
DagsterでS3のファイルをアップロードしたことをトリガーにジョブを起動してみた
こんにちは、データ事業本部のキタガワです。
DagsterではAssetやJobを起動する方法の一つとしてSensorがあります。Sensorはファイルがアップロードされたり外部APIの状態が変化したりといったイベントをトリガーとする仕組みです。例えばS3にファイルが連携されると特定のパイプラインを実行するという、ETLで一般的なフローもこれで実現できます。
このブログではいくつかのステップに分けてこの機能の説明を行います。
DagsterはOSS版を前提とします。また、DagsterはPythonのパッケージマネージャとしてuvを推奨していますので、この記事でもuvを前提に進めます。Pythonのバージョンは3.13を使用します。
作成したソースコードは以下のGitHubリポジトリで公開しています。
準備
uvがインストールされていない場合はuvをインストールします。
curl -LsSf https://astral.sh/uv/install.sh | sh
uv --version
uv 0.9.21 (0dc9556ad 2025-12-30)
次にDagsterのプロジェクトを作成します。uvx create-dagster project PROJECT_NAME で作成できます。PROJECT_NAME の部分は好きなプロジェクト名を指定してください。ここではdagster-sensor-s3-put-event とします。
uvx create-dagster@latest project dagster-sensor-s3-put-event
cd dagster-sensor-s3-put-event
uv python pin 3.13
source .venv/bin/activate
dg --version
dg, version 1.12.8
ここまで実行できると以下のようなプロジェクトが作られています。これでDagsterプロジェクトの準備は完了です。
├── src
│ └── dagster-sensor-s3-put-event
│ ├── __init__.py
│ ├── definitions.py
│ ├── defs
│ │ └── __init__.py
│ └── components
│ └── __init__.py
├── tests
│ └── __init__.py
└── pyproject.toml
ローカル検証
ローカルでDagsterを立ち上げ、Sensorの検証を行います。AWSリソースを使用する場合には dagster-aws を追加します。
uv add dagster-aws
Sensorの仕組み
Sensorは外部の状態変化を定期的に監視し、条件を満たしたときにAssetやJobを起動する仕組みです。よって、基本的にSensorにはAssetやJobを実行するための条件を決定する処理を記述することになります。
例えば今回の例では「特定のS3バケット・プリフィックスにCSVファイルがアップロードされたら」が条件となります。この条件の定義は実際のETLパイプラインによって変わってくるかと思いますが、ここではS3の ListObjectsV2 APIで取得できる LastModified を基準にします。
Asset定義
まずはSensorで実行するAssetを定義します。ベースとなるファイルは dg CLIで作成します。
dg scaffold defs dagster.asset assets.py
src/dagster_sensor_s3_put_event/defs/assets.py が作成されたと思います。このファイルを以下のように編集してください。ここではシンプルにSensorが検知したS3のパスを出力するだけのAssetを定義しています。
import dagster as dg
class MyAssetConfig(dg.Config):
s3_key: str
# Define the asset
@dg.asset
def my_asset(context: dg.AssetExecutionContext, config: MyAssetConfig):
s3_path = config.s3_key
context.log.info(f"Hello, {s3_path}!")
Resources定義
またS3をDagsterの共通リソースとして扱うためのResourcesを定義します。同じように dg CLIで以下のコマンドを実行し、作成されたファイルを修正してください。
dg scaffold defs dagster.resources resources.py
import dagster as dg
from dagster_aws.s3 import S3Resource
s3_resource = S3Resource()
@dg.definitions
def resources() -> dg.Definitions:
return dg.Definitions(resources={"s3_resource": s3_resource})
Sensor定義
続いてSensorの定義を行います。Sensorは @dg.sensor デコレータで定義できます。Sensor用のファイルの作成には以下のコマンドを実行します。
dg scaffold defs dagster.sensor sensors.py
これまでと同じように作成されたファイルを、次のように編集します。
bucket と prefix には任意の値を指定してください。
from datetime import datetime
import dagster as dg
from dagster_aws.s3 import S3Resource
from dagster_aws.s3.sensor import get_objects
from dagster_sensor_s3_put_event.defs.assets import MyAssetConfig, my_asset
@dg.sensor(
target=my_asset,
default_status=dg.DefaultSensorStatus.RUNNING,
minimum_interval_seconds=60,
)
def my_sensor(
context: dg.SensorEvaluationContext, s3_resource: S3Resource
) -> dg.SensorResult | dg.SkipReason:
context.log.debug(context.cursor)
s3_client = s3_resource.get_client()
bucket = "dagster-sensor-demo-bucket"
prefix = "incoming/"
last_modified = datetime.fromisoformat(context.cursor) if context.cursor else None
new_objects = get_objects(
bucket=bucket,
prefix=prefix,
since_last_modified=last_modified,
client=s3_client,
)
new_csv_objects = [obj for obj in new_objects if obj["Key"].endswith(".csv")]
if not new_csv_objects:
return dg.SkipReason("No new objects.")
last_modified = max(obj["LastModified"] for obj in new_csv_objects)
return dg.SensorResult(
run_requests=[
dg.RunRequest(
run_key=obj["Key"],
run_config=dg.RunConfig({"my_asset": MyAssetConfig(s3_key=obj["Key"])}),
)
for obj in new_csv_objects
],
cursor=last_modified.isoformat(),
)
それぞれ軽く説明します。
まずDagsterとAWSを統合するには dagster-aws ライブラリを使用します。S3を扱うには dagster-aws.s3 が用意されています。
@dg.sensor(
target=my_asset,
default_status=dg.DefaultSensorStatus.RUNNING,
minimum_interval_seconds=60,
)
@dg.sensor の引数の target には my_asset を指定しています。Sensorが起動対象とするJobやAssetがここで決まります。minimum_interval_seconds でSensorが評価する最小の間隔を指定できます。ただしこれは最小間隔であり、必ずこのタイミングで実行されるわけではないことに注意が必要です。
It's important to note that this interval represents a minimum interval between runs of the sensor and not the exact frequency the sensor runs. If a sensor takes longer to complete than the specified interval, the next evaluation will be delayed accordingly.
last_modified = datetime.fromisoformat(context.cursor) if context.cursor else None
... 中略
last_modified = max(obj["LastModified"] for obj in new_csv_objects)
重複処理を防ぐため、前回処理した最新の LastModified を context.cursor に保持しています。評価時にカーソルを取得し、処理後に更新することで、新規ファイルのみをトリガー対象にしています。
new_objects = get_objects(
bucket=bucket,
prefix=prefix,
since_last_modified=last_modified,
client=s3_client,
)
new_csv_objects = [obj for obj in new_objects if obj["Key"].endswith(".csv")]
if not new_csv_objects:
return dg.SkipReason("No new objects.")
前回処理以降にS3に新しいファイルがアップロードされているかを確認する処理です。ここがSensorの本体となる箇所です。get_objects() により last_modified 以降の日時で更新されたファイルがあれば、その情報がリストの形式で返却されます。返却されたリストが空であればSensorは dg.SkipReason を返却し、このSensor評価でのAsset実行はスキップされます。
get_objects() は dagster_aws.s3.sensor モジュールに定義されています。ここでは簡単のためにこの関数を使用していますが、実際の使用シーンではそれぞれの要件に応じた処理の作成が必要になってきます。
return dg.SensorResult(
run_requests=[
dg.RunRequest(
run_key=obj["Key"],
run_config=dg.RunConfig({"my_asset": MyAssetConfig(s3_key=obj["Key"])}),
)
for obj in new_csv_objects
],
cursor=last_modified.isoformat(),
)
Sensor評価の結果として dg.RunRequest() のリストを返却します。これにより target に指定したAssetやJobを起動できます。
run_key は実行の一意なキーになります。同じキーを持つ RunRequest は重複実行されません。例えば data/sample.csv がアップロードされた場合、このパスが run_key となります。後から同じファイルが上書きされても、すでに同じ run_key で実行済みのため二重処理されません。
run_config には my_asset 実行時に処理対象のS3キーを渡します。Asset側では config.s3_key でこの値を参照しています。
cursor で次回のSensor評価で参照するタイムスタンプを更新しています。
動作検証
ここまで完了したらこのような構成になっているはずです。
.
├── .gitignore
├── .python-version
├── pyproject.toml
├── README.md
├── src
│ └── dagster_sensor_s3_put_event
│ ├── __init__.py
│ ├── definitions.py
│ └── defs
│ ├── __init__.py
│ ├── assets.py
│ ├── resources.py
│ └── sensors.py
├── tests
│ └── __init__.py
└── uv.lock
definitions.py がエントリーポイントとして機能していて、defs/ 以下の定義を読み込む構成になっています。
次に各種定義が正常に実装できているかの検証を行います。
dg check defs
All component YAML validated successfully.
All definitions loaded successfully.
問題なければ上記のような出力が行われます。
それではローカルでDagsterを起動してみましょう。次のコマンドを実行します。
dg dev
All component YAML validated successfully.
2026-01-06 11:28:55 +0900 - dagster - INFO - Using temporary directory /work_dir/dagster-sensor-s3-put-event/.tmp_dagster_home_dby3enl5 for storage. This will be removed when dagster dev exits.
2026-01-06 11:28:55 +0900 - dagster - INFO - To persist information across sessions, set the environment variable DAGSTER_HOME to a directory to use.
2026-01-06 11:28:56 +0900 - dagster - INFO - Launching Dagster services...
2026-01-06 11:28:57 +0900 - dagster.daemon - INFO - Instance is configured with the following daemons: ['AssetDaemon', 'BackfillDaemon', 'FreshnessDaemon', 'QueuedRunCoordinatorDaemon', 'SchedulerDaemon', 'SensorDaemon']
2026-01-06 11:28:58 +0900 - dagster.daemon.SensorDaemon - INFO - Checking for new runs for sensor: my_sensor
2026-01-06 11:28:58 +0900 - dagster-webserver - INFO - Serving dagster-webserver on http://127.0.0.1:3000 in process 9436
2026-01-06 11:28:58 +0900 - dagster.daemon.SensorDaemon - INFO - Sensor my_sensor skipped: No new objects.
コマンドの実行時にはAWSの認証情報が設定されている必要があります。もしDagsterが認証情報を取得できないと NoCredentialsError() が発生します。お使いの環境に応じて設定してください。余談ですが私の場合は認証情報の管理に aws-vault を使用しているので、aws-vault exec <profile> -- dg dev などで実行しています。
Dagsterが起動すると http://127.0.0.1:3000 でサーバーが立ち上がります。ブラウザ経由でこれにアクセスすると次のような画面が表示されます。
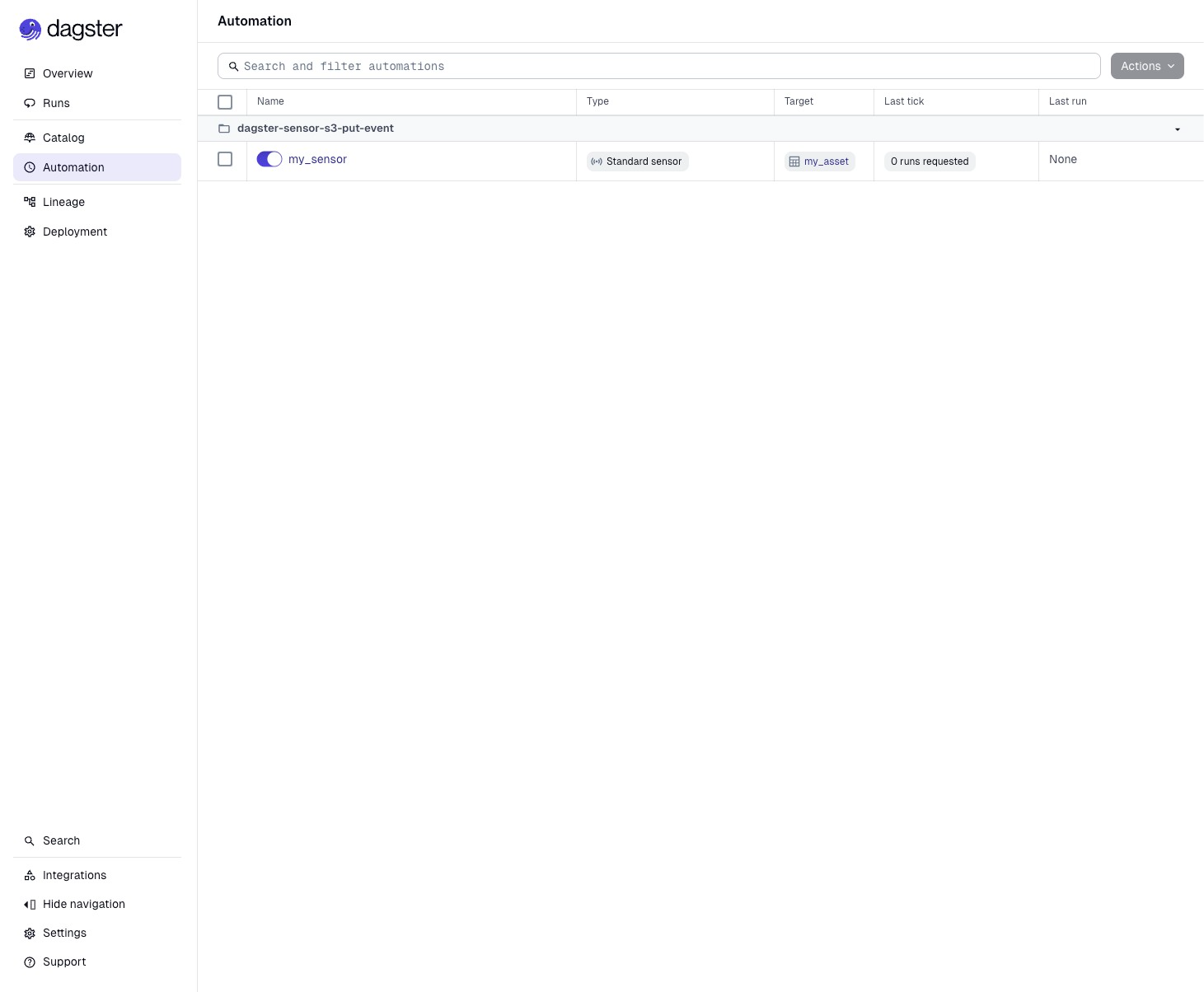
左側のペインのAutomationを押すと先ほど定義した my_sensor が有効化された状態で表示されています。
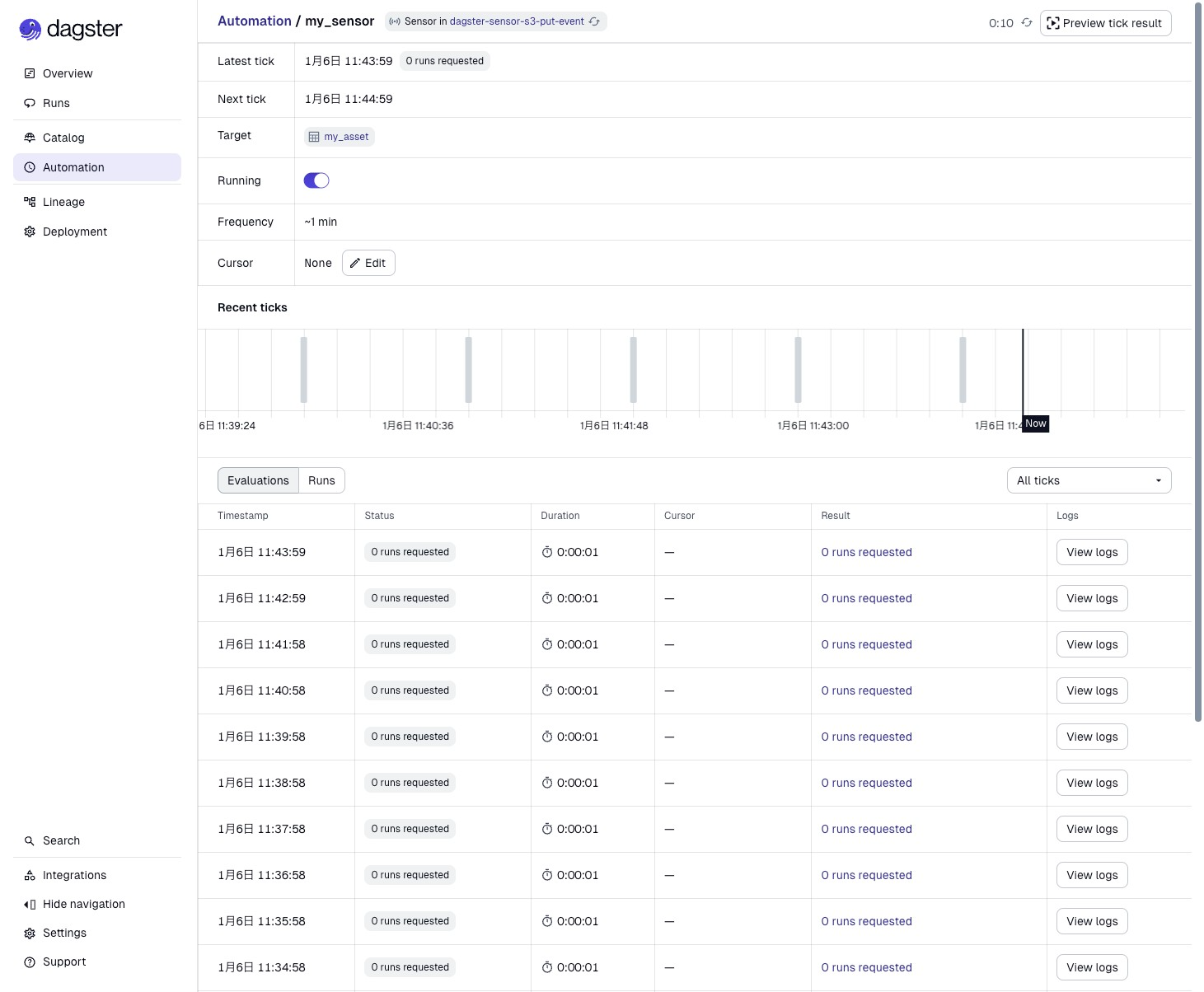
さらに my_sensor を押すとSensorの状態を詳しく確認できます。おおよそ1分間隔でSensorの評価がされていることがわかります。今S3バケットには何も配置していないのでAssetの実行はスキップされ続けている状態です。
適当なCSVファイルをS3にアップロードして動作検証をしてみます。中身は空で問題ないです。
touch test.csv
aws s3 cp test.csv s3://dagster-sensor-demo-bucket/incoming/
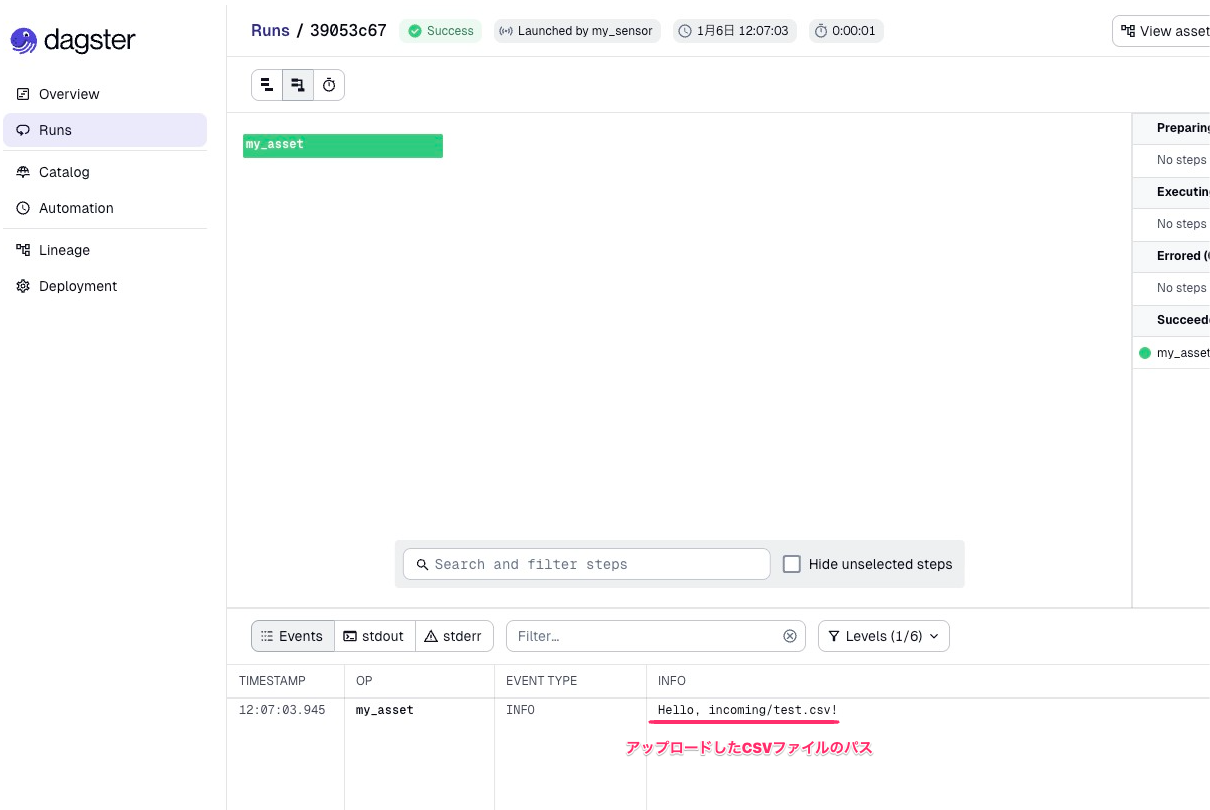
Sensor評価の結果、新たにCSVファイルがアップロードされたと判断され、Assetが実行されました。
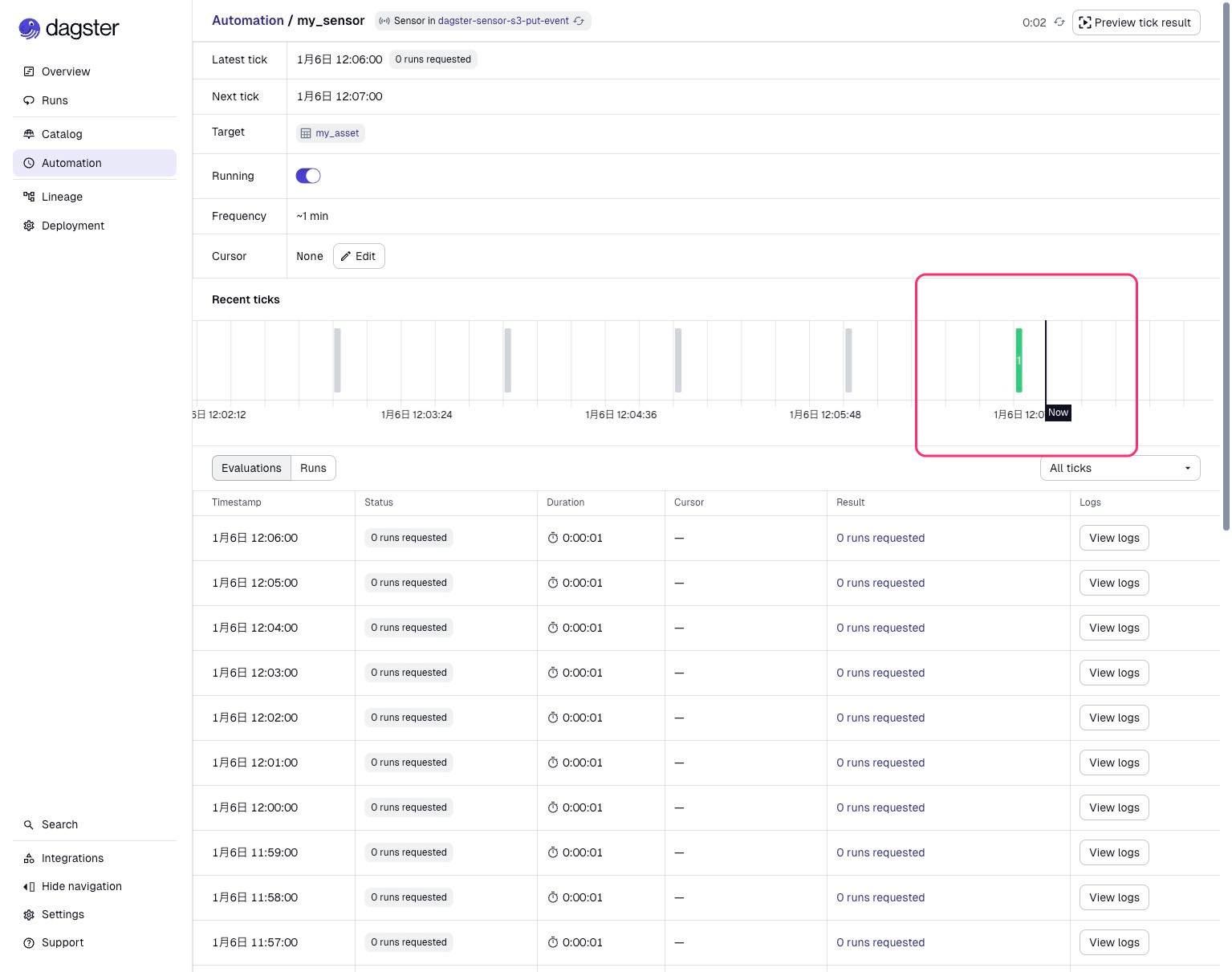
画像下側のRunsからこの実行の詳細を見ることができます。ログにはSensorから受け取ったS3パスが出力されていますね。先ほどアップロードしたCSVファイルを検知して実行されたことがわかります。
続いて run_key の効果も確認してみます。上で説明した通り、同じ名前のファイルを再度アップロードしても実行はスキップされるはずです。
aws s3 cp test.csv s3://dagster-sensor-demo-bucket/incoming/
操作画面ではファイルアップロードがなかったときと同じ表示になりますが、Dagster Daemonのログに以下の出力がされていました。想定通り同じS3のパスであることを理由に実行がスキップされています。これにより同じファイルが何度も更新されるような場合でもJobの重複実行を避けることができます。
2026-01-06 12:25:02 +0900 - dagster.daemon.SensorDaemon - INFO - Checking for new runs for sensor: my_sensor
2026-01-06 12:25:03 +0900 - dagster.daemon.SensorDaemon - INFO - Skipping 1 run for sensor my_sensor already completed with run keys: ["incoming/test.csv"]
まとめ
このブログではDagsterのSensorを使ってS3へのファイルアップロードを検知し、Assetを実行する方法を紹介しました。
Sensorを実装する上でのポイントをおさらいします。
-
Sensorは定期的なポーリング
外部の状態変化を監視し、条件を満たした時にAssetやJobを起動します。 -
カーソルで状態管理
context.cursorを使って前回の処理位置を保持し、新規の変更のみを処理対象にします。 -
run_keyで重複防止
同じキーを持つRunRequestは再実行されないため、重複実行を防止できます。
今回はローカル環境での動作検証を行いました。
この検証で用いた get_objects() はシンプルな実装ですが、ファイル数が多い環境ではSensor評価のたびにバケット内のオブジェクトリストを取得するため、非効率な処理になる上、S3のList API呼び出し回数が増加します。本番環境ではEventBridgeやSQSなどのイベント駆動型アーキテクチャを検討することで、効率的な構成を実現できます。次回以降ではより本番向けの構成の検証を行いたいと思います。
それではまた次のブログでお会いしましょう。









