![[小ネタ]カラム数の多い CSV ファイルを JSON に変換してロードしてみた #SnowflakeDB](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-37f4322e7cca0bb66380be0a31ceace4/0886455fd66594d3e7d8947c9c7c844d/eyecatch_snowflake?w=3840&fm=webp)
[小ネタ]カラム数の多い CSV ファイルを JSON に変換してロードしてみた #SnowflakeDB
はじめに
Snowflake でカラム数の多いデータファイルをロードする機会があり、試した内容を記事としました。
本記事の結論
もしデータファイルを事前に変換できるなら、ロード前に JSON などの半構造化形式に変換し、VARIANT 型の単一カラムにロードすることで、ロード時のパフォーマンス向上が期待できます。
本記事で試すこと
カラム数の多いデータファイルのロードとして、以下の内容を試してみます。
- カラム数の多いデータファイル(CSV)を作成
- カラム数は最大で 20,000 としました
- データファイルのロード(COPY コマンドの実行)
- CSV 形式でのロード
- 最大 20,000 カラムのテーブルを定義
- データファイルを JSON 形式に変換し VARIANT 型の 1 カラムにロード
- ロード後 Snowflake 内で縦に展開
- ロード後 Snowflake 内で横に展開
- CSV 形式でのロード
事前準備
サンプルデータの作成やデータファイルの CSV から JSON への変換は Python で行いました。
上記など、検証時に使用する各種 Python 関数は以下の通りです。これらの関数の作成は生成 AI に対応してもらいました。
サンプルデータを作成する関数
import pandas as pd
import numpy as np
import sys
def generate_survey_data(rows: int, cols: int):
"""
引数に指定した行数と列数で、アンケート回答データのサンプルを生成し、CSVとして出力する関数
Args:
rows (int): 行数(回答者数)
cols (int): 列数(USERID + 質問数)
"""
if cols < 1:
print("列数は1以上を指定してください。")
return
# カラム名を生成
columns = ['USERID']
for i in range(1, cols):
columns.append(f'Q-{i}')
# USERID列を除くデータの作成(0, 1をランダムに生成)
data = np.random.randint(0, 2, size=(rows, cols - 1))
# DataFrameの作成
df = pd.DataFrame(data, columns=columns[1:])
# USERID列を追加
df.insert(0, 'USERID', range(1, rows + 1))
# CSVファイルとして出力
file_name = f'survey_data_{rows}x{cols}.csv'
df.to_csv(file_name, index=False)
print(f'CSVファイルを生成しました: {file_name}')
if __name__ == '__main__':
if len(sys.argv) != 3:
print("使い方: python generate_survey_data.py <行数> <列数>")
else:
try:
rows = int(sys.argv[1])
cols = int(sys.argv[2])
generate_survey_data(rows, cols)
except ValueError:
print("引数には整数を指定してください。")
大量カラムのテーブル用の DDL 文を作成する関数
import sys
def generate_ddl_to_file(table_name: str, num_questions: int, output_file: str):
"""
指定されたテーブル名と質問数でSnowflakeのCREATE TABLE DDLを生成し、
ファイルに書き出す関数。
Args:
table_name (str): 作成するテーブル名。
num_questions (int): 質問列(Q-1, Q-2...)の数。
output_file (str): DDL文を書き出すファイル名。
"""
if num_questions < 1:
print("エラー: 質問数には1以上の整数を指定してください。")
return
columns = ['\t"USERID" NUMBER(2,0)']
for i in range(1, num_questions + 1):
columns.append(f'\t"Q-{i}" NUMBER(1,0)')
columns_str = ",\n".join(columns)
ddl = f"create or replace TABLE {table_name} (\n{columns_str}\n);"
try:
with open(output_file, 'w') as f:
f.write(ddl)
print(f"DDLが正常に'{output_file}'に書き込まれました。")
except Exception as e:
print(f"エラー: ファイルへの書き込みに失敗しました。詳細: {e}")
if __name__ == "__main__":
# 引数の数をチェック (スクリプト名 + 質問数 = 2)
if len(sys.argv) != 2:
print("使い方: python generate_snowflake_ddl.py <質問数>")
sys.exit(1)
num_questions_str = sys.argv[1]
try:
num_questions = int(num_questions_str)
if num_questions < 1:
raise ValueError("質問数には1以上の整数を指定してください。")
# テーブル名と出力ファイル名を自動生成
total_columns = num_questions + 1
table_name = f'MY_SURVEY_TABLE_{total_columns}'
output_file = f'{table_name}.sql'
generate_ddl_to_file(table_name, num_questions, output_file)
except ValueError as e:
print(f"エラー: {e}")
CSVファイルをJSON形式に変換する関数
import csv
import json
import sys
def csv_to_json(csv_file_path, json_file_path):
"""
指定されたCSVファイルを読み込み、JSONファイルとして出力する関数。
Args:
csv_file_path (str): 読み込むCSVファイルのパス。
json_file_path (str): 出力するJSONファイルのパス。
"""
data = []
try:
with open(csv_file_path, 'r') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
data.append(row)
except FileNotFoundError:
print(f"エラー: ファイル '{csv_file_path}' が見つかりません。")
return
except Exception as e:
print(f"エラー: CSVファイルの読み込みに失敗しました。詳細: {e}")
return
try:
with open(json_file_path, 'w', encoding='utf-8') as json_file:
json.dump(data, json_file, indent=4, ensure_ascii=False)
print(f"'{csv_file_path}' を読み込み、'{json_file_path}' としてJSONファイルに変換しました。")
except Exception as e:
print(f"エラー: JSONファイルの書き込みに失敗しました。詳細: {e}")
if __name__ == '__main__':
if len(sys.argv) != 3:
print("使い方: python csv_to_json_converter.py <入力CSVファイル名> <出力JSONファイル名>")
sys.exit(1)
input_csv = sys.argv[1]
output_json = sys.argv[2]
csv_to_json(input_csv, output_json)
サンプルデータ
先の関数で、ここでは以下のデータファイルを作成しました。
# 1000カラム
$ python generate_sample_data.py 10 1000
CSVファイルを生成しました: survey_data_10x1000.csv
# 10,000カラム
$ python generate_sample_data.py 10 10000
CSVファイルを生成しました: survey_data_10x10000.csv
# 20,000カラム
$ python generate_sample_data.py 10 20000
CSVファイルを生成しました: survey_data_10x20000.csv
内容としては、それぞれ 10 レコードは変わらず、カラム数が 1000、10,000、20,000 となっています。一部ですが、データファイルの中身は以下の通りです。
USERID,Q-1,Q-2,・・・,Q-997,Q-998,Q-999
1,0,1,・・・,1,0,1
2,0,1,・・・,1,0,1
3,1,1,・・・,0,0,1
・
・
・
8,1,1,・・・,1,0,1
9,1,1,・・・,0,0,1
10,1,1,・・・,1,1,1
Snowflake 側:各種オブジェクトの作成
検証用のデータベース・スキーマ、内部ステージなどのオブジェクトを作成します。
CREATE DATABASE IF NOT EXISTS test_db;
USE SCHEMA PUBLIC;
--内部ステージを作成
CREATE STAGE my_int_stage;
ファイルフォーマットは2つ作成しました。PARSE_HEADER = TRUEとしているものは、スキーマ検出によるテーブル定義時に使用します。
--ファイルフォーマットを作成
CREATE OR REPLACE FILE FORMAT my_csv_format_parse_header
TYPE = CSV
FIELD_DELIMITER = ','
PARSE_HEADER = TRUE
EMPTY_FIELD_AS_NULL = true
COMPRESSION = NONE;
CREATE OR REPLACE FILE FORMAT my_csv_format
TYPE = CSV
FIELD_DELIMITER = ','
SKIP_HEADER = 1
EMPTY_FIELD_AS_NULL = true
COMPRESSION = NONE;
検証用の仮想ウェアハウスを作成します。ここでは2つのサイズを用意しました。
--仮想ウェアハウス
USE ROLE SYSADMIN;
CREATE WAREHOUSE xs_wh
WAREHOUSE_SIZE = XSMALL
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
CREATE WAREHOUSE large_wh
WAREHOUSE_SIZE = LARGE
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
キャッシュも無効化しておきました。
ALTER ACCOUNT SET USE_CACHED_RESULT = false;
作成したサンプルデータファイルは、内部ステージに配置しておきます。
>ls @my_int_stage;
+---------------------------------------+--------+----------------------------------+-------------------------------+
| name | size | md5 | last_modified |
|---------------------------------------+--------+----------------------------------+-------------------------------|
| my_int_stage/survey_data_10x1000.csv | 25904 | 6c12874310c2c463e72cf8b541f69a60 | Sun, 31 Aug 2025 06:10:26 GMT |
| my_int_stage/survey_data_10x10000.csv | 268896 | d206836f0772efaa56cd121058528c08 | Sun, 31 Aug 2025 06:10:26 GMT |
| my_int_stage/survey_data_10x20000.csv | 548896 | 106958550d2deb822149657d885cabe3 | Sun, 31 Aug 2025 06:10:26 GMT |
+---------------------------------------+--------+----------------------------------+-------------------------------+
試してみる
各カラム数のデータファイル(CSV)をロードしてみます。
1000 カラム
カラム数が多いので、スキーマ検出機能でテーブル定義しました。
--スキーマ検出機能によりテーブルを定義:1000カラム
CREATE OR REPLACE TABLE MY_SURVEY_TABLE_1000
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_int_stage/survey_data_10x1000.csv',
FILE_FORMAT=>'my_csv_format_parse_header'
)
)
);
--カラム数を確認
>DESC TABLE MY_SURVEY_TABLE_1000
->> SELECT count(*) FROM $1;
+----------+
| COUNT(*) |
|----------|
| 1000 |
+----------+
--USERIDをいれて1000カラム
>DESC TABLE MY_SURVEY_TABLE_1000
->> SELECT "name" FROM $1 LIMIT 3;
+--------+
| name |
|--------|
| USERID |
| Q-1 |
| Q-2 |
+--------+
>DESC TABLE MY_SURVEY_TABLE_1000
->> SELECT "name" FROM $1 LIMIT 3 OFFSET 997;
+-------+
| name |
|-------|
| Q-997 |
| Q-998 |
| Q-999 |
+-------+
ロードしてみます。このカラム数の場合は XS サイズのみで試しました。ここでは 5 秒程でロードできました。
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_1000
FROM @my_int_stage/survey_data_10x1000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
+--------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|--------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x1000.csv | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+--------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
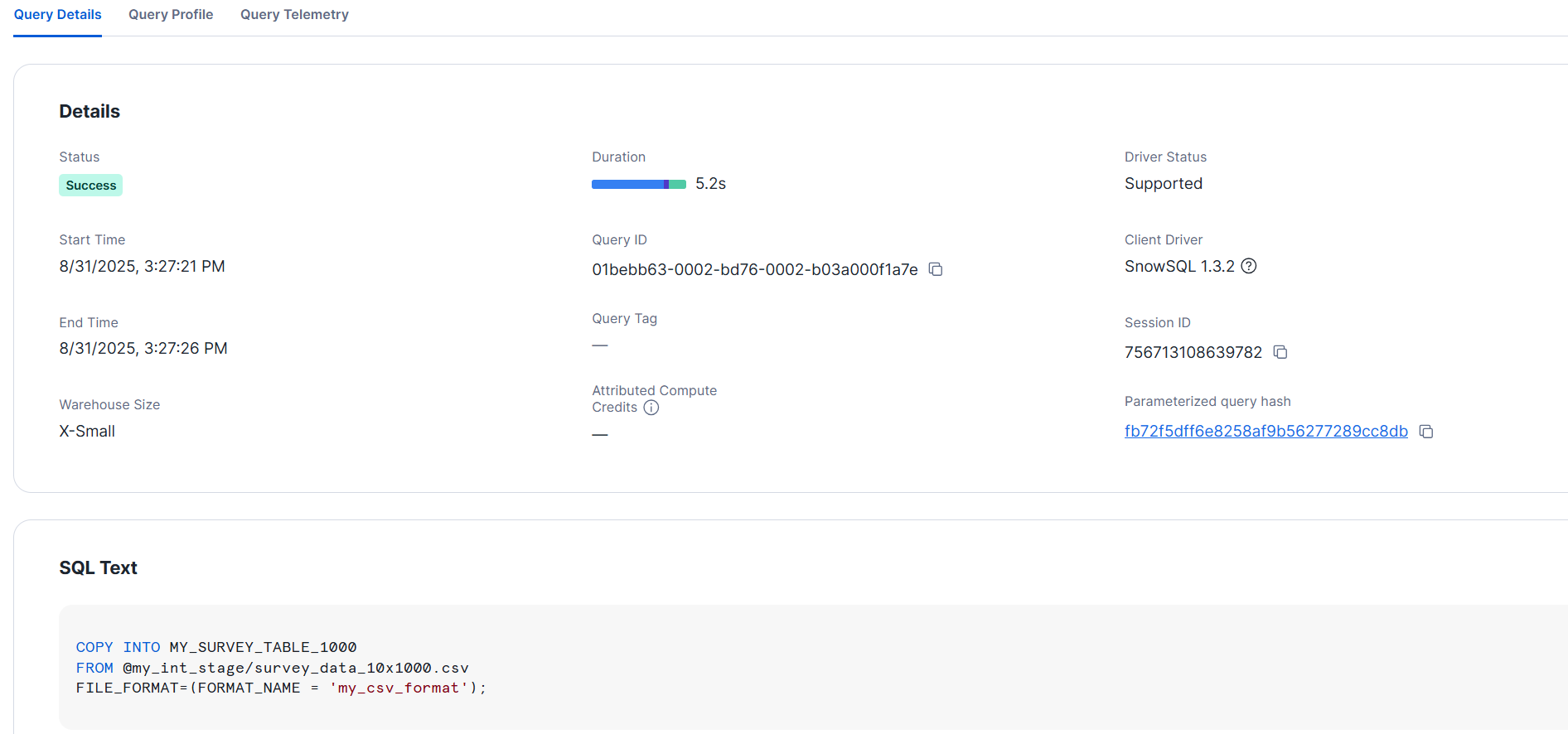
10000カラムのCSV
次に、10000 カラムの CSV データファイルを試してみます。カラム数が多いので、同様にスキーマ検出機能でテーブル定義しました。
--スキーマ検出機能によりテーブルを定義:10000カラム
CREATE OR REPLACE TABLE MY_SURVEY_TABLE_10000
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_int_stage/survey_data_10x10000.csv',
FILE_FORMAT=>'my_csv_format_parse_header'
)
)
);
--カラム数を確認
>DESC TABLE MY_SURVEY_TABLE_10000
->> SELECT count(*) FROM $1;
+----------+
| COUNT(*) |
|----------|
| 10000 |
+----------+
ここからは、各ウェアハウスサイズでロードしてみます。
- XS サイズ
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_10000
FROM @my_int_stage/survey_data_10x10000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
+---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x10000.csv | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
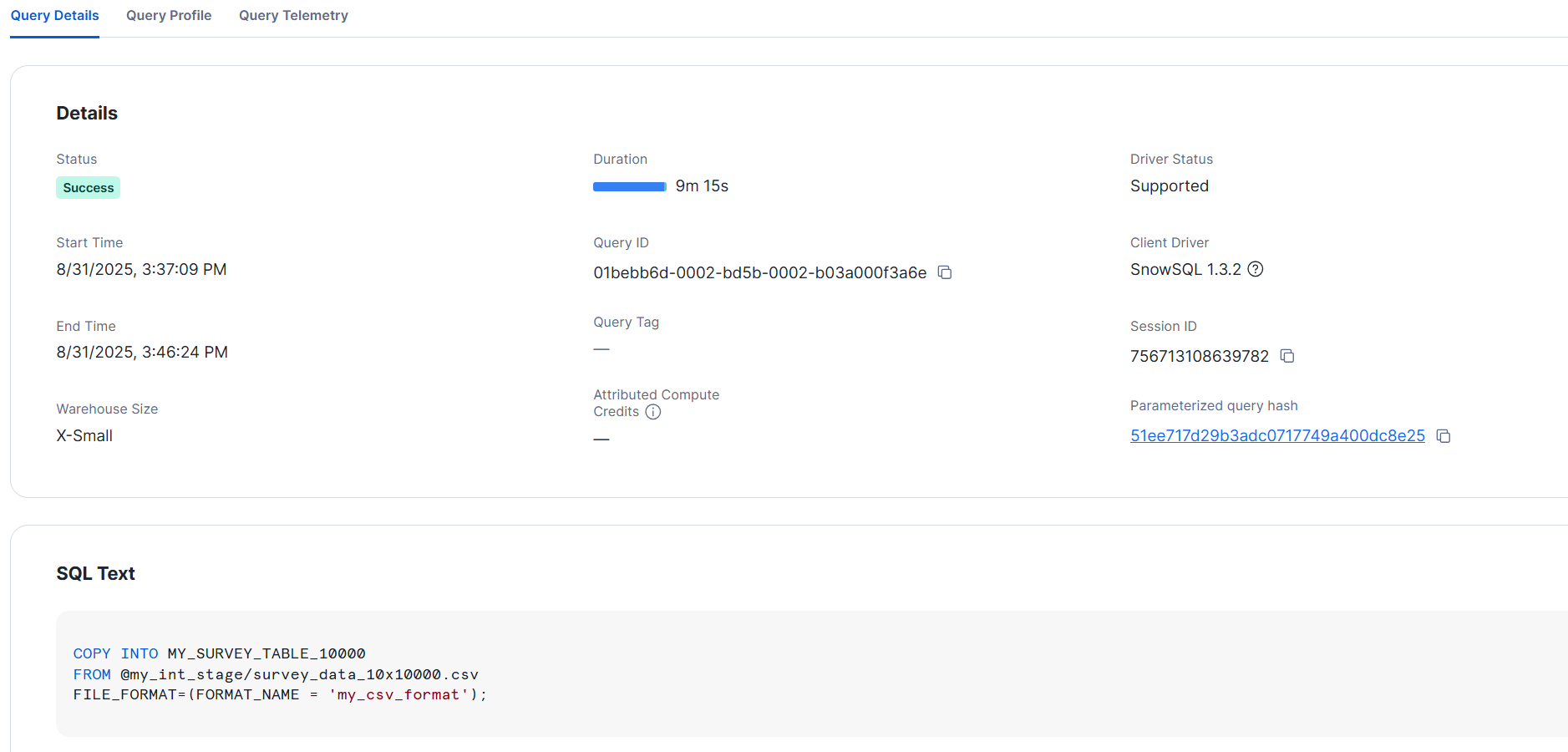
- L サイズ
TRUNCATE TABLE MY_SURVEY_TABLE_10000;
>ALTER WAREHOUSE large_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE large_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_10000
FROM @my_int_stage/survey_data_10x10000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
+---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x10000.csv | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
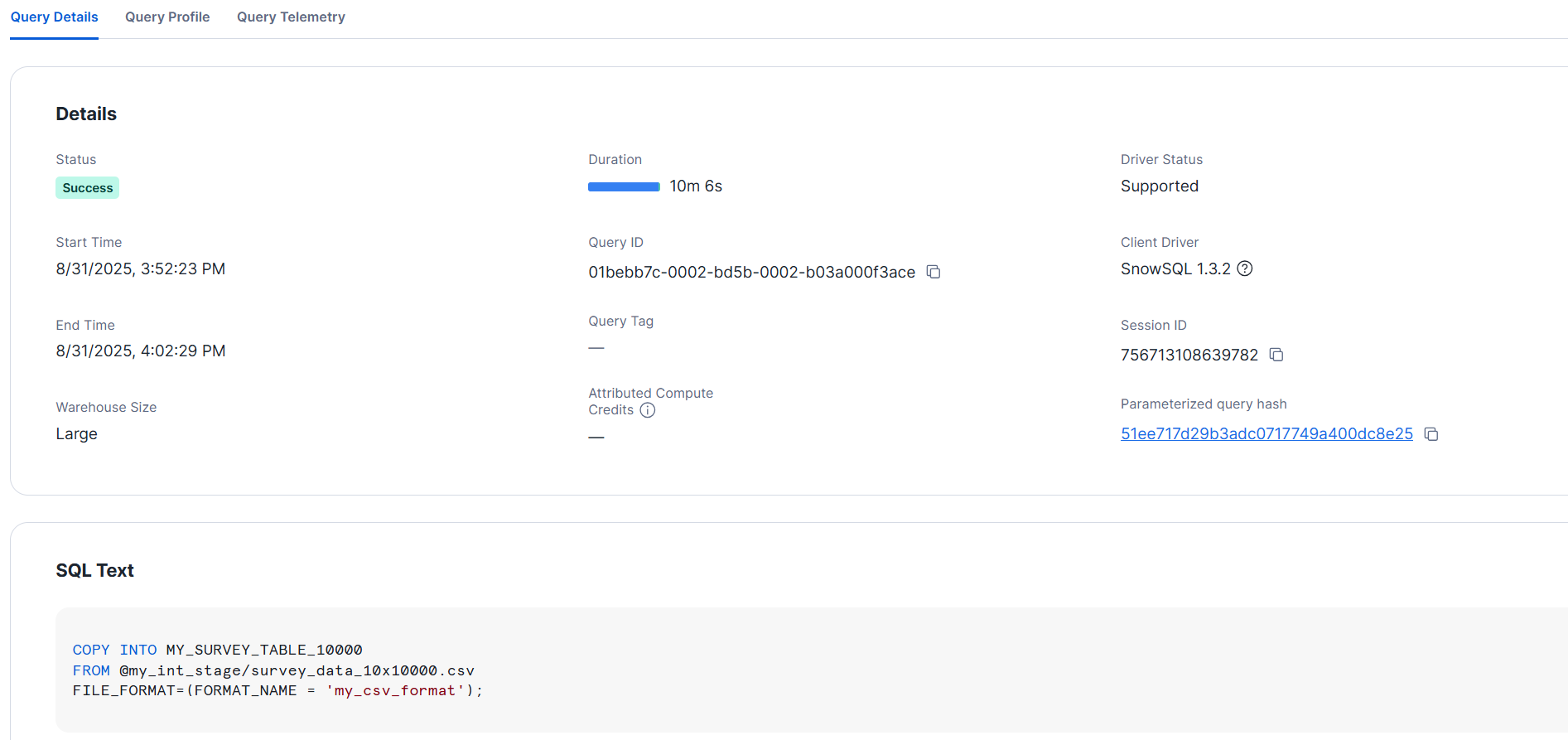
上記は、各1回の試行結果ですが、それぞれおおよそ10分でロードできました。検証時は、単一のファイルをロードしているので、サイズを変えることのメリットは見られません。
※詳細は後述します。
2000カラムのCSV
さらにカラム数を増やした 20000 カラムの CSV ファイルをロードしてみます。この際、同様にスキーマ検出でテーブルを定義するとエラーとなりました。
>CREATE OR REPLACE TABLE MY_SURVEY_TABLE_20000
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_int_stage/survey_data_10x20000.csv',
FILE_FORMAT=>'my_csv_format_parse_header'
)
)
);
100316 (22000): Column position is 10000 but max column position allowed is 9999
エラーメッセージの内容によると、この場合、最大カラム数は 9,999 までのようです。先の手順で10,000カラムではテーブル定義できたので、10,001 カラムのデータファイルで試してみたところ、この場合はエラーとなりました。
$ python generate_sample_data.py 10 10001
エラーになる
>CREATE OR REPLACE TABLE MY_SURVEY_TABLE_10001
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_int_stage/survey_data_10x10001.csv',
FILE_FORMAT=>'my_csv_format_parse_header'
)
)
);
100316 (22000): Column position is 10000 but max column position allowed is 9999
スキーマ検出機能はエラーとなりますが、Snowflake からテーブル定義自体はできるので、事前準備で用意した関数で DDL 文を生成し、このファイルを実行することでテーブルを定義しました。
$ python generate_ddl.py 19999
DDLが正常に'MY_SURVEY_TABLE_20000.sql'に書き込まれました。
定義されたDDL文の一部
create or replace TABLE MY_SURVEY_TABLE_20000 (
"USERID" NUMBER(2,0),
"Q-1" NUMBER(1,0),
"Q-2" NUMBER(1,0),
・
・
・
"Q-19997" NUMBER(1,0),
"Q-19998" NUMBER(1,0),
"Q-19999" NUMBER(1,0)
);
ステージに SQL ファイルを配置し実行します。
--テーブルを定義
>EXECUTE IMMEDIATE FROM @my_int_stage/MY_SURVEY_TABLE_20000.sql;
+---------------------------------------------------+
| status |
|---------------------------------------------------|
| Table MY_SURVEY_TABLE_20000 successfully created. |
+---------------------------------------------------+
--カラム数を確認
>DESC TABLE MY_SURVEY_TABLE_20000
->> SELECT count(*) FROM $1;
+----------+
| COUNT(*) |
|----------|
| 20000 |
+----------+
各ウェアハウスサイズでロードしてみます。
- XS サイズ
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_20000
FROM @my_int_stage/survey_data_10x20000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
>SELECT COUNT(*) FROM MY_SURVEY_TABLE_20000;
+----------+
| COUNT(*) |
|----------|
| 10 |
+----------+
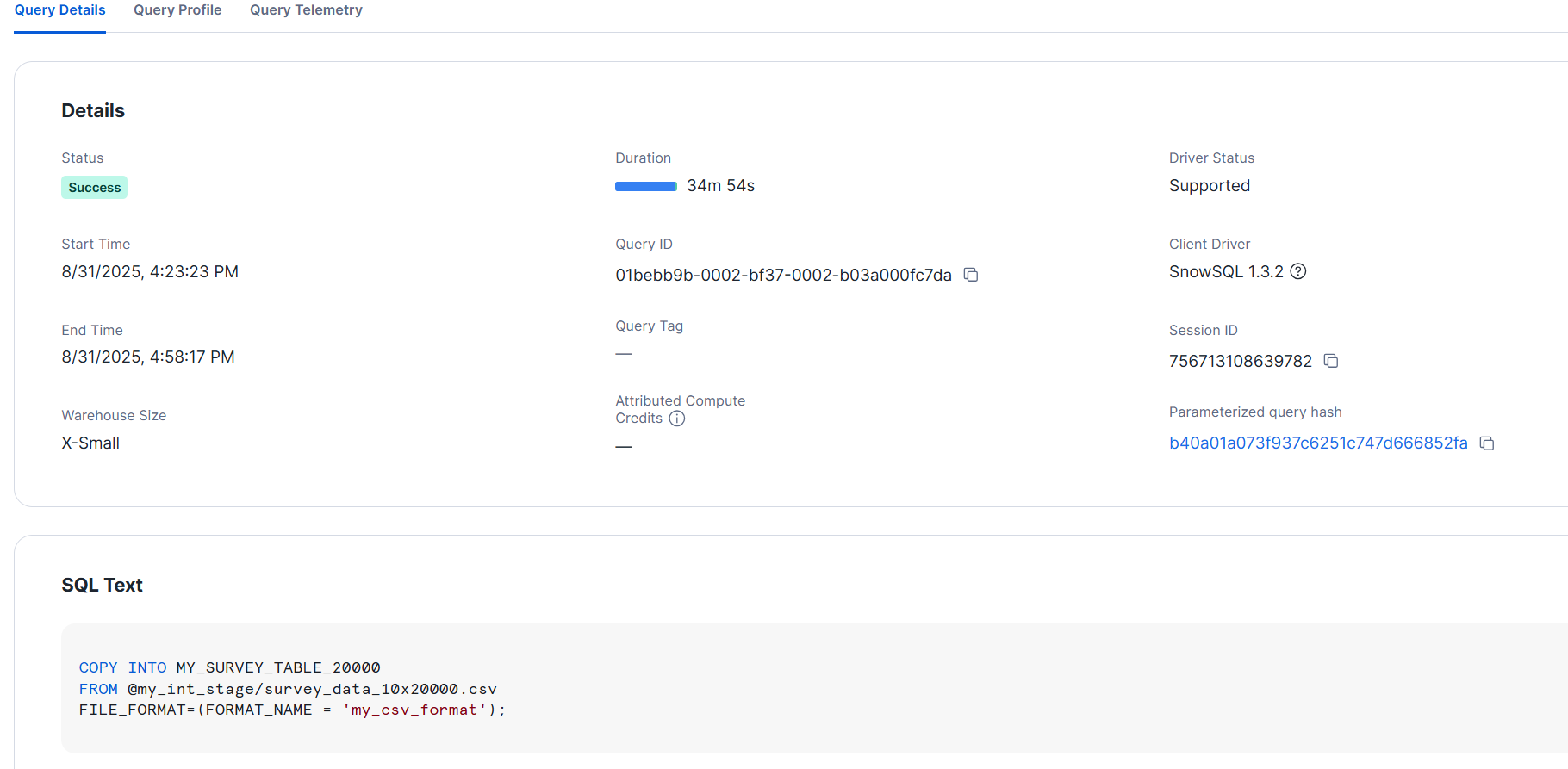
- L サイズ
TRUNCATE TABLE MY_SURVEY_TABLE_20000;
>ALTER WAREHOUSE large_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE large_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_20000
FROM @my_int_stage/survey_data_10x20000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
>SELECT COUNT(*) FROM MY_SURVEY_TABLE_20000;
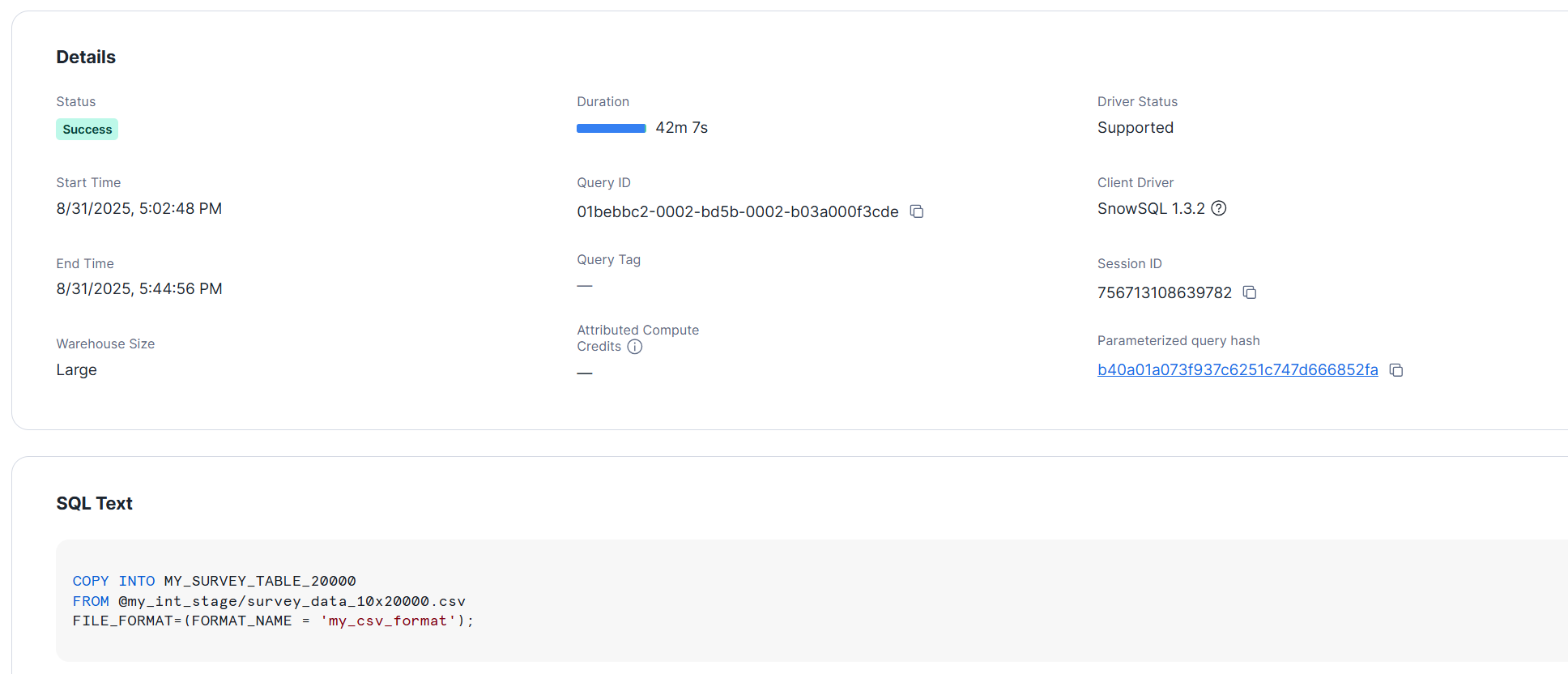
それぞれ 30分以上かかる結果となりました。同様にサイズ上昇によるメリットは見られません。
JSON 形式に変換後にロードしてみる
CSV を JSON に変換し、VARIANT型の単一のカラムとしてロードしてみます。また、元のカラム数として、ここでは10000,20000カラムで試してみます。
先のデータファイルを JSON 形式に変換します。
$ python csv_to_json.py survey_data_10x10000.csv survey_data_10x10000.json
'survey_data_10x10000.csv' を読み込み、'survey_data_10x10000.json' としてJSONファイルに変換しました。
$ python csv_to_json.py survey_data_10x20000.csv survey_data_10x20000.json
'survey_data_10x20000.csv' を読み込み、'survey_data_10x20000.json' としてJSONファイルに変換しました。
JSON ファイルの中身は以下のようになっています。
[
{
"USERID": "1",
"Q-1": "1",
"Q-2": "0",
・
・
・
"Q-9998": "1",
"Q-9999": "1"
},
{
"USERID": "2",
"Q-1": "1",
"Q-2": "0",
・
・
・
"Q-9998": "0",
"Q-9999": "0"
}
]
作成した JSON ファイルは内部ステージに配置しておきます。
10000カラムのCSVをJSON形式に変換しロード
こちらも各サイズで試しみます。
- XS サイズ
--テーブルを定義
CREATE OR REPLACE TABLE test_10000 (v VARIANT);
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO test_10000
FROM @my_int_stage/survey_data_10x10000.json
FILE_FORMAT = (
TYPE = 'JSON'
,STRIP_OUTER_ARRAY = TRUE
);
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x10000.json | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
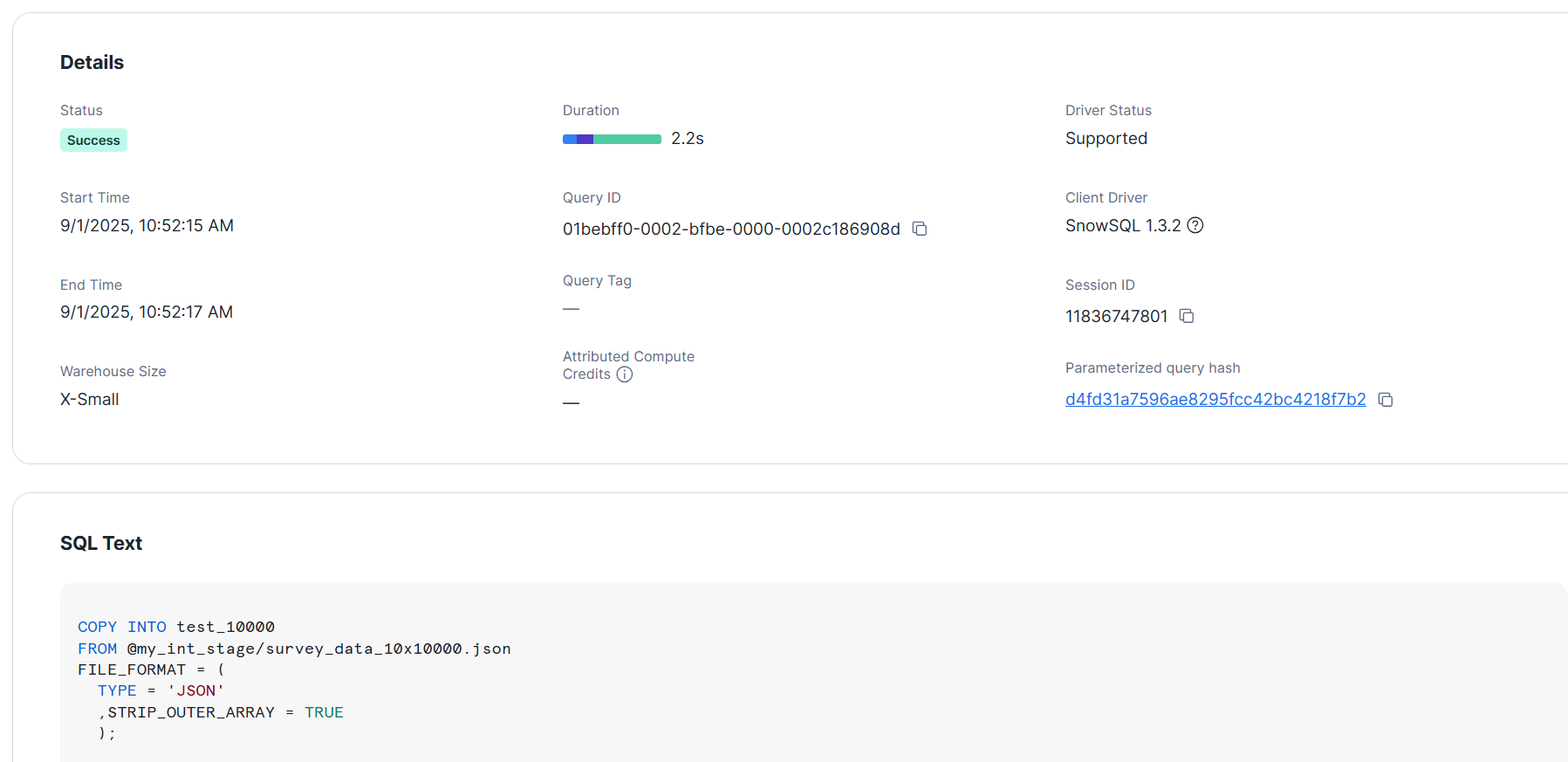
- L サイズ
TRUNCATE TABLE test_10000;
>ALTER WAREHOUSE large_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE large_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO test_10000
FROM @my_int_stage/survey_data_10x10000.json
FILE_FORMAT = (
TYPE = 'JSON'
,STRIP_OUTER_ARRAY = TRUE
);
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x10000.json | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
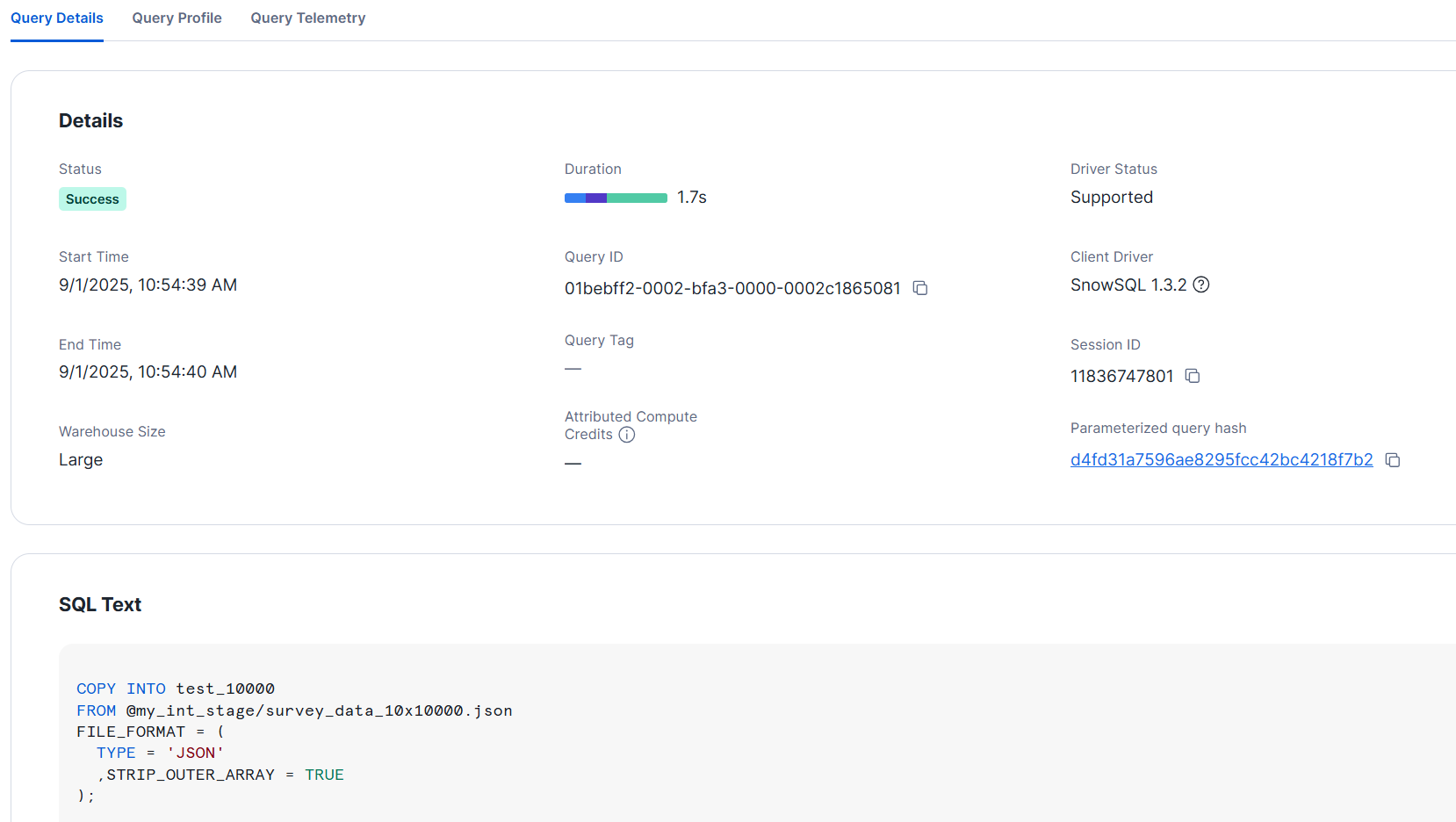
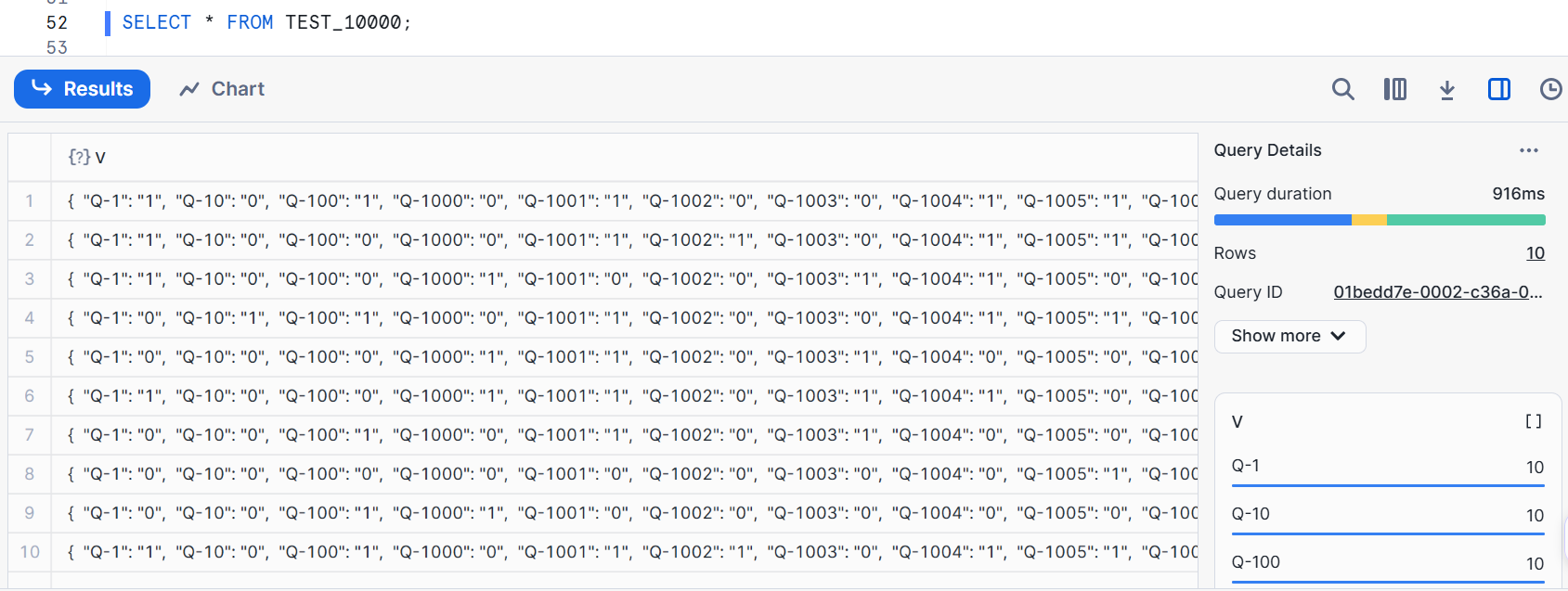
この場合、XS サイズでも2秒程度でロードできました。ロード後は下図のようになっています。
20000カラムのCSVをJSON形式に変換しロード
こちらも各サイズで試してみました。
- XSサイズ
--テーブルを定義
CREATE OR REPLACE TABLE test_20000 (v VARIANT);
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO test_20000
FROM @my_int_stage/survey_data_10x20000.json
FILE_FORMAT = (
TYPE = 'JSON'
,STRIP_OUTER_ARRAY = TRUE
);
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x20000.json | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
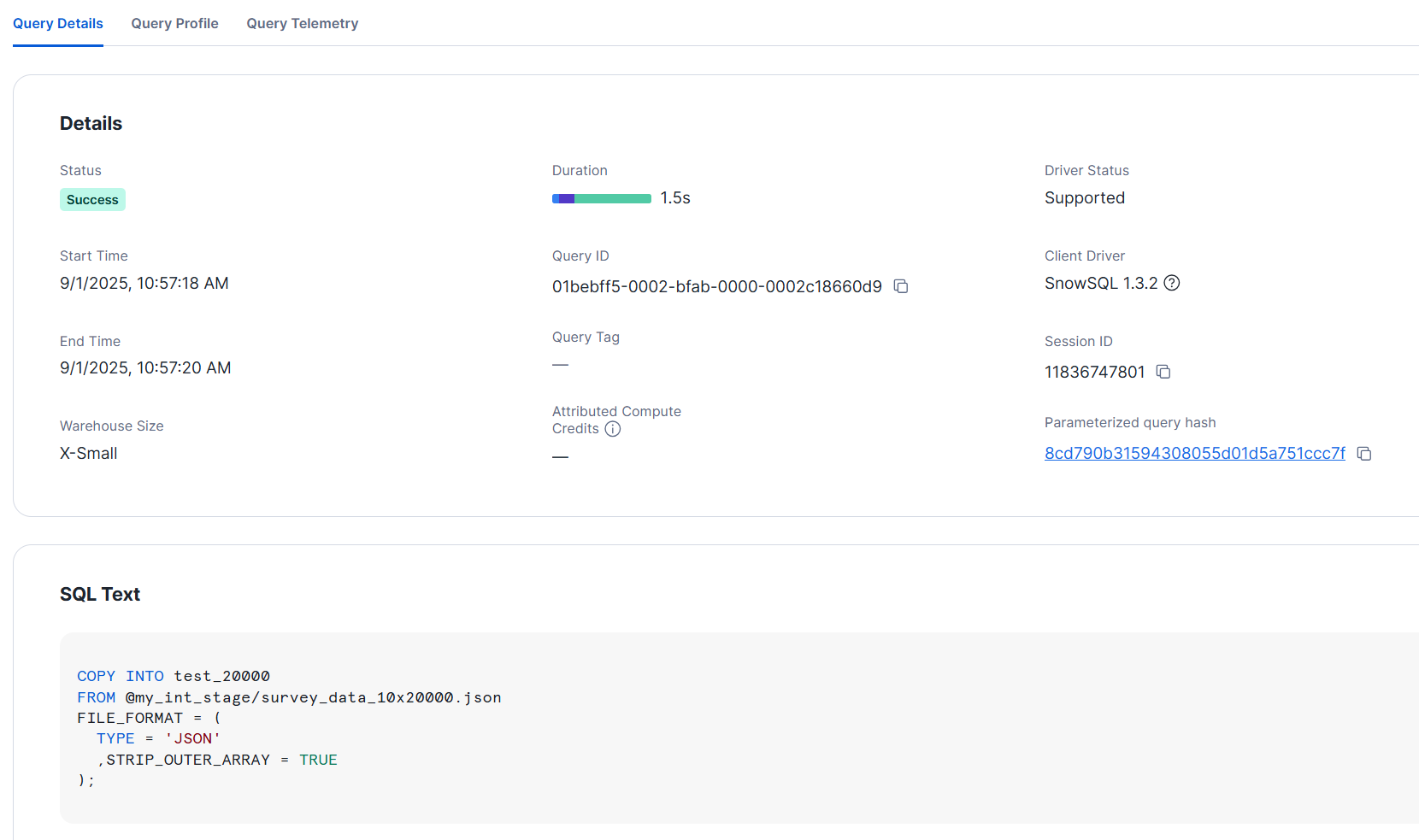
- L サイズ
TRUNCATE TABLE test_20000;
>ALTER WAREHOUSE large_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE large_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO test_20000
FROM @my_int_stage/survey_data_10x20000.json
FILE_FORMAT = (
TYPE = 'JSON'
,STRIP_OUTER_ARRAY = TRUE
);
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x20000.json | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
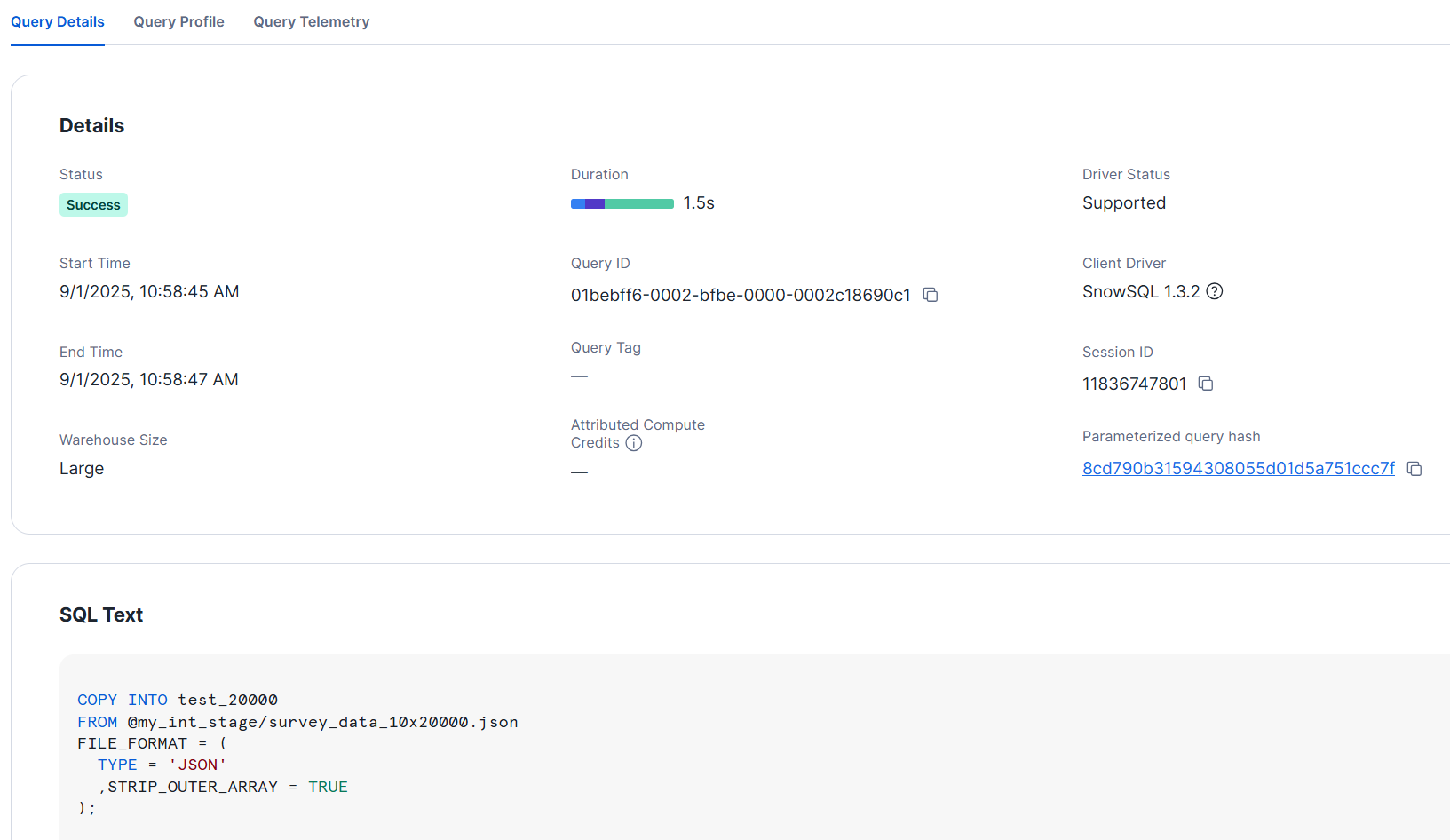
XS サイズでも2秒以内にロードできました。
ロード後の変換処理を試してみる
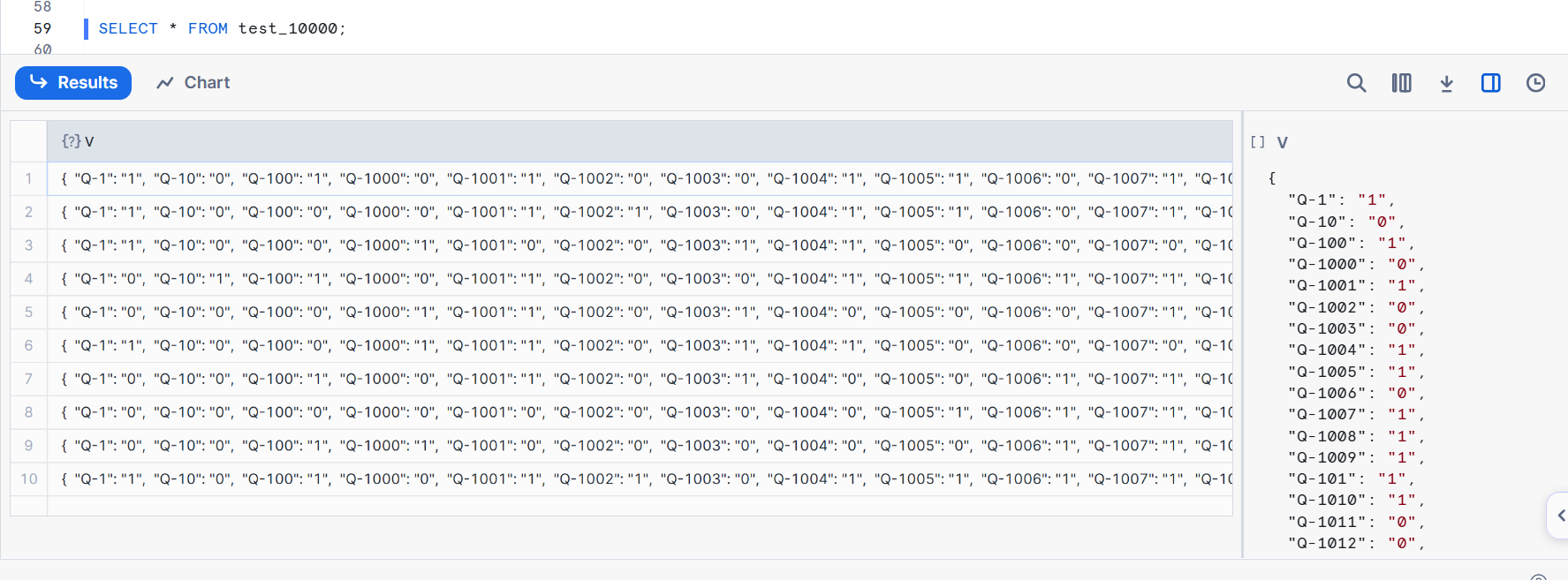
VARIANT 型のカラムにデータをロードしたので、ロード後のデータは下図のようになっています。各レコードは、ユーザーごとのアンケート回答をキーバリュー形式で保存しています。
以下のクエリで縦持ちに変換します。はじめに元は10,000カラムの CSV ファイルを JSON 形式としてロードしたデータで試してみます。
- XS サイズ
ALTER WAREHOUSE xs_wh RESUME;
USE WAREHOUSE xs_wh;
SELECT
t.v:"USERID"::NUMBER AS userid,
f.key::VARCHAR AS key,
f.value::VARCHAR AS value
FROM
test_10000 AS t,
LATERAL FLATTEN(input => t.v) AS f
WHERE
f.key <> 'USERID'
ORDER BY
userid,
key;
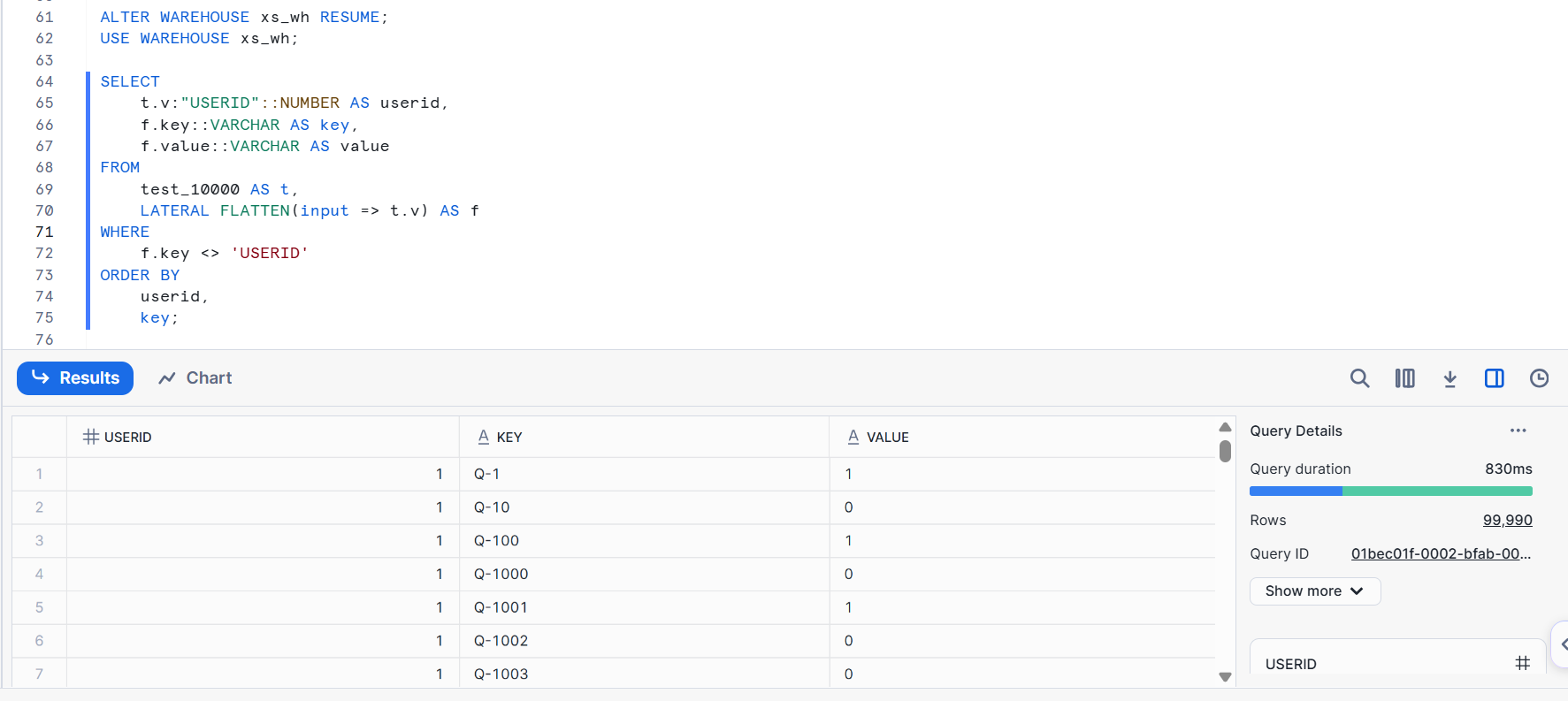
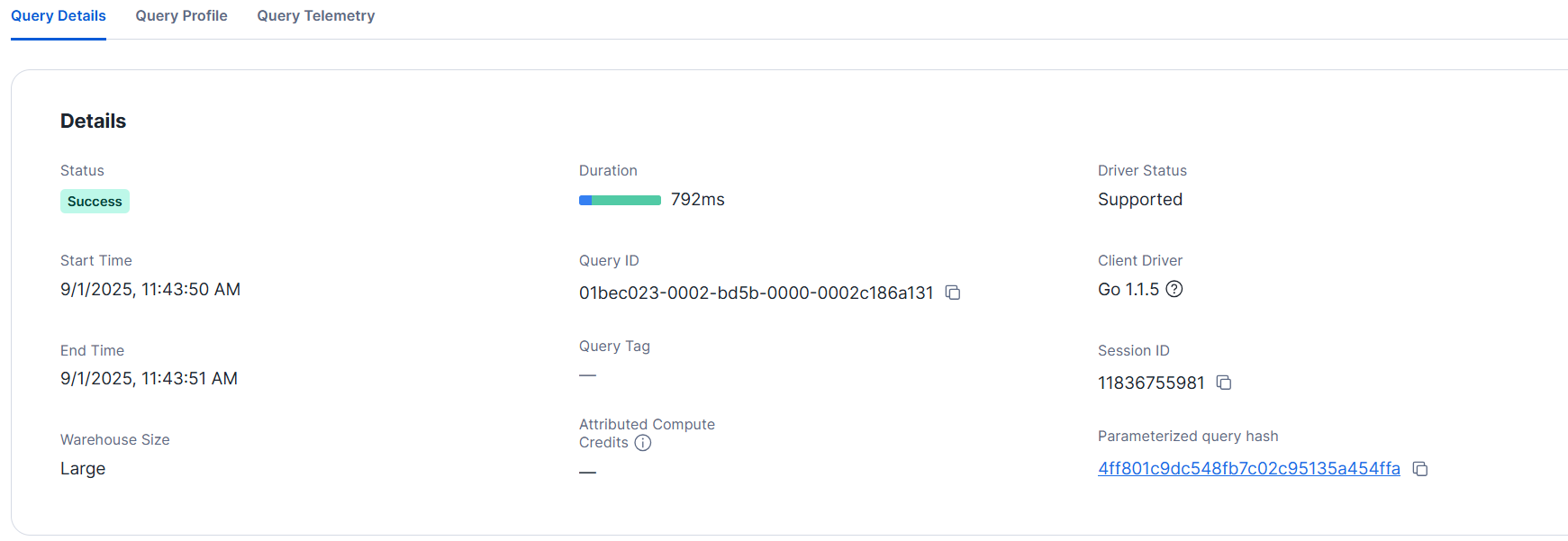
クエリの詳細は下図の通りでした。1秒もかからず完了しました。
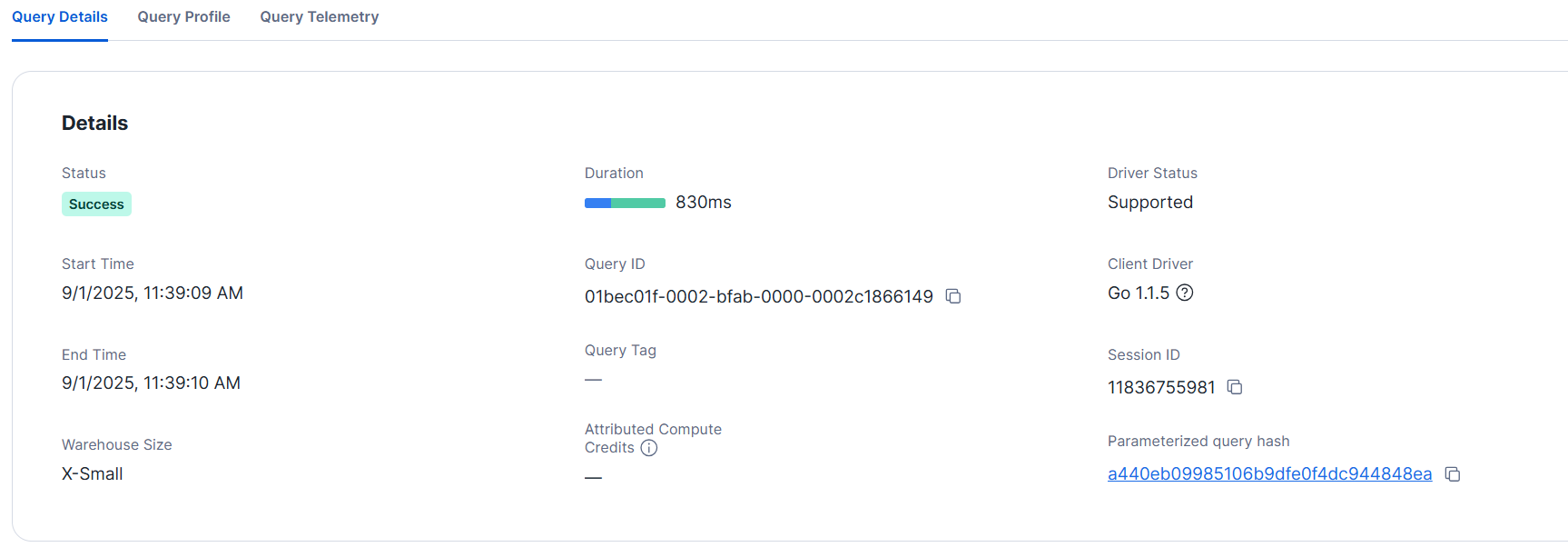
- L サイズ
クエリの詳細は下図の通りです。同様に1秒もかからず完了しました。
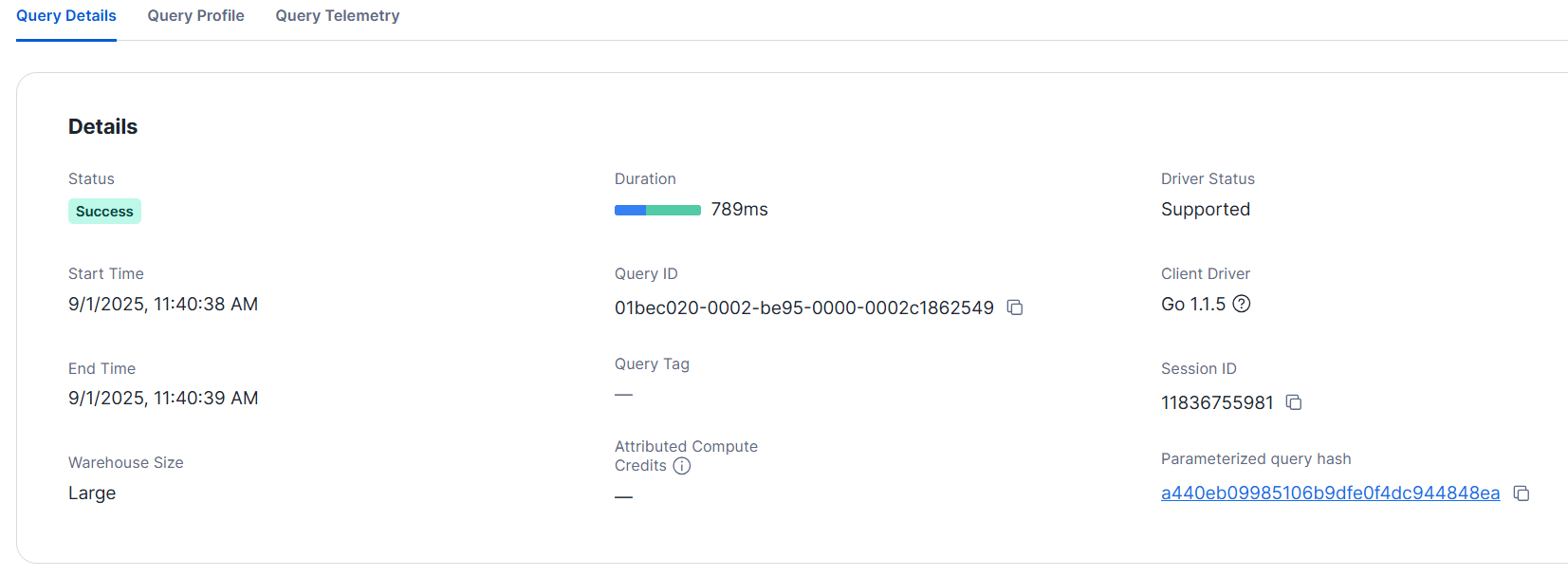
次に、元は20,000カラムの CSV ファイルを JSON 形式としてロードしたデータで試してみます。
- XS サイズ
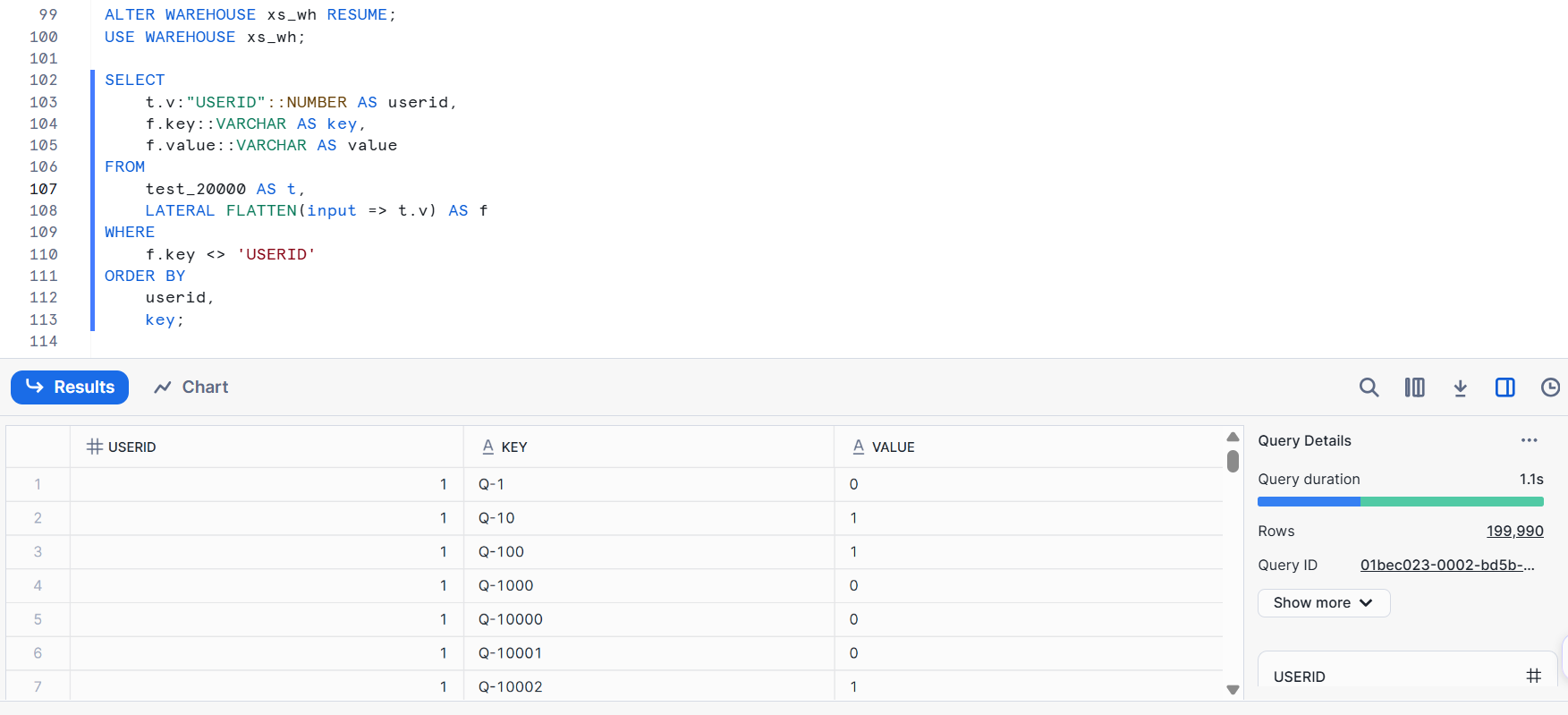
クエリの詳細
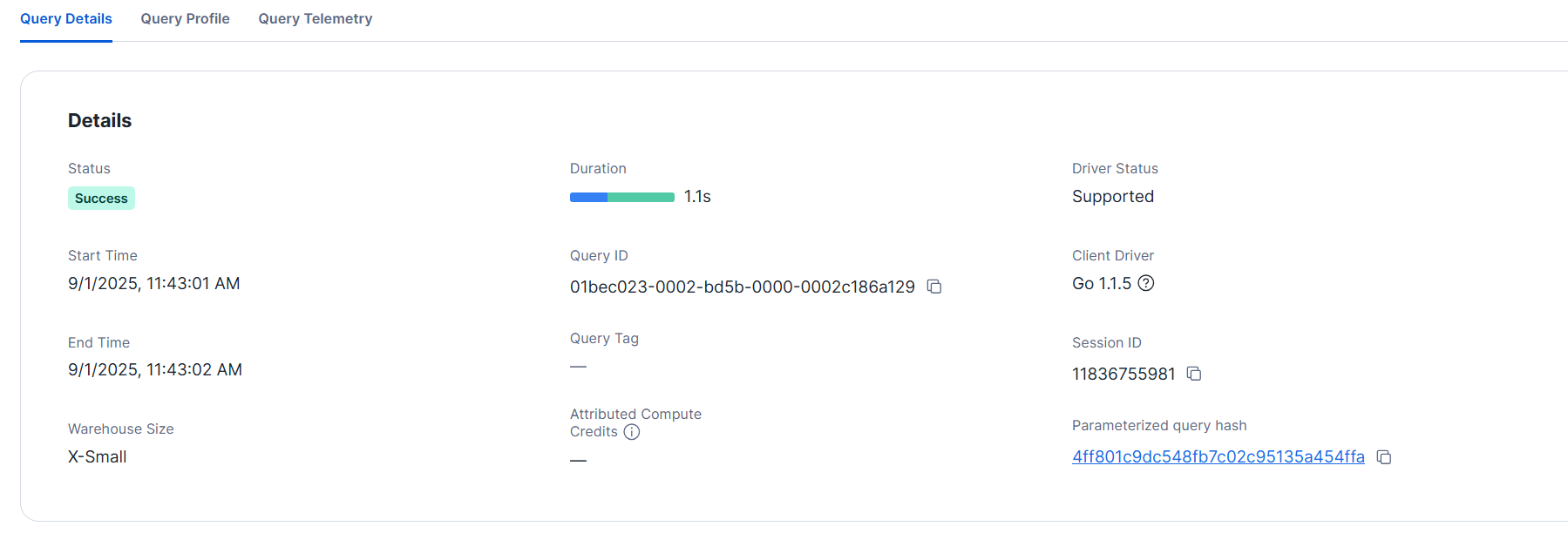
- Lサイズ
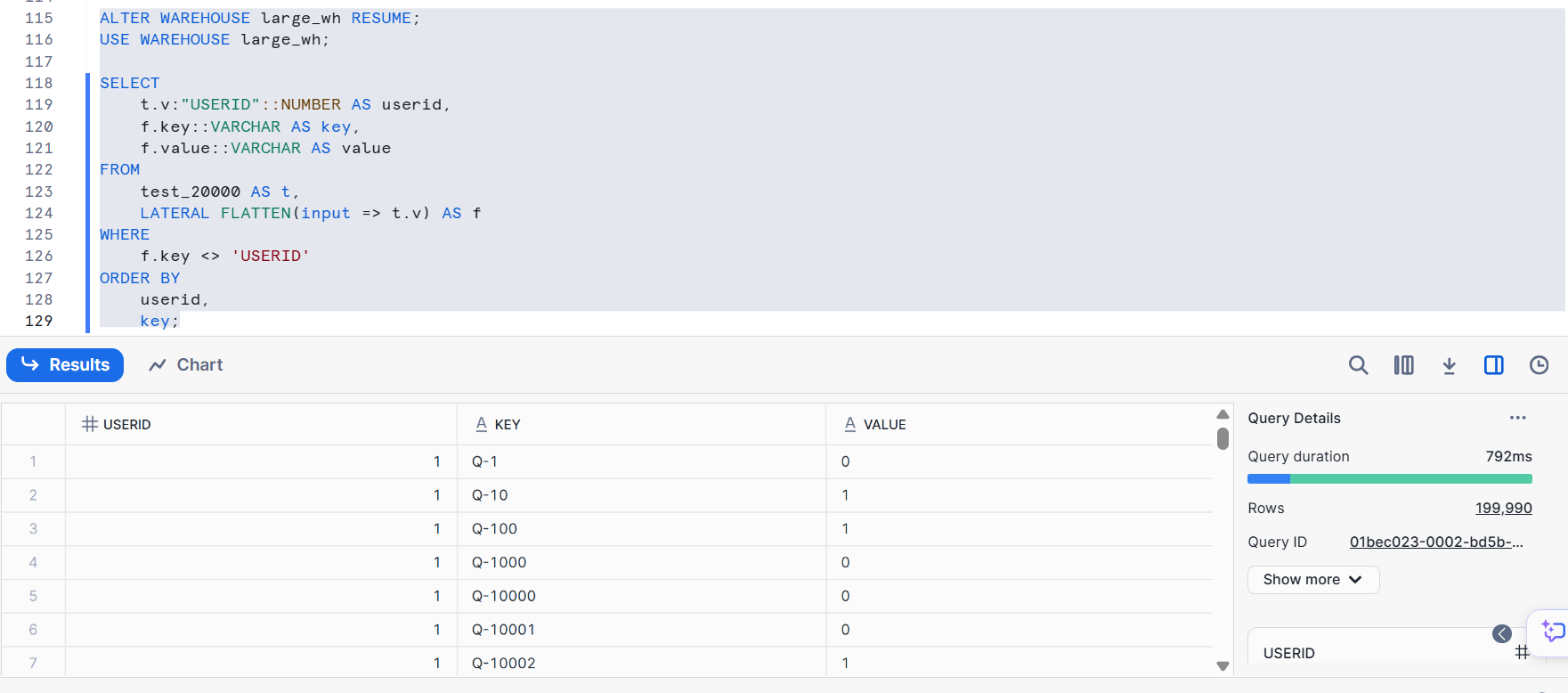
こちらも1秒程度で完了しました。同時に1万を超えるカラムとして保持することが必須でなければ、縦持ちの方がパフォーマンス・分析しやすさ共に向上が見込めると考えられます。
カラムを展開
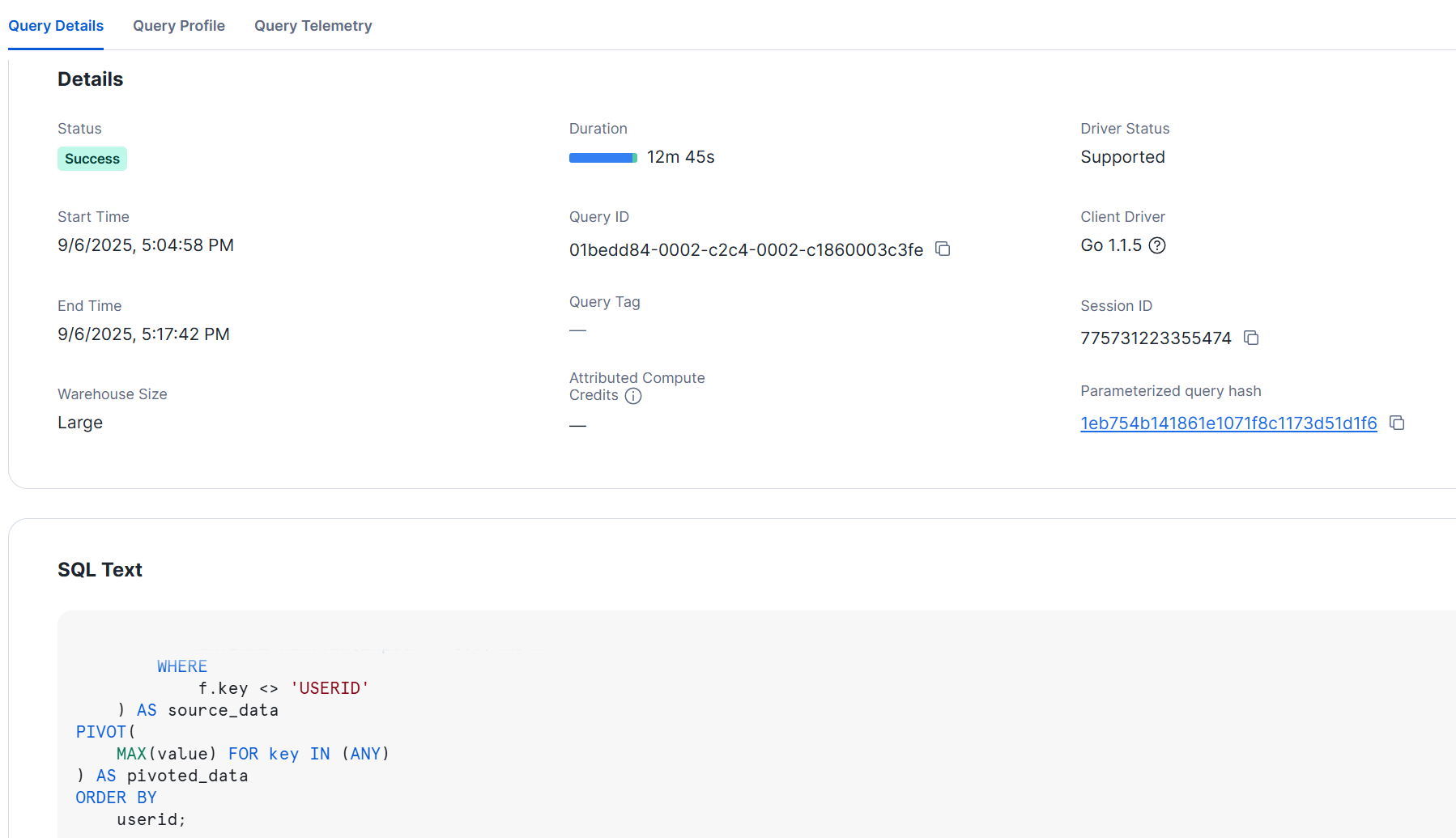
最後に、元は10,000カラムのCSVをJSON形式で Snowflake に取り込んだのち、Snowflake 内で10,000カラムに展開してみました。
以下は L サイズのウェアハウスで試してみた例ですが、この場合、ロード時と同様に 10 分以上かかる結果となりました。
CREATE OR REPLACE TABLE test_10000_flat AS
SELECT
*
FROM
(
SELECT
t.v:"USERID"::NUMBER AS userid,
f.key::VARCHAR AS key,
f.value::VARCHAR AS value
FROM
test_10000 AS t,
LATERAL FLATTEN(input => t.v) AS f
WHERE
f.key <> 'USERID'
) AS source_data
PIVOT(
MAX(value) FOR key IN (ANY)
) AS pivoted_data
ORDER BY
userid;
--カラム数を確認
DESC TABLE test_10000_flat
->> SELECT count(*) FROM $1;
+----------+
| COUNT(*) |
|----------|
| 10000 |
+----------+
クエリの詳細
カラム数が多い場合の考慮事項
まず今回の設定に関わるデータロード時のデータファイルの数について、以下に関連する内容の記載があります。
Snowflake の仮想ウェアハウスは、各スレッドが一度に単一のファイルを取り込みます。
XS サイズであれば8つのスレッドが提供され、ウェアハウスのサイズが1つ大きくなるごとに利用可能なスレッドの数は倍増します。そのため、ロード対象のファイル数が多い場合に、スケールアップの恩恵を受けられます。
一方で、今回のケースのようにファイル数が少ない場合、サイズを上げようとも、各スレッドが単一のファイルを処理するため、処理速度は変わりません。
また、カラム数とパフォーマンスに関しては以下で詳しく解説されています。
カラム数が多いテーブルは、圧縮率の低下やコンパイル時のメタデータ処理の増加により、パフォーマンスが低下します。特に、ここではコンパイルにかかる時間が、クエリの実行速度に大きく影響しています。
参考までに、実際に関連するクエリのコンパイル時間を比較した内容が以下です。3レコードありますが、クエリ内容は上から順に以下の通りです。
- 10,000カラムの CSV を JSON に変換し、VARIANT 型の1カラムに格納したテーブルを SELECT
- VARIANT 型の1カラムに格納したテーブルを Snowflake 内で 10,000カラムに展開したテーブルを SELECT
- VARIANT 型の1カラムに格納したテーブルから Snowflake 内で 10,000カラムのテーブルを作成(CTAS)
>SELECT
QUERY_TEXT
,QUERY_TYPE
,TOTAL_ELAPSED_TIME
,BYTES_SCANNED,COMPILATION_TIME
,EXECUTION_TIME
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE QUERY_ID IN ('01beddb4-0002-c33c-0002-c186000471da','01beddae-0002-c2d9-0002-c186000442aa','01bedd84-0002-c2c4-0002-c1860003c3fe')
ORDER BY start_time DESC;
+------------------------------------------------+------------------------+--------------------+---------------+------------------+----------------+
| QUERY_TEXT | QUERY_TYPE | TOTAL_ELAPSED_TIME | BYTES_SCANNED | COMPILATION_TIME | EXECUTION_TIME |
|------------------------------------------------+------------------------+--------------------+---------------+------------------+----------------|
| select * from test_10000; | SELECT | 831 | 403488 | 184 | 508 |
| select * from test_10000_flat; | SELECT | 108843 | 3183136 | 107624 | 1082 |
| CREATE OR REPLACE TABLE test_10000_flat AS | CREATE_TABLE_AS_SELECT | 764722 | 403488 | 709523 | 54311 |
| SELECT | | | | | |
| * | | | | | |
| FROM | | | | | |
| ( | | | | | |
| SELECT | | | | | |
| t.v:"USERID"::NUMBER AS userid, | | | | | |
| f.key::VARCHAR AS key, | | | | | |
| f.value::VARCHAR AS value | | | | | |
| FROM | | | | | |
| test_10000 AS t, | | | | | |
| LATERAL FLATTEN(input => t.v) AS f | | | | | |
| WHERE | | | | | |
| f.key <> 'USERID' | | | | | |
| ) AS source_data | | | | | |
| PIVOT( | | | | | |
| MAX(value) FOR key IN (ANY) | | | | | |
| ) AS pivoted_data | | | | | |
| ORDER BY | | | | | |
| userid; | | | | | |
+------------------------------------------------+------------------------+--------------------+---------------+------------------+----------------+
JSON をそのまま参照する最初のクエリ(184ms)と比べて、Snowflake 内でカラムを展開してから参照するクエリはコンパイル時間が圧倒的に長くなっています。特に、CREATE TABLE AS SELECTでテーブルを作成する際には、膨大なメタデータ処理が発生するためか、コンパイル時間が 70万msを超える結果となりました。
さいごに
カラム数が多い CSV ファイルのロードを試してみました。
こちらの内容が何かの参考になれば幸いです。







