持つ側に任せると速くなりやすいのか
増え方の違いが生まれた理由として考えられること
A の処理時間が増えた理由としては、次の要因が考えられます。
まず、A は記事数
一方で B は、ヒット件数 select により返すフィールドも title と slug に絞っています。この条件では、
オーダー記号の説明との対応関係
この実験結果は、背景で述べた
ただし、今回測ったのは処理完了までの時間であり、ネットワークや接続確立の定数項も含まれます。そのため、本記事では
まとめ
ヘッドレス CMS が速いと言われる理由の 1 つは、検索や絞り込みの処理をデータを持つ側に任せられることです。今回の検証では、全件取得してアプリ側でフィルタリングする方法は記事数 select で返却フィールドを絞る方法は、記事数を増やしても処理時間がほとんど増えませんでした。 記事一覧に検索や絞り込みを付ける場合は、まず API 側のフィルタリングとフィールド選択を検討すると安全です。








