【Copilot Studio】ナレッジでファイルに基づく回答を試してみた:Web検索オフとの比較も
はじめに
こんにちは、けーまです。
エージェントを作ったあと、次に出てくる要望が「自社の資料に基づいて答えてほしい」です。一般知識だけで答えるエージェントは、社内の数値や独自ドキュメントの内容には答えられません。Copilot Studio では「ナレッジ」を追加することで、アップロードした資料を根拠にした回答(グラウンディング)ができます。
そこで本記事では、Copilot Studio のナレッジ機能を取り上げ、2026年6月時点で実機検証しました。架空SaaS企業3社のKPIデータ(docx)をアップロードし、資料に基づく根拠付き回答ができるかを確認します。あわせて、既定でオンになっているWeb検索をオフにして、資料だけに回答を限定した場合との違いも比較します。資料に基づいて回答するエージェントを作りたい方の参考にしていただければと思います。
本記事は、Copilot Studio でエージェントを作るシリーズの第2回です。
シリーズ全体では「収集 → 集計 → グラフ → 示唆 → 資料化」を一気通貫で行うエージェントを目指しており、本記事はその最初のステップ「収集(ナレッジ)」を扱います。
対象読者:Copilot Studio で、自社の資料(ファイル)に基づいて回答するエージェントを作りたい方
シリーズ記事一覧
| 回 | テーマ | 記事 |
|---|---|---|
| 第1回 | 最初のエージェント | 初めてのエージェントを作ってみた |
| 第2回 | ナレッジ(本記事) | (本記事) |
前回(第1回)でエージェントを作成し、指示を与えてテストしました。今回は、そのエージェントに自社資料を読み込ませて、根拠付きで回答できるようにします。
今回やること
- 架空SaaS3社のKPI比較レポート(docx)をナレッジとしてアップロード
- Dataverse へのインデックス化を待ち、根拠付き回答をテスト
- Web検索のオン/オフで回答ソースの違いを比較
ナレッジとは
ナレッジは、エージェントが回答の根拠として使える情報ソースです。追加方法は複数あります。
- ファイルアップロード: Word(doc/docx)・Excel(xls/xlsx)・PowerPoint(ppt/pptx)・PDF・テキスト(txt/md/log)・HTML・CSV・XML・JSON・YAML など、テキストベースの形式に対応。画像・音声・動画・実行ファイルは非対応で、画像は PDF に埋め込まれた注釈(alt-text)付きのものだけ扱えます(alt-text は画像の内容を説明するテキスト)
- 外部ソース接続: SharePoint / OneDrive / 公開Webサイト / Dataverse(テーブル)/ コネクタ経由のエンタープライズデータ(Microsoft Search でインデックスした組織データ。Salesforce・ServiceNow・Confluence・Zendesk などのナレッジ記事を含む)
ファイルアップロードの上限は、1ファイル最大512MB、1エージェントあたり最大500ファイルです。ただし実際にアップロードできる数は、環境の Dataverse のファイルストレージ容量にも依存します。
Image, video, executables, and audio files can't be used as uploaded documents.
Images are only supported when they're embedded in PDF files.
引用元: Upload files as a knowledge source | Microsoft Learn
ファイルをアップロードすると Dataverse に格納され、自動でインデックス化されます。テスト時にエージェントがナレッジを検索し、ヒットした内容を参照ソースとして引用しながら回答します。
Copilot Studio agents require Dataverse search to use this knowledge source. If you can't add a Dataverse-enabled file to an agent, ask your administrator to turn on Dataverse search in your environment.
引用元: Unstructured data as a knowledge source | Microsoft Learn
今回はもっともシンプルな「ファイルアップロード」を試します。
ステップ1: ナレッジ用のファイルを用意する
検証用に、架空SaaS企業3社の四半期KPIデータをまとめた docx ファイルを用意しました。
| 企業名 | ARR(百万円) | NRR(%) | 解約率(月次%) | 営業利益率(%) | 顧客数(社) | ARPA(万円/月) |
|---|---|---|---|---|---|---|
| CloudNova | 1,800 | 118 | 1.2 | 12.5 | 1,250 | 12.0 |
| StreamForge | 1,150 | 104 | 2.1 | -3.0 | 2,400 | 4.0 |
| Datapeak | 2,600 | 126 | 0.8 | 18.4 | 640 | 33.9 |
すべて架空のデータです。実在する企業とは一切関係ありません。
ステップ2: ファイルをアップロードする
ナレッジタブから「ナレッジの追加」をクリックし、ファイルのアップロードを選びます。ドラッグ&ドロップまたは「デバイスから参照」でファイルを選択できます。
2025Q2-saas-kpi-summary.docx を選択し、「エージェントに追加する」を押します。
ステップ3: インデックス化の完了を確認する
ナレッジタブに戻ると、アップロードしたファイルが一覧に表示されます。「状態」列にスピナーが出ている間はインデックス化中です。数分待つと緑のチェックマークに変わり、エージェントが検索・引用できる状態になります。
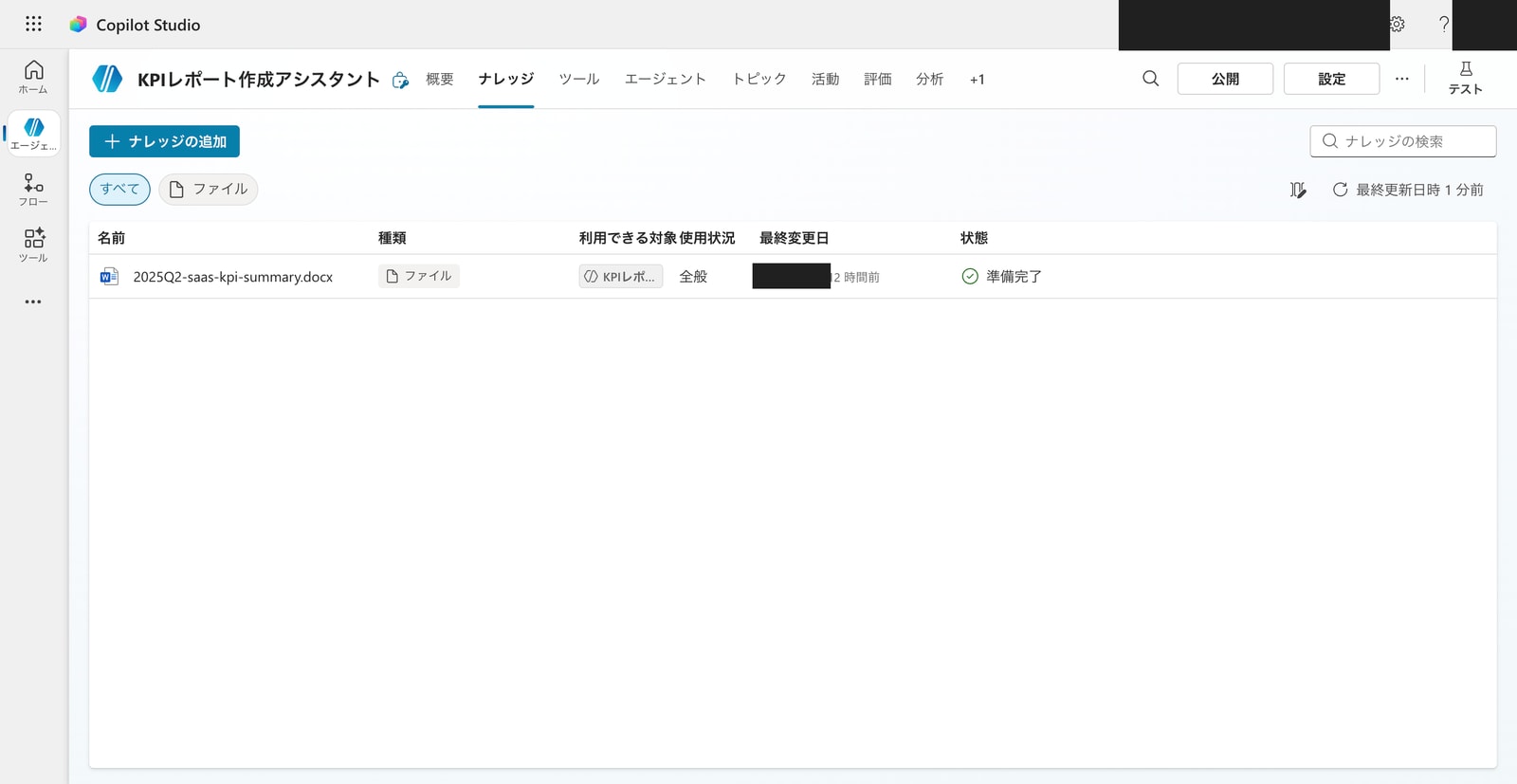
一覧には「名前・種類・利用できる対象・使用状況・最終変更日・状態」が表示されます。「利用できる対象」は、このナレッジをどのエージェントが使えるかを示しています。
ステップ4: 根拠付き回答をテストする
テストチャットで、アップロードしたファイルの内容について質問してみます。
Datapeakの営業利益率は?
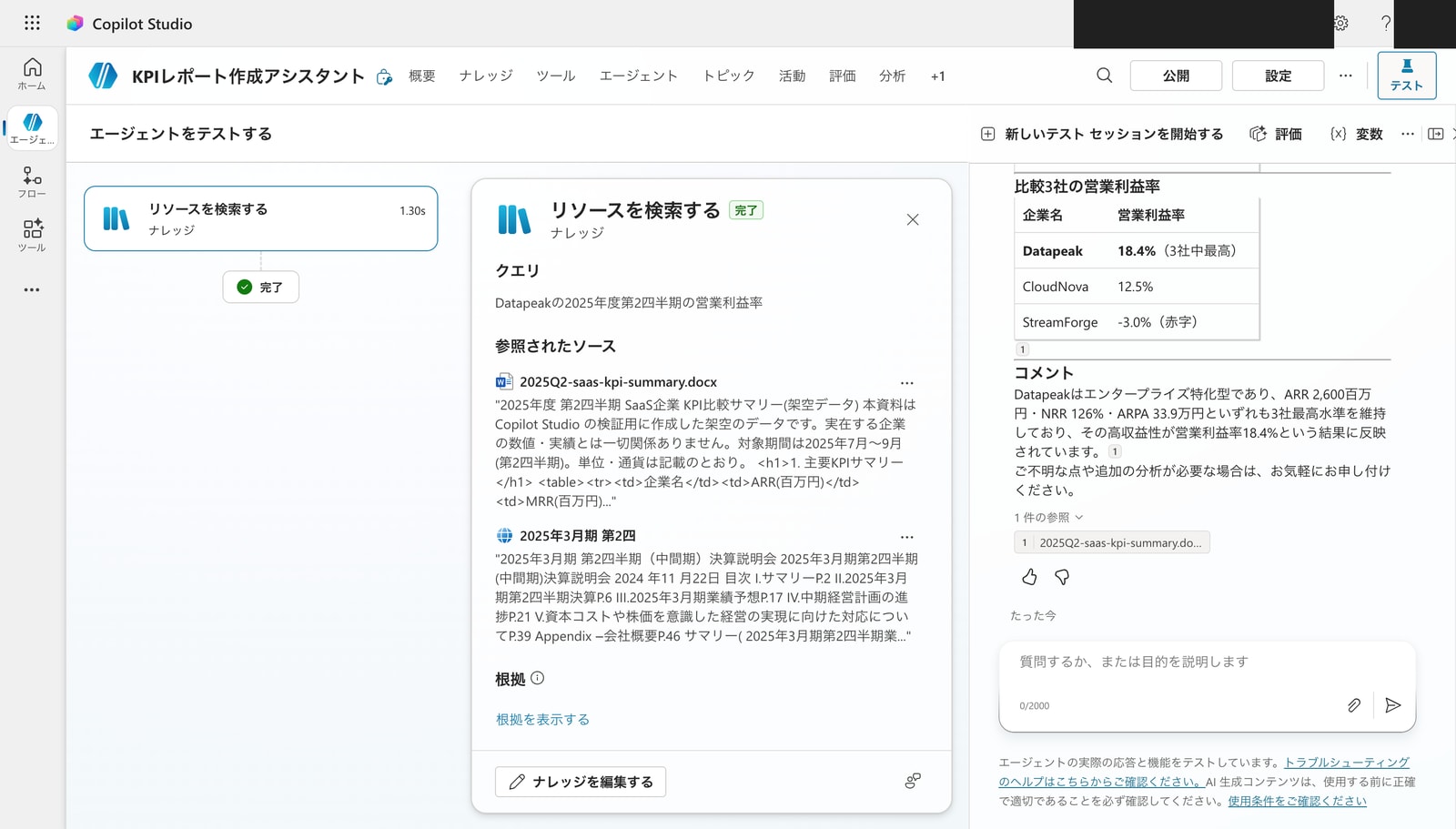
Datapeak の営業利益率 18.4% を正確に回答し、さらに CloudNova(12.5%)・StreamForge(-3.0%)との比較表やコメントも添えてくれました。回答の下には「参照されたソース」として 2025Q2-saas-kpi-summary.docx が明示されています。
ファイルの内容に基づいた根拠付き回答(グラウンディング)が機能しています。
Web検索オンの注意点
ここで1つ気づいたことがあります。私の環境では、作成直後からWeb検索が有効になっていました。検索アクティビティを確認すると、docx だけでなくWeb上の実在する決算資料(公開されている企業の決算説明会資料など)も参照ソース候補に含まれていました。
今回は最終回答には影響しませんでしたが、社内データだけで回答させたい場面では意図しない外部情報が混入するリスクがあります。
ステップ5: Web検索をオフにして比較する
Web検索のオン/オフは、概要画面のナレッジセクション(または「生成 AI」設定)で切り替えられます。このWeb検索(「Webの情報を使用する」)の設定は、生成オーケストレーションが有効なエージェントでのみ利用できます。
You can find the Use information from the web setting on the Generative AI settings page. You can also find the Web Search setting in the Knowledge section of the agent's Overview page. This setting requires that the agent has generative orchestration turned on.
引用元: Knowledge sources summary | Microsoft Learn
「Web 検索」のトグルをオフにします。私の環境では、この変更はその場で反映されました(保存操作は不要でした)。
Web検索オフで同じ質問をテスト
Web検索をオフにした状態で、同じ質問「Datapeakの営業利益率は?」をテストします。
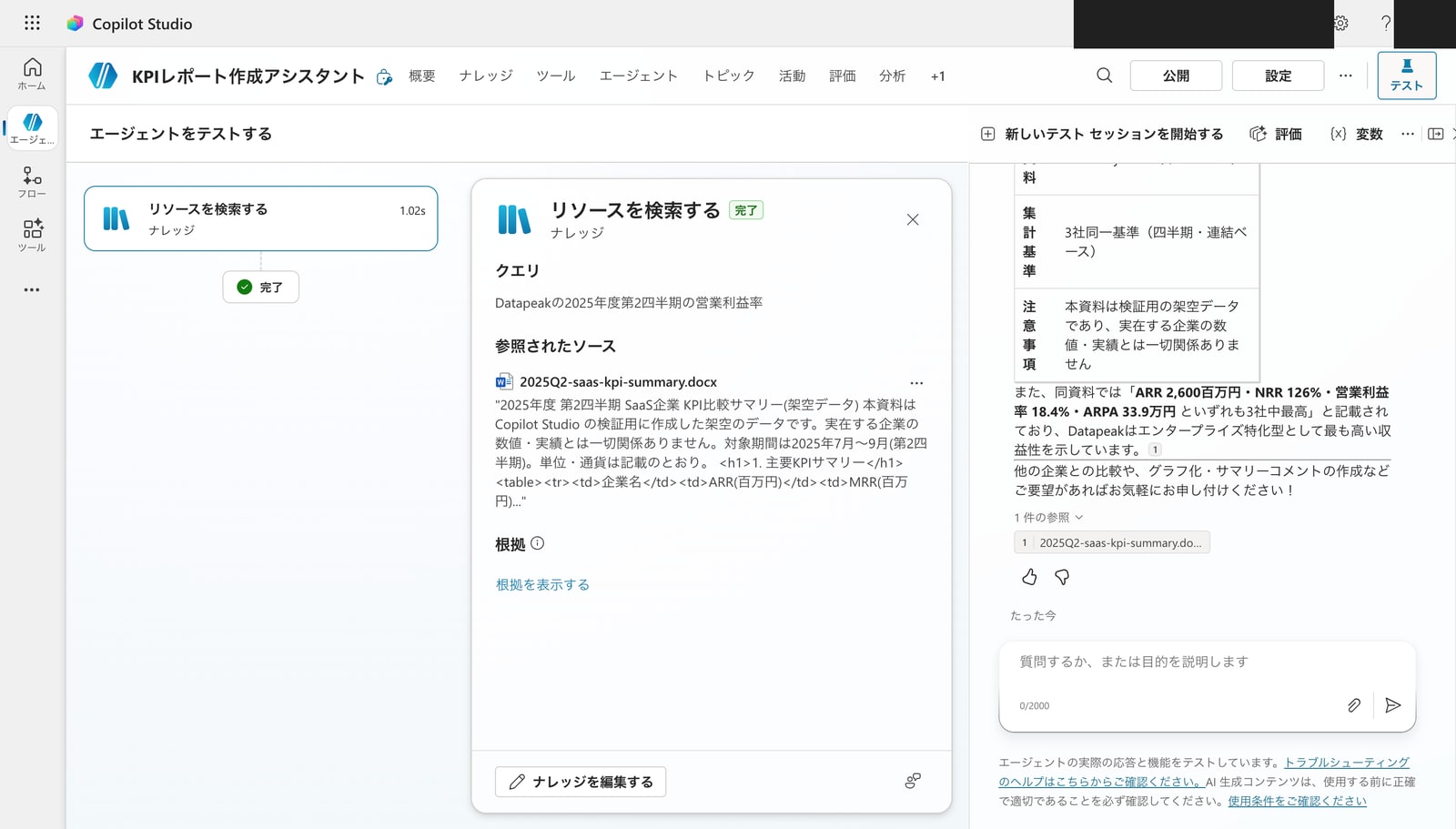
参照されたソースが docx ファイルのみ に限定されました。Web上の外部資料は一切参照されていません。回答内容もアップロードした資料のデータだけに基づいています。
Web検索 オン vs オフの比較
| Web検索 オン | Web検索 オフ | |
|---|---|---|
| 参照ソース | アップロードファイル + 公開Web | アップロードファイルのみ |
| 外部データの混入 | あり得る | なし |
| 用途 | 一般知識も含めて幅広く回答させたい場合 | 社内資料・特定データだけで回答させたい場合 |
社内の機密データや、今回のように架空のデータなど外部情報と混ざると困るケースでは、Web検索オフが安全です。逆に、公開情報を補完的に使いたい場合はオンのまま活用できます。
今回のつまずきポイント
- インデックス化に数分かかる: アップロード直後にテストすると、ナレッジが見つからず一般知識で回答されます。ナレッジ一覧の「状態」が緑チェックになるのを確認してからテストしましょう。
- 対応ファイル形式に注意: テキストベースのファイルが対象です。画像・動画・音声・実行ファイルはアップロードできません(画像は PDF に埋め込まれた注釈(alt-text)付きのものだけ扱えます)。
- Web検索が有効になっていることがある: 私の環境では、作成直後からWeb検索が有効でした。社内資料だけで回答させたい場合は明示的にオフにしましょう。なお、この設定は生成オーケストレーションが有効なときに利用できます。
まとめ
ファイルを1つアップロードするだけで、その内容を根拠にした回答が返ってくるようになりました。「参照されたソース」が明示されるため、どの資料に基づいた回答かが一目でわかります。Web検索のオン/オフで回答ソースの範囲をコントロールできるのも実用的です。